Mengapa CAP Menjadi Model Mental Andalan
Ketika Anda menyimpan data yang sama di lebih dari satu mesin, Anda mendapatkan kecepatan dan toleransi kesalahan—tetapi Anda juga mewarisi masalah baru: ketidaksepakatan. Dua server bisa menerima pembaruan berbeda, pesan bisa tiba terlambat atau hilang, dan pengguna mungkin membaca jawaban yang berbeda tergantung replika mana yang mereka temui. CAP menjadi populer karena memberi insinyur cara yang bersih untuk membicarakan realitas berantakan itu tanpa basa-basi.
Eric Brewer, seorang ilmuwan komputer dan salah satu pendiri Inktomi, memperkenalkan gagasan inti ini pada tahun 2000 sebagai pernyataan praktis tentang sistem bereplikasi saat terjadi kegagalan. Pemikirannya cepat menyebar karena cocok dengan pengalaman tim di produksi: sistem terdistribusi tidak hanya gagal dengan cara mati; mereka gagal dengan terbelah.
CAP adalah lensa kegagalan, bukan daftar fitur
CAP paling berguna saat sesuatu rusak—terutama ketika jaringan tidak berperilaku semestinya. Pada hari yang sehat, banyak sistem bisa terlihat cukup konsisten dan tersedia. Ujinya adalah saat mesin tidak bisa berkomunikasi dengan andal dan Anda harus memutuskan apa yang dilakukan pada baca dan tulis sementara sistem terbagi.
Pembingkaian itulah yang membuat CAP menjadi model mental andalan: ia tidak berdebat tentang praktik terbaik; ia memaksa pertanyaan konkret—apa yang akan kita korbankan selama pemisahan?
Apa yang bisa Anda putuskan setelah membaca ini
Di akhir artikel ini, Anda seharusnya bisa:
- Mengenali kapan Anda menghadapi skenario CAP sejati (replikasi + kemungkinan terputusnya komunikasi).
- Memilih dengan sengaja apakah sistem Anda harus memprioritaskan konsistensi (semua melihat kebenaran yang sama) atau ketersediaan (sistem terus merespons) ketika replika tidak bisa sepakat.
- Menghubungkan pilihan itu ke dampak produk: apa yang dialami pengguna, error apa yang ditampilkan, dan perbaikan apa yang diperlukan setelah partisi sembuh.
CAP bertahan karena mengubah ucapan samar “terdistribusi itu sulit” menjadi keputusan yang bisa Anda buat—dan pertahankan.
Persiapan: Replikasi dan Masalah Ketidaksepakatan
Sebuah sistem terdistribusi adalah, secara sederhana, banyak komputer yang mencoba bertindak seperti satu. Anda mungkin memiliki beberapa server di rak, region, atau zona cloud berbeda, tetapi bagi pengguna itu adalah “aplikasi” atau “basis data.”
Mengapa kita mereplikasi data
Agar sistem bersama itu bekerja pada skala dunia nyata, kita biasanya mereplikasi: menyimpan beberapa salinan data yang sama di mesin berbeda.
Replikasi populer karena tiga alasan praktis:
- Skala: lebih banyak mesin bisa menangani lebih banyak lalu lintas.
- Performa: pengguna bisa dilayani oleh salinan terdekat, mengurangi latensi.
- Keandalan: jika satu mesin mati, salinan lain bisa menjaga layanan tetap berjalan.
Sejauh ini, replikasi terdengar seperti kemenangan yang jelas. Masalahnya, replikasi menciptakan tugas baru: menjaga semua salinan tetap sepakat.
Tegangan inti: salinan bisa berbeda pendapat
Jika setiap replika selalu bisa berkomunikasi satu sama lain secara instan, mereka bisa mengoordinasikan pembaruan dan tetap selaras. Tetapi jaringan nyata tidak sempurna. Pesan bisa tertunda, hilang, atau dialihkan karena kegagalan.
Ketika komunikasi sehat, replika biasanya bisa saling bertukar pembaruan dan berkonvergensi pada keadaan yang sama. Tetapi ketika komunikasi terputus (bahkan sementara), Anda bisa berakhir dengan dua versi “kebenaran” yang tampak valid.
Misalnya, seorang pengguna mengubah alamat pengiriman. Replika A menerima pembaruan, replika B tidak. Sekarang sistem harus menjawab pertanyaan sederhana: apa alamat saat ini?
Operasi normal vs. operasi saat gagal
Ini adalah perbedaan antara:
- Operasi normal: replika bisa berkoordinasi; ketidaksepakatan kebanyakan soal waktu.
- Operasi kegagalan: beberapa replika tidak bisa berkomunikasi; ketidaksepakatan menjadi tidak terhindarkan.
Berpikir ala CAP dimulai tepat di sini: begitu replikasi ada, ketidaksepakatan saat kegagalan komunikasi bukanlah kasus pinggiran—itu masalah desain sentral.
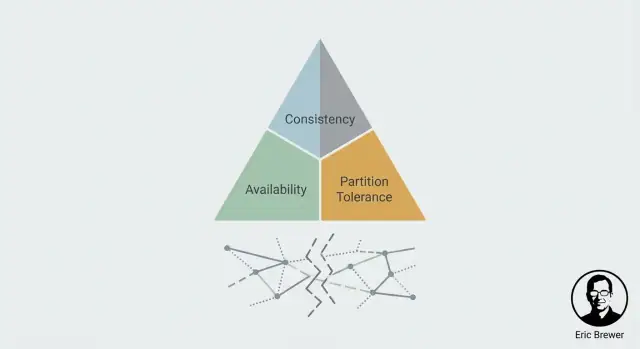
CAP dalam Bahasa Sederhana: C, A, dan P
CAP adalah model mental untuk apa yang dirasakan pengguna sebenarnya ketika sistem tersebar di banyak mesin (seringkali di banyak lokasi). Ia tidak menggambarkan sistem “baik” atau “buruk”—hanya tegangan yang harus Anda kelola.
Konsistensi (C): apakah saya melihat tulisannya yang terbaru?
Konsistensi soal kesepakatan. Jika Anda memperbarui sesuatu, apakah baca berikutnya (dari mana saja) akan mencerminkan pembaruan itu?
Dari sudut pengguna, ini beda antara “saya baru saja mengubahnya, dan semua orang melihat nilai baru yang sama” versus “beberapa orang masih melihat nilai lama untuk sementara waktu.”
Ketersediaan (A): apakah saya mendapat jawaban sama sekali?
Ketersediaan berarti sistem merespons permintaan—baca dan tulis—dengan hasil sukses. Bukan “yang tercepat,” tetapi “ia tidak menolak melayani Anda.”
Saat masalah (server down, gangguan jaringan), sistem yang tersedia tetap menerima permintaan, meski harus menjawab dengan data yang mungkin sedikit kadaluwarsa.
Toleransi partisi (P): apa yang terjadi ketika node tidak bisa bicara?
Partisi adalah ketika jaringan terbelah: mesin masih berjalan, tetapi pesan antar beberapa mesin tidak bisa lewat (atau tiba terlalu lambat untuk berguna). Dalam sistem terdistribusi, Anda tidak bisa menganggap ini mustahil—Anda harus mendefinisikan perilaku saat itu terjadi.
Kisah sederhana: dua toko, satu inventori
Bayangkan dua toko ritel yang sama-sama menjual produk yang sama dan berbagi “1 hitungan inventori.” Seorang pelanggan membeli barang terakhir di Toko A, jadi Toko A menulis inventory = 0. Pada saat yang sama, partisi jaringan mencegah Toko B mengetahuinya.
Jika Toko B tetap tersedia, ia mungkin menjual barang yang tidak lagi ada (menerima penjualan saat terpartisi). Jika Toko B menegakkan konsistensi, ia mungkin menolak penjualan sampai bisa mengonfirmasi inventori terbaru (menolak layanan selama pemisahan).
Apa Sebenarnya Partisi Itu (dan Mengapa Anda Tak Bisa Mengabaikannya)
“Partisi” bukan hanya “internet mati.” Ini adalah situasi apa pun di mana bagian sistem Anda tidak bisa berkomunikasi dengan andal—meskipun tiap bagian mungkin masih berjalan baik.
Dalam sistem bereplikasi, node terus bertukar pesan: tulis, acknowledgement, heartbeat, pemilihan leader, permintaan baca. Partisi adalah ketika pesan-pesan itu berhenti tiba (atau tiba terlambat), menciptakan ketidaksepakatan tentang realitas: “Apakah tulis itu terjadi?” “Siapa leader?” “Apakah node B hidup?”
Partisi adalah kegagalan komunikasi
Komunikasi bisa gagal dengan cara yang berantakan dan parsial:
- Kehilangan paket yang memicu retry dan timeout
- Masalah routing di mana lalu lintas mengambil jalur memutar atau terblackhole
- Link yang kelebihan beban (atau NIC yang jenuh) menyebabkan penundaan panjang
- Firewall / security group yang salah konfigurasi memblokir port atau arah tertentu
- DNS atau gangguan discovery layanan yang mencegah node menemukan satu sama lain
Poin penting: partisi sering berupa degradasi, bukan outage yang bersih on/off. Dari sudut aplikasi, “cukup lambat” bisa tidak bisa dibedakan dari “mati.”
Mengapa partisi tak terelakkan pada skala besar
Saat Anda menambah lebih banyak mesin, jaringan, region, dan bagian yang bergerak, ada lebih banyak kesempatan komunikasi putus sementara. Bahkan jika komponen individual andal, sistem keseluruhan tetap mengalami kegagalan karena lebih banyak dependensi dan koordinasi lintas-node.
Anda tidak perlu mengasumsikan tingkat kegagalan tertentu untuk menerima realitas: jika sistem Anda berjalan cukup lama dan mencakup cukup banyak infrastruktur, partisi akan terjadi.
Apa arti “toleransi partisi” dalam praktik
Toleransi partisi berarti sistem Anda dirancang untuk terus beroperasi selama pemisahan—meskipun node tidak bisa sepakat atau mengonfirmasi apa yang dilihat sisi lain. Itu memaksa pilihan: terus melayani permintaan (mengorbankan konsistensi) atau menghentikan/menolak beberapa permintaan (mempertahankan konsistensi).
Momen Kunci: Memilih Konsistensi atau Ketersediaan Saat Terjadi Pemisahan
Setelah Anda memiliki replikasi, partisi hanyalah putusnya komunikasi: dua bagian sistem Anda tidak bisa berkomunikasi dengan andal untuk sementara. Replika masih berjalan, pengguna masih mengklik tombol, dan layanan Anda masih menerima permintaan—tetapi replika tidak bisa sepakat tentang kebenaran terbaru.
Itulah tegangan CAP dalam satu kalimat: saat partisi, Anda harus memilih memprioritaskan Konsistensi (C) atau Ketersediaan (A). Anda tidak bisa mendapatkan keduanya sekaligus.
Jika Anda memilih Konsistensi (C)
Anda berkata: “Saya lebih memilih benar daripada responsif.” Ketika sistem tidak bisa memastikan bahwa sebuah permintaan akan menjaga semua replika tetap sinkron, ia harus gagal atau menunggu.
Dampak praktis: beberapa pengguna melihat error, timeout, atau pesan “coba lagi”—terutama untuk operasi yang mengubah data. Ini umum ketika Anda lebih memilih menolak pembayaran daripada risiko penagihan ganda, atau memblokir reservasi kursi daripada oversell.
Jika Anda memilih Ketersediaan (A)
Anda berkata: “Saya lebih memilih merespons daripada memblokir.” Masing-masing sisi partisi akan terus menerima permintaan, meski tidak bisa berkoordinasi.
Dampak praktis: pengguna mendapat respons sukses, tetapi data yang dibaca mungkin kadaluwarsa, dan pembaruan simultan bisa konflik. Anda kemudian bergantung pada rekonsiliasi nanti (aturan merge, last-write-wins, tinjauan manual, dll.).
Pilihan bisa berbeda per operasi
Ini tidak selalu pengaturan global tunggal. Banyak produk memadukan strategi:
- Baca vs tulis: biarkan baca tetap tersedia, tetapi buat tulis lebih ketat.
- Aksi kritikal vs non-kritikal: tegakkan konsistensi untuk uang, identitas, dan inventori; izinkan ketersediaan untuk feed, analitik, “like,” atau profil yang di-cache.
Momen kuncinya adalah memutuskan—per operasi—apa yang lebih buruk: memblokir pengguna sekarang, atau memperbaiki kebenaran yang konflik nanti.
Kesalahpahaman Umum: Lebih dari Sekadar Slogan “Pilih Dua”
Mulai kecil, skala nanti
Mulai di tier gratis dan naikkan hanya saat prototipe Anda membutuhkan kapasitas lebih.
Slogan “pilih dua” mudah diingat, tetapi sering menyesatkan orang menjadi berpikir CAP adalah menu tiga fitur di mana Anda hanya boleh menyimpan dua selamanya. CAP membahas apa yang terjadi ketika jaringan berhenti bekerjasama: saat partisi (atau hal apa pun yang tampak seperti itu), sistem terdistribusi harus memilih antara mengembalikan jawaban konsisten dan tetap tersedia untuk setiap permintaan.
Salah kaprah 1: “Saya akan memilih C dan A lalu menghindari partisi”
Di sistem nyata, partisi bukanlah pengaturan yang bisa Anda matikan. Jika sistem Anda mencakup mesin, rak, zona, atau region, maka pesan bisa tertunda, hilang, diurutkan ulang, atau dialihkan aneh. Itu adalah partisi dari perspektif perangkat lunak: node tidak bisa cukup baik untuk berkoordinasi.
Bahkan jika jaringan fisik baik, kegagalan di tempat lain menghasilkan efek yang sama—node kelebihan beban, pause GC, tetangga berisik, DNS yang bermasalah, load balancer yang flakey. Hasilnya sama: beberapa bagian sistem tidak bisa saling bicara cukup baik untuk berkoordinasi.
Salah kaprah 2: “Partisi adalah kasus pinggiran yang jarang”
Aplikasi tidak mengalami “partisi” sebagai peristiwa biner yang rapi. Mereka mengalami lonjakan latensi dan timeout. Jika permintaan timeout setelah 200 ms, tidak penting apakah paket tiba pada 201 ms atau tidak pernah tiba sama sekali: aplikasi harus memutuskan apa yang dilakukan selanjutnya. Dari sudut aplikasi, komunikasi lambat sering tak bisa dibedakan dari komunikasi rusak.
Salah kaprah 3: “Sistem itu CP atau AP saja”
Banyak sistem nyata adalah kebanyakan konsisten atau kebanyakan tersedia, tergantung konfigurasi dan kondisi operasi. Timeout, kebijakan retry, ukuran quorum, dan opsi “read your writes” bisa menggeser perilaku.
Dalam kondisi normal, sebuah basis data mungkin tampak sangat konsisten; saat stres atau gangguan lintas-region, ia mungkin mulai menolak permintaan (memprioritaskan konsistensi) atau mengembalikan data lama (memprioritaskan ketersediaan).
CAP lebih sedikit soal memberi label produk dan lebih soal memahami pertukaran yang Anda buat ketika ketidaksepakatan terjadi—terutama ketika ketidaksepakatan itu disebabkan oleh kelambanan biasa.
Opsi Konsistensi yang Sebenarnya Bisa Anda Pilih
Diskusi CAP sering membuat konsistensi terdengar biner: “sempurna” atau “semua boleh.” Sistem nyata menawarkan menu jaminan, masing-masing dengan pengalaman pengguna berbeda ketika replika berselisih atau link jaringan putus.
Konsistensi kuat (dan harganya saat kegagalan)
Konsistensi kuat (sering disebut “linearizable”) berarti setelah sebuah tulis diakui, setiap baca berikutnya—tak peduli replika mana—mengembalikan tulis itu.
Biayanya: selama partisi atau saat minoritas replika tidak dapat dijangkau, sistem mungkin menunda atau menolak baca/tulis untuk menghindari konflik. Pengguna merasakannya sebagai timeout, “coba lagi,” atau perilaku sementara hanya-baca.
Konsistensi eventual (dan yang mungkin dilihat pengguna)
Konsistensi eventual menjanjikan bahwa jika tidak ada pembaruan baru, seluruh replika akan konvergen. Ia tidak menjamin dua pengguna yang membaca saat yang sama akan melihat hal yang sama.
Yang mungkin dilihat pengguna: foto profil yang baru saja diperbarui “kembali,” penghitung yang tertinggal, atau pesan yang baru dikirim tidak terlihat di perangkat lain untuk beberapa saat.
Jaminan jembatan yang berguna
Anda sering bisa mendapatkan pengalaman yang lebih baik tanpa menuntut konsistensi kuat penuh:
- Read-your-writes: setelah Anda memperbarui sesuatu, Anda tidak akan membaca versi lama milik Anda sendiri.
- Monotonic reads: setelah Anda melihat versi N, Anda tidak akan kembali ke versi N-1.
- Causal consistency: jika peristiwa B bergantung pada A (membalas setelah membaca pesan), semua orang melihat A sebelum B.
Jaminan ini cocok dengan cara orang berpikir (“jangan tunjukkan perubahan saya menghilang”) dan lebih mudah dipertahankan selama kegagalan parsial.
Memilih level konsistensi berdasarkan ekspektasi
Mulailah dengan janji kepada pengguna, bukan jargon:
- Jika baca yang salah menciptakan kerugian tak dapat dipulihkan (transfer uang, reservasi inventori, perubahan izin), condong ke konsistensi lebih kuat dan terima ketidaktersediaan sementara.
- Jika fitur dapat ditoleransi dengan ketidaksepakatan singkat (like, hitungan tampilan, peringkat feed), eventual atau causal consistency biasanya cocok.
- Jika sakit utama adalah kebingungan pribadi (“saya menyimpannya—kenapa saya tidak melihatnya?”), prioritaskan read-your-writes dan monotonic reads.
Konsistensi adalah pilihan produk: definisikan apa yang tampak “salah” bagi pengguna, lalu pilih jaminan paling lemah yang mencegah kesalahan itu.
Ketersediaan sebagai Keputusan Produk, Bukan Sekadar Angka Uptime
Amankan percobaan ulang
Tambahkan kunci idempotensi dan handler yang aman terhadap retry untuk menghindari efek ganda saat timeout.
Ketersediaan dalam CAP bukan metrik pameran (“lima sembilan”)—ia adalah janji yang Anda buat kepada pengguna tentang apa yang terjadi ketika sistem tidak bisa yakin.
Sukses cepat vs. sukses akurat
Saat replika tidak bisa sepakat, Anda sering memilih antara:
- Sukses cepat: kembalikan sesuatu dengan cepat (meski mungkin kadaluwarsa).
- Sukses akurat: kembalikan hanya ketika Anda bisa membuktikan jawabannya up-to-date.
Pengguna merasakan ini sebagai “aplikasi bekerja” versus “aplikasi benar.” Tidak ada yang lebih baik secara universal; pilihan tergantung pada apa arti “salah” di produk Anda. Feed sosial sedikit telat itu menyebalkan. Saldo rekening yang kadaluwarsa bisa berbahaya.
“Fail closed” vs. “fail open”
Dua perilaku umum muncul saat ketidakpastian:
- Fail closed: menolak permintaan (error, timeout, mode hanya-baca). Anda melindungi kebenaran, tetapi pengguna bisa terblokir.
- Fail open: melayani respons best-effort (data cache, replika lokal, tulis yang diantre). Anda mempertahankan alur, tetapi bisa menampilkan hasil yang tidak konsisten.
Ini bukan keputusan murni teknis; ini keputusan kebijakan. Produk harus mendefinisikan apa yang boleh ditampilkan dan apa yang tidak boleh ditebak.
Ketersediaan parsial tetaplah ketersediaan
Ketersediaan jarang hitam-putih. Saat pemisahan, Anda mungkin melihat ketersediaan parsial: beberapa region, jaringan, atau grup pengguna berhasil sementara yang lain gagal. Ini bisa desain sengaja (tetap melayani di mana replika lokal sehat) atau kecelakaan (imbalans routing, jangkauan quorum yang tidak merata).
Mode terdegradasi: pertahankan inti, batasi risiko
Jalan tengah praktis adalah mode terdegradasi: terus melayani aksi-aksi aman sambil membatasi yang berisiko. Misalnya, izinkan penelusuran dan browsing, tetapi sementara nonaktifkan “transfer dana”, “ubah kata sandi”, atau operasi lain di mana kebenaran dan keunikan penting.
Contoh Konkret: Memadankan Pilihan CAP ke Kasus Penggunaan
CAP terasa abstrak sampai Anda memetakannya ke apa yang dialami pengguna selama pemisahan jaringan: apakah Anda lebih suka sistem terus merespons, atau berhenti dan menghindari pengembalian (atau penerimaan) data yang bertentangan?
Inventori dan pemesanan: risiko oversell vs. outage checkout
Bayangkan dua data center yang sama-sama menerima pesanan sementara mereka tidak bisa saling bicara.
Jika Anda menjaga flow checkout tersedia, setiap sisi mungkin menjual “barang terakhir” dan Anda akan oversell. Itu bisa diterima untuk barang berisiko rendah (Anda mengatur backorder atau minta maaf), tetapi menyakitkan untuk rilis inventori terbatas.
Jika Anda memilih perilaku konsistensi-pertama, Anda mungkin memblokir pesanan baru ketika tidak bisa mengonfirmasi stok secara global. Pengguna melihat “coba lagi nanti,” tetapi Anda menghindari menjual barang yang tidak bisa dipenuhi.
Pembayaran dan saldo: pola prioritas-kebenaran (dan alasannya)
Uang adalah domain klasik “salah itu mahal.” Jika dua replika menerima penarikan secara independen selama partisi, sebuah akun bisa menjadi negatif.
Sistem sering memilih konsistensi saat menulis yang kritikal: menolak atau menunda aksi jika tidak bisa mengonfirmasi saldo terbaru. Anda akan menukar beberapa ketersediaan (gagal pembayaran sementara) dengan kebenaran, auditability, dan kepercayaan.
Chat, feed, analitik: “tersedia dengan data sedikit kadaluwarsa” biasanya oke
Dalam chat dan feed sosial, pengguna biasanya mentolerir ketidakkonsistenan kecil: pesan tiba beberapa detik terlambat, jumlah like meleset, metrik tampilan terupdate belakangan.
Di sini, merancang untuk ketersediaan bisa menjadi pilihan produk yang baik, selama Anda jelas elemen mana yang “akhirnya akan benar” dan Anda bisa menggabungkan pembaruan dengan rapi.
Intinya: tradeoff Anda adalah keputusan bisnis
Pilihan CAP yang “benar” bergantung pada biaya salah: refund, paparan hukum, kepercayaan pengguna, atau kekacauan operasional. Putuskan di mana Anda bisa menerima kekadaluarsa sementara—dan di mana Anda harus fail closed.
Pola Desain yang Mewujudkan Tradeoff Anda
Setelah Anda memutuskan apa yang dilakukan saat pemisahan jaringan, Anda memerlukan mekanisme yang membuat keputusan itu nyata. Pola-pola ini muncul di berbagai basis data, sistem pesan, dan API—bahkan jika produk tidak pernah menyebut “CAP.”
Quorum: kesepakatan mayoritas
Quorum hanyalah “mayoritas replika setuju.” Jika Anda punya 5 salinan data, mayoritas adalah 3.
Dengan mensyaratkan baca dan/atau tulis mengontak mayoritas, Anda mengurangi kemungkinan mengembalikan data kadaluwarsa atau konflik. Misalnya, jika sebuah tulis harus diakui oleh 3 replika, lebih sulit bagi dua grup terisolasi untuk sama-sama menerima “kebenaran” berbeda.
Trade-off-nya adalah kecepatan dan jangkauan: jika Anda tidak bisa mencapai mayoritas (karena partisi atau outage), sistem mungkin menolak operasi—memilih konsistensi daripada ketersediaan.
Timeout, retry, dan backoff membentuk persepsi ketersediaan
Banyak masalah “ketersediaan” sebenarnya bukan kegagalan keras melainkan respons yang lambat. Menetapkan timeout pendek membuat sistem terasa responsif, tetapi juga meningkatkan peluang Anda menganggap keberhasilan yang lambat sebagai kegagalan.
Retry bisa pulihkan blip sementara, tetapi retry agresif bisa membebani layanan yang sedang berjuang. Backoff (menunggu sedikit lebih lama antar retry) dan jitter (acak) membantu mencegah retry berubah menjadi ledakan trafik.
Kuncinya adalah menyelaraskan pengaturan ini dengan janji Anda: “selalu merespons” biasanya berarti lebih banyak retry dan fallback; “tidak pernah berbohong” berarti batasan lebih ketat dan error yang jelas.
Penanganan konflik saat Anda mengizinkan divergensi
Jika Anda memilih tetap tersedia selama partisi, replika bisa menerima pembaruan berbeda dan Anda harus merekonsiliasi nanti. Pendekatan umum meliputi:
- Last-write-wins (LWW): ambil pembaruan dengan timestamp terbaru. Sederhana, tetapi bisa menghapus perubahan valid jika jam tidak sinkron.
- Version vectors (tingkat tinggi): lampirkan “sejarah” kecil yang membantu mendeteksi apakah pembaruan bersamaan atau satu menggantikan yang lain.
- Aturan merge: definisikan bagaimana menggabungkan perubahan (mis. union item keranjang; counter dijumlah; profil pilih field yang tidak kosong). Ini sering bekerja terbaik jika dirancang sejak awal ke model data.
Idempoten: membuat retry aman
Retry bisa menciptakan duplikasi: penagihan kartu ganda atau pengiriman pesanan dua kali. Idempoten mencegah itu.
Pola umum adalah idempotency key (ID permintaan) yang dikirim bersama setiap permintaan. Server menyimpan hasil pertama dan mengembalikan hasil yang sama untuk pengulangan—sehingga retry meningkatkan ketersediaan tanpa merusak data.
Cara Memvalidasi Asumsi CAP Anda di Dunia Nyata
Modelkan perilaku CP dengan aman
Jalankan layanan Go dengan PostgreSQL dan tambahkan aturan mirip kuorum di bagian yang membutuhkan ketepatan.
Kebanyakan tim “memilih” sikap CAP di papan tulis—lalu menemukan di produksi bahwa sistem berperilaku berbeda saat stres. Validasi berarti sengaja menciptakan kondisi di mana tradeoff CAP menjadi terlihat, dan memeriksa apakah sistem bereaksi sesuai desain.
Uji partisi dengan sengaja (dengan aman)
Anda tidak perlu benar-benar memotong kabel untuk belajar sesuatu. Gunakan fault injection terkontrol di staging (dan hati-hati di produksi) untuk mensimulasikan partisi:
- Blackhole traffic antar layanan atau node tertentu (drop paket tanpa menutup koneksi) untuk meniru split diam-diam.
- Hentikan link dengan memblokir port atau aturan security group antar replika/region.
- Tambahkan latensi ekstrem dan kehilangan paket sehingga timeout dan retry berperilaku seperti partisi.
- Paksa isolasi leader (mis. isolasi primary dari quorum) untuk melihat apakah Anda gagal “konsisten” atau “tersedia.”
Tujuannya adalah menjawab pertanyaan konkret: Apakah tulis ditolak atau diterima? Apakah baca menampilkan data lama? Apakah sistem pulih otomatis, dan berapa lama rekonsiliasi berlangsung?
Jika Anda ingin memvalidasi perilaku ini lebih awal (sebelum berinvestasi berminggu-minggu menyambungkan layanan), membantu jika membuat prototipe realistis cepat. Misalnya, tim yang menggunakan Koder.ai sering memulai dengan menghasilkan layanan kecil (biasanya backend Go dengan PostgreSQL plus UI React) lalu iterasi pada perilaku seperti retry, idempotency key, dan alur “mode terdegradasi” di lingkungan sandbox.
Pantau sinyal yang mengungkap rasa sakit CAP
Cek uptime tradisional tidak akan menangkap “tersedia tapi salah” perilaku. Lacak:
- Tingkat error per jenis operasi (baca vs tulis vs pembaruan kondisional).
- Indikator baca kadaluwarsa (pelanggaran read-your-writes, mismatch versi/ETag, metrik lag).
- Divergensi replika (lag replikasi, jumlah apply gagal, tingkat konflik).
- Timeout dan retry (sering tanda pertama munculnya split).
Runbook dan komunikasi ke pengguna
Operator butuh tindakan yang sudah diputuskan saat partisi: kapan membekukan tulis, kapan fail over, kapan menurunkan fitur, dan bagaimana memvalidasi keamanan re-merge.
Rencanakan juga perilaku yang terlihat pengguna. Jika Anda memilih konsistensi, pesannya mungkin “Kami belum bisa mengonfirmasi pembaruan Anda sekarang—silakan coba lagi.” Jika memilih ketersediaan, jelaskan: “Pembaruan Anda mungkin butuh beberapa menit untuk muncul di semua tempat.” Perkataan yang jelas mengurangi beban dukungan dan menjaga kepercayaan.
Daftar Periksa CAP Praktis untuk Keputusan Sistem Sehari-hari
Saat membuat keputusan sistem, CAP paling berguna sebagai audit cepat “apa yang rusak saat terjadi pemisahan?”—bukan debat teoritis. Gunakan daftar periksa ini sebelum memilih fitur basis data, strategi caching, atau mode replikasi.
1) Daftar periksa CAP singkat
Tanyakan ini berurutan:
- Apa yang harus benar? (mis. “saldo bank tidak boleh negatif,” “inventori tidak boleh oversell,” “izin harus akurat”)
- Apa yang harus tetap hidup? (mis. endpoint checkout, login, katalog hanya-baca)
- Apa yang bisa menurun sementara? (mis. analitik, rekomendasi, avatar profil, “last seen”)
Jika partisi jaringan terjadi, Anda memutuskan mana dari ini yang akan Anda lindungi terlebih dahulu.
2) Putuskan per tipe data dan per endpoint
Hindari pengaturan global tunggal seperti “kami adalah sistem AP.” Sebaliknya, putuskan per:
- Tipe data: uang vs like vs log
- Endpoint: “place order” vs “view order” vs “track shipment”
Contoh: selama partisi, Anda mungkin memblokir tulis ke payments (prioritaskan konsistensi) tetapi menjaga baca untuk product_catalog tersedia dengan data cache.
3) Definisikan “ketidakkonsistenan yang bisa diterima” secara konkret
Tuliskan apa yang bisa Anda toleransi, dengan contoh:
- Batas waktu: “hitung mungkin tertinggal 5–10 menit”
- Magnitudo: “inventori mungkin meleset ±1 untuk barang permintaan rendah”
- Level field: “ETA pengiriman bisa kadaluwarsa; total pesanan tidak boleh”
- Kata yang terlihat pengguna: “tampilkan ‘pending’ daripada status pasti”
Jika Anda tidak bisa menjelaskan ketidakkonsistenan dengan contoh sederhana, Anda akan kesulitan mengujinya dan menjelaskan insiden.
4) Kesimpulan + bacaan lanjut
- Partisi mengubah jaminan yang "bagus untuk dimiliki" menjadi pilihan yang dipaksakan.
- Buat pilihan itu eksplisit per endpoint, dan dokumentasikan ketidakkonsistenan yang dapat diterima.
Topik berikut yang cocok dipelajari setelah ini: konsensus (/blog/consensus-vs-cap), model konsistensi (/blog/consistency-models-explained), dan SLOs/error budgets (/blog/sre-slos-error-budgets).