OLTP vs OLAP: Apa Itu (Tanpa Jargon)
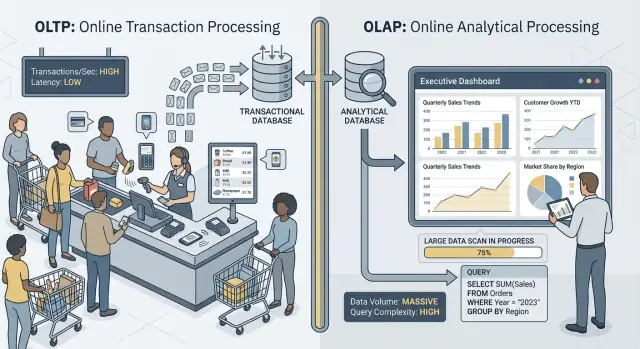
Saat orang mengatakan “OLTP” dan “OLAP,” mereka berbicara tentang dua cara pemakaian database yang sangat berbeda.
OLTP: database yang menjalankan bisnis
OLTP (Online Transaction Processing) adalah beban kerja di balik tindakan sehari-hari yang harus cepat dan benar setiap kali. Bayangkan: “simpan perubahan ini sekarang juga.”
Tugas OLTP tipikal termasuk membuat pesanan, memperbarui inventaris, mencatat pembayaran, atau mengubah alamat pelanggan. Operasi ini biasanya kecil (beberapa baris), sering terjadi, dan harus merespons dalam milidetik karena ada orang atau sistem lain yang menunggu.
OLAP: database yang menjelaskan bisnis
OLAP (Online Analytical Processing) adalah beban kerja yang digunakan untuk memahami apa yang terjadi dan mengapa. Bayangkan: “pindai banyak data dan ringkas itu.”
Tugas OLAP tipikal termasuk dashboard, laporan tren, analisis kohort, peramalan, dan pertanyaan “slice-and-dice” seperti: “Bagaimana perubahan pendapatan menurut wilayah dan kategori produk selama 18 bulan terakhir?” Kueri ini sering membaca banyak baris, melakukan agregasi berat, dan bisa berjalan selama detik (atau menit) tanpa menjadi “salah.”
Data sama, tujuan berbeda—dan kebutuhan juga berbeda
Gagasan utamanya sederhana: OLTP mengoptimalkan untuk penulisan cepat dan konsisten serta pembacaan kecil, sementara OLAP mengoptimalkan untuk pembacaan besar dan perhitungan kompleks. Karena tujuannya berbeda, pengaturan database terbaik, indeks, tata letak penyimpanan, dan pendekatan skala juga sering berbeda.
Perlu dicatat kata yang digunakan: jarang, bukan tidak pernah. Beberapa tim kecil bisa berbagi satu database untuk sementara, khususnya dengan volume data yang sederhana dan disiplin kueri yang hati-hati. Bagian selanjutnya membahas apa yang duluan rusak, pola pemisahan umum, dan cara memindahkan pelaporan dari produksi dengan aman.
Contoh cepat
- Checkout (OLTP): seorang pelanggan mengklik “Bayar,” dan aplikasi Anda menulis pesanan, status pembayaran, dan pembaruan inventaris.
- Dashboard pelaporan (OLAP): seorang manajer membuka dashboard yang mengagregasi ribuan (atau jutaan) pesanan untuk menunjukkan conversion rate, rata-rata nilai pesanan, dan tren mingguan.
Tujuan Berbeda, Metrik Keberhasilan Berbeda
OLTP dan OLAP mungkin sama-sama “menggunakan SQL,” tetapi mereka dioptimalkan untuk pekerjaan berbeda—dan itu terlihat pada apa yang masing‑masing anggap sukses.
OLTP: kecepatan, konkruensi, dan kebenaran
Sistem OLTP (transaksional) menyalakan operasi sehari‑hari: alur checkout, pembaruan akun, reservasi, alat support. Prioritasnya jelas:
- Waktu respons cepat untuk pembacaan/tulisan kecil (pikirkan milidetik)
- Banyak pengguna konkuren tanpa perlambatan
- Kebenaran dan konsistensi, karena saldo yang salah atau pesanan ganda adalah masalah bisnis nyata
Keberhasilan sering diukur dengan metrik latensi seperti p95/p99 request time, tingkat error, dan bagaimana sistem berperilaku saat puncak konkruensi.
OLAP: memindai, mengagregasi, dan fleksibilitas
Sistem OLAP (analitik) menjawab pertanyaan seperti “Apa yang berubah kuartal ini?” atau “Segmen mana yang churn setelah harga baru?” Kueri ini sering:
- Memindai jumlah data besar di banyak baris
- Melakukan agregasi (SUM, COUNT, persentil) dan join
- Sering berubah saat analis mengeksplorasi dan menyempurnakan pertanyaan
Keberhasilan di sini terlihat lebih seperti throughput kueri, waktu untuk mendapatkan wawasan, dan kemampuan menjalankan kueri kompleks tanpa tuning manual untuk setiap laporan.
Mengapa “satu sistem untuk semua” menciptakan trade‑off
Saat Anda memaksakan kedua beban kerja ke satu database, Anda meminta database itu menjadi sangat baik sekaligus pada transaksi kecil yang bervolume tinggi dan pada pemindaian eksploratori besar. Hasilnya biasanya kompromi: OLTP mendapatkan latensi yang tidak terduga, OLAP dibatasi untuk melindungi produksi, dan tim berdebat soal kueri siapa yang “diizinkan.” Tujuan yang berbeda pantas punya metrik keberhasilan terpisah—dan biasanya sistem terpisah.
Kontensi Sumber Daya: Ketika Analitik Mengambil Dari Transaksi
Saat OLTP (transaksi harian aplikasi Anda) dan OLAP (pelaporan dan analisis) berjalan di database yang sama, mereka berebut sumber daya yang terbatas. Hasilnya bukan sekadar “pelaporan lebih lambat.” Sering kali checkout melambat, login tertahan, dan gangguan aplikasi menjadi tidak terduga.
CPU dan memori: kueri panjang vs kueri pendek
Kueri analitik cenderung berjalan lama dan berat: join di tabel besar, agregasi, penyortiran, dan pengelompokan. Mereka dapat menguasai core CPU dan, sama pentingnya, memori untuk hash join dan buffer sort.
Sementara itu, kueri transaksional biasanya kecil tetapi sensitif terhadap latensi. Jika CPU jenuh atau tekanan memori memaksa pengosongan sering, kueri‑kueri kecil itu mulai menunggu di belakang kueri besar—meskipun setiap transaksi hanya membutuhkan sedikit waktu kerja.
Disk I/O: pemindaian besar vs banyak baca/tulis kecil
Analitik sering memicu pemindaian tabel besar dan membaca banyak halaman secara sekuensial. Beban OLTP melakukan kebalikan: banyak baca acak kecil ditambah penulisan konstan ke index dan log.
Gabungkan keduanya dan subsistem penyimpanan harus menjongkok pola akses yang tidak kompatibel. Cache yang membantu OLTP bisa “terbasuh” oleh pemindaian analitik, dan latensi tulis bisa melonjak saat disk sibuk men‑stream data untuk laporan.
Tekanan pool koneksi dan antrean
Beberapa analis menjalankan kueri luas dapat mengikat koneksi selama menit. Jika aplikasi Anda menggunakan pool berukuran tetap, permintaan akan antre menunggu koneksi kosong. Efek antrean itu bisa membuat sistem yang sehat terasa rusak: rata‑rata latensi mungkin terlihat dapat diterima, tetapi tail latencies (p95/p99) menjadi menyakitkan.
Apa yang pengguna perhatikan
Dari luar, ini muncul sebagai timeout, alur checkout lambat, hasil pencarian tertunda, dan perilaku yang rentan—seringkali “hanya saat pelaporan” atau “hanya di akhir bulan.” Tim aplikasi melihat error; tim analitik melihat kueri lambat; masalah sebenarnya adalah kontensi bersama di bawah permukaan.
Tata Letak Data dan Kebutuhan Indeks yang Berlawanan
OLTP dan OLAP tidak hanya “menggunakan database berbeda”—mereka memberi penghargaan pada desain fisik yang berlawanan. Saat Anda mencoba memenuhi keduanya di satu tempat, biasanya berakhir dengan kompromi yang mahal dan tetap kurang memuaskan.
OLTP: dioptimalkan untuk lookup selektif cepat
Beban transaksional didominasi oleh kueri pendek yang menyentuh irisan kecil data: ambil satu pesanan, perbarui satu baris inventaris, tampilkan 20 event terakhir untuk satu pengguna.
Itu mendorong skema OLTP ke arah penyimpanan berorientasi baris dan indeks yang mendukung point lookup dan scan range kecil (sering pada primary key, foreign key, dan beberapa secondary index bernilai tinggi). Tujuannya adalah latensi rendah yang dapat diprediksi—terutama untuk tulis.
OLAP: dioptimalkan untuk pemindaian, pengelompokan, dan peringkasan
Beban analitik sering perlu membaca banyak baris dan hanya beberapa kolom: “pendapatan per minggu per wilayah,” “conversion rate per kampanye,” “produk teratas menurut margin.”
Sistem OLAP mendapat manfaat dari penyimpanan kolom (agar membaca hanya kolom yang dibutuhkan), partisi (agar memangkas data lama atau tidak relevan dengan cepat), dan pre‑aggregasi (materialized views, rollups, tabel ringkasan) sehingga laporan tidak menghitung ulang total yang sama berulang kali.
Mengapa “indeks untuk semua” malah merugikan
Reaksi umum adalah menambahkan indeks sampai setiap dashboard cepat. Tapi setiap indeks ekstra meningkatkan biaya penulisan: insert, update, dan delete sekarang harus memelihara lebih banyak struktur. Ini juga meningkatkan penyimpanan dan dapat memperlambat tugas pemeliharaan seperti vacuuming, reindexing, dan backup.
Perencana kueri dan drift statistik (dalam istilah sederhana)
Database memilih rencana kueri berdasarkan statistik—perkiraan berapa banyak baris yang cocok filter, seberapa selektif sebuah indeks, dan bagaimana data didistribusikan. OLTP mengubah data secara terus‑menerus. Saat distribusi bergeser, statistik bisa drift, dan planner mungkin memilih rencana yang bagus untuk data kemarin tetapi lambat hari ini.
Campurkan kueri OLAP yang memindai dan meng‑join tabel besar, dan Anda mendapat lebih banyak variabilitas: “rencana terbaik” menjadi lebih sulit diprediksi, dan tuning untuk satu beban kerja sering membuat yang lain memburuk.
Locking, MVCC, dan Efek Pemeliharaan
Bahkan jika database Anda “mendukung konkruensi,” mencampur pelaporan berat dengan transaksi langsung menciptakan perlambatan halus yang sulit diprediksi—dan bahkan lebih sulit dijelaskan kepada pelanggan yang sedang melihat checkout berputar.
Kueri panjang masih menciptakan masalah lock
Kueri ala OLAP sering memindai banyak baris, meng‑join beberapa tabel, dan berjalan selama detik atau menit. Selama itu mereka dapat memegang lock (mis. pada objek skema, atau ketika perlu menyortir/agregasi ke struktur temp) dan sering meningkatkan kontensi lock secara tidak langsung dengan menjaga banyak baris “dalam permainan.”
Bahkan dengan MVCC (multi‑version concurrency control), database harus melacak beberapa versi baris agar pembaca dan penulis tidak saling memblokir. Itu membantu, tetapi tidak menghilangkan kontensi—terutama saat kueri menyentuh tabel panas yang sering diperbarui transaksi.
MVCC punya biaya tersembunyi: pembersihan jadi lebih sulit
MVCC berarti versi baris lama tetap ada sampai database bisa menghapusnya dengan aman. Laporan yang berjalan lama bisa menjaga snapshot lama tetap terbuka, yang mencegah pembersihan mereklamasi ruang.
Itu memengaruhi:
- Vacuum/garbage collection: pembersihan tidak bisa segera menghapus tuple/versi mati.
- Bloat/fragmentasi: penyimpanan tumbuh, indeks jadi kurang efisien, dan cache menjadi kurang berguna.
- Tekanan kompaksi: beberapa engine merespons dengan kerja latar belakang lebih berat, yang mencuri I/O dan CPU dari transaksi.
Hasilnya adalah pukulan ganda: pelaporan membuat database bekerja lebih keras dan memperlambat sistem seiring waktu.
Level isolasi memperbesar variabilitas latensi
Alat pelaporan sering meminta isolasi yang lebih kuat (atau tidak sengaja berjalan dalam transaksi panjang). Isolasi lebih tinggi dapat meningkatkan waktu tunggu pada lock dan jumlah versioning yang harus dikelola engine. Dari sisi OLTP, Anda melihat ini sebagai spike yang tidak dapat diprediksi: sebagian besar pesanan menulis cepat, lalu beberapa tiba‑tiba tertahan.
Contoh praktis: pelaporan akhir bulan melambatkan pesanan
Pada akhir bulan, finance menjalankan kueri “pendapatan per produk” yang memindai pesanan dan item baris untuk seluruh bulan. Saat berjalan, tulis pesanan baru masih diterima, tetapi vacuum tidak bisa mereklamasi versi lama dan indeks berputar. API order mulai melihat timeout sesekali—bukan karena “down,” tetapi karena kontensi dan overhead pembersihan diam‑diam mendorong latensi melewati batas Anda.
Spikiness Beban Kerja dan Latensi yang Tidak Terduga
Ajak rekan tim dan dapatkan kredit
Ajak rekan melalui rujukan dan dapatkan kredit saat pengguna baru bergabung.
Sistem OLTP hidup dan mati oleh keterdugaan. Checkout, tiket support, atau pembaruan saldo tidak “sebagiannya baik” jika cepat 95% dari waktu—pengguna memperhatikan momen‑momen lambat. OLAP, sebaliknya, sering bersifat bursty: beberapa kueri berat bisa tenang berjam‑jam lalu tiba‑tiba mengonsumsi banyak CPU, memori, dan I/O.
Spike terjadi karena alasan bisnis yang normal
Traffic analitik cenderung menumpuk di sekitar rutinitas:
- Dashboard “standup” pagi di mana banyak orang segarili meng‑refresh grafik yang sama
- Laporan terjadwal yang semua kick‑off di awal jam
- Penutupan akhir bulan dan tinjauan kuartalan yang memicu pemindaian dan join panjang
Sementara itu, traffic OLTP biasanya lebih stabil (atau setidaknya lebih kontinu). Ketika kedua beban kerja berbagi satu database, spike analitik itu diterjemahkan menjadi latensi tak terduga untuk transaksi—timeout, page load lebih lambat, dan retry yang menambah beban.
Mengapa pembatasan dan penjadwalan membantu—tetapi tidak menyelesaikan ketidaksesuaian
Anda bisa mengurangi kerusakan dengan taktik seperti menjalankan laporan di malam hari, membatasi konkruensi, menegakkan statement timeout, atau menetapkan cap biaya kueri. Ini adalah pengaman yang berguna, terutama untuk “pelaporan di produksi.”
Tetapi mereka tidak menghapus ketegangan fundamental: kueri OLAP dirancang untuk menggunakan banyak sumber daya untuk menjawab pertanyaan besar, sementara OLTP membutuhkan irisan sumber daya kecil dan cepat sepanjang hari. Saat refresh dashboard tak terduga, kueri ad‑hoc, atau laporan backfill lolos, database bersama terekspos lagi.
Problem tetangga berisik
Pada infrastruktur bersama, satu pengguna analitik atau job yang “berisik” bisa memonopoli cache, men‑saturate disk, atau menekan penjadwalan CPU—tanpa melakukan sesuatu yang salah. Beban OLTP menjadi korban, dan yang paling sulit adalah kegagalan tampak acak: lonjakan latensi daripada error yang jelas dan dapat direproduksi.
Kompleksitas Operasional: Backup, Keamanan, dan Perencanaan Kapasitas
Mencampur OLTP (transaksi) dan OLAP (analitik) tidak hanya menciptakan sakit kepala performa—itu juga membuat operasi sehari‑hari lebih sulit. Database menjadi kotak “segala hal”, dan setiap tugas operasional mewarisi risiko gabungan kedua beban kerja.
Backup, restore, dan disaster recovery melambat
Tabel analitik cenderung tumbuh lebar dan cepat (lebih banyak history, lebih banyak kolom, lebih banyak agregat). Volume ekstra itu mengubah cerita recovery Anda.
Backup penuh membutuhkan waktu lebih lama, memakai lebih banyak penyimpanan, dan meningkatkan peluang melewatkan jendela backup. Restore lebih buruk: ketika Anda perlu pulih cepat, Anda memulihkan bukan hanya data transaksional yang dibutuhkan aplikasi, tetapi juga dataset analitik besar yang tidak diperlukan untuk menjalankan bisnis. Tes disaster recovery juga menjadi lebih lama, sehingga lebih jarang dilakukan—sebaliknya dari yang Anda inginkan.
Perencanaan kapasitas jadi tebakan
Pertumbuhan transaksional biasanya dapat diprediksi: lebih banyak pelanggan, lebih banyak pesanan, lebih banyak baris. Pertumbuhan analitik seringkali bergelombang: dashboard baru, kebijakan retensi baru, atau satu tim memutuskan menyimpan “satu tahun lagi” event mentah.
Saat keduanya hidup bersama, Anda tidak mudah menjawab:
- Apakah kita tumbuh karena produk sukses, atau karena laporan menyimpan lebih banyak history?
- Perlukah storage lebih cepat untuk transaksi, atau storage murah lebih banyak untuk analitik?
Ketidakpastian itu mendorong overprovisioning (membayar headroom yang tidak perlu) atau underprovisioning (outage mengejutkan).
Pengaman lebih sulit ditegakkan secara adil
Di database bersama, satu kueri “tidak bersalah” bisa menjadi insiden. Anda akan menambahkan pengaman seperti statement timeout, kuota beban kerja, jendela pelaporan terjadwal, atau aturan manajemen beban kerja. Ini membantu, tapi rapuh: aplikasi dan analis kini bersaing untuk batas yang sama, dan perubahan kebijakan untuk satu kelompok bisa merusak yang lain.
Keamanan dan kontrol akses jadi berantakan
Aplikasi biasanya membutuhkan izin sempit dan tujuan‑khusus. Analis sering membutuhkan akses baca yang luas, kadang melintasi banyak tabel, untuk mengeksplorasi dan memvalidasi. Menaruh keduanya di satu database meningkatkan tekanan untuk memberikan hak akses lebih luas “agar laporan jalan,” memperbesar blast radius kesalahan dan menambah jumlah orang yang bisa melihat data operasional sensitif.
Skalabilitas dan Biaya: Anda Berakhir Membayar Dua Kali (atau Lebih)
Beralih ke CDC saat siap
Mulai sederhana, lalu ekspor kode saat menambahkan model ELT dan layanan analitik.
Mencoba menjalankan OLTP dan OLAP di database yang sama sering tampak lebih murah—sampai Anda mulai menskalakan. Masalahnya bukan hanya performa. Cara “benar” untuk menskalakan setiap beban kerja mendorong Anda ke infrastruktur berbeda, dan menggabungkannya memaksa kompromi mahal.
Skalasi OLTP didorong oleh tulis (dan biasanya menyakitkan)
Sistem transaksional dibatasi oleh tulis: banyak update kecil, latensi ketat, dan lonjakan yang harus ditangani segera. Menskalakan OLTP biasanya berarti scaling vertikal (CPU lebih besar, disk lebih cepat, lebih banyak memori) karena beban tulis sulit di‑fan‑out.
Saat batas vertikal tercapai, Anda melihat sharding atau pola scaling tulis lain. Itu menambah overhead engineering dan sering memerlukan perubahan hati‑hati pada aplikasi.
Skalasi OLAP didorong oleh compute (dan sering elastis)
Beban analitik skalanya berbeda: pemindaian panjang, agregasi berat, dan banyak throughput baca. Sistem OLAP biasanya diskalakan dengan menambah compute terdistribusi, dan banyak setup modern memisahkan compute dari storage sehingga Anda bisa menambah tenaga kueri tanpa memindahkan atau menduplikasi data.
Jika OLAP berbagi database OLTP, Anda tidak bisa menskalakan analitik secara independen. Anda menskalakan seluruh database—meskipun transaksi sudah baik.
Tagihan tersembunyi: membayar sumber daya kelas OLTP untuk analitik
Untuk menjaga transaksi cepat sambil menjalankan laporan, tim seringkali melakukan over‑provision database produksi: headroom CPU ekstra, storage kelas tinggi, instance lebih besar “untuk berjaga‑jaga.” Itu berarti Anda membayar harga OLTP untuk mendukung perilaku OLAP.
Pemisahan mengurangi over‑provisioning karena setiap sistem bisa disesuaikan untuk tugasnya: OLTP untuk tulis berlatensi rendah yang dapat diprediksi, OLAP untuk baca berat yang bursty. Hasilnya sering lebih murah secara keseluruhan—meskipun menjadi “dua sistem”—karena Anda berhenti membeli kapasitas transaksi premium untuk menjalankan pelaporan di produksi.
Arsitektur Umum yang Memisahkan OLTP dan OLAP
Sebagian besar tim memisahkan beban kerja transaksional (OLTP) dari beban kerja analitik (OLAP) dengan menambahkan sistem kedua yang “berorientasi baca” daripada memaksa satu database melayani keduanya.
Pola 1: Read replica untuk pelaporan
Langkah pertama yang umum adalah read replica (atau follower) dari database OLTP, tempat alat BI menjalankan kueri.
Kelebihan: perubahan aplikasi minimal, SQL familiar, cepat disiapkan.
Kekurangan: tetap engine dan schema yang sama, jadi laporan berat dapat men‑saturate CPU/I/O replica; beberapa laporan memerlukan fitur yang tidak tersedia di replica; dan replication lag membuat angka mungkin tertinggal beberapa menit (atau lebih). Lag juga menciptakan kebingungan “mengapa tidak cocok dengan produksi?” selama insiden.
Cocok untuk: tim kecil, volume data moderat, “near‑real‑time” bagus tapi tidak kritis, dan kueri pelaporan bisa dikontrol.
Pola 2: Data warehouse / database analitik khusus
Di sini, OLTP tetap dioptimalkan untuk tulis dan baca titik, sementara analitik pindah ke data warehouse (atau DB analitik kolom) yang dirancang untuk pemindaian, kompresi, dan agregasi besar.
Kelebihan: performa OLTP yang dapat diprediksi, dashboard lebih cepat, konkruensi lebih baik untuk analis, dan tuning biaya/performa yang lebih jelas.
Kekurangan: sekarang Anda mengoperasikan sistem lain dan butuh model data (sering star schema) yang ramah untuk analitik.
Cocok untuk: data yang tumbuh, banyak stakeholder, pelaporan kompleks, atau kebutuhan latensi OLTP yang ketat.
Pola 3: Pipeline berbasis CDC ke analitik
Alih‑alih ETL periodik, Anda stream perubahan menggunakan CDC (change data capture) dari log OLTP ke warehouse (sering dengan ELT).
Kelebihan: data lebih segar tanpa membebani OLTP, pemrosesan inkremental lebih mudah, dan auditabilitas lebih baik.
Kekurangan: lebih banyak komponen bergerak dan perlu penanganan perubahan skema dengan hati‑hati.
Cocok untuk: volume besar, kebutuhan kesegaran tinggi, dan tim yang siap untuk pipeline data.
Memindahkan Data Dari OLTP ke OLAP dengan Aman
Memindahkan data dari database transaksional (OLTP) ke sistem analitik (OLAP) lebih tentang membangun pipeline yang andal dan berdampak rendah daripada sekadar “menyalin tabel.” Tujuannya sederhana: analitik mendapat apa yang dibutuhkan tanpa mempertaruhkan lalu lintas produksi.
ETL vs ELT (versi ringkas)
ETL (Extract, Transform, Load) berarti Anda membersihkan dan merombak data sebelum mendarat di warehouse. Berguna ketika warehouse mahal untuk dihitung, atau Anda ingin kontrol ketat atas apa yang disimpan.
ELT (Extract, Load, Transform) memuat data mentah lebih dulu, lalu mentransformasi di dalam warehouse. Ini sering lebih cepat disiapkan dan lebih mudah berkembang: Anda bisa menyimpan history sumber dan menyesuaikan transformasi saat kebutuhan berubah.
Aturan praktis: jika logika bisnis sering berubah, ELT mengurangi pekerjaan ulang; jika tata kelola mengharuskan hanya data terkurasi yang tersimpan, ETL mungkin lebih cocok.
Dasar CDC: menangkap perubahan tanpa kueri berat
Change Data Capture (CDC) men‑stream insert/update/delete dari OLTP (sering dari log database) ke sistem analitik. Daripada memindai tabel besar berulang‑ulang, CDC memungkinkan Anda memindahkan hanya yang berubah.
Yang dimungkinkan:
- Pelaporan near‑real‑time tanpa melakukan baca besar di produksi
- Replay dan backfill saat perlu membangun ulang tabel analitik
- Pelacakan history (siapa mengubah apa, dan kapan), jika Anda menyimpan event perubahan
Kesegaran data: real‑time vs near‑real‑time vs harian
Kesegaran adalah keputusan bisnis dengan biaya teknis.
- Real‑time (detik): terbaik untuk dashboard operasional, tetapi paling sulit dijaga stabil; gangguan kecil pipeline langsung terlihat.
- Near‑real‑time (menit): titik manis umum—keputusan cepat tanpa kompleksitas ekstrem.
- Batch harian: paling sederhana dan paling murah, cocok untuk pelaporan ala finance di mana “kemarin” cukup.
Tentukan SLA yang jelas (mis. “data tertinggal hingga 15 menit”) agar pemangku kepentingan tahu apa arti “segar.”
Pemeriksaan kualitas data yang mencegah kegagalan diam‑diam
Pipeline biasanya rusak secara diam—sampai seseorang menyadari angka meleset. Tambahkan pemeriksaan ringan untuk:
- Perubahan skema: kolom baru, penggantian nama field, atau perubahan tipe yang bisa membuat data kosong
- Event datang terlambat: pesanan atau pembayaran yang muncul jam kemudian; tangani dengan “lookback window”
- Deduplicasi: retry dan replay bisa menggandakan hitungan; gunakan ID stabil dan load idempotent
Pengaman ini menjaga kepercayaan OLAP sambil melindungi OLTP.
Kapan Berbagi Satu Database Dapat Diterima
Deploy di wilayah pilihan Anda
Pilih region AWS untuk hosting guna memenuhi kebutuhan residensi data.
Menjaga OLTP dan OLAP bersama tidak otomatis “salah.” Bisa menjadi pilihan sementara yang masuk akal ketika aplikasi kecil, kebutuhan pelaporan sempit, dan Anda bisa menegakkan batas keras sehingga analitik tidak mengejutkan pelanggan dengan checkout yang lambat, pembayaran gagal, atau timeout.
Situasi di mana itu bisa bekerja
Aplikasi kecil dengan analitik ringan dan batas kueri ketat sering baik‑baik saja pada satu database—terutama di awal. Kuncinya adalah jujur tentang apa arti “ringan”: beberapa dashboard, jumlah baris moderat, dan batas jelas pada runtime dan konkruensi kueri.
Untuk set laporan berulang yang sempit, materialized views atau tabel ringkasan dapat mengurangi biaya analitik. Alih‑alih memindai transaksi mentah, Anda pra‑hitung total harian, kategori teratas, atau rollup per pelanggan. Itu menjaga sebagian besar kueri pendek dan dapat diprediksi.
Jika pengguna bisnis bisa mentolerir angka yang tertunda, jendela pelaporan off‑peak membantu. Jadwalkan job berat di malam hari atau periode lalu lintas rendah, dan pertimbangkan role pelaporan terdedikasi dengan izin dan batas sumber daya yang lebih ketat.
Pengaman yang harus Anda tambahkan
- Tetapkan statement timeout dan batalkan kueri yang meleset.
- Batasi konkruensi untuk pengguna pelaporan.
- Pantau p95/p99 latency untuk transaksi inti terpisah dari pelaporan.
Tanda peringatan jelas bahwa sudah waktunya memisah
Jika Anda melihat peningkatan latensi transaksi, insiden berulang saat menjalankan laporan, kehabisan pool koneksi, atau cerita “satu kueri menjatuhkan produksi,” Anda sudah melewati zona aman. Pada titik itu, memisahkan database (atau setidaknya menggunakan read replica) berhenti menjadi optimasi dan menjadi kebersihan operasional dasar.
Checklist Migrasi Praktis: Dari Berbagi ke Terpisah
Memindahkan analitik dari database produksi bukan soal “rewrite besar” melainkan membuat pekerjaan terlihat, menetapkan target, dan migrasi bertahap yang terkontrol.
1) Inventarisasi apa yang benar‑benar terjadi sekarang
Mulai dengan bukti, bukan asumsi. Tarik daftar:
- Endpoint/kueri OLTP teratas berdasarkan frekuensi dan p95/p99 latency (checkout, login, create order, dll.)
- Laporan/dashboard OLAP teratas berdasarkan runtime, volume pemindaian, dan pentingnya bisnis
Sertakan analitik “tersembunyi”: SQL ad‑hoc dari alat BI, ekspor terjadwal, dan unduhan CSV.
2) Definisikan target: SLO OLTP dan kesegaran analitik
Tuliskan target yang akan Anda optimalkan untuknya:
- SLO OLTP: p95/p99 latency, tingkat error, dan peak throughput yang harus dipertahankan
- Kesegaran analitik: seberapa stale yang diterima (5 menit, 1 jam, besok), plus waktu untuk rebuild jika pipeline rusak
Ini mencegah perdebatan seperti “lambat” vs “baik” dan membantu memilih arsitektur yang tepat.
3) Pilih jalur pemisahan
Pilih opsi paling sederhana yang memenuhi target:
- Read replica: tercepat diadopsi untuk pelaporan baca‑berat, tapi bisa tertekan oleh kueri mahal dan lag replikasi
- Warehouse: paling tepat untuk pemindaian besar, banyak join, dan sejarah panjang; biasanya rumah yang tepat untuk BI
- CDC pipeline (ETL/ELT): terbaik saat Anda butuh analitik near‑real‑time tanpa menyentuh produksi
4) Lakukan rollout dengan aman (paralel dulu)
- Validasi definisi (zona waktu, refund, “active user,” dll.) agar angka cocok.
- Jalankan dashboard lama dan baru paralel selama satu siklus bisnis penuh.
- Cut over laporan per laporan, mulai dari kueri paling menyakitkan.
- Kunci akses langsung “pelaporan di produksi” setelah pemangku percaya pada sumber baru.
5) Tambahkan pengaman agar tidak kembali
Atur monitoring untuk replication lag/pipeline delay, runtime dashboard, dan pengeluaran warehouse. Tambahkan anggaran kueri (timeouts, batas konkruensi), dan siapkan playbook insiden: apa yang dilakukan saat kesegaran meleset, beban melonjak, atau metrik kunci menyimpang.
Catatan praktis jika Anda membangun aplikasi sendiri
Jika Anda masih awal dan bergerak cepat, risiko terbesar adalah tanpa sadar membangun analitik langsung ke jalur database yang sama dengan transaksi inti (mis. kueri dashboard yang diam‑diam menjadi “kritis produksi”). Salah satu cara menghindarinya adalah merancang pemisahan sejak awal—bahkan jika Anda mulai dengan read replica sederhana—dan memasukkannya ke checklist arsitektur.
Platform seperti Koder.ai dapat membantu karena Anda bisa mem‑prototype sisi OLTP (React app + Go services + PostgreSQL) dan merancang batas pelaporan/warehouse dalam mode perencanaan sebelum diluncurkan. Saat produk tumbuh, Anda bisa mengekspor kode sumber, mengembangkan skema, dan menambahkan komponen CDC/ELT tanpa menjadikan “pelaporan di produksi” kebiasaan permanen.