21 Sep 2025·7 menit
Pola Disruptor untuk latensi rendah: desain waktu‑nyata yang dapat diprediksi
Pelajari pola Disruptor untuk latensi rendah dan cara merancang sistem real‑time dengan waktu respons yang dapat diprediksi menggunakan antrean, memori, dan pilihan arsitektur.
Mengapa aplikasi real‑time terasa lambat meski kodenya cepat
Kecepatan punya dua sisi: throughput dan latensi. Throughput adalah berapa banyak pekerjaan yang selesai per detik (request, pesan, frame). Latensi adalah berapa lama satu unit kerja membutuhkan waktu dari mulai hingga selesai.
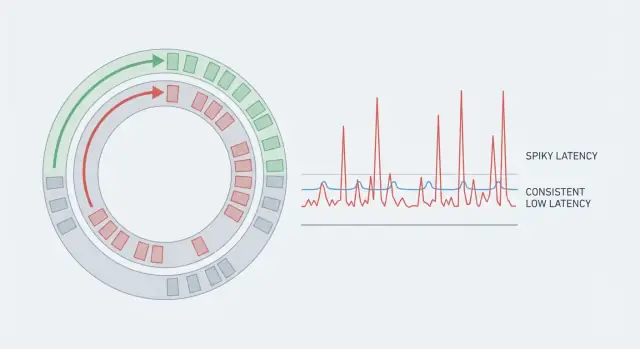
Sebuah sistem bisa memiliki throughput hebat namun terasa lambat jika beberapa request memakan waktu jauh lebih lama daripada yang lain. Itulah kenapa rata‑rata menipu. Jika 99 aksi memerlukan 5 ms dan satu aksi memerlukan 80 ms, rata‑rata terlihat baik, tetapi pengguna yang mengalami kasus 80 ms merasakan jeda. Pada sistem real‑time, lonjakan jarang itulah keseluruhan cerita karena mereka merusak ritme.
Latensi yang dapat diprediksi berarti Anda tidak hanya mengejar rata‑rata rendah. Anda mengejar konsistensi, sehingga sebagian besar operasi selesai dalam rentang sempit. Itu sebabnya tim memantau tail (p95, p99). Di situ lah jeda bersembunyi.
Lonjakan 50 ms bisa berarti pada area seperti suara dan video (glitch audio), game multiplayer (rubber‑banding), trading real‑time (harga terlewat), monitoring industri (alarm terlambat), dan dashboard live (angka melompat, alert terasa tidak dapat diandalkan).
Contoh sederhana: aplikasi chat mungkin mengantarkan pesan dengan cepat kebanyakan waktu. Tapi jika jeda latar belakang membuat satu pesan datang terlambat 60 ms, indikator pengetikan berkedip dan percakapan terasa lag meski server terlihat “cepat” menurut rata‑rata.
Jika Anda ingin real‑time terasa nyata, Anda butuh lebih sedikit kejutan, bukan hanya kode yang lebih cepat.
Dasar latensi: ke mana waktu sebenarnya pergi
Sebagian besar sistem real‑time tidak lambat karena CPU kewalahan. Mereka terasa lambat karena pekerjaan menghabiskan sebagian besar waktunya untuk menunggu: menunggu dijadwalkan, menunggu di antrean, menunggu jaringan, atau menunggu penyimpanan.
End‑to‑end latency adalah waktu penuh dari “sesuatu terjadi” sampai “pengguna melihat hasil.” Meski handler Anda berjalan 2 ms, request masih bisa memakan 80 ms jika terhenti di lima tempat berbeda.
Cara berguna untuk memecah jalur adalah:
- Waktu jaringan (client ke edge, service ke service, retry)
- Waktu penjadwalan (thread Anda menunggu untuk berjalan)
- Waktu antrean (pekerjaan duduk di belakang pekerjaan lain)
- Waktu storage (disk, lock database, cache miss)
- Waktu serialisasi (encoding dan decoding data)
Penantian‑penantian itu menumpuk. Beberapa milidetik di sana sini mengubah jalur kode yang “cepat” menjadi pengalaman yang lambat.
Tail latency adalah saat pengguna mulai mengeluh. Latensi rata‑rata mungkin terlihat baik, tapi p95 atau p99 menunjukkan 5% atau 1% terlama dari request. Outlier biasanya datang dari jeda yang jarang: siklus GC, tetangga berisik di host, kontensi lock singkat, refill cache, atau ledakan trafik yang menciptakan antrean.
Contoh konkret: update harga tiba lewat jaringan dalam 5 ms, menunggu 10 ms karena worker sibuk, menghabiskan 15 ms di belakang event lain, lalu menemui stall database selama 30 ms. Kode Anda masih berjalan 2 ms, tetapi pengguna menunggu 62 ms. Tujuannya membuat setiap langkah dapat diprediksi, bukan hanya komputasinya cepat.
Sumber jitter biasa di luar kecepatan kode
Algoritma cepat tetap bisa terasa lambat jika waktu per request berfluktuasi. Pengguna memperhatikan lonjakan, bukan rata‑rata. Fluktuasi itu adalah jitter, dan sering datang dari hal yang tidak sepenuhnya dikendalikan oleh kode Anda.
Cache CPU dan perilaku memori adalah biaya tersembunyi. Jika data panas tidak muat di cache, CPU berhenti sambil menunggu RAM. Struktur penuh objek, memori yang tersebar, dan “satu lookup lagi” bisa berubah menjadi cache miss berulang.
Alokasi memori menambah ketidakpastian. Mengalokasikan banyak objek yang pendek umurnya meningkatkan tekanan heap, yang kemudian muncul sebagai jeda (garbage collection) atau kontensi allocator. Bahkan tanpa GC, alokasi sering dapat memfragmentasi memori dan merusak localitas.
Penjadwalan thread adalah sumber lain yang umum. Ketika sebuah thread dideschedule, Anda membayar overhead context switch dan kehilangan kehangatan cache. Di mesin sibuk, thread “real‑time” Anda mungkin menunggu di belakang pekerjaan yang tidak relevan.
Kontensi lock adalah tempat sistem yang dapat diprediksi sering runtuh. Lock yang “biasanya bebas” bisa berubah menjadi konvoi: thread bangun, bersaing untuk lock, lalu kembali tidur. Pekerjaan tetap selesai, tetapi tail latency mengembang.
I/O wait bisa menenggelamkan semuanya. Satu syscall, buffer jaringan penuh, handshake TLS, flush disk, atau lookup DNS lambat dapat menciptakan lonjakan tajam yang tak bisa diperbaiki oleh micro‑optimisasi.
Jika Anda memburu jitter, mulailah dengan mencari cache miss (sering disebabkan struktur pointer‑heavy dan akses acak), alokasi sering, context switch karena terlalu banyak thread atau tetangga berisik, kontensi lock, dan I/O blocking (jaringan, disk, logging, panggilan sinkron).
Contoh: layanan ticker harga mungkin menghitung update dalam mikrodetik, tetapi satu panggilan logger sinkron atau lock metrik yang sibuk bisa menambahkan puluhan milidetik secara intermittan.
Martin Thompson dan apa itu pola Disruptor
Martin Thompson terkenal di dunia rekayasa latensi‑rendah karena fokusnya pada bagaimana sistem berperilaku di bawah tekanan: bukan hanya kecepatan rata‑rata, tetapi kecepatan yang dapat diprediksi. Bersama tim LMAX, ia membantu mempopulerkan pola Disruptor, sebuah pendekatan referensi untuk memindahkan event melalui sistem dengan delay kecil dan konsisten.
Pendekatan Disruptor adalah jawaban atas apa yang membuat banyak aplikasi “cepat” menjadi tak terduga: kontensi dan koordinasi. Antrian biasa sering mengandalkan lock atau atomik berat, membangunkan thread bolak‑balik, dan menghasilkan lonjakan tunggu ketika producer dan consumer bersaing atas struktur bersama.
Alih‑alih antrean, Disruptor menggunakan ring buffer: array melingkar berukuran tetap yang menampung event di slot. Producer mengklaim slot berikutnya, menulis data, lalu mempublikasikan nomor urut. Consumer membaca berurutan dengan mengikuti nomor urut itu. Karena buffer dipra‑alokasi, Anda menghindari alokasi sering dan mengurangi tekanan pada garbage collector.
Ide kunci adalah prinsip single‑writer: biarkan satu komponen bertanggung jawab atas sepotong state bersama (mis. cursor yang maju melalui ring). Lebih sedikit penulis berarti lebih sedikit momen “siapa selanjutnya?”
Backpressure bersifat eksplisit. Ketika consumer tertinggal, producer pada akhirnya mencapai slot yang masih digunakan. Pada titik itu sistem harus menunggu, menjatuhkan, atau melambat, tetapi dilakukan dengan cara yang terkontrol dan terlihat alih‑alih menyembunyikan masalah di dalam antrean yang terus membesar.
Ide desain inti yang menjaga latensi tetap konsisten
Yang membuat desain bergaya Disruptor cepat bukanlah micro‑optimisasi pintar. Ini adalah menghapus jeda yang tak terduga yang muncul ketika sistem berkonflik dengan bagiannya sendiri: alokasi, cache miss, kontensi lock, dan pekerjaan lambat yang tercampur dalam jalur panas.
Model mental yang berguna adalah lini perakitan. Event bergerak melalui rute tetap dengan serah terima jelas. Itu mengurangi state bersama dan membuat setiap langkah lebih mudah dijaga tetap sederhana dan terukur.
Jaga memori dan data tetap dapat diprediksi
Sistem cepat menghindari alokasi mengejutkan. Jika Anda pra‑alokasi buffer dan menggunakan ulang objek pesan, Anda mengurangi lonjakan kadang‑kadang yang disebabkan GC, pertumbuhan heap, dan lock allocator.
Juga membantu menjaga pesan kecil dan stabil. Ketika data yang Anda sentuh per event muat di cache CPU, Anda menghabiskan lebih sedikit waktu menunggu memori.
Dalam praktik, kebiasaan yang biasanya paling berpengaruh adalah: gunakan ulang objek daripada membuat yang baru per event, jaga data event kompak, pilih single writer untuk state bersama, dan batching dengan hati‑hati supaya Anda membayar biaya koordinasi lebih jarang.
Buat jalur lambat jelas
Aplikasi real‑time sering membutuhkan tambahan seperti logging, metrik, retry, atau penulisan database. Pola pikir Disruptor adalah mengisolasi hal‑hal itu dari loop inti sehingga mereka tidak bisa memblokirnya.
Pada feed harga live, jalur panas mungkin hanya memvalidasi tick dan mempublikasikan snapshot harga berikutnya. Apa pun yang bisa menahan (disk, panggilan jaringan, serialisasi berat) dipindahkan ke consumer terpisah atau kanal samping, sehingga jalur yang dapat diprediksi tetap terjaga.
Pilihan arsitektur untuk latensi yang dapat diprediksi
Ukur dalam kondisi nyata
Siapkan staging environment cepat agar Anda bisa mengukur jitter jaringan nyata.
Latensi yang dapat diprediksi sebagian besar adalah masalah arsitektur. Anda bisa punya kode cepat namun tetap mendapat lonjakan jika terlalu banyak thread berjuang atas data yang sama, atau pesan melompat‑lompat melintasi jaringan tanpa perlu.
Mulailah dengan memutuskan berapa banyak penulis dan pembaca yang menyentuh antrean atau buffer yang sama. Satu producer lebih mudah dipertahankan karena menghindari koordinasi. Setup multi‑producer bisa meningkatkan throughput, tetapi sering menambah kontensi dan membuat waktu terburuk kurang dapat diprediksi. Jika Anda butuh beberapa producer, kurangi penulisan bersama dengan melakukan sharding event berdasarkan key (mis. userId atau instrumentId) sehingga setiap shard punya jalur panas sendiri.
Di sisi consumer, satu consumer memberi timing paling stabil saat ordering penting, karena state tetap lokal pada satu thread. Worker pool membantu bila tugas benar‑benar independen, tetapi mereka menambah delay penjadwalan dan bisa mengubah urutan kecuali Anda hati‑hati.
Batching adalah tradeoff lain. Batch kecil memotong overhead (lebih sedikit wakeup, lebih sedikit cache miss), tetapi batching juga bisa menambah waktu tunggu jika Anda menahan event untuk mengisi batch. Jika Anda melakukan batching di sistem real‑time, batasi waktu tunggu (mis. “hingga 16 event atau 200 mikrodetik, mana yang lebih dulu”).
Batas layanan juga penting. Messaging in‑process biasanya terbaik jika Anda butuh latensi ketat. Hop jaringan berguna untuk scaling, tetapi setiap hop menambah antrean, retry, dan delay variabel. Jika Anda perlu hop, jaga protokol sederhana dan hindari fan‑out di jalur panas.
Aturan praktis: gunakan single‑writer per shard bila bisa, skalakan lewat sharding key daripada berbagi satu antrean panas, batching hanya dengan batas waktu yang ketat, tambahkan worker pool hanya untuk pekerjaan paralel dan independen, dan anggap setiap hop jaringan sebagai sumber jitter potensial sampai Anda mengukurnya.
Langkah demi langkah: merancang pipeline low‑jitter
Mulailah dengan budget latensi tertulis sebelum menyentuh kode. Pilih target (apa yang terasa “baik”) dan p99 (batas yang harus Anda patuhi). Bagi angka itu ke tahap‑tahap seperti input, validasi, pencocokan, persistensi, dan update outbound. Jika suatu tahap tidak punya budget, maka tahap itu tidak punya batas.
Selanjutnya, gambarkan alur data penuh dan tandai setiap serah terima: batas thread, antrean, hop jaringan, dan panggilan penyimpanan. Setiap serah terima adalah tempat di mana jitter bersembunyi. Saat Anda melihatnya, Anda bisa menguranginya.
Workflow yang menjaga desain tetap jujur:
- Tulis budget per‑tahap (target dan p99), plus buffer kecil untuk hal tak terduga.
- Petakan pipeline dan beri label antrean, lock, alokasi, dan panggilan blocking.
- Pilih model concurrency yang bisa Anda pahami (single writer, worker terpartisi per key, atau thread I/O khusus).
- Definisikan bentuk pesan sejak awal: skema stabil, payload kompak, dan minimal penyalinan.
- Tentukan aturan backpressure di depan: drop, delay, degrade, atau shed load. Buat itu terlihat dan dapat diukur.
Lalu putuskan apa yang bisa dibuat asinkron tanpa merusak pengalaman pengguna. Aturan sederhana: apa pun yang mengubah apa yang pengguna lihat “sekarang” tetap di jalur kritis. Sisanya pindahkan keluar.
Analitik, audit log, dan secondary indexing sering aman dipindahkan dari jalur panas. Validasi, ordering, dan langkah yang diperlukan untuk menghasilkan state berikutnya biasanya tidak bisa dipindahkan.
Pilihan runtime dan OS yang memengaruhi tail latency
Kode cepat tetap bisa terasa lambat ketika runtime atau OS menjeda kerja Anda pada saat yang salah. Tujuan bukan hanya throughput tinggi. Ini mengurangi kejutan pada 1% terburuk request.
Runtime yang memakai garbage collector (JVM, Go, .NET) hebat untuk produktivitas, tetapi bisa menambah jeda saat memori perlu dibersihkan. Collector modern jauh lebih baik, namun tail latency masih bisa melonjak jika Anda membuat banyak objek pendek umur di bawah beban. Bahasa non‑GC (Rust, C, C++) menghindari jeda GC, tetapi memindahkan biaya ke kepemilikan manual dan disiplin alokasi. Bagaimanapun, perilaku memori sama pentingnya dengan kecepatan CPU.
Kebiasaan praktisnya sederhana: temukan di mana alokasi terjadi dan buat itu membosankan. Gunakan ulang objek, pra‑ukuran buffer, dan hindari mengubah data jalur panas menjadi string atau map sementara.
Pilihan threading juga muncul sebagai jitter. Setiap antrean ekstra, hop async, atau handoff thread pool menambah waktu tunggu dan meningkatkan varian. Utamakan sejumlah kecil thread hidup lama, jaga batas producer‑consumer jelas, dan hindari panggilan blocking di jalur panas.
Beberapa setting OS dan container sering menentukan apakah tail Anda bersih atau berduri. Throttling CPU dari limit ketat, tetangga berisik pada host shared, dan logging/metrik yang ditempatkan dengan buruk bisa menciptakan perlambatan tiba‑tiba. Jika hanya mengubah satu hal, mulailah dengan mengukur laju alokasi dan context switch selama lonjakan latensi.
Data, storage, dan batas layanan tanpa jeda mengejutkan
Bangun pipeline yang dapat diprediksi
Prototype pipeline event ber-latensi-rendah dari satu chat di Koder.ai.
Banyak lonjakan latensi bukanlah "kode lambat." Mereka adalah penantian yang tak Anda rencanakan: lock database, badai retry, panggilan lintas layanan yang macet, atau cache miss yang berubah menjadi perjalanan penuh bolak‑balik.
Jaga jalur kritis pendek. Setiap hop ekstra menambah penjadwalan, serialisasi, antrean jaringan, dan lebih banyak tempat untuk terblok. Jika Anda bisa menjawab permintaan dari satu proses dan satu data store, lakukan itu pertama. Pisah jadi lebih banyak layanan hanya bila setiap panggilan bersifat opsional atau terbatas kuat.
Menjaga penantian berbatas adalah perbedaan antara rata‑rata cepat dan latensi yang dapat diprediksi. Beri timeout tegas pada panggilan remote, dan gagal cepat ketika dependency tidak sehat. Circuit breaker bukan hanya untuk menyelamatkan server. Mereka membatasi berapa lama pengguna bisa terjebak.
Saat akses data memblok, pisahkan jalurnya. Baca sering menginginkan bentuk yang terindeks, denormalisasi, dan ramah cache. Tulis sering menginginkan durabilitas dan ordering. Memisahkan keduanya dapat menghilangkan kontensi dan mengurangi waktu lock. Jika kebutuhan konsistensi Anda memungkinkan, catatan append‑only (event log) sering berperilaku lebih dapat diprediksi daripada update in‑place yang memicu hot‑row locking atau pemeliharaan latar belakang.
Aturan sederhana untuk aplikasi real‑time: persistensi tidak seharusnya berada di jalur kritis kecuali benar‑benar diperlukan untuk kebenaran. Bentuk yang lebih baik seringkali: update di memori, respond, lalu persist secara asinkron dengan mekanisme replay (seperti outbox atau write‑ahead log).
Dalam banyak pipeline ring‑buffer, ini sering berakhir sebagai: publish ke buffer in‑memory, update state, respond, lalu biarkan consumer terpisah mengumpulkan dan menulis batch ke PostgreSQL.
Contoh realistis: update real‑time dengan latensi yang dapat diprediksi
Bayangkan aplikasi kolaborasi live (atau game multiplayer kecil) yang mendorong update setiap 16 ms (sekitar 60 kali per detik). Tujuannya bukan “cepat rata‑rata.” Tapi “biasanya di bawah 16 ms,” bahkan ketika koneksi salah satu pengguna buruk.
Alur sederhana bergaya Disruptor terlihat seperti ini: input pengguna menjadi event kecil, dipublish ke ring buffer yang telah dipra‑alokasi, lalu diproses oleh set handler tetap berurutan (validate -> apply -> prepare outbound messages), dan akhirnya disiarkan ke klien.
Batching bisa membantu di tepi. Misalnya, batch penulisan outbound per klien sekali per tick agar Anda memanggil layer jaringan lebih sedikit. Tapi jangan batching di dalam jalur panas dengan menunggu “sedikit lagi” untuk event tambahan. Menunggu adalah cara Anda melewatkan tick.
Ketika sesuatu melambat, tangani itu sebagai masalah containment. Jika satu handler melambat, isolasi di belakang buffer sendiri dan publish item kerja ringan alih‑alih memblokir loop utama. Jika satu klien lambat, jangan biarkan ia menumpuk broadcaster; beri setiap klien antrian kirim kecil dan drop atau coalesce update lama sehingga Anda mempertahankan state terbaru. Jika kedalaman buffer tumbuh, terapkan backpressure di tepi (hentikan menerima input ekstra untuk tick itu, atau degradasi fitur).
Anda tahu itu berhasil ketika angka‑angkanya tetap membosankan: backlog mendekati nol, event yang dijatuhkan/di‑coalesce jarang dan dapat dijelaskan, serta p99 tetap di bawah budget tick selama beban realistis.
Kesalahan umum yang menciptakan lonjakan latensi
Kirim setup app nyata
Tempatkan app di domain kustom untuk routing klien dan caching yang realistis.
Sebagian besar lonjakan latensi adalah self‑inflicted. Kode bisa cepat, tapi sistem tetap terhenti saat menunggu thread lain, OS, atau apa pun di luar cache CPU.
Beberapa kesalahan yang sering muncul:
- Menggunakan shared lock di mana‑mana karena terasa sederhana. Satu lock yang kontenden dapat menahan banyak request.
- Mencampur I/O lambat ke jalur panas, seperti logging sinkron, penulisan database, atau panggilan remote sinkron.
- Menyimpan antrean tanpa batas. Mereka menyembunyikan overload sampai Anda punya backlog berdetik‑detik.
- Memantau rata‑rata alih‑alih p95 dan p99.
- Over‑tuning terlalu dini. Men‑pin thread tidak akan membantu jika delay datang dari GC, kontensi, atau menunggu socket.
Cara cepat mengurangi lonjakan adalah membuat penantian terlihat dan berbatas. Pindahkan pekerjaan lambat ke jalur terpisah, batasi antrean, dan tentukan apa yang terjadi saat penuh (drop, shed, atau degradasi fitur).
Daftar periksa cepat untuk latensi yang dapat diprediksi
Anggap latensi yang dapat diprediksi sebagai fitur produk, bukan kecelakaan. Sebelum mengatur kode, pastikan sistem punya tujuan dan penjaga.
- Tetapkan target p99 eksplisit (dan p99.9 jika penting), lalu tulis budget latensi per tahap.
- Jaga jalur panas bebas dari I/O blocking. Jika I/O harus terjadi, pindahkan ke jalur samping dan tentukan apa yang Anda lakukan saat itu melambat.
- Gunakan antrean berbatas dan definisikan perilaku overload (drop, shed, coalesce, atau backpressure).
- Ukur terus‑menerus: kedalaman backlog, waktu per‑tahap, dan tail latency.
- Minimalkan alokasi di hot loop dan buatnya mudah terlihat di profil.
Uji sederhana: simulasi ledakan (10x trafik normal selama 30 detik). Jika p99 meledak, tanyakan di mana penantian terjadi: antrean yang membesar, consumer yang lambat, jeda GC, atau resource bersama.
Langkah selanjutnya: bagaimana menerapkan ini di aplikasi Anda
Anggap pola Disruptor sebagai alur kerja, bukan sekadar pilihan library. Buktikan latensi yang dapat diprediksi dengan slice tipis sebelum menambah fitur.
Pilih satu aksi pengguna yang harus terasa instan (mis. “harga baru tiba, UI terupdate”). Tulis budget end‑to‑end, lalu ukur p50, p95, dan p99 sejak hari pertama.
Urutan yang cenderung berhasil:
- Bangun pipeline tipis dengan satu input, satu loop inti, dan satu output. Validasi p99 di bawah beban sejak awal.
- Buat tanggung jawab eksplisit (siapa yang memiliki state, siapa yang publish, siapa yang consume), dan jaga state bersama kecil.
- Tambah concurrency dan buffering secara bertahap, dan pastikan perubahan bisa dibalik.
- Deploy dekat pengguna bila budget ketat, lalu ukur ulang di bawah beban realistis (ukuran payload sama, pola ledakan sama).
Jika Anda membangun di Koder.ai (koder.ai), membantu untuk memetakan alur event dulu di Planning Mode agar antrean, lock, dan batas layanan tidak muncul begitu saja. Snapshot dan rollback juga mempermudah menjalankan eksperimen latensi berulang dan membatalkan perubahan yang meningkatkan throughput tetapi memperburuk p99.
Jaga pengukuran jujur. Gunakan skrip tes tetap, lakukan warm‑up sistem, dan rekam throughput serta latensi. Saat p99 melonjak dengan beban, jangan langsung “mengoptimalkan kode.” Cari jeda dari GC, tetangga berisik, ledakan logging, penjadwalan thread, atau panggilan blocking tersembunyi.
Pertanyaan umum
Mengapa aplikasi saya terasa lambat padahal rata‑rata latensi terlihat bagus?
Rata‑rata menyembunyikan jeda yang jarang terjadi. Jika sebagian besar aksi cepat tapi beberapa memakan waktu jauh lebih lama, pengguna merasakan lonjakan itu sebagai stutter atau “lag,” terutama pada alur real‑time di mana ritme penting.
Pantau tail latency (seperti p95/p99) karena di situ masalah yang terlihat berada.
Apa perbedaan throughput dan latensi dalam sistem real‑time?
Throughput adalah seberapa banyak pekerjaan yang selesai per detik. Latensi adalah berapa lama satu aksi berlangsung dari awal sampai akhir.
Anda bisa punya throughput tinggi tetapi tetap mengalami jeda panjang sekali‑kali, dan jeda‑jeda itulah yang membuat aplikasi waktu‑nyata terasa lambat.
Apa arti p95/p99 latency dan kenapa penting?
Tail latency (p95/p99) mengukur permintaan paling lambat, bukan yang tipikal. p99 berarti 1% operasi lebih lambat dari angka itu.
Pada aplikasi real‑time, 1% itu sering muncul sebagai jitter yang terlihat: bunyi audio pecah, rubber‑banding pada game, indikator berkedip, atau tick yang terlewat.
Dari mana biasanya datangnya end‑to‑end latency jika kode saya cepat?
Sebagian besar waktu biasanya dihabiskan untuk menunggu, bukan menghitung:
- Delay jaringan dan retry
- Antrian di belakang pekerjaan lain
- Penjadwalan thread dan context switch
- Stall pada storage (lock, cache miss, flush disk)
- Serialisasi dan menyalin data
Handler 2 ms masih bisa menghasilkan end‑to‑end 60–80 ms jika menunggu di beberapa tempat.
Apa penyebab paling umum dari lonjakan latensi (jitter) di luar algoritma?
Sumber jitter umum meliputi:
- Garbage collection atau kontensi allocator
- Kontensi lock (konvoi pada lock yang “biasanya bebas”)
- Cache miss akibat struktur pointer‑heavy atau akses acak
- I/O blocking di jalur panas (logging, DNS, disk, panggilan sinkron)
- Terlalu banyak perpindahan thread dan antrean
Untuk debug, korelasikan lonjakan dengan laju alokasi, context switch, dan kedalaman antrean.
Apa itu pola Disruptor secara sederhana?
Disruptor adalah pola untuk memindahkan event melalui pipeline dengan delay kecil dan konsisten. Ia memakai ring buffer yang telah dipra‑alokasi dan nomor urut (sequence) alih‑alih antrean bersama biasa.
Tujuannya mengurangi jeda yang tak terduga akibat kontensi, alokasi, dan wakeup—sehingga latensi tetap “membosankan”, bukan hanya cepat secara rata‑rata.
Bagaimana pra‑alokasi dan penggunaan ulang objek membantu latensi yang dapat diprediksi?
Pra‑alokasi dan reuse objek/buffer di hot loop mengurangi:
- Tekanan garbage collection
- Kejutan pertumbuhan heap
- Perlambatan allocator acak
Juga jaga data event kecil supaya CPU menyentuh lebih sedikit memori per event (perilaku cache lebih baik).
Haruskah saya menggunakan loop single‑threaded, sharding, atau worker pool untuk pemrosesan real‑time?
Mulai dengan single‑writer per shard bila memungkinkan (lebih mudah dipahami, sedikit kontensi). Scale dengan sharding berdasarkan key (mis. userId atau instrumentId) daripada membiarkan banyak producer menulis ke satu antrean panas.
Gunakan worker pool hanya untuk pekerjaan yang benar‑benar independen; selain itu Anda sering menukar throughput untuk tail latency yang lebih buruk dan debugging yang rumit.
Kapan batching membantu, dan kapan batching merugikan latensi?
Batching mengurangi overhead, tetapi bisa menambah waktu tunggu jika Anda menahan event untuk mengisi batch.
Aturan praktis: batasi batching menurut waktu dan ukuran (mis. “hingga N event atau T mikrodetik, mana yang lebih dulu”) agar batching tak diam‑diam melanggar budget latensi Anda.
Apa langkah praktis untuk merancang pipeline low‑jitter?
Tulis budget latensi dulu (target dan p99), lalu bagikan ke tiap tahap. Peta setiap handoff (antrean, thread pool, hop jaringan, panggilan storage) dan buat menunggu terlihat dengan metrik seperti kedalaman antrean dan waktu per‑tahap.
Jaga I/O blocking di luar jalur kritis, gunakan antrean berbatas, dan tentukan perilaku overload dari awal (drop, shed, coalesce, atau backpressure). Jika prototipe di Koder.ai, Planning Mode membantu menggambar batas‑batas ini lebih awal, dan snapshot/rollback memudahkan eksperimen yang memengaruhi p99.