03 Apr 2025·8 menit
Mengelola State di Frontend dan Backend dalam Aplikasi AI
Pelajari bagaimana UI, sesi, dan state data bergerak antara frontend dan backend dalam aplikasi AI, dengan pola praktis untuk sinkronisasi, persistensi, caching, dan keamanan.
Apa arti “state” dalam aplikasi berbasis AI
“State” adalah segala sesuatu yang perlu diingat aplikasi Anda agar berperilaku dengan benar dari satu momen ke momen berikutnya.
Jika pengguna menekan Kirim di UI chat, aplikasi tidak boleh melupakan apa yang mereka ketik, apa yang sudah dibalas oleh asisten, apakah permintaan masih berjalan, atau pengaturan apa (tone, model, tools) yang aktif. Semua itu adalah state.
State, dengan kata sederhana
Cara yang berguna untuk memikirkan state adalah: kebenaran saat ini dari aplikasi—nilai-nilai yang memengaruhi apa yang dilihat pengguna dan apa yang akan dilakukan sistem selanjutnya. Itu mencakup hal-hal yang jelas seperti input formulir, tetapi juga fakta “tak nampak” seperti:
- Percakapan mana yang sedang aktif
- Apakah respons terakhir sedang di-stream atau sudah selesai
- Daftar pesan dan urutannya
- Pemanggilan tools dan hasilnya (hasil pencarian, lookup database, ekstrak file)
- Error, retry, dan backoff rate-limit
Mengapa aplikasi AI memiliki lebih banyak bagian bergerak
Aplikasi tradisional seringkali membaca data, menampilkannya, dan menyimpan pembaruan. Aplikasi AI menambahkan langkah ekstra dan keluaran antara:
- Satu aksi pengguna bisa memicu beberapa operasi backend (panggilan LLM, pemanggilan tool, panggilan LLM lainnya).
- Respons bisa datang secara bertahap (token yang di-stream), sehingga UI harus mengelola state parsial.
- Konteks penting: sistem mungkin perlu mempertahankan memori percakapan, keluaran tool, dan pengaturan model yang konsisten antar permintaan.
Pergerakan ekstra ini adalah alasan mengapa manajemen state sering menjadi kompleks tersembunyi dalam aplikasi AI.
Apa yang akan dibahas panduan ini
Di bagian-bagian berikut, kita akan membagi state menjadi kategori praktis (UI state, session state, data yang dipersist, dan model/runtime state), dan menunjukan di mana masing-masing sebaiknya berada (frontend vs backend). Kami juga akan membahas sinkronisasi, caching, pekerjaan jangka panjang, pembaruan streaming, dan keamanan—karena state hanya berguna jika benar dan terlindungi.
Contoh skenario singkat
Bayangkan aplikasi chat di mana pengguna bertanya: “Ringkas invoice bulan lalu dan tandai yang tidak biasa.” Backend mungkin (1) mengambil invoice, (2) menjalankan tool analisis, (3) melakukan stream ringkasan ke UI, dan (4) menyimpan laporan akhir.
Agar terasa mulus, aplikasi harus melacak pesan, hasil tool, progres, dan output yang disimpan—tanpa mencampur percakapan atau membocorkan data antar pengguna.
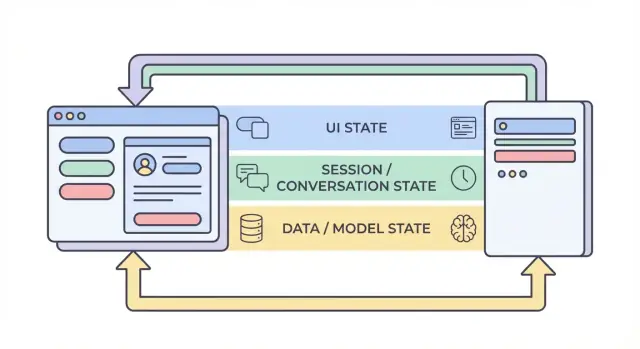
Empat lapisan state: UI, session, data, dan model
Ketika orang mengatakan “state” dalam aplikasi AI, mereka sering mencampurkan hal-hal yang sangat berbeda. Membagi state menjadi empat lapisan—UI, session, data, dan model/runtime—membuat lebih mudah memutuskan di mana sesuatu harus berada, siapa yang bisa mengubahnya, dan bagaimana menyimpannya.
1) UI state (apa yang dilakukan pengguna saat ini)
UI state adalah state hidup, momen-ke-momen di browser atau aplikasi mobile: input teks, toggle, item terpilih, tab yang terbuka, dan apakah sebuah tombol dinonaktifkan.
Aplikasi AI menambah beberapa detail spesifik UI:
- Indikator pemuatan dan status “berpikir”
- Token yang di-stream (teks parsial yang muncul saat dihasilkan)
- Draft pesan lokal (sebelum dikirim)
UI state harus mudah direset dan aman untuk hilang. Jika pengguna me-refresh halaman, Anda mungkin kehilangan ini—dan itu biasanya bisa diterima.
2) Session / conversation state (konteks bersama untuk alur pengguna)
Session state mengikat pengguna ke interaksi yang sedang berlangsung: identitas pengguna, ID percakapan, dan tampilan konsisten dari riwayat pesan.
Dalam aplikasi AI, ini sering mencakup:
- Riwayat pesan (atau referensinya)
- Jejak tool (tools/fungsi yang dipanggil dan dengan hasil apa)
- Pilihan “working set” seperti proyek/dokumen saat ini, model yang dipilih, atau workspace
Lapisan ini sering melintasi frontend dan backend: frontend memegang identifier ringan, sementara backend adalah otoritas untuk kontinuitas session dan kontrol akses.
3) Data state (catatan tahan lama di storage)
Data state adalah apa yang Anda simpan secara sengaja di database: proyek, dokumen, embedding, preferensi, log audit, event penagihan, dan transkrip percakapan yang disimpan.
Berbeda dengan UI dan session state, data state harus:
- Tahan lama (bertahan saat restart)
- Dapat di-query (bisa dicari/disaring)
- Dapat diaudit (Anda bisa memahami apa yang terjadi kemudian)
4) Model / runtime state (bagaimana AI dikonfigurasi sekarang)
Model/runtime state adalah pengaturan operasional yang digunakan untuk menghasilkan jawaban: system prompts, tools yang diaktifkan, temperature/max tokens, pengaturan keamanan, rate limits, dan cache sementara.
Sebagian adalah konfigurasi (default stabil); sebagian ephemeral (cache jangka pendek atau budget token per-permintaan). Sebagian besar layak ditempatkan di backend agar bisa dikontrol konsisten dan tidak terekspos tanpa perlu.
Mengapa pemisahan mengurangi bug
Saat lapisan-lapisan ini kabur, Anda mendapatkan kegagalan klasik: UI menunjukkan teks yang belum disimpan, backend memakai pengaturan prompt berbeda dari yang diharapkan frontend, atau memori percakapan “bocor” antar pengguna. Batas yang jelas menciptakan sumber kebenaran yang lebih jelas—dan membuatnya terlihat apa yang harus dipersist, apa yang bisa dihitung ulang, dan apa yang harus dilindungi.
Apa yang hidup di frontend vs backend (dan kenapa)
Cara yang andal untuk mengurangi bug di aplikasi AI adalah memutuskan, untuk setiap potongan state, di mana ia harus berada: di browser (frontend), di server (backend), atau keduanya. Pilihan ini memengaruhi reliabilitas, keamanan, dan seberapa “mengejutkan” aplikasi saat pengguna merefresh, membuka tab baru, atau kehilangan koneksi.
Frontend state: cepat, sementara, dan digerakkan pengguna
Frontend state terbaik untuk hal yang berubah cepat dan tidak perlu bertahan setelah refresh. Menjaganya lokal membuat UI responsif dan menghindari panggilan API yang tidak perlu.
Contoh yang umum hanya di frontend:
- Teks draft pesan yang sedang diketik pengguna
- Filter lokal dan urutan sort pada tabel
- Modal terbuka/tertutup, tab yang dipilih, hover state
Jika Anda kehilangan state ini saat refresh, biasanya dapat diterima (dan sering diharapkan).
Backend state: otoritatif, sensitif, dan dibagi
Backend state harus memegang apa saja yang harus dipercayai, diaudit, atau ditegakkan konsistensinya. Ini termasuk state yang perlu dilihat perangkat/tab lain, atau yang harus tetap benar meskipun client dimodifikasi.
Contoh yang umum hanya di backend:
- Izin dan peran (apa yang boleh dilakukan pengguna)
- Status penagihan/langganan dan batas penggunaan
- Pekerjaan jangka panjang (pengindeksan dokumen, ekspor besar, fine-tune) dan statusnya
Sikap yang baik: jika state yang salah bisa menyebabkan biaya, bocornya data, atau rusaknya kontrol akses, itu milik backend.
Shared state: dikoordinasikan, tapi dengan satu sumber kebenaran
Beberapa state secara alami dibagi:
- Judul percakapan
- Sumber pengetahuan yang dipilih untuk chat
- Field profil pengguna yang dipakai di berbagai perangkat
Meski dibagi, pilih satu “sumber kebenaran.” Biasanya backend bersifat otoritatif dan frontend hanya cache salinan untuk kecepatan.
Aturan praktis (dan anti-pola umum)
Letakkan state sedekat mungkin dengan tempat dibutuhkannya, tapi persist apa yang harus bertahan lewat refresh, ganti perangkat, atau gangguan.
Hindari anti-pola menyimpan state sensitif atau otoritatif hanya di browser (mis. flag isAdmin di sisi client, tier plan, atau status penyelesaian job sebagai kebenaran). UI boleh menampilkannya, tapi backend harus memverifikasi.
Siklus hidup permintaan AI tipikal: dari klik hingga selesai
Satu fitur AI terasa seperti “satu aksi,” tetapi sebenarnya adalah rangkaian transisi state yang dibagi antara browser dan server. Memahami lifecycle membuat lebih mudah menghindari UI yang tidak cocok, konteks hilang, dan tagihan ganda.
1) Aksi pengguna → frontend menyiapkan intent
Pengguna menekan Kirim. UI segera memperbarui state lokal: bisa menambah bubble pesan “pending”, menonaktifkan tombol kirim, dan menangkap input saat ini (teks, attachment, tools yang dipilih).
Pada titik ini frontend harus menghasilkan atau melampirkan identifier korelasi:
- conversation_id: thread mana ini terkait
- message_id: ID klien untuk pesan pengguna baru
- request_id: unik per percobaan (berguna untuk retry)
ID ini memungkinkan kedua sisi berbicara tentang event yang sama bahkan ketika respons datang terlambat atau dua kali.
2) Panggilan API → server memvalidasi dan mempersist
Frontend mengirim request API dengan pesan pengguna plus ID-ID tersebut. Server memvalidasi izin, rate limit, dan bentuk payload, lalu mempersist pesan pengguna (atau setidaknya catatan log immutable) yang dikunci oleh conversation_id dan message_id.
Langkah persistensi ini mencegah “riwayat hantu” saat pengguna merefresh di tengah permintaan.
3) Server merekonstruksi konteks
Untuk memanggil model, server membangun ulang konteks dari sumber kebenarannya:
- Ambil pesan terbaru untuk conversation_id
- Tarik catatan terkait (dokumen, preferensi, output tool)
- Terapkan kebijakan percakapan (system prompts, aturan memori, pemotongan)
Ide kuncinya: jangan bergantung pada client untuk menyediakan riwayat penuh. Client bisa ketinggalan.
4) Eksekusi model/tool → state antara
Server mungkin memanggil tool (pencarian, lookup database) sebelum atau selama generasi model. Setiap pemanggilan tool menghasilkan state antara yang harus dilacak terhadap request_id supaya bisa diaudit dan di-retry dengan aman.
5) Respons (streaming atau tidak) → penyelesaian UI
Dengan streaming, server mengirim token/evet parsial. UI secara bertahap memperbarui pesan asisten yang pending, tetapi tetap memperlakukannya sebagai “sedang berjalan” sampai event final menandai penyelesaian.
6) Titik gagal yang harus diantisipasi
Retry, submit ganda, dan respons keluar urutan memang terjadi. Gunakan request_id untuk deduplikasi di server, dan message_id untuk rekonsiliasi di UI (abaikan potongan terlambat yang tidak cocok dengan request aktif). Selalu tunjukkan status “gagal” yang jelas dengan retry aman yang tidak membuat pesan duplikat.
Sesi dan memori percakapan: menjaga konteks tanpa kekacauan
Ubah arsitektur jadi kode
Jelaskan model state Anda dan biarkan Koder.ai menghasilkan kerangka untuk React, Go, dan PostgreSQL.
Sesi adalah “benang” yang mengikat aksi pengguna bersama: workspace yang sedang dipakai, pencarian terakhir, draft yang sedang diedit, dan percakapan yang harus dilanjutkan oleh AI. State session yang baik membuat aplikasi terasa kontinu antar halaman—dan idealnya antar perangkat—tanpa mengubah backend Anda menjadi tempat pembuangan semua yang pernah dikatakan pengguna.
Tujuan session state
Bertujuan pada: (1) kontinuitas (pengguna bisa pergi dan kembali), (2) kebenaran (AI menggunakan konteks yang tepat untuk percakapan yang tepat), dan (3) kontainment (satu session tidak boleh bocor ke session lain). Jika Anda mendukung banyak perangkat, perlakukan session sebagai scope pengguna plus scope perangkat: “akun sama” tidak selalu berarti “jendela kerja yang sama”.
Cookie vs token vs server session
Anda biasanya memilih salah satu cara untuk mengidentifikasi session:
- Cookies: paling sederhana untuk web app karena browser mengirimkannya otomatis. Bagus untuk session tradisional, tapi Anda harus men-set flag secure (
HttpOnly,Secure,SameSite) dan menangani CSRF. - Tokens (mis. JWT): cocok untuk API dan aplikasi mobile karena client dapat melampirkannya secara eksplisit. Skalanya baik, tetapi revocation dan rotasi memerlukan desain tambahan (dan Anda tidak boleh menyimpan state sensitif di dalam token).
- Server sessions: server menyimpan data session (sering di Redis), dan client hanya memegang session ID opak. Paling mudah untuk dicabut dan diperbarui, tapi Anda harus menjalankan dan menskalakan penyimpanan session.
Strategi memori percakapan
“Memori” hanyalah state yang Anda pilih untuk dikirim kembali ke model.
- Riwayat penuh: paling akurat, tapi mahal dan bisa memunculkan konten sensitif lama.
- Riwayat yang diringkas: simpan ringkasan berjalan plus beberapa giliran terakhir; lebih murah dan biasanya cukup.
- Konteks jendela: hanya N pesan terakhir; paling sederhana, tapi bisa kehilangan keputusan penting sebelumnya.
Polanya yang praktis adalah ringkasan + jendela: dapat diprediksi dan membantu menghindari perilaku model yang mengejutkan.
Pemanggilan tool: dapat diulang dan dapat diaudit
Jika AI menggunakan tools (pencarian, query DB, baca file), simpan setiap pemanggilan tool dengan: input, timestamp, versi tool, dan output yang dikembalikan (atau referensi ke output). Ini memungkinkan Anda menjelaskan “mengapa AI mengatakan itu,” memutar ulang run untuk debugging, dan mendeteksi saat hasil berubah karena tool atau dataset berubah.
Pembatasan privasi
Jangan menyimpan memori jangka panjang secara default. Simpan hanya yang diperlukan untuk kontinuitas (conversation ID, ringkasan, log tool), tetapkan batas retensi, dan hindari menyimpan teks pengguna mentah kecuali ada alasan produk yang jelas dan persetujuan pengguna.
Menyinkronkan state dengan aman: sumber kebenaran dan penanganan konflik
State menjadi berisiko ketika “hal” yang sama bisa diedit di lebih dari satu tempat—UI Anda, tab browser kedua, atau pekerjaan latar yang memperbarui percakapan. Perbaikannya lebih sedikit soal kode pintar dan lebih kepada kepemilikan yang jelas.
Tentukan sumber kebenaran
Putuskan sistem mana yang otoritatif untuk tiap potongan state. Dalam sebagian besar aplikasi AI, backend harus memiliki catatan kanonik untuk semua yang harus benar: pengaturan percakapan, izin tool, riwayat pesan, batas penagihan, dan status job. Frontend dapat cache dan menurunkan state untuk kecepatan (tab terpilih, teks prompt draft, indikator “sedang mengetik”), tetapi harus menganggap backend benar ketika ada mismatch.
Aturan praktis: kalau Anda akan marah kehilangan itu saat refresh, kemungkinan besar itu milik backend.
Optimistic UI updates (gunakan dengan hati-hati)
Optimistic updates membuat aplikasi terasa instan: toggle pengaturan, perbarui UI segera, lalu konfirmasi dengan server. Ini cocok untuk aksi berisiko rendah dan bisa dibalik (mis. memberi bintang pada percakapan).
Ini menyebabkan kebingungan saat server mungkin menolak atau mengubah perubahan (cek izin, batas kuota, validasi, atau default sisi server). Dalam kasus tersebut, tampilkan status “saving…” dan perbarui UI setelah konfirmasi.
Menangani konflik (dua tab, satu percakapan)
Konflik terjadi saat dua client memperbarui record yang sama berdasarkan versi awal berbeda. Contoh umum: Tab A dan Tab B sama-sama mengubah temperature model.
Gunakan versioning ringan sehingga backend bisa mendeteksi write usang:
updated_attimestamps (sederhana, mudah dibaca manusia)- ETags / header
If-Match(native HTTP) - Nomor revisi yang meningkat (deteksi konflik eksplisit)
Jika versi tidak cocok, kembalikan respons konflik (sering HTTP 409) dan kirim kembali objek server terbaru.
Rancang API untuk mengurangi mismatch
Setelah setiap write, buat API mengembalikan objek yang disimpan sebagaimana dipersist (termasuk default yang dibuat server, field yang dinormalisasi, dan versi baru). Ini memungkinkan frontend mengganti cache-nya segera—satu update sumber-kebenaran daripada menebak apa yang berubah.
Caching dan performa: mempercepat tanpa state usang
Caching adalah salah satu cara tercepat membuat aplikasi AI terasa instan, tetapi juga menciptakan salinan state kedua. Jika Anda meng-cache hal yang salah—atau di tempat yang salah—Anda akan mengirim UI yang terasa cepat tapi membingungkan.
Apa yang dicache di client
Cache sisi klien harus fokus pada pengalaman, bukan otoritas. Kandidat bagus meliputi preview percakapan terbaru (judul, snippet pesan terakhir), preferensi UI (tema, model terpilih, status sidebar), dan state UI optimis (pesan yang “mengirim”).
Jaga cache klien kecil dan dapat dibuang: jika dihapus, aplikasi harus tetap bekerja dengan mem-fetch ulang dari server.
Apa yang dicache di server
Cache server harus fokus pada pekerjaan yang mahal atau sering diulang:
- Hasil tool yang aman dipakai ulang (mis. lookup cuaca untuk kota yang sama dalam 5 menit)
- Lookup embedding dan hasil pencarian vektor untuk query berulang (sering dengan TTL pendek)
- State rate-limit dan penghitung throttling (untuk melindungi API dan biaya)
Ini juga tempat Anda bisa cache state turunan seperti hitungan token, keputusan moderasi, atau output parsing dokumen—apa pun yang deterministik dan mahal.
Dasar-dasar invalidasi cache (tanpa terlalu rumit)
Tiga aturan praktis:
- Gunakan kunci cache yang jelas yang meng-encode input (
user_id, model, parameter tool, versi dokumen). - Tetapkan TTL berdasarkan seberapa cepat data dasar berubah. TTL pendek lebih baik daripada logika rumit.
- Lewati cache saat kebenaran lebih penting daripada kecepatan: setelah pengguna memperbarui dokumen, mengubah izin, atau meminta refresh.
Jika Anda tidak bisa menjelaskan kapan entri cache menjadi salah, jangan cache.
Jangan cache secret atau data personal di cache bersama
Hindari menaruh API key, token auth, prompt mentah yang berisi teks sensitif, atau konten spesifik pengguna ke layer bersama seperti CDN cache. Jika harus meng-cache data pengguna, isolasi per pengguna dan enkripsi saat disimpan—atau simpan di database utama.
Ukur dampak: kecepatan vs UI usang
Caching harus dibuktikan, bukan diasumsikan. Lacak p95 latency sebelum/sesudah, hit rate cache, dan error yang terlihat pengguna seperti “pesan diperbarui setelah dirender.” Respons cepat yang kemudian bertentangan dengan UI seringkali lebih buruk daripada respons sedikit lebih lambat yang konsisten.
Persistensi dan pekerjaan jangka panjang: job, queue, dan state status
Cegah duplikat saat retry
Biarkan Koder.ai menambahkan ID permintaan dan kunci idempoten ke endpoint Anda.
Beberapa fitur AI selesai dalam satu detik. Yang lain butuh menit: meng-upload dan memparsing PDF, embedding dan mengindeks knowledge base, atau menjalankan workflow multi-langkah tool. Untuk ini, “state” bukan hanya apa yang di layar—melainkan apa yang bertahan lewat refresh, retry, dan waktu.
Apa yang dipersist (dan kenapa)
Persist hanya yang membuka nilai produk nyata.
Riwayat percakapan jelas: pesan, timestamp, identitas pengguna, dan (sering) model/tool yang dipakai. Ini memungkinkan “lanjutkan nanti,” audit trail, dan dukungan yang lebih baik.
Pengaturan pengguna dan workspace harus di database: model preferensi, default temperature, feature toggles, system prompts, dan preferensi UI yang mengikuti pengguna antar perangkat.
File dan artefak (upload, teks hasil ekstraksi, laporan yang dihasilkan) biasanya disimpan di object storage dengan record database yang menunjuk ke mereka. Database menyimpan metadata (pemilik, ukuran, tipe konten, status pemrosesan), sedangkan blob store menyimpan byte-nya.
Background job untuk tugas panjang
Jika sebuah request tidak bisa selesai andal dalam timeout HTTP normal, pindahkan pekerjaan ke queue.
Polanya tipikal:
- Frontend memanggil API seperti
POST /jobsdengan input (file id, conversation id, parameter). - Backend mengantri job (ekstraksi, indexing, batch tool runs) dan langsung mengembalikan
job_id. - Worker memproses job secara asinkron dan menulis hasil kembali ke storage persisten.
Ini membuat UI responsif dan membuat retry lebih aman.
State status yang dapat dipercaya UI
Buat state job eksplisit dan dapat di-query: queued → running → succeeded/failed (opsional canceled). Simpan transisi ini di server dengan timestamp dan detail error.
Pada frontend, refleksikan status dengan jelas:
- Queued/running: tunjukkan spinner dan nonaktifkan aksi duplikat.
- Failed: tampilkan error singkat, plus tombol Retry.
- Succeeded: muat artefak yang dihasilkan atau perbarui percakapan.
Expose GET /jobs/{id} (polling) atau stream update (SSE/WebSocket) agar UI tidak perlu menebak.
Idempotency keys: retry tanpa duplikasi write
Timeout jaringan terjadi. Jika frontend retry POST /jobs, Anda tidak mau dua job identik (dan dua tagihan).
Minta Idempotency-Key per aksi logis. Backend menyimpan key dengan job_id/response yang dihasilkan dan mengembalikan hasil yang sama untuk permintaan berulang.
Kebijakan cleanup dan kadaluarsa
Aplikasi AI jangka panjang mengumpulkan data cepat. Tetapkan aturan retensi sejak awal:
- Expire percakapan lama setelah N hari (atau beri pilihan konfigurasi ke pengguna).
- Hapus artefak turunan saat sumbernya dihapus.
- Secara berkala purge job yang gagal dan file intermediate.
Anggap cleanup sebagai bagian dari manajemen state: mengurang i risiko, biaya, dan kebingungan.
Respons streaming dan pembaruan real-time: mengelola state parsial
Streaming membuat state lebih rumit karena “jawaban” bukan lagi satu blob. Anda berurusan dengan token parsial (teks datang kata demi kata) dan kadang kerja tool parsial (pencarian dimulai, lalu selesai belakangan). Itu berarti UI dan backend harus sepakat apa yang dianggap sementara vs final.
Backend: stream event bertipe, bukan sekadar teks
Pola yang bersih adalah men-stream serangkaian event kecil, masing-masing dengan tipe dan payload. Contoh:
token: teks incremental (atau chunk kecil)tool_start: pemanggilan tool dimulai (mis. “Mencari…”, dengan id)tool_result: output tool sudah siap (id sama)done: pesan asisten selesaierror: sesuatu gagal (sertakan pesan aman untuk pengguna dan debug id)
Stream event ini lebih mudah di-versioning dan di-debug daripada streaming teks mentah, karena frontend dapat merender progres dengan akurat (dan menampilkan status tool) tanpa menebak.
Frontend: update append-only, lalu commit final
Di client, perlakukan streaming sebagai append-only: buat pesan asisten “draft” dan terus perpanjang saat event token datang. Saat menerima done, lakukan commit: tandai pesan final, persist jika Anda menyimpannya lokal, dan buka aksi seperti copy, rate, atau regenerate.
Ini menghindari penulisan ulang riwayat tengah stream dan menjaga UI tetap dapat diprediksi.
Menangani interupsi (cancel, drop, timeout)
Streaming meningkatkan kemungkinan kerja setengah jadi:
- Pengguna membatalkan: kirim sinyal cancel; hentikan rendering token; pertahankan draft yang terlihat dibatalkan.
- Koneksi jaringan putus: hentikan stream; tampilkan “reconnecting…” dan jangan menganggap selesai.
- Timeout/server error: finalisasikan draft sebagai gagal, dan beri opsi retry yang memulai request baru (jangan menyambung stream secara diam-diam).
Rehydration: reload dan rekonstruksi state stabil
Jika halaman di-refresh di tengah stream, bangun kembali dari state stabil terakhir: pesan yang terakhir dikomit ditambah metadata draft yang tersimpan (message id, teks terakumulasi sejauh ini, status tool). Jika Anda tidak bisa melanjutkan stream, tampilkan draft sebagai terinterupsi dan biarkan pengguna retry, daripada pura-pura selesai.
Keamanan dan privasi: melindungi state ujung-ke-ujung
Deploy tanpa setup tambahan
Dari chat ke build web dan backend terhosting tanpa perlu mengelola pipeline penuh.
State bukan hanya “data yang Anda simpan”—itu adalah prompt pengguna, upload, preferensi, keluaran yang dihasilkan, dan metadata yang mengikat semuanya. Dalam aplikasi AI, state bisa sangat sensitif (info personal, dokumen proprietary, keputusan internal), jadi keamanan harus dirancang ke setiap lapisan.
Simpan rahasia di server
Apa pun yang memungkinkan client menyamar sebagai aplikasi Anda harus tetap di backend: API keys, konektor privat (Slack/Drive/DB credentials), dan system prompt atau logika routing internal. Frontend bisa meminta aksi (“ringkas file ini”), tetapi backend harus memutuskan bagaimana dieksekusi dan dengan kredensial apa.
Otorisasi setiap write (dan sebagian besar read)
Perlakukan setiap mutasi state sebagai operasi berprivilege. Saat client mencoba membuat pesan, mengganti nama percakapan, atau melampirkan file, backend harus memverifikasi:
- Pengguna terautentikasi.
- Pengguna memiliki resource (percakapan, workspace, proyek).
- Pengguna diizinkan melakukan aksi itu (peran, batas plan, kebijakan organisasi).
Ini mencegah serangan tebak-ID di mana seseorang menukar conversation_id dan mengakses riwayat pengguna lain.
Jangan percaya browser: validasi dan sanitasi
Asumsikan setiap state yang diberikan client adalah input yang tidak dipercaya. Validasi skema dan constraint (tipe, panjang, enum yang diizinkan), dan sanitasi untuk destinasi (SQL/NoSQL, log, rendering HTML). Jika Anda menerima “update state” (mis. pengaturan, parameter tool), whitelist field yang diizinkan ketimbang menggabungkan JSON sebarang.
Jejak audit untuk aksi kritis
Untuk aksi yang mengubah state tahan-lama—sharing, eksport, penghapusan, akses konektor—catat siapa melakukan apa dan kapan. Log audit ringan membantu respon insiden, dukungan pelanggan, dan kepatuhan.
Minimalkan data dan enkripsi
Simpan hanya yang dibutuhkan untuk fitur. Jika Anda tidak butuh prompt penuh selamanya, pertimbangkan jendela retensi atau redaksi. Enkripsi state sensitif saat istirahat bila sesuai (token, kredensial konektor, dokumen upload) dan gunakan TLS saat transit. Pisahkan metadata operasional dari konten agar Anda bisa membatasi akses lebih ketat.
Arsitektur referensi praktis dan checklist pembangunan
Default yang berguna untuk aplikasi AI adalah sederhana: backend adalah sumber kebenaran, dan frontend adalah cache optimis yang cepat. UI bisa terasa instan, tetapi apa pun yang akan membuat Anda sedih jika hilang (pesan, status job, output tool, event terkait tagihan) harus dikonfirmasi dan disimpan di server.
Jika Anda membangun dengan workflow “vibe-coding”—di mana banyak permukaan produk dihasilkan cepat—model state jadi makin penting. Platform seperti Koder.ai dapat membantu tim mengirimkan web, backend, dan mobile apps dari chat, tetapi aturan yang sama tetap berlaku: iterasi cepat paling aman saat sumber-kebenaran, ID, dan transisi status dirancang sejak awal.
Arsitektur referensi (yang bisa Anda kirimkan)
Frontend (browser/mobile)
- UI state: panel terbuka, teks prompt draft, model terpilih, indikator “sedang mengetik” sementara.
- Cached server state: percakapan recent, status job terakhir yang diketahui, buffer stream parsial.
- Satu pipeline request yang selalu melampirkan:
session_id,conversation_id, danrequest_idbaru.
Backend (API + workers)
- Layanan API: memvalidasi input, membuat record, mengeluarkan respons streaming.
- Penyimpanan tahan-lama (SQL/NoSQL): percakapan, pesan, pemanggilan tool, status job.
- Queue + worker: tugas jangka panjang (RAG indexing, parsing file, image generation).
- Cache (opsional): hot reads (ringkasan percakapan, metadata embeddings), selalu diberi key dengan version/timestamp.
Catatan: salah satu cara praktis menjaga konsistensi ini adalah menstandardisasi stack backend Anda lebih awal. Mis. backend yang dihasilkan Koder.ai sering menggunakan Go dengan PostgreSQL (dan React di frontend), yang memudahkan memusatkan state “otoritatif” di SQL sementara cache client bisa dibuang.
Rancang model state Anda terlebih dulu
Sebelum membangun tampilan, definisikan field yang akan Anda andalkan di setiap lapisan:
- IDs dan kepemilikan:
user_id,org_id,conversation_id,message_id,request_id. - Timestamps dan pengurutan:
created_at,updated_at, dansequenceeksplisit untuk pesan. - Field status:
queued | running | streaming | succeeded | failed | canceled(untuk job dan pemanggilan tool). - Versioning:
etagatauversionuntuk pembaruan yang aman konflik.
Ini mencegah bug klasik di mana UI “terlihat benar” tapi tidak bisa merekonsiliasi retry, refresh, atau edit bersamaan.
Gunakan bentuk API yang konsisten
Buat endpoint prediktabel di seluruh fitur:
GET /conversations(list)GET /conversations/{id}(get)POST /conversations(create)POST /conversations/{id}/messages(append)PATCH /jobs/{id}(update status)GET /streams/{request_id}atauPOST .../stream(stream)
Kembalikan gaya envelope yang sama di mana-mana (termasuk error) sehingga frontend dapat memperbarui state secara seragam.
Tambahkan observability di tempat state bisa rusak
Log dan kembalikan request_id untuk setiap panggilan AI. Catat input/output pemanggilan tool (dengan redaksi), latency, retry, dan status akhir. Permudah menjawab: “Apa yang model lihat, tools apa yang berjalan, dan state apa yang kita persist?”
Checklist pembangunan (menghindari bug state umum)
- Backend adalah sumber kebenaran; cache frontend jelas berlabel dan dapat dibuang.
- Setiap write idempotent (aman untuk retry) menggunakan
request_id(dan/atau Idempotency-Key). - Transisi status eksplisit dan tervalidasi (tidak ada loncatan diam-diam dari
queuedkesucceeded). - Update streaming digabung berdasarkan ID/sequence, bukan berdasarkan “last message wins.”
- Konflik ditangani via
version/etagatau aturan merge sisi server. - PII dan secret tidak pernah disimpan di state client; redaksi log secara default.
- Ada satu tampilan dashboard untuk debugging: requests, pemanggilan tool, status job, dan error.
Saat Anda mengadopsi siklus build lebih cepat (termasuk generasi yang dibantu AI), pertimbangkan menambahkan guardrail yang menegakkan item checklist ini otomatis—validasi skema, idempotency, dan streaming evented—sehingga “bergerak cepat” tidak berubah menjadi drift state. Praktiknya, di situlah platform end-to-end seperti Koder.ai berguna: mempercepat delivery, sambil tetap memungkinkan Anda mengekspor source code dan menjaga pola penanganan state konsisten di web, backend, dan mobile.