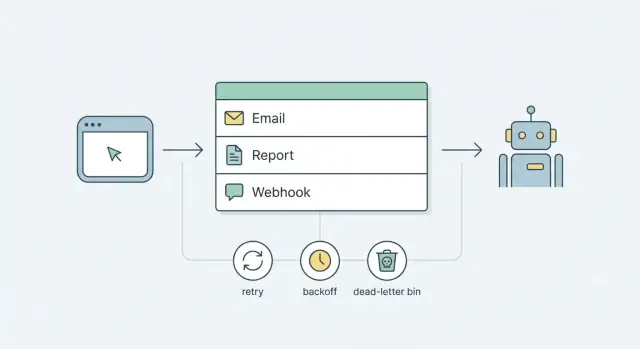
Mengapa Anda membutuhkan pekerjaan latar belakang (dan mengapa ini cepat menjadi berantakan)
Pekerjaan yang bisa memakan waktu lebih dari satu atau dua detik sebaiknya tidak berjalan di dalam permintaan pengguna. Mengirim email, membuat laporan, dan mengirim webhook bergantung pada jaringan, layanan pihak ketiga, atau query lambat. Kadang mereka berhenti sebentar, gagal, atau membutuhkan waktu lebih lama dari yang Anda duga.
Jika Anda melakukan pekerjaan itu sementara pengguna menunggu, orang akan langsung menyadarinya. Halaman macet, tombol "Simpan" berputar, dan permintaan timeout. Retry juga bisa terjadi di tempat yang salah. Pengguna merefresh, load balancer Anda melakukan retry, atau frontend mengirim ulang, dan Anda berakhir dengan email ganda, panggilan webhook ganda, atau dua proses laporan yang saling bersaing.
Pekerjaan latar belakang memperbaiki ini dengan menjaga permintaan kecil dan dapat diprediksi: terima aksi, catat job untuk dikerjakan nanti, balas cepat. Job berjalan di luar permintaan, dengan aturan yang Anda kendalikan.
Bagian yang sulit adalah keandalan. Setelah pekerjaan keluar dari jalur permintaan, Anda tetap harus menjawab pertanyaan seperti:
- Bagaimana jika penyedia email down selama 3 menit?
- Bagaimana jika endpoint webhook mengembalikan 500, atau timeout?
- Bagaimana jika job berjalan dua kali?
- Bagaimana Anda mendeteksi job yang macet sebelum pengguna mengeluh?
Banyak tim merespons dengan menambahkan "infrastruktur berat": message broker, fleet worker terpisah, dashboard, alerting, dan playbook. Alat-alat itu berguna saat memang diperlukan, tapi mereka juga menambah bagian yang bergerak dan mode kegagalan baru.
Tujuan awal yang lebih baik lebih sederhana: job yang andal menggunakan bagian yang sudah Anda miliki. Untuk kebanyakan produk, itu berarti antrean berbasis database plus proses worker kecil. Tambahkan strategi retry dan backoff yang jelas, serta pola dead-letter untuk job yang terus gagal. Anda mendapatkan perilaku yang dapat diprediksi tanpa berkomitmen pada platform kompleks sejak hari pertama.
Bahkan jika Anda membangun cepat dengan alat chat-driven seperti Koder.ai, pemisahan ini tetap penting. Pengguna harus mendapat respons cepat sekarang, dan sistem Anda harus menyelesaikan pekerjaan yang lambat dan rawan gagal dengan aman di latar belakang.
Apa itu antrean dalam istilah sederhana
Antrean adalah barisan menunggu untuk pekerjaan. Alih-alih melakukan tugas lambat atau tidak dapat diandalkan selama permintaan pengguna (mengirim email, membuat laporan, memanggil webhook), Anda menaruh catatan kecil ke antrean dan mengembalikan respons cepat. Nanti, proses terpisah mengambil catatan itu dan melakukan pekerjaannya.
Beberapa istilah yang sering Anda temui:
- Job: satu unit kerja, seperti "mengirim email selamat datang ke user 123".
- Worker: kode yang menarik job dan menjalankannya.
- Attempt: satu kali percobaan menjalankan job.
- Schedule: kapan job harus dijalankan (sekarang, atau nanti).
- Queue: tempat job menunggu sampai worker mengambilnya.
Alur paling sederhana terlihat seperti ini:
-
Enqueue: aplikasi Anda menyimpan record job (tipe, payload, waktu jalan).
-
Claim: worker menemukan job yang tersedia berikutnya dan "mengunci"nya agar hanya satu worker yang menjalankannya.
-
Run: worker melakukan tugas (mengirim, membuat, mengantarkan).
-
Finish: tandai selesai, atau catat kegagalan dan atur waktu jalan berikutnya.
Jika volume job Anda sederhana dan Anda sudah punya database, antrean berbasis database seringkali sudah cukup. Mudah dipahami, mudah di-debug, dan cocok untuk kebutuhan umum seperti pemrosesan job email dan keandalan pengiriman webhook.
Platform streaming mulai masuk akal ketika Anda membutuhkan throughput sangat tinggi, banyak konsumen independen, atau kemampuan untuk replay riwayat event besar ke banyak sistem. Jika Anda menjalankan puluhan layanan dengan jutaan event per jam, alat seperti Kafka bisa membantu. Sampai saat itu, tabel database plus loop worker mencakup banyak antrean dunia nyata.
Data minimum yang harus Anda lacak untuk setiap job
Antrean berbasis database tetap tertib jika setiap record job menjawab tiga pertanyaan dengan cepat: apa yang harus dilakukan, kapan mencoba lagi, dan apa yang terjadi terakhir kali. Jika itu benar, operasi menjadi membosankan (itu tujuannya).
Apa yang disimpan di payload (dan apa yang tidak)
Simpan input terkecil yang diperlukan untuk melakukan pekerjaan, bukan seluruh output yang sudah dirender. Payload yang baik adalah ID dan beberapa parameter, seperti { "user_id": 42, "template": "welcome" }.
Hindari menyimpan blob besar (HTML email penuh, data laporan besar, body webhook raksasa). Ini membuat database Anda tumbuh lebih cepat dan mempersulit debugging. Jika job perlu dokumen besar, simpan referensi saja: report_id, export_id, atau key file. Worker bisa mengambil data lengkap saat dijalankan.
Field yang sepadan dengan investasi
Minimalnya, sediakan ruang untuk:
- job_type + payload:
job_type memilih handler (send_email, generate_report, deliver_webhook). payload menyimpan input kecil seperti ID dan opsi.
- status: buat eksplisit (misalnya:
queued, running, succeeded, failed, dead).
- pelacakan percobaan:
attempt_count dan max_attempts agar Anda bisa berhenti saat jelas tidak akan berhasil.
- field waktu:
created_at dan next_run_at (kapan job menjadi eligible). Tambahkan started_at dan finished_at jika ingin visibilitas lebih baik untuk job lambat.
- idempotency + last_error:
idempotency_key untuk mencegah efek ganda, dan last_error agar Anda bisa melihat kenapa gagal tanpa menggali tumpukan log.
Idempotensi terdengar mewah, tapi idenya sederhana: jika job yang sama berjalan dua kali, percobaan kedua harus mendeteksi itu dan tidak melakukan hal berbahaya. Contohnya, job pengiriman webhook bisa menggunakan idempotency key seperti webhook:order:123:event:paid sehingga Anda tidak mengirim event yang sama dua kali jika retry tumpang tindih dengan timeout.
Juga tangkap beberapa angka dasar sejak awal. Anda tidak perlu dashboard besar untuk memulai, cukup query yang memberi tahu: berapa banyak job yang antre, berapa banyak yang gagal, dan umur job antrean tertua.
Langkah demi langkah: antrean database sederhana yang bisa Anda bangun hari ini
Jika Anda sudah punya database, Anda bisa memulai antrean latar belakang tanpa menambah infrastruktur baru. Job adalah baris, dan worker adalah proses yang terus mengambil baris yang sudah waktunya dan melakukan pekerjaan.
1) Buat tabel jobs
Jaga tabel tetap kecil dan sederhana. Anda ingin field yang cukup untuk menjalankan, melakukan retry, dan melakukan debugging later.
CREATE TABLE jobs (
id bigserial PRIMARY KEY,
job_type text NOT NULL,
payload jsonb NOT NULL,
status text NOT NULL DEFAULT 'queued',
attempts int NOT NULL DEFAULT 0,
next_run_at timestamptz NOT NULL DEFAULT now(),
locked_at timestamptz,
locked_by text,
last_error text,
created_at timestamptz NOT NULL DEFAULT now(),
updated_at timestamptz NOT NULL DEFAULT now()
);
CREATE INDEX jobs_due_idx ON jobs (status, next_run_at);
Jika Anda membangun di Postgres (umum pada backend Go), jsonb praktis untuk menyimpan data job seperti { "user_id":123,"template":"welcome" }.
2) Enqueue dengan aman (khususnya untuk aksi pengguna)
Saat aksi pengguna harus memicu job (mengirim email, memicu webhook), tulis baris job dalam transaksi database yang sama dengan perubahan utama jika memungkinkan. Itu mencegah "pengguna dibuat tapi job hilang" jika crash terjadi tepat setelah penulisan utama.
Contoh: saat user mendaftar, insert row user dan job send_welcome_email dalam satu transaksi.
3) Jalankan loop worker yang bisa diskalakan
Worker mengulang siklus yang sama: temukan satu job yang sudah waktunya, klaim agar tidak ada yang lain mengambilnya, proses, lalu tandai selesai atau jadwalkan retry.
Dalam praktiknya, itu berarti:
- Pilih satu job dengan
status='queued' dan next_run_at <= now().
- Klaimnya secara atomik (di Postgres,
SELECT ... FOR UPDATE SKIP LOCKED adalah pendekatan umum).
- Set
status='running', locked_at=now(), locked_by='worker-1'.
- Proses job.
- Tandai selesai (mis.
done/succeeded), atau catat last_error dan jadwalkan percobaan berikutnya.
Beberapa worker bisa berjalan bersamaan. Langkah klaim yang atomik mencegah pengambilan ganda.
4) Tangani shutdown tanpa merusak job
Saat shutdown, berhenti mengambil job baru, selesaikan job yang sedang berjalan, lalu keluar. Jika proses mati di tengah job, gunakan aturan sederhana: anggap job yang bertahan di running melewati timeout sebagai eligible untuk dikeluarkan lagi oleh tugas periodik "reaper".
Jika Anda membangun di Koder.ai, pola antrean-database ini adalah default yang solid untuk email, laporan, dan webhook sebelum Anda menambahkan layanan antrean khusus.
Retry dan backoff yang tidak menyebabkan kekacauan
Modelkan tipe job dengan rapi
Buat tipe job terpisah untuk email, webhook, dan laporan dengan aturan jelas per handler.
Retry menjaga antrean tetap tenang saat dunia nyata berantakan. Tanpa aturan jelas, retry berubah jadi loop berisik yang menyebalkan pengguna, membombardir API, dan menyembunyikan bug nyata.
Mulailah dengan memutuskan apa yang harus diretry dan apa yang harus gagal cepat.
Retry masalah sementara: timeout jaringan, 502/503, rate limit, atau gangguan koneksi database singkat.
Gagal cepat saat job tidak akan berhasil: alamat email hilang, response 400 dari webhook karena payload tidak valid, atau permintaan laporan untuk akun yang dihapus.
Backoff adalah jeda antar percobaan. Linear backoff (5s, 10s, 15s) sederhana, tapi masih bisa menciptakan gelombang trafik. Exponential backoff (5s, 10s, 20s, 40s) menyebarkan beban lebih baik dan biasanya lebih aman untuk webhook dan penyedia pihak ketiga. Tambahkan jitter (delay acak kecil) agar ribuan job tidak retry di detik yang sama setelah gangguan.
Aturan yang cenderung berperilaku baik di produksi:
- Retry hanya pada error yang jelas bersifat sementara (timeouts, 429, 5xx).
- Gunakan exponential backoff dengan jitter.
- Batasi percobaan, lalu berhenti dan tandai job sebagai failed.
- Set timeout per percobaan agar worker tidak tersangkut.
- Buat setiap job idempotent supaya retry tidak membuat duplikasi.
Max attempts bertujuan membatasi kerusakan. Untuk banyak tim, 5 sampai 8 percobaan sudah cukup. Setelah itu, berhenti retry dan letakkan job untuk ditinjau (alur dead-letter) daripada berputar selamanya.
Timeout mencegah job "zombie". Email mungkin timeout dalam 10–20 detik per percobaan. Webhook sering membutuhkan batas lebih pendek, seperti 5–10 detik, karena penerima mungkin down dan Anda ingin melanjutkan. Pembuatan laporan boleh memakan menit, tapi tetap harus ada cutoff keras.
Jika Anda membangun ini di Koder.ai, anggap should_retry, next_run_at, dan idempotency key sebagai field kelas satu. Detail kecil itu menjaga sistem tetap tenang saat ada masalah.
Penanganan dead-letter dan operasi sederhana
Status dead-letter adalah tempat job masuk saat retry tidak lagi aman atau berguna. Ini mengubah kegagalan senyap menjadi sesuatu yang bisa Anda lihat, cari, dan tindaklanjuti.
Apa yang disimpan pada job dead-letter
Simpan cukup konteks untuk memahami apa yang terjadi dan memutar ulang job tanpa menebak, tapi berhati-hatilah terhadap rahasia.
Simpan:
- Input job (payload) persis seperti digunakan, plus tipe job dan versi
- Pesan error terakhir dan jejak stack singkat (atau kode error jika tidak ada stack)
- Jumlah percobaan, waktu jalan pertama, waktu jalan terakhir, dan next_run_at (jika dijadwalkan)
- Identitas worker (nama layanan, host) dan correlation ID untuk log
- Alasan dead-letter (timeout, validation error, 4xx dari vendor, dll.)
Jika payload berisi token atau data pribadi, redaksi atau enkripsi sebelum menyimpan.
Alur triase sederhana
Saat job masuk dead-letter, buat keputusan cepat: retry, perbaiki, atau abaikan.
Retry untuk outage eksternal dan timeout. Perbaiki untuk data buruk (email hilang, URL webhook salah) atau bug di kode Anda. Abaikan sebaiknya jarang, tapi valid saat job tidak relevan lagi (mis. pelanggan menghapus akun). Jika mengabaikan, catat alasannya agar job tidak terlihat lenyap.
Requeue manual paling aman jika membuat job baru dan membuat yang lama immutable. Tandai job dead-letter dengan siapa yang mengantri ulang, kapan, dan kenapa, lalu enqueue salinan baru dengan ID baru.
Untuk alerting, pantau sinyal yang biasanya berarti masalah nyata: jumlah dead-letter naik cepat, error yang sama muncul berulang di banyak job, dan job antre lama yang tidak diklaim.
Jika Anda menggunakan Koder.ai, snapshot dan rollback membantu saat rilis buruk tiba-tiba meningkatkan kegagalan, karena Anda bisa membatalkan perubahan cepat saat menyelidiki.
Terakhir, tambahkan katup pengaman untuk outage vendor. Batasi pengiriman per penyedia, dan gunakan circuit breaker: jika endpoint webhook gagal parah, jeda percobaan baru selama jangka pendek agar Anda tidak membanjiri server mereka (dan server Anda sendiri).
Pola untuk email, laporan, dan webhook
Berkembang melampaui satu worker
Skalakan dari antrean database dasar ke banyak worker saat throughput Anda meningkat.
Antrean bekerja terbaik ketika setiap tipe job punya aturan jelas: apa yang dihitung sebagai sukses, apa yang harus diretry, dan apa yang tidak boleh terjadi dua kali.
Email. Kebanyakan kegagalan email bersifat sementara: timeout penyedia, rate limit, atau outage singkat. Perlakukan itu sebagai retryable, dengan backoff. Risiko lebih besar adalah pengiriman duplikat, jadi buat job email idempotent. Simpan kunci dedupe stabil seperti user_id + template + event_id dan tolak mengirim jika kunci itu sudah ditandai sebagai terkirim.
Juga berguna menyimpan nama dan versi template (atau hash subject/body yang dirender). Jika nanti perlu menjalankan ulang job, Anda bisa memilih apakah mengirim ulang konten yang sama persis atau merender ulang dari template terbaru. Jika penyedia mengembalikan message ID, simpan agar dukungan bisa melacak kejadian.
Laporan. Laporan gagal dengan cara berbeda. Mereka bisa berjalan berjam-jam, mencapai limit pagination, atau kehabisan memori jika melakukan semuanya sekaligus. Pecah pekerjaan menjadi bagian kecil. Pola umum: satu job "request laporan" membuat banyak job "page" (atau "chunk"), masing-masing memproses irisan data.
Simpan hasil untuk diunduh nanti daripada membuat pengguna menunggu. Itu bisa berupa tabel database yang di-key oleh report_run_id, atau referensi file plus metadata (status, jumlah baris, created_at). Tambahkan field progres agar UI bisa menunjukkan "processing" vs "ready" tanpa menebak.
Webhooks. Webhook soal keandalan pengiriman, bukan kecepatan. Tanda tangani setiap request (mis. HMAC dengan shared secret) dan sertakan timestamp untuk mencegah replay. Retry hanya saat penerima mungkin berhasil nanti.
Aturan sederhana:
- Retry pada timeout dan response 5xx, menggunakan backoff dan batas percobaan.
- Anggap sebagian besar response 4xx sebagai kegagalan permanen dan hentikan retry.
- Catat kode status terakhir dan body response singkat untuk debugging.
- Gunakan idempotency key agar penerima bisa mengabaikan duplikat dengan aman.
- Batasi ukuran payload dan log apa yang benar-benar Anda kirim.
Ordering dan prioritas. Sebagian besar job tidak memerlukan ordering ketat. Saat urutan penting, biasanya per key (per user, per invoice, per endpoint webhook). Tambahkan group_key dan jalankan hanya satu job dalam penerbangan per key.
Untuk prioritas, pisahkan pekerjaan mendesak dari pekerjaan lambat. Backlog laporan besar tidak boleh menunda email reset password.
Contoh: setelah pembelian, Anda enqueue (1) email konfirmasi order, (2) webhook ke partner, dan (3) job pembaruan laporan. Email bisa retry cepat, webhook retry lebih lama dengan backoff, dan laporan jalan nanti dengan prioritas rendah.
Contoh realistis: alur signup plus webhook plus laporan malam
Seorang pengguna mendaftar di aplikasi Anda. Tiga hal harus terjadi, tapi tidak satu pun harus memperlambat halaman signup: kirim email selamat datang, beri tahu CRM lewat webhook, dan masukkan pengguna ke laporan aktivitas malam.
Apa yang diantrekan saat signup
Tepat setelah membuat record user, tulis tiga baris job ke antrean database Anda. Masing-masing baris punya tipe, payload (seperti user_id), status, jumlah percobaan, dan timestamp next_run_at.
Siklus tipikal terlihat seperti ini:
queued: dibuat dan menunggu workerrunning: worker telah mengklaimnyasucceeded: selesai, tidak ada kerja lagifailed: gagal, dijadwalkan lagi atau kehabisan retrydead: gagal berkali-kali dan butuh perhatian manusia
Job email selamat datang menyertakan idempotency key seperti welcome_email:user:123. Sebelum mengirim, worker memeriksa tabel kunci idempotensi yang selesai (atau menegakkan constraint unik). Jika job berjalan dua kali karena crash, percobaan kedua melihat kunci dan melewatkan pengiriman. Tidak ada email selamat datang ganda.
Sebuah kegagalan dan bagaimana ia pulih
Sekarang endpoint CRM webhook down. Job webhook gagal karena timeout. Worker Anda menjadwalkan retry menggunakan backoff (mis. 1 menit, 5 menit, 30 menit, 2 jam) plus sedikit jitter agar banyak job tidak retry di detik yang sama.
Setelah maksimal percobaan, job menjadi dead. Pengguna tetap mendaftar, mendapat email selamat datang, dan job laporan malam bisa berjalan normal. Hanya notifikasi CRM yang terjebak, dan itu terlihat.
Keesokan paginya, support (atau on-call) bisa menanganinya tanpa menggali log berjam-jam:
- Filter job dead berdasarkan tipe (mis.
webhook.crm).
- Baca pesan error terakhir dan konfirmasi payload tampak benar.
- Verifikasi CRM sudah pulih.
- Requeue job (dead -> queued, reset attempts) atau nonaktifkan tujuan sementara.
Jika Anda membangun aplikasi di platform seperti Koder.ai, pola yang sama berlaku: jaga alur pengguna cepat, dorong efek samping ke job, dan buat kegagalan mudah diperiksa dan dijalankan ulang.
Kesalahan umum yang membuat antrean tak andal
Miliki implementasi antrean Anda
Miliki seluruh kode sumber antrean dan worker agar tim Anda bisa memperluasnya.
Cara tercepat merusak antrean adalah menganggapnya opsional. Tim sering mulai dengan "kirim email di request kali ini saja" karena terasa lebih sederhana. Lalu menyebar: reset password, struk, webhook, export laporan. Lama-kelamaan aplikasi terasa lambat, timeout naik, dan gangguan pihak ketiga menjadi outage bagi Anda.
Perangkap lain adalah melewatkan idempotensi. Jika job bisa berjalan dua kali, ia tidak boleh menghasilkan dua hasil. Tanpa idempotensi, retry berubah jadi email ganda, event webhook berulang, atau lebih buruk.
Masalah ketiga adalah visibilitas. Jika Anda hanya tahu tentang kegagalan dari tiket support, antrean sudah merugikan pengguna. Bahkan tampilan internal dasar yang menunjukkan jumlah job per status plus last_error yang dapat dicari sangat menghemat waktu.
Pembunuh keandalan yang harus diwaspadai
Beberapa masalah muncul cepat, bahkan di antrean sederhana:
- Retry langsung setelah gagal. Jika penyedia down, retry cepat menciptakan spike trafik sendiri.
- Mencampur job lambat dengan job mendesak. Laporan 10 menit bisa memblokir email verifikasi.
- Menganggap error bersifat sementara selamanya. Job yang tak pernah berhasil terus berputar dan menyembunyikan masalah nyata.
- Tidak ada kepemilikan versi payload. Jika Anda mengubah bentuk job, job lama bisa mulai gagal.
- Mengabaikan rate limit. Antrean bisa membanjiri penyedia yang membatasi Anda.
Backoff mencegah outage buatan sendiri. Bahkan jadwal dasar seperti 1 menit, 5 menit, 30 menit, 2 jam membuat kegagalan lebih aman. Juga set batas percobaan sehingga job rusak berhenti dan menjadi terlihat.
Jika Anda membangun di platform seperti Koder.ai, ada baiknya mengirimkan dasar-dasar ini bersama fitur, bukan beberapa minggu kemudian sebagai proyek pembersihan.
Daftar periksa singkat dan langkah selanjutnya
Sebelum Anda menambahkan tooling, pastikan dasar-dasarnya kuat. Antrean berbasis database bekerja baik bila setiap job mudah diklaim, mudah diretry, dan mudah diperiksa.
Daftar periksa reliabilitas cepat:
- Setiap job punya: id, type, payload, status, attempts, max_attempts, run_at/next_run_at, dan last_error.
- Worker mengklaim job dengan aman (satu worker dapat satu job) dan pulih setelah crash (lock timeout + reaper).
- Setiap job punya timeout jelas sehingga pekerjaan yang tersangkut menjadi retryable alih-alih menggantung selamanya.
- Retry dibatasi dan delay retry tumbuh (backoff) untuk menghindari thundering herd.
- Ada state dead-letter (atau tabel) plus cara jelas untuk menjalankan ulang atau membuang job.
Selanjutnya, pilih tiga tipe job pertama Anda dan tuliskan aturannya. Contoh: email reset password (retry cepat, max singkat), laporan malam (sedikit retry, timeout lebih lama), pengiriman webhook (lebih banyak retry, backoff lebih lama, berhenti pada 4xx permanen).
Jika Anda ragu kapan antrean database tidak lagi cukup, pantau sinyal seperti kontensi tingkat baris dari banyak worker, kebutuhan ordering ketat di banyak tipe job, fan-out besar (satu event memicu ribuan job), atau konsumsi lintas-layanan di mana tim berbeda memiliki worker masing-masing.
Jika Anda ingin prototipe cepat, Anda bisa merancang alur di Koder.ai (koder.ai) menggunakan planning mode, menghasilkan tabel jobs dan loop worker, dan iterasi dengan snapshot dan rollback sebelum deploy.