18 Okt 2025·8 menit
Cara Membangun Web App untuk Impor, Ekspor & Validasi Data
Pelajari cara merancang web app yang mengimpor/mengekspor CSV/Excel/JSON, memvalidasi data dengan pesan error jelas, mendukung peran, audit log, dan pemrosesan andal.
Pelajari cara merancang web app yang mengimpor/mengekspor CSV/Excel/JSON, memvalidasi data dengan pesan error jelas, mendukung peran, audit log, dan pemrosesan andal.
Sebelum Anda merancang layar atau memilih parser file, tentukan secara spesifik siapa yang memindahkan data masuk/keluar produk Anda dan mengapa. Aplikasi web impor data yang dibuat untuk operator internal akan terlihat sangat berbeda dari alat impor Excel self-serve yang digunakan pelanggan.
Mulai dengan mendaftarkan peran yang akan menyentuh impor/ekspor:
Untuk setiap peran, definisikan tingkat keahlian yang diharapkan dan toleransi terhadap kompleksitas. Pelanggan biasanya butuh lebih sedikit opsi dan penjelasan in-product yang jauh lebih baik.
Tuliskan skenario utama Anda dan prioritaskan. Yang umum meliputi:
Lalu definisikan metrik sukses yang bisa Anda ukur. Contoh: lebih sedikit impor gagal, waktu penyelesaian error lebih cepat, dan lebih sedikit tiket dukungan tentang “file saya tidak bisa diunggah.” Metrik ini membantu membuat tradeoff nanti (mis. investasi di pelaporan error yang lebih jelas vs. lebih banyak format file).
Jelaskan secara eksplisit apa yang akan Anda dukung pada hari pertama:
Akhirnya, identifikasi kebutuhan kepatuhan sejak awal: apakah file mengandung PII, aturan retensi (berapa lama menyimpan upload), dan kebutuhan audit (siapa mengimpor apa, kapan, dan apa yang berubah). Keputusan ini memengaruhi penyimpanan, logging, dan izin di seluruh sistem.
Sebelum memikirkan UI pemetaan kolom yang keren atau aturan validasi CSV, pilih arsitektur yang tim Anda bisa kirim dan operasikan dengan percaya diri. Impor dan ekspor adalah infrastruktur “membosankan”—kecepatan iterasi dan kemudahan debugging lebih penting daripada novelty.
Stack web mainstream apa pun bisa menjalankan aplikasi impor data. Pilih berdasarkan keterampilan yang ada dan realitas perekrutan:
Kuncinya konsistensi: stack harus memudahkan penambahan tipe impor baru, aturan validasi baru, dan format ekspor baru tanpa perlu rewrite.
Jika ingin mempercepat scaffolding tanpa terikat pada prototype sekali pakai, platform vibe-coding seperti Koder.ai bisa membantu: Anda dapat mendeskripsikan alur impor (upload → preview → mapping → validation → background processing → history) lewat chat, menghasilkan UI React dengan backend Go + PostgreSQL, dan iterasi cepat menggunakan planning mode serta snapshot/rollback.
Gunakan relational database (Postgres/MySQL) untuk record terstruktur, upsert, dan audit log perubahan data.
Simpan unggahan asli (CSV/Excel) di object storage (S3/GCS/Azure Blob). Menyimpan file mentah sangat berharga untuk dukungan: Anda bisa mereproduksi isu parsing, menjalankan ulang job, dan menjelaskan keputusan penanganan error.
File kecil bisa dijalankan sinkron (upload → validate → apply) untuk UX yang responsif. Untuk file besar, pindahkan pekerjaan ke background jobs:
Ini juga memudahkan retry dan penulisan yang dibatasi laju.
Jika Anda membangun SaaS, putuskan lebih awal bagaimana memisahkan data tenant (scoping baris, schema terpisah, atau database terpisah). Pilihan ini memengaruhi API ekspor data, izin, dan performa.
Tuliskan target untuk uptime, ukuran file maksimal, ekspektasi baris per impor, waktu penyelesaian, dan batas biaya. Angka-angka ini mengarahkan pilihan antrean job, strategi batching, dan indexing—sebelum Anda memoles UI.
Alur intake menentukan nada untuk setiap impor. Jika terasa dapat diprediksi dan memaafkan kesalahan, pengguna akan mencoba lagi saat ada masalah—dan tiket dukungan berkurang.
Tawarkan drag-and-drop plus file picker klasik untuk UI web. Drag-and-drop lebih cepat untuk power user, sedangkan file picker lebih mudah diakses dan familiar.
Jika pelanggan mengimpor dari sistem lain, tambahkan endpoint API juga. Bisa menerima multipart upload (file + metadata) atau alur pre-signed URL untuk file besar.
Saat upload, lakukan parsing ringan untuk membuat “preview” tanpa commit data:
Preview ini menjadi dasar langkah selanjutnya seperti pemetaan kolom dan validasi.
Selalu simpan file asli secara aman (object storage tipikal). Jaga agar tetap immutable sehingga Anda bisa:
Perlakukan setiap unggahan sebagai record kelas-satu. Simpan metadata seperti pengunggah, timestamp, sistem sumber, nama file, dan checksum (untuk mendeteksi duplikat dan memastikan integritas). Ini sangat berguna untuk auditabilitas dan debugging.
Jalankan pre-check cepat segera dan gagalkan lebih awal bila perlu:
Jika pre-check gagal, kembalikan pesan yang jelas dan tunjukkan apa yang harus diperbaiki. Tujuannya memblokir file yang benar-benar buruk dengan cepat—tanpa memblokir data valid namun imperfect yang bisa dimapping dan dibersihkan di langkah selanjutnya.
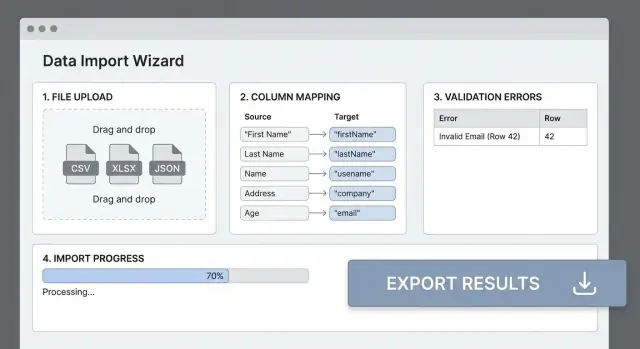
Sebagian besar kegagalan impor terjadi karena header file tidak cocok dengan field aplikasi Anda. Langkah pemetaan kolom yang jelas mengubah “CSV berantakan” menjadi input yang terprediksi dan menghemat pengguna dari coba-coba.
Tampilkan tabel sederhana: Source column → Destination field. Deteksi otomatis kecocokan yang mungkin (pencocokan case-insensitive, sinonim seperti “E-mail” → email), tetapi selalu biarkan pengguna menimpa.
Sertakan beberapa sentuhan agar nyaman:
Jika pelanggan mengimpor format yang sama setiap minggu, buat jadi satu klik. Biarkan mereka menyimpan template yang scoped ke:
Saat file baru diunggah, sarankan template berdasarkan overlap kolom. Juga dukung versioning sehingga pengguna bisa memperbarui template tanpa merusak run lama.
Tambahkan transformasi ringan yang bisa diterapkan per field yang dipetakan:
Jaga agar transformasi eksplisit di UI (“Applied: Trim → Parse Date”) sehingga output mudah dijelaskan.
Sebelum memproses seluruh file, tampilkan preview hasil pemetaan untuk (mis.) 20 baris. Tampilkan nilai asli, nilai setelah transformasi, dan peringatan (seperti “Could not parse date”). Di sinilah pengguna menangkap masalah lebih awal.
Minta pengguna memilih key field (email, external_id, SKU) dan jelaskan apa yang terjadi pada duplikat. Bahkan jika Anda menangani upserts nanti, langkah ini mengatur ekspektasi: Anda bisa memperingatkan tentang kunci duplikat dalam file dan menyarankan record mana yang “menang” (first, last, atau error).
Validasi adalah pembeda antara “file uploader” dan fitur impor yang bisa dipercaya. Tujuannya bukan ketat demi ketat—melainkan mencegah penyebaran data buruk sambil memberikan umpan balik yang jelas dan dapat ditindaklanjuti kepada pengguna.
Perlakukan validasi sebagai tiga cek terpisah, masing-masing dengan tujuan berbeda:
email string?”, “Apakah amount angka?”, “Apakah customer_id ada?” Ini cepat dan dapat dijalankan segera setelah parsing.country=US, state wajib”, “end_date harus setelah start_date”, “Nama plan harus ada di workspace ini.” Ini sering membutuhkan konteks (kolom lain atau lookup DB).Memisahkan lapisan-lapisan ini membuat sistem lebih mudah diperluas dan lebih mudah dijelaskan di UI.
Putuskan lebih awal apakah impor harus:
Anda juga bisa mendukung keduanya: strict sebagai default, dengan opsi “Allow partial import” untuk admin.
Setiap error harus menjawab: apa yang terjadi, di mana, dan bagaimana memperbaikinya.
Contoh: “Baris 42, Kolom ‘Start Date’: harus berupa tanggal valid dalam format YYYY-MM-DD.”
Bedakan:
Pengguna jarang memperbaiki semuanya dalam satu kali. Permudah re-upload dengan menjaga hasil validasi terkait dengan satu percobaan impor dan mengizinkan pengguna untuk mengunggah ulang file yang sudah dikoreksi. Pasangkan ini dengan laporan error yang dapat diunduh sehingga mereka bisa menyelesaikan isu secara massal.
Pendekatan praktis adalah hybrid:
Ini menjaga validasi tetap fleksibel tanpa berubah menjadi “settings maze” yang sulit di-debug.
Impor cenderung gagal karena alasan sepele: database lambat, lonjakan file pada jam sibuk, atau satu baris “bermasalah” yang memblokir seluruh batch. Keandalan sebagian besar soal mengeluarkan pekerjaan berat dari jalur request/response dan membuat setiap langkah aman untuk dijalankan ulang.
Jalankan parsing, validasi, dan penulisan dalam background jobs (queue/worker) sehingga upload tidak terkena timeout web. Ini juga memungkinkan Anda menskalakan worker secara terpisah ketika pelanggan mulai mengimpor spreadsheet yang lebih besar.
Pola praktis adalah membagi pekerjaan menjadi chunk (mis. 1.000 baris per job). Satu job “parent” menjadwalkan chunk job, mengagregasi hasil, dan memperbarui progress.
Modelkan impor sebagai state machine sehingga UI dan tim ops selalu tahu apa yang terjadi:
Simpan timestamp dan jumlah percobaan per transisi state sehingga Anda dapat menjawab “kapan mulai?” dan “berapa kali retry?” tanpa mengorek log.
Tampilkan progres yang terukur: baris yang diproses, baris tersisa, dan error yang ditemukan sejauh ini. Jika bisa memperkirakan throughput, tambahkan ETA kasar—lebih baik “~3 min” daripada hitungan mundur presisi.
Retry tidak boleh membuat duplikat atau menerapkan update dua kali. Teknik umum:
import_id plus row_number (atau row hash) sebagai idempotency key stabil.external_id) bukan “insert always.”Batasi laju impor concurrent per workspace dan throttle langkah penulisan yang berat (mis. max N rows/sec) untuk menghindari membebani database dan menurunkan pengalaman pengguna lain.
Jika orang tidak mengerti apa yang salah, mereka akan mengulangi file yang sama sampai menyerah. Perlakukan setiap impor sebagai “run” kelas-satu dengan jejak kertas yang jelas dan error yang dapat ditindaklanjuti.
Mulailah dengan membuat entitas import run pada saat file dikirim. Record ini harus menangkap hal-hal penting:
Ini menjadi layar riwayat impor Anda: daftar run sederhana dengan status, hitungan, dan halaman “view details”.
Log aplikasi bagus untuk engineer, tetapi pengguna butuh error yang dapat di-query. Simpan error sebagai record terstruktur terkait import run, idealnya di kedua level:
Dengan struktur ini Anda bisa menyokong filter cepat dan insight agregat seperti “Top 3 tipe error minggu ini.”
Di halaman detail run, sediakan filter berdasarkan tipe, kolom, dan severity, plus kotak pencarian (mis. “email”). Lalu tawarkan downloadable CSV error report yang menyertakan baris asli plus kolom tambahan seperti error_columns dan error_message, dengan panduan jelas seperti “Perbaiki format tanggal ke YYYY-MM-DD.”
Mode “dry run” memvalidasi semuanya dengan mapping dan aturan yang sama, tetapi tidak menulis data. Ideal untuk impor pertama kali dan memungkinkan pengguna iterasi aman sebelum commit perubahan.
Impor terasa “selesai” setelah baris masuk ke database—tetapi biaya jangka panjang biasanya ada pada update yang berantakan, duplikat, dan riwayat perubahan yang tidak jelas. Bagian ini tentang merancang model data agar impor dapat diprediksi, dapat dibalik, dan dapat dijelaskan.
Mulai dengan mendefinisikan bagaimana baris impor dipetakan ke model domain Anda. Untuk setiap entitas, putuskan apakah impor bisa:
Keputusan ini harus eksplisit di UI pengaturan impor dan disimpan bersama job impor sehingga perilaku bisa diulang.
Jika mendukung “create or update,” Anda butuh upsert key yang stabil—field yang mengidentifikasi record yang sama tiap kali. Pilihan umum:
external_id (terbaik saat datang dari sistem lain)account_id + sku)Definisikan aturan collision: apa yang terjadi jika dua baris berbagi kunci yang sama, atau jika kunci cocok dengan banyak record? Default yang baik adalah “gagal baris dengan error jelas” atau “last row wins,” tetapi pilih secara sengaja.
Gunakan transaksi ketika melindungi konsistensi (mis. membuat parent dan child). Hindari satu transaksi besar untuk file 200k baris; itu bisa mengunci tabel dan membuat retry menyakitkan. Lebih baik penulisan terpotong (mis. 500–2.000 baris per batch) dengan upsert idempotent.
Impor harus menghormati relasi: jika baris mereferensi parent (seperti Company), baik wajib ada atau dibuat dalam langkah terkendali. Gagal lebih awal dengan error “missing parent” mencegah data setengah-terhubung.
Tambahkan audit log untuk perubahan yang dipicu impor: siapa memicu impor, kapan, file sumber, dan ringkasan per-record apa yang berubah (old vs new). Ini memudahkan dukungan, membangun kepercayaan pengguna, dan menyederhanakan rollback.
Ekspor terlihat sederhana sampai pelanggan mencoba men-download “semua” tepat sebelum tenggat waktu. Sistem ekspor yang dapat diskalakan harus menangani dataset besar tanpa memperlambat aplikasi Anda atau menghasilkan file inkonsisten.
Mulai dengan tiga opsi:
Export incremental sangat membantu untuk integrasi dan mengurangi beban dibandingkan dump penuh berulang.
Apa pun yang Anda pilih, pertahankan header konsisten dan urutan kolom yang stabil agar proses downstream tidak rusak.
Ekspor besar tidak boleh memuat semua baris ke memori. Gunakan pagination/streaming untuk menulis baris saat Anda mengambilnya. Ini mencegah timeout dan menjaga responsivitas web app.
Untuk dataset besar, buat ekspor dalam background job dan beri tahu pengguna saat siap. Pola umum:
Ini cocok dengan background jobs untuk impor dan pola “run history + downloadable artifact” yang sama yang Anda gunakan untuk laporan error.
Ekspor sering diaudit. Selalu sertakan:
Detail ini mengurangi kebingungan dan mendukung rekonsiliasi yang andal.
Impor dan ekspor adalah fitur kuat karena dapat memindahkan banyak data dengan cepat. Itu juga membuatnya tempat umum untuk bug keamanan: satu peran terlalu permisif, satu URL file bocor, atau satu baris log yang tidak sengaja menyertakan data pribadi.
Mulailah dengan autentikasi yang sama yang dipakai di seluruh aplikasi—jangan buat jalur auth “khusus” untuk impor.
Jika pengguna bekerja di browser, session-based auth (plus opsi SSO/SAML) biasanya paling cocok. Jika impor/ekspor otomatis (job malam, partner integrasi), pertimbangkan API key atau token OAuth dengan scoping dan rotasi yang jelas.
Aturan praktis: UI impor dan API impor harus menerapkan izin yang sama, meskipun digunakan oleh audiens berbeda.
Perlakukan kemampuan impor/ekspor sebagai privilege eksplisit. Peran umum meliputi:
Jadikan “download files” permission terpisah. Banyak kebocoran sensitif terjadi ketika seseorang bisa melihat import run dan sistem menganggap mereka juga bisa mendownload spreadsheet asli.
Pertimbangkan juga batasan tingkat baris atau tenant-level: pengguna harus hanya mengimpor/mengekspor data untuk account/workspace yang mereka miliki.
Untuk file yang disimpan (unggahan, CSV error yang dihasilkan, arsip ekspor), gunakan object storage privat dan link unduhan berumur singkat. Enkripsi at-rest bila diperlukan oleh kepatuhan Anda, dan konsisten: unggahan asli, staging terproses, dan laporan yang dihasilkan harus mengikuti aturan yang sama.
Hati-hati dengan log. Redaksi field sensitif (email, nomor telepon, ID, alamat) dan jangan pernah mencatat baris mentah secara default. Saat debugging diperlukan, kunci “verbose row logging” di pengaturan admin-only dan pastikan kadaluarsa.
Perlakukan setiap unggahan sebagai input yang tidak dipercaya:
Juga validasi struktur lebih awal: tolak file yang jelas-malformed sebelum mencapai background job, dan berikan pesan yang jelas kepada pengguna tentang apa yang salah.
Catat event yang ingin Anda lihat saat investigasi: siapa yang mengunggah file, siapa memulai impor, siapa mendownload ekspor, perubahan permission, dan percobaan akses yang gagal.
Entri audit harus mencakup actor, timestamp, workspace/tenant, dan objek yang terpengaruh (import run ID, export ID), tanpa menyimpan data baris sensitif. Ini cocok dengan UI riwayat impor dan membantu menjawab “siapa mengubah apa, dan kapan?” dengan cepat.
Jika impor dan ekspor menyentuh data pelanggan, Anda akan menemui edge case: encoding aneh, sel gabungan, baris setengah terisi, duplikat, dan misteri “kemarin berhasil”. Operability menjaga agar masalah tersebut tidak berubah jadi bencana dukungan.
Mulai dengan tes fokus di bagian yang paling rawan gagal: parsing, mapping, dan validasi.
Kemudian tambahkan setidaknya satu end-to-end test untuk alur lengkap: upload → background processing → generation report. Tes ini menangkap mismatch kontrak antara UI, API, dan worker (mis. payload job yang kehilangan konfigurasi mapping).
Lacak sinyal yang mencerminkan dampak pengguna:
Kaitkan alert ke gejala (kenaikan failure, antrean yang tumbuh) bukan setiap exception.
Berikan tim internal permukaan admin kecil untuk menjalankan ulang job, membatalkan impor macet, dan memeriksa kegagalan (metadata file input, mapping yang dipakai, ringkasan error, dan link ke log/trace).
Untuk pengguna, kurangi error yang dapat dicegah dengan tips inline, template sampel yang dapat diunduh, dan langkah selanjutnya yang jelas di layar error. Pertahankan halaman bantuan pusat dan tautkan dari UI impor (mis. /docs).
Mengirim sistem impor/ekspor bukan hanya “push ke produksi.” Perlakukan sebagai fitur produk dengan default aman, jalur pemulihan yang jelas, dan ruang untuk berkembang.
Siapkan dev/staging/prod terpisah dengan database terisolasi dan bucket object storage terpisah (atau prefix) untuk file unggahan dan ekspor yang dihasilkan. Gunakan key enkripsi dan kredensial berbeda per environment, dan pastikan worker background job menunjuk ke queue yang tepat.
Staging harus meniru produksi: concurrency job yang sama, timeout, dan batas ukuran file. Di situlah Anda dapat memvalidasi performa dan izin tanpa mempertaruhkan data pelanggan nyata.
Impor cenderung “hidup selamanya” karena pelanggan menyimpan spreadsheet lama. Gunakan migrasi DB seperti biasa, tetapi juga versioning template impor (dan preset mapping) sehingga perubahan skema tidak merusak CSV kuartal lalu.
Pendekatan praktis: simpan template_version dengan setiap import run dan pertahankan kode kompatibilitas untuk versi lama sampai Anda dapat mendeprekasi mereka.
Gunakan feature flag untuk mengirim perubahan dengan aman:
Flag memungkinkan uji coba dengan pengguna internal atau kohort pelanggan kecil sebelum hidup luas.
Dokumentasikan bagaimana dukungan menyelidiki kegagalan menggunakan riwayat impor, job ID, dan log. Checklist sederhana membantu: konfirmasi versi template, tinjau baris gagal pertama, periksa akses storage, lalu inspeksi log worker. Tautkan ini dari runbook internal dan, bila sesuai, dari UI admin (mis. /admin/imports).
Setelah alur inti stabil, perluas di luar upload:
Peningkatan ini mengurangi pekerjaan manual dan membuat aplikasi impor data Anda terasa native dalam proses pelanggan.
Jika Anda membangun ini sebagai fitur produk dan ingin memperpendek timeline “versi pertama yang bisa dipakai”, pertimbangkan menggunakan Koder.ai untuk mem-prototype import wizard, halaman status job, dan layar riwayat run end-to-end, lalu ekspor source code untuk workflow engineering konvensional. Pendekatan itu praktis saat tujuan Anda adalah keandalan dan kecepatan iterasi (bukan kesempurnaan UI custom pada hari pertama).
Mulailah dengan memperjelas siapa yang melakukan impor/ekspor (admin, operator, pelanggan) dan skenario utama Anda (bulk load saat onboarding, sinkronisasi berkala, ekspor satu kali).
Tulis keterbatasan hari-pertama:
Keputusan ini menentukan arsitektur, kompleksitas UI, dan beban dukungan.
Gunakan pemrosesan sinkron ketika file kecil dan validasi + penulisan bisa selesai dalam batas waktu permintaan web.
Gunakan background jobs ketika:
Pola umum: upload → enqueue → tampilkan status/progress run → beri notifikasi saat selesai.
Simpan keduanya, untuk alasan berbeda:
Pertahankan upload mentah immutabel, dan kaitkan dengan record import run.
Bangun langkah preview yang mendeteksi header dan mengurai sampel kecil (mis. 20–100 baris) sebelum meng-commit apa pun.
Tangani variabilitas umum:
Gagal cepat pada pemblokir nyata (file tidak bisa dibaca, kolom yang diwajibkan hilang), tetapi jangan menolak data yang bisa dimapping atau ditransformasi nanti.
Gunakan tabel pemetaan sederhana: Source column → Destination field.
Praktik terbaik:
Selalu tunjukkan preview hasil pemetaan agar pengguna menangkap kesalahan sebelum memproses seluruh file.
Dukung transformasi ringan dan eksplisit agar pengguna bisa memprediksi hasil:
ACTIVE)Tampilkan “original → transformed” di preview, dan munculkan peringatan bila transformasi gagal diterapkan.
Pisahkan validasi ke beberapa lapisan:
Di UI, sediakan pesan yang dapat ditindaklanjuti dengan referensi baris/kolom (mis. “Baris 42, Start Date: harus YYYY-MM-DD”).
Putuskan apakah impor (gagal seluruh file) atau (terima baris valid), dan pertimbangkan menawarkan keduanya untuk admin.
Buat pemrosesan aman untuk retry:
import_id + row_number atau row hash)external_id) daripada selalu insertBuat record import run segera setelah file diserahkan, dan simpan error terstruktur yang dapat di-query—bukan hanya log.
Fitur pelaporan error yang berguna:
Perlakukan impor/ekspor sebagai tindakan istimewa:
Jika menangani PII, putuskan kebijakan retensi dan penghapusan lebih awal agar tidak menumpuk file sensitif selamanya.
Juga batasi concurrent imports per workspace untuk melindungi DB dan pengguna lain.
error_columns dan error_messageIni mengurangi perilaku “coba lagi sampai berhasil” dan tiket dukungan.