06 Nov 2025·8 menit
Cara Membangun Aplikasi Web untuk Pelacakan Insiden & Postmortem
Blueprint praktis untuk merancang, membangun, dan meluncurkan aplikasi web pelacakan insiden dan postmortem—mulai dari workflow hingga pemodelan data dan UX.
Blueprint praktis untuk merancang, membangun, dan meluncurkan aplikasi web pelacakan insiden dan postmortem—mulai dari workflow hingga pemodelan data dan UX.
Sebelum Anda menggambar layar atau memilih database, sepakati apa yang dimaksud tim Anda dengan aplikasi pelacakan insiden—dan apa yang harus dicapai oleh “manajemen postmortem”. Tim sering menggunakan kata yang sama dengan makna berbeda: bagi satu grup, insiden adalah masalah yang dilaporkan pelanggan; bagi grup lain, hanya outage Sev-1 yang memicu eskalasi on-call.
Tulis definisi singkat yang menjawab:
Definisi ini mengarahkan workflow respons insiden Anda dan mencegah aplikasi menjadi terlalu ketat (tak ada yang menggunakannya) atau terlalu longgar (data tidak konsisten).
Putuskan apa itu postmortem di organisasi Anda: ringkasan ringan untuk setiap insiden, atau RCA penuh hanya untuk kejadian berdampak tinggi. Jelaskan apakah tujuannya adalah pembelajaran, kepatuhan, mengurangi pengulangan insiden, atau ketiganya.
Aturan yang berguna: jika Anda mengharapkan postmortem menghasilkan perubahan, alat Anda harus mendukung pelacakan item tindakan, bukan sekadar penyimpanan dokumen.
Kebanyakan tim membuat aplikasi semacam ini untuk memperbaiki beberapa titik nyeri berulang:
Jaga daftar ini tetap ringkas. Setiap fitur yang Anda tambahkan harus memetakan ke setidaknya satu masalah di atas.
Pilih beberapa metrik yang bisa Anda ukur otomatis dari model data aplikasi:
Ini menjadi metrik operasional Anda dan “definisi selesai” untuk rilis pertama.
Aplikasi yang sama melayani peran berbeda dalam operasi on-call:
Jika Anda merancang untuk semua sekaligus, UI akan berantakan. Sebaiknya pilih pengguna utama untuk v1—dan pastikan yang lain masih bisa mendapatkan apa yang mereka butuhkan lewat tampilan yang disesuaikan, dashboard, dan izin nanti.
Workflow yang jelas mencegah dua kegagalan umum: insiden yang terhenti karena tidak ada yang tahu “apa selanjutnya”, dan insiden yang tampak “selesai” namun tak menghasilkan pembelajaran. Mulailah dengan memetakan siklus hidup Anda secara menyeluruh lalu kaitkan peran dan izin ke setiap langkah.
Kebanyakan tim mengikuti busur sederhana: detect → triage → mitigate → resolve → learn. Aplikasi Anda harus mencerminkan ini dengan sedikit langkah yang dapat diprediksi, bukan menu opsi yang tak berujung.
Definisikan apa arti “selesai” untuk setiap tahap. Misalnya, mitigasi mungkin berarti dampak pelanggan dihentikan, meskipun penyebab akar masih belum diketahui.
Buat peran eksplisit agar orang bisa bertindak tanpa menunggu rapat:
UI Anda harus membuat “pemilik saat ini” terlihat, dan workflow harus mendukung delegasi (reassign, tambah responder, rotasi pemimpin).
Pilih status yang diwajibkan dan transisi yang diizinkan, seperti Investigating → Mitigated → Resolved. Tambahkan guardrail:
Pisahkan pembaruan internal (cepat, taktis, bisa berantakan) dari pembaruan untuk stakeholder (jelas, bertimestamp, dikurasi). Bangun dua aliran pembaruan dengan template, visibilitas, dan aturan persetujuan berbeda—seringkali pemimpin insiden adalah satu-satunya publisher untuk pembaruan ke stakeholder.
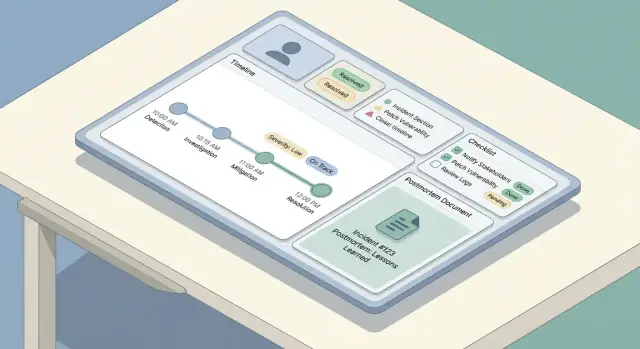
Alat insiden yang baik terasa “sederhana” di UI karena model data yang konsisten di baliknya. Sebelum membangun layar, putuskan objek apa yang ada, bagaimana mereka saling terkait, dan apa yang harus akurat secara historis.
Mulai dengan set kecil objek kelas satu:
Kebanyakan relasi adalah one-to-many:
Gunakan identifier stabil (UUID) untuk insiden dan event. Manusia tetap perlu kunci ramah seperti INC-2025-0042, yang bisa Anda hasilkan dari urutan.
Model ini lebih awal sehingga Anda bisa memfilter, mencari, dan melaporkan:
Data insiden sensitif dan sering ditinjau kembali. Perlakukan edit sebagai data—bukan overwrite:
Struktur ini membuat fitur selanjutnya—pencarian, metrik, dan izin—lebih mudah diimplementasikan tanpa rework.
Ketika sesuatu rusak, tugas aplikasi adalah mengurangi pengetikan dan meningkatkan kejelasan. Bagian ini membahas “jalur tulis”: bagaimana orang membuat insiden, terus memperbaruinya, dan merekonstruksi apa yang terjadi kemudian.
Jaga form intake cukup singkat agar selesai saat Anda troubleshooting. Set default field wajib yang baik adalah:
Semua yang lain sebaiknya opsional pada saat pembuatan (dampak, link tiket pelanggan, dugaan penyebab). Gunakan default cerdas: set start time ke “sekarang”, preselect tim on-call pengguna, dan tawarkan aksi satu-klik “Create & open incident room”.
UI pembaruan Anda harus dioptimalkan untuk edit kecil yang berulang. Sediakan panel pembaruan kompak dengan:
Buat pembaruan bersifat append-friendly: setiap pembaruan menjadi entri bertimestamp, bukan overwrite teks sebelumnya.
Bangun timeline yang mencampur:
Ini menciptakan narasi yang dapat dipercaya tanpa memaksa orang mengingat untuk mencatat setiap klik.
Selama outage, banyak pembaruan terjadi dari ponsel. Prioritaskan layar yang cepat dan minim gesekan: target sentuh besar, satu halaman yang dapat digulir, draft yang ramah offline, dan aksi satu-klik seperti “Post update” dan “Copy incident link”.
Keparahan adalah “speed dial” respons insiden: memberi tahu seberapa mendesak bertindak, seberapa luas komunikasi, dan trade-off apa yang dapat diterima.
Hindari label samar seperti “tinggi/sedang/rendah.” Buat setiap level keparahan memetakan ke ekspektasi operasional yang jelas—terutama waktu respons dan cadence komunikasi.
Contoh:
Tampilkan aturan ini di UI saat memilih keparahan agar responder tidak perlu mencari dokumentasi.
Checklist mengurangi beban kognitif saat orang stres. Jaga checklist singkat, dapat ditindaklanjuti, dan terkait peran.
Polanya berguna adalah beberapa bagian:
Buat item checklist bertimestamp dan dapat diatribusikan, sehingga mereka menjadi bagian dari catatan insiden.
Insiden jarang hidup di satu alat. Aplikasi Anda harus memungkinkan responder melampirkan link ke:
Preferensi link “bertipe” (mis. Runbook, Ticket) sehingga bisa difilter nanti.
Jika organisasi Anda melacak target reliabilitas, tambahkan field ringan seperti SLO affected (ya/tidak), perkiraan pembakaran error budget, dan risiko SLA pelanggan. Buat opsional—tetapi mudah diisi selama atau segera setelah insiden, saat detail masih segar.
Postmortem yang baik mudah dimulai, sulit dilupakan, dan konsisten antar tim. Cara paling sederhana: sediakan template default (dengan field minimal yang wajib) dan isi otomatis dari record insiden sehingga orang menghabiskan waktu untuk berpikir—bukan mengetik ulang.
Template bawaan harus menyeimbangkan struktur dan fleksibilitas:
Buat “Root cause” opsional pada awalnya jika Anda ingin publikasi lebih cepat, tetapi wajibkan sebelum persetujuan akhir.
Postmortem tidak boleh menjadi dokumen terpisah yang terombang-ambing. Saat postmortem dibuat, lampirkan otomatis:
Gunakan ini untuk mengisi pra-template postmortem. Misalnya, blok “Impact” bisa dimulai dengan waktu mulai/selesai insiden dan keparahan saat ini, sementara “Apa yang kami lakukan” bisa menarik entri dari timeline.
Tambahkan workflow ringan sehingga postmortem tidak mandek:
Di setiap langkah, tangkap catatan keputusan: apa yang diubah, mengapa diubah, dan siapa yang menyetujui. Ini menghindari “edit diam‑diam” dan mempermudah audit atau review pembelajaran di masa depan.
Jika Anda ingin UI sederhana, perlakukan review seperti komentar dengan hasil eksplisit (Approve / Request changes) dan simpan persetujuan akhir sebagai catatan tak berubah.
Untuk tim yang membutuhkannya, hubungkan “Published” ke workflow pembaruan status Anda (lihat /blog/integrations-status-updates) tanpa menyalin konten secara manual.
Postmortem hanya mengurangi insiden di masa depan jika pekerjaan tindak lanjut benar-benar dilakukan. Perlakukan action item sebagai objek kelas satu di aplikasi—bukan paragraf di bagian bawah dokumen.
Setiap action item harus punya field konsisten agar bisa ditracking dan diukur:
Tambahkan metadata kecil namun berguna: tag (mis. “monitoring”, “docs”), komponen/layanan, dan “created from” (incident ID dan postmortem ID).
Jangan mengurung action item di halaman postmortem tunggal. Sediakan:
Ini mengubah tindak lanjut menjadi antrean operasional daripada catatan yang terpisah.
Beberapa tugas berulang (game days kuartalan, review runbook). Dukungan template recurring yang menghasilkan item baru sesuai jadwal, sambil menjaga setiap kejadian dapat dilacak secara mandiri.
Jika tim sudah menggunakan tracker lain, izinkan action item menyertakan link referensi eksternal dan ID eksternal, sambil menjadikan aplikasi Anda sebagai sumber untuk pengaitan insiden dan verifikasi.
Bangun nudges ringan: beri tahu pemilik saat jatuh tempo mendekat, tandai item yang terlambat ke lead tim, dan munculkan pola keterlambatan kronis dalam laporan. Jaga aturan dapat dikonfigurasi agar tim bisa menyesuaikan dengan realitas operasi on-call dan beban kerja.
Insiden dan postmortem sering berisi detail sensitif—identitas pelanggan, IP internal, temuan keamanan, atau masalah vendor. Aturan akses yang jelas menjaga alat tetap kolaboratif tanpa menjadi sumber kebocoran data.
Mulai dengan set peran kecil dan mudah dimengerti:
Jika Anda punya banyak tim, pertimbangkan scoping role berdasarkan layanan/tim (mis. “Payments Editors”) daripada memberikan akses global.
Klasifikasikan konten sejak awal, sebelum orang terbiasa:
Polanya praktis adalah menandai bagian sebagai Internal atau Shareable dan menegakkannya pada ekspor dan halaman status. Insiden keamanan mungkin memerlukan tipe insiden terpisah dengan default yang lebih ketat.
Untuk setiap perubahan pada insiden dan postmortem, catat: siapa yang mengubah, apa yang diubah, dan kapan. Sertakan edit ke keparahan, timestamp, dampak, dan persetujuan "final". Buat log audit dapat dicari dan tidak dapat diubah.
Dukung auth kuat dari awal: email + MFA atau magic link, dan tambahkan SSO (SAML/OIDC) jika pengguna mengharapkannya. Gunakan sesi berumur pendek, cookie aman, proteksi CSRF, dan revokasi sesi otomatis saat perubahan peran. Untuk pertimbangan rollout lebih lanjut, lihat /blog/testing-rollout-continuous-improvement.
Saat insiden aktif, orang melakukan scan—bukan membaca. UX Anda harus membuat keadaan saat ini jelas dalam beberapa detik, sambil membiarkan responder menelusuri detail tanpa tersesat.
Mulai dengan tiga layar yang mencakup sebagian besar alur kerja:
Aturan sederhana: halaman detail insiden harus menjawab “Apa yang terjadi sekarang?” di bagian atas, dan “Bagaimana kita sampai di sini?” di bawah.
Insiden menumpuk cepat, jadi buat penemuan cepat dan toleran:
Tawarkan saved views seperti My open incidents atau Sev-1 this week agar insinyur on-call tidak mengulang filter setiap shift.
Gunakan badge konsisten dan color-safe di seluruh aplikasi (hindari nuansa halus yang gagal di bawah tekanan). Pertahankan kosakata status yang sama di mana‑mana: daftar, header detail, dan event timeline.
Sekilas, responder harus melihat:
Prioritaskan kemampuan dipindai:
Rancang untuk momen terburuk: jika seseorang kurang tidur dan paging lewat ponsel, UI harus tetap membimbing mereka ke aksi yang tepat dengan cepat.
Integrasi mengubah tracker insiden dari “tempat menulis catatan” menjadi sistem tempat tim benar‑benar menjalankan insiden. Mulai dengan daftar sistem yang harus Anda hubungkan: monitoring/observability (PagerDuty/Opsgenie, Datadog, CloudWatch), chat (Slack/Teams), email, ticketing (Jira/ServiceNow), dan halaman status.
Sebagian besar tim berakhir dengan campuran:
Alert berisik, di‑retry, dan sering datang tidak berurutan. Definisikan idempotency key stabil per event provider (misal: provider + alert_id + occurrence_id), dan simpan dengan constraint unik. Untuk deduplikasi, tentukan aturan seperti “layanan sama + signature sama dalam 15 menit” harus menambahkan ke insiden yang ada daripada membuat yang baru.
Jadilah eksplisit tentang apa yang dimiliki aplikasi Anda versus apa yang tetap di alat sumber:
Saat integrasi gagal, degrade secara anggun: antri retry, tampilkan peringatan di insiden (“Slack posting delayed”), dan selalu izinkan operator melanjutkan secara manual.
Perlakukan pembaruan status sebagai output utama: aksi “Update” terstruktur di UI Anda harus bisa mempublish ke chat, menambahkan ke timeline insiden, dan opsional menyinkronkan ke halaman status—tanpa menyuruh responder menulis pesan yang sama tiga kali.
Alat insiden Anda adalah sistem "saat outage", jadi utamakan kesederhanaan dan keandalan daripada hal baru yang canggih. Stack terbaik biasanya yang tim Anda bisa bangun, debug, dan operasikan jam 2 pagi dengan percaya diri.
Mulai dari apa yang insinyur Anda sudah produksi. Framework web mainstream (Rails, Django, Laravel, Spring, Express/Nest, ASP.NET) biasanya lebih aman daripada framework baru yang hanya satu orang paham.
Untuk penyimpanan data, database relasional (PostgreSQL/MySQL) cocok untuk record insiden: incidents, updates, participants, action items, dan postmortem mendapat manfaat dari transaksi dan relasi yang jelas. Tambah Redis hanya jika benar‑benar perlu untuk caching, queue, atau lock ephemeral.
Hosting bisa sesederhana platform terkelola (Render/Fly/Heroku‑like) atau cloud yang sudah Anda pakai (AWS/GCP/Azure). Lebih baik gunakan database terkelola dan backup terkelola bila memungkinkan.
Insiden aktif terasa lebih baik dengan pembaruan real-time, tapi Anda tidak selalu perlu websockets di hari pertama.
Pendekatan praktis: desain API/event agar Anda bisa mulai dengan polling dan naik ke websockets nanti tanpa menulis ulang UI.
Jika aplikasi ini gagal saat insiden, ia menjadi bagian dari insiden. Tambahkan:
Perlakukan ini seperti sistem produksi:
Jika Anda ingin memvalidasi workflow dan layar sebelum investasi penuh, pendekatan prototipe bisa berguna: gunakan alat yang bisa menghasilkan prototype bekerja dari spesifikasi chat terperinci, lalu iterasi dengan responder selama tabletop exercise. Karena prototype dapat menghasilkan frontend React nyata dengan backend Go + PostgreSQL (dan mendukung export kode sumber), versi awal bisa diperlakukan sebagai prototype yang bisa dibuang atau sebagai titik mulai yang dapat diperkuat—tanpa kehilangan pembelajaran dari simulasi insiden nyata.
Merilis aplikasi pelacakan insiden tanpa latihan adalah taruhan. Tim terbaik memperlakukan alat ini seperti sistem operasional lain: uji jalur kritis, jalankan drill realistis, rollout bertahap, dan terus tuning berdasarkan penggunaan nyata.
Fokus terlebih dahulu pada alur yang akan diandalkan orang saat stres:
Tambahkan regression test yang memvalidasi hal-hal yang tidak boleh rusak: cap waktu, zona waktu, dan pengurutan event. Insiden adalah narasi—jika timeline salah, kepercayaan hilang.
Bug izin adalah risiko operasional dan keamanan. Tulis tes yang membuktikan:
Juga uji “near misses,” seperti pengguna kehilangan akses di tengah insiden atau reorg tim yang mengubah keanggotaan grup.
Sebelum rollout luas, lakukan simulasi tabletop menggunakan aplikasi Anda sebagai sumber kebenaran. Pilih skenario yang dikenal organisasi (mis. partial outage, keterlambatan data, kegagalan pihak ketiga). Amati friction: field yang membingungkan, konteks yang hilang, terlalu banyak klik, kepemilikan yang tidak jelas.
Tangkap umpan balik segera dan ubah menjadi perbaikan kecil dan cepat.
Mulai dengan satu tim pilot dan beberapa template siap pakai (tipe insiden, checklist, format postmortem). Sediakan pelatihan singkat dan panduan satu halaman “bagaimana kita menjalankan insiden” yang terhubung dari aplikasi (mis. /docs/incident-process).
Lacak metrik adopsi dan iterasi pada titik‑titik friksi: waktu untuk membuat, % insiden dengan pembaruan, tingkat penyelesaian postmortem, dan waktu penutupan item tindakan. Perlakukan ini sebagai metrik produk—bukan metrik kepatuhan—dan terus tingkatkan setiap rilis.
Mulailah dengan menulis definisi konkret yang disepakati organisasi Anda:
Definisi itu harus langsung memetakan ke status workflow dan field yang wajib sehingga data tetap konsisten tanpa membebani penggunaan.
Perlakukan postmortem sebagai alur kerja, bukan sekadar dokumen:
Jika Anda mengharapkan perubahan nyata, Anda memerlukan pelacakan action item dan pengingat—bukan sekadar menyimpan dokumen.
Set praktis untuk v1 meliputi:
Tunda otomasi tingkat lanjut sampai alur ini berjalan lancar saat situasi stres.
Gunakan beberapa tahapan yang dapat diprediksi dan sesuai praktik tim:
Tentukan “selesai” untuk setiap tahap, lalu tambahkan guardrail:
Ini mencegah insiden terhenti dan meningkatkan kualitas analisis selanjutnya.
Modelkan beberapa peran yang jelas dan kaitkan ke izin:
Buat pemilik/komandan saat ini tak terbantahkan di UI dan izinkan delegasi (reassign, rotate commander).
Jaga model data kecil namun terstruktur:
Gunakan identifier stabil (UUID) plus kunci ramah-manusia (mis. INC-2025-0042). Perlakukan edit sebagai sejarah dengan created_at/created_by dan log audit untuk perubahan.
Pisahkan aliran dan terapkan aturan berbeda:
Implementasikan template/visibility berbeda, dan simpan keduanya dalam record insiden sehingga keputusan dapat direkonstruksi nanti tanpa membocorkan detail sensitif.
Definisikan level keparahan dengan ekspektasi yang jelas (urgensi respons dan cadence komunikasi). Contoh:
Tampilkan aturan ini di UI di mana pun keparahan dipilih sehingga responder tidak perlu membuka dokumen terpisah saat outage.
Perlakukan action item sebagai record terstruktur, bukan teks bebas:
Kemudian sediakan tampilan global (overdue, due soon, berdasarkan pemilik/layanan) dan pengingat/escalation ringan agar tindak lanjut tidak hilang setelah review.
Gunakan idempotency key per provider dan aturan deduplikasi:
provider + alert_id + occurrence_idSelalu izinkan linking manual sebagai fallback ketika API/integrasi gagal.