05 Okt 2025·8 menit
RabbitMQ untuk Aplikasi Anda: Pola, Setup, dan Operasional
Pelajari cara menggunakan RabbitMQ dalam aplikasi Anda: konsep inti, pola umum, tips keandalan, skala, keamanan, dan pemantauan untuk produksi.
Pelajari cara menggunakan RabbitMQ dalam aplikasi Anda: konsep inti, pola umum, tips keandalan, skala, keamanan, dan pemantauan untuk produksi.
RabbitMQ adalah broker pesan: ia berada di antara bagian-bagian sistem Anda dan memindahkan “pekerjaan” (pesan) secara andal dari producer ke consumer. Tim aplikasi biasanya mengadopsinya ketika panggilan sinkron langsung (service-ke-service HTTP, database bersama, cron) mulai menciptakan ketergantungan rapuh, beban tidak merata, dan rantai kegagalan yang sulit di-debug.
Lonjakan trafik dan beban tidak merata. Jika aplikasi Anda mendapat 10× lebih banyak pendaftaran atau pesanan dalam jendela singkat, memproses semuanya sekaligus bisa membanjiri layanan downstream. Dengan RabbitMQ, producer mengantri tugas dengan cepat dan consumer memprosesnya secara bertahap dengan laju terkontrol.
Keterikatan erat antar layanan. Ketika Service A harus memanggil Service B dan menunggu, kegagalan dan latensi merambat. Messaging melepaskan keterikatan: A mempublikasikan pesan dan melanjutkan; B memproses saat tersedia.
Penanganan kegagalan yang lebih aman. Tidak setiap kegagalan harus terlihat sebagai error ke pengguna. RabbitMQ membantu Anda melakukan retry di background, mengisolasi pesan “beracun”, dan menghindari kehilangan pekerjaan selama pemadaman sementara.
Tim biasanya mendapatkan aliran kerja lebih halus (menyangga puncak), layanan yang terlepas (lebih sedikit ketergantungan saat runtime), dan retry terkontrol (lebih sedikit reprocessing manual). Sama pentingnya, jadi lebih mudah menebak di mana pekerjaan tersendat—pada producer, di antrian, atau di consumer.
Panduan ini fokus pada RabbitMQ praktis untuk tim aplikasi: konsep inti, pola umum (pub/sub, work queues, retry dan dead-letter queue), dan perhatian operasional (keamanan, skala, observabilitas, troubleshooting).
Ini tidak dimaksudkan sebagai walkthrough lengkap spesifikasi AMQP atau deep dive setiap plugin RabbitMQ. Tujuannya membantu Anda merancang aliran pesan yang tetap mudah dipelihara di sistem nyata.
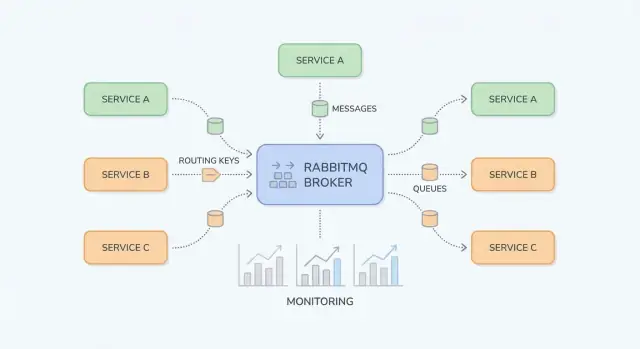
RabbitMQ adalah broker pesan yang merutekan pesan antar bagian sistem Anda, sehingga producer bisa menyerahkan pekerjaan dan consumer bisa memprosesnya ketika siap.
Dengan panggilan HTTP langsung, Service A mengirim permintaan ke Service B dan biasanya menunggu respons. Jika Service B lambat atau down, Service A gagal atau terhenti, dan Anda harus mengatasi timeouts, retries, dan backpressure di setiap pemanggil.
Dengan RabbitMQ (umumnya lewat AMQP), Service A mempublikasikan pesan ke broker. RabbitMQ menyimpan dan merutekan pesan itu ke queue yang tepat, dan Service B mengonsumsinya secara asinkron. Pergeseran kunci adalah Anda berkomunikasi melalui lapisan tengah yang tahan banting yang meratakan lonjakan dan memperhalus beban yang tidak merata.
Messaging cocok ketika Anda:
Messaging kurang cocok ketika:
Sinkron (HTTP):
Sebuah layanan checkout memanggil layanan invoicing lewat HTTP: “Buat invoice.” Pengguna menunggu sementara invoicing berjalan. Jika invoicing lambat, latensi checkout meningkat; jika down, checkout gagal.
Asinkron (RabbitMQ):
Checkout mempublikasikan invoice.requested dengan id pesanan. Pengguna mendapat konfirmasi segera bahwa pesanan diterima. Invoicing mengonsumsi pesan, membuat invoice, lalu mempublikasikan invoice.created agar email/notifikasi menindaklanjuti. Setiap langkah bisa melakukan retry sendiri, dan gangguan sementara tidak otomatis mematahkan alur end-to-end.
RabbitMQ paling mudah dipahami bila Anda memisahkan “tempat pesan dipublikasikan” dari “tempat pesan disimpan.” Producer mempublikasikan ke exchange; exchange merutekan ke queue; consumer membaca dari queue.
Sebuah exchange tidak menyimpan pesan. Ia mengevaluasi aturan dan meneruskan pesan ke satu atau beberapa queue.
billing atau email).Sebuah queue adalah tempat pesan menunggu sampai consumer memprosesnya. Sebuah queue bisa punya satu atau banyak consumer (competing consumers), dan pesan biasanya dikirim ke satu consumer pada satu waktu.
Sebuah binding menghubungkan exchange ke queue dan mendefinisikan aturan routing. Pikirkan seperti: “Saat pesan masuk exchange X dengan routing key Y, kirimkan ke queue Q.” Anda bisa mengikat beberapa queue ke exchange yang sama (pub/sub) atau mengikat satu queue beberapa kali untuk routing key berbeda.
Untuk direct exchange, routing bersifat eksak. Untuk topic exchange, routing key berbentuk kata-kata dipisah titik, misalnya:
orders.createdorders.eu.refundedBinding dapat memasukkan wildcard:
* mencocokkan tepat satu kata (mis., orders.* cocok orders.created)# mencocokkan nol atau lebih kata (mis., orders.# cocok orders.created dan orders.eu.refunded)Ini memberi cara bersih untuk menambah konsumer tanpa mengubah producer—buat queue baru dan bind dengan pola yang Anda butuhkan.
Setelah RabbitMQ mengirim pesan, consumer melaporkan apa yang terjadi:
Hati-hati dengan requeue: pesan yang selalu gagal bisa berputar tanpa henti dan memblokir queue. Banyak tim memadukan nack dengan strategi retry dan dead-letter queue sehingga kegagalan ditangani dengan prediktabel.
RabbitMQ unggul ketika Anda perlu memindahkan pekerjaan atau notifikasi antar bagian sistem tanpa membuat semuanya menunggu satu langkah lambat. Berikut pola praktis yang sering muncul di produk sehari-hari.
Ketika banyak konsumer harus merespons event yang sama—tanpa publisher tahu siapa mereka—publish/subscribe adalah pilihan bersih.
Contoh: ketika pengguna memperbarui profilnya, Anda mungkin memberi tahu indexing pencarian, analytics, dan sinkron CRM secara paralel. Dengan fanout exchange Anda broadcast ke semua queue yang terikat; dengan topic exchange Anda merutekan secara selektif (mis., user.updated, user.deleted). Ini menghindari keterikatan erat layanan dan memungkinkan tim menambah subscriber baru nanti tanpa mengubah producer.
Jika tugas memakan waktu, dorong ke queue dan biarkan worker memproses secara asinkron:
Ini menjaga permintaan web tetap cepat sambil memungkinkan Anda menskalakan worker secara independen. Ini juga cara alami mengontrol konkurensi: queue menjadi “daftar tugas”, dan jumlah worker menjadi “kenop throughput”.
Banyak alur kerja melintasi batas layanan: order → billing → shipping adalah contoh klasik. Alih-alih satu layanan memanggil berikutnya dan memblokir, setiap layanan bisa mempublikasikan event ketika menyelesaikan langkahnya. Layanan downstream mengonsumsi event dan melanjutkan alur.
Ini meningkatkan ketahanan (pemadaman sementara shipping tidak mematahkan checkout) dan memperjelas kepemilikan: setiap layanan bereaksi pada event yang relevan.
RabbitMQ juga menjadi buffer antara aplikasi Anda dan dependensi yang lambat atau flakey (API pihak ketiga, sistem legacy, database batch). Anda mengantri request dengan cepat, lalu memprosesnya dengan retry terkontrol. Jika dependensi down, pekerjaan menumpuk dengan aman dan akan dikuras nanti—daripada menyebabkan timeout di seluruh aplikasi.
Jika Anda berencana memperkenalkan queue secara bertahap, sebuah “async outbox” kecil atau satu queue job latar seringkali langkah awal yang baik (lihat /blog/next-steps-rollout-plan).
Setup RabbitMQ tetap nyaman bekerja bila rute mudah diprediksi, penamaan konsisten, dan payload berkembang tanpa merusak konsumer lama. Sebelum menambah queue lagi, pastikan “cerita” sebuah pesan jelas: dari mana ia berasal, bagaimana dirutekan, dan bagaimana rekan bisa men-debugnya end-to-end.
Memilih exchange yang tepat sejak awal mengurangi binding ad-hoc dan fan-out yang tak terduga:
billing.invoice.created).billing.*.created, *.invoice.*). Ini pilihan paling umum untuk routing bergaya event yang mudah dipelihara.Aturan praktis: jika Anda menemukan diri mengimplementasikan logika routing kompleks di kode, mungkin itu cocok untuk pola topic exchange.
Perlakukan body pesan seperti API publik. Gunakan versioning eksplisit (misalnya field top-level schema_version: 2) dan usahakan backward compatibility:
Ini menjaga konsumer lama tetap bekerja sementara konsumer baru mengadopsi schema baru sesuai jadwal.
Buat troubleshooting murah dengan menstandarkan metadata:
correlation_id: mengikat perintah/event yang termasuk dalam satu aksi bisnis.\trace_id (atau W3C traceparent): menghubungkan pesan ke distributed tracing di jalur HTTP dan alur async.Ketika setiap publisher menyetel ini secara konsisten, Anda bisa mengikuti satu transaksi melintasi banyak layanan tanpa tebakan.
Gunakan nama yang dapat diprediksi dan mudah dicari. Satu pola umum:
<domain>.<type> (mis., billing.events)\<domain>.<entity>.<verb> (mis., billing.invoice.created)\<service>.<purpose> (mis., reporting.invoice_created.worker)Konsistensi lebih baik daripada kepintaran: Anda (dan tim on-call) akan berterima kasih nanti.
Messaging yang andal sebagian besar tentang merencanakan kegagalan: konsumer crash, API downstream timeout, dan beberapa event rusak. RabbitMQ memberi Anda alatnya, tetapi kode aplikasi harus bekerja sama.
Setup umum adalah at-least-once delivery: sebuah pesan mungkin dikirim lebih dari sekali, tetapi tidak boleh hilang tanpa jejak. Ini terjadi ketika konsumer menerima pesan, mulai kerja, lalu gagal sebelum meng-ack—RabbitMQ akan requeue dan mengirim ulang.
Intinya praktis: duplikat adalah normal, jadi handler Anda harus aman dijalankan berkali-kali.
Idempotensi berarti “memproses pesan yang sama dua kali menghasilkan efek yang sama seperti sekali.” Pendekatan berguna termasuk:
message_id stabil (atau business key seperti order_id + event_type + version) dan simpan di tabel/cache “sudah diproses” dengan TTL.\PENDING) atau constraint unik database untuk mencegah double-create.\Retry paling baik diperlakukan sebagai alur terpisah, bukan loop ketat di consumer.
Pola umum:
Ini menciptakan backoff tanpa membuat pesan “terkunci” sebagai unacked.
Beberapa pesan tak pernah berhasil (schema rusak, data referensi hilang, bug kode). Deteksi dengan:
Rutekan ini ke DLQ untuk dikarantina. Perlakukan DLQ sebagai inbox operasional: inspeksi payload, perbaiki isu mendasar, lalu replay manual pesan terpilih (sebaiknya via tool/script terkendali) daripada memasukkan semuanya kembali ke queue utama.
Performa RabbitMQ biasanya dibatasi oleh beberapa faktor praktis: bagaimana Anda mengelola koneksi, seberapa cepat konsumer memproses pekerjaan dengan aman, dan apakah queue digunakan sebagai “storage.” Tujuannya throughput stabil tanpa backlog yang tumbuh.
Kesalahan umum adalah membuka koneksi TCP baru untuk setiap publisher atau consumer. Koneksi lebih berat daripada yang Anda kira (handshake, heartbeat, TLS), jadi pertahankan koneksi jangka panjang dan reuse.\
Gunakan channel untuk memultiplex kerja di sejumlah koneksi lebih sedikit. Aturan praktis: sedikit koneksi, banyak channel. Namun, jangan buat ribuan channel sembarangan—setiap channel punya overhead, dan library klien mungkin punya limit sendiri. Lebih baik punya pool channel kecil per layanan dan reuse channel untuk publishing.
Jika konsumer menarik terlalu banyak pesan sekaligus, Anda akan melihat lonjakan memori, waktu proses panjang, dan latensi tidak merata. Atur prefetch (QoS) sehingga setiap konsumer hanya memegang jumlah unacked yang terkontrol.
Panduan praktis:
Pesan besar menurunkan throughput dan meningkatkan tekanan memori (pada publisher, broker, dan consumer). Jika payload besar (dokumen, gambar, JSON besar), pertimbangkan menyimpannya di tempat lain (object storage atau database) dan kirim hanya ID + metadata lewat RabbitMQ.
Heuristik baik: jaga pesan di kisaran KB, bukan MB.
Pertumbuhan antrean adalah gejala, bukan strategi. Tambahkan backpressure agar producer melambat ketika consumer tak bisa mengejar:
Jika ragu, ubah satu pengaturan pada satu waktu dan ukur: publish rate, ack rate, panjang antrean, dan latensi end-to-end.
Keamanan RabbitMQ sebagian besar tentang mengeraskan “tepi”: bagaimana klien terhubung, siapa yang bisa melakukan apa, dan bagaimana menjaga kredensial tetap aman. Gunakan checklist ini sebagai baseline, lalu sesuaikan dengan kebutuhan kepatuhan Anda.
Izin RabbitMQ kuat bila dipakai konsisten.
Untuk hardening operasional (port, firewall, auditing), simpan runbook internal singkat dan link-kan dari /docs/security agar tim mengikuti standar yang sama.
Saat RabbitMQ bermasalah, gejala muncul di aplikasi Anda dulu: endpoint lambat, timeout, pembaruan hilang, atau job yang “tak selesai.” Observabilitas yang baik memungkinkan Anda mengonfirmasi apakah broker penyebabnya, menemukan bottleneck (publisher, broker, atau consumer), dan bertindak sebelum pengguna menyadari.
Mulailah dengan sekumpulan sinyal kecil yang memberi tahu apakah pesan mengalir.
Alert pada tren, bukan hanya ambang absolut.
Log broker membantu memisahkan “RabbitMQ down” dari “klien yang menyalahgunakannya.” Cari kegagalan autentikasi, koneksi diblokir (resource alarms), dan error channel yang sering. Di sisi aplikasi, pastikan setiap percobaan pemrosesan mencatat correlation ID, nama queue, dan hasil (acked, rejected, retried).
Jika Anda memakai distributed tracing, propagasikan header trace lewat properti pesan sehingga Anda bisa menghubungkan “permintaan API → pesan dipublikasikan → kerja consumer.”
Buat satu dashboard per alur kritikal: laju publish, laju ack, kedalaman, unacked, requeues, dan jumlah consumer. Tambahkan link langsung di dashboard ke runbook internal Anda, mis. /docs/monitoring, dan checklist “yang harus dicek pertama” untuk responder on-call.
Saat sesuatu “berhenti bergerak” di RabbitMQ, tahan diri untuk tidak langsung merestart. Kebanyakan masalah jelas setelah Anda memeriksa (1) binding dan routing, (2) kesehatan consumer, dan (3) resource alarms.
Jika publisher melaporkan “terkirim” tapi queue tetap kosong (atau queue yang salah penuh), periksa routing sebelum kode.
Mulai di Management UI:
topic).\Jika queue berisi pesan tapi tak ada yang mengonsumsi, konfirmasi:
Duplikat umumnya dari retry (consumer crash setelah memproses tapi sebelum ack), gangguan jaringan, atau requeue manual. Kurangi dengan membuat handler idempotent (mis., dedupe dengan message ID di database).
Pengiriman tidak berurutan diharapkan saat Anda punya banyak consumer atau requeue. Jika urutan penting, gunakan satu consumer untuk queue tersebut, atau partisi berdasarkan key ke beberapa queue.
Alarm menandakan RabbitMQ sedang melindungi dirinya:
Sebelum replay, perbaiki akar penyebab dan cegah loop pesan beracun. Requeue dalam batch kecil, tambahkan cap retry, dan beri metadata kegagalan (attempt count, last error). Pertimbangkan mengirim pesan replay ke queue terpisah terlebih dahulu, agar Anda bisa berhenti cepat jika error sama terulang.
Memilih alat messaging lebih soal mencocokkan pola trafik, toleransi kegagalan, dan kenyamanan operasional daripada soal “terbaik”.
RabbitMQ unggul ketika Anda perlu pengiriman pesan yang andal dan routing fleksibel antar komponen aplikasi. Ini pilihan kuat untuk alur kerja async klasik—command, job latar, notifikasi fan-out, dan pola request/response—terutama ketika Anda ingin:
Jika tujuan utama adalah memindahkan pekerjaan daripada menyimpan sejarah event panjang, RabbitMQ sering menjadi default yang nyaman.
Kafka dan platform serupa dibangun untuk streaming throughput tinggi dan log event jangka panjang. Pilih Kafka-like ketika Anda butuh:
Trade-off: sistem gaya Kafka bisa punya overhead operasional lebih tinggi dan mendorong desain berorientasi throughput (batching, strategi partition). RabbitMQ cenderung lebih mudah untuk throughput rendah–sedang dengan latensi end-to-end lebih rendah dan routing kompleks.
Jika Anda punya satu aplikasi yang memproduksi job dan satu worker pool yang mengonsumsinya—dan Anda oke dengan semantik yang lebih sederhana—antrian berbasis Redis (atau layanan task terkelola) mungkin cukup. Tim biasanya mulai merasa tidak cocok saat butuh jaminan pengiriman lebih kuat, dead-lettering, banyak pola routing, atau pemisahan producer/consumer yang lebih jelas.
Rancang kontrak pesan seolah-olah Anda mungkin berpindah kelak:
Jika kemudian Anda butuh stream yang dapat direplay, Anda sering dapat menjembatani event RabbitMQ ke sistem log-based sambil tetap menggunakan RabbitMQ untuk alur operasional. Untuk rencana rollout praktis, lihat /blog/rabbitmq-rollout-plan-and-checklist.
Rollout RabbitMQ paling baik bila Anda memperlakukannya sebagai produk: mulai kecil, tentukan kepemilikan, dan buktikan keandalan sebelum memperluas ke lebih banyak layanan.
Pilih satu alur kerja yang mendapat manfaat dari pemrosesan asinkron (mis., pengiriman email, pembuatan laporan, sinkronisasi ke API pihak ketiga).
Jika Anda perlu template referensi untuk penamaan, tier retry, dan kebijakan dasar, simpan terpusat di /docs.
Saat menerapkan pola ini, pertimbangkan menstandarkan scaffolding antar tim. Misalnya, tim yang menggunakan Koder.ai sering menghasilkan kerangka service producer/consumer kecil dari prompt chat (termasuk konvensi penamaan, wiring retry/DLQ, dan header trace/correlation), lalu mengekspor kode sumber untuk review dan iterasi dalam “planning mode” sebelum rollout.
RabbitMQ sukses bila “seseorang memiliki queue.” Tentukan ini sebelum produksi:
Jika Anda memformalkan dukungan atau hosting terkelola, sinkronkan ekspektasi sejak dini (lihat /pricing) dan sediakan jalur kontak untuk insiden atau bantuan onboarding di /contact.
Jalankan latihan kecil berdurasi terbatas untuk membangun kepercayaan:
Setelah satu layanan stabil beberapa minggu, replikasi pola yang sama—jangan menemukan ulang roda per tim.
Gunakan RabbitMQ ketika Anda ingin melepaskan keterikatan antar layanan, menyerap lonjakan trafik, atau memindahkan pekerjaan lambat keluar dari jalur permintaan.
Cocok untuk pekerjaan latar (email, PDF), notifikasi acara ke banyak konsumen, dan alur kerja yang harus terus berjalan saat layanan downstream sementara bermasalah.
Hindari bila Anda benar-benar butuh jawaban instan (pembacaan/validasi sederhana) atau bila Anda tidak bisa berkomitmen pada versioning, retry, dan monitoring — itu bukan opsional di produksi.
Terbitkan ke sebuah exchange dan rute ke queue:
orders.* atau orders.#.\Mayoritas tim default ke topic exchange untuk routing event-style yang mudah dipelihara.
Queue menyimpan pesan sampai konsumer memprosesnya; binding adalah aturan yang menghubungkan exchange ke queue.
Untuk men-debug masalah routing:
Tiga pemeriksaan ini menjelaskan sebagian besar insiden “dipublikasikan tapi tidak dikonsumsi”.
Gunakan work queue ketika Anda ingin satu dari banyak worker memproses tiap tugas.
Tips praktis:
At-least-once delivery berarti sebuah pesan dapat dikirim lebih dari sekali (misalnya, jika konsumer crash setelah melakukan kerja tapi sebelum ack).
Buat konsumer aman dengan:
message_id yang stabil (atau business key) dan mencatat ID yang sudah diproses dengan TTL.\Anggap duplikat adalah normal, dan desainlah sesuai.
Hindari loop requeue ketat. Pendekatan umum adalah “retry queues” plus DLQ:
Lakukan replay dari DLQ hanya setelah memperbaiki akar masalah, dan lakukan dalam batch kecil.
Mulai dengan nama yang dapat diprediksi dan perlakukan pesan seperti API publik:
schema_version pada payload.\Standarkan metadata:
Fokus pada beberapa sinyal yang menunjukkan apakah pekerjaan mengalir:
Alert berdasarkan tren (mis. “backlog tumbuh selama 10 menit”), lalu gunakan log yang menyertakan nama queue, correlation_id, dan hasil pemrosesan (acked/retried/rejected).
Lakukan dasar-dasarnya konsisten:
Simpan runbook internal singkat agar tim mengikuti standar yang sama (mis. link dari /docs/security).
Mulailah dengan menempatkan di mana aliran berhenti:
Restart jarang menjadi langkah pertama atau terbaik.
correlation_id untuk mengikat event/command ke satu aksi bisnis.\trace_id (atau header trace W3C) untuk menghubungkan kerja async ke distributed trace.Ini memudahkan onboarding dan respon insiden.