Apa yang dibahas di posting ini (dan mengapa penting)
Snowflake memopulerkan ide sederhana tapi berdampak luas dalam gudang data cloud: memisahkan penyimpanan data dan compute query. Pemisahan itu mengubah dua masalah sehari-hari untuk tim data—bagaimana warehouse melakukan scaling dan bagaimana Anda membayarnya.
Alih-alih memperlakukan warehouse seperti satu “kotak” tetap (di mana lebih banyak pengguna, lebih banyak data, atau query yang lebih kompleks saling berebut sumber daya yang sama), model Snowflake memungkinkan Anda menyimpan data sekali dan memutar jumlah compute yang tepat saat dibutuhkan. Hasilnya seringkali waktu-jawab lebih cepat, lebih sedikit bottleneck saat puncak penggunaan, dan kontrol yang lebih jelas atas apa yang berbiaya (dan kapan).
Posting ini menjelaskan, dengan bahasa sederhana, apa arti sebenarnya memisahkan storage dan compute—dan bagaimana itu memengaruhi:
- Concurrency (banyak orang menjalankan query bersamaan)
- Elastic scaling (menaikkan atau menurunkan compute)
- Perilaku biaya (membayar compute hanya saat berjalan, ditambah biaya penyimpanan terus menerus)
Kami juga menunjukkan di mana model ini tidak serta-merta menyelesaikan segalanya—karena beberapa kejutan biaya dan performa datang dari desain workload, bukan platformnya sendiri.
Tema #2: mengapa ekosistem bisa sama pentingnya dengan kecepatan mentah
Platform yang cepat bukanlah seluruh cerita. Untuk banyak tim, time-to-value bergantung pada apakah Anda dapat dengan mudah menghubungkan warehouse ke alat yang sudah Anda gunakan—pipeline ETL/ELT, dashboard BI, alat katalog/tata kelola, kontrol keamanan, dan sumber data mitra.
Ekosistem Snowflake (termasuk pola berbagi data dan distribusi ala marketplace) dapat memperpendek timeline implementasi dan mengurangi engineering kustom. Posting ini membahas seperti apa “kedalaman ekosistem” dalam praktik, dan bagaimana mengevaluasinya untuk organisasi Anda.
Siapa yang dituju
Panduan ini ditulis untuk pemimpin data, analis, dan pengambil keputusan non-spesialis—siapa pun yang perlu memahami trade-off di balik arsitektur Snowflake, scaling, biaya, dan pilihan integrasi tanpa tenggelam dalam jargon vendor.
Sebelum pemisahan: mengapa gudang tradisional mencapai batas
Gudang data tradisional dibangun di atas asumsi sederhana: Anda membeli (atau menyewa) jumlah hardware tetap, lalu menjalankan semuanya pada kotak atau cluster yang sama. Itu bekerja baik ketika workload dapat diprediksi dan pertumbuhan bertahap—tetapi menciptakan batas struktural setelah volume data dan jumlah pengguna meningkat cepat.
Model klasik: cluster tetap dan perencanaan kapasitas yang hati-hati
Sistem on-prem dan deployment cloud “lift-and-shift” awal biasanya terlihat seperti ini:
- Satu cluster MPP (massively parallel processing) menangani storage, CPU, dan memori bersama-sama.
- Anda mengatur ukuran cluster untuk puncak permintaan, karena mengubah ukuran lambat, berisiko, atau memerlukan downtime.
- Perencanaan kapasitas menjadi proyek berulang: memproyeksikan pertumbuhan, membenarkan anggaran, memesan hardware, memasang, migrasi.
Bahkan ketika vendor menawarkan “node,” pola inti tetap sama: scaling biasanya berarti menambah node yang lebih besar atau lebih banyak node ke satu lingkungan bersama.
Titik sakit: scaling lambat, pemborosan biaya, dan antrean
Desain ini menimbulkan beberapa masalah umum:
- Scaling lambat: Jika crunch laporan triwulanan tiba-tiba butuh lebih banyak tenaga, Anda tidak selalu dapat menambahnya dengan cepat. Anda menunggu, atau Anda overprovision “untuk berjaga-jaga.”
- Kapasitas menganggur: Cluster yang diukur untuk puncak sering menganggur sebagian besar waktu—tetapi Anda tetap membayar (biaya hardware, lisensi, waktu ops).
- Antrean saat beban: Ketika banyak tim menjalankan query bersamaan, mereka saling berebut sumber daya. Job berat bisa memblokir dashboard interaktif, menyebabkan timeouts, pemangku kepentingan frustrasi, dan aturan seperti “jangan jalankan query itu selama jam kerja.”
Karena gudang ini terikat erat ke lingkungan mereka, integrasi sering tumbuh secara organik: script ETL kustom, connector buatan tangan, dan pipeline satu kali. Mereka bekerja—sampai skema berubah, sistem hulu pindah, atau alat baru diperkenalkan. Menjaga semuanya berjalan bisa terasa seperti pemeliharaan konstan ketimbang kemajuan stabil.
Ide inti: memisahkan storage dan compute
Gudang data tradisional sering mengikat dua tugas yang sangat berbeda: storage (tempat data Anda berada) dan compute (tenaga yang membaca, join, agregasi, dan menulis data itu).
Storage vs. compute (dengan istilah sederhana)
Storage seperti pantry jangka panjang: tabel, file, dan metadata disimpan dengan aman dan murah, dirancang untuk tahan lama dan selalu tersedia.
Compute seperti staf dapur: kumpulan CPU dan memori yang benar-benar “memasak” query Anda—menjalankan SQL, mengurutkan, memindai, membangun hasil, dan menangani banyak pengguna sekaligus.
Perubahan kunci: menskalakan keduanya secara independen
Snowflake memisahkan keduanya sehingga Anda dapat menyesuaikan satu tanpa memaksa yang lain berubah.
- Jika volume data tumbuh, Anda menambah storage (biasanya bertahap dan relatif dapat diprediksi).
- Jika lalu lintas laporan melonjak, Anda menambah compute (dengan meresize atau menambahkan virtual warehouses) tanpa memindahkan atau menduplikasi data dasar.
Secara praktis, ini mengubah operasi harian: Anda tidak perlu “membeli compute berlebih” hanya karena storage tumbuh, dan Anda dapat mengisolasi workload (mis. analis vs. job ETL) sehingga mereka tidak saling memperlambat.
Ini bukanlah
Pemisahan ini kuat, tetapi bukan sulap.
- Ini bukan “scaling gratis.” Warehouse yang lebih besar atau lebih banyak umumnya berarti pengeluaran compute lebih tinggi.
- Ini bukan penghematan otomatis setiap saat. Query buruk, jadwal refresh yang tidak perlu, atau warehouse yang selalu hidup masih bisa memicu biaya.
- Ini bukan alasan untuk mengabaikan perencanaan. Anda tetap harus memilih ukuran warehouse, mengatur auto-suspend, dan menyelaraskan compute dengan pola penggunaan bisnis.
Nilainya adalah kontrol: membayar storage dan compute sesuai kebutuhan masing-masing, dan mencocokkannya dengan apa yang tim Anda benar-benar butuhkan.
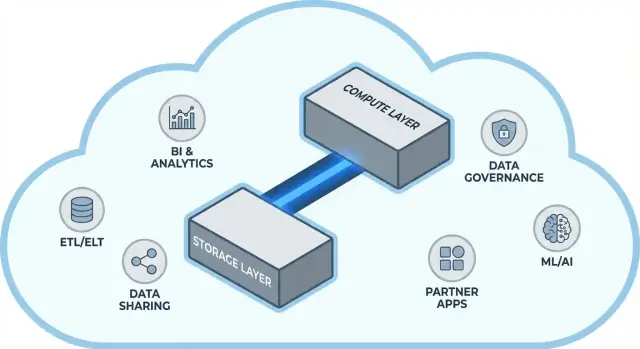
Arsitektur Snowflake dengan istilah sederhana
Snowflake paling mudah dipahami sebagai tiga lapisan yang bekerja bersama, tetapi dapat diskalakan secara independen.
1) Storage: object storage cloud
Tabel Anda pada akhirnya hidup sebagai file data di object storage penyedia cloud Anda (mis. S3, Azure Blob, atau GCS). Snowflake mengelola format file, kompresi, dan organisasinya untuk Anda. Anda tidak “melampirkan disk” atau mengatur ukuran volume storage—storage tumbuh seiring data bertambah.
2) Compute: virtual warehouses
Compute dikemas sebagai virtual warehouses: klaster CPU/memori independen yang mengeksekusi query. Anda dapat menjalankan beberapa warehouses terhadap data yang sama pada saat bersamaan. Itu perbedaan kunci dari sistem lama di mana workload berat cenderung berebut satu pool sumber daya.
Lapisan layanan terpisah menangani “otak” sistem: autentikasi, parsing dan optimisasi query, manajemen transaksi/metadata, dan koordinasi. Lapisan ini memutuskan bagaimana menjalankan query secara efisien sebelum compute menyentuh data.
Alur sebuah query
Saat Anda mengirim SQL, lapisan services Snowflake mem-parse, membangun execution plan, lalu menyerahkan plan itu ke virtual warehouse yang dipilih. Warehouse membaca hanya file data yang diperlukan dari object storage (dan mendapat manfaat dari caching saat memungkinkan), memprosesnya, dan mengembalikan hasil—tanpa memindahkan data dasar secara permanen ke dalam warehouse.
Concurrency dan isolasi (tanpa jargon)
Jika banyak orang menjalankan query sekaligus, Anda bisa:
- menggunakan warehouse terpisah untuk tim/workload berbeda (isolasi workload), atau
- mengaktifkan multi-cluster warehouses sehingga Snowflake dapat menambah klaster compute saat permintaan melonjak, lalu mengecil kembali.
Itu adalah landasan arsitektural di balik performa Snowflake dan kontrol terhadap “noisy neighbor.”
Scaling dan concurrency: apa yang benar-benar berubah
Perubahan praktis besar Snowflake adalah Anda menskalakan compute secara independen dari data. Alih-alih “warehouse membesar,” Anda mendapatkan kemampuan untuk mengatur sumber daya naik/turun per workload—tanpa menyalin tabel, repartition disk, atau menjadwalkan downtime.
Elastisitas: meresize compute tanpa memindahkan data
Di Snowflake, virtual warehouse adalah mesin compute yang menjalankan query. Anda dapat mengubah ukurannya (mis. dari Small ke Large) dalam hitungan detik, dan data tetap di storage bersama. Itu berarti tuning performa sering menjadi pertanyaan sederhana: “Apakah workload ini butuh tenaga lebih sekarang?”
Ini juga memungkinkan burst sementara: scale up untuk penutupan akhir bulan, lalu scale down saat lonjakan selesai.
Concurrency: lebih sedikit antrean
Sistem tradisional sering memaksa tim berbeda berbagi compute yang sama, yang membuat jam sibuk seperti antre di kasir.
Snowflake memungkinkan Anda menjalankan warehouse terpisah per tim atau per workload—misalnya satu untuk analis, satu untuk dashboard, dan satu untuk ETL. Karena warehouse ini membaca data dasar yang sama, Anda mengurangi masalah “dashboard saya memperlambat laporan Anda” dan membuat performa lebih dapat diprediksi.
Trade-off yang akan Anda lihat
Compute elastis bukanlah keberhasilan otomatis. Beberapa jebakan umum termasuk:
- Cold starts: warehouse yang disuspensi butuh waktu untuk resume, yang menambah latensi untuk job yang jarang.
- Pilihan right-sizing: oversize membuang-buang uang; undersize menyebabkan query lambat dan frustrasi.
- Perlu guardrail: gunakan auto-suspend/auto-resume, resource monitors, dan kepemilikan jelas agar warehouse tidak terbiarkan menyala atau berkembang tanpa kendali.
Perubahan bersih: scaling dan concurrency bergeser dari proyek infrastruktur menjadi keputusan operasi sehari-hari.
Model biaya: di mana penghematan terjadi (dan di mana tidak)
Sesuaikan kapasitas dengan pembatas
Buat alat admin cepat untuk keputusan penentuan ukuran gudang data dan aturan isolasi beban kerja.
Bagaimana penagihan Snowflake sebenarnya bekerja
“Bayar sesuai pakai” Snowflake pada dasarnya dua meter yang berjalan paralel:
- Compute: ditagih untuk waktu saat virtual warehouse berjalan (dalam kredit).
- Storage: ditagih untuk jumlah data yang disimpan (ditambah storage ekstra untuk fitur seperti Time Travel/Fail-safe).
Pembagian ini adalah tempat penghematan dapat terjadi: Anda bisa menyimpan banyak data dengan biaya relatif murah sambil menyalakan compute hanya saat dibutuhkan.
Di mana biaya merayap naik
Kebanyakan pengeluaran “tak terduga” datang dari perilaku compute daripada storage mentah. Pemicu umum meliputi:
- Warehouse terlalu besar (memilih ukuran lebih besar dari yang diperlukan)
- Workload selalu hidup (warehouse dibiarkan berjalan semalam atau akhir pekan)
- Query tidak efisien (scan tak terfilter, join tak perlu, transformasi berat yang berjalan berulang)
- Pola concurrency tinggi (banyak dashboard kecil melakukan refresh konstan)
Memisahkan storage dan compute tidak otomatis membuat query efisien—SQL buruk tetap bisa membakar kredit dengan cepat.
Kontrol praktis yang efektif di dunia nyata
Anda tidak perlu departemen keuangan khusus untuk ini—hanya beberapa guardrail:
- Auto-suspend / auto-resume untuk menghentikan pembayaran waktu menganggur
- Resource monitors untuk memberi peringatan atau membatasi konsumsi kredit per warehouse/tim
- Penjadwalan (jalankan batch pada jendela tertentu; jeda DEV/TEST di luar jam kerja)
- Right-sizing dan menguji ukuran warehouse yang lebih kecil sebelum scale up
Jika digunakan dengan baik, model ini memberi imbalan pada disiplin: compute yang berjalan singkat dan berukuran tepat dipasangkan dengan pertumbuhan storage yang dapat diprediksi.
Berbagi data dan kolaborasi sebagai fitur kelas satu
Snowflake memperlakukan sharing sebagai bagian yang didesain ke dalam platform—bukan tambahan yang ditempelkan ke export, file drop, dan ETL satu-kali.
Berbagi tanpa menyalin (dalam banyak kasus)
Alih-alih mengirim ekstrak, Snowflake dapat membiarkan akun lain meng-query data yang sama melalui “share” yang aman. Dalam banyak skenario, data tidak perlu diduplikasi ke warehouse kedua atau didorong ke object storage untuk diunduh. Konsumen melihat database/tabel yang dibagikan seolah lokal, sementara penyedia tetap mengendalikan apa yang diekspos.
Pendekatan “decoupled” ini berharga karena mengurangi sprawl data, mempercepat akses, dan menurunkan jumlah pipeline yang harus Anda bangun dan pelihara.
Pola kolaborasi umum
Berbagi dengan mitra dan pelanggan: Vendor dapat menerbitkan dataset kurasi ke pelanggan (mis. analytics penggunaan atau data referensi) dengan batasan jelas—hanya skema, tabel, atau view yang diizinkan.
Berbagi domain internal: Tim pusat dapat mengekspos dataset yang tersertifikasi ke product, finance, dan operations tanpa membuat setiap tim membangun salinan sendiri. Itu mendukung budaya “satu sumber kebenaran” sambil tetap membiarkan tim menjalankan compute mereka sendiri.
Kolaborasi yang diatur: Proyek bersama (mis. dengan agen, pemasok, atau anak perusahaan) dapat bekerja dari dataset bersama sambil menjaga kolom sensitif dimask dan akses dicatat.
Batasan yang perlu direncanakan
Sharing bukanlah “atur sekali dan lupa.” Anda tetap perlu:
- Tata kelola: kepemilikan jelas, review akses, dan kebijakan untuk data PII/terregulasi.
- Kontrak dan ekspektasi: siapa yang membayar compute, SLA, retensi, dan apa yang terjadi saat definisi berubah.
- Dapat ditemukan: tanpa katalog dan penamaan yang baik, orang tidak akan menemukan (atau mempercayai) data bersama yang benar. Selaraskan share dengan dokumentasi dan katalog data jika ada.
Gudang yang cepat bernilai, tetapi kecepatan saja jarang menentukan apakah proyek selesai tepat waktu. Yang sering membuat perbedaan adalah ekosistem di sekitar platform: koneksi siap pakai, alat, dan know-how yang mengurangi pekerjaan kustom.
Dalam praktik, ekosistem mencakup:
- Connector ke sumber dan tujuan data (aplikasi SaaS, database, alat streaming)
- Alat mitra untuk ingest, transformasi, BI, kualitas data, dan observability
- Aplikasi dan integrasi native yang berjalan dekat dengan data
- Template dan arsitektur referensi (model umum, pola, panduan deployment)
- Pengetahuan komunitas: contoh, forum, meetup, dan ketersediaan tenaga kerja
Mengapa ekosistem sering mengalahkan benchmark untuk kecepatan pengiriman
Benchmark mengukur potongan sempit performa dalam kondisi terkontrol. Proyek nyata menghabiskan sebagian besar waktu untuk:
- Memasukkan data secara andal dan inkremental
- Memodelkan, menguji, dan mendokumentasikan dataset
- Tugas operasional (monitoring, alerting, kontrol biaya)
- Tinjauan keamanan, kontrol akses, dan audit
Jika platform Anda memiliki integrasi matang untuk langkah-langkah ini, Anda menghindari membangun dan memelihara glue code. Itu biasanya memperpendek timeline implementasi, meningkatkan keandalan, dan mempermudah pergantian tim atau vendor tanpa menulis ulang semuanya.
Lensa evaluasi sederhana: cakupan, kualitas, pemeliharaan
Saat menilai ekosistem, cari:
- Cakupan: mendukung sumber kunci Anda, alat BI, orkestrasi, dan kebutuhan tata kelola?
- Kualitas: connector aktif dipelihara, terdokumentasi baik, dan terbukti pada skala Anda?
- Pemeliharaan: berapa banyak usaha berkelanjutan yang diperlukan—upgrade, breaking change, debugging, dan dukungan?
Performa memberi Anda kapabilitas; ekosistem sering menentukan seberapa cepat Anda bisa mengubah kapabilitas itu menjadi hasil bisnis.
Ekosistem integrasi: memindahkan data masuk, keluar, dan digunakan
Miliki kode sumber Anda
Buat web app yang berfungsi dan ekspor kode sumber saat Anda siap memilikinya.
Snowflake bisa menjalankan query cepat, tetapi nilai muncul ketika data bergerak andal melalui stack Anda: dari sumber, ke Snowflake, dan keluar lagi ke alat yang dipakai orang setiap hari. “Last mile” biasanya yang menentukan apakah platform terasa mudah—atau terus-menerus rapuh.
Kategori integrasi utama yang harus direncanakan
Kebanyakan tim membutuhkan campuran:
- ELT/ETL untuk ingest dari database, aplikasi SaaS, file, dan object storage.
- BI dan analytics untuk dashboard, eksplorasi self-serve, dan semantic layer.
- Reverse ETL untuk mendorong data kurasi kembali ke CRM, marketing, dan sistem support.
- Orkestrasi untuk penjadwalan, dependensi, backfill, dan promosi environment.
- Streaming untuk event near-real-time dan change data capture (CDC).
- Alat ML untuk pipeline fitur, alur training, dan monitoring model.
Pertanyaan yang harus diajukan sebelum memilih connector
Tidak semua alat “kompatibel Snowflake” berperilaku sama. Saat evaluasi, fokus pada detail praktis:
- Apakah connector tersertifikasi/didukung (oleh siapa)? Apa jalur eskalasinya?
- Dapatkah menangani load inkremental dengan bersih (CDC, timestamp, high-water marks)?
- Bagaimana menangani schema drift—kolom baru, perubahan tipe, field yang dihapus?
- Apa jaminan pada retry, deduplikasi, dan exactly-once vs at-least-once?
Jangan abaikan operasional
Integrasi juga perlu kesiapan hari-ke-2: monitoring dan alerting, hook lineage/katalog, dan workflow respons insiden (ticketing, on-call, runbook). Ekosistem yang kuat bukan sekadar daftar logo—melainkan lebih sedikit kejutan saat pipeline gagal jam 2 pagi.
Tata kelola, keamanan, dan kepercayaan pada skala
Seiring pertumbuhan tim, bagian tersulit dari analytics sering bukan kecepatan—melainkan memastikan orang yang tepat mengakses data yang tepat, untuk tujuan yang tepat, dengan bukti bahwa kontrol bekerja. Fitur tata kelola Snowflake dibuat untuk realitas itu: banyak pengguna, banyak produk data, dan berbagi yang sering.
Dasar tata kelola yang benar-benar bertahan
Mulailah dengan peran yang jelas dan mindset least-privilege. Alih-alih memberi akses langsung ke individu, definisikan peran seperti ANALYST_FINANCE atau ETL_MARKETING, lalu berikan peran itu akses ke database, schema, tabel, dan (jika perlu) view tertentu.
Untuk field sensitif (PII, identifier finansial), gunakan masking policies sehingga orang bisa meng-query dataset tanpa melihat nilai mentah kecuali perannya memungkinkan. Padukan itu dengan auditing: catat siapa query apa, dan kapan, sehingga tim keamanan dan kepatuhan bisa menjawab pertanyaan tanpa menebak.
Mengapa tata kelola mengubah sharing dan self-service
Tata kelola yang baik membuat berbagi data lebih aman dan dapat diskalakan. Ketika model sharing Anda dibangun di atas peran, kebijakan, dan akses yang diaudit, Anda bisa dengan percaya diri memungkinkan self-service (lebih banyak pengguna mengeksplor data) tanpa membuka pintu ke eksposur yang tidak disengaja.
Ini juga mengurangi hambatan untuk upaya kepatuhan: kebijakan menjadi kontrol yang dapat diulang ketimbang pengecualian sekali-kali. Itu penting ketika dataset digunakan kembali lintas proyek, departemen, atau mitra eksternal.
Tips praktis yang mencegah sakit di masa depan
- Konvensi penamaan: standarisasi nama database/schema yang memberi sinyal tujuan dan sensitivitas (mis.
PROD_FINANCE, DEV_MARKETING, SHARED_PARTNER_X). Konsistensi mempercepat review dan mengurangi kesalahan.
- Pemisahan environment: pisahkan DEV/TEST/PROD secara logis, dengan kontrol lebih ketat di PROD. Perlakukan data produksi sebagai pengecualian, bukan default.
- Review akses: tetapkan cadence (bulanan untuk data berisiko tinggi, triwulanan untuk lainnya). Tinjau keanggotaan peran, user yang tidak aktif, dan peran istimewa.
Kepercayaan pada skala bukan soal satu kontrol “sempurna” melainkan sistem kebiasaan kecil yang dapat diandalkan yang membuat akses disengaja dan dapat dijelaskan.
Workload dan pola praktik terbaik
Beralih dari demo ke penerapan
Terapkan prototipe Anda dan iterasikan dengan snapshot serta rollback seiring perubahan kebutuhan.
Snowflake cenderung bersinar ketika banyak orang dan alat perlu meng-query data yang sama untuk alasan berbeda. Karena compute dikemas menjadi “warehouses” independen, Anda dapat memetakan tiap workload ke bentuk dan jadwal yang sesuai.
Analytics & dashboards: Tempatkan alat BI pada warehouse khusus yang ukurannya disesuaikan untuk volume query yang stabil dan dapat diprediksi. Ini menjaga refresh dashboard agar tidak diperlambat oleh eksplorasi ad hoc.
Analisis ad hoc: Beri analis warehouse terpisah (seringkali lebih kecil) dengan auto-suspend aktif. Anda mendapat iterasi cepat tanpa membayar waktu menganggur.
Data science & eksperimen: Gunakan warehouse yang diukur untuk scan lebih berat dan burst sesekali. Jika eksperimen melonjak, scale warehouse ini sementara tanpa memengaruhi pengguna BI.
Data apps & embedded analytics: Perlakukan lalu lintas aplikasi seperti layanan produksi—warehouse terpisah, timeout konservatif, dan resource monitors untuk mencegah kejutan pengeluaran.
Jika Anda membangun aplikasi data internal ringan (mis. portal ops yang meng-query Snowflake dan menampilkan KPI), jalur cepat adalah membuat scaffold React + API yang berfungsi dan iterasi dengan pemangku kepentingan. Platform seperti Koder.ai (platform vibe-coding yang membangun aplikasi web/server/mobile dari chat) dapat membantu tim mem-prototype aplikasi berbasis Snowflake dengan cepat, lalu mengekspor kode sumber saat Anda siap mengoperasionalkan.
Pola praktik terbaik yang bertahan
Aturan sederhana: pisahkan warehouses berdasarkan audiens dan tujuan (BI, ELT, ad hoc, ML, app). Padukan itu dengan kebiasaan query yang baik—hindari SELECT * luas, saring lebih awal, dan awasi join yang tidak efisien. Di sisi pemodelan, prioritaskan struktur yang cocok dengan cara orang query (seringkali semantic layer yang bersih atau marts yang terdefinisi baik), daripada meng-overoptimalkan layout fisik.
Kapan mempertimbangkan alternatif atau pelengkap
Snowflake bukan pengganti untuk segala hal. Untuk workload transaksi ber-throughput tinggi dan latensi rendah (tipikal OLTP), database khusus biasanya lebih cocok, dengan Snowflake digunakan untuk analytics, reporting, sharing, dan produk data turunannya. Setup hybrid umum—dan seringkali paling praktis.
Pertimbangan migrasi: apa yang harus direncanakan sebelum pindah
Migrasi ke Snowflake jarang sekadar “lift and shift.” Pemisahan storage/compute mengubah cara Anda mengukur, men-tune, dan membayar workload—jadi perencanaan di muka mencegah kejutan nanti.
Urutan migrasi yang praktis
Mulailah dengan inventaris: sumber data apa yang memberi makan gudang, pipeline mana yang mentransformasikannya, dashboard mana yang bergantung padanya, dan siapa pemilik tiap bagian. Prioritaskan berdasarkan dampak bisnis dan kompleksitas (mis. laporan finance kritis dulu, sandbox eksperimental belakangan).
Selanjutnya, konversi logika SQL dan ETL. Banyak SQL standar dapat dipindahkan, tetapi detail seperti fungsi, penanganan tanggal, kode prosedural, dan pola temp-table sering perlu ditulis ulang. Validasi hasil sejak dini: jalankan output paralel, bandingkan hitungan baris dan agregat, dan konfirmasi kasus tepi (null, zona waktu, logika deduplikasi). Akhirnya, rencanakan cutover: jendela freeze, jalur rollback, dan definisi selesai yang jelas untuk tiap dataset dan laporan.
Risiko tipikal yang perlu diwaspadai
Dependensi tersembunyi adalah yang paling umum: ekstrak spreadsheet, connection string hard-coded, job downstream yang tak ada yang ingat. Kejutan performa bisa terjadi saat asumsi tuning lama tidak berlaku (mis. terlalu banyak warehouse kecil, atau banyak query kecil tanpa mempertimbangkan concurrency). Lonjakan biaya biasanya berasal dari meninggalkan warehouse menyala, retry tak terkendali, atau duplikasi workload dev/test. Celah izin muncul saat migrasi dari peran kasar ke tata kelola yang lebih granular—uji termasuk percobaan user dengan prinsip least privilege.
Manajemen perubahan (jangan dilewatkan)
Tetapkan model kepemilikan (siapa pemilik data, pipeline, dan biaya), berikan pelatihan berbasis peran untuk analis dan engineers, dan definisikan rencana dukungan untuk minggu-minggu pertama setelah cutover (rotasi on-call, runbook insiden, dan tempat pelaporan masalah).
Memilih platform data modern bukan sekadar soal kecepatan benchmark puncak. Ini tentang apakah platform cocok untuk workload nyata Anda, cara kerja tim Anda, dan alat yang sudah Anda andalkan.
Daftar pemeriksaan evaluasi praktis
Gunakan pertanyaan ini untuk memandu shortlist dan percakapan dengan vendor:
- Workloads: Apakah Anda terutama menjalankan dashboard terjadwal, analisis ad-hoc, data science, ELT/ETL, atau aplikasi customer-facing? Butuh jendela batch yang dapat diprediksi, atau kapasitas burst elastis?
- Kebutuhan concurrency: Berapa banyak orang (atau aplikasi) yang akan query bersamaan, dan seberapa “spiky” penggunaan selama jam kerja?
- Kebutuhan berbagi data: Perlu berbagi data live dengan mitra, unit bisnis, atau pelanggan tanpa mengirim file? Apakah Anda akan mengonsumsi dataset pihak ketiga?
- Kesesuaian tooling: Apakah BI, orkestrasi, katalog, dan workflow CI/CD Anda akan terintegrasi dengan baik? Apa yang rusak jika Anda pindah?
- Tata kelola dan keamanan: Perlu kontrol akses granular, jejak audit, masking, kebijakan retensi, dan pemisahan tugas yang jelas?
- Batasan biaya: Biaya mana yang paling penting—pengeluaran steady-state, pengeluaran jam puncak, atau kemampuan mematikan compute? Bagaimana mencegah pemborosan “selalu hidup”?
Rencana pilot singkat (2–4 minggu)
Pilih dua atau tiga dataset representatif (bukan sampel main-main): satu tabel fact besar, satu sumber semi-terstruktur berantakan, dan satu domain “kritis bisnis”.
Lalu jalankan query pengguna nyata: dashboard pada puncak pagi, eksplorasi analis, load terjadwal, dan beberapa join kasus terburuk. Lacak: waktu query, perilaku concurrency, waktu ingest, usaha operasional, dan biaya per workload.
Jika bagian evaluasi Anda termasuk “seberapa cepat kita bisa mengirim sesuatu yang orang benar-benar gunakan,” pertimbangkan menambahkan deliverable kecil ke pilot—mis. aplikasi metrik internal atau workflow permintaan data yang diatur yang meng-query Snowflake. Membangun lapisan tipis itu sering mengungkap realitas integrasi dan keamanan lebih cepat daripada benchmark saja, dan alat seperti Koder.ai dapat mempercepat siklus prototype-ke-produksi dengan menghasilkan struktur aplikasi via chat dan memberi Anda opsi ekspor kode.
Langkah selanjutnya yang disarankan
Jika Anda ingin bantuan memperkirakan pengeluaran dan membandingkan opsi, mulai dengan /pricing.
Untuk panduan migrasi dan tata kelola, jelajahi artikel terkait di /blog.