Apa yang Sebenarnya Dilakukan Pengindeksan Basis Data
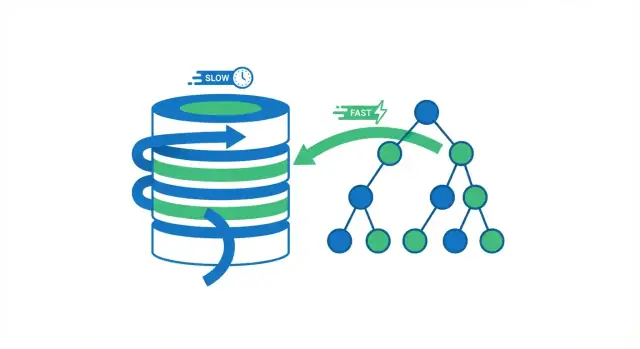
Indeks basis data adalah struktur lookup terpisah yang membantu database menemukan baris lebih cepat. Ini bukan salinan kedua dari tabel Anda. Pikirkan seperti halaman indeks di sebuah buku: Anda menggunakan indeks untuk melompat ke bagian yang tepat, lalu membaca halaman (baris) yang Anda butuhkan.
Tanpa indeks, database sering hanya punya satu opsi aman: membaca banyak baris untuk memeriksa mana yang cocok dengan kueri Anda. Itu mungkin baik ketika tabel memiliki beberapa ribu baris. Saat tabel tumbuh menjadi jutaan baris, “memeriksa lebih banyak baris” berubah menjadi lebih banyak pembacaan disk, lebih banyak tekanan memori, dan lebih banyak kerja CPU—sehingga kueri yang dulunya terasa instan mulai melambat.
Apa yang diubah indeks (dan apa yang tidak)
Indeks mengurangi jumlah data yang harus diperiksa database untuk menjawab pertanyaan seperti “cari order dengan ID 123” atau “ambil user dengan email ini.” Alih‑alih memindai semuanya, database mengikuti struktur ringkas yang mempersempit pencarian dengan cepat.
Tetapi pengindeksan bukan solusi universal. Beberapa kueri tetap perlu memproses banyak baris (laporan luas, filter berselektivitas rendah, agregasi berat). Dan indeks memiliki biaya nyata: penyimpanan ekstra dan tulis yang lebih lambat, karena INSERT dan UPDATE juga harus memperbarui indeks.
Apa yang akan Anda pelajari di panduan ini
Anda akan melihat:
- mengapa menghindari full table scan adalah kemenangan besar untuk kecepatan
- bagaimana struktur indeks umum (seperti B-tree) membuat lookup cepat
- kueri mana yang paling mendapat manfaat, dan kapan tidak
- cara memilih indeks komposit/penutup dan memvalidasinya dengan EXPLAIN plan
- cara memelihara indeks dari waktu ke waktu agar performa tidak menurun diam‑diam
Kemenangan Inti: Menghindari Full Table Scans
Saat database menjalankan kueri, ada dua opsi luas: memindai seluruh tabel baris demi baris, atau langsung melompat ke baris yang cocok. Sebagian besar keuntungan indexing berasal dari menghindari pembacaan yang tidak perlu.
Full table scan vs. index lookup
Sebuah full table scan persis seperti namanya: database membaca setiap baris, memeriksa apakah itu cocok dengan kondisi WHERE, dan baru kemudian mengembalikan hasil. Itu dapat diterima untuk tabel kecil, tetapi menjadi lebih lambat dengan cara yang dapat diprediksi saat tabel bertambah—lebih banyak baris berarti lebih banyak kerja.
Dengan indeks, database sering dapat menghindari membaca sebagian besar baris. Sebagai gantinya, ia berkonsultasi ke indeks terlebih dulu (struktur ringkas yang dibangun untuk pencarian) untuk menemukan di mana baris yang cocok berada, lalu membaca hanya baris‑baris itu.
Analogi sederhana
Bayangkan sebuah buku. Jika Anda ingin setiap halaman yang menyebutkan “fotosintesis,” Anda bisa membaca seluruh buku dari awal sampai akhir (full scan). Atau Anda bisa menggunakan indeks buku, melompat ke halaman yang tercantum, dan membaca hanya bagian‑bagian itu (index lookup). Pendekatan kedua lebih cepat karena Anda melewati hampir semua halaman.
Mengapa lebih sedikit pembacaan biasanya berarti kueri lebih cepat
Database banyak menghabiskan waktu menunggu pembacaan—terutama ketika data belum ada di memori. Mengurangi jumlah baris (dan halaman) yang harus disentuh biasanya mengurangi:
- pembacaan disk/SSD
- waktu CPU yang dihabiskan untuk mengevaluasi filter
- tekanan memori dari memasukkan data yang tidak perlu ke cache
Kapan kemenangan kecepatan muncul
Pengindeksan paling membantu ketika data besar dan pola kueri bersifat selektif (misalnya, mengambil 20 baris yang cocok dari 10 juta). Jika kueri Anda mengembalikan sebagian besar baris juga, atau tabel cukup kecil untuk muat nyaman di memori, full scan mungkin sama cepatnya—atau bahkan lebih cepat.
Bagaimana Struktur Indeks Membuat Lookup Cepat
Indeks bekerja karena mereka mengorganisir nilai sehingga database dapat melompat mendekati apa yang Anda inginkan daripada memeriksa setiap baris.
Indeks B-tree: andalan default
Struktur indeks yang paling umum di database SQL adalah B-tree (sering ditulis “B-tree” atau “B+tree”). Secara konseptual:
- nilai disimpan tersortir
- indeks dibagi menjadi halaman (potongan) yang menunjuk ke halaman lain, dan akhirnya ke baris tabel yang cocok
Karena tersortir, B-tree bagus untuk lookup kesetaraan (WHERE email = ...) dan kueri rentang (WHERE created_at >= ... AND created_at < ...). Database dapat menavigasi ke lingkungan nilai yang tepat lalu memindai maju secara berurutan.
Apa arti “logaritmik” (tanpa matematika)
Orang mengatakan lookup B-tree bersifat “logaritmik.” Praktisnya, itu berarti: saat tabel Anda tumbuh dari ribuan ke jutaan baris, jumlah langkah untuk menemukan nilai bertambah perlahan, bukan sebanding. Alih‑alih “dua kali data berarti dua kali kerja,” lebih seperti “jauh lebih banyak data hanya berarti beberapa langkah navigasi ekstra,” karena database mengikuti pointer melalui beberapa level kecil di tree.
Indeks hash: cepat untuk pencocokan tepat (dengan batasan)
Beberapa engine juga menawarkan indeks hash. Ini bisa sangat cepat untuk pemeriksaan kesetaraan karena nilai diubah menjadi hash dan digunakan untuk menemukan entri secara langsung.
Pertukarannya: indeks hash biasanya tidak membantu untuk rentang atau pemindaian terurut, dan ketersediaan/perilaku bervariasi antar database.
Detail engine berbeda, idenya tetap sama
PostgreSQL, MySQL/InnoDB, SQL Server, dan lainnya menyimpan serta menggunakan indeks secara berbeda (ukuran halaman, clustering, kolom yang disertakan, pengecekan visibilitas). Tetapi konsep intinya sama: indeks membuat struktur ringkas dan dapat dinavigasi yang membiarkan database menemukan baris yang cocok dengan jauh lebih sedikit kerja dibandingkan memindai seluruh tabel.
Kueri yang Paling Diuntungkan oleh Indeks
Indeks tidak mempercepat “SQL” secara umum—mereka mempercepat pola akses tertentu. Ketika indeks cocok dengan bagaimana kueri Anda memfilter, meng‑join, atau mengurutkan, database dapat melompat langsung ke baris relevan alih‑alih membaca seluruh tabel.
Pola kueri yang paling ramah indeks
1) Filter WHERE (khususnya pada kolom yang selektif)
Jika kueri Anda sering menyaring tabel besar menjadi sejumlah kecil baris, indeks biasanya menjadi tempat pertama untuk melihat. Contoh klasik adalah mencari user berdasarkan identifier.
Tanpa indeks pada users.email, database mungkin harus memindai setiap baris:
SELECT * FROM users WHERE email = '[email protected]';
Dengan indeks pada email, ia dapat menemukan baris yang cocok dengan cepat dan berhenti.
2) Kunci JOIN (foreign key dan kolom yang direferensikan)
Join adalah tempat “ketidakefisienan kecil” berubah menjadi biaya besar. Jika Anda join orders.user_id ke users.id, mengindeks kolom join (biasanya orders.user_id dan primary key users.id) membantu database mencocokkan baris tanpa memindai berulang‑ulang.
3) ORDER BY (ketika Anda ingin hasil sudah terurut)
Sorting mahal ketika database harus mengumpulkan banyak baris lalu mengurutkannya. Jika Anda sering menjalankan:
SELECT * FROM orders WHERE user_id = 42 ORDER BY created_at DESC;
indeks yang selaras dengan user_id dan kolom sort dapat membuat engine membaca baris dalam urutan yang dibutuhkan daripada melakukan sort pada hasil perantara yang besar.
4) GROUP BY (ketika pengelompokan sejajar dengan indeks)
Pengelompokan dapat diuntungkan ketika database dapat membaca data dalam urutan tergrup. Bukan jaminan, tetapi jika Anda sering mengelompokkan pada kolom yang juga dipakai untuk penyaringan (atau secara alami terklaster dalam indeks), engine mungkin melakukan lebih sedikit pekerjaan.
Filter rentang: kemenangan B-tree yang umum
Indeks B-tree sangat baik untuk kondisi rentang—pikirkan tanggal, harga, dan kueri “antara”:
SELECT * FROM orders
WHERE created_at >= '2025-01-01' AND created_at < '2025-02-01';
Untuk dashboard, laporan, dan layar “aktivitas terbaru”, pola ini ada di mana‑mana, dan indeks pada kolom rentang sering menghasilkan peningkatan instan.
Tema sederhana: indeks membantu paling ketika mereka mencerminkan bagaimana Anda mencari dan menyortir. Jika kueri Anda sejajar dengan pola akses itu, database dapat melakukan pembacaan terarah alih‑alih pemindaian luas.
Selektivitas: Mengapa Beberapa Indeks Tidak Membantu
Indeks paling membantu ketika secara tajam mempersempit berapa banyak baris yang harus disentuh database. Properti ini disebut selektivitas.
Apa arti "selektivitas" dalam praktik
Selektivitas pada dasarnya: berapa banyak baris yang cocok untuk sebuah nilai? Kolom yang sangat selektif memiliki banyak nilai berbeda, sehingga setiap lookup cocok hanya sedikit baris.
- Selektivitas tinggi:
email, user_id, order_number (sering unik atau hampir unik)
- Selektivitas rendah:
is_active, is_deleted, status dengan beberapa nilai umum
Dengan selektivitas tinggi, indeks dapat melompat langsung ke set baris kecil. Dengan selektivitas rendah, indeks menunjuk ke bagian besar tabel—sehingga database masih harus membaca dan menyaring banyak data.
Mengapa indeks boolean (dan sejenisnya) mengecewakan
Pertimbangkan tabel dengan 10 juta baris dan kolom is_deleted di mana 98% bernilai false. Indeks pada is_deleted tidak banyak menghemat untuk:
SELECT * FROM orders WHERE is_deleted = false;
Set kecocokan masih hampir seluruh tabel. Menggunakan indeks malah bisa lebih lambat daripada sequential scan karena engine melakukan kerja ekstra meloncat antara entri indeks dan halaman tabel.
Mengapa database bisa mengabaikan indeks Anda
Perencana kueri memperkirakan biaya. Jika indeks tidak mengurangi kerja cukup—karena terlalu banyak baris yang cocok, atau karena kueri juga butuh sebagian besar kolom—mereka dapat memilih full table scan.
Selektivitas berubah seiring waktu
Distribusi data tidak tetap. Kolom status mungkin awalnya terdistribusi merata, lalu bergeser sehingga satu nilai mendominasi. Jika statistik tidak diperbarui, perencana bisa membuat keputusan buruk, dan indeks yang dulu membantu mungkin berhenti memberikan keuntungan.
Indeks Komposit dan Penutup (Dan Urutan Kolom)
Indeks satu kolom adalah awal yang baik, tetapi banyak kueri nyata memfilter pada satu kolom dan menyortir atau memfilter pada kolom lain. Di sinilah indeks komposit (multi‑kolom) unggul: satu indeks dapat melayani beberapa bagian kueri.
Urutan kolom: aturan “kiri‑ke‑kanan"
Sebagian besar database (terutama dengan indeks B-tree) hanya dapat menggunakan indeks komposit secara efisien dari kolom paling kiri ke depan. Pikirkan indeks sebagai tersortir pertama berdasarkan kolom A, lalu di dalamnya berdasarkan kolom B, dan seterusnya.
Itu berarti:
- indeks (account_id, created_at) bagus untuk kueri yang memfilter
account_id lalu menyortir atau memfilter created_at
- indeks yang sama biasanya tidak membantu untuk kueri yang hanya memfilter
created_at (karena bukan kolom paling kiri)
Pola praktis: timeline per‑akun
Beban kerja umum adalah “tampilkan event terbaru untuk akun ini.” Pola kueri ini:
SELECT id, created_at, type
FROM events
WHERE account_id = ?
ORDER BY created_at DESC
LIMIT 50;
sering mendapat manfaat besar dari:
CREATE INDEX events_account_created_at
ON events (account_id, created_at);
Database dapat langsung menuju bagian indeks untuk satu akun dan membaca baris dalam urutan waktu, alih‑alih memindai dan mengurutkan set yang besar.
Indeks penutup: ketika indeks adalah jawabannya
Sebuah indeks penutup berisi semua kolom yang dibutuhkan kueri, sehingga database dapat mengembalikan hasil dari indeks tanpa melihat baris tabel (lebih sedikit pembacaan, lebih sedikit I/O acak).
Hati‑hati: menambah kolom ekstra bisa membuat indeks besar dan mahal.
Jangan buat komposit lebar “untuk berjaga‑jaga”
Indeks komposit lebar dapat memperlambat penulisan dan mengonsumsi banyak penyimpanan. Tambahkan hanya untuk kueri bernilai tinggi tertentu, dan verifikasi dengan EXPLAIN dan pengukuran nyata sebelum dan sesudah.
Tradeoff: Perlambatan Tulis dan Penyimpanan Ekstra
Indeks sering digambarkan sebagai “kecepatan gratis,” tetapi sebenarnya tidak gratis. Struktur indeks harus dipelihara setiap kali tabel dasar berubah, dan mereka mengonsumsi sumber daya nyata.
INSERT/UPDATE/DELETE lebih lambat (karena setiap indeks harus diperbarui)
Saat Anda INSERT baris baru, database tidak hanya menulis baris itu sekali—ia juga memasukkan entri yang sesuai ke setiap indeks pada tabel itu. Hal yang sama berlaku untuk DELETE, dan banyak UPDATE.
Itulah mengapa “lebih banyak indeks” bisa memperlambat beban kerja tulis secara nyata. UPDATE yang menyentuh kolom terindeks bisa sangat mahal: database mungkin harus menghapus entri indeks lama dan menambah yang baru (dan di beberapa engine ini bisa memicu page split atau rebalancing internal). Jika aplikasi Anda melakukan banyak tulis—event order, data sensor, log audit—mengindeks semuanya dapat membuat database terasa lambat meskipun baca cepat.
Penyimpanan ekstra dan tekanan memori
Setiap indeks membutuhkan ruang disk. Pada tabel besar, indeks bisa menyaingi (atau melebihi) ukuran tabel, terutama jika Anda punya banyak indeks yang tumpang tindih.
Ini juga memengaruhi memori. Database sangat bergantung pada caching; jika working set Anda mencakup beberapa indeks besar, cache harus menampung lebih banyak halaman agar tetap cepat. Jika tidak, Anda akan melihat lebih banyak I/O disk dan performa yang kurang dapat diprediksi.
Keseimbangan praktis
Pengindeksan adalah soal memilih apa yang dipercepat. Jika beban kerja Anda banyak baca, lebih banyak indeks mungkin sepadan. Jika banyak tulis, prioritaskan indeks yang mendukung kueri paling penting Anda dan hindari duplikasi. Aturan berguna: tambahkan indeks hanya ketika Anda bisa menyebutkan kueri yang dibantu—dan verifikasi bahwa kenaikan kecepatan baca mengimbangi biaya tulis dan pemeliharaan.
Cara Membuktikan Indeks Membantu: EXPLAIN dan Pengukuran
Menambahkan indeks terasa seperti harusnya membantu—tetapi Anda bisa (dan harus) memverifikasinya. Dua alat yang membuat ini konkret adalah rencana kueri (EXPLAIN) dan pengukuran nyata sebelum/sesudah.
Baca rencana: apakah indeks benar‑benar dipakai?
Jalankan EXPLAIN (atau EXPLAIN ANALYZE) pada kueri persis yang Anda pedulikan.
- Tipe scan: Seq Scan / Full Table Scan berarti database membaca seluruh tabel. Index Scan / Index Seek (atau Index Range Scan) menunjukkan indeks dipakai untuk mempersempit baris.
- Perkiraan vs. aktual baris (khususnya di
EXPLAIN ANALYZE): Jika rencana memperkirakan 100 baris tetapi sebenarnya menyentuh 100.000, optimizer membuat tebakan buruk—sering karena statistik usang atau filter kurang selektif dari dugaan.
- Langkah sort: Jika Anda melihat operasi Sort eksplisit, database mengurutkan hasil setelah mengambilnya. Jika indeks baru cocok dengan
ORDER BY, sort itu mungkin hilang—yang bisa menjadi kenaikan besar.
Ukur dengan benar: sebelum/sesudah, kondisi sama
Benchmark kueri dengan parameter yang sama, pada volume data representatif, dan tangkap baik latensi maupun baris yang diproses.
Berhati‑hatilah dengan caching: run pertama mungkin lebih lambat karena data belum di memori; run berulang mungkin terlihat “tetap cepat” bahkan tanpa indeks. Untuk menghindari penilaian palsu, bandingkan beberapa run dan fokus pada apakah rencana berubah (indeks dipakai, lebih sedikit baris dibaca) selain waktu mentah.
Jika EXPLAIN ANALYZE menunjukkan lebih sedikit baris disentuh dan lebih sedikit langkah mahal (seperti sort), Anda telah membuktikan indeks membantu—bukan hanya berharap begitu.
Kesalahan Umum yang Membatalkan Manfaat Indeks
Anda bisa menambahkan indeks yang "tepat" dan tetap tidak melihat peningkatan jika kueri ditulis sedemikian rupa sehingga mencegah database menggunakannya. Masalah ini sering halus, karena kueri tetap mengembalikan hasil yang benar—hanya dijalankan dengan rencana lebih lambat.
Anti‑pola yang menghalangi penggunaan indeks
1) Wildcard di awal
Saat Anda menulis:
WHERE name LIKE '%term'
database tidak bisa menggunakan B-tree normal untuk melompat ke titik awal yang benar, karena tidak tahu di mana dalam urutan tersortir “%term” dimulai. Seringkali ini kembali ke pemindaian banyak baris.
Alternatif:
- Jika memungkinkan, gunakan pencarian prefix:
WHERE name LIKE 'term%'.
- Jika benar‑benar membutuhkan pencarian “contains”, pertimbangkan tipe indeks khusus (mis. full‑text/trigram) daripada mengandalkan indeks standar.
2) Fungsi pada kolom terindeks
Ini terlihat sepele:
WHERE LOWER(email) = '[email protected]'
Tetapi LOWER(email) mengubah ekspresi, sehingga indeks pada email tidak bisa dipakai langsung.
Alternatif:
- Simpan data ternormalisasi (mis. email sudah lowercase) dan kueri
WHERE email = ....
- Atau buat indeks ekpresi/function‑based (bergantung database) khusus untuk
LOWER(email).
Pemblokir indeks tersembunyi yang sering terlewat
Cast tipe implisit: Membandingkan tipe berbeda dapat memaksa database melakukan cast pada satu sisi, yang dapat menonaktifkan indeks. Contoh: membandingkan kolom integer dengan literal string.
Collation/encoding yang tidak cocok: Jika perbandingan menggunakan collation berbeda dari yang dipakai saat indeks dibuat (umum pada teks lintas lokal), optimizer mungkin menghindari indeks.
Checklist cepat: "Kenapa indeks saya tidak dipakai?"
- Apakah kondisi dimulai dengan wildcard (
LIKE '%x')?
- Apakah Anda menerapkan fungsi pada kolom terindeks (
LOWER(col), DATE(col), CAST(col)) ?
- Apakah tipe identik di kedua sisi (tanpa cast implisit)?
- Apakah collation/locale konsisten untuk perbandingan?
- Apakah predikat cukup selektif (tidak mencocokkan sebagian besar tabel)?
- Apakah Anda memfilter/menyortir pada kolom paling kiri dari indeks komposit?
- Sudahkah Anda memeriksa rencana dengan
EXPLAIN untuk memastikan apa yang dipilih database?
Pemeliharaan Indeks: Statistik, Bloat, dan Kesehatan Jangka Panjang
Indeks bukanlah “atur lalu lupa”. Seiring waktu, data berubah, pola kueri bergeser, dan bentuk fisik tabel serta indeks melenceng. Indeks yang dipilih dengan baik bisa perlahan menjadi kurang efektif—atau bahkan merugikan—jika tidak Anda pelihara.
Statistik: peta perencana bisa usang
Kebanyakan database mengandalkan query planner (optimizer) untuk memilih bagaimana menjalankan kueri: indeks mana yang digunakan, urutan join, dan apakah lookup indeks sepadan. Untuk membuat keputusan itu, planner menggunakan statistik—ringkasan mengenai distribusi nilai, jumlah baris, dan skew data.
Saat statistik usang, perkiraan baris planner bisa sangat meleset. Itu mengarah ke pilihan rencana yang buruk, seperti memilih indeks yang mengembalikan jauh lebih banyak baris daripada perkiraan, atau melewatkan indeks yang seharusnya lebih cepat.
Perbaikan rutin: jadwalkan pembaruan statistik secara berkala (sering disebut “ANALYZE” atau nama serupa). Setelah load data besar, delete besar, atau churn signifikan, segarkan statistik lebih cepat.
Bloat dan fragmentasi: saat struktur menjadi berantakan
Saat baris disisipkan, diubah, dan dihapus, indeks bisa mengumpulkan bloat (halaman ekstra yang tidak lagi berisi data berguna) dan fragmentasi (data tersebar sehingga meningkatkan I/O). Hasilnya adalah indeks lebih besar, lebih banyak pembacaan, dan pemindaian lebih lambat—terutama untuk kueri rentang.
Perbaikan rutin: secara periodik rebuild atau reorganize indeks yang sering digunakan ketika mereka tumbuh tidak proporsional atau performa melorot. Alat dan dampaknya berbeda per database, jadi lakukan ini sebagai operasi terukur, bukan aturan baku.
Pantau dari waktu ke waktu, bukan sekali saja
Siapkan pemantauan untuk:
- kueri lambat (latensi, frekuensi, dan pelanggar terburuk)
- penggunaan indeks (indeks yang tidak pernah dipakai vs. yang "hot")
- pertumbuhan ukuran indeks dan perubahan rencana yang tiba‑tiba
Loop umpan balik itu membantu Anda menangkap kapan pemeliharaan diperlukan—dan kapan sebuah indeks harus disesuaikan atau dihapus. Untuk lebih lanjut tentang memvalidasi perbaikan, lihat /blog/how-to-prove-an-index-helps-explain-and-measurements.
Alur Kerja Praktis untuk Menambahkan Indeks yang Tepat
Menambahkan indeks harus menjadi perubahan yang disengaja, bukan tebakan. Alur kerja ringan menjaga fokus pada kemenangan yang terukur dan mencegah “index sprawl.”
1) Identifikasi kueri bermasalah sejati
Mulailah dengan bukti: log kueri lambat, trace APM, atau laporan pengguna. Pilih satu kueri yang lambat dan sering—laporan langka 10 detik kurang penting daripada lookup umum 200 ms.
Tangkap SQL tepat dan pola parameter (mis. WHERE user_id = ? AND status = ? ORDER BY created_at DESC LIMIT 50). Perbedaan kecil mengubah indeks yang dibutuhkan.
2) Ukur baseline
Catat latensi saat ini (p50/p95), baris yang dipindai, dan dampak CPU/I/O. Simpan output rencana saat ini (mis. EXPLAIN / EXPLAIN ANALYZE) untuk perbandingan nanti.
3) Rancang indeks paling kecil yang berguna
Pilih kolom yang sesuai dengan bagaimana kueri memfilter dan menyortir. Pilih indeks minimal yang membuat rencana berhenti memindai rentang besar.
Uji di staging dengan volume data mirip produksi. Indeks bisa terlihat bagus pada dataset kecil dan mengecewakan pada skala.
4) Buat dengan aman
Pada tabel besar, gunakan opsi online bila didukung (mis. PostgreSQL CREATE INDEX CONCURRENTLY). Jadwalkan perubahan saat traffic lebih rendah jika database bisa mengunci write.
5) Validasi dengan bukti sebelum/sesudah
Jalankan ulang kueri yang sama dan bandingkan:
- bentuk rencana (apakah berubah dari full scan ke index access?)
- waktu eksekusi dan baris yang dipindai
- dampak pada tulis (latensi insert/update)
6) Siapkan rollback
Jika indeks menambah biaya tulis atau memblow up memori, hapus dengan bersih (mis. DROP INDEX CONCURRENTLY bila tersedia). Buat migrasi dapat dibalik.
7) Dokumentasikan “mengapa”
Di migrasi atau catatan skema, tulis kueri mana yang dilayani indeks dan metrik apa yang membaik. Anda (atau rekan) di masa depan akan tahu mengapa indeks itu ada dan kapan aman untuk menghapusnya.
Di mana Koder.ai masuk dalam alur ini
Jika Anda membangun layanan baru dan ingin menghindari “index sprawl” sejak awal, Koder.ai dapat membantu mengiterasi lebih cepat pada loop penuh di atas: menghasilkan aplikasi React + Go + PostgreSQL dari chat, menyesuaikan skema/migrasi indeks saat kebutuhan berubah, lalu mengekspor kode sumber saat Anda siap mengambil alih. Dalam praktiknya, itu mempermudah proses dari “endpoint ini lambat” menjadi “berikut EXPLAIN plan, indeks minimal, dan migrasi yang dapat dibalik” tanpa menunggu pipeline tradisional penuh.
Saat Pengindeksan Tidak Cukup (Dan Apa yang Dilakukan Selanjutnya)
Indeks adalah tuas besar, tetapi bukan tombol ajaib “jadikan cepat”. Kadang bagian lambat suatu permintaan terjadi setelah database menemukan baris yang benar—atau pola kueri membuat pengindeksan menjadi langkah yang kurang tepat.
Kasus ketika indeks bukan perbaikan utama
Jika kueri Anda sudah memakai indeks yang baik namun masih terasa lambat, cari penyebab umum ini:
- Pagination yang hilang atau salah: Mengambil halaman 1.000 dengan
OFFSET 999000 bisa lambat bahkan dengan indeks. Gunakan keyset pagination (mis. “beri saya baris setelah id/timestamp terakhir yang dilihat”).
- Mengembalikan terlalu banyak data: Memilih baris lebar (
SELECT *) atau mengembalikan puluhan ribu record dapat menjadi bottleneck pada jaringan, serialisasi JSON, atau pemrosesan aplikasi.
- Ketidaksesuaian skema: Join berlebihan karena normalisasi berlebihan, menyimpan nilai pencarian dalam JSON/text blob, atau penggunaan tipe data yang salah dapat memaksa operasi mahal yang tidak sepenuhnya bisa ditutupi indeks.
Optimisasi pelengkap yang sering lebih penting
- Tulis ulang kueri: Hapus join yang tidak perlu, hindari fungsi pada kolom terindeks di WHERE, dan sederhanakan predikat OR‑berat.
- Batasi kolom dan baris: Pilih hanya yang Anda butuhkan, tambahkan
LIMIT yang masuk akal, dan paginasi hasil secara terarah.
- Caching: Cache pembacaan panas di lapisan aplikasi atau gunakan cache read‑through untuk kueri mahal yang sering diulang.
- Partisi: Jika sebagian besar kueri mengenai “data terbaru,” partisi berdasarkan waktu (atau boundary alami lain) untuk memperkecil ruang pencarian.
Jika Anda ingin metode diagnosis bottleneck yang lebih mendalam, padukan ini dengan alur kerja di /blog/how-to-prove-an-index-helps.
Prioritaskan: perbaiki bottleneck terbesar dulu
Jangan menebak. Ukur di mana waktu habis (eksekusi database vs. baris yang dikembalikan vs. kode aplikasi). Jika database cepat tetapi API lambat, menambah indeks tidak akan membantu.
Checklist cepat