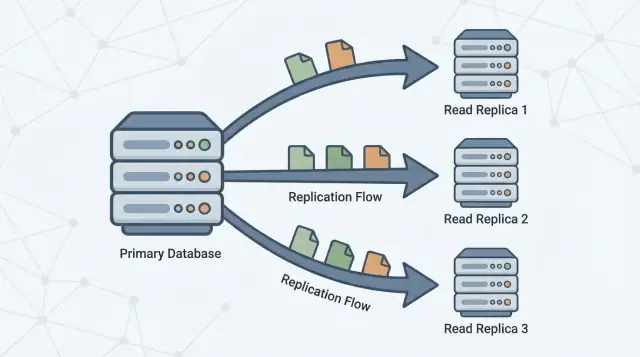
Apa Itu Read Replica (dan Apa yang Bukan)
Sebuah read replica adalah salinan dari database utama Anda (sering disebut primary) yang tetap terbarui dengan terus menerima perubahan darinya. Aplikasi Anda dapat mengirim kueri hanya-baca (seperti SELECT) ke replica, sementara primary tetap menangani semua penulisan (seperti INSERT, UPDATE, dan DELETE).
Janji dasar
Janjinya sederhana: kapasitas baca lebih besar tanpa menambah tekanan pada primary.
Jika aplikasi Anda memiliki banyak lalu lintas “ambil” — beranda, halaman produk, profil pengguna, dashboard — memindahkan beberapa baca itu ke satu atau lebih replica dapat membebaskan primary untuk fokus pada pekerjaan tulis dan baca kritis. Dalam banyak pengaturan, ini bisa dilakukan dengan perubahan aplikasi minimal: Anda mempertahankan satu database sebagai sumber kebenaran dan menambahkan replica sebagai tempat tambahan untuk menanyakan data.
Apa yang bukan read replica
Read replica berguna, tapi bukan tombol ajaib performa. Mereka tidak:
- Meningkatkan kapasitas tulis. Semua penulisan tetap mendarat di primary.
- Memperbaiki kueri lambat. Jika sebuah kueri tidak efisien (index hilang, pemindaian tabel besar, pola join buruk), kemungkinan besar juga akan lambat di replica—hanya saja lambatnya terasa di tempat lain.
- Menggantikan desain skema dan data yang baik. Replica tidak menyelesaikan hot spot, baris terlalu besar, atau tabel “segala hal” yang membengkak.
- Menghilangkan kebutuhan monitoring. Replica menambah bagian bergerak: lag, batas koneksi, dan perilaku failover.
Menetapkan ekspektasi untuk sisa panduan
Anggap replica sebagai alat skala-baca dengan kompromi. Sisa artikel ini menjelaskan kapan mereka benar-benar membantu, cara umum mereka membuat masalah, dan bagaimana konsep seperti replication lag dan konsistensi eventual memengaruhi apa yang dilihat pengguna ketika Anda mulai membaca dari salinan daripada primary.
Mengapa Read Replica Ada
Satu server database primary sering kali terasa “cukup besar” saat awal. Ia menangani tulis (insert, update, delete) dan juga menjawab setiap permintaan baca (SELECT) dari aplikasi Anda, dashboard, dan alat internal.
Saat penggunaan tumbuh, biasanya baca berkembang lebih cepat daripada tulis: setiap tampilan halaman bisa memicu beberapa kueri, layar pencarian bisa menyebar ke banyak lookup, dan kueri bergaya analitik dapat memindai banyak baris. Bahkan jika volume tulis sedang, primary masih bisa menjadi bottleneck karena harus melakukan dua pekerjaan sekaligus: menerima perubahan dengan aman dan cepat, dan melayani tumpukan lalu lintas baca yang berkembang dengan latensi rendah.
Memisahkan baca dari tulis
Read replica ada untuk memecah beban itu. Primary tetap fokus memproses tulis dan mempertahankan “sumber kebenaran,” sementara satu atau lebih replica menangani kueri hanya-baca. Ketika aplikasi Anda bisa merutekan beberapa kueri ke replica, Anda mengurangi tekanan CPU, memori, dan I/O pada primary. Itu biasanya meningkatkan responsivitas keseluruhan dan memberi ruang lebih untuk lonjakan tulis.
Replikasi dalam satu kalimat
Replikasi adalah mekanisme yang menjaga replica tetap terbarui dengan menyalin perubahan dari primary ke server lain. Primary mencatat perubahan, dan replica menerapkan perubahan itu sehingga mereka bisa menjawab kueri menggunakan data yang hampir sama.
Polanya umum di banyak sistem database dan layanan terkelola (mis. PostgreSQL, MySQL, dan varian yang di-host di cloud). Implementasinya berbeda-beda, tapi tujuannya sama: menambah kapasitas baca tanpa memaksa primary untuk terus naik skala vertikal.
Bagaimana Replikasi Bekerja (Model Mental Sederhana)
Bayangkan database primary sebagai “sumber kebenaran.” Ia menerima setiap tulis—membuat pesanan, memperbarui profil, mencatat pembayaran—dan memberi perubahan itu urutan yang pasti.
Satu atau lebih read replica lalu mengikuti primary, menyalin perubahan tersebut agar bisa menjawab kueri baca (seperti “tampilkan riwayat pesanan saya”) tanpa menambah beban pada primary.
Alur dasar
- Primary menerima tulis dan mencatatnya dalam log yang tahan lama (nama tepatnya berbeda menurut database).
- Replica men-stream atau mengambil entri log tersebut dari primary.
- Replica memutar ulang perubahan yang sama dengan urutan yang sama, perlahan-lahan mengejar ketertinggalan.
Baca bisa dilayani dari replica, tetapi tulis tetap ke primary.
Replikasi sinkron vs asinkron (tingkat tinggi)
Replikasi bisa terjadi dalam dua mode besar:
- Sinkron: primary menunggu konfirmasi dari replica (atau quorum) bahwa perubahan diterima sebelum tulis dianggap “committed.” Ini mengurangi pembacaan kadaluarsa, tapi bisa menambah latensi tulis dan membuat tulis sensitif terhadap masalah replica/jaringan.
- Asinkron: primary meng-commit tulis segera, dan replica mengejar kemudian. Ini menjaga tulis cepat dan tahan banting, tapi replica bisa sementara tertinggal.
Replication lag dan “konsistensi eventual”
Delay itu—replica yang tertinggal dari primary—disebut replication lag. Ini bukan otomatis kegagalan; sering kali ini adalah kompromi normal yang Anda terima untuk menskalakan baca.
Bagi pengguna akhir, lag muncul sebagai konsistensi eventual: setelah Anda mengubah sesuatu, sistem akan menjadi konsisten di seluruh tempat, tapi tidak harus instan.
Contoh: Anda memperbarui alamat email dan menyegarkan halaman profil. Jika halaman disajikan dari replica yang tertinggal beberapa detik, Anda mungkin sebentar melihat email lama—sampai replica menerapkan pembaruan dan “mengejar.”
Kapan Read Replica Benar-benar Membantu
Read replica membantu ketika database primary sehat untuk menulis tetapi kewalahan melayani lalu lintas baca. Mereka paling efektif ketika Anda bisa memindahkan sebagian besar beban SELECT tanpa mengubah cara Anda menulis data.
Tanda-tanda Anda dibatasi oleh baca (bukan tulis)
Perhatikan pola seperti:
- CPU primary tinggi saat puncak trafik, sementara throughput tulis tidak luar biasa tinggi
- Rasio
SELECT yang sangat tinggi dibandingkan INSERT/UPDATE/DELETE
- Kueri baca melambat saat puncak meskipun tulis tetap stabil
- Saturasi pool koneksi yang didorong oleh endpoint berat baca (halaman produk, feed, hasil pencarian)
Cara memastikan baca memang masalah (metrik yang harus dicek)
Sebelum menambah replica, validasi dengan beberapa sinyal konkret:
- CPU vs I/O: Apakah CPU primary penuh saat latensi baca naik? Atau apakah I/O disk menjadi bottleneck?
- Campuran kueri: Persentase waktu yang dihabiskan pada pernyataan
SELECT (dari slow query log/APM Anda).
- p95/p99 latensi baca: Lacak endpoint baca dan latensi kueri database secara terpisah.
- Tingkat hit buffer/cache: Hit rate rendah bisa berarti baca memaksa akses disk.
- Top kueri menurut total waktu: Satu kueri mahal bisa mendominasi “beban baca.”
Jangan lewatkan perbaikan yang lebih murah
Sering kali, langkah pertama terbaik adalah tuning: tambahkan index yang tepat, tulis ulang satu kueri, kurangi panggilan N+1, atau cache pembacaan yang panas. Perubahan ini bisa lebih cepat dan lebih murah daripada menjalankan replica.
Daftar cepat: replica vs tuning
Pilih replica jika:
- Sebagian besar beban adalah trafik baca, dan baca sudah cukup dioptimalkan
- Anda dapat mentolerir sesekali baca kadaluarsa untuk kueri yang dipindahkan
- Anda butuh kapasitas tambahan dengan cepat tanpa perubahan skema/kueri yang berisiko
Pilih tuning dulu jika:
- Beberapa kueri mendominasi total waktu
- Index hilang atau join tidak efisien jelas terlihat
- Baca lambat bahkan pada trafik rendah (tanda masalah desain kueri)
Kasus Penggunaan yang Cocok
Read replica paling berharga ketika primary sibuk menangani tulis (checkout, pendaftaran, pembaruan), tetapi sebagian besar trafik adalah baca. Dalam arsitektur primary–replica, memindahkan kueri yang tepat ke replica meningkatkan kinerja database tanpa mengubah fitur aplikasi.
1) Dashboard dan analitik yang tidak boleh memperlambat transaksi
Dashboard sering menjalankan kueri panjang: pengelompokan, filter rentang tanggal besar, atau join multi-tabel. Kueri itu bisa bersaing dengan pekerjaan transaksional untuk CPU, memori, dan cache.
Read replica cocok untuk:
- Beban kerja pelaporan internal
- Dashboard admin
- Tampilan metrik harian/mingguan
Anda menjaga primary fokus pada transaksi cepat dan terprediksi sementara baca analitik dapat diskalakan secara independen.
2) Halaman pencarian dan penelusuran dengan volume baca tinggi
Penelusuran katalog, profil pengguna, dan feed konten dapat menghasilkan volume kueri baca serupa yang tinggi. Ketika tekanan skala baca menjadi bottleneck, replica dapat menyerap trafik dan mengurangi lonjakan latensi.
Ini sangat efektif ketika baca sering melewati cache (banyak kueri unik) atau ketika Anda tidak bisa hanya mengandalkan cache aplikasi.
3) Job latar belakang yang memindai banyak data
Ekspor, backfill, recompute summary, dan job “temukan setiap record yang cocok X” dapat mengganggu primary. Menjalankan pemindaian ini pada replica sering lebih aman.
Pastikan saja job toleran terhadap konsistensi eventual: dengan lag replikasi, job mungkin tidak melihat pembaruan terbaru.
4) Baca multi-wilayah untuk latensi lebih rendah (dengan catatan ketinggalan)
Jika Anda melayani pengguna global, menempatkan replica lebih dekat kepada mereka dapat mengurangi round-trip time. Komprominya adalah lebih besar paparan terhadap baca kadaluarsa saat lag atau masalah jaringan, jadi ini terbaik untuk halaman di mana “hampir up-to-date” dapat diterima (penelusuran, rekomendasi, konten publik).
Saat Replica Bisa Berbalik Buruk
Tentukan Mana yang Harus Selalu Terbaru
Peta layar yang 'harus terkini' vs pembacaan replika yang aman dengan Mode Perencanaan Koder.ai.
Read replica hebat ketika “cukup dekat” sudah memadai. Mereka berisiko ketika produk Anda diam-diam menganggap setiap baca mencerminkan tulis terbaru.
Gejala klasik: “Saya baru saja memperbaruinya, kenapa tidak berubah?”
Pengguna mengedit profil, mengirim formulir, atau mengubah pengaturan—dan muat ulang berikutnya diambil dari replica yang tertinggal beberapa detik. Pembaruan berhasil, tapi pengguna melihat data lama dan mengulang, mengirim dua kali, atau kehilangan kepercayaan.
Ini sangat menyakitkan di alur di mana pengguna mengharapkan konfirmasi segera: mengubah email, mengubah preferensi, mengunggah dokumen, atau memposting komentar lalu diarahkan kembali.
Layar yang harus selalu mutakhir (jangan berjudi di sini)
Beberapa baca tidak boleh ketinggalan, bahkan sebentar:
- Keranjang belanja dan total checkout
- Saldo dompet, poin loyalitas, hitungan inventori
- Layar "Apakah pembayaran saya berhasil?"
Jika replica tertinggal, Anda bisa menampilkan total yang salah, menjual stok berlebih, atau menampilkan saldo lama. Meski sistem nanti memperbaiki, pengalaman pengguna (dan volume dukungan) terganggu.
Alat admin dan operasi butuh kebenaran paling mutakhir
Dashboard internal sering memandu keputusan nyata: review fraud, dukungan pelanggan, pemenuhan pesanan, moderasi, dan respons insiden. Jika alat admin membaca dari replica, Anda berisiko bertindak atas data yang belum lengkap—mis. mengembalikan uang untuk pesanan yang sudah dikembalikan sebelumnya, atau melewatkan perubahan status terbaru.
Perbaikan praktis: rute “read-your-writes” ke primary
Pola umum adalah routing kondisional:
- Setelah pengguna menulis, kirim baca konfirmasi mereka ke primary untuk jangka waktu singkat (detik sampai menit).
- Pertahankan baca latar belakang, anonim, atau non-kritis di replica.
Ini mempertahankan manfaat replica tanpa membuat konsistensi menjadi tebakan.
Memahami Replication Lag dan Baca Kadaluarsa
Replication lag adalah jeda antara saat tulis dikomit di primary dan saat perubahan yang sama terlihat di read replica. Jika aplikasi Anda membaca dari replica selama jeda itu, hasilnya bisa “kadaluarsa” — data yang benar beberapa saat lalu, tapi tidak lagi.
Mengapa lag terjadi
Lag normal dan biasanya bertambah saat beban naik. Penyebab umum:
- Lonjakan beban pada primary: banyak tulis berarti lebih banyak perubahan untuk dikirim dan diterapkan.
- Replica kekurangan daya atau sibuk: replica tidak bisa menerapkan perubahan secepat datangnya (CPU, disk I/O).
- Latensi atau jitter jaringan: penundaan dalam memindahkan stream replikasi.
- Transaksi besar / pembaruan massal: satu perubahan besar butuh waktu untuk diserialisasi, dipindahkan, dan diputar ulang.
Bagaimana baca kadaluarsa muncul di perilaku produk
Lag tidak hanya memengaruhi “kebaruan”—ia memengaruhi kebenaran dari perspektif pengguna:
- Pengguna memperbarui profil, lalu menyegarkan dan melihat nilai lama.
- Lencana “pesan belum dibaca” atau notifikasi bergeser karena hitungan dihitung dari baris yang sedikit usang.
- Layar admin/pelaporan melewatkan pesanan, pengembalian, atau perubahan status terbaru.
Cara praktis menanganinya
Mulai dengan memutuskan apa yang dapat ditoleransi fitur Anda:
- Tambahkan jendela toleransi: “Data mungkin hingga 30 detik tertinggal” diterima untuk banyak dashboard.
- Rutekan read-after-write ke primary: setelah pengguna mengubah sesuatu, baca entitas itu dari primary untuk periode singkat.
- Pesan UI: atur ekspektasi (“Memperbarui…”, “Mungkin butuh beberapa detik untuk muncul”).
- Logika retry: jika baca kritis tidak menemukan record yang baru ditulis, retry terhadap primary atau ulang setelah jeda singkat.
Apa yang harus dipantau dan di-alert
Lacak lag replica (waktu/bytes di belakang), laju apply replica, error replikasi, dan CPU/disk I/O replica. Alert saat lag melebihi toleransi Anda (mis. 5s, 30s, 2m) dan saat lag terus meningkat dari waktu ke waktu (tanda replica tidak akan mengejar tanpa intervensi).
Skala Baca vs Skala Tulis (Kompromi Utama)
Pisahkan Pelaporan dari Transaksi
Bangun layar pelaporan internal tanpa mencampurkan pembacaan berat ke jalur tulis yang kritis.
Read replica adalah alat untuk skala baca: menambah tempat untuk melayani kueri SELECT. Mereka bukan alat untuk skala tulis: meningkatkan jumlah INSERT/UPDATE/DELETE yang bisa diterima sistem Anda.
Skala baca: apa yang bagus dari replica
Saat Anda menambah replica, Anda menambah kapasitas baca. Jika aplikasi Anda dibatasi oleh endpoint baca (halaman produk, feed, lookup), Anda dapat menyebarkan kueri-ke-kueri itu ke beberapa mesin.
Ini sering memperbaiki:
- Latensi kueri di bawah beban (lebih sedikit kontensi di primary)
- Throughput untuk baca (lebih banyak CPU/memori/I/O untuk
SELECT)
- Isolasi untuk baca berat, seperti beban pelaporan, sehingga tidak mengganggu trafik transaksional
Skala tulis: apa yang tidak dilakukan replica
Salah kaprah umum adalah “lebih banyak replica = lebih banyak throughput tulis.” Dalam setup primary-replica tipikal, semua tulis tetap ke primary. Bahkan, lebih banyak replica bisa sedikit menambah kerja untuk primary, karena harus menghasilkan dan mengirim data replikasi ke setiap replica.
Jika masalah Anda throughput tulis, replica tidak akan memperbaikinya. Anda biasanya melihat pendekatan lain (tuning kueri/index, batching, partisi/sharding, atau merubah model data).
Batas koneksi dan pooling: bottleneck tersembunyi
Walaupun replica memberi Anda CPU baca lebih banyak, Anda masih bisa mencapai batas koneksi terlebih dahulu. Setiap node database punya jumlah koneksi konkuren maksimum, dan menambah replica bisa menggandakan tempat aplikasi bisa terkoneksi—tanpa mengurangi total permintaan.
Aturan praktis: gunakan connection pooling (atau pooler) dan jaga jumlah koneksi per-layanan agar sengaja. Kalau tidak, replica bisa menjadi “lebih banyak database untuk dibebani.”
Trade-off biaya: kapasitas tidak gratis
Replica menambah biaya nyata:
- Lebih banyak node (pengeluaran compute)
- Lebih banyak storage (setiap replica menyimpan salinan penuh)
- Lebih banyak upaya operasi (monitoring lag, strategi backup/restore, perubahan skema, respons insiden)
Trade-offnya sederhana: replica dapat membeli headroom baca dan isolasi, tapi menambah kompleksitas dan tidak menaikkan batas tulis.
Ketersediaan Tinggi dan Failover: Apa yang Bisa Dilakukan Replica
Read replica bisa meningkatkan ketersediaan baca: jika primary kelebihan beban atau sementara tidak tersedia, Anda mungkin masih bisa melayani beberapa trafik baca dari replica. Itu dapat menjaga halaman yang terlihat pelanggan tetap responsif (untuk konten yang mentolerir sedikit kadaluarsa) dan mengurangi radius dampak insiden primary.
Apa yang replica tidak sediakan adalah rencana ketersediaan penuh sendirian. Replica biasanya tidak siap menerima tulis secara otomatis, dan “salinan yang dapat dibaca ada” berbeda dengan “sistem dapat dengan aman dan cepat menerima tulis lagi.”
Failover biasanya berarti: deteksi kegagalan primary → pilih replica → promosikan menjadi primary baru → arahkan tulis (dan biasanya baca) ke node yang dipromosikan.
Beberapa database terkelola mengotomatiskan sebagian besar ini, tapi intinya tetap: Anda mengubah siapa yang boleh menerima tulis.
Risiko kunci yang harus direncanakan
- Data replica yang kadaluarsa: replica mungkin tertinggal. Jika Anda mempromosikannya, Anda mungkin kehilangan tulis terbaru yang belum sempat tereplikasi.
- Pencegahan split-brain: Anda harus mencegah dua node menerima tulis bersamaan. Karena itu promosi biasanya digarisbawahi oleh otoritas tunggal (control plane terkelola, sistem quorum, atau prosedur operasional ketat).
- Routing dan cache: aplikasi Anda butuh cara andal untuk berpindah target—connection string, DNS, proxy, atau router database. Pastikan trafik tulis tidak “sengaja” tetap ke primary lama.
Uji seperti fitur
Perlakukan failover sebagai sesuatu yang Anda latih. Jalankan game-day test di staging (dan hati-hati di produksi pada jendela risiko rendah): simulasi kehilangan primary, ukur waktu-pulih, verifikasi routing, dan pastikan aplikasi menangani periode read-only dan reconnect dengan rapi.
Pola Routing Praktis (Pemecahan Baca/Tulis)
Read replica hanya membantu jika trafik Anda benar-benar menuju ke mereka. “Read/write splitting” adalah sekumpulan aturan yang mengirim tulis ke primary dan baca yang eligible ke replica—tanpa merusak kebenaran.
Pola 1: Pisahkan di aplikasi
Pendekatan paling sederhana adalah routing eksplisit dalam lapisan akses data Anda:
- Semua tulis (
INSERT/UPDATE/DELETE, perubahan skema) pergi ke primary.
- Hanya baca yang dipilih yang boleh memakai replica.
Ini mudah dipahami dan mudah dibatalkan. Di sini Anda juga bisa mengkodekan aturan bisnis seperti “setelah checkout, selalu baca status order dari primary untuk sementara.”
Pola 2: Pisahkan lewat proxy atau driver
Beberapa tim lebih suka proxy database atau driver pintar yang mengerti endpoint “primary vs replica” dan merutekan berdasarkan tipe kueri atau pengaturan koneksi. Ini mengurangi perubahan kode aplikasi, tapi hati-hati: proxy tidak selalu tahu mana baca yang “aman” dari perspektif produk.
Memilih kueri mana yang aman ke replica
Kandidat yang baik:
- Analitik, beban pelaporan, dashboard
- Halaman pencarian/penelusuran di mana sedikit kadaluarsa bisa diterima
- Job latar yang melakukan retry dan tak butuh nilai terbaru
Hindari merutekan baca yang segera mengikuti tulis pengguna (mis. “update profile → reload profile”) kecuali Anda punya strategi konsistensi.
Transaksi dan konsistensi sesi
Dalam sebuah transaksi, lakukan semua baca pada primary.
Di luar transaksi, pertimbangkan sesi “read-your-writes”: setelah tulis, pin user/sesi ke primary untuk TTL singkat, atau rute kueri tindak lanjut tertentu ke primary.
Mulai kecil dan ukur
Tambahkan satu replica, rute sekumpulan endpoint/kueri terbatas, dan bandingkan sebelum/setelah:
- CPU primary dan read IOPS
- Pemanfaatan replica
- Tingkat error dan persentil latensi
- Insiden terkait baca kadaluarsa
Perluas routing hanya jika dampaknya jelas dan aman.
Monitoring dan Operasi Dasar
Dapatkan Kredit untuk Pengiriman
Bagikan apa yang Anda bangun dengan Koder.ai dan dapatkan kredit melalui program konten.
Read replica bukanlah “pasang lalu lupa.” Mereka adalah server database tambahan dengan batas performa, mode kegagalan, dan tugas operasional sendiri. Disiplin monitoring kecil biasanya membedakan antara “replica membantu” dan “replica menambah kebingungan.”
Apa yang harus dipantau (metrik sedikit tapi penting)
Fokus pada indikator yang menjelaskan gejala yang terlihat pengguna:
- Lag replica: seberapa jauh di belakang primary replica tersebut (detik, byte, atau posisi WAL/LSN tergantung database). Ini peringatan dini untuk baca kadaluarsa.
- Error replikasi: koneksi putus, auth gagal, disk penuh, atau masalah replication slot. Anggap ini insiden, bukan “noise.”
- Latensi kueri (p50/p95) pada replica vs primary: replica bisa lambat meski primary baik (kondisi cache berbeda, hardware berbeda, laporan panjang).
- Tingkat hit cache: replica yang terus-menerus miss cache mungkin menunjukkan latensi lebih tinggi setelah restart atau pergeseran trafik.
Perencanaan kapasitas: butuh berapa replica?
Mulai dengan satu replica jika tujuan Anda adalah mengurangi beban baca. Tambah lebih banyak saat Anda punya constraint yang jelas:
- Throughput baca: satu replica tidak cukup untuk puncak QPS atau kueri analitik berat.
- Isolasi: dedikasikan replica untuk beban pelaporan agar dashboard tidak mencuri sumber daya dari trafik pengguna.
- Geografi: satu replica per region bisa memangkas latensi baca, tapi menambah overhead operasional.
Aturan praktis: skala replica hanya setelah Anda memastikan baca adalah bottleneck (bukan index, kueri lambat, atau caching aplikasi).
Tugas operasional umum
- Backup: putuskan dari node mana backup diambil. Mengambil backup dari replica bisa mengurangi beban primary, tapi verifikasi persyaratan konsistensi dan kesehatan replica.
- Perubahan skema: uji migrasi dengan replikasi dalam pikiran (DDL yang berjalan lama bisa menambah lag). Koordinasikan rollout sehingga app dan perubahan skema kompatibel selama propagasi.
- Jendela pemeliharaan: patch atau restart replica sementara mengurangi kapasitas baca. Rencanakan rotasi agar Anda tidak turun di bawah headroom baca yang diperlukan.
Checklist troubleshooting: “replica lambat”
- Cek replica lag: jika tinggi, pengguna mungkin melakukan retry atau melihat data kadaluarsa.
- Bandingkan slow query logs di replica vs primary: kueri pelaporan sering muncul di sini.
- Verifikasi CPU, memory, disk I/O, dan jaringan pada host replica.
- Cari kontensi lock atau transaksi yang lama di primary yang menunda replikasi.
- Pastikan routing baca Anda tidak membebani satu replica saja (load balancing tidak merata).
- Validasi index ada di replica (harus mencerminkan primary) dan statistik up-to-date.
Alternatif dan Kerangka Keputusan Sederhana
Read replica adalah salah satu alat untuk skala baca, tapi jarang menjadi tuas pertama. Sebelum menambah kompleksitas operasional, periksa apakah perbaikan yang lebih sederhana memberi hasil yang sama.
Alternatif yang layak dicoba dulu
Caching bisa menghilangkan kelas baca dari database Anda. Untuk halaman yang “sebagian besar dibaca” (detail produk, profil publik, konfigurasi), cache aplikasi atau CDN dapat mengurangi beban secara drastis—tanpa memperkenalkan lag replikasi.
Index dan optimisasi kueri seringkali mengungguli replica untuk kasus umum: beberapa kueri mahal yang menghabiskan CPU. Menambahkan index yang tepat, mengurangi kolom SELECT, menghindari N+1, dan memperbaiki join yang buruk dapat mengubah “kita butuh replica” menjadi “kita hanya butuh rencana yang lebih baik.”
Materialized views / pre-aggregation membantu ketika beban memang berat (analitik, dashboard). Alih-alih menjalankan kueri kompleks berulang, simpan hasil terhitung dan refresh sesuai jadwal.
Kapan mempertimbangkan sharding/partisi
Jika tulis adalah bottleneck (hot rows, lock contention, batas IOPS tulis), replica tidak akan banyak membantu. Saat itulah partisi tabel berdasarkan waktu/tenant, atau sharding berdasarkan ID pelanggan, dapat menyebarkan beban tulis dan mengurangi kontensi. Ini langkah arsitektural lebih besar, tapi menangani constraint yang sebenarnya.
Kerangka keputusan sederhana
Tanyakan empat hal:
- Apa tujuannya? Kurangi latensi baca, offload beban pelaporan, atau tingkatkan ketersediaan?
- Seberapa segar harus datanya? Jika Anda tidak bisa mentolerir baca kadaluarsa, replica bisa menimbulkan masalah.
- Berapa anggarannya? Replica menambah biaya infrastruktur dan operasi berkelanjutan.
- Berapa banyak kompleksitas yang bisa ditanggung? Read/write splitting, menangani konsistensi eventual, dan pengujian failover bukan hal sepele.
Jika Anda membuat prototipe produk atau menyalakan layanan cepat, membantu untuk memasukkan batasan ini ke arsitektur sejak awal. Misalnya, tim yang membangun di Koder.ai (platform vibe-coding yang menghasilkan aplikasi React dengan backend Go + PostgreSQL dari antarmuka chat) sering mulai dengan satu primary untuk kesederhanaan, lalu naik kelas ke replica segera setelah dashboard, feed, atau pelaporan internal mulai bersaing dengan trafik transaksional. Menggunakan alur kerja yang berbasis perencanaan membuat lebih mudah memutuskan endpoint mana yang bisa mentolerir konsistensi eventual dan mana yang harus “read-your-writes” dari primary.
Jika Anda ingin bantuan memilih jalur, lihat /pricing untuk opsi, atau telusuri panduan terkait di /blog.