Apa itu Halaman Status SaaS (dan Mengapa Penting)
Halaman status SaaS adalah situs publik (atau hanya untuk pelanggan) yang menunjukkan apakah produk Anda berfungsi sekarang—dan apa yang Anda lakukan jika tidak. Ini menjadi sumber kebenaran tunggal selama insiden, terpisah dari media sosial, tiket support, dan rumor.
Halaman ini membantu lebih banyak orang daripada yang Anda kira:
- Pelanggan bisa cepat memastikan “Apa hanya saya?” dan memutuskan apakah menunggu, mencoba lagi, atau menggunakan solusi sementara.
- Tim support bisa menautkan ke satu pembaruan kanonis daripada mengulang penjelasan di puluhan tiket.
- Tim Sales dan Customer Success bisa proaktif mengelola pembaruan kontrak dan akun penting dengan informasi bertimestamp yang akurat.
Status real-time vs. riwayat insiden vs. postmortem
Situs status yang baik biasanya berisi tiga lapisan terkait (tetapi berbeda):
- Status real-time: apa yang berfungsi, turun, atau mengalami degradasi sekarang di seluruh komponen Anda (API, dashboard, billing, dll.).
- Halaman riwayat insiden: garis waktu insiden dan pemeliharaan sebelumnya, sehingga pelanggan dapat memahami pola dan melihat bahwa masalah ditangani.
- Ulasan pasca-insiden (postmortem): tulisan lebih mendalam yang menjelaskan akar masalah, perbaikan, dan langkah pencegahan. Ini bisa dipublikasikan atau dibagikan secara pribadi kepada pelanggan yang terdampak.
Tujuannya adalah kejelasan: status real-time menjawab “Bisakah saya menggunakan produk?” sementara riwayat menjawab “Seberapa sering ini terjadi?” dan postmortem menjawab “Mengapa ini terjadi, dan apa yang berubah?”
Menetapkan ekspektasi: transparansi, kecepatan, dan kejelasan
Halaman status bekerja ketika pembaruan bersifat cepat, menggunakan bahasa sederhana, dan jujur tentang dampak. Anda tidak perlu diagnosis sempurna untuk berkomunikasi. Anda perlu timestamp, cakupan (siapa yang terdampak), dan waktu pembaruan berikutnya.
Momen umum saat Anda akan menggunakannya
Anda akan mengandalkannya selama gangguan, degradasi kinerja (login lambat, webhook tertunda), dan pemeliharaan terjadwal yang bisa menyebabkan gangguan singkat atau risiko.
Setelah Anda memposisikan halaman status sebagai permukaan produk (bukan halaman ops sekali jadi), sisa pengaturan menjadi jauh lebih mudah: Anda bisa menetapkan pemilik, membuat template, dan menghubungkan monitoring tanpa membuat ulang proses setiap insiden.
Tetapkan Tujuan, Audiens, dan Kepemilikan
Sebelum memilih alat atau desain layout, putuskan apa yang seharusnya dilakukan oleh halaman status Anda. Tujuan yang jelas dan pemilik yang jelas menjaga halaman status tetap berguna selama insiden—ketika semua orang sibuk dan informasi berantakan.
Definisikan tujuan (apa arti “sukses”)
Kebanyakan tim SaaS membuat halaman status untuk tiga hasil praktis:
- Mengurangi tiket support dengan menjawab “Apakah ini turun?” di satu tempat publik
- Membangun kepercayaan dengan membagikan pembaruan tepat waktu dalam bahasa sederhana
- Mempercepat komunikasi antara Support, Engineering, Sales, dan Customer Success
Tulis 2–3 sinyal terukur yang bisa Anda pantau setelah peluncuran: berkurangnya tiket duplikat selama gangguan, waktu-ke-pembaruan-pertama yang lebih cepat, atau lebih banyak pelanggan menggunakan langganan.
Identifikasi audiens dan tingkat bacaan
Pembaca utama Anda biasanya adalah pelanggan non-teknis yang ingin tahu:
- Apakah produk bekerja sekarang?
- Apa yang terdampak (login, API, billing, dll.)?
- Apa yang harus saya lakukan selanjutnya?
- Kapan akan diperbaiki?
Itu berarti minimalkan jargon. Lebih baik tulis “Beberapa pelanggan tidak bisa masuk” daripada “Elevated 5xx rates on auth.” Jika Anda butuh detail teknis, buat sebagai kalimat singkat sekunder.
Pilih nada, aturan, dan kepemilikan
Pilih nada yang bisa Anda pertahankan di bawah tekanan: tenang, faktual, dan transparan. Putuskan di muka:
- Siapa yang bisa memposting pembaruan (satu peran atau rotasi on-call)
- Siapa yang menyetujui pembaruan (jika ada) dan berapa lama persetujuan dapat memakan waktu
- Frekuensi pembaruan minimum selama insiden aktif (misalnya setiap 30 menit)
Jadikan kepemilikan eksplisit: halaman status tidak boleh menjadi “pekerjaan semua orang,” atau akhirnya menjadi pekerjaan tidak seorang pun.
Tentukan tempat publikasinya
Anda punya dua opsi umum:
- Situs terpisah (mis. status.namaanda.com): pemisahan lebih jelas dan sering lebih tahan terhadap outage
- Subpath (mis. /status): branding dan analytics lebih sederhana
Jika aplikasi utama Anda bisa down, situs status terpisah biasanya lebih aman. Anda tetap bisa menautkannya secara menonjol dari aplikasi dan pusat bantuan (mis. /help).
Halaman status berguna sejauh “peta” di baliknya. Sebelum memilih warna atau menulis copy, putuskan apa yang sebenarnya Anda laporkan. Tujuannya adalah merefleksikan bagaimana pelanggan merasakan produk Anda—bukan bagaimana bagan organisasi Anda tersusun.
Mulai dengan inventaris komponen
Daftar bagian yang mungkin disebut pelanggan ketika mereka bilang “ini rusak.” Untuk banyak produk SaaS, set awal praktis meliputi:
- API
- Web app
- Dashboard / admin
- Autentikasi (login, SSO)
- Billing
- Integrations (Slack, Salesforce, webhooks, dll.)
Jika Anda menawarkan beberapa region atau tier, catat itu juga (mis. “API – US” dan “API – EU”). Gunakan nama yang mudah dipahami pelanggan: “Login” lebih jelas daripada “IdP Gateway.”
Tentukan bagaimana mengelompokkan komponen
Pilih pengelompokan yang cocok dengan cara pelanggan memikirkan layanan Anda:
- Per produk: bagus jika Anda punya penawaran yang berbeda (Produk A vs Produk B)
- Per region: bagus jika ketersediaan berbeda menurut geografis
- Per fitur/workflow: bagus jika pelanggan mengandalkan tugas tertentu (Reporting, Imports, Notifications)
Hindari daftar yang tak berujung. Jika Anda punya puluhan integrasi, pertimbangkan satu komponen induk (“Integrations”) plus beberapa anak berdampak tinggi (mis. “Salesforce,” “Webhooks”).
Definisikan level status Anda (dan apa artinya)
Model yang sederhana dan konsisten mencegah kebingungan saat insiden. Level umum meliputi:
- Operational: berfungsi seperti yang diharapkan
- Degraded Performance: lebih lambat dari normal atau kesalahan intermiten
- Partial Outage: subset pengguna/fitur signifikan tidak tersedia
- Major Outage: layanan secara luas tidak tersedia
Tulis kriteria internal untuk tiap level (meskipun tidak dipublikasikan). Misalnya, “Partial Outage = satu region down” atau “Degraded = p95 latency di atas X selama Y menit.” Konsistensi membangun kepercayaan.
Catat dependensi—dan pilih yang akan ditampilkan
Kebanyakan outage melibatkan pihak ketiga: hosting cloud, pengiriman email, prosesor pembayaran, atau penyedia identitas. Dokumentasikan dependensi ini agar pembaruan insiden Anda akurat.
Menampilkan dependensi secara publik tergantung audiens. Jika pelanggan bisa terdampak langsung (mis. pembayaran), menampilkan komponen dependensi bisa membantu. Jika hanya menambah kebisingan atau mengundang permainan menyalahkan, simpan dependensi secara internal namun referensikan dalam pembaruan saat relevan (mis. “Kami sedang menyelidiki elevated errors dari penyedia pembayaran kami”).
Setelah Anda punya model komponen ini, sisa setup halaman status jadi lebih mudah: setiap insiden punya “di mana” (komponen) dan “seberapa parah” (status) yang jelas dari awal.
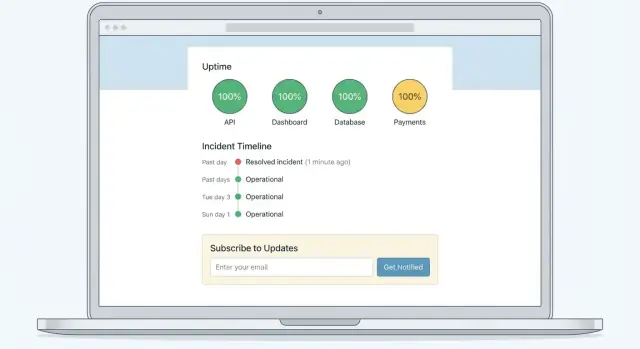
Rancang Halaman Status yang Sederhana dan Ramah Pelanggan
Halaman status paling berguna ketika menjawab pertanyaan pelanggan dalam beberapa detik. Orang biasanya datang dalam kondisi stres dan ingin kejelasan—bukan banyak navigasi.
Mulai dari yang pelanggan butuhkan terlebih dahulu
Prioritaskan yang esensial di bagian paling atas:
- Kondisi saat ini: Apakah semuanya Operational, Degraded, atau Down?
- Dampak: Apa yang terdampak (siapa/region/fitur) dan apa yang pelanggan alami
- ETA (jika ada): Hati-hati—bagikan estimasi waktu hanya jika bisa dipertanggungjawabkan
- Waktu pembaruan berikutnya: Janji spesifik seperti “Pembaruan berikutnya paling lambat 14:30 UTC” mengurangi tiket berulang
Tulis dalam bahasa sederhana. “Elevated error rates on API requests” lebih jelas daripada “Partial outage in upstream dependency.” Jika harus pakai istilah teknis, tambahkan terjemahan singkat (“Beberapa permintaan mungkin gagal atau timeout”).
Gunakan layout yang mudah dipindai
Pola andalan:
- Banner atas untuk status keseluruhan (All Systems Operational / Degraded Performance / Major Outage)
- Daftar komponen dengan status jelas (Web App, API, Billing, Integrations, dll.)
- Insiden aktif dan pemeliharaan terjadwal langsung di bawah, diurutkan berdasarkan pembaruan terbaru
Untuk daftar komponen, gunakan label yang mudah dipahami pelanggan. Jika layanan internal Anda bernama “k8s-cluster-2,” pelanggan lebih perlu melihat “API” atau “Background Jobs.”
Aksesibilitas dan dasar mobile
Buat halaman terbaca saat dalam tekanan:
- Kontras warna yang kuat dan label teks (jangan hanya andalkan warna)
- Ikon yang jelas dengan makna konsisten (mis. hijau = operational, kuning = degraded, merah = outage)
- Spasi dan target tap yang ramah mobile; banyak pengguna akan memeriksa status dari ponsel
Tambahkan tautan cepat di tempat orang mengharapkannya
Letakkan beberapa tautan kecil di dekat bagian atas (header atau tepat di bawah banner):
- Subscribe (untuk notifikasi email/SMS/webhook)
- Incident History (untuk insiden dan garis waktu sebelumnya)
- Contact Support di /support
Tujuannya adalah memberi rasa percaya: pelanggan harus segera mengerti apa yang terjadi, apa yang terdampak, dan kapan mereka akan mendengar kabar berikutnya.
Buat Template Pembaruan Insiden dan Pemeliharaan
Saat insiden terjadi, tim Anda jongkok antara diagnosis, mitigasi, dan pertanyaan pelanggan. Template menghilangkan tebak-tebakan sehingga pembaruan tetap konsisten, jelas, dan cepat—terutama ketika orang berbeda mungkin yang memposting.
Tentukan field insiden yang selalu dipublikasikan
Pembaruan yang baik dimulai dengan fakta inti yang sama setiap kali. Minimal, standarkan field ini agar pelanggan cepat memahami situasinya:
- Waktu mulai insiden (dengan zona waktu)
- Komponen/layanan yang terdampak (sesuai model status Anda)
- Dampak pelanggan (siapa yang terdampak dan bagaimana)
- Status saat ini (Investigating, Identified, Monitoring, Resolved)
- Log pembaruan (entri bertimestamp)
- Waktu penyelesaian (ketika layanan kembali normal)
Jika Anda menerbitkan halaman riwayat insiden, menjaga konsistensi field ini membuat insiden lampau mudah dipindai dan dibandingkan.
Gunakan template pembaruan insiden yang sederhana dan bisa diulang
Targetkan pembaruan singkat yang menjawab pertanyaan yang sama dari pelanggan setiap kali. Berikut template praktis yang bisa Anda salin ke alat halaman status:
Title: Ringkasan singkat dan spesifik (mis. “API errors untuk region EU”)
Start time: YYYY-MM-DD HH:MM (TZ)
Affected components: API, Dashboard, Payments
Impact: Apa yang pengguna lihat (error, timeout, degradasi) dan siapa yang terdampak
What we know: Satu kalimat tentang penyebab jika sudah terkonfirmasi (hindari spekulasi)
What we’re doing: Tindakan konkret (rollback, scaling, eskalasi vendor)
Next update: Waktu Anda akan memposting lagi
Updates:
- HH:MM (TZ) — Investigating: …
- HH:MM (TZ) — Identified: …
- HH:MM (TZ) — Monitoring: …
- HH:MM (TZ) — Resolved: …
Tetapkan aturan frekuensi pembaruan yang jelas
Pelanggan tidak hanya ingin informasi—mereka ingin prediktabilitas.
- Untuk insiden besar, komitmen untuk pembaruan setiap 30–60 menit, bahkan jika pembaruan hanya “Kami masih menyelidiki; belum ada ETA; pembaruan berikutnya jam X.”
- Untuk isu minor, Anda boleh memposting lebih jarang, tapi tetap tetapkan waktu “pembaruan berikutnya.”
- Jika Anda tak bisa memenuhi frekuensi, posting catatan singkat yang mengakui keterlambatan dan mengatur ulang ekspektasi.
Tambahkan template pengumuman pemeliharaan
Pemeliharaan terjadwal harus terasa tenang dan terstruktur. Standarkan posting pemeliharaan dengan:
- Jendela pemeliharaan: waktu mulai/selesai (dengan zona waktu)
- Dampak yang diharapkan: none / degraded / intermittent / downtime
- Komponen terdampak
- Tindakan pelanggan (jika ada): “Tidak perlu tindakan” atau langkah jelas
- Pembaruan pengingat: posting singkat saat pemeliharaan dimulai, dan lagi saat selesai
Jaga bahasa pemeliharaan spesifik (apa yang berubah, apa yang mungkin pelanggan rasakan), dan hindari berjanji berlebihan—pelanggan menghargai akurasi daripada optimisme.
Bangun Riwayat Insiden yang Mudah Dipindai
Halaman riwayat insiden lebih dari sekadar log—itu cara agar pelanggan (dan tim Anda) cepat memahami seberapa sering masalah terjadi, jenis masalah yang berulang, dan bagaimana Anda merespons.
Mengapa riwayat insiden layak usaha
Riwayat yang jelas membangun kepercayaan lewat transparansi. Ia juga menciptakan visibilitas tren: jika Anda melihat insiden “latency API” berulang setiap beberapa minggu, itu sinyal untuk investasi perbaikan kinerja (dan prioritaskan proses post-incident review). Seiring waktu, pelaporan konsisten bisa mengurangi tiket support karena pelanggan dapat mencari jawaban sendiri.
Tentukan retensi: seberapa jauh ke belakang harus disimpan?
Pilih jendela retensi yang cocok dengan ekspektasi pelanggan dan kematangan produk.
- 90 hari: umum untuk SaaS tahap awal, menjaga halaman ringan
- 6–12 bulan: lebih baik untuk pembeli enterprise yang mengevaluasi keandalan
- Lebih lama: pertimbangkan mengekspor catatan lama ke halaman arsip terpisah jika timeline menjadi bising
Apa pun pilihan Anda, nyatakan dengan jelas (mis. “Riwayat insiden disimpan selama 12 bulan”).
Buat setiap entri mudah dipahami dalam sekejap
Konsistensi mempermudah pemindaian. Gunakan format penamaan yang dapat diprediksi seperti:
YYYY-MM-DD — Ringkasan singkat (mis. “2025-10-14 — Pengiriman email tertunda”)
Untuk tiap insiden, tampilkan setidaknya:
- komponen terdampak
- waktu mulai/selesai (dengan zona waktu)
- tingkat dampak (minor/major)
- catatan resolusi singkat
Tautkan konteks lebih dalam bila tersedia
Jika Anda memublikasikan postmortem, tautkan dari halaman detail insiden ke tulisan itu (mis. “Baca postmortem” menautkan ke /blog/postmortems/2025-10-14-email-delays). Ini menjaga timeline tetap bersih sambil tetap menawarkan detail bagi pelanggan yang mau menggali.
Tambahkan Langganan dan Notifikasi
Halaman status berguna saat pelanggan terpikir untuk memeriksanya. Langganan membalik skenario: pelanggan menerima pembaruan otomatis, tanpa merefresh halaman atau mengirim email ke support untuk konfirmasi.
Tawarkan channel yang pelanggan sudah gunakan
Kebanyakan tim menyediakan setidaknya beberapa opsi:
- Email (default untuk banyak pelanggan)
- SMS (terbaik untuk peringatan mendesak dengan sinyal tinggi)
- Slack atau Microsoft Teams (ideal untuk pelanggan bisnis dan tim ops)
- RSS/Atom (masih populer di kalangan pengguna teknis dan untuk tooling internal)
Jika mendukung banyak channel, jaga alur pengaturan konsisten agar pelanggan tidak merasa mendaftar empat cara berbeda.
Buat opt-in dan preferensi sangat jelas
Langganan harus selalu opt-in. Jelaskan apa yang akan diterima sebelum konfirmasi—khususnya untuk SMS.
Berikan kontrol kepada pelanggan atas:
- Cakupan: semua insiden vs hanya komponen terpilih (mis. “API” tapi bukan “Marketing site”)
- Tipe: hanya insiden, hanya pemeliharaan, atau keduanya
- Tingkat keparahan (opsional): hanya “Major outage” vs “Semua pembaruan”
Preferensi ini mengurangi kelelahan notifikasi dan menjaga kepercayaan. Jika belum punya langganan per-komponen, mulai dengan “Semua pembaruan” lalu tambahkan filter nanti.
Pastikan notifikasi tidak gagal di saat dibutuhkan
Saat insiden, volume pesan melonjak dan penyedia pihak ketiga bisa men-throttle trafik. Periksa:
- Deliverability: SPF/DKIM/DMARC untuk email; domain pengirim terverifikasi; alamat "from" yang dikenali pelanggan
- Batas laju dan throttling: batas penyedia email/SMS Anda, limit webhook Slack/Teams, dan perilaku retry
- Fallbacks: jika posting Slack gagal, apakah Anda tetap mengirim email? Jika SMS tertunda, apakah Anda menampilkan banner jelas di homepage status?
Layak menjalankan tes terjadwal (mis. kuartalan) untuk memastikan langganan masih berfungsi.
Letakkan “Subscribe to updates” di tempat yang tak terlewatkan
Tambahkan callout jelas di homepage status—di atas lipatan jika memungkinkan—agar pelanggan dapat berlangganan sebelum insiden berikutnya. Tampilkan di mobile, dan sertakan di tempat pelanggan mencari bantuan (seperti tautan dari portal support atau /help center).
Memilih cara membangun halaman status lebih soal apa yang ingin Anda optimalkan: kecepatan peluncuran, keandalan saat insiden, dan upaya pemeliharaan.
Opsi 1: Gunakan tool status page hosted
Tool hosted biasanya jalur tercepat. Anda mendapatkan halaman status siap pakai, langganan, timeline insiden, dan sering integrasi dengan sistem monitoring umum.
Yang perlu dicari di tool hosted:
- Keandalan dan independensi: halaman status harus tetap dapat dijangkau meski aplikasi utama down
- API dan automasi: buat insiden, update komponen, dan posting pembaruan lewat API atau webhook
- Kontrol akses: peran siapa yang bisa mempublikasikan vs menyimpan draf; SSO adalah bonus
- Branding dan domain kustom: logo/warna Anda, plus domain seperti status.namaanda.com
- Analytics: jumlah subscriber, views pembaruan, dan metrik pengiriman email
- Kebutuhan kepatuhan: audit log dan retensi jika Anda beroperasi di lingkungan teregulasi
Opsi 2: Bangun sendiri (DIY)
DIY bisa jadi pilihan bagus jika Anda mau kontrol penuh atas desain, retensi data, dan cara riwayat insiden ditampilkan. Trade-off-nya adalah Anda bertanggung jawab atas keandalan dan operasi.
Arsitektur DIY praktis:
- Situs statis (cepat, ramah cache) untuk UI status dan halaman riwayat insiden
- Sumber data berbasis API (atau CMS ringan) yang menyimpan insiden, komponen, dan pembaruan
- Caching agresif + CDN supaya halaman status tetap cepat di bawah lonjakan trafik
Jika self-host, rencanakan mode kegagalan: apa yang terjadi jika database utama tidak tersedia, atau pipeline deploy Anda down? Banyak tim menaruh halaman status di infrastruktur terpisah (atau bahkan penyedia terpisah) dari produk utama.
Jika Anda ingin kontrol DIY tanpa membangun semua dari nol, platform vibe-coding seperti Koder.ai bisa membantu Anda menyiapkan situs status kustom (UI web plus API insiden kecil) dengan cepat dari spesifikasi berbasis chat. Itu berguna untuk tim yang ingin model komponen khusus, UX riwayat insiden, atau alur admin internal—sambil tetap bisa mengekspor kode sumber, deploy, dan iterasi cepat.
Perencanaan biaya
Tool hosted punya harga bulanan yang dapat diprediksi; DIY butuh waktu engineering, biaya hosting/CDN, dan pemeliharaan berkelanjutan. Saat membandingkan opsi, buat perkiraan biaya bulanan dan waktu internal yang dibutuhkan—lalu cek dengan anggaran Anda (lihat /pricing).
Hubungkan Monitoring dan Alur Kerja Insiden
Halaman status hanya berguna jika mencerminkan realitas dengan cepat. Cara termudah adalah menghubungkan sistem yang mendeteksi masalah (monitoring) dengan sistem yang mengoordinasikan respons (incident workflow), sehingga pembaruan konsisten dan tepat waktu.
Dari mana pembaruan status harus berasal
Sebagian besar tim menggabungkan tiga sumber data:
- Monitoring alerts (health checks, synthetic tests, error rates, latency, queue depth). Bagus untuk deteksi, tapi tidak selalu menggambarkan dampak pelanggan.
- Pembaruan manual dari on-call atau tim support. Manusia bisa menambahkan konteks: siapa yang terdampak, apa solusi sementara, apa yang berubah.
- Alat manajemen insiden (PagerDuty, Opsgenie, Jira Service Management, dll.). Ini menyediakan timeline, peran, dan catatan resolusi yang bisa dirangkum halaman status Anda.
Aturan praktis: monitoring mendeteksi; incident workflow mengoordinasikan; halaman status mengomunikasikan.
Automasi yang membantu (tanpa menjanjikan berlebihan)
Automasi bisa menghemat menit yang berarti:
- Buat insiden dari alert ketika monitor high-severity memicu (mis. “API error rate > 5% selama 5 menit”). Isi pra-judul, komponen terdampak, dan severity awal.
- Update komponen dari health checks untuk sinyal objektif (mis. “Web app: Degraded Performance” ketika ambang latency terlampaui).
- Sinkronkan perubahan status ke channel insiden Anda (Slack/Teams) sehingga responder melihat apa yang pelanggan lihat.
Jaga pesan publik pertama tetap konservatif. “Investigating elevated errors” lebih aman daripada “Outage confirmed” saat Anda masih memvalidasi.
Jangan buat otomatis sepenuhnya tanpa review manusia
Pesan otomatis penuh bisa berbalik efek:
- Alert berisik bisa memposting insiden palsu.
- Kegagalan parsial bisa terlihat “down” ke satu monitor padahal pelanggan baik-baik saja.
- Auto-resolve bisa menutup insiden sementara pengguna masih terdampak.
Gunakan automasi untuk membuat draf dan saran pembaruan, tapi minta manusia menyetujui kata-kata ke pelanggan—terutama untuk status Identified, Mitigated, dan Resolved.
Simpan jejak audit
Perlakukan halaman status seperti buku log publik. Pastikan Anda bisa menjawab:
- Siapa yang mengubah status insiden?
- Apa yang diubah (teks, komponen, timestamp)?
- Kapan diubah?
Jejak audit membantu post-incident review, mengurangi kebingungan saat handoff, dan membangun kepercayaan ketika pelanggan meminta klarifikasi.
Pastikan Keandalan: Hosting, DNS, dan Outage-Proofing
Halaman status hanya membantu jika dapat dijangkau saat produk Anda tidak. Mode kegagalan paling umum adalah membangun halaman status pada infrastruktur yang sama dengan app—sehingga saat app down, halaman status juga menghilang, meninggalkan pelanggan tanpa sumber kebenaran.
Isolasi dari stack inti Anda
Jika memungkinkan, host halaman status di provider berbeda dari aplikasi produksi Anda (atau setidaknya akun/region berbeda). Tujuannya adalah pemisahan blast-radius: outage di platform app Anda tidak boleh sekaligus menjatuhkan komunikasi insiden.
Pertimbangkan juga memisahkan DNS. Jika DNS domain utama dikelola di tempat yang sama dengan edge/CDN aplikasi, masalah DNS atau sertifikat bisa memblokir keduanya. Banyak tim menggunakan subdomain terdedikasi (mis. status.namaanda.com) dengan DNS yang dihosting terpisah.
Buat halaman cepat dan tangguh
Jaga aset ringan: JavaScript minimal, CSS terkompresi, dan tanpa dependensi yang membutuhkan API app Anda untuk dirender. Pasang CDN di depan halaman status dan aktifkan caching untuk resource statis supaya halaman tetap dapat dimuat meski trafik tinggi.
Jaring pengaman praktis adalah mode statis fallback:
- prerender status terakhir dan banner insiden
- sajikan dari object storage atau hosting statis
- update dinamis saat sistem sehat, tapi degrade secara anggun saat tidak
Publik secara default, dengan admin yang aman
Pelanggan tidak perlu login untuk melihat kesehatan layanan. Buat halaman status publik, tetapi tempatkan alat admin/editor di belakang autentikasi (SSO jika ada), dengan kontrol akses kuat dan audit log.
Akhirnya, uji skenario kegagalan: blokir origin app sementara di environment staging dan pastikan halaman status masih resolve, load cepat, dan bisa diperbarui saat Anda membutuhkannya.
Proses Operasional: Siapa yang Memperbarui dan Kapan
Halaman status hanya membangun kepercayaan jika diperbarui secara konsisten selama insiden nyata. Konsistensi itu tidak terjadi begitu saja—Anda butuh kepemilikan jelas, aturan sederhana, dan cadence yang dapat diprediksi.
Definisikan peran (sebelum segala sesuatunya rusak)
Jaga tim inti kecil dan eksplisit:
- Incident Commander (IC): menjalankan respons, memutuskan prioritas, dan mengonfirmasi ketika stabil
- Communications Lead: memposting pembaruan ke halaman status dan menjaga bahasa agar ramah pelanggan
- Engineers on call: menyelidiki, mitigasi, dan memberi fakta terkonfirmasi ke IC
Jika tim kecil, satu orang bisa memegang dua peran—yang penting tentukan di muka. Dokumentasikan handoff peran dan jalur eskalasi dalam panduan on-call Anda (lihat /docs/on-call).
Checklist pembaruan sederhana untuk diikuti tiap kali
Saat alert menjadi insiden yang berdampak pelanggan, ikuti alur yang bisa diulang:
- Acknowledge: posting pembaruan “Investigating” dengan cepat (meskipun detail terbatas)
- Assess impact: konfirmasi komponen, region, atau segmen pelanggan yang terdampak
- Post update: jelaskan apa yang mungkin pelanggan rasakan, solusi sementara (jika ada), dan kapan Anda akan memperbarui lagi
- Resolve: konfirmasi layanan pulih dan apa yang Anda pantau
- Recap: tambahkan ringkasan singkat dan tautkan ke ulasan penuh saat tersedia
Aturan praktis: posting pembaruan pertama dalam 10–15 menit, lalu setiap 30–60 menit selama dampak berlanjut—meskipun pesannya “Tidak ada perubahan, masih menyelidiki.”
Setelah penyelesaian: tinjau dan perbaiki
Dalam 1–3 hari kerja, jalankan post-incident review ringan:
- Timeline: peristiwa kunci dari deteksi hingga pemulihan
- Root cause (status terbaik): jelaskan dalam bahasa sederhana
- Action items: perbaikan spesifik, pemilik, dan tenggat
Lalu perbarui entri insiden dengan ringkasan final sehingga riwayat insiden tetap berguna—bukan hanya log pesan “resolved.”
Checklist Peluncuran dan Peningkatan Berkelanjutan
Halaman status hanya berguna jika mudah ditemukan, mudah dipercaya, dan diperbarui secara konsisten. Sebelum mengumumkan, lakukan pengecekan "production-ready"—lalu siapkan cadence ringan untuk meningkatkannya dari waktu ke waktu.
Checklist peluncuran (versi praktis)
Copy dan struktur
- Pastikan nama komponen cocok dengan apa yang dikenali pelanggan (mis. “Dashboard” vs nama layanan internal).
- Tambahkan intro singkat “Apa yang ditunjukkan halaman ini” dan tautan jelas ke support (mis. /support) untuk masalah akun spesifik.
- Pastikan pembaruan insiden menjelaskan dampak pelanggan (“pembayaran gagal”) dan langkah selanjutnya (“coba lagi setelah 10 menit”).
Branding dan kepercayaan
- Tambahkan logo, favicon, dan sistem warna sederhana untuk status (hindari nuansa yang terlalu halus).
- Sertakan format timestamp dan zona waktu yang jelas.
Akses dan izin
- Verifikasi siapa yang bisa mempublikasikan insiden, jadwalkan pemeliharaan, dan mengedit pengaturan halaman.
- Siapkan “cadangan on-call” agar pembaruan tidak terblokir oleh satu orang.
Uji alur penuh
- Jalankan insiden tes (tandai sebagai tes dan tandai resolved).
- Berlangganan via email/SMS dan pastikan notifikasi tiba dan menyertakan tautan yang benar.
Umumkan
- Tambahkan tautan halaman status di footer aplikasi, pusat bantuan, dan balasan otomatis support.
- Kirim pengumuman singkat ke pelanggan menjelaskan apa yang diharapkan dan cara berlangganan.
Jika Anda membangun situs status sendiri, jalankan checklist peluncuran yang sama di environment staging terlebih dahulu. Tools seperti Koder.ai dapat mempercepat loop iterasi ini dengan menghasilkan UI web, layar admin, dan endpoint backend dari satu spesifikasi—lalu membiarkan Anda mengekspor kode dan deploy di mana pun diperlukan.
Ukur apa yang dimaksud dengan “lebih baik”
Pantau beberapa hasil sederhana dan tinjau bulanan:
- Berkurangnya tiket: bandingkan volume tiket terkait insiden sebelum/sesudah peluncuran.
- Waktu pembaruan pertama yang lebih cepat: ukur dari deteksi hingga pembaruan publik pertama.
- Pertumbuhan subscriber: pantau subscriber per channel dan komponen yang diikuti.
Belajar dari pola insiden
Simpan taksonomi dasar agar riwayat menjadi dapat ditindaklanjuti:
- Tandai insiden menurut kategori (kinerja, partial outage, pihak ketiga, pemeliharaan, terkait keamanan).
- Catat komponen yang berulang dan pelaku masalah berulang.
- Gunakan ini untuk memprioritaskan perbaikan dan menginformasikan proses post-incident review.
Dasar SEO (agar pelanggan mudah menemukan halaman yang tepat)
- Gunakan judul halaman yang jelas seperti “Service Status” dan “Incident History.”
- Jaga struktur heading (H2/H3) sehingga halaman riwayat mudah dipindai.
- Prefer indeksasi halaman riwayat insiden (kecuali ada alasan keamanan/privasi), dan pastikan tautan antar halaman status dan tiap insiden dapat dicrawl.
Seiring waktu, peningkatan kecil—bahasa yang lebih jelas, pembaruan lebih cepat, kategorisasi yang lebih baik—akan terakumulasi menjadi lebih sedikit gangguan, lebih sedikit tiket, dan kepercayaan pelanggan yang lebih besar.