12 Sep 2025·8 menit
Paket starter observability produksi untuk pemantauan hari pertama
Paket observability produksi hari-pertama: log, metrik, dan trace minimum yang perlu ditambahkan, plus alur triage sederhana untuk laporan “lambat”.
Paket observability produksi hari-pertama: log, metrik, dan trace minimum yang perlu ditambahkan, plus alur triage sederhana untuk laporan “lambat”.
Hal pertama yang rusak jarang berarti seluruh aplikasi. Biasanya satu langkah yang tiba-tiba sibuk, satu query yang baik-baik saja saat tes, atau satu dependency yang mulai timeout. Pengguna nyata membawa variasi nyata: ponsel lebih lambat, jaringan fluktuatif, input aneh, dan lonjakan traffic di waktu yang tidak pas.
Saat seseorang bilang “lambat”, itu bisa berarti hal yang sangat berbeda. Halaman mungkin butuh waktu lama untuk dimuat, interaksi terasa tersendat, satu panggilan API mungkin timeout, job background menumpuk, atau layanan pihak ketiga menarik semuanya ke bawah.
Itulah mengapa Anda butuh sinyal sebelum Anda butuh dashboard. Di hari pertama, Anda tidak perlu grafik sempurna untuk setiap endpoint. Anda butuh cukup log, metrik, dan trace untuk menjawab satu pertanyaan dengan cepat: ke mana waktu pergi?
Ada juga risiko nyata jika melakukan instrumentasi berlebihan terlalu dini. Terlalu banyak event menciptakan noise, menambah biaya, dan bahkan bisa memperlambat aplikasi. Lebih parah lagi, tim berhenti mempercayai telemetri karena terasa berantakan dan tidak konsisten.
Tujuan realistis hari-pertama itu sederhana: ketika Anda mendapat laporan “lambat”, Anda bisa menemukan langkah yang lambat dalam kurang dari 15 menit. Anda harus bisa mengatakan apakah bottleneck ada di rendering klien, handler API dan dependency-nya, database atau cache, atau worker background atau layanan eksternal.
Contoh: alur checkout baru terasa lambat. Bahkan tanpa tumpukan tooling besar, Anda tetap ingin bisa berkata, “95% waktu dihabiskan pada panggilan provider pembayaran,” atau “query cart memindai terlalu banyak baris.” Jika Anda membangun aplikasi cepat dengan alat seperti Koder.ai, baseline hari-pertama ini jadi lebih penting, karena kecepatan pengiriman hanya membantu jika Anda juga bisa debug dengan cepat.
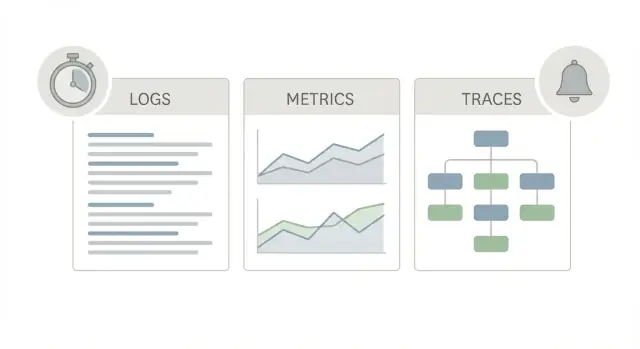
Paket observability produksi yang baik menggunakan tiga “pandangan” berbeda dari aplikasi yang sama, karena tiap pandangan menjawab pertanyaan yang berbeda.
Log adalah cerita. Mereka memberi tahu apa yang terjadi untuk satu request, satu pengguna, atau satu job background. Satu baris log bisa mengatakan “pembayaran gagal untuk order 123” atau “DB timeout setelah 2s,” plus detail seperti request ID, user ID, dan pesan error. Ketika seseorang melaporkan kasus aneh sekali-sekali, log sering kali cara tercepat untuk mengonfirmasi itu terjadi dan siapa yang terdampak.
Metrik adalah papan skor. Mereka adalah angka yang bisa Anda tren dan beri alert: rate request, tingkat error, percentiles latency, CPU, kedalaman antrean. Metrik memberi tahu apakah sesuatu langka atau luas, dan apakah ini memburuk. Jika latency melonjak untuk semua orang pada 10:05, metrik yang akan menunjukkannya.
Trace adalah peta. Trace mengikuti satu request saat bergerak melalui sistem Anda (web -> API -> database -> pihak ketiga). Trace menunjukkan di mana waktu dihabiskan, langkah demi langkah. Itu penting karena “lambat” hampir tidak pernah satu misteri besar. Biasanya satu hop yang lambat.
Saat insiden, alur praktis terlihat seperti ini:
Aturan sederhana: jika setelah beberapa menit Anda tidak bisa menunjuk satu bottleneck, Anda tidak perlu lebih banyak alert. Anda butuh trace yang lebih baik, dan ID konsisten yang menghubungkan trace ke log.
Sebagian besar insiden “kita tidak bisa menemukannya” bukan disebabkan oleh data yang hilang. Mereka terjadi karena hal yang sama dicatat berbeda di berbagai layanan. Beberapa konvensi bersama di hari pertama membuat log, metrik, dan trace sejajar ketika Anda butuh jawaban cepat.
Mulailah dengan memilih satu nama layanan per unit yang bisa dideploy dan jaga agar stabil. Jika “checkout-api” berubah menjadi “checkout” di setengah dashboard Anda, Anda kehilangan histori dan merusak alert. Lakukan hal yang sama untuk label environment. Pilih set kecil seperti prod dan staging, dan gunakan di mana-mana.
Selanjutnya, buat setiap request mudah diikuti. Hasilkan request ID di edge (API gateway, web server, atau handler pertama) dan teruskan melalui panggilan HTTP, message queue, dan job background. Jika tiket support mengatakan “lambat pada 10:42,” satu ID memungkinkan Anda mengambil log dan trace yang tepat tanpa menebak.
Set konvensi yang bekerja dengan baik di hari pertama:
Sepakati satuan waktu sejak awal. Pilih milidetik untuk latency API dan detik untuk job yang lebih lama, lalu konsisten. Satuan campur membuat grafik yang tampak baik tapi memberi cerita yang salah.
Contoh konkret: jika setiap API log duration_ms, route, status, dan request_id, maka laporan seperti “checkout lambat untuk tenant 418” menjadi filter cepat, bukan perdebatan tentang dari mana memulai.
Jika Anda hanya melakukan satu hal dalam paket observability produksi, buat log mudah dicari. Itu dimulai dengan log terstruktur (biasanya JSON) dan field yang sama di setiap layanan. Log teks polos oke untuk pengembangan lokal, tapi berubah menjadi noise setelah Anda punya traffic nyata, retry, dan beberapa instance.
Aturan bagus: log apa yang benar-benar akan Anda gunakan saat insiden. Kebanyakan tim perlu menjawab: Request apa ini? Siapa yang melakukan? Di mana gagal? Apa yang disentuh? Jika satu baris log tidak membantu menjawab salah satu dari itu, kemungkinan besar tidak perlu ada.
Untuk hari pertama, pertahankan set field kecil dan konsisten sehingga Anda bisa memfilter dan menggabungkan event antar layanan:
Saat error terjadi, log satu kali saja, dengan konteks. Sertakan tipe error (atau kode), pesan singkat, stack trace untuk error server, dan dependency upstream yang terlibat (misalnya: postgres, payment provider, cache). Hindari mengulang stack trace yang sama di setiap retry. Sebagai gantinya, lampirkan request_id sehingga Anda bisa mengikuti rantai peristiwa.
Contoh: seorang pengguna melaporkan mereka tidak bisa menyimpan pengaturan. Satu pencarian untuk request_id menunjukkan 500 pada PATCH /settings, lalu timeout downstream ke Postgres dengan duration_ms. Anda tidak perlu payload penuh, hanya route, user/session, dan nama dependency.
Privasi adalah bagian dari logging, bukan tugas nanti. Jangan log password, token, header auth, body request penuh, atau PII sensitif. Jika perlu mengidentifikasi pengguna, log ID stabil (atau nilai hashed) alih-alih email atau nomor telepon.
Jika Anda membangun aplikasi di Koder.ai (React, Go, Flutter), ada baiknya menanamkan field-field ini ke setiap layanan yang dihasilkan sejak awal supaya Anda tidak “memperbaiki logging” saat insiden pertama.
Paket observability produksi yang baik dimulai dengan set kecil metrik yang menjawab satu pertanyaan cepat: apakah sistem sehat sekarang, dan jika tidak, di mana yang sakit?
Sebagian besar masalah produksi muncul sebagai salah satu dari empat “sinyal emas”: latency (response lambat), traffic (beban berubah), error (gagal), dan saturasi (sumber daya bersama penuh). Jika Anda bisa melihat keempat sinyal ini per bagian utama aplikasi, Anda bisa triage sebagian besar insiden tanpa menebak.
Latency harus berupa percentiles, bukan rata-rata. Pantau p50, p95, dan p99 sehingga Anda bisa melihat ketika sekelompok kecil pengguna mengalami pengalaman buruk. Untuk traffic, mulai dengan requests per second (atau jobs per minute untuk worker). Untuk error, pisahkan 4xx vs 5xx: naiknya 4xx sering berarti perilaku klien atau perubahan validasi; naiknya 5xx menunjuk ke aplikasi Anda atau dependency-nya. Saturasi adalah sinyal “kita kehabisan sesuatu” (CPU, memori, koneksi DB, backlog antrean).
Set minimum yang mencakup sebagian besar aplikasi:
Contoh konkret: jika pengguna melaporkan “lambat” dan p95 API melonjak sementara traffic tetap datar, periksa saturasi berikutnya. Jika penggunaan pool DB hampir selalu maksimal dan timeout naik, Anda menemukan bottleneck yang mungkin. Jika DB terlihat baik tetapi kedalaman antrean tumbuh cepat, pekerjaan background mungkin memakan sumber daya bersama.
Jika Anda membangun aplikasi di Koder.ai, anggap checklist ini sebagai bagian dari definisi done hari-pertama Anda. Lebih mudah menambahkan metrik ini saat aplikasi masih kecil daripada saat insiden nyata pertama.
Jika pengguna bilang “lambat”, log sering memberi tahu apa yang terjadi, dan metrik memberi tahu seberapa sering terjadi. Trace memberi tahu di mana waktu dihabiskan dalam satu request. Garis waktu itu mengubah keluhan kabur menjadi perbaikan yang jelas.
Mulailah di sisi server. Instrumentasikan request masuk di edge aplikasi Anda (handler pertama yang menerima request) sehingga setiap request bisa menghasilkan satu trace. Tracing sisi klien bisa menunggu.
Trace hari-pertama yang baik memiliki span yang memetakan bagian yang biasanya menyebabkan kelambatan:
Agar trace bisa dicari dan dibandingkan, tangkap beberapa atribut kunci dan jaga konsistensinya antar layanan.
Untuk span request inbound, catat route (gunakan template seperti /orders/:id, bukan URL penuh), method HTTP, status code, dan latency. Untuk span database, catat sistem DB (PostgreSQL, MySQL), tipe operasi (select, update), dan nama tabel jika mudah ditambahkan. Untuk panggilan eksternal, catat nama dependency (payments, email, maps), host target, dan status.
Sampling penting di hari pertama, kalau tidak biaya dan noise tumbuh cepat. Gunakan aturan head-based sederhana: trace 100% error dan request lambat (jika SDK mendukung), dan sample persentase kecil dari traffic normal (mis. 1-10%). Mulai lebih tinggi saat traffic rendah, lalu turunkan saat penggunaan meningkat.
Apa itu “baik”: satu trace di mana Anda bisa membaca cerita dari atas ke bawah. Contoh: GET /checkout memakan 2.4s, DB 120ms, cache 10ms, dan panggilan pembayaran eksternal memakan 2.1s dengan retry. Sekarang Anda tahu masalah ada pada dependency, bukan kode Anda. Ini inti dari paket observability produksi.
Saat seseorang bilang “lambat”, kemenangan tercepat adalah mengubah perasaan kabur itu menjadi beberapa pertanyaan konkret. Alur triage paket observability produksi ini bekerja bahkan jika aplikasi Anda benar-benar baru.
Mulailah dengan menyempitkan masalah, kemudian ikuti bukti secara berurutan. Jangan langsung lompat ke database.
Setelah menstabilkan, lakukan satu perbaikan kecil: catat apa yang terjadi dan tambahkan satu sinyal yang hilang. Misalnya, jika Anda tidak bisa tahu apakah perlambatan hanya di satu region, tambahkan tag region pada metrik latency. Jika Anda melihat span DB panjang tanpa petunjuk query mana, tambahkan label query dengan hati-hati, atau field “query name”.
Contoh cepat: jika p95 checkout naik dari 400 ms menjadi 3 s dan trace menunjukkan span pembayaran 2.4 s, Anda dapat berhenti berdebat soal kode aplikasi dan fokus pada provider, retry, dan timeout.
Saat seseorang bilang “lambat”, Anda bisa membuang satu jam hanya untuk memahami maksud mereka. Paket observability produksi hanya berguna jika membantu Anda mempersempit masalah dengan cepat.
Mulailah dengan tiga pertanyaan yang memperjelas:
Lalu lihat beberapa angka yang biasanya menunjukkan ke mana harus melanjutkan. Jangan berburu dashboard sempurna. Anda hanya butuh sinyal “lebih buruk dari normal”.
Jika p95 naik tetapi error datar, buka satu trace untuk route paling lambat dalam 15 menit terakhir. Satu trace sering menunjukkan apakah waktu dihabiskan di database, panggilan API eksternal, atau menunggu lock.
Lalu lakukan satu pencarian log. Jika Anda punya laporan pengguna spesifik, cari berdasarkan request_id (atau correlation ID) dan baca timeline. Jika tidak, cari pesan error paling umum di jendela waktu yang sama dan lihat apakah itu sejalan dengan perlambatan.
Akhirnya, putuskan apakah mitigasi sekarang atau dalami lebih lanjut. Jika pengguna terblokir dan saturasi tinggi, mitigasi cepat (scale up, rollback, atau matikan feature flag non-esensial) bisa beli waktu. Jika dampak kecil dan sistem stabil, terus investigasi dengan trace dan slow query logs.
Beberapa jam setelah rilis, tiket support mulai masuk: “Checkout butuh 20–30 detik.” Tidak ada yang bisa meniru di laptop mereka, jadi dugaan mulai bermunculan. Di sinilah paket observability produksi membayar dirinya.
Pertama, buka metrik dan konfirmasi gejala. Grafik p95 latency untuk request HTTP menunjukkan lonjakan jelas, tapi hanya untuk POST /checkout. Route lain normal, dan tingkat error tetap datar. Itu menyempitkan dari “seluruh situs lambat” menjadi “satu endpoint yang melambat setelah rilis.”
Selanjutnya, buka trace untuk request POST /checkout yang lambat. Waterfall trace membuat pelakunya jelas. Dua hasil umum:
Sekarang validasi dengan log, gunakan request ID yang sama dari trace (atau trace ID jika Anda menyimpannya di log). Dalam log untuk request itu, Anda melihat peringatan berulang seperti “payment timeout reached” atau “context deadline exceeded,” plus retry yang ditambahkan di rilis baru. Jika jalur database, log mungkin menunjukkan pesan tunggu lock atau pernyataan query lambat yang dicatat karena melewati ambang.
Dengan ketiga sinyal sejajar, perbaikannya jadi jelas:
Intinya Anda tidak perlu menebak. Metrik menunjuk ke endpoint, trace menunjuk ke langkah lambat, dan log mengonfirmasi mode kegagalan dengan request yang tepat di tangan.
Sebagian besar waktu insiden hilang karena gap yang bisa dihindari: data ada, tapi berisik, berisiko, atau kehilangan detail yang Anda butuhkan untuk menghubungkan gejala dengan penyebab. Paket observability produksi hanya membantu jika tetap bisa dipakai saat situasi tegang.
Salah satu jebakan umum adalah mencatat terlalu banyak, terutama body request mentah. Kedengarannya membantu sampai Anda membayar untuk penyimpanan besar, pencarian menjadi lambat, dan Anda tanpa sengaja menangkap password, token, atau data pribadi. Lebih baik field terstruktur (route, status code, latency, request_id) dan log hanya potongan input kecil yang diizinkan secara eksplisit.
Waktu juga terbuang pada metrik yang tampak rinci tapi tidak bisa diagregasi. Label cardinality tinggi seperti full user ID, email, atau nomor order dapat meledakkan jumlah series metrik dan membuat dashboard tidak dapat diandalkan. Gunakan label kasar saja (nama route, method HTTP, kelas status, nama dependency), dan simpan hal spesifik pengguna di log.
Kesalahan yang sering menghalangi diagnosis cepat:
Contoh kecil: jika p95 checkout melonjak dari 800ms ke 4s, Anda ingin menjawab dua pertanyaan dalam beberapa menit: apakah ini mulai tepat setelah deploy, dan apakah waktu dihabiskan di aplikasi Anda atau di dependency (DB, payment provider, cache)? Dengan percentiles, tag rilis, dan trace dengan nama route plus nama dependency, Anda bisa sampai ke jawaban dengan cepat. Tanpa itu, Anda membakar jendela insiden berdebat tentang tebakan.
Kemenangan nyata adalah konsistensi. Paket observability produksi hanya membantu jika setiap layanan baru dikirimkan dengan dasar yang sama, dinamai dengan cara yang sama, dan mudah ditemukan saat sesuatu rusak.
Ubah pilihan hari-pertama Anda menjadi template singkat yang tim pakai ulang. Jaga agar kecil, tapi spesifik.
Buat satu tampilan “home” yang bisa dibuka siapa saja saat insiden. Satu layar harus menunjukkan requests per minute, tingkat error, p95 latency, dan metrik saturasi utama Anda, dengan filter untuk environment dan versi.
Jaga alert seminimal mungkin di awal. Dua alert menutup banyak kasus: lonjakan tingkat error pada route kunci, dan lonjakan p95 latency pada route yang sama. Jika menambah yang lain, pastikan setiap alert punya aksi jelas.
Terakhir, jadwalkan review bulanan berulang. Hapus alert yang berisik, rapikan penamaan, dan tambahkan satu sinyal yang hilang yang akan menghemat waktu pada insiden terakhir.
Untuk memasukkan ini ke proses build Anda, tambahkan “observability gate” ke checklist rilis: tidak ada deploy tanpa request ID, tag versi, home view, dan dua alert dasar. Jika Anda mengirim dengan Koder.ai, Anda bisa mendefinisikan sinyal hari-pertama ini di planning mode sebelum deploy, lalu iterasi aman menggunakan snapshot dan rollback saat perlu menyesuaikan dengan cepat.
Mulailah dari tempat pertama pengguna memasuki sistem Anda: web server, API gateway, atau handler pertama Anda.
request_id dan teruskan ke setiap panggilan internal.route, method, status, dan duration_ms untuk setiap request.Itu saja biasanya sudah membawa Anda ke endpoint dan jendela waktu yang spesifik dengan cepat.
Targetkan standar ini: Anda bisa mengidentifikasi langkah yang lambat dalam kurang dari 15 menit.
Anda tidak perlu dashboard sempurna di hari pertama. Anda butuh cukup sinyal untuk menjawab:
Gunakan semuanya bersama-sama, karena tiap alat menjawab pertanyaan berbeda:
Saat insiden: konfirmasi dampak dengan metrik, temukan bottleneck dengan trace, jelaskan dengan log.
Pilih beberapa konvensi kecil dan terapkan di mana-mana:
Gunakan structured logs (seringnya JSON) dengan kunci yang sama di mana-mana.
Field minimum yang langsung membantu:
Mulai dengan empat “golden signals” per komponen utama:
Tambahkan checklist kecil per komponen:
Instrumentasikan sisi server dulu agar setiap request masuk bisa menghasilkan trace.
Trace yang berguna hari pertama memiliki span untuk:
Buat span bisa dicari dengan atribut konsisten seperti (template), , dan nama dependency yang jelas (mis. , , ).
Default aman dan sederhana:
Mulai dengan sampling lebih tinggi saat traffic rendah, lalu kurangi saat volume tumbuh.
Tujuannya menjaga trace berguna tanpa meledakkan biaya atau noise, dan tetap punya cukup contoh jalur lambat untuk diagnosis.
Gunakan alur yang bisa diulang yang mengikuti bukti:
Kesalahan ini menghabiskan waktu (dan kadang biaya):
service_name yang stabil, environment (mis. prod/staging), dan versionrequest_id yang dibuat di edge dan diteruskan antar panggilan dan jobroute, method, status_code, dan tenant_id (jika multi-tenant)duration_ms)Tujuannya agar satu filter bisa bekerja di seluruh layanan alih-alih memulai ulang tiap kali.
timestamp, level, service_name, environment, versionrequest_id (dan trace_id jika tersedia)route, method, status_code, duration_msuser_id atau session_id (ID stabil, bukan email)Log error satu kali dengan konteks (tipe/kode error + pesan + nama dependency). Hindari mengulang stack trace yang sama pada setiap retry.
routestatus_codepaymentspostgrescacheTuliskan satu sinyal yang kurang yang akan membuat proses ini lebih cepat, lalu tambahkan berikutnya.
Sederhanakan: ID stabil, percentiles, nama dependency yang jelas, dan tag versi di mana-mana.