26 Agu 2025·8 menit
Cara Membangun Produk Berorientasi AI dengan Model di Logika Aplikasi
Panduan praktis membangun produk berorientasi AI di mana model menggerakkan keputusan: arsitektur, prompt, tool, data, evaluasi, keselamatan, dan monitoring.
Apa Arti Membangun Produk Berorientasi AI
Membangun sebuah produk berorientasi AI bukan sekadar “menambahkan chatbot.” Ini berarti model menjadi bagian nyata dan bekerja dari logika aplikasi Anda—sama seperti mesin aturan, indeks pencarian, atau algoritme rekomendasi.
Aplikasi Anda bukan hanya menggunakan AI; ia dirancang mengelilingi fakta bahwa model akan menginterpretasi input, memilih tindakan, dan menghasilkan keluaran terstruktur yang menjadi dasar bagi bagian lain sistem.
Dalam praktik: alih-alih mengkodekan setiap jalur keputusan secara kaku (“jika X maka lakukan Y”), Anda membiarkan model menangani bagian-bagian yang samar—bahasa, niat, ambiguitas, prioritisasi—sementara kode Anda mengurus apa yang harus presisi: izin, pembayaran, penulisan basis data, dan penegakan kebijakan.
Kapan pendekatan AI-first cocok (dan kapan tidak)
AI-first paling cocok ketika masalah memiliki:
- Banyak input yang valid (teks bebas, dokumen berantakan, tujuan pengguna bervariasi)
- Terlalu banyak edge case untuk dipelihara dengan aturan manual
- Nilai pada penilaian, rangkuman, atau sintesis ketimbang determinisme sempurna
Otomasi berbasis aturan biasanya lebih baik ketika kebutuhan stabil dan tepat—perhitungan pajak, logika inventaris, pengecekan kelayakan, atau alur kepatuhan yang harus sama setiap kali.
Tujuan produk umum yang didukung AI-first
Tim umumnya mengadopsi logika yang digerakkan model untuk:
- Meningkatkan kecepatan: draf respons, ekstraksi field, routing permintaan lebih cepat
- Personalisasi pengalaman: menyesuaikan penjelasan, rencana, atau rekomendasi
- Mendukung keputusan: menyoroti tradeoff, menghasilkan opsi, merangkum bukti
Tradeoff yang harus Anda terima (dan rancang)
Model bisa tidak terduga, kadang yakin tetapi salah, dan perilakunya dapat berubah saat prompt, penyedia, atau konteks yang diambil berubah. Mereka juga menambah biaya per permintaan, bisa menambah latensi, dan menimbulkan kekhawatiran keamanan & kepercayaan (privasi, keluaran berbahaya, pelanggaran kebijakan).
Polanya: anggap model sebagai komponen, bukan kotak jawaban ajaib. Perlakukan seperti dependensi dengan spesifikasi, mode kegagalan, tes, dan monitoring—sehingga Anda mendapatkan fleksibilitas tanpa mempertaruhkan produk pada harapan semata.
Pilih Use Case yang Tepat dan Definisikan Keberhasilan
Tidak semua fitur mendapat manfaat dari menempatkan model sebagai pengambil keputusan utama. Use case AI-first terbaik dimulai dengan job-to-be-done yang jelas dan berakhir dengan keluaran terukur yang bisa Anda pantau minggu demi minggu.
Mulai dari tugas, bukan model
Tulis satu kalimat job story: “Ketika ___, saya ingin ___, sehingga saya bisa ___.” Lalu buat outcomenya terukur.
Contoh: “Ketika saya menerima email panjang dari pelanggan, saya ingin saran balasan yang sesuai kebijakan kami, sehingga saya bisa merespons dalam kurang dari 2 menit.” Ini jauh lebih dapat ditindaklanjuti daripada “tambahkan LLM ke email.”
Petakan titik keputusan
Identifikasi momen-momen di mana model akan memilih tindakan. Titik keputusan ini harus eksplisit agar bisa diuji.
Titik keputusan umum meliputi:
- Mengklasifikasikan niat dan merutekan ke alur kerja yang tepat
- Memutuskan apakah harus mengajukan pertanyaan klarifikasi atau melanjutkan
- Memilih tool (pencarian, lookup CRM, drafting, pembuatan tiket)
- Memutuskan kapan harus meningkat ke manusia
Jika Anda tidak bisa menamai keputusan-keputusan ini, Anda belum siap untuk mengirim logika yang digerakkan model.
Tulis kriteria penerimaan untuk perilaku
Perlakukan perilaku model seperti kebutuhan produk lainnya. Definisikan apa itu “bagus” dan “buruk” dengan bahasa sederhana.
Contoh:
- Bagus: menggunakan kebijakan terbaru, mengutip ID pesanan yang benar, mengajukan satu pertanyaan jelas jika info hilang
- Buruk: mengarang diskon, merujuk locale yang tidak didukung, atau menjawab tanpa memeriksa data yang diperlukan
Kriteria ini menjadi dasar untuk set evaluasi Anda nanti.
Identifikasi kendala sejak awal
Daftar kendala yang membentuk pilihan desain Anda:
- Waktu (target latensi respons)
- Anggaran (biaya per tugas)
- Kepatuhan (penanganan PII, kebutuhan audit)
- Locale yang didukung (bahasa, nada, ekspektasi budaya)
Definisikan metrik sukses yang bisa dimonitor
Pilih sedikit metrik yang terkait dengan job:
- Tingkat penyelesaian tugas
- Akurasi (atau kepatuhan kebijakan) pada kasus representatif
- CSAT atau penilaian kualitatif pengguna
- Waktu yang dihemat per tugas (atau waktu-untuk-resolusi)
Jika Anda tidak bisa mengukur keberhasilan, Anda akan berdebat soal perasaan alih-alih memperbaiki produk.
Rancang Alur Pengguna Berbasis AI dan Batas Sistem
Alur AI-first bukan “layar yang memanggil LLM.” Ini perjalanan ujung-ke-ujung di mana model membuat keputusan tertentu, produk mengeksekusinya dengan aman, dan pengguna tetap terorientasi.
Petakan loop ujung-ke-ujung
Mulailah dengan menggambar pipeline sebagai rantai sederhana: input → model → tindakan → keluaran.
- Input: apa yang diberikan pengguna (teks, file, pilihan) ditambah konteks aplikasi (tier akun, workspace, aktivitas terakhir).
- Langkah model: apa yang menjadi tanggung jawab model (klasifikasi, draf, rangkuman, memilih tindakan berikutnya).
- Tindakan: apa yang mungkin dilakukan sistem Anda (pencarian, membuat tugas, memperbarui record, mengirim email).
- Keluaran: apa yang dilihat pengguna (draf, penjelasan, layar konfirmasi, error dengan langkah selanjutnya).
Peta ini memaksa kejelasan tentang di mana ketidakpastian dapat diterima (pembuatan draf) versus di mana tidak (perubahan penagihan).
Gambar batas sistem: model vs kode deterministik
Pisahkan jalur deterministik (cek izin, aturan bisnis, perhitungan, penulisan DB) dari keputusan yang digerakkan model (interpretasi, prioritisasi, generasi bahasa alami).
Aturan berguna: model boleh merekomendasikan, tapi kode harus memverifikasi sebelum sesuatu yang tidak dapat dibatalkan terjadi.
Tentukan tempat model dijalankan
Pilih runtime berdasarkan kendala:
- Server: terbaik untuk data privat, tooling konsisten, log audit.
- Klien: berguna untuk bantuan ringan dan privasi karena pemrosesan lokal, tapi lebih sulit dikontrol.
- Edge: latensi global lebih cepat, tapi ketergantungan terbatas.
- Hibrida: bagi deteksi niat cepat di edge dan kerja berat di server.
Anggarkan latensi, biaya, dan izin data
Tetapkan anggaran per-permintaan untuk latensi dan biaya (termasuk retry dan pemanggilan tool), lalu rancang UX di sekitarnya (streaming, hasil progresif, “lanjutkan di latar belakang”).
Dokumentasikan sumber data dan izin yang dibutuhkan di setiap langkah: apa yang boleh dibaca model, apa yang boleh ditulis, dan apa yang memerlukan konfirmasi eksplisit pengguna. Ini menjadi kontrak bagi engineering dan kepercayaan pengguna.
Pola Arsitektur: Orkestrasi, State, dan Jejak
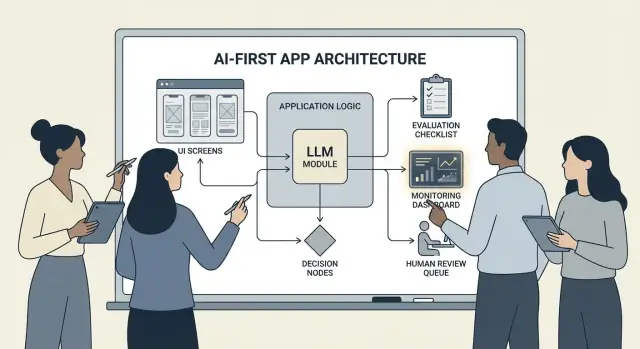
Saat model menjadi bagian logika aplikasi, “arsitektur” bukan hanya server dan API—itu tentang bagaimana Anda menjalankan rangkaian keputusan model secara andal tanpa kehilangan kendali.
Orkestrasi: konduktor kerja model
Orkestrasi adalah lapisan yang mengelola bagaimana suatu tugas AI dieksekusi ujung-ke-ujung: prompt dan template, pemanggilan tool, memori/konteks, retry, timeout, dan fallback.
Orkestrator yang baik menganggap model sebagai satu komponen dalam pipeline. Ia memutuskan prompt mana yang dipakai, kapan memanggil tool (pencarian, DB, email, pembayaran), bagaimana mengompresi atau mengambil konteks, dan apa yang dilakukan jika model mengembalikan sesuatu yang tidak valid.
Jika Anda ingin bergerak lebih cepat dari ide ke orkestrasi yang bekerja, alur kerja vibe-coding dapat membantu Anda prototipe pipeline ini tanpa membangun kerangka aplikasi dari nol. Misalnya, Koder.ai memungkinkan tim membuat web app (React), backend (Go + PostgreSQL), dan bahkan aplikasi mobile (Flutter) via chat—lalu mengiterasi alur seperti “input → model → pemanggilan tool → validasi → UI” dengan fitur seperti planning mode, snapshots, dan rollback, plus export source-code saat Anda siap mengelola repo.
Mesin status untuk tugas multi-langkah
Pengalaman multi-langkah (triase → kumpulkan info → konfirmasi → eksekusi → ringkasan) paling baik dimodelkan sebagai workflow atau mesin status.
Pola sederhana: setiap langkah memiliki (1) input yang diizinkan, (2) output yang diharapkan, dan (3) transisi. Ini mencegah percakapan yang melantur dan menjadikan edge case eksplisit—misalnya apa yang terjadi jika pengguna berubah pikiran atau memberikan info parsial.
Penalaran satu-kali vs multi-turn
Single-shot cocok untuk tugas terbungkus: mengklasifikasikan pesan, membuat balasan singkat, mengekstrak field dari dokumen. Lebih murah, lebih cepat, dan lebih mudah divalidasi.
Multi-turn reasoning cocok saat model harus menanyakan pertanyaan klarifikasi atau saat tool diperlukan secara iteratif (mis., rencana → cari → perbaiki → konfirmasi). Gunakan dengan sengaja, dan batasi loop dengan batas waktu/langkah.
Idempoten: hindari efek samping berulang
Model melakukan retry. Jaringan gagal. Pengguna mengklik dua kali. Jika langkah AI dapat memicu efek samping—mengirim email, memesan, mengenakan biaya—buatlah idempoten.
Taktik umum: lampirkan idempotency key pada setiap aksi “eksekusi”, simpan hasil aksi, dan pastikan retry mengembalikan hasil yang sama alih-alih mengulanginya.
Jejak: buat setiap langkah dapat didebug
Tambahkan keterlacakan sehingga Anda bisa menjawab: Apa yang dilihat model? Apa yang diputuskan? Tool apa yang dijalankan?
Log jejak terstruktur per run: versi prompt, input, ID konteks yang diambil, permintaan/respon tool, error validasi, retry, dan keluaran akhir. Ini mengubah “AI melakukan sesuatu yang aneh” menjadi timeline yang dapat diaudit dan diperbaiki.
Prompting sebagai Logika Produk: Kontrak dan Format yang Jelas
Saat model menjadi bagian logika aplikasi Anda, prompt berhenti menjadi “teks copy” dan menjadi spesifikasi eksekusi. Perlakukan seperti kebutuhan produk: cakupan eksplisit, keluaran yang dapat diprediksi, dan kontrol perubahan.
Mulai dengan system prompt yang mendefinisikan kontrak
System prompt harus menentukan peran model, apa yang boleh dan tidak boleh dilakukan, dan aturan keselamatan yang penting bagi produk Anda. Pertahankan stabil dan dapat dipakai ulang.
Sertakan:
- Peran dan tujuan: siapa ia (mis., “asisten triase support”) dan seperti apa suksesnya.
- Batas cakupan: permintaan yang harus ditolak atau dinaikkan ke manusia.
- Aturan keselamatan: penanganan PII, disclaimer medis/keuangan, jangan menebak.
- Kebijakan tool: kapan memanggil tool vs menjawab langsung.
Strukturkan prompt dengan input/output yang jelas
Tulis prompt seperti definisi API: daftar input yang Anda sediakan (teks pengguna, tier akun, locale, potongan kebijakan) dan keluaran tepat yang Anda harapkan. Tambahkan 1–3 contoh yang mencerminkan trafik nyata, termasuk edge case yang rumit.
Pola berguna: Konteks → Tugas → Kendala → Format keluaran → Contoh.
Gunakan format terbatas untuk hasil yang dapat dibaca mesin
Jika kode perlu bertindak atas keluaran, jangan mengandalkan prosa. Minta JSON yang cocok dengan skema dan tolak yang lain.
{
"type": "object",
"properties": {
"intent": {"type": "string"},
"confidence": {"type": "number", "minimum": 0, "maximum": 1},
"actions": {
"type": "array",
"items": {"type": "string"}
},
"user_message": {"type": "string"}
},
"required": ["intent", "confidence", "actions", "user_message"],
"additionalProperties": false
}
Versi prompt dan rollout yang aman
Simpan prompt di version control, tag release, dan lakukan rollout seperti fitur: staged deployment, A/B bila sesuai, dan rollback cepat. Log versi prompt dengan setiap respons untuk debugging.
Bangun suite tes prompt
Buat kumpulan kecil kasus representatif (happy path, permintaan ambigu, pelanggaran kebijakan, input panjang, locale berbeda). Jalankan otomatis setiap perubahan prompt, dan gagalkan build saat keluaran melanggar kontrak.
Pemanggilan Tool: Biarkan Model Memutuskan, Biarkan Kode Menjalankan
Bawa ke seluler
Tambahkan aplikasi mobile Flutter ke produk berbasis AI Anda menggunakan alur chat yang sama.
Pemanggilan tool adalah cara paling bersih untuk membagi tanggung jawab: model memutuskan apa yang perlu terjadi dan kemampuan mana yang dipakai, sementara kode aplikasi Anda melakukan aksi dan mengembalikan hasil yang tervalidasi.
Ini menjaga fakta, perhitungan, dan efek samping (membuat tiket, memperbarui record, mengirim email) berada dalam kode deterministik yang dapat diaudit—daripada mempercayai teks bebas.
Rancang set tool yang kecil dan disengaja
Mulai dengan beberapa tool yang mencakup 80% permintaan dan mudah diamankan:
- Search (dokumen/help center) untuk menjawab pertanyaan produk
- DB lookup (read-only dulu) untuk status pengguna/akun/pesanan
- Calculator untuk harga, total, konversi, dan matematika berbasis aturan
- Ticketing untuk membuka permintaan support saat pengguna butuh tindak lanjut manusia
Jaga supaya tiap tool memiliki tujuan sempit. Tool yang melakukan “apa saja” jadi sulit dites dan mudah disalahgunakan.
Validasi input, sanitasi output
Perlakukan model seperti pemanggil yang tidak tepercaya.
- Validasi input tool dengan skema ketat (tipe, rentang, enum). Tolak atau perbaiki argumen yang tidak aman (mis., ID hilang, query terlalu luas).
- Sanitasi output tool sebelum memberikannya kembali ke model: hapus rahasia, normalisasi format, dan kembalikan hanya field yang diperlukan.
Ini mengurangi risiko prompt-injection via teks yang diambil dan membatasi kebocoran data tak sengaja.
Tambahkan izin dan rate limit per tool
Setiap tool harus menegakkan:
- Pemeriksaan izin (siapa bisa mengakses record mana, tindakan apa yang boleh dilakukan)
- Rate limit (per pengguna/sesi/tool) untuk mengurangi penyalahgunaan dan loop tak terkendali
Jika tool dapat mengubah state (ticketing, refund), minta otorisasi lebih kuat dan tulis log audit.
Selalu sediakan jalur “tanpa tool”
Kadang tindakan terbaik adalah tidak bertindak: menjawab dari konteks yang ada, mengajukan pertanyaan klarifikasi, atau menjelaskan keterbatasan.
Jadikan “tanpa tool” hasil kelas utama sehingga model tidak memanggil tool hanya demi terlihat sibuk.
Data dan RAG: Biar Model Berlandaskan Realitas Anda
Jika jawaban produk Anda harus cocok dengan kebijakan, inventaris, kontrak, atau pengetahuan internal, Anda perlu membuat model ter-grounding ke data Anda—bukan hanya pelatihan umum.
RAG vs fine-tuning vs konteks sederhana
- Konteks sederhana (tempel beberapa paragraf ke prompt) bekerja bila pengetahuan kecil, stabil, dan Anda mampu mengirimkannya setiap kali (mis., tabel harga singkat).
- RAG (Retrieval-Augmented Generation) terbaik saat informasi besar, sering berubah, atau perlu sitasi (mis., artikel help-center, dokumen produk, data akun-spesifik).
- Fine-tuning terbaik saat Anda ingin gaya/format yang konsisten atau pola domain-spesifik—bukan sebagai cara utama menyimpan fakta. Gunakan untuk memperbaiki cara model menulis dan mengikuti aturan Anda; padukan dengan RAG untuk kebenaran terkini.
Dasar-dasar ingest: chunking, metadata, freshness
Kualitas RAG sebatas masalah ingest.
Pecah dokumen menjadi potongan berukuran sesuai model (sering beberapa ratus token), idealnya selaras batas alami (judul, entri FAQ). Simpan metadata seperti: judul dokumen, heading bagian, produk/versi, audiens, locale, dan izin.
Rencanakan ketepatan waktu: jadwalkan re-indexing, lacak “last updated”, dan kedaluwarsa chunk lama. Chunk usang yang mendapat peringkat tinggi akan menurunkan fitur secara diam-diam.
Sitasi dan jawaban yang terkalibrasi
Minta model mengutip sumber dengan mengembalikan: (1) jawaban, (2) daftar ID snippet/URL, dan (3) pernyataan kepercayaan.
Jika retrieval tipis, arahkan model untuk menyatakan apa yang tidak dapat dikonfirmasi dan menawarkan langkah selanjutnya (“Saya tidak menemukan kebijakan itu; ini kontak yang relevan”). Hindari membiarkannya mengisi kekosongan.
Data privat: kontrol akses dan redaksi
Terapkan akses sebelum retrieval (filter menurut izin pengguna/organisasi) dan lagi sebelum generasi (redaksi field sensitif).
Perlakukan embeddings dan indeks sebagai store data sensitif dengan log audit.
Saat retrieval gagal: fallback yang anggun
Jika hasil teratas tidak relevan atau kosong, fallback ke: mengajukan pertanyaan klarifikasi, merutekan ke support manusia, atau beralih ke mode respons non-RAG yang menjelaskan keterbatasan alih-alih menebak.
Reliabilitas: Guardrail, Validasi, dan Caching
Saat model menjadi bagian logika aplikasi Anda, “cukup baik kebanyakan waktu” tidaklah cukup. Reliabilitas berarti pengguna melihat perilaku konsisten, sistem Anda dapat mengonsumsi keluaran dengan aman, dan kegagalan menurun secara anggun.
Definisikan tujuan reliabilitas (sebelum menambahkan perbaikan)
Tuliskan apa arti “reliable” untuk fitur:
- Keluaran konsisten: input serupa harus menghasilkan jawaban yang sebanding (nada, tingkat detail, kendala)
- Format stabil: respons harus dapat diparse setiap waktu (JSON, daftar, field tertentu)
- Perilaku terbatas: batas jelas apa yang boleh dilakukan model (jangan menebak, kutip sumber, tanyakan saat tidak pasti)
Tujuan ini menjadi kriteria penerimaan untuk prompt dan kode.
Guardrail: validasi, filter, dan penegakan kebijakan
Perlakukan keluaran model sebagai input yang tidak tepercaya.
- Validasi skema: mensyaratkan format ketat (mis., JSON dengan key wajib) dan tolak yang tidak parse.
- Filter konten: jalankan pemeriksaan profanity, detektor PII, atau validator kebijakan pada input pengguna dan keluaran model.
- Aturan bisnis: terapkan batasan di kode (rentang harga, aturan kelayakan, tindakan yang diizinkan), walau prompt menyebutkannya.
Jika validasi gagal, kembalikan fallback aman (tanya klarifikasi, beralih ke template sederhana, atau rute ke manusia).
Retry yang benar-benar membantu
Hindari pengulangan buta. Retry dengan prompt yang diubah untuk menangani mode kegagalan:
- “Return valid JSON only. No markdown.”
- “If unsure, set
confidenceto low and ask one question.”
Batasi retry dan log alasan tiap kegagalan.
Post-processing deterministik
Gunakan kode untuk menormalkan apa yang dihasilkan model:
- kanonisasikan satuan, tanggal, dan nama
- hapus duplikasi item
- terapkan aturan peringkat atau ambang
Ini mengurangi varians dan membuat keluaran lebih mudah dites.
Caching tanpa masalah privasi
Cache hasil yang dapat diulang (mis., query identik, embedding bersama, respon tool) untuk mengurangi biaya dan latensi.
Preferensi:
- TTL pendek untuk data spesifik pengguna
- kunci cache yang mengecualikan PII mentah (atau hash dengan hati-hati)
- flag “do not cache” untuk alur sensitif
Jika dilakukan dengan benar, caching meningkatkan konsistensi sambil mempertahankan kepercayaan pengguna.
Keamanan dan Kepercayaan: Kurangi Risiko Tanpa Membunuh UX
Pertahankan kontrol penuh atas kode
Miliki repo Anda saat siap dengan mengekspor kode sumber dari Koder.ai.
Keamanan bukan lapisan kepatuhan terpisah yang Anda tempelkan di akhir. Dalam produk AI-first, model dapat mempengaruhi tindakan, redaksi, dan keputusan—jadi keselamatan harus menjadi bagian dari kontrak produk: apa yang asisten diizinkan lakukan, apa yang harus ditolak, dan kapan harus meminta bantuan.
Kekhawatiran keselamatan utama untuk dirancang
Namai risiko yang sebenarnya dihadapi aplikasi Anda, lalu petakan tiap risiko ke kontrol:
- Data sensitif: pengenal pribadi, kredensial, dokumen privat, dan apa pun yang diatur
- Panduan berbahaya: instruksi yang bisa memungkinkan self-harm, kekerasan, aktivitas ilegal, atau tindakan medis/keuangan yang tidak aman
- Bias dan hasil yang tidak adil: kualitas layanan yang tidak konsisten, rekomendasi, atau keputusan yang berbeda di antara kelompok
Topik yang diizinkan/diblokir + jalur eskalasi
Tulis kebijakan eksplisit yang bisa ditegakkan produk Anda. Buat konkret: kategori, contoh, dan respons yang diharapkan.
Gunakan tiga tingkat:
- Diizinkan: jawab normal.
- Terbatas: jawab dengan batasan (mis., informasi umum saja, tanpa langkah demi langkah).
- Diblokir: tolak dan rute ke jalur eskalasi (support, sumber daya, atau agen manusia).
Eskalasi harus berupa alur produk, bukan sekadar pesan penolakan. Sediakan opsi “Bicara dengan orang” dan pastikan handoff menyertakan konteks yang sudah dibagikan pengguna (dengan izin).
Tinjauan manusia untuk aksi berdampak besar
Jika model bisa memicu konsekuensi nyata—pembayaran, refund, perubahan akun, pembatalan, penghapusan data—tambahkan checkpoint.
Pola bagus: layar konfirmasi, “draf lalu setujui,” batasan jumlah, dan antrean tinjauan manusia untuk edge case.
Pengungkapan, persetujuan, dan kebijakan yang dapat dites
Beritahu pengguna saat mereka berinteraksi dengan AI, data apa yang digunakan, dan apa yang disimpan. Minta persetujuan bila perlu, terutama untuk menyimpan percakapan atau menggunakan data untuk meningkatkan sistem.
Perlakukan kebijakan keselamatan internal seperti kode: versioning, dokumentasikan alasan, dan tambahkan tes (prompt contoh + keluaran yang diharapkan) agar keselamatan tidak mundur setiap kali prompt atau model diperbarui.
Evaluasi: Uji Model Seperti Komponen Kritis Lainnya
Jika LLM bisa mengubah apa yang produk Anda lakukan, Anda butuh cara berulang untuk membuktikan ia masih bekerja—sebelum pengguna menemukan regresi.
Perlakukan prompt, versi model, skema tool, dan pengaturan retrieval sebagai artefak rilis yang memerlukan pengujian.
Bangun set evaluasi dari data nyata
Kumpulkan niat pengguna nyata dari tiket support, query pencarian, log chat (dengan persetujuan), dan panggilan sales. Ubah menjadi test case yang mencakup:
- Permintaan umum jalur bahagia
- Prompt ambigu yang butuh pertanyaan klarifikasi
- Edge case (data hilang, konflik kendala, format tak biasa)
- Skenario sensitif kebijakan (data pribadi, konten terlarang)
Setiap kasus harus menyertakan perilaku yang diharapkan: jawaban, keputusan yang diambil (mis., “panggil tool A”), dan struktur yang dibutuhkan (field JSON hadir, sitasi disertakan, dll.).
Pilih metrik yang cocok dengan risiko produk
Satu skor tidak akan menangkap kualitas. Gunakan sekumpulan metrik kecil yang memetakan hasil pengguna:
- Akurasi / keberhasilan tugas: apakah menyelesaikan tujuan pengguna?
- Groundedness: apakah klaim didukung konteks atau sumber?
- Validitas format: apakah keluaran sesuai kontrak (JSON, tabel, bullet)?
- Tingkat penolakan: apakah menolak saat seharusnya—dan menghindari menolak saat tidak perlu?
Pantau biaya dan latensi bersamaan kualitas; model “lebih baik” yang menggandakan waktu respons bisa merusak konversi.
Jalankan evaluasi offline untuk setiap perubahan
Jalankan evaluasi offline sebelum rilis dan setelah setiap perubahan prompt, model, tool, atau retrieval. Simpan hasil terversioning agar Anda bisa membandingkan run dan cepat menemukan apa yang rusak.
Tambah tes online dengan guardrail
Gunakan A/B online untuk mengukur hasil nyata (tingkat penyelesaian, edit, rating pengguna), tetapi tambahkan batas keselamatan: definisikan kondisi berhenti (mis., lonjakan keluaran tidak valid, penolakan, atau error tool) dan rollback otomatis ketika ambang terlampaui.
Monitoring Produksi: Drift, Kegagalan, dan Umpan Balik
Buat pipeline orkestrasi
Ubah rangkaian input→model→pemanggilan alat jadi alur aplikasi nyata yang bisa diuji end-to-end.
Mengirim fitur AI-first bukanlah garis finis. Saat pengguna datang, model akan menghadapi frasa baru, edge case, dan data yang berubah. Monitoring mengubah “bekerja di staging” menjadi “tetap bekerja bulan depan.”
Log yang penting (tanpa mengumpulkan rahasia)
Tangkap konteks cukup untuk mereproduksi kegagalan: niat pengguna, versi prompt, pemanggilan tool, dan keluaran akhir model.
Log input/output dengan redaksi aman privasi. Perlakukan log sebagai data sensitif: hapus email, nomor telepon, token, dan teks bebas yang mungkin mengandung detail pribadi. Simpan “debug mode” yang bisa diaktifkan sementara untuk sesi tertentu alih-alih logging maksimal default.
Awasi sinyal yang tepat
Pantau tingkat error, kegagalan tool, pelanggaran skema, dan drift. Secara konkret, lacak:
- Tingkat sukses pemanggilan tool dan timeout (apakah model memilih tool yang tepat, dan apakah ia tereksekusi?)
- Kepatuhan format/skema keluaran (apakah validator menolaknya?)
- Penggunaan fallback (seberapa sering harus merutekan ke jalur lebih aman atau sederhana)
- Pemblokiran keamanan konten (seberapa sering Anda menolak atau mensanitasi)
Untuk drift, bandingkan trafik saat ini ke baseline: perubahan campuran topik, bahasa, panjang prompt rata-rata, dan niat “tidak dikenal”. Drift tidak selalu buruk—tapi selalu isyarat untuk evaluasi ulang.
Alert, runbook, dan respons insiden
Tetapkan ambang alert dan runbook on-call. Alert harus dipetakan ke tindakan: rollback versi prompt, nonaktifkan tool bermasalah, perketat validasi, atau beralih ke fallback.
Rencanakan respons insiden untuk perilaku tak aman atau salah. Definisikan siapa yang dapat mengaktifkan switch keselamatan, bagaimana memberi tahu pengguna, dan bagaimana mendokumentasikan serta belajar dari kejadian.
Tutup loop dengan umpan balik pengguna
Gunakan loop umpan balik: jempol atas/bawah, kode alasan, laporan bug. Minta opsi “mengapa?” ringkas (fakta salah, tidak mengikuti instruksi, berbahaya, terlalu lambat) sehingga Anda bisa merutekan isu ke perbaikan yang tepat—prompt, tool, data, atau kebijakan.
UX untuk Logika yang Digunakan Model: Transparansi dan Kontrol
Fitur yang digerakkan model terasa ajaib saat bekerja—dan rapuh saat tidak. UX harus mengasumsikan ketidakpastian dan tetap membantu pengguna menyelesaikan tugas.
Tunjukkan “mengapa” tanpa membebani orang
Pengguna lebih mempercayai keluaran AI saat mereka bisa melihat asalnya—bukan karena mereka ingin kuliah, tapi karena itu membantu memutuskan apakah akan bertindak.
Gunakan disclosure bertahap:
- Mulai dengan hasil (jawaban, draf, rekomendasi).
- Tawarkan toggle “Mengapa?” atau “Tunjukkan kerja” yang menampilkan input kunci: permintaan pengguna, tool yang dipakai, dan sumber atau record yang dikonsultasikan.
- Jika Anda menggunakan retrieval, tampilkan sitasi yang melompat ke cuplikan tepat (mis., “Berdasarkan: Kebijakan §3.2”). Buat agar mudah dipindai.
Jika ada penjelasan yang lebih mendalam, tautkan secara internal (mis., /blog/rag-grounding) daripada menjejalkan UI dengan detail.
Rancang untuk ketidakpastian (tanpa peringatan menakutkan)
Model bukan kalkulator. Antarmuka harus mengomunikasikan kepercayaan dan mengundang verifikasi.
Pola praktis:
- Petunjuk kepercayaan dalam bahasa biasa (“Kemungkinan benar”, “Perlu ditinjau”) daripada presisi palsu.
- Opsi, bukan jawaban tunggal: “Berikut 3 cara merespons.” Ini mengurangi biaya salah tebakan pertama.
- Konfirmasi untuk aksi berdampak besar (mengirim email, menghapus data, memesan pembayaran). Tanyakan satu pertanyaan jelas: “Kirim pesan ini ke 12 penerima?”
Buat koreksi dan pemulihan mudah
Pengguna harus dapat mengarahkan keluaran tanpa memulai dari awal:
- Edit inline dengan “Terapkan perubahan” sehingga model melanjutkan dari koreksi pengguna.
- “Regenerate” dengan kontrol (nada, panjang, kendala) daripada blind reroll.
- “Undo” dan riwayat terlihat agar kesalahan bisa dibalik.
Sediakan jalur pelarian
Saat model gagal—atau pengguna ragu—tawarkan alur deterministik atau bantuan manusia.
Contoh: “Beralih ke formulir manual”, “Gunakan template”, atau “Hubungi support” (mis., /support). Ini bukan fallback yang memalukan; ini cara melindungi penyelesaian tugas dan kepercayaan.
Dari Prototipe ke Produksi (Tanpa Membangun Ulang Segalanya)
Sebagian besar tim gagal bukan karena LLM tidak mampu; mereka gagal karena jalan dari prototipe ke fitur yang andal, dapat dites, dan dimonitor lebih panjang dari perkiraan.
Cara praktis mempersingkat jalur itu adalah menstandarkan “kerangka produk” sejak awal: mesin status, skema tool, validasi, jejak, dan cerita deploy/rollback. Platform seperti Koder.ai berguna bila Anda ingin cepat membangun alur kerja AI-first—membangun UI, backend, dan database bersama—lalu mengiterasi dengan snapshot/rollback, domain kustom, dan hosting. Saat siap mengoperasionalkan, Anda bisa mengekspor source code dan melanjutkan dengan CI/CD serta stack observability pilihan Anda.