03 Nov 2025·8 menit
Pola SaaS Multi-tenant: Isolasi, Skala, dan Desain AI
Pelajari pola SaaS multi-tenant umum, trade-off isolasi tenant, dan strategi penskalaan. Lihat bagaimana arsitektur yang dihasilkan AI mempercepat desain dan tinjauan.
Apa Arti Multi-tenancy (Tanpa Istilah Rumit)
Multi-tenancy berarti satu produk perangkat lunak melayani banyak pelanggan (tenant) dari sistem yang sama yang sedang berjalan. Setiap tenant merasa seperti “aplikasi mereka sendiri,” tetapi di balik layar mereka berbagi bagian infrastruktur—seperti server web yang sama, basis kode yang sama, dan sering kali basis data yang sama.
Model mental yang membantu adalah gedung apartemen. Setiap orang punya unit yang terkunci sendiri (data dan pengaturan mereka), tetapi kalian berbagi lift, plumbing, dan tim pemeliharaan gedung (compute, storage, dan operasi aplikasi).
Mengapa tim memilih multi-tenancy
Kebanyakan tim tidak memilih SaaS multi-tenant karena sedang tren—mereka memilih karena efisien:
- Biaya per pelanggan lebih rendah: infrastruktur bersama biasanya lebih murah dibanding menyiapkan stack penuh per pelanggan.
- Operasi lebih sederhana: satu platform untuk dipantau, dipatch, dan diamankan (daripada ratusan deployment kecil).
- Pengiriman lebih cepat: peningkatan meluncur ke semua orang sekaligus, dan Anda menghindari “version drift” antar pelanggan.
Di mana bisa salah
Dua mode kegagalan klasik adalah keamanan dan kinerja.
Pada sisi keamanan: jika batasan tenant tidak ditegakkan di mana-mana, bug bisa membocorkan data antar pelanggan. Kebocoran ini jarang berupa “peretasan” dramatis—seringkali kesalahan biasa seperti filter yang terlupa, pengecekan izin yang salah konfigurasi, atau job latar yang berjalan tanpa konteks tenant.
Pada sisi kinerja: sumber daya bersama berarti satu tenant sibuk bisa memperlambat yang lain. Efek “noisy neighbor” ini muncul sebagai query lambat, beban kerja mendadak, atau satu pelanggan yang menghabiskan kapasitas API secara tidak proporsional.
Pratinjau cepat pola yang dibahas
Artikel ini membahas blok bangunan yang tim gunakan untuk mengelola risiko tersebut: isolasi data (database, skema, atau baris), identitas dan izin sadar-tenant, kontrol noisy-neighbor, serta pola operasional untuk penskalaan dan manajemen perubahan.
Pertukaran Inti: Isolasi vs Efisiensi
Multi-tenancy adalah pilihan tentang di mana Anda berada pada spektrum: seberapa banyak yang Anda bagi antar tenant versus seberapa banyak yang Anda dedikasikan per tenant. Setiap pola arsitektur di bawah hanyalah titik berbeda pada garis itu.
Sumber daya bersama vs berdedikasi: spektrum inti
Di salah satu ujung, tenant berbagi hampir semuanya: instance aplikasi yang sama, basis data yang sama, antrean yang sama, cache yang sama—dipisahkan secara logis dengan tenant ID dan aturan akses. Ini biasanya termurah dan termudah dijalankan karena Anda mempool kapasitas.
Di ujung lain, tenant mendapatkan “irisan” sendiri dari sistem: database terpisah, compute terpisah, kadang deployment terpisah. Ini meningkatkan keamanan dan kontrol, tetapi juga meningkatkan overhead operasional dan biaya.
Mengapa isolasi dan biaya saling tarik-menarik
Isolasi mengurangi kemungkinan satu tenant mengakses data tenant lain, menghabiskan anggaran kinerja mereka, atau terpengaruh oleh pola penggunaan yang tidak biasa. Itu juga memudahkan memenuhi audit dan persyaratan kepatuhan tertentu.
Efisiensi meningkat ketika Anda mengamortisasi kapasitas menganggur di banyak tenant. Infrastruktur bersama memungkinkan Anda menjalankan lebih sedikit server, mempertahankan pipeline deployment yang lebih sederhana, dan menskalakan berdasarkan permintaan agregat daripada permintaan terburuk per-tenant.
Faktor keputusan umum
Posisi “benar” Anda pada spektrum jarang filosofis—dipengaruhi oleh kendala:
- SLA dan harapan pelanggan: target uptime atau latensi yang ketat mendorong ke isolasi lebih.
- Kepatuhan dan lokasi data: persyaratan dapat memaksa penyimpanan atau lingkungan terdedikasi.
- Tahap pertumbuhan: produk awal sering mulai lebih berbagi untuk bergerak cepat; nanti Anda bisa memperkenalkan opsi terdedikasi untuk pelanggan besar.
- Kematangan operasional: lebih banyak isolasi biasanya berarti lebih banyak hal yang harus dipantau, dipatch, dan dimigrasikan.
Model mental sederhana untuk memilih pola
Tanyakan dua pertanyaan:
-
Seberapa besar blast radius jika satu tenant salah berperilaku atau dikompromikan?
-
Berapa biaya bisnis untuk mengurangi blast radius itu?
Jika blast radius harus sangat kecil, pilih komponen yang lebih berdedikasi. Jika biaya dan kecepatan paling penting, bagikan lebih banyak—dan investasikan pada kontrol akses yang kuat, batas laju, dan monitoring per-tenant untuk menjaga keamanan berbagi.
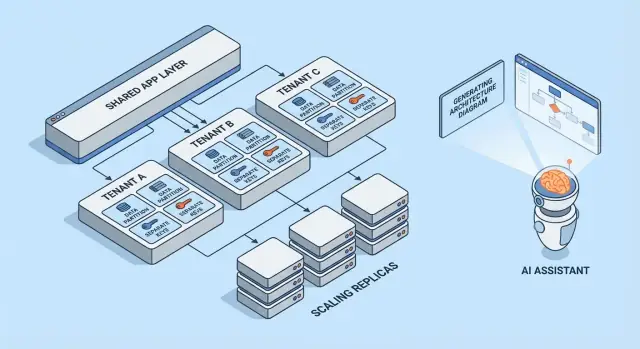
Model Multi-tenant Sekilas
Multi-tenancy bukan satu arsitektur tunggal—itu kumpulan cara untuk berbagi (atau tidak berbagi) infrastruktur antar pelanggan. Model terbaik tergantung seberapa banyak isolasi yang Anda butuhkan, berapa banyak tenant yang Anda harapkan, dan seberapa besar overhead operasional yang tim Anda mampu tangani.
1) Single-tenant (didedikasikan) — baseline
Setiap pelanggan mendapatkan stack aplikasi mereka sendiri (atau setidaknya runtime dan database yang terisolasi). Ini paling mudah dipahami untuk keamanan dan kinerja, tetapi biasanya paling mahal per tenant dan bisa memperlambat skala operasi Anda.
2) Aplikasi bersama + DB bersama — biaya terendah, perlu kehati-hatian tertinggi
Semua tenant berjalan pada aplikasi dan basis data yang sama. Biaya biasanya paling rendah karena Anda memaksimalkan reuse, tetapi Anda harus sangat teliti tentang konteks tenant di mana-mana (query, caching, job latar, ekspor analytics). Kesalahan tunggal dapat menjadi bocoran data lintas-tenant.
3) Aplikasi bersama + DB terpisah — isolasi lebih kuat, lebih banyak operasi
Aplikasi dibagi, tetapi setiap tenant memiliki database sendiri (atau instance database sendiri). Ini meningkatkan kontrol blast-radius untuk insiden, memudahkan backup/restore per-tenant, dan dapat menyederhanakan pembicaraan kepatuhan. Trade-offnya adalah operasional: lebih banyak database untuk diprovisikan, dipantau, dimigrasikan, dan diamankan.
4) Model hybrid untuk “tenant besar”
Banyak produk SaaS mencampur pendekatan: kebanyakan pelanggan hidup di infrastruktur bersama, sementara tenant besar atau yang diatur mendapatkan database terdedikasi atau compute terdedikasi. Hybrid sering menjadi kondisi praktis akhir, tetapi perlu aturan yang jelas: siapa yang memenuhi syarat, berapa biayanya, dan bagaimana upgrade dijalankan.
Jika Anda ingin kajian lebih dalam tentang teknik isolasi di setiap model, lihat /blog/data-isolation-patterns.
Pola Isolasi Data (DB, Skema, Baris)
Isolasi data menjawab pertanyaan sederhana: “Bisakah satu pelanggan melihat atau memengaruhi data pelanggan lain?” Ada tiga pola umum, masing-masing dengan implikasi keamanan dan operasional yang berbeda.
Isolasi tingkat baris (tabel bersama + tenant_id)
Semua tenant berbagi tabel yang sama, dan setiap baris menyertakan kolom tenant_id. Ini model paling efisien untuk tenant kecil-ke-menengah karena meminimalkan infrastruktur dan menjaga pelaporan serta analytics tetap sederhana.
Risikonya juga sederhana: jika ada query yang lupa memfilter berdasarkan tenant_id, Anda bisa membocorkan data. Bahkan satu endpoint “admin” atau job latar bisa menjadi titik lemah. Mitigasi mencakup:
- Menegakkan pemfilteran tenant di lapisan akses data bersama (agar pengembang tidak menulis filter sendiri)
- Menggunakan fitur database seperti row-level security (RLS) bila tersedia
- Menambahkan tes otomatis yang sengaja mencoba akses lintas-tenant
- Mengindeks jalur akses umum (sering
(tenant_id, created_at)atau(tenant_id, id)) agar query ber-skop-tenant tetap cepat
Skema-per-tenant (sama database, skema terpisah)
Setiap tenant mendapat skema sendiri (namespace seperti tenant_123.users, tenant_456.users). Ini meningkatkan isolasi dibanding berbagi baris dan dapat mempermudah ekspor tenant atau tuning khusus tenant.
Trade-offnya adalah overhead operasional. Migrasi harus dijalankan di banyak skema, dan kegagalan menjadi lebih rumit: Anda mungkin berhasil memigrasi 9.900 tenant dan tersangkut pada 100. Monitoring dan tooling penting di sini—proses migrasi Anda perlu perilaku retry dan pelaporan yang jelas.
Database-per-tenant (database terpisah)
Setiap tenant mendapat database terpisah. Isolasinya kuat: batas akses lebih jelas, query noisy dari satu tenant kecil kemungkinan memengaruhi tenant lain, dan merestore satu tenant dari backup jauh lebih bersih.
Biaya dan skala adalah kekurangan utama: lebih banyak database untuk dikelola, lebih banyak pool koneksi, dan potensi kerja upgrade/migrasi lebih besar. Banyak tim menggunakan model ini untuk tenant bernilai tinggi atau yang diatur, sementara tenant kecil tetap di infrastruktur bersama.
Sharding dan strategi penempatan saat tenant tumbuh
Sistem nyata sering mencampur pola-pola ini. Jalur umum adalah isolasi tingkat baris untuk pertumbuhan awal, lalu “mengangkat” tenant besar ke skema atau database terpisah.
Sharding menambahkan lapisan penempatan: memutuskan cluster database mana tempat tenant tinggal (berdasarkan region, tier ukuran, atau hashing). Kuncinya adalah membuat penempatan tenant eksplisit dan dapat diubah—sehingga Anda dapat memindahkan tenant tanpa menulis ulang aplikasi, dan menskalakan dengan menambah shard alih-alih merancang ulang semuanya.
Identitas, Akses, dan Konteks Tenant
Multi-tenancy gagal dengan cara yang mengejutkan biasa: filter yang terlupa, objek cache dibagi antar tenant, atau fitur admin yang “lupa” siapa yang membuat permintaan. Perbaikannya bukan satu fitur keamanan besar—melainkan konteks tenant yang konsisten dari byte pertama sebuah permintaan hingga query basis data terakhir.
Identifikasi tenant (bagaimana Anda tahu “siapa”)
Kebanyakan produk SaaS memilih satu identifier utama dan menganggap yang lain sebagai kenyamanan:
- Subdomain:
acme.yourapp.commudah untuk pengguna dan bekerja baik dengan pengalaman bermerek tenant. - Header: berguna untuk klien API dan layanan internal (tetapi harus diautentikasi).
- Claim token: JWT yang ditandatangani (atau sesi) menyertakan
tenant_id, sehingga sulit dimanipulasi.
Pilih satu sumber kebenaran dan log itu di mana-mana. Jika Anda mendukung beberapa sinyal (subdomain + token), definisikan presedensi dan tolak permintaan yang ambigu.
Pembatasan permintaan (bagaimana setiap query tetap dalam tenant)
Aturan bagus: setelah Anda menyelesaikan tenant_id, semuanya di downstream harus membacanya dari satu tempat (konteks permintaan), bukan menurunkannya lagi.
Penjaga umum meliputi:
- Middleware yang melampirkan
tenant_idke konteks permintaan - Helper akses data yang mengharuskan
tenant_idsebagai parameter - Penegakan di database (seperti kebijakan row-level) sehingga kesalahan gagal tertutup
handleRequest(req):
tenantId = resolveTenant(req) // subdomain/header/token
req.context.tenantId = tenantId
return next(req)
Dasar-dasar otorisasi (peran dalam tenant)
Pisahkan autentikasi (siapa pengguna) dari otorisasi (apa yang boleh mereka lakukan).
Peran SaaS tipikal adalah Owner / Admin / Member / Read-only, tetapi kuncinya adalah cakupan: seorang pengguna bisa jadi Admin di Tenant A dan Member di Tenant B. Simpan izin per-tenant, bukan global.
Mencegah kebocoran lintas-tenant (tes dan penjaga)
Perlakukan akses lintas-tenant seperti insiden tingkat atas dan cegah secara proaktif:
- Tambahkan tes otomatis yang mencoba membaca data Tenant B saat terautentikasi sebagai Tenant A
- Buat bug filter tenant yang hilang lebih sulit untuk dikirim (linters, query builder, parameter tenant wajib)
- Log dan beri alert pola mencurigakan (mis. mismatch tenant antara token dan subdomain)
Jika Anda ingin checklist operasional lebih dalam, tautkan aturan ini ke runbook engineering Anda di /security dan jaga versinya bersama kode Anda.
Isolasi Selain Basis Data
Rencanakan Model Tenant Anda
Susun rencana aplikasi multi-tenant lewat chat dan iterasi aman dengan mode perencanaan.
Isolasi basis data hanyalah separuh cerita. Banyak insiden multi-tenant nyata terjadi di pipa bersama di sekitar aplikasi Anda: cache, antrean, dan penyimpanan objek. Lapisan-lapisan ini cepat, nyaman, dan mudah tanpa sengaja menjadi global.
Cache bersama: cegah tabrakan kunci dan kebocoran data
Jika beberapa tenant berbagi Redis atau Memcached, aturan utamanya sederhana: jangan pernah menyimpan kunci tanpa konteks tenant.
Pola praktis adalah memberi prefix setiap kunci dengan identifier tenant yang stabil (bukan domain email, bukan nama tampilan). Contoh: t:{tenant_id}:user:{user_id}. Ini melakukan dua hal:
- Mencegah tabrakan di mana dua tenant punya ID internal yang sama
- Membuat invalidasi massal layak dilakukan (hapus berdasarkan prefix) selama insiden dukungan atau migrasi
Juga tentukan apa yang boleh dibagi secara global (mis. feature flag publik, metadata statis) dan dokumentasikan—global tidak sengaja adalah sumber umum eksposur lintas-tenant.
Limit laju dan kuota sadar-tenant
Bahkan jika data terisolasi, tenant masih bisa memengaruhi yang lain melalui compute bersama. Tambahkan batas sadar-tenant di pinggiran:
- Batas rate API per tenant (dan sering per pengguna dalam tenant)
- Kuota untuk operasi mahal (ekspor, pembuatan laporan, panggilan AI)
Buat batas tersebut terlihat (header, pemberitahuan UI) sehingga pelanggan memahami throttling adalah kebijakan, bukan ketidakstabilan.
Job latar: partisi antrean berdasarkan tenant
Satu antrean bersama dapat membuat satu tenant sibuk mendominasi waktu worker.
Perbaikan umum:
- Antrean terpisah per tier/plan (mis.
free,pro,enterprise) - Antrean terpartisi per-bucket tenant (hash tenant_id ke N antrean)
- Penjadwalan sadar-tenant sehingga setiap tenant mendapat irisan waktu yang adil
Selalu propagasi konteks tenant ke payload job dan log untuk menghindari efek samping ke tenant yang salah.
Penyimpanan file/objek: path, kebijakan, dan kunci terpisah
Untuk penyimpanan gaya S3/GCS, isolasi biasanya berbasis path dan kebijakan:
- Bucket-per-tenant untuk pemisahan ketat (batas lebih kuat, overhead lebih besar)
- Bucket bersama dengan prefix tenant (lebih sederhana, memerlukan IAM dan signed URL yang hati-hati)
Apa pun pilihan Anda, pastikan upload/download memvalidasi kepemilikan tenant pada setiap permintaan, bukan hanya di UI.
Menangani Noisy Neighbors dan Penggunaan Sumber Daya yang Adil
Sistem multi-tenant berbagi infrastruktur, yang berarti satu tenant bisa tanpa sengaja (atau sengaja) mengonsumsi lebih dari bagiannya. Ini masalah noisy neighbor: satu beban kerja keras menyebabkan penurunan performa untuk semua orang.
Bagaimana "noisy neighbor" terlihat
Bayangkan fitur pelaporan yang mengekspor setahun data ke CSV. Tenant A menjadwalkan 20 ekspor pada jam 9:00. Ekspor tersebut menyerap CPU dan I/O DB, sehingga layar aplikasi Tenant B mulai timeout—meskipun B tidak melakukan apa-apa yang tidak biasa.
Kontrol sumber daya: batas, kuota, dan pembentukan beban kerja
Mencegah ini dimulai dengan batas sumber daya eksplisit:
- Rate limits (permintaan per detik) per tenant dan per endpoint, sehingga API mahal tidak bisa diserbu.
- Kuota (total harian/bulanan) untuk hal seperti ekspor, email, panggilan AI, atau job latar.
- Workload shaping: masukkan tugas berat (ekspor, impor, re-indexing) ke antrean dengan cap concurrency per-tenant dan aturan prioritas.
Pola praktis adalah memisahkan lalu lintas interaktif dari pekerjaan batch: jaga request user-facing pada jalur cepat, dan dorong sisanya ke antrean yang terkontrol.
Circuit breaker dan bulkhead per-tenant
Tambahkan katup pengaman yang memicu saat tenant melewati ambang:
- Circuit breakers: menolak sementara atau menunda operasi mahal ketika tingkat error, latensi, atau kedalaman antrean melebihi batas untuk tenant itu.
- Bulkheads: mengisolasi pool bersama (koneksi DB, thread worker, cache) sehingga satu tenant tidak menghabiskan kapasitas global.
Jika dilakukan dengan baik, Tenant A bisa memperlambat kecepatan ekspornya sendiri tanpa menjatuhkan Tenant B.
Kapan memindahkan tenant ke kapasitas terdedikasi
Pindahkan tenant ke sumber daya terdedikasi ketika mereka konsisten melebihi asumsi bersama: throughput tinggi berkelanjutan, lonjakan tak terduga terkait event bisnis, kebutuhan kepatuhan yang ketat, atau workload yang memerlukan tuning kustom. Aturan sederhana: jika melindungi tenant lain memerlukan throttling permanen terhadap pelanggan yang membayar, saatnya kapasitas terdedikasi (atau tier yang lebih tinggi) daripada terus menerus memperbaiki masalah.
Pola Penskalaan yang Bekerja untuk SaaS Multi-tenant
Validasi Isolasi dengan Kode
Jadikan kompromi isolasi Anda sebagai baseline kerja yang bisa diukur.
Penskalaan multi-tenant bukan sekadar “lebih banyak server” melainkan menjaga pertumbuhan satu tenant agar tidak mengejutkan semua orang. Pola terbaik membuat skala dapat diprediksi, terukur, dan dapat dibalik.
Penskalaan horizontal untuk layanan stateless
Mulailah dengan membuat tier web/API stateless: simpan sesi di cache bersama (atau gunakan auth berbasis token), simpan upload di object storage, dan dorong pekerjaan lama ke job latar. Setelah request tidak bergantung pada memori atau disk lokal, Anda dapat menambah instance di belakang load balancer dan menskalakan keluar dengan cepat.
Tip praktis: jaga konteks tenant di tepi (diturunkan dari subdomain atau header) dan teruskan ke setiap handler permintaan. Stateless tidak berarti tak menyadari tenant—artinya menyadari tenant tanpa server yang lengket.
Hotspot per-tenant: identifikasi dan ratakan
Kebanyakan masalah penskalaan adalah “satu tenant berbeda.” Waspadai hotspot seperti:
- Satu tenant menghasilkan trafik yang sangat besar
- Beberapa tenant dengan dataset sangat besar
- Penggunaan batch (laporan akhir bulan, impor malam)
Taktik perataan termasuk batas laju per-tenant, ingestion berbasis antrean, caching jalur baca khusus tenant, dan mem-shard tenant berat ke pool worker terpisah.
Read replica, partisi, dan beban kerja asinkron
Gunakan read replica untuk beban baca berat (dashboard, pencarian, analytics) dan pertahankan tulis di primary. Partisi (berdasarkan tenant, waktu, atau keduanya) membantu menjaga indeks lebih kecil dan query lebih cepat. Untuk tugas mahal—ekspor, scoring ML, webhook—pilih job asinkron dengan idempoten supaya retry tidak menggandakan beban.
Sinyal perencanaan kapasitas dan ambang sederhana
Jaga sinyal sederhana dan sadar-tenant: p95 latency, tingkat error, kedalaman antrean, CPU DB, dan rate permintaan per-tenant. Tetapkan ambang mudah (mis., “queue depth > N selama 10 menit” atau “p95 > X ms”) yang memicu autoscaling atau pembatasan sementara tenant—sebelum tenant lain merasakannya.
Observability dan Operasi per Tenant
Sistem multi-tenant tidak biasanya gagal secara global dulu—mereka biasanya gagal untuk satu tenant, satu tier plan, atau satu workload bising. Jika log dan dashboard Anda tidak bisa menjawab “tenant mana yang terdampak?” dalam beberapa detik, waktu on-call berubah jadi tebak-tebakan.
Log, metrik, dan trace yang sadar-tenant
Mulailah dengan konteks tenant konsisten di seluruh telemetri:
- Logs: sertakan
tenant_id,request_id, danactor_id(user/service) yang stabil pada setiap request dan job latar. - Metrics: kirimkan counter dan histogram latensi yang dipisah berdasarkan tier tenant minimal (mis.,
tier=basic|premium) dan berdasarkan endpoint tingkat tinggi (bukan URL mentah). - Traces: propagasi konteks tenant sebagai atribut trace sehingga Anda bisa memfilter trace lambat ke tenant tertentu dan melihat di mana waktu dihabiskan (DB, cache, panggilan pihak ketiga).
Jaga cardinality: metrik per-tenant untuk semua tenant bisa mahal. Kompromi umum adalah metrik per-tier secara default ditambah drill-down per-tenant on-demand (mis., sampling trace untuk “20 tenant teratas berdasarkan trafik” atau “tenant yang sedang melanggar SLO”).
Menghindari kebocoran data sensitif di telemetri
Telemetri adalah saluran ekspor data. Perlakukan seperti data produksi.
Utamakan ID daripada konten: log customer_id=123 daripada nama, email, token, atau payload query. Tambahkan redaksi di layer logger/SDK, dan blocklist rahasia umum (header Authorization, API key). Untuk alur dukungan, simpan payload debug di sistem terpisah yang terkontrol akses—jangan di log bersama.
SLO per tier tenant (tanpa janji berlebihan)
Definisikan SLO yang sesuai dengan apa yang benar-benar bisa Anda tegakkan. Tenant premium mungkin mendapatkan toleransi latensi/error lebih ketat, tetapi hanya jika Anda juga punya kontrol (rate limit, isolasi beban kerja, antrean prioritas). Publikasikan SLO tier sebagai target, dan pantau per tier serta untuk sekumpulan tenant bernilai tinggi yang dikurasi.
Runbook on-call: insiden umum di SaaS multi-tenant
Runbook Anda harus dimulai dengan “identifikasi tenant yang terdampak” lalu tindakan isolasi tercepat:
- Noisy neighbor: throttle tenant, jeda job berat, atau pindahkan ke antrean prioritas lebih rendah.
- DB hotspot/runaway queries: aktifkan query timeout, inspeksi query teratas per tenant, terapkan index atau batasi endpoint.
- Bug konteks tenant (mix-up data): segera nonaktifkan feature flag atau endpoint dan verifikasi scoping tenant di pemeriksaan akses.
- Penumpukan job latar: kosongkan antrean per-tenant, cap concurrency, dan replay dengan safeguard idempoten.
Secara operasional, tujuannya sederhana: deteksi per tenant, kendalikan per tenant, dan pulihkan tanpa memengaruhi semua orang.
Deploy, Migrasi, dan Rilis Per-Tenant
Multi-tenant SaaS mengubah irama pengiriman. Anda tidak hanya mendeply “sebuah aplikasi”; Anda mendeploy runtime bersama dan jalur data bersama yang banyak pelanggan andalkan sekaligus. Tujuannya adalah menghadirkan fitur baru tanpa memaksa upgrade big-bang tersinkronisasi di semua tenant.
Rolling deploy dan migrasi tanpa downtime
Utamakan pola deployment yang mentolerir versi campuran untuk jangka pendek (blue/green, canary, rolling). Itu hanya bekerja jika perubahan basis data Anda juga bertahap.
Aturan praktis adalah expand → migrate → contract:
- Expand: tambahkan kolom/tabel/index baru tanpa merusak kode lama.
- Migrate: backfill data dalam batch (sering per tenant) dan verifikasi.
- Contract: hapus field lama hanya setelah semua instance app tidak lagi mengandalkannya.
Untuk tabel yang aktif, lakukan backfill secara bertahap (dan throttle), kalau tidak Anda menciptakan sendiri event noisy-neighbor selama migrasi.
Feature flag per tenant untuk rilis lebih aman
Feature flag tingkat tenant memungkinkan Anda mengirim kode secara global sambil mengaktifkan perilaku secara selektif.
Ini mendukung:
- Program akses awal untuk beberapa tenant
- Rollback cepat dengan menonaktifkan fitur hanya untuk tenant terdampak
- Eksperimen A/B tanpa memfork deployment
Jaga sistem flag dapat diaudit: siapa mengaktifkan apa, untuk tenant mana, dan kapan.
Versi dan ekspektasi kompatibilitas mundur
Asumsikan beberapa tenant mungkin tertinggal pada konfigurasi, integrasi, atau pola penggunaan. Rancang API dan event dengan versi yang jelas sehingga producer baru tidak merusak consumer lama.
Ekspektasi umum untuk ditetapkan secara internal:
- Rilis baru harus membaca bentuk data lama dan baru selama jendela migrasi.
- Deprecation memerlukan timeline yang dipublikasikan (bahkan jika hanya catatan internal plus template email untuk pelanggan).
Manajemen konfigurasi spesifik tenant
Perlakukan konfigurasi tenant sebagai permukaan produk: perlu validasi, default, dan riwayat perubahan.
Simpan konfigurasi terpisah dari kode (dan idealnya terpisah dari secret runtime), dan dukung fallback safe-mode saat konfigurasi tidak valid. Halaman internal ringan seperti /settings/tenants bisa menghemat jam saat respons insiden dan rilis bertahap.
Bagaimana Arsitektur yang Dihasilkan AI Membantu (dan Batasannya)
Tegakkan Konteks Tenant di Mana Saja
Minta ke Koder.ai pola middleware dan akses data yang menjaga konsistensi konteks tenant.
AI dapat mempercepat pemikiran arsitektur awal untuk SaaS multi-tenant, tetapi bukan pengganti penilaian engineering, pengujian, atau tinjauan keamanan. Perlakukan sebagai mitra brainstorming berkualitas tinggi yang menghasilkan draf—lalu verifikasi setiap asumsi.
Apa yang seharusnya (dan tidak seharusnya) dilakukan arsitektur yang dihasilkan AI
AI berguna untuk menghasilkan opsi dan menyorot mode kegagalan umum (seperti di mana konteks tenant bisa hilang, atau di mana sumber daya bersama bisa menimbulkan kejutan). AI tidak seharusnya memutuskan model Anda, menjamin kepatuhan, atau memvalidasi performa. AI tidak bisa melihat trafik nyata Anda, kekuatan tim Anda, atau edge case yang tersembunyi di integrasi warisan.
Input yang penting: kebutuhan, kendala, risiko, pertumbuhan
Kualitas keluaran bergantung pada apa yang Anda berikan. Input yang membantu termasuk:
- Jumlah tenant hari ini vs 12–24 bulan ke depan, dan volume data yang diharapkan per tenant
- Persyaratan isolasi (kontraktual, regulasi, harapan pelanggan)
- Anggaran dan kapasitas operasional (maturity on-call, dukungan SRE, tooling)
- Target latensi, pola puncak penggunaan, dan burstiness per tenant
- Toleransi risiko: apa yang terjadi jika satu tenant memengaruhi tenant lain?
Menggunakan AI untuk mengusulkan opsi pola dengan trade-off
Minta 2–4 desain kandidat (misalnya: database-per-tenant vs skema-per-tenant vs isolasi tingkat baris) dan minta tabel trade-off yang jelas: biaya, kompleksitas operasional, blast radius, upaya migrasi, dan batasan skala. AI bagus dalam mencantumkan gotcha yang bisa Anda ubah jadi pertanyaan desain untuk tim Anda.
Jika Anda ingin beralih dari “draf arsitektur” ke prototipe kerja lebih cepat, platform vibe-coding seperti Koder.ai dapat membantu Anda mengubah pilihan itu menjadi kerangka aplikasi nyata lewat chat—seringkali dengan frontend React dan backend Go + PostgreSQL—jadi Anda bisa memvalidasi propagasi konteks tenant, rate limit, dan alur migrasi lebih awal. Fitur seperti planning mode plus snapshot/rollback sangat berguna saat mengiterasi model data multi-tenant.
Menggunakan AI untuk menghasilkan threat model dan checklist
AI dapat menyusun threat model sederhana: titik masuk, boundary kepercayaan, propagasi konteks tenant, dan kesalahan umum (seperti pengecekan otorisasi yang hilang di job latar). Gunakan itu untuk menghasilkan checklist review untuk PR dan runbook—tetapi validasi dengan keahlian keamanan nyata dan riwayat insiden Anda sendiri.
Checklist Praktis untuk Tim Anda
Memilih pendekatan multi-tenant lebih soal kecocokan daripada “praktik terbaik”: sensitivitas data Anda, laju pertumbuhan, dan seberapa banyak kompleksitas operasional yang bisa Anda tanggung.
Checklist langkah demi langkah (pakai ini di workshop 30 menit)
-
Data: Data apa yang dibagi antar tenant (jika ada)? Apa yang tidak boleh pernah dikolat bersama?
-
Identitas: Di mana identitas tenant disimpan (invite link, domain, klaim SSO)? Bagaimana konteks tenant ditetapkan di setiap permintaan?
-
Isolasi: Putuskan tingkat isolasi default Anda (baris/skema/database) dan identifikasi pengecualian (mis., pelanggan enterprise yang butuh pemisahan lebih kuat).
-
Penskalaan: Identifikasi tekanan penskalaan pertama yang Anda harapkan (storage, trafik baca, job latar, analytics) dan pilih pola paling sederhana yang mengatasinya.
Pertanyaan untuk divalidasi dengan engineer dan peninjau keamanan
- Bagaimana kita mencegah akses lintas-tenant jika seorang developer lupa filter?
- Apa cerita audit per tenant kita (siapa melakukan apa, kapan)?
- Bagaimana kita menangani penghapusan dan retensi data per tenant?
- Berapa blast radius dari migrasi buruk atau query runaway?
- Dapatkah kita throttling, rate-limit, dan menganggarkan sumber daya per tenant?
Tanda bahaya yang butuh desain lebih mendalam
- “Kita akan menambahkan pengecekan tenant nanti.”
- Alat admin bersama yang bisa melihat semuanya tanpa kontrol ketat.
- Tidak ada rencana untuk backup/restore per-tenant atau respons insiden.
- Satu antrean/worker pool tanpa fairness per-tenant.
Contoh ringkasan “tindakan berikutnya” yang direkomendasikan
Rekomendasi: Mulai dengan isolasi tingkat baris + penegakan konteks tenant yang ketat, tambahkan throttle per-tenant, dan definisikan jalur peningkatan ke isolasi skema/database untuk tenant berisiko tinggi.
Tindakan berikutnya (2 minggu): threat-model boundary tenant, prototipe penegakan di satu endpoint, dan lakukan latihan migrasi pada salinan staging. Untuk panduan rollout, lihat /blog/tenant-release-strategies.