13 Jun 2025·8 menit
Palantir vs Perangkat Lunak Perusahaan: Integrasi, Analitik, dan Penyebaran
Lihat bagaimana pendekatan Palantir terhadap integrasi data, analitik operasional, dan penyebaran berbeda dari perangkat lunak perusahaan tradisional—dan apa artinya bagi pembeli.
Apa yang Dimaksud dengan “Palantir” dan “Perangkat Lunak Perusahaan Tradisional” di Sini
Orang sering menggunakan “Palantir” sebagai singkatan untuk beberapa produk terkait dan satu cara umum membangun operasi berbasis data. Untuk menjaga perbandingan ini jelas, berguna untuk menyebutkan apa yang sebenarnya dibahas—dan apa yang tidak.
Apa yang dimaksud “Palantir” dalam tulisan ini
Ketika seseorang mengatakan “Palantir” dalam konteks perusahaan, biasanya mereka mengacu pada satu (atau lebih) dari ini:
- Foundry: platform komersial Palantir, berfokus pada mengintegrasikan data, memodelkannya, dan memungkinkan pengambilan keputusan operasional.
- Gotham: sering dikaitkan dengan kasus penggunaan pertahanan dan sektor publik, dengan tema serupa tetapi sejarah dan penempatan yang berbeda.
- Apollo: sistem penyebaran dan pengiriman yang digunakan untuk mengirim dan mengelola perangkat lunak di banyak lingkungan (termasuk lingkungan terbatas).
Tulisan ini menggunakan istilah “bergaya Palantir” untuk menggambarkan kombinasi (1) integrasi data yang kuat, (2) lapisan semantik/ontologi yang menyelaraskan tim pada makna, dan (3) pola penyebaran yang dapat menjangkau cloud, on‑prem, dan pengaturan terputus.
Apa yang dimaksud “perangkat lunak perusahaan tradisional” di sini
“Perangkat lunak perusahaan tradisional” bukanlah satu produk—itu adalah tumpukan tipikal yang banyak organisasi susun seiring waktu, seperti:
- Sistem ERP dan CRM (sistem pencatatan untuk keuangan, rantai pasok, penjualan)
- Data warehouse atau data lake ditambah dashboard BI (sistem untuk pelaporan dan analitik)
- Middleware integrasi (alat ETL/ELT, iPaaS, antrean pesan, API)
Dalam pendekatan ini, integrasi, analitik, dan operasi sering ditangani oleh alat dan tim yang terpisah, dihubungkan melalui proyek dan proses tata kelola.
Apa yang dibandingkan (dan apa yang bukan)
Ini adalah perbandingan pendekatan, bukan dukungan vendor. Banyak organisasi berhasil dengan tumpukan konvensional; yang lain mendapat manfaat dari model platform yang lebih terintegrasi.
Pertanyaan praktisnya adalah: trade-off apa yang Anda lakukan dalam kecepatan, kontrol, dan seberapa langsung analitik terhubung ke pekerjaan sehari-hari?
Untuk menjaga sisa artikel tetap terfokus, kita akan memusatkan pembahasan pada tiga area:
- Integrasi data: bagaimana data terhubung, dipelihara, dan dimiliki
- Analitik operasional: bagaimana analisis bergerak melampaui dashboard menjadi keputusan
- Model penyebaran: cloud, on‑prem, dan realitas terputus/air‑gapped
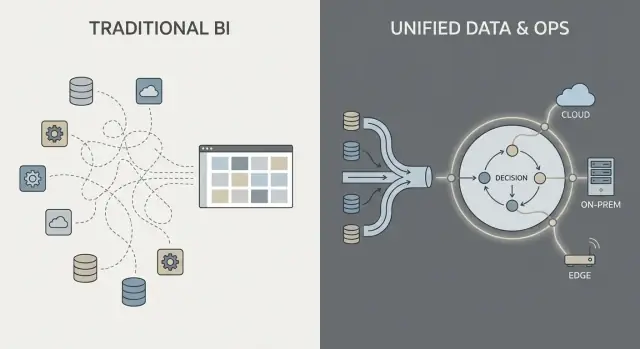
Integrasi Data: Pipeline dan Tanggung Jawab
Sebagian besar pekerjaan data pada “perangkat lunak perusahaan tradisional” mengikuti rantai yang familiar: tarik data dari sistem (ERP, CRM, log), transformasi, muat ke warehouse atau lake, lalu bangun dashboard BI plus beberapa aplikasi hilir.
Polanya bisa bekerja dengan baik, tetapi sering mengubah integrasi menjadi serangkaian penyerahan yang rapuh: satu tim memiliki skrip ekstraksi, tim lain memiliki model warehouse, tim ketiga mendefinisikan dashboard, dan tim bisnis memelihara spreadsheet yang diam-diam mendefinisikan ulang “angka yang sebenarnya.”
Pola tradisional: ETL/ELT seperti lomba estafet
Dengan ETL/ELT, perubahan cenderung menyebar. Field baru di sistem sumber dapat memecahkan pipeline. “Perbaikan cepat” menciptakan pipeline kedua. Tidak lama kemudian Anda memiliki metrik yang duplikat (“pendapatan” di tiga tempat), dan tidak jelas siapa yang bertanggung jawab saat angka tidak cocok.
Pemrosesan batch umum di sini: data mendarat setiap malam, dashboard diperbarui di pagi hari. Near-real-time mungkin mungkin, tetapi sering menjadi tumpukan streaming terpisah dengan tooling dan pemiliknya sendiri.
Pola bergaya Palantir: integrasikan, standarisasi makna, lalu gunakan ulang di mana-mana
Pendekatan bergaya Palantir bertujuan untuk menyatukan sumber dan menerapkan semantik yang konsisten (definisi, relasi, dan aturan) lebih awal, lalu mengekspos data yang sama yang telah dikurasi itu ke analitik dan alur kerja operasional.
Secara sederhana: alih-alih setiap dashboard atau aplikasi “menentukan sendiri” apa arti pelanggan, aset, kasus, atau pengiriman, makna itu didefinisikan sekali dan digunakan berulang. Ini dapat mengurangi logika duplikat dan memperjelas kepemilikan—karena ketika definisi berubah, Anda tahu di mana ia berada dan siapa yang menyetujuinya.
Titik sakit umum yang perlu diwaspadai
Integrasi biasanya gagal karena masalah tanggung jawab, bukan konektor:
- Pipeline yang rapuh yang rusak karena perubahan sumber kecil
- Metrik yang terduplikasi didefinisikan berbeda antar tim
- Kepemilikan yang tidak jelas untuk kualitas data, definisi, dan perbaikan
Kunci pertanyaannya bukan hanya “Bisakah kita terhubung ke sistem X?” Melainkan “Siapa yang memiliki pipeline, definisi metrik, dan makna bisnis itu dari waktu ke waktu?”
Lapisan Semantik dan Ontologi: Titik Berat yang Berbeda
Perangkat lunak perusahaan tradisional sering memperlakukan “makna” sebagai hal yang terabaikan: data disimpan dalam banyak skema spesifik aplikasi, definisi metrik tinggal di dashboard individual, dan tim diam-diam memelihara versi mereka sendiri tentang “apa itu pesanan” atau “kapan sebuah kasus dianggap selesai.” Hasilnya sudah dikenal—angka berbeda di tempat berbeda, rapat rekonsiliasi yang panjang, dan kepemilikan yang kabur saat ada yang salah.
Ontologi, dijelaskan dengan sederhana
Dalam pendekatan bergaya Palantir, lapisan semantik bukan hanya kenyamanan pelaporan. Sebuah ontologi berfungsi sebagai model bisnis bersama yang mendefinisikan:
- Entitas (hal-hal yang penting bagi bisnis Anda): Order, Customer, Asset, Shipment, Case
- Relasi (bagaimana hal-hal itu terhubung): sebuah Order milik Customer; sebuah Shipment memenuhi Order; sebuah Asset terpasang di Site
- Aksi (apa yang orang lakukan terhadapnya): approve, dispatch, escalate, retire, refund
Ini menjadi “titik berat” untuk analitik dan operasi: beberapa sumber data masih bisa ada, tetapi mereka dipetakan ke sekumpulan objek bisnis umum dengan definisi yang konsisten.
Mengapa semantik lebih penting dari yang diperkirakan
Model bersama mengurangi angka yang tidak cocok karena tim tidak lagi menemukan kembali definisi di setiap laporan atau aplikasi. Ini juga meningkatkan akuntabilitas: jika “Pengiriman tepat waktu” didefinisikan terhadap event Shipment dalam ontologi, lebih jelas siapa yang memiliki data dan logika bisnis di bawahnya.
Contoh praktis yang mudah dibayangkan
- Order: Sales, keuangan, dan dukungan melihat objek Order yang sama, termasuk status, nilai, persetujuan, dan pengecualian—tanpa “tabel order” terpisah per departemen.
- Aset: Pemeliharaan, operasi, dan kepatuhan berbagi satu catatan Asset dengan lokasi, riwayat inspeksi, dan flag risiko.
- Kasus: Kasus dukungan terhubung ke pelanggan, order, dan pengiriman, sehingga aturan eskalasi dan metrik layanan tidak menyimpang antar tim.
Jika dikerjakan dengan baik, sebuah ontologi tidak hanya membuat dashboard lebih rapi—ia mempercepat pengambilan keputusan sehari-hari dan mengurangi perdebatan.
Analitik Operasional vs Dashboard BI
Dashboard BI dan pelaporan tradisional terutama tentang melihat ke belakang dan memantau. Mereka menjawab pertanyaan seperti “Apa yang terjadi minggu lalu?” atau “Apakah kita on track terhadap KPI?” Dashboard penjualan, laporan penutupan keuangan, atau scoreboard eksekutif sangat berharga—tetapi sering berhenti pada tingkat visibilitas.
Analitik operasional berbeda: ini adalah analitik yang ditanam di keputusan dan eksekusi harian. Alih-alih menjadi “tujuan analitik” terpisah, analisis muncul di dalam workflow tempat pekerjaan dilakukan, dan mengarahkan langkah berikutnya yang spesifik.
BI: Mengamati dan menjelaskan
BI/pelaporan biasanya fokus pada:
- Metrik standar dan definisi KPI
- Refresh terjadwal dan review mingguan/bulanan
- Tampilan agregat (tim, wilayah, periode waktu)
- Eksplorasi akar masalah setelah hasil diketahui
Itu sangat baik untuk tata kelola, manajemen kinerja, dan akuntabilitas.
Analitik operasional: Memutuskan dan melakukan
Analitik operasional fokus pada:
- Sinyal real-time atau near-real-time
- Dukungan keputusan pada saat tindakan dilakukan
- Rekomendasi, prioritisasi, dan penanganan pengecualian
- Loop umpan balik (apakah tindakan berhasil, dan apa yang berubah?)
Contoh konkret terlihat kurang seperti “sebuah grafik” dan lebih seperti antrian kerja dengan konteks:
- Dispatching: memilih pekerjaan mana dikirim ke kru mana mengingat lokasi, keterampilan, SLA, dan ketersediaan suku cadang
- Alokasi inventori: memutuskan ke mana stok terbatas harus dikirim untuk mengurangi backorder dan pengiriman yang terlewat
- Triase penipuan: memberi peringkat kasus berdasarkan risiko dan merutekannya ke penyidik dengan bukti yang tepat
- Penjadwalan pemeliharaan: memprediksi kegagalan dan menjadwalkan downtime mengelilingi kendala produksi
Perubahan kunci: dari “melihat” menjadi “bertindak”
Perubahan paling penting adalah analisis terkait dengan langkah alur kerja yang spesifik. Dashboard BI mungkin menunjukkan “pengiriman terlambat meningkat.” Analitik operasional mengubah itu menjadi “ini 37 pengiriman yang berisiko hari ini, penyebab kemungkinan, dan intervensi yang direkomendasikan,” dengan kemampuan untuk mengeksekusi atau menugaskan langkah berikutnya secara langsung.
Dari Wawasan ke Tindakan: Desain yang Berfokus pada Workflow
Analitik perusahaan tradisional sering berakhir pada tampilan dashboard: seseorang melihat masalah, mengekspor ke CSV, mengirim email laporan, dan tim terpisah “melakukan sesuatu” kemudian. Pendekatan bergaya Palantir dirancang untuk memendekkan jurang itu dengan menanamkan analitik langsung ke dalam workflow tempat keputusan dibuat.
Keputusan dengan manusia sebagai loop (bukan autopilot)
Sistem berfokus workflow biasanya menghasilkan rekomendasi (mis. “prioritaskan 12 pengiriman ini,” “flag 3 vendor ini,” “jadwalkan pemeliharaan dalam 72 jam”) tetapi masih memerlukan persetujuan eksplisit. Langkah persetujuan itu penting karena menciptakan:
- Akuntabilitas keputusan: siapa menyetujui, kapan, dan berdasarkan data apa
- Jejak audit: rantai terekam dari data input → logika/model → rekomendasi → aksi
- Pengecualian terkontrol: operator dapat menimpanya dengan alasan, bukan bekerja di luar alat
Ini sangat berguna di operasi yang diatur atau berisiko tinggi di mana “karena model mengatakan begitu” bukan justifikasi yang dapat diterima.
Workflow menggantikan “serah terima laporan”
Alih-alih memperlakukan analitik sebagai tujuan terpisah, antarmuka dapat merutekan wawasan ke tugas: menugaskan ke antrian, meminta persetujuan, memicu notifikasi, membuka kasus, atau membuat work order. Pergeseran penting adalah hasil dilacak di dalam sistem yang sama—sehingga Anda dapat mengukur apakah tindakan benar-benar mengurangi risiko, biaya, atau keterlambatan.
Pengalaman berbasis peran dan hak keputusan
Desain berfokus workflow biasanya memisahkan pengalaman menurut peran:
- Operator garis depan: antrian cepat, tindakan terbaik berikutnya, konteks minimal yang diperlukan
- Analis: drill-down lebih dalam, pengujian skenario, dan pemantauan kualitas data/model
- Eksekutif: KPI yang terkait dengan throughput operasional dan hambatan, bukan sekadar grafik
Faktor keberhasilan umum adalah menyelaraskan produk dengan hak keputusan dan prosedur operasional: siapa yang boleh bertindak, persetujuan apa yang diperlukan, dan apa arti “selesai” secara operasional.
Tata Kelola, Keamanan, dan Kepercayaan pada Data
Buktikan jalur data
Jalankan layanan Go dan PostgreSQL untuk memvalidasi integrasi dan aturan data.
Tata kelola adalah tempat banyak program analitik berhasil atau terhenti. Itu bukan hanya “pengaturan keamanan” — melainkan seperangkat aturan praktis dan bukti yang memungkinkan orang mempercayai angka, berbagi data dengan aman, dan menggunakannya untuk membuat keputusan nyata.
Apa yang harus dicakup tata kelola (selain login)
Kebanyakan perusahaan membutuhkan kontrol inti yang sama, terlepas dari vendor:
- Kontrol akses: siapa yang bisa melihat, mengedit, atau menyetujui data, model, dan output operasional
- Lineage data: dari mana sebuah metrik berasal, sumber apa yang memasoknya, dan transformasi apa yang terjadi
- Log audit: catatan yang dapat dipertahankan tentang siapa mengubah apa dan kapan
- Persetujuan dan kontrol perubahan: khususnya untuk metrik “resmi”, dataset bersama, dan workflow produksi
Ini bukan birokrasi tanpa tujuan. Ini cara mencegah masalah “dua versi kebenaran” dan mengurangi risiko saat analitik bergerak lebih dekat ke operasi.
“Keamanan di dashboard” vs keamanan menyeluruh sepanjang rantai
Implementasi BI tradisional sering menempatkan keamanan terutama di lapisan laporan: pengguna dapat melihat dashboard tertentu, dan administrator mengelola izin di sana. Itu bisa bekerja ketika analitik bersifat deskriptif.
Pendekatan bergaya Palantir mendorong keamanan dan tata kelola melalui seluruh pipeline: dari ingest data mentah, ke lapisan semantik (objek, relasi, definisi), ke model, bahkan ke aksi yang dipicu dari wawasan. Tujuannya adalah agar keputusan operasional (seperti mengirim kru, melepaskan inventori, atau memprioritaskan kasus) mewarisi kontrol yang sama dengan data di belakangnya.
Prinsip least privilege dan segregasi tugas (dijelaskan sederhana)
Dua prinsip penting untuk keselamatan dan akuntabilitas:
- Least privilege: orang hanya mendapat akses yang mereka perlukan untuk melakukan tugasnya
- Segregasi tugas: orang yang membangun atau mengubah logika bukanlah orang yang menyetujuinya untuk penggunaan produksi
Misalnya, seorang analis dapat mengusulkan definisi metrik, seorang data steward menyetujuinya, dan operasi menggunakannya—dengan jejak audit yang jelas.
Mengapa tata kelola mendorong adopsi
Tata kelola yang baik bukan hanya untuk tim kepatuhan. Ketika pengguna bisnis dapat mengklik lineage, melihat definisi, dan mengandalkan izin yang konsisten, mereka berhenti berdebat tentang spreadsheet dan mulai bertindak berdasarkan wawasan. Keyakinan itu-lah yang mengubah analitik dari “laporan menarik” menjadi perilaku operasional.
Model Penyebaran: Cloud, On-Prem, dan Lingkungan Terputus
Di mana perangkat lunak perusahaan dijalankan kini bukan lagi detail TI—itu membentuk apa yang dapat Anda lakukan dengan data, seberapa cepat Anda bisa berubah, dan risiko apa yang dapat Anda terima. Pembeli biasanya mengevaluasi empat pola penyebaran.
Public cloud
Public cloud (AWS/Azure/GCP) mengoptimalkan untuk kecepatan: provisioning cepat, layanan terkelola mengurangi pekerjaan infrastruktur, dan penskalaan mudah. Pertanyaan utama pembeli adalah residensi data (region mana, backup mana, akses dukungan siapa), integrasi ke sistem on‑prem, dan apakah model keamanan Anda dapat mentolerir konektivitas jaringan cloud.
Private cloud
Private cloud (single-tenant atau Kubernetes/VM yang dikelola pelanggan) sering dipilih ketika Anda membutuhkan otomasi ala cloud tetapi kontrol batas jaringan dan persyaratan audit yang lebih ketat. Ini dapat mengurangi beberapa gesekan kepatuhan, tetapi Anda tetap perlu disiplin operasional yang kuat seputar patching, monitoring, dan review akses.
On‑prem
Penyebaran on‑prem tetap umum di manufaktur, energi, dan sektor sangat teregulasi di mana sistem inti dan data tidak boleh meninggalkan fasilitas. Trade-off‑nya adalah overhead operasional: siklus hidup hardware, perencanaan kapasitas, dan lebih banyak pekerjaan untuk menjaga konsistensi lingkungan dev/test/prod. Jika organisasi Anda kesulitan menjalankan platform secara andal, on‑prem dapat memperlambat time-to-value.
Disconnected / air‑gapped
Lingkungan terputus (air-gapped) adalah kasus khusus: pertahanan, infrastruktur kritis, atau situs dengan konektivitas terbatas. Di sini, model penyebaran harus mendukung kontrol pembaruan yang ketat—artefak bertanda tangan, promosi rilis yang terkontrol, dan instalasi yang dapat diulang di jaringan terisolasi.
Keterbatasan jaringan juga memengaruhi perpindahan data: alih-alih sinkronisasi kontinu, Anda mungkin mengandalkan transfer bertahap dan workflow “export/import.”
Trade-off kunci
Dalam praktiknya, ini seperti segitiga: fleksibilitas (cloud), kontrol (on‑prem/air-gapped), dan kecepatan perubahan (otomasi + pembaruan). Pilihan yang tepat bergantung pada aturan residensi, realitas jaringan, dan seberapa banyak operasi platform yang tim Anda siap miliki.
Mengoperasionalkan Pembaruan: Apa yang Berubah dengan Pengiriman Bergaya Apollo
Rancang untuk tata kelola
Tambahkan langkah human-in-the-loop agar rekomendasi menjadi keputusan yang dapat diaudit.
“Pengiriman bergaya Apollo” pada dasarnya adalah continuous delivery untuk lingkungan bernilai tinggi: Anda dapat mengirim perbaikan sering (mingguan, harian, bahkan beberapa kali per hari) sambil menjaga operasi tetap stabil.
Tujuannya bukan “bergerak cepat lalu merusak.” Melainkan “bergerak sering dan tidak merusak apa pun.”
Continuous delivery dalam istilah sederhana
Alih-alih menggabungkan perubahan ke dalam rilis kuartalan besar, tim mengirim pembaruan kecil yang dapat dibalik. Setiap pembaruan lebih mudah diuji, lebih mudah dijelaskan, dan lebih mudah di-rollback jika terjadi masalah.
Untuk analitik operasional, itu penting karena “perangkat lunak” Anda bukan hanya UI—ia adalah pipeline data, logika bisnis, dan workflow yang diandalkan orang. Proses pembaruan yang lebih aman menjadi bagian dari operasi sehari-hari.
Bagaimana ini berbeda dari siklus perusahaan tradisional
Upgrade perangkat lunak perusahaan tradisional sering terlihat seperti proyek: jendela perencanaan panjang, koordinasi downtime, kekhawatiran kompatibilitas, pelatihan ulang, dan tanggal cutover yang keras. Bahkan ketika vendor menawarkan patch, banyak organisasi menunda pembaruan karena risiko dan upaya yang tidak dapat diprediksi.
Tooling bergaya Apollo bertujuan membuat upgrade menjadi rutinitas daripada kejadian istimewa—lebih seperti memelihara infrastruktur daripada menjalankan migrasi besar.
Memisahkan “membangun” dari “mengirim”
Tooling penyebaran modern memungkinkan tim mengembangkan dan menguji di lingkungan terisolasi, lalu “mempromosikan” build yang sama melalui tahapan (dev → test → staging → production) dengan kontrol yang konsisten. Pemisahan itu membantu mengurangi kejutan menit-terakhir yang disebabkan oleh perbedaan antar lingkungan.
Pertanyaan yang harus diajukan ke vendor
- Bagaimana Anda menangani rollback—satu klik, rollback parsial, atau langkah pemulihan kompleks?
- Versi apa yang ada untuk pipeline, model, dan perubahan ontologi (bukan hanya UI)?
- Bagaimana promosi lingkungan bekerja, dan siapa yang bisa menyetujui?
- Dapatkah Anda menjalankan rilis canary (subset kecil terlebih dahulu) atau feature flags?
- Jejak audit apa yang menunjukkan siapa mengirim apa, kapan, dan mengapa?
- Berapa downtime yang diharapkan—idealnya tidak ada—untuk pembaruan tipikal?
Implementasi dan Time-to-Value: Apa yang Sebenarnya Memerlukan Upaya
Time-to-value kurang soal seberapa cepat Anda bisa “menginstal” sesuatu dan lebih soal seberapa cepat tim setuju pada definisi, menghubungkan data yang berantakan, dan mengubah wawasan menjadi keputusan harian.
Gaya implementasi: konfigurasi, rakit, atau bangun
Perangkat lunak perusahaan tradisional sering menekankan konfigurasi: Anda mengadopsi model data dan workflow yang sudah ditentukan, lalu memetakan bisnis Anda ke dalamnya.
Platform bergaya Palantir cenderung mencampur tiga mode:
- Konfigurasi untuk kontrol akses, koneksi data, dan komponen standar
- Blok bangunan yang dapat digunakan ulang (template, komponen, pola) yang dapat dirakit menjadi kasus penggunaan baru
- Pengembangan aplikasi kustom ketika workflow unik (mis. persetujuan, penanganan pengecualian, serah terima operasional)
Janjinya adalah fleksibilitas—tetapi itu juga berarti Anda perlu kejelasan tentang apa yang sedang dibangun versus apa yang distandarisasi.
Salah satu opsi praktis selama discovery awal adalah mem‑prototype aplikasi workflow dengan cepat—sebelum berkomitmen pada roll‑out platform besar. Misalnya, tim terkadang menggunakan Koder.ai (platform vibe-coding) untuk mengubah deskripsi workflow menjadi aplikasi web kerja via chat, lalu iterasi dengan pemangku kepentingan menggunakan planning mode, snapshots, dan rollback. Karena Koder.ai mendukung export kode sumber dan stack produksi umum (React di web; Go + PostgreSQL di backend; Flutter untuk mobile), ini bisa menjadi cara berisiko rendah untuk memvalidasi pengalaman “wawasan → tugas → jejak audit” dan kebutuhan integrasi selama proof-of-value.
Di mana tim sebenarnya menghabiskan waktu
Sebagian besar upaya biasanya masuk ke empat area:
- Onboarding data: mendapatkan pemilik sumber memberikan akses, mendokumentasikan field, menangani gap kualitas, dan menetapkan harapan refresh
- Pemodelan dan semantik: menyepakati definisi bisnis (apa yang dihitung sebagai “aktif,” “terlambat,” “tersedia”) dan menjaganya konsisten
- Desain workflow: memutuskan siapa yang bertindak atas alert, keputusan apa yang diizinkan, dan apa arti “selesai”
- Pelatihan dan adopsi: mengubah alat menjadi kebiasaan—terutama bagi pengguna garis depan yang tidak akan mentolerir kompleksitas
Tanda bahaya yang memperlambat atau membunuh nilai
Waspadai kepemilikan yang tidak jelas (tidak ada pemilik data/produk yang bertanggung jawab), terlalu banyak definisi bespoke (setiap tim menciptakan metrik sendiri), dan tidak ada jalur dari pilot ke skala (demo yang tidak dapat dioperasionalkan, didukung, atau diatur).
Menstrukturkan pilot yang dapat diskalakan
Pilot yang baik sengaja sempit: pilih satu workflow, definisikan pengguna spesifik, dan berkomitmen pada hasil terukur (mis. kurangi waktu proses sebesar 15%, potong backlog pengecualian 30%). Rancang pilot sehingga data, semantik, dan kontrol yang sama dapat diperluas ke kasus penggunaan berikutnya—daripada memulai ulang.
Biaya dan Pengadaan: Platform vs Solusi Titik
Pembicaraan biaya bisa membingungkan karena “platform” menggabungkan kemampuan yang sering dibeli sebagai alat terpisah. Kuncinya adalah memetakan harga ke hasil yang Anda butuhkan (integrasi + pemodelan + tata kelola + aplikasi operasional), bukan hanya ke baris yang disebut “software”.
Faktor biaya umum untuk platform bergaya Palantir
Sebagian besar kesepakatan platform dibentuk oleh beberapa variabel:
- Jumlah pengguna dan peran: pembangun (engineer, modeler) vs konsumen (operator, analis)
- Compute dan storage: beban kerja berat (data real-time, simulasi, join besar) menaikkan biaya infrastruktur
- Jumlah lingkungan: dev/test/prod, plus lingkungan teregulasi atau terputus, masing‑masing menambah overhead
- Persyaratan dukungan dan uptime: dukungan 24/7, SLA insiden, dan tim keberhasilan berdedikasi mengubah harga
- Layanan profesional: onboarding data awal, desain ontologi, dan pembangunan workflow sering menjadi pendorong biaya awal yang nyata
Apa yang disembunyikan biaya tumpukan tradisional
Pendekatan solusi titik bisa tampak lebih murah pada awalnya, tetapi biaya total cenderung tersebar ke:
- Banyak lisensi (ETL/ELT, BI, katalog, tata kelola, workflow, feature store, dll.)
- Pekerjaan integrasi antar alat (connector, identitas, sinkronisasi metadata)
- Pemeliharaan berkelanjutan (upgrade versi, pipeline rusak, definisi metrik duplikat)
Platform sering mengurangi sprawl alat, tetapi Anda menukar itu dengan kontrak yang lebih besar dan bersifat strategis.
Pengadaan: membeli platform vs aplikasi
Dengan platform, pengadaan harus memperlakukannya seperti infrastruktur bersama: definisikan cakupan enterprise, domain data, persyaratan keamanan, dan milestone delivery. Minta pemisahan yang jelas antara lisensi, cloud/infrastruktur, dan layanan, sehingga Anda dapat membandingkan secara apple-to-apple.
Daftar periksa anggaran sederhana
- Tim mana yang akan aktif membangun vs hanya melihat?
- Workflow mana yang harus berjalan di produksi (bukan hanya dashboard)?
- Berapa banyak lingkungan dan region yang diperlukan?
- Adakah situs air-gapped atau offline?
- Perkiraan pertumbuhan volume data/frekuensi refresh?
- Layanan yang diperlukan untuk 90 hari pertama?
Jika Anda ingin cara cepat untuk menyusun asumsi, lihat /pricing.
Kapan Pendekatan Bergaya Palantir Cocok (dan Kapan Tidak)
Tunjukkan, jangan jelaskan
Tempatkan prototipe Anda dan bagikan kepada pemangku kepentingan untuk umpan balik nyata.
Platform bergaya Palantir cenderung bersinar ketika masalah bersifat operasional (orang perlu membuat keputusan dan mengambil tindakan lintas sistem), bukan sekadar analitis (orang butuh laporan). Trade-off‑nya adalah Anda mengadopsi pendekatan yang lebih “platform”—kuat, tetapi meminta lebih banyak dari organisasi Anda dibandingkan hanya roll‑out BI sederhana.
Skenario yang cocok
Pendekatan bergaya Palantir biasanya cocok ketika pekerjaan melintasi banyak sistem dan tim dan Anda tidak bisa mentolerir penyerahan yang rapuh.
Contoh umum termasuk operasi lintas-sistem seperti koordinasi rantai pasok, operasi penipuan dan risiko, perencanaan misi, manajemen kasus, atau workflow armada dan pemeliharaan—di mana data yang sama harus diinterpretasikan secara konsisten oleh peran yang berbeda.
Ini juga cocok ketika izin kompleks (akses baris/kolom, data multi-tenant, aturan need-to-know) dan ketika Anda membutuhkan jejak audit yang jelas tentang bagaimana data digunakan. Akhirnya, cocok di lingkungan yang diatur atau terbatas: persyaratan on‑prem, penyebaran air‑gapped/terputus, atau akreditasi keamanan yang ketat di mana model penyebaran adalah kebutuhan tingkat pertama, bukan pemikiran tambahan.
Skenario yang kurang cocok
Jika tujuannya terutama pelaporan sederhana—KPI mingguan, beberapa dashboard, rollup keuangan dasar—BI tradisional di atas warehouse yang dikelola dengan baik bisa lebih cepat dan lebih murah.
Ini juga bisa berlebihan untuk dataset kecil, skema yang stabil, atau analitik satu departemen di mana satu tim mengontrol sumber dan definisi, dan tindakan utama terjadi di luar alat.
Kriteria keputusan (kecocokan dengan masalah)
Ajukan tiga pertanyaan praktis:
- Urgensi: Apakah tim membutuhkan workflow yang bekerja dalam minggu, atau ini program modernisasi jangka panjang?
- Kompleksitas data: Apakah keputusan kunci terhambat oleh definisi yang tidak konsisten dan sistem sumber yang terfragmentasi?
- Kapasitas perubahan: Apakah Anda memiliki kepemilikan produk, SME, dan bandwidth tata kelola untuk mengadopsi platform dan menjaganya tetap mutakhir?
Hasil terbaik datang dari memperlakukan ini sebagai “cocok untuk masalah,” bukan “satu alat menggantikan segalanya.” Banyak organisasi mempertahankan BI yang ada untuk pelaporan luas sambil menggunakan pendekatan bergaya Palantir untuk domain operasional yang paling kritis.
Daftar Periksa Pembeli dan Langkah Selanjutnya
Membeli platform bergaya Palantir versus perangkat lunak perusahaan tradisional kurang soal kotak fitur dan lebih soal di mana pekerjaan nyata akan ditempatkan: integrasi, makna bersama (semantik), dan penggunaan operasional harian. Gunakan daftar periksa di bawah untuk memaksa kejelasan sejak awal, sebelum Anda terikat pada implementasi panjang atau alat titik yang sempit.
Daftar periksa perbandingan vendor praktis
Minta setiap vendor spesifik tentang siapa melakukan apa, bagaimana menjaga konsistensi, dan bagaimana digunakan dalam operasi nyata.
- Upaya integrasi: Sumber data apa yang tipikal (ERP, log, spreadsheet, feed partner)? Apa yang sudah siap pakai vs custom? Siapa yang memelihara pipeline setelah go‑live—TI, data engineering, atau vendor?
- Konsistensi semantik: Bagaimana mereka mencegah lima tim mendefinisikan “pelanggan,” “aset,” atau “mission-ready” secara berbeda? Dapatkah mereka menunjukkan lapisan bisnis yang digovern (ontologi/model semantik) dan bagaimana perubahan dipropagasi?
- Dukungan workflow: Dapatkah tim garis depan menyelesaikan tugas (triage, approve, dispatch, investigate) di dalam produk, atau “analisis di sini, bertindak di tempat lain”? Bagaimana pengecualian ditangani?
- Tata kelola dan keamanan: Kontrol akses granular, log audit, dan manajemen kebijakan—bisakah pemilik data mengontrol siapa melihat apa, pada tingkat apa, dan mengapa?
- Keterbatasan penyebaran: Dapatkah berjalan di lingkungan yang Anda butuhkan (cloud, on‑prem, air‑gapped/terputus)? Apa yang rusak saat konektivitas terbatas? Apa jalur upgrade?
Pertanyaan bukti untuk demo (jangan terima slide saja)
- Tunjukkan lineage: Pilih satu KPI kritis dan telusuri dari sumber ke metrik akhir. Di mana bisa salah, dan bagaimana Anda mendeteksinya?
- Demonstrasikan workflow ujung-ke-ujung: Mulai dari data mentah, lalu alert → keputusan → aksi → jejak audit. Sertakan persetujuan dan “siapa mengubah apa.”
- Simulasikan outage/rollback: Apa yang terjadi jika pipeline gagal atau rilis menyebabkan regresi? Dapatkah mereka rollback dengan bersih, dan seberapa cepat?
Siapa yang perlu ada di ruangan
Sertakan pemangku kepentingan yang akan hidup dengan trade-off:
- TI dan pemilik platform (kepemilikan integrasi, keandalan, biaya)
- Keamanan dan kepatuhan (kontrol, auditing, persetujuan penyebaran)
- Pemilik data/steward (definisi, aturan akses, akuntabilitas)
- Pemimpin operasi (dampak proses, adopsi)
- Pengguna garis depan (apakah ini benar-benar membantu mereka melakukan pekerjaan lebih cepat?)
Langkah selanjutnya
Jalankan proof-of-value berbatas waktu yang berfokus pada satu workflow operasional bernilai tinggi (bukan dashboard generik). Definisikan kriteria keberhasilan di muka: waktu-ke-keputusan, pengurangan kesalahan, auditabilitas, dan kepemilikan pekerjaan data berkelanjutan.
Jika Anda ingin panduan lebih lanjut tentang pola evaluasi, lihat /blog. Untuk bantuan menyusun proof-of-value atau pemeringkatan vendor, hubungi kami di /contact.
Pertanyaan umum
Apa yang dimaksud dengan “Palantir” dalam perbandingan ini, dan apa yang termasuk dalam “perangkat lunak perusahaan tradisional"?
Dalam tulisan ini, “Palantir” adalah singkatan untuk pendekatan bergaya platform yang biasanya dikaitkan dengan Foundry (platform komersial data/operasi), Gotham (akar di sektor publik/pertahanan), dan Apollo (sistem penyebaran/pengiriman di berbagai lingkungan).
“Perangkat lunak perusahaan tradisional” merujuk pada tumpukan yang lebih umum disusun organisasi: ERP/CRM + warehouse/lake + BI + ETL/ELT/iPaaS dan middleware integrasi, yang sering dimiliki oleh tim terpisah dan dihubungkan melalui proyek serta proses tata kelola.
Apa perbedaan antara lapisan semantik dan ontologi?
Lapisan semantik adalah tempat Anda mendefinisikan makna bisnis sekali saja (misalnya, apa arti “Pesanan”, “Pelanggan”, atau “Pengiriman tepat waktu”) lalu menggunakan kembali definisi itu di seluruh analitik dan workflow.
Sebuah ontologi melangkah lebih jauh dengan memodelkan:
- Entitas (Order, Shipment, Asset, Case)
- Relasi (Shipment memenuhi Order)
- (approve, dispatch, escalate)
Mengapa upaya integrasi data menjadi rentan dalam tumpukan tradisional?
ETL/ELT tradisional sering menjadi seperti lomba estafet: ekstraksi sumber → transformasi → model di warehouse → dashboard, dengan pemilik berbeda di tiap langkah.
Mode kegagalan umum adalah:
- Pipeline yang rusak ketika skema sumber berubah
- Metrik yang terduplikasi (“pendapatan” terdefinisi berkali-kali)
- Tanggung jawab perbaikan yang tidak jelas
Pendekatan bergaya Palantir mencoba menstandarisasi makna lebih awal lalu menggunakan objek yang dikurasi itu di mana-mana, sehingga logika duplikat berkurang dan kontrol perubahan menjadi lebih eksplisit.
Bagaimana analitik operasional berbeda dari dashboard BI?
Dashboard BI adalah tentang mengamati dan menjelaskan: memantau KPI, refresh terjadwal, dan analisis retrospektif.
Analitik operasional adalah memutuskan dan melakukan:
- Sinyal near-real-time
- Antrian kerja yang diprioritaskan dan rekomendasi
- Tindakan yang terbenam (assign, approve, buat work order)
- Loop umpan balik yang mengukur apakah intervensi berhasil
Jika outputnya “sebuah grafik”, biasanya itu BI. Jika outputnya “ini yang harus dilakukan selanjutnya, dan lakukan di sini”, itu analitik operasional.
Apa arti “berbasis workflow” dan mengapa itu penting?
Sistem yang berfokus pada workflow mempersingkat jarak antara wawasan dan eksekusi dengan menanamkan analisis ke dalam tempat kerja dilakukan.
Dalam praktiknya, ia menggantikan “export ke CSV dan email” dengan:
- Antrian pengecualian atau peluang
- Konteks terlampir (bukti, riwayat, kendala)
- Langkah berikutnya yang terdefinisi (approve, dispatch, escalate)
- Pelacakan hasil (apakah tindakan mengurangi keterlambatan/risiko?)
Tujuannya bukan sekadar laporan yang lebih rapi—melainkan keputusan yang lebih cepat dan dapat diaudit.
Apa itu pengambilan keputusan “human-in-the-loop” dalam analitik operasional?
“Human-in-the-loop” berarti sistem dapat merekomendasikan tindakan, tetapi orang secara eksplisit menyetujui atau menimpanya.
Ini penting karena menciptakan:
- Akuntabilitas (siapa menyetujui apa, kapan, dan mengapa)
- Auditabilitas (data input → logika/model → rekomendasi → aksi)
- Pengecualian terkontrol (override dengan alasan, bukan solusi darurat)
Khususnya penting di operasi yang diatur atau bernilai tinggi di mana otomatisasi tanpa verifikasi tidak dapat diterima.
Kontrol tata kelola apa yang harus saya harapkan di luar izin dashboard dasar?
Tata kelola bukan sekadar login; itu adalah aturan operasional dan bukti yang membuat data aman dan dapat dipercaya.
Sebagai minimal, perusahaan biasanya membutuhkan:
- Kontrol akses (siapa dapat melihat/mengedit/menyetujui)
- Garis keturunan data (dari mana metrik berasal)
- Log audit (siapa mengubah apa dan kapan)
- Kontrol perubahan (persetujuan untuk definisi “resmi” dan workflow produksi)
Ketika tata kelola kuat, tim lebih sedikit menghabiskan waktu merekonsiliasi angka dan lebih banyak bertindak berdasarkan wawasan.
Bagaimana cloud, on-prem, dan penyebaran air-gapped mengubah apa yang mungkin dilakukan?
Pilihan penyebaran membatasi kecepatan, kontrol, dan beban operasi:
- Public cloud: provisioning dan skala tercepat; perlu perhatian pada residensi dan konektivitas.
- Private cloud: kontrol batas yang lebih kuat dengan otomasi ala cloud; tetap menuntut disiplin operasional.
- On-prem: menjaga data lokal; overhead lebih tinggi untuk siklus hardware, kapasitas, dan konsistensi lingkungan.
Apa yang berubah dengan pengiriman ‘bergaya Apollo’ dibanding siklus upgrade tradisional?
Pengiriman bergaya Apollo adalah continuous delivery yang dirancang untuk lingkungan yang dibatasi dan bernilai tinggi: pembaruan kecil, sering, dan reversibel dengan kontrol kuat.
Dibanding siklus upgrade tradisional, ini menekankan:
- Upgrade rutin daripada rilis besar berkala
- Promosi melalui lingkungan (dev → test → prod) dengan persetujuan
- Rollback, canary, dan feature flag
- Versi untuk pipeline, model, dan perubahan semantik/ontologi (bukan hanya UI)
Ini penting karena analitik operasional bergantung pada pipeline dan logika bisnis yang andal, bukan sekadar laporan.
Bagaimana saya harus menyusun pilot agar dapat diskalakan di luar demo?
Bukti nilai yang dapat diskalakan bersifat sempit dan operasional.
Struktur praktis: