26 Nov 2025·8 menit
Cara Membangun Aplikasi Web untuk Melacak Hambatan Operasional
Panduan langkah‑demi‑langkah untuk merencanakan, merancang, dan meluncurkan aplikasi web yang menangkap data alur kerja, mendeteksi hambatan, dan membantu tim memperbaiki keterlambatan.
Mulai dari Masalah dan Keputusan
Aplikasi pelacakan proses hanya berguna jika menjawab pertanyaan spesifik: “Di mana kita tersendat, dan apa yang harus kita lakukan?” Sebelum Anda mendesain layar atau memilih arsitektur aplikasi web, definisikan apa yang dimaksud dengan “hambatan” dalam operasi Anda.
Definisikan apa yang dihitung sebagai hambatan
Hambatan bisa berupa langkah (mis. “tinjauan QA”), tim (mis. “pemenuhan”), sistem (mis. “gateway pembayaran”), atau bahkan vendor (mis. “penjemputan kurir”). Pilih definisi yang benar-benar akan Anda kelola. Contoh:
- Suatu langkah jadi hambatan ketika rata‑rata waktu antri melebihi 24 jam.
- Sebuah tim jadi hambatan ketika WIP (pekerjaan dalam proses) tetap di atas ambang selama 3 hari.
- Sebuah sistem jadi hambatan ketika insiden menyebabkan lonjakan waktu siklus di luar kisaran yang disepakati.
Daftar keputusan yang harus didukung aplikasi
Dasbor operasional Anda harus mendorong tindakan, bukan sekadar pelaporan. Tuliskan keputusan yang ingin Anda ambil lebih cepat dan dengan lebih percaya diri, misalnya:
- Staffing: “Apakah kita memindahkan satu orang dari Tim A ke Tim B minggu ini?”
- Prioritas: “Pesanan/tiket mana yang harus diprioritaskan agar SLA tetap aman?”
- Otomatisasi: “Langkah mana yang cukup stabil (dan mahal) untuk diotomatisasi terlebih dahulu?”
Identifikasi pengguna utama dan apa yang mereka butuhkan
Pengguna berbeda memerlukan tampilan berbeda:
- Manajer operasional membutuhkan tampilan “di mana harus intervensi hari ini”.
- Pimpinan tim perlu drill‑down ke antrian individu, penghambat, dan serah terima.
- Analis membutuhkan definisi konsisten dan ekspor untuk analitik alur kerja.
Tetapkan metrik keberhasilan untuk aplikasinya sendiri
Tentukan bagaimana Anda tahu aplikasinya bekerja. Ukuran yang baik termasuk adopsi (pengguna aktif mingguan), waktu yang dihemat untuk pelaporan, dan resolusi lebih cepat (pengurangan time‑to‑detect dan time‑to‑fix hambatan). Metrik ini menjaga fokus pada hasil, bukan fitur.
Pilih Alur Kerja dan Tulis Peta Proses Sederhana
Sebelum mendesain tabel, dasbor, atau peringatan, pilih alur kerja yang bisa Anda jelaskan dalam satu kalimat. Tujuannya adalah melacak di mana pekerjaan menunggu—jadi mulailah kecil dan pilih satu atau dua proses yang penting dan menghasilkan volume stabil, seperti pemenuhan pesanan, tiket dukungan, atau onboarding karyawan.
Lingkup yang ketat menjaga definisi selesai tetap jelas dan mencegah proyek terhenti karena tim yang berbeda berselisih soal bagaimana proses seharusnya berjalan.
Mulai dengan 1–2 proses dengan sinyal tinggi
Pilih alur kerja yang:
- Terjadi sering (cukup data untuk melihat pola)
- Melibatkan setidaknya satu serah terima (di tempat antrian muncul)
- Memiliki dampak pelanggan yang jelas (waktu, biaya, kepuasan)
Contoh: “tiket dukungan” seringkali lebih baik daripada “customer success” karena memiliki unit kerja yang jelas dan aksi yang diberi cap waktu.
Petakan langkah dan serah terima dengan bahasa sederhana
Tulis alur kerja sebagai daftar langkah sederhana menggunakan istilah yang sudah dipakai tim. Anda tidak sedang mendokumentasikan kebijakan—Anda mengidentifikasi status yang dilalui item kerja.
Contoh peta proses ringan:
- Ticket dibuat → triage → ditugaskan → agen mengerjakan → menunggu pelanggan → terselesaikan
Sebutkan serah terima secara eksplisit (triage → ditugaskan, agen → spesialis, dll.). Serah terima adalah tempat di mana waktu antri sering tersembunyi, dan itu momen yang ingin Anda ukur nanti.
Definisikan event mulai/selesai dan apa itu “selesai” untuk setiap langkah
Untuk setiap langkah, tulis dua hal:
- Start event (apa yang membuktikan langkah dimulai?)
- End event (apa yang membuktikan langkah selesai?)
Buat dapat diamati. “Agen mulai menyelidiki” subjektif; “status berubah menjadi In Progress” atau “catatan internal pertama ditambahkan” bisa dilacak.
Juga definisikan apa arti “selesai” agar aplikasi tidak salah menafsirkan penyelesaian parsial sebagai selesai. Misalnya, “terselesaikan” bisa berarti “pesan resolusi dikirim dan ticket diberi label Resolved,” bukan hanya “pekerjaan internal selesai.”
Catat pengecualian umum yang akan Anda lacak nanti
Operasi nyata memiliki jalur yang berantakan: rework, eskalasi, informasi hilang, dan item yang dibuka ulang. Jangan mencoba memodelkan semuanya pada hari pertama—cukup tuliskan pengecualian sehingga Anda bisa menambahnya secara terencana nanti.
Catatan sederhana seperti “10–15% tiket diekskalasi ke Tier 2” sudah cukup. Anda akan menggunakan catatan ini untuk memutuskan apakah pengecualian menjadi langkah sendiri, tag, atau alur terpisah saat memperluas sistem.
Definisikan Metrik yang Sebenarnya Mengungkap Hambatan
Hambatan bukan sekadar perasaan—itu perlambatan yang terukur pada langkah tertentu. Sebelum membuat grafik, putuskan angka mana yang akan membuktikan di mana pekerjaan menumpuk dan mengapa.
Pilih seperangkat metrik inti kecil
Mulailah dengan empat metrik yang bekerja di sebagian besar alur kerja:
- Waktu siklus (Cycle time): berapa lama sebuah item dari start ke done.
- Waktu tunggu/antrian (Wait/queue time): berapa lama item diam antara langkah.
- Throughput: berapa banyak item yang selesai per periode waktu.
- WIP (work in progress): berapa banyak item yang saat ini “dalam sistem”.
Metrik ini mencakup kecepatan (cycle), ketidakteraktifan (queue), output (throughput), dan beban (WIP). Sebagian besar “penyumbatan misterius” muncul sebagai peningkatan waktu antri dan WIP pada langkah tertentu.
Definisikan perhitungan (termasuk kasus tepi)
Tulis definisi yang bisa disetujui seluruh tim, lalu terapkan persis itu.
- Cycle time =
done_timestamp − start_timestamp.- Kasus tepi: item yang dibuka ulang (perlakukan sebagai siklus baru vs memperpanjang siklus asli), item yang tidak pernah dimulai (kecualikan dari cycle time tapi hitung dalam WIP), timestamp hilang (tandai sebagai kualitas data buruk).
- Queue time = jumlah celah antar langkah saat status adalah “waiting”.
- Kasus tepi: malam/minggu (waktu kalender vs jam kerja), status diblokir (hitung terpisah dari penantian normal jika ingin penyebab lebih jelas).
- Throughput = hitung item dengan
done_timestampdalam jendela.- Kasus tepi: pembatalan (kecualikan atau lacak terpisah), penyelesaian parsial.
- WIP = hitung item yang tidak berada di status terminal pada titik waktu tertentu.
- Kasus tepi: item on‑hold (masih WIP, tapi Anda mungkin ingin kategori “blocked WIP” terpisah).
Pilih pemecahan (breakdowns) yang mendorong keputusan
Pilih slice yang benar‑benar digunakan manajer Anda: tim, saluran, lini produk, wilayah, dan prioritas. Tujuannya menjawab, “Di mana lambat, untuk siapa, dan dalam kondisi apa?”
Tetapkan jendela waktu dan target
Tentukan ritme pelaporan Anda (harian dan mingguan umum dipakai) dan definisikan target seperti ambang SLA/SLO (mis. “80% item prioritas tinggi selesai dalam 2 hari”). Target membuat dasbor bersifat tindakan, bukan hiasan.
Rencanakan Sumber Data dan Metode Pengumpulan
Cara tercepat membuat aplikasi pelacak hambatan mandek adalah berasumsi data akan “langsung ada”. Sebelum mendesain tabel atau grafik, catat dari mana setiap event dan timestamp akan berasal—dan bagaimana Anda menjaganya konsisten dari waktu ke waktu.
Inventarisasi sumber yang sudah Anda miliki
Sebagian besar tim operasi sudah melacak pekerjaan di beberapa tempat. Titik awal umum meliputi:
- Spreadsheet untuk serah terima, log harian, atau hitungan produksi
- Sistem ERP/CRM (pesanan, pelanggan, langkah pemenuhan)
- Alat tiket (antrian dukungan, permintaan perubahan, tugas pemeliharaan)
- Basis data internal (scan gudang, tabel penjadwalan pekerjaan, data eksekusi manufaktur)
Untuk setiap sumber, catat apa yang bisa disediakannya: ID rekaman stabil, riwayat status (bukan hanya status saat ini), dan setidaknya dua timestamp (masuk langkah, keluar langkah). Tanpa itu, monitoring waktu antrian dan pelacakan waktu siklus akan menjadi tebakan.
Pilih metode capture yang sesuai sumber
Umumnya ada tiga opsi, dan banyak aplikasi menggunakan kombinasi:
- API pull: sinkronisasi terjadwal dari ERP/CRM/alat tiket. Mudah dipahami, tapi Anda harus menangani paginasi, batas laju, dan pembaruan inkremental.
- Webhooks: kirim pembaruan saat pekerjaan berubah. Bagus untuk peringatan hampir waktu‑nyata, tapi desain harus menangani retry dan event yang datang tidak berurutan.
- Entri manual / unggah CSV: berguna untuk tim yang mulai dari spreadsheet atau kasus pinggiran. Buat aman dengan template, validasi, dan pesan error yang jelas.
Rencanakan kualitas data (karena itu akan terjadi)
Harapkan timestamp hilang, duplikat, dan status yang tidak konsisten (“In Progress” vs “Working”). Bangun aturan sejak awal:
- Utamakan log event yang tidak dapat diubah daripada menimpa rekaman
- Dedup dengan source ID + waktu event + status
- Normalisasikan status ke langkah kanonis aplikasi Anda
- Tandai rekaman yang tidak bisa menghasilkan pelacakan waktu siklus yang andal
Putuskan cadence refresh
Tidak semua proses perlu pembaruan waktu‑nyata. Pilih berdasarkan keputusan:
- Waktu‑nyata: dispatching, triage dukungan, risiko SLA
- Per jam: throughput gudang, monitoring waktu antrian
- Harian: pelaporan mingguan, review perbaikan berkelanjutan
Tuliskan sekarang; itu menentukan strategi sinkronisasi, biaya, dan ekspektasi untuk dasbor operasi Anda.
Rancang Model Data yang Dibuat untuk Analisis Berbasis Waktu
Aplikasi pelacak hambatan hidup atau mati berdasarkan seberapa baik ia bisa menjawab pertanyaan waktu: “Berapa lama ini?”, “Di mana ia menunggu?”, dan “Apa yang berubah tepat sebelum melambat?” Cara termudah untuk mendukung pertanyaan‑pertanyaan itu nanti adalah memodelkan data di sekitar event dan timestamp sejak hari pertama.
Mulai dengan entitas inti
Jaga model kecil dan jelas:
- Process: alur kerja keseluruhan (mis. “Pemenuhan Pesanan”).
- Step: tahap dalam proses (mis. “Pick”, “Pack”, “Ship”).
- Work item: unit yang bergerak melalui langkah (tiket, pesanan, klaim).
- Event: perubahan status yang dicatat (masuk langkah, ditugaskan, diblokir, selesai).
- User/Team dan Assignment: siapa yang memegang pekerjaan pada waktu tertentu.
Struktur ini memungkinkan Anda mengukur waktu siklus per langkah, waktu antri antar langkah, dan throughput seluruh proses tanpa membuat kasus khusus.
Utamakan log event daripada field “status saat ini”
Anggap setiap perubahan status sebagai rekaman event yang tidak dapat diubah. Daripada menimpa current_step dan kehilangan riwayat, tambahkan event seperti:
- work_item_id
- from_step → to_step (atau “entered_step”)
- event_type (assigned, started, blocked, completed)
- event_time
Anda masih bisa menyimpan snapshot “status saat ini” untuk performa, tetapi analitik harus bergantung pada log event.
Buat waktu dan keterelusuran tidak bisa ditawar
Simpan timestamp secara konsisten dalam UTC. Juga simpan identifier sumber asli (mis. kunci issue Jira, ID pesanan ERP) pada work item dan event, sehingga setiap grafik bisa ditelusuri kembali ke rekaman nyata.
Tangkap pengecualian tanpa menciptakan beban kerja berlebih
Rencanakan field ringan untuk momen yang menjelaskan keterlambatan:
- reason_code (opsi standar seperti “Waiting on customer”)
- comment (teks opsional)
- blocked_flag atau severity
Buat mereka opsional dan mudah diisi, agar Anda belajar dari pengecualian tanpa mengubah aplikasi menjadi latihan mengisi formulir.
Pilih Arsitektur yang Cocok untuk Tim Anda
Pasang Peringatan Dini
Buat aturan ambang sederhana supaya kemacetan terdeteksi sebelum tinjauan mingguan.
“Arsitektur terbaik” adalah yang bisa dibangun, dipahami, dan dioperasikan tim Anda bertahun‑tahun. Mulailah dengan memilih stack yang sesuai dengan pool perekrutan dan keterampilan yang ada—pilihan umum dan terdukung termasuk React + Node.js, Django, atau Rails. Konsistensi lebih baik daripada hal baru ketika Anda menjalankan dasbor operasi yang digunakan setiap hari.
Pisahkan concern supaya sistem tetap mudah diedit
Aplikasi pelacak hambatan biasanya bekerja lebih baik ketika Anda membaginya ke lapisan yang jelas:
- Ingestion: menerima event (perubahan status, timestamp, serah terima) dari form, integrasi, atau impor.
- Storage: database transaksional untuk penulisan yang andal dan riwayat audit.
- Analytics queries: query atau view yang dioptimalkan baca untuk menghitung waktu siklus, waktu antri, dan throughput.
- UI/API: endpoint dan layar yang menjaga dasbor cepat dan dapat diprediksi.
Pemisahan ini memungkinkan Anda mengubah satu bagian (mis. menambah sumber data) tanpa menulis ulang semuanya.
Tentukan di mana perhitungan harus dijalankan
Beberapa metrik cukup sederhana untuk dihitung dalam query database (mis. “rata‑rata waktu antri per langkah 7 hari terakhir”). Lainnya mahal atau butuh pra‑proses (mis. persentil, deteksi anomali, kohort mingguan). Aturan praktis:
- Lakukan filter real‑time dan breakdown di database.
- Gunakan background jobs untuk pra‑hitung agregat berat dan simpan hasilnya agar dashboard cepat.
- Tambahkan lapisan analitik hanya jika tim Anda akan memeliharanya dengan percaya diri.
Rencanakan performa sejak dini
Dasbor operasional gagal ketika terasa lambat. Gunakan indexing pada timestamp, ID langkah alur kerja, dan tenant/team ID. Tambah paginasi untuk log event. Cache tampilan dasbor umum (seperti “hari ini” dan “7 hari terakhir”) dan invalidasi cache saat event baru datang.
Jika Anda ingin diskusi perdagangan yang lebih dalam, simpan catatan keputusan singkat di repo agar perubahan masa depan tidak menyimpang.
Jalur lebih cepat untuk tim yang ingin segera mengirimkan
Jika tujuan Anda memvalidasi analitik alur kerja dan peringatan sebelum komit ke build penuh, platform vibe‑coding seperti Koder.ai bisa membantu Anda menyiapkan versi pertama lebih cepat: Anda menjelaskan alur kerja, entitas, dan dasbor lewat chat, lalu iterasi pada UI React yang dihasilkan dan backend Go + PostgreSQL saat Anda menyempurnakan instrumentasi KPI.
Keuntungan praktis untuk aplikasi pelacak hambatan adalah kecepatan mendapatkan umpan balik: Anda bisa pilot ingestion (API pull, webhook, atau impor CSV), menambah layar drill‑down, dan menyesuaikan definisi metrik tanpa berminggu‑minggu scaffolding. Saat siap, Koder.ai juga mendukung ekspor kode sumber dan deployment/hosting, memudahkan perpindahan dari prototype ke alat internal yang dipelihara.
Rancang Pengalaman Dasbor dan Drill‑Down
Aplikasi pelacak hambatan berhasil atau gagal berdasarkan apakah orang bisa menjawab satu pertanyaan dengan cepat: “Di mana pekerjaan tersendat sekarang, dan item mana yang menyebabkannya?” Dasbor Anda harus membuat jalur itu jelas, bahkan untuk seseorang yang hanya berkunjung seminggu sekali.
Mulai dengan 2–3 layar inti
Pertahankan rilis pertama ringkas:
- Overview dashboard: papan status untuk waktu siklus, waktu antri, dan langkah yang paling diblokir.
- Daftar work‑item: tabel yang bisa dicari dan difilter dari item yang terkena dampak keterlambatan.
- Detail alur kerja: tampilan langkah‑per‑langkah yang menunjukkan waktu di setiap tahap dan titik serah terima.
Layar‑layar ini menciptakan alur drill‑down alami tanpa memaksa pengguna mempelajari UI kompleks.
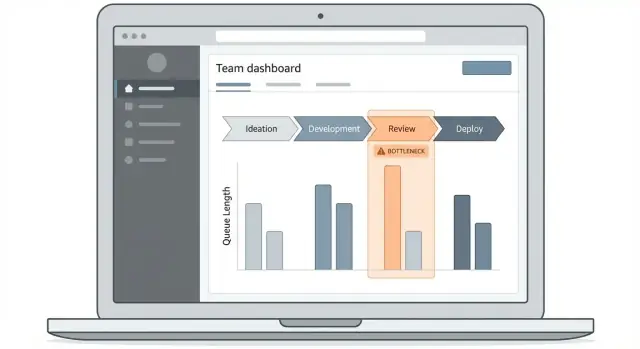
Gunakan visual yang menjelaskan waktu dan aliran
Pilih tipe grafik yang cocok dengan pertanyaan operasional:
- Funnel per tahap: menunjukkan di mana volume menumpuk (bagus untuk mendeteksi antrian).
- Bar waktu‑di‑tahap: bandingkan langkah berdasarkan median dan persentil, bukan hanya rata‑rata.
- Garis tren: jawab “apakah ini membaik atau memburuk?” selama minggu‑minggu.
- Heatmap: ungkap pola seperti “Senin banyak di Review” atau “serah terima shift malam.”
Gunakan label yang jelas: “Waktu menunggu” vs. “Latensi antrian.”
Buat filter konsisten dan mudah terlihat
Gunakan satu bar filter bersama antar layar (penempatan sama, default sama): rentang tanggal, tim, prioritas, dan langkah. Tampilkan filter aktif sebagai chip agar orang tidak salah membaca angka.
Rancang jalur drill‑down yang jelas
Setiap tile KPI harus bisa diklik dan mengarah ke sesuatu yang berguna:
KPI → langkah → daftar item terdampak
Contoh: mengklik “Waktu antri terpanjang” membuka detail langkah, lalu satu klik lagi menunjukkan item‑item yang saat ini menunggu di sana—diurutkan berdasarkan usia, prioritas, dan pemilik. Ini mengubah rasa ingin tahu menjadi daftar tindakan konkret, yang membuat dasbor digunakan daripada diabaikan.
Tambahkan Peringatan dan Sinyal Peringatan Dini
Iterasi Tanpa Takut
Gunakan snapshot dan rollback saat perubahan metrik atau pembaruan UI perlu revert cepat.
Dasbor bagus untuk review, tapi hambatan biasanya paling merugikan di antara pertemuan. Peringatan mengubah aplikasi Anda menjadi sistem peringatan dini: Anda menemukan masalah saat terbentuk, bukan setelah minggu terbuang.
Mulai dengan aturan yang jelas dan sederhana
Mulailah dengan beberapa tipe peringatan yang tim Anda sudah setujui sebagai “buruk”:
- Pelanggaran ambang: waktu siklus atau waktu antri di atas batas yang diketahui (mis. “Review step > 24 jam”).
- Peningkatan abnormal: median waktu siklus hari ini naik 30% vs minggu lalu.
- Item macet: tidak ada perubahan status selama N jam/hari, atau item melebihi usia maksimum.
Sederhanakan versi pertama. Beberapa aturan deterministik menangkap sebagian besar masalah dan lebih mudah dipercaya daripada model kompleks.
Tambahkan pemeriksaan anomali ringan
Setelah ambang stabil, tambahkan sinyal “aneh” dasar:
- Persentase perubahan vs minggu lalu (hari yang sama membantu mengurangi false alarm).
- Drift moving average (mis. rata‑rata 7 hari naik terus).
- Mismatch volume (input naik lebih cepat daripada output pada suatu langkah).
Buat anomali saran, bukan darurat: beri label “Heads up” sampai pengguna mengonfirmasi berguna.
Kirim peringatan ke tempat orang bekerja
Dukung beberapa saluran sehingga tim bisa memilih yang cocok:
- Email untuk manajer dan ringkasan harian
- Slack/Microsoft Teams untuk triage waktu‑nyata
- Notifikasi in‑app untuk pemilik di dalam alat
Buat setiap peringatan dapat ditindaklanjuti
Peringatan harus menjawab “apa, di mana, dan langkah selanjutnya”:
- Langkah mana yang terpengaruh, dan jendela waktu
- Pendorong utama (mis. tim, kategori, prioritas)
- Tautan langsung untuk investigasi, seperti:
/dashboard?step=review&range=7d&filter=stuck
Jika peringatan tidak mengarah ke tindakan konkret, orang akan mematikannya—perlakukan kualitas peringatan sebagai fitur produk, bukan tambahan.
Tangani Izin, Keamanan, dan Auditabilitas
Aplikasi pelacak hambatan cepat menjadi “sumber kebenaran.” Itu baik—sampai orang yang salah mengubah definisi, mengekspor data sensitif, atau membagikan dasbor di luar timnya. Izin dan jejak audit bukan birokrasi; mereka melindungi kepercayaan pada angka.
Definisikan peran dan aturan akses
Mulai dengan model peran kecil dan jelas, kembangkan hanya bila perlu:
- Viewer: akses baca‑saja ke dasbor dan laporan.
- Manager: bisa memfilter berdasarkan tim, membuat saved views, mengakui peringatan, dan menambahkan catatan (tetapi tidak mengubah pengaturan global).
- Admin: mengelola definisi proses, rumus KPI, integrasi, dan akses pengguna.
Jelaskan secara eksplisit apa yang bisa dilakukan tiap peran: melihat event mentah vs agregat, mengekspor data, mengubah ambang, dan mengelola integrasi.
Pisahkan data berdasarkan tim atau unit bisnis
Jika banyak tim menggunakan aplikasi, tegakkan pemisahan di layer data—bukan hanya di UI. Pilihan umum:
- Multi‑tenant: setiap rekaman punya
tenant_id, dan setiap query di‑scope ke situ. - Partitions/projects: workspace terpisah per unit bisnis, dengan pengaturan dan dasbor independen.
Putuskan sejak awal apakah manajer bisa melihat data tim lain. Buat visibilitas lintas‑tim sebagai izin yang disengaja, bukan default.
Autentikasi aman (SSO atau siap MFA)
Jika organisasi Anda punya SSO (SAML/OIDC), gunakan supaya offboarding dan kontrol akses tersentralisasi. Kalau tidak, implementasikan login yang siap MFA (TOTP atau passkeys), mendukung reset kata sandi aman, dan memberlakukan timeout sesi.
Buat perubahan bisa diaudit
Log aksi yang bisa mengubah hasil atau mengekspos data: ekspor, perubahan ambang, edit alur kerja, pembaruan izin, dan pengaturan integrasi. Rekam siapa, kapan, apa yang berubah (sebelum/sesudah), dan di mana (workspace/tenant). Sediakan tampilan “Audit Log” agar masalah bisa diselidiki cepat.
Ubah Insight Menjadi Tindakan dan Perbaikan Proses
Dasbor hambatan hanya penting jika mengubah apa yang dilakukan orang selanjutnya. Tujuan bagian ini adalah mengubah “grafik menarik” menjadi ritme operasi yang dapat diulang: putuskan, bertindak, ukur, dan pertahankan apa yang berhasil.
Buat review hambatan ringan
Tetapkan cadence mingguan sederhana (30–45 menit) dengan pemilik yang jelas. Mulai dengan 1–3 hambatan teratas berdasarkan impact (mis. waktu antri tertinggi atau penurunan throughput terbesar), lalu sepakati satu tindakan per hambatan.
Jaga alur kerja kecil:
- Owner: satu orang bertanggung jawab per tindakan
- Due date: review berikutnya secara default
- Definition of done: perubahan terukur (bukan “selidiki lebih lanjut”)
Simpan keputusan langsung di aplikasi agar dasbor dan log aksi tetap terhubung.
Lacak perbaikan sebagai eksperimen
Perlakukan perbaikan seperti eksperimen agar Anda cepat belajar dan menghindari “optimisasi acak.” Untuk setiap perubahan, catat:
- Hipotesis (apa yang memperlambat dan kenapa)
- Perubahan (apa yang akan dilakukan)
- Dampak yang diharapkan (metrik apa yang harus bergerak, dan berapa banyak)
- Hasil (apa yang sebenarnya terjadi)
Seiring waktu, ini menjadi playbook apa yang mengurangi waktu siklus, apa yang mengurangi rework, dan apa yang tidak.
Tambah konteks dengan anotasi
Grafik bisa menyesatkan tanpa konteks. Tambahkan anotasi sederhana pada timeline (mis. pegawai baru onboarded, outage sistem, pembaruan kebijakan) agar pemirsa dapat menginterpretasikan pergeseran waktu antri atau throughput dengan benar.
Permudah berbagi
Sediakan opsi ekspor untuk analisis dan pelaporan—unduhan CSV dan laporan terjadwal—agar tim dapat memasukkan hasil ke update operasional dan tinjauan kepemimpinan. Jika Anda sudah punya halaman pelaporan, tautkan dari dasbor (mis. /reports).
Deploy, Monitor, dan Jaga Data Tetap Segar
Luncurkan Pilot Cepat
Gunakan hosting Koder.ai untuk menjalankan pilot tool internal Anda dan iterasi bersama pengguna nyata.
Aplikasi pelacak hambatan hanya berguna jika konsisten tersedia dan angkanya tetap dapat dipercaya. Perlakukan deployment dan kesegaran data sebagai bagian produk, bukan hal tambahan.
Gunakan lingkungan terpisah dan deploy yang dapat diulang
Siapkan dev / staging / prod sejak awal. Staging harus meniru produksi (database engine sama, volume data mirip, background job sama) agar Anda bisa menangkap query lambat dan migrasi rusak sebelum pengguna.
Otomatiskan deployment dengan pipeline tunggal: jalankan tes, terapkan migration, deploy, lalu lakukan smoke check cepat (log in, muat dasbor, verifikasi ingestion berjalan). Jaga deploy kecil dan sering; mengurangi risiko dan mempermudah rollback.
Monitor aplikasi dan pipeline
Anda perlu monitoring dari dua sisi:
- Kesehatan aplikasi: tingkat error, latency, endpoint lambat, dan query lambat.
- Kesehatan data: kegagalan ingestion, ukuran backlog, dan “waktu sejak event terakhir diterima.”
Alert pada gejala yang dirasakan pengguna (dasbor timeout) dan sinyal awal (antrian tumbuh 30 menit). Juga lacak kegagalan perhitungan metrik—waktu siklus yang hilang bisa terlihat seperti “perbaikan.”
Jaga data tetap segar: event terlambat, koreksi, dan backfill
Data operasional datang terlambat, tidak berurutan, atau dikoreksi. Rencanakan untuk:
- Ingestion idempotent (memproses ulang event yang sama tidak menggandakan)
- Backfill untuk rentang tanggal ketika sumber down
- Recompute saat data referensi berubah (mis. kalender shift diperbarui)
Definisikan apa arti “segar” (mis. 95% event dalam 5 menit) dan tampilkan kesegaran di UI.
Tulis runbook agar perbaikan tidak tebak‑tebakan
Dokumentasikan runbook langkah demi langkah: cara merestart sinkronisasi yang rusak, memvalidasi KPI kemarin, dan memastikan backfill tidak mengubah angka historis secara tak terduga. Simpan bersama proyek dan tautkan dari /docs sehingga tim bisa merespons cepat.
Iterasi dengan Pengguna dan Perluas Cakupan
Aplikasi pelacak hambatan berhasil ketika orang mempercayainya dan benar‑benar menggunakannya. Itu terjadi setelah Anda mengamati pengguna nyata mencoba menjawab pertanyaan nyata (“Kenapa persetujuan lambat minggu ini?”) lalu mengasah produk di sekitar alur kerja tersebut.
Mulai dengan pilot dan pelajari yang rusak
Mulailah dengan satu tim pilot dan sedikit alur kerja. Jaga lingkup cukup sempit sehingga Anda bisa mengamati penggunaan dan merespons cepat.
Dalam minggu pertama atau dua, fokus pada apa yang membingungkan atau hilang:
- Grafik mana yang sering disalahpahami pengguna?
- Di mana mereka kebingungan saat drill‑down?
- Data apa yang mereka harapkan tapi tidak ditemukan?
- Hambatan operasional mana yang terasa “jelas” bagi mereka tapi tidak tercermin di aplikasi?
Tangkap umpan balik langsung di alat (prompt sederhana “Apakah ini berguna?” di layar kunci bekerja baik) sehingga Anda tidak bergantung pada ingatan dari rapat.
Validasi metrik untuk mencegah “argumen dasbor”
Sebelum memperluas ke lebih banyak tim, kunci definisi dengan orang yang akan dimintai pertanggungjawaban. Banyak rollout gagal karena tim tidak sepakat soal makna metrik.
Untuk setiap KPI (waktu siklus, waktu antri, tingkat rework, pelanggaran SLA), dokumentasikan:
- Event start dan end yang tepat
- Penanganan jeda, akhir pekan, dan timestamp hilang
- Bagaimana pengecualian dihitung (pembatalan, eskalasi, pembukaan kembali)
Lalu tinjau definisi tersebut dengan pengguna dan tambahkan tooltip singkat di UI. Jika Anda mengubah definisi, tampilkan changelog jelas agar orang mengerti kenapa angka bergerak.
Perluas cakupan tanpa membuat aplikasi berantakan
Tambahkan fitur secara hati‑hati dan hanya ketika analitik alur kerja tim pilot stabil. Ekspansi umum berikutnya termasuk langkah kustom (tim berbeda memberi label tahap berbeda), sumber tambahan (tiket + CRM + spreadsheet), dan segmentasi lanjutan (berdasarkan lini produk, wilayah, prioritas, tier pelanggan).
Aturan berguna: tambahkan satu dimensi baru sekaligus dan verifikasi itu meningkatkan keputusan, bukan sekadar pelaporan.
Permudah onboarding agar bisa diulang
Saat Anda menggulirkan ke lebih banyak tim, Anda butuh konsistensi. Buat panduan onboarding singkat: cara menghubungkan data, cara membaca dasbor operasi, dan cara menindaklanjuti peringatan hambatan.
Tautkan orang ke halaman relevan dalam produk dan konten Anda, seperti /pricing dan /blog, sehingga pengguna baru bisa menemukan jawaban sendiri tanpa menunggu sesi pelatihan.