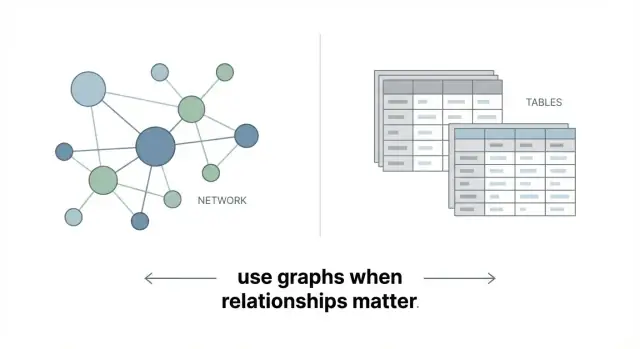
Apa Itu Database Graf (Tanpa Hype)
Database graf menyimpan data sebagai jaringan, bukan sekumpulan tabel. Ide inti sederhana:
- Node adalah “hal” yang Anda pedulikan (seorang pelanggan, produk, akun, perangkat, lokasi).
- Relationship menghubungkan node (pelanggan MEMBELI produk, akun TRANSFER_KE akun lain, pengguna MENGIKUTI pengguna).
- Properties adalah detail yang Anda lampirkan pada node dan relationship (nama, harga, timestamp, jumlah, status).
Itu saja: database graf dibangun untuk merepresentasikan data yang terhubung secara langsung.
Relasi adalah “kelas utama”
Di database graf, relationship bukan hal yang dianggap remeh—mereka disimpan sebagai objek nyata yang bisa dikueri. Relationship bisa memiliki properti sendiri (misalnya, relationship PURCHASED bisa menyimpan tanggal, channel, dan diskon), dan Anda bisa melakukan traversal dari satu node ke node berikutnya secara efisien.
Ini penting karena banyak pertanyaan bisnis secara alami tentang jalur dan koneksi: “Siapa yang terhubung dengan siapa?”, “Berapa langkah dari entitas ini?”, atau “Apa tautan umum antara dua hal ini?”
Perbedaan dengan tabel dan join
Database relasional unggul pada catatan terstruktur: pelanggan, pesanan, faktur. Hubungan juga ada di sana, tetapi biasanya direpresentasikan secara tidak langsung lewat foreign key, dan menghubungkan beberapa hop sering berarti menulis JOIN di beberapa tabel.
Graf menyimpan koneksi tepat di samping data, jadi mengeksplorasi relasi multi-langkah cenderung lebih mudah dimodelkan dan dikueri.
Menetapkan ekspektasi
Database graf sangat baik ketika relasi adalah inti—rekomendasi, cincin penipuan, pemetaan dependensi, knowledge graph. Mereka tidak otomatis lebih baik untuk pelaporan sederhana, total, atau beban kerja yang sangat tabelar. Tujuannya bukan mengganti semua database, melainkan menggunakan graf ketika keterhubunganlah yang memberi nilai.
Mengapa Relasi Mengubah Permainan
Sebagian besar pertanyaan bisnis bukan hanya tentang catatan tunggal—melainkan bagaimana hal-hal terhubung.
Seorang pelanggan bukan sekadar baris; dia terhubung ke pesanan, perangkat, alamat, tiket dukungan, referal, dan kadang-kadang pelanggan lain. Transaksi bukan hanya peristiwa; ia terhubung ke pedagang, metode pembayaran, lokasi, jendela waktu, dan rantai aktivitas terkait. Ketika pertanyaannya “siapa/apa yang terhubung ke apa, dan bagaimana?”, data relasi menjadi pemeran utama.
Traversal: mengikuti koneksi langkah demi langkah
Database graf dirancang untuk traversal: Anda mulai di satu node dan “berjalan” di jaringan dengan mengikuti edges.
Daripada menggabungkan tabel berkali-kali, Anda mengekspresikan jalur yang Anda peduli: Customer → Device → Login → IP Address → Other Customers. Kerangka langkah-demi-langkah itu cocok dengan cara orang menyelidiki penipuan, menelusuri dependensi, atau menjelaskan rekomendasi.
Mengapa kueri multi-hop menjadi lebih sederhana
Perbedaan nyata muncul ketika Anda membutuhkan banyak hop (dua, tiga, lima langkah) dan Anda tidak tahu di muka di mana koneksi menarik akan muncul.
Dalam model relasional, pertanyaan multi-hop sering berubah menjadi rangkaian panjang JOIN ditambah logika ekstra untuk menghindari duplikat dan mengontrol panjang jalur. Dalam graf, “temukan semua jalur hingga N hop” adalah pola normal dan mudah dibaca—terutama pada model property graph yang digunakan banyak database graf.
Properti relationship menambah makna
Edges bukan sekadar garis; mereka bisa membawa data:
- Tipe: purchased, referred, works_with
- Waktu: kapan relationship dimulai, berakhir, atau terakhir terjadi
- Bobot: frekuensi, skor kepercayaan, jumlah, level risiko
Properti itu memungkinkan Anda mengajukan pertanyaan yang lebih baik: “terhubung dalam 30 hari terakhir,” “ikatan terkuat,” atau “jalur yang mencakup transaksi berisiko tinggi”—tanpa memaksa segala sesuatu ke tabel lookup terpisah.
Kasus Penggunaan yang Cocok untuk Database Graf
Database graf bersinar ketika pertanyaan Anda bergantung pada keterhubungan: “siapa terhubung ke siapa, melalui apa, dan berapa langkah jauhnya?” Jika nilai data Anda hidup pada data relasi (bukan sekadar baris atribut), model graf bisa membuat pemodelan data dan kueri terasa lebih alami.
Jejaring sosial dan profesional
Apa pun yang berbentuk jaringan—teman, pengikut, rekan kerja, tim, referal—terpeta dengan rapi ke node dan relationship. Pertanyaan khas termasuk “koneksi mutual,” “jalur terpendek ke seseorang,” atau “siapa yang menghubungkan dua grup ini?” Kueri seperti ini sering kali canggung (atau lambat) bila dipaksa ke banyak tabel join.
Rekomendasi (dan discovery)
Mesin rekomendasi sering bergantung pada koneksi multi-langkah: user → item → kategori → item serupa → user lain. Database graf cocok untuk “orang yang menyukai X juga menyukai Y,” “item yang sering dilihat bersama,” dan “temukan produk yang terhubung melalui atribut atau perilaku bersama.” Ini sangat berguna saat sinyal beragam dan Anda terus menambah tipe relationship baru.
Penyelidikan penipuan dan risiko
Graf deteksi penipuan bekerja baik karena perilaku mencurigakan jarang terisolasi. Akun, perangkat, transaksi, nomor telepon, email, dan alamat membentuk jaring identifier bersama. Graf memudahkan melihat cincin, pola berulang, dan tautan tak langsung (mis. dua akun “tidak terkait” menggunakan perangkat yang sama melalui rantai aktivitas).
Untuk layanan, host, API, panggilan, dan kepemilikan, pertanyaan utama adalah dependensi: “apa yang rusak jika ini berubah?” Graf mendukung analisis dampak, eksplorasi akar masalah, dan kueri “blast radius” ketika sistem saling terkait.
Knowledge graph
Knowledge graph menghubungkan entitas (orang, perusahaan, produk, dokumen) ke fakta dan referensi. Ini membantu pencarian, resolusi entitas, dan menelusuri “mengapa” sebuah fakta diketahui (provenance) di banyak sumber terhubung.
Pertanyaan Umum pada Graf yang Mudah Dijawab
Database graf unggul ketika pertanyaannya benar-benar tentang koneksi: siapa terikat ke siapa, lewat rantai apa, dan pola apa yang berulang. Daripada menggabungkan tabel berkali-kali, Anda menanyakan pertanyaan relasi secara langsung dan menjaga kueri tetap terbaca seiring jaringan berkembang.
1) Pencarian jalur: “Bagaimana A dan B terhubung?”
Pertanyaan tipikal:
- “Apa jalur terpendek dari pelanggan ini ke pedagang itu?”
- “Rekan mana yang menghubungkan Alice dan Bob, dan melalui berapa langkah?”
- “Tunjukkan semua rute dari perangkat ini ke akun itu dalam 3 hop.”
Ini berguna untuk dukungan pelanggan (“mengapa kami menyarankan ini?”), kepatuhan (“tunjukkan rantai kepemilikan”), dan investigasi (“bagaimana ini menyebar?”).
2) Deteksi komunitas: grup dan klaster dalam jaringan
Graf membantu menemukan pengelompokan alami:
- “Pelanggan mana yang membentuk klaster berdasarkan alamat, telepon, dan perangkat bersama?”
- “Di mana komunitas ketat dalam jaringan pemasok kami?”
Anda bisa menggunakan ini untuk segmentasi pengguna, menemukan kru penipuan, atau memahami bagaimana produk dibeli bersama. Intinya adalah bahwa “grup” didefinisikan oleh cara hal-hal terhubung, bukan oleh satu kolom.
3) Centrality dan influence: menemukan node penting
Kadang pertanyaannya bukan hanya “siapa terhubung,” tetapi “siapa yang paling penting” dalam web:
- “Akun mana yang berada pada sebagian besar jalur antar yang lain?”
- “Produk mana yang menjadi jembatan terkuat antara dua segmen pelanggan?”
Node sentral ini sering menunjuk ke influencer, infrastruktur kritis, atau bottleneck yang patut dimonitor.
4) Pattern matching: “temukan segitiga” dan “temukan cincin mencurigakan”
Graf hebat untuk mencari bentuk yang berulang:
- Segitiga: “A mengenal B, B mengenal C, dan C mengenal A.”
- Cincin: “Akun mentransfer dana dalam sebuah loop.”
Dalam Cypher (bahasa kueri graf yang umum), pola segitiga bisa terlihat seperti:
MATCH (a)-[:KNOWS]->(b)-[:KNOWS]->(c)-[:KNOWS]->(a)
RETURN a,b,c
Bahkan jika Anda tidak pernah menulis Cypher sendiri, ini menggambarkan mengapa graf mudah didekati: kueri mencerminkan gambar di kepala Anda.
Graf vs Relasional: Perbedaan Sebenarnya
Database relasional hebat untuk apa yang mereka dirancang: transaksi dan catatan berstruktur baik. Jika data Anda cocok rapi ke tabel (pelanggan, pesanan, faktur) dan Anda mostly mengambilnya berdasarkan ID, filter, dan agregat, sistem relasional sering kali pilihan paling sederhana dan aman.
Masalah join bukan “join itu buruk”—melainkan join dalam-dalam
JOIN baik-baik saja ketika sesekali dan dangkal. Friksi muncul ketika pertanyaan paling penting Anda membutuhkan banyak JOIN, sepanjang waktu, di berbagai tabel.
Contoh:
- “Pelanggan mana yang membeli dari penjual yang terhubung ke pemasok ini melalui dua perantara?”
- “Temukan semua perangkat yang berbagi jaringan dengan perangkat yang digunakan oleh kontak dekat akun ini.”
Di SQL, ini bisa berubah menjadi kueri panjang dengan self-join berulang dan logika kompleks. Mereka juga bisa jadi lebih sulit di-tune saat kedalaman relasi bertambah.
Graf membuat “jalan” multi-langkah menjadi operasi kelas satu
Database graf menyimpan relationship secara eksplisit, jadi traversal multi-langkah di seluruh koneksi adalah operasi alami. Daripada menjahit tabel saat kueri dijalankan, Anda menelusuri node dan edge yang terhubung.
Itu sering berarti:
- Kueri lebih pendek untuk pola multi-hop (kueri lebih mirip dengan pertanyaannya)
- Kompleksitas lebih terprediksi saat mengeksplorasi jalur dengan kedalaman variabel (mis. 2 sampai 6 hop)
Aturan praktis
Jika tim Anda sering menanyakan pertanyaan multi-hop—“terhubung ke,” “melalui,” “dalam jaringan yang sama dengan,” “dalam N langkah”—maka database graf layak dipertimbangkan.
Jika beban kerja inti Anda adalah transaksi volume tinggi, skema ketat, pelaporan, dan join sederhana, relasional biasanya pilihan default yang lebih baik. Banyak sistem nyata menggunakan keduanya; lihat /blog/practical-architecture-graph-alongside-other-databases.
Saat Database Graf Bukan Alat yang Tepat
Buat MVP graf penipuan
Bangun alur kerja investigasi untuk jalur, klaster, dan cincin dengan UI yang bisa digunakan tim Anda.
Database graf bersinar ketika relasi adalah “pertunjukan utama.” Jika nilai aplikasi Anda tidak bergantung pada traversal koneksi (siapa-mengenal-siapa, bagaimana item saling terkait, jalur, lingkungan), graf bisa menambah kompleksitas tanpa banyak manfaat.
CRUD sederhana dengan kebanyakan lookup per-record
Jika sebagian besar permintaan adalah “ambil user berdasarkan ID,” “perbarui profil,” “buat pesanan,” dan data yang Anda butuhkan ada di satu record (atau satu set tabel yang dapat diprediksi), database graf sering tidak perlu. Anda akan menghabiskan waktu memodelkan node dan edge, menyetel traversal, dan mempelajari gaya kueri baru—sementara database relasional menangani pola ini secara efisien dengan tooling yang sudah dikenal.
Pelaporan/BI yang berfokus pada agregat
Dashboard yang dibangun dari total, rata-rata, dan metrik tergrup (pendapatan per bulan, pesanan per wilayah, tingkat konversi per channel) biasanya lebih pas di SQL dan sistem kolumnar daripada kueri graf. Engine graf dapat menjawab beberapa pertanyaan agregat, tetapi jarang merupakan jalur termudah atau tercepat untuk beban kerja OLAP berat.
Kebutuhan transaksi kuat dan fitur “SQL-native”
Saat Anda bergantung pada fitur SQL matang—JOIN kompleks dengan constraint ketat, strategi indexing lanjutan, stored procedure, atau pola transaksi ACID yang mapan—sistem relasional sering menjadi pilihan alami. Banyak database graf mendukung transaksi, tetapi ekosistem dan pola operasional sekitarnya mungkin tidak cocok dengan apa yang tim Anda andalkan.
Catatan independen dengan sedikit link bermakna
Jika data Anda sebagian besar adalah himpunan entitas independen (tiket, faktur, pembacaan sensor) dengan sedikit cross-linking, model graf bisa terasa dipaksakan. Dalam kasus ini, fokuslah pada skema relasional yang bersih (atau model dokumen) dan pertimbangkan graf nanti jika pertanyaan berat pada relasi menjadi pusat.
Aturan bagus: jika Anda bisa menjelaskan kueri teratas tanpa kata-kata seperti “terhubung,” “jalur,” “lingkungan,” atau “rekomend,” database graf mungkin bukan pilihan pertama yang tepat.
Trade-Off yang Perlu Diketahui Sebelum Memilih Graf
Database graf bersinar saat Anda perlu mengikuti koneksi dengan cepat—tetapi kekuatan itu ada biayanya. Sebelum berkomitmen, baik memahami di mana graf cenderung kurang efisien, lebih mahal, atau sekadar berbeda dijalankan sehari-hari.
Database graf sering menyimpan dan mengindeks relationship sedemikian rupa agar hop cepat (mis. dari pelanggan ke perangkat ke transaksi). Trade-off-nya adalah mereka bisa lebih mahal dalam memori dan storage dibandingkan setup relasional sebanding, terutama setelah Anda menambahkan indeks untuk lookup umum dan menjaga data relasi mudah diakses.
Tidak semua kueri menjadi lebih cepat
Jika beban kerja Anda mirip spreadsheet—pemindaian tabel besar, kueri pelaporan atas jutaan baris, atau agregasi berat (total, rata-rata, rollup)—database graf bisa lebih lambat atau lebih mahal untuk hasil yang sama. Graf dioptimalkan untuk traversal (“siapa terhubung ke apa?”), bukan untuk mengolah batch besar catatan independen.
Perbedaan operasional
Kompleksitas operasional bisa menjadi faktor nyata. Backup, scaling, dan monitoring berbeda dari yang biasa dengan sistem relasional. Beberapa platform graf paling baik diskalakan dengan memperbesar mesin, sementara yang lain mendukung scaling out namun membutuhkan perencanaan cermat terkait konsistensi, replikasi, dan pola kueri.
Tim Anda mungkin perlu waktu untuk mempelajari pola pemodelan dan pendekatan kueri baru (mis. model property graph dan bahasa seperti Cypher). Kurva belajarnya bisa dikelola, tetapi tetaplah sebuah biaya—terutama jika Anda menggantikan alur kerja reporting berbasis SQL yang matang.
Pendekatan yang praktis: gunakan graf ketika relasi adalah produk, dan pertahankan sistem yang ada untuk reporting, agregasi, dan analitik tabular.
Dasar Pemodelan Data: Node, Edge, dan Skema
Modelkan node dan edge
Gunakan mode perencanaan untuk memetakan node, edge, dan query sebelum menulis detail implementasi.
Cara berguna untuk memikirkan pemodelan graf sederhana: node adalah hal, dan edge adalah hubungan antar hal. Orang, akun, perangkat, pesanan, produk, lokasi—itu node. “Bought,” “logged in from,” “works with,” “is parent of”—itu edge.
Property graphs vs RDF triples
Sebagian besar produk graf komersial menggunakan property graph: baik node maupun edge bisa memiliki properties (field key–value). Contohnya, edge PURCHASED mungkin menyimpan date, amount, dan channel. Ini membuatnya alami untuk memodelkan “relationship dengan detail.”
RDF merepresentasikan pengetahuan sebagai triple: subject – predicate – object. RDF baik untuk vocabulary yang interoperable dan menghubungkan data antar sistem, tetapi sering menggeser “detail relationship” ke node/triple tambahan. Secara praktis, Anda akan melihat RDF mendorong penggunaan ontologi standar dan pola SPARQL, sementara property graph terasa lebih dekat dengan pemodelan data aplikasi.
Bahasa kueri dalam istilah sederhana
- Cypher (populer pada property graph) terbaca seperti pola yang ingin Anda temukan: “(Customer)-[PURCHASED]->(Product).”
- Gremlin lebih seperti traversal langkah demi langkah: mulai di sini, jalan mengikuti edge seperti ini, filter, lalu agregasi.
- SPARQL adalah bahasa kueri dunia RDF, mencocokkan pola graf terhadap triple, sering memakai vocabulary bersama.
Anda tidak perlu menghafal sintaks di awal—yang penting adalah bahwa kueri graf biasanya diekspresikan sebagai jalur dan pola, bukan sebagai penggabungan tabel.
Apa arti “skema” di sistem graf
Graf sering fleksibel skema, artinya Anda bisa menambah label node atau properti tanpa migrasi besar. Tapi fleksibilitas tetap membutuhkan disiplin: tetapkan konvensi penamaan, properti yang wajib (mis. id), dan aturan untuk tipe relationship.
Tipe relationship, arah, dan properti
Pilih tipe relationship yang menjelaskan makna (“FRIEND_OF” vs “CONNECTED”). Gunakan arah untuk memperjelas semantik (mis. FOLLOWS dari follower ke creator), dan tambahkan properti edge ketika relationship membawa fakta sendiri (waktu, confidence, peran, bobot).
Cara Menentukan Jika Masalah Anda Didorong Oleh Relasi
Sebuah masalah “didorong relasi” jika bagian sulitnya bukan menyimpan record—melainkan memahami bagaimana hal-hal terhubung, dan bagaimana koneksi itu mengubah makna tergantung jalur yang Anda ambil.
Mulai dari pertanyaan, bukan tabel
Mulailah dengan menulis 5–10 pertanyaan teratas dalam bahasa biasa—yang sering ditanyakan pemangku kepentingan dan sistem saat ini menjawabnya dengan lambat atau tidak konsisten. Kandidat graf yang baik biasanya menyertakan frasa seperti “terhubung ke,” “melalui,” “mirip dengan,” “dalam N langkah,” atau “siapa lagi.”
Contoh:
- “Pelanggan mana yang terhubung ke cincin penipuan ini melalui perangkat dan alamat bersama?”
- “Produk apa yang sering dibeli bersama orang yang juga melihat X?”
- “Pemasok mana yang terdampak tidak langsung jika pabrik ini offline?”
Terjemahkan pertanyaan menjadi entitas dan interaksi
Setelah punya pertanyaan, petakan kata benda dan kata kerja:
- Entitas kunci menjadi node (Customer, Account, Device, Product, Supplier).
- Interaksi menjadi relationship (PAID_WITH, LOGGED_IN_FROM, BOUGHT, SUPPLIES).
Kemudian putuskan apa yang harus menjadi relationship versus node. Aturan praktis: jika sesuatu membutuhkan atribut sendiri dan Anda akan menghubungkan banyak pihak kepadanya, jadikan itu node (mis. Order atau event Login bisa jadi node ketika membawa detail dan menghubungkan banyak entitas).
Permudah filter dan scoring
Tambahkan properti yang memudahkan mempersempit hasil dan memberi peringkat relevansi tanpa join tambahan atau pemrosesan pasca. Properti bernilai tinggi tipikal meliputi waktu, jumlah, status, channel, dan confidence score.
Jika sebagian besar pertanyaan penting Anda memerlukan koneksi multi-langkah ditambah filter berdasarkan properti tersebut, besar kemungkinan Anda berurusan dengan masalah yang digerakkan relasi di mana database graf unggul.
Arsitektur Praktis: Graf Bersama Database Lain
Sebagian besar tim tidak mengganti semuanya dengan database graf. Pendekatan yang lebih praktis adalah mempertahankan “system of record” tempatnya sudah bekerja (sering SQL), dan menggunakan database graf sebagai mesin khusus untuk pertanyaan berat relasi.
Pertahankan source of truth di SQL (atau datastore inti Anda)
Gunakan database relasional untuk transaksi, constraint, dan entitas kanonik (pelanggan, pesanan, akun). Lalu proyeksikan view relasi ke database graf—hanya node dan edge yang Anda butuhkan untuk kueri terhubung.
Ini menjaga audit dan tata kelola data tetap sederhana sambil membuka kueri traversal cepat.
Bangun graf untuk satu fitur, bukan seluruh perusahaan
Database graf bersinar saat Anda mengaitkannya dengan fitur yang scope-nya jelas, seperti:
- Rekomendasi (“orang yang membeli X juga membeli Y”)
- Skoring risiko (cincin penipuan, perangkat bersama, instrumen pembayaran umum)
- Resolusi identitas (menghubungkan profil antar sistem)
Mulai dari satu fitur, satu tim, dan satu hasil terukur. Anda bisa meluas nanti jika terbukti memberi nilai.
Jika hambatan Anda adalah mengirimkan prototipe (bukan memperdebatkan model), platform vibe-coding seperti Koder.ai dapat membantu Anda membangun aplikasi graf sederhana dengan cepat: Anda jelaskan fitur lewat chat, hasilkan UI React dan backend Go/PostgreSQL, lalu iterasi sementara tim data memvalidasi skema dan kueri graf.
Strategi sinkronisasi: batch vs near-real-time
Seberapa segar graf harusnya?
- Update batch (per jam/per malam) lebih sederhana dan sering cukup untuk analitik, discovery, dan banyak mesin rekomendasi.
- Streaming near-real-time (menit/detik) cocok untuk graf deteksi penipuan dan keputusan operasional.
Pola umum: tulis transaksi ke SQL → publish event perubahan → perbarui graf.
Identifier konsisten dan kepemilikan jelas
Graf bisa berantakan saat ID bergeser.
Tentukan identifier stabil (mis. customer_id, account_id) yang cocok antar sistem, dan dokumentasikan siapa yang “memiliki” setiap field dan relationship. Jika dua sistem bisa membuat edge yang sama (mis. “knows”), putuskan mana yang menang.
Jika Anda merencanakan pilot, lihat /blog/getting-started-a-low-risk-pilot-plan untuk pendekatan rollout bertahap.
Memulai: Rencana Pilot Berisiko Rendah
Kurangi biaya pembangunan
Dapatkan kredit dengan membagikan hasil kerja Anda di Koder.ai atau mengajak rekan untuk mencobanya.
Pilot graf harus terasa seperti eksperimen, bukan rewrite. Tujuannya membuktikan (atau mematahkan) bahwa kueri berat relasi menjadi lebih sederhana dan lebih cepat—tanpa mempertaruhkan seluruh tumpukan data.
1) Pilih irisan kecil dan bernilai tinggi
Mulai dari dataset sempit yang sudah menyakitkan: terlalu banyak JOIN, SQL rapuh, atau pertanyaan “siapa terhubung ke apa?” yang lambat. Batasi ke satu workflow (mis. customer ↔ account ↔ device, atau user ↔ product ↔ interaction) dan definisikan beberapa kueri yang ingin Anda jawab end-to-end.
2) Definisikan metrik sukses sebelum membangun
Ukur lebih dari kecepatan:
- Kompleksitas kueri: Berapa baris, join, atau tabel menengah yang dibutuhkan sekarang vs. di graf?
- Latensi: Waktu untuk mengembalikan hasil pada volume data realistis.
- Waktu developer: Berapa lama untuk membangun dan mengubah kueri saat kebutuhan berubah?
Jika Anda tidak bisa menyebut angka “sebelum”-nya, Anda tidak akan percaya “sesudah.”
3) Jaga model tetap bertujuan (hindari sprawl graf)
Godaan memodelkan semuanya sebagai node dan edge itu besar. Tahan diri. Perhatikan “graph sprawl”: terlalu banyak tipe node/edge tanpa kueri jelas yang memerlukannya. Setiap label atau relationship baru harus earning tempatnya dengan memungkinkan pertanyaan nyata.
4) Perlakukan tata kelola sebagai bagian pilot
Rencanakan privasi, kontrol akses, dan retensi data sejak awal. Data relasi bisa mengungkap lebih banyak daripada catatan individual (mis. koneksi yang mengimplikasikan perilaku). Tentukan siapa yang boleh mengkueri apa, bagaimana hasil diaudit, dan bagaimana data dihapus bila diperlukan.
5) Jalankan berdampingan dengan database Anda saat ini
Gunakan sinkronisasi sederhana (batch atau streaming) untuk mengisi graf sementara sistem eksisting tetap source of truth. Saat pilot terbukti bernilai, Anda bisa memperluas cakupan—dengan hati-hati, satu use case pada satu waktu.
Daftar Periksa Cepat: Gunakan Graf untuk Relasi
Jika Anda memilih database, jangan mulai dari teknologi—mulailah dari pertanyaan yang perlu dijawab. Database graf bersinar ketika masalah tersulit Anda tentang koneksi dan jalur, bukan sekadar menyimpan catatan.
Daftar singkat “apakah ini digerakkan relasi?”
Gunakan daftar ini untuk memeriksa kecocokan sebelum berinvestasi:
- Kedalaman relasi: Apakah Anda rutin perlu mengikuti relasi 2+ hop (A→B→C→D) untuk mendapatkan jawaban?
- Pola kueri: Apakah pertanyaan utama Anda tentang pola (mis. “orang yang berbagi pemberi kerja dan nomor telepon”) bukan filter satu-tabel?
- Frekuensi update: Apakah relasi sering berubah (koneksi baru, penghapusan, perubahan peran), dan apakah Anda perlu perubahan itu tercermin cepat?
- Skala: Apakah dataset cukup besar sehingga menggabungkan banyak tabel (atau menjahit di kode aplikasi) menjadi lambat, mahal, atau rapuh?
Jika Anda menjawab “ya” untuk sebagian besar ini, graf bisa sangat cocok—terutama saat Anda butuh pencocokan pola multi-hop seperti:
- “Temukan jalur terpendek antara dua entitas.”
- “Tunjukkan semua akun yang terhubung ke perangkat ini dalam 3 langkah.”
- “Rekomendasikan item berdasarkan tetangga bersama, bukan hanya kategori.”
Kapan tetap menggunakan SQL/NoSQL
Jika pekerjaan Anda kebanyakan lookup sederhana (berdasarkan ID/email) atau agregasi (“total penjualan per bulan”), database relasional atau penyimpanan key-value/dokumen biasanya lebih sederhana dan lebih murah dijalankan.
Cara mengurangi risiko keputusan
Tuliskan 10 pertanyaan bisnis teratas Anda dalam kalimat biasa, lalu uji pada data nyata dalam pilot kecil. Waktu kueri, catat apa yang sulit diungkapkan, dan buat log singkat perubahan model yang Anda perlukan. Jika pilot Anda kebanyakan berubah menjadi “lebih banyak join” atau “lebih banyak caching,” itu sinyal graf mungkin bermanfaat. Jika lebih banyak hitungan dan filter, besar kemungkinan tidak.