13 Des 2025·8 menit
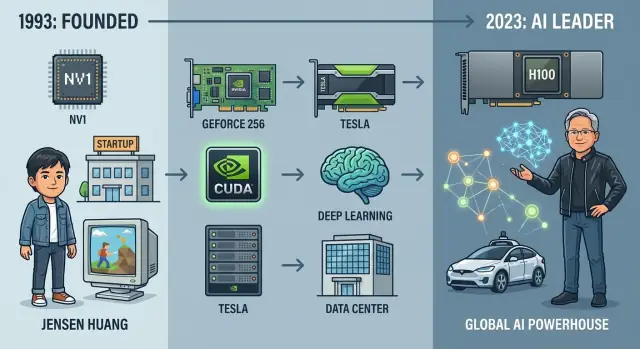
Dari Startup Grafis ke Raksasa AI: Sejarah Nvidia
Jelajahi perjalanan Nvidia dari startup grafis 1993 menjadi raksasa AI global, menelusuri produk penting, terobosan, pemimpin, dan taruhan strategisnya.
Pendahuluan: Mengapa Kisah Nvidia Penting
Nvidia telah menjadi nama yang dikenal luas karena alasan yang sangat berbeda, tergantung siapa yang Anda tanyakan. Pemain PC berpikir tentang kartu grafis GeForce dan frame rate yang halus. Peneliti AI berpikir tentang GPU yang melatih model perintis dalam hitungan hari, bukan bulan. Investor melihat salah satu perusahaan semikonduktor paling bernilai dalam sejarah, sebuah saham yang menjadi proxy bagi booming AI secara keseluruhan.
Namun hal ini tidaklah pasti sejak awal. Saat Nvidia didirikan pada 1993, itu adalah startup kecil yang bertaruh pada ide nisbah: bahwa chip grafis akan mengubah komputasi personal. Selama tiga dekade, perusahaan tersebut berkembang dari pembuat kartu grafis sederhana menjadi pemasok sentral perangkat keras dan perangkat lunak untuk AI modern, menenagai semuanya dari sistem rekomendasi dan prototipe swakemudi hingga model bahasa besar.
Mengapa kisah ini penting
Memahami sejarah Nvidia adalah salah satu cara paling jelas untuk memahami perangkat keras AI modern dan model bisnis yang terbentuk di sekitarnya. Perusahaan ini duduk pada persimpangan beberapa kekuatan:
- Evolusi komputasi GPU dari grafis fungsi‑tetap menjadi prosesor paralel masif
- Kebangkitan CUDA sebagai platform pemrograman, bukan sekadar fitur chip
- Peralihan dari gaming konsumen ke cloud dan pusat data AI sebagai mesin pertumbuhan utama
Sepanjang jalan, Nvidia berulang kali mengambil taruhan berisiko tinggi: mendukung GPU yang dapat diprogram sebelum pasar jelas, membangun tumpukan perangkat lunak penuh untuk deep learning, dan menghabiskan miliaran untuk akuisisi seperti Mellanox untuk mengendalikan lebih banyak aspek pusat data.
Apa yang akan dibahas artikel ini
Artikel ini menelusuri perjalanan Nvidia dari 1993 hingga sekarang, fokus pada:
- Bagaimana Jensen Huang dan rekan‑pendirinya mengubah ide grafis menjadi perusahaan platform
- Tonggak produk penting: RIVA, GeForce, CUDA, dan era GPU pusat data
- Terobosan deep learning yang membuka dominasi AI Nvidia
- Strategi, persaingan dengan AMD dan lainnya, serta akuisisi besar
- Transformasi finansial: dari pembuat chip niche menjadi raksasa pasar
- Apa yang masa lalu Nvidia tunjukkan tentang masa depan AI dan peran perusahaan dalamnya
Artikel ditulis untuk pembaca di bidang teknologi, bisnis, dan investasi yang menginginkan pandangan naratif jelas tentang bagaimana Nvidia menjadi raksasa AI—dan apa yang mungkin terjadi selanjutnya.
Mendirikan Nvidia: Dari Ide ke Startup
Pada 1993, tiga insinyur dengan kepribadian berbeda tetapi keyakinan bersama tentang grafis 3D memulai Nvidia di sebuah booth Denny’s di Silicon Valley. Jensen Huang, insinyur Taiwan‑Amerika dan mantan perancang chip di LSI Logic, membawa ambisi besar dan bakat bercerita kepada pelanggan dan investor. Chris Malachowsky datang dari Sun Microsystems dengan pengalaman mendalam pada workstation performa‑tinggi. Curtis Priem, sebelumnya di IBM dan Sun, adalah arsitek sistem yang terobsesi pada bagaimana perangkat keras dan perangkat lunak saling cocok.
Silicon Valley pada awal 1990‑an
Valley pada waktu itu berputar di sekitar workstation, minikomputer, dan produsen PC yang sedang muncul. Grafis 3D kuat tetapi mahal, kebanyakan terkait dengan Silicon Graphics (SGI) dan vendor workstation lain yang melayani profesional di CAD, film, dan visualisasi ilmiah.
Huang dan rekan‑pendiri melihat celah: membawa daya komputasi visual sejenis itu ke PC konsumen yang terjangkau. Jika jutaan orang bisa mendapatkan grafis 3D berkualitas tinggi untuk game dan multimedia, pasar akan jauh lebih besar daripada dunia workstation yang nisbah.
Visi awal: grafis akselerasi untuk semua orang
Ide pendirian Nvidia bukanlah semikonduktor umum; itu adalah grafis yang dipercepat untuk pasar massal. Alih‑alih CPU melakukan segala hal, prosesor grafis khusus akan menangani matematika berat merender scene 3D.
Tim percaya ini membutuhkan:
- Arsitektur grafis khusus yang bisa berkembang lebih cepat daripada roadmap CPU
- Keterkaitan erat antara perangkat keras dan perangkat lunak (driver, API, alat pengembang)
- Pengurangan biaya tanpa henti sehingga pembuat PC OEM akan mengadopsinya secara massal
Pendanaan awal, hampir gagal, dan bertahan dengan seadanya
Huang mengumpulkan modal awal dari firma ventura seperti Sequoia, tetapi uang tidak pernah melimpah. Chip pertama, NV1, ambisius tetapi tidak selaras dengan standar DirectX yang sedang muncul dan API game dominan. Itu terjual buruk dan nyaris membunuh perusahaan.
Nvidia bertahan dengan cepat berputar ke NV3 (RIVA 128), memposisikan ulang arsitektur seputar standar industri dan belajar bekerja lebih erat dengan pengembang game dan Microsoft. Pelajaran: teknologi saja tidak cukup; penyelarasan ekosistem menentukan kelangsungan hidup.
Budaya: kecepatan, kedalaman rekayasa, dan hemat
Sejak awal, Nvidia membudayakan lingkungan di mana insinyur memegang pengaruh besar dan waktu‑ke‑pasar diperlakukan sebagai hal eksistensial. Tim bergerak cepat, mengiterasi desain secara agresif, dan menerima bahwa beberapa taruhan akan gagal.
Keterbatasan kas melahirkan hemat: furnitur kantor yang digunakan ulang, jam kerja panjang, dan kecenderungan merekrut sedikit insinyur sangat kapabel daripada membangun tim besar berhirarki. Budaya awal itu—intensitas teknis, urgensi, dan pengeluaran hati‑hati—kemudian membentuk cara Nvidia menyerang peluang yang jauh lebih besar di luar grafis PC.
Revolusi Grafis Pertama: RIVA, GeForce dan Gaming PC
Grafis PC sebelum kebangkitan Nvidia
Pada awal hingga pertengahan 1990‑an, grafis PC masih dasar dan terfragmentasi. Banyak game masih mengandalkan rendering perangkat lunak, dengan CPU melakukan sebagian besar pekerjaan. Akselerator 2D khusus ada untuk Windows, dan kartu add‑in 3D awal seperti 3dfx Voodoo membantu game, tetapi belum ada cara standar memprogram hardware 3D. API seperti Direct3D dan OpenGL masih matang, dan pengembang sering harus menargetkan kartu tertentu.
Lingkungan ini adalah tempat Nvidia masuk: bergerak cepat, kacau, dan penuh peluang bagi siapa pun yang bisa menggabungkan performa dengan model pemrograman yang bersih.
NV1: Sebuah langkah ambisius yang keliru
Produk besar pertama Nvidia, NV1, diluncurkan pada 1995. Ia berusaha melakukan segala hal sekaligus: 2D, 3D, audio, dan bahkan dukungan gamepad Sega Saturn pada satu kartu. Secara teknis, ia fokus pada permukaan kuadratik alih‑alih segitiga, saat Microsoft dan mayoritas industri menstandarkan API 3D seputar poligon segitiga.
Ketidaksesuaian dengan DirectX dan dukungan perangkat lunak yang terbatas membuat NV1 menjadi kekecewaan komersial. Namun ia mengajarkan dua pelajaran penting: ikuti API dominan (DirectX), dan fokus tajam pada performa 3D daripada fitur eksotik.
RIVA 128 dan TNT: Membangun Kredibilitas
Nvidia bangkit kembali dengan RIVA 128 pada 1997. Ia menerima segitiga dan Direct3D, memberikan performa 3D yang kuat, dan mengintegrasikan 2D serta 3D ke dalam satu kartu. Pengulas memperhatikan, dan OEM mulai melihat Nvidia sebagai mitra serius.
RIVA TNT dan TNT2 menyempurnakan formula: kualitas gambar lebih baik, resolusi lebih tinggi, dan driver yang ditingkatkan. Meski 3dfx masih memimpin dalam share perhatian, Nvidia menutup jarak dengan cepat lewat pembaruan driver yang sering dan pendekatan yang ramah pada pengembang game.
GeForce 256 dan kelahiran GPU
Pada 1999, Nvidia memperkenalkan GeForce 256 dan memasarkan sebagai "GPU pertama di dunia" — sebuah Graphics Processing Unit. Ini lebih dari sekadar pemasaran. GeForce 256 mengintegrasikan transformasi dan pencahayaan perangkat keras (T&L), memindahkan perhitungan geometri dari CPU ke chip grafis.
Perubahan ini membebaskan CPU untuk logika game dan fisika sementara GPU menangani scene 3D yang semakin kompleks. Game dapat menggambar lebih banyak poligon, menggunakan pencahayaan yang lebih realistis, dan berjalan lebih lancar pada resolusi lebih tinggi.
Menunggangi ledakan gaming PC dengan kemitraan OEM
Pada saat yang sama, gaming PC meledak, didorong oleh judul seperti Quake III Arena dan Unreal Tournament, serta adopsi Windows dan DirectX yang cepat. Nvidia selaras erat dengan pertumbuhan ini.
Perusahaan mengamankan design win dengan OEM besar seperti Dell dan Compaq, memastikan jutaan PC mainstream dikirim dengan grafis Nvidia secara default. Program pemasaran bersama dengan studio game dan brand “The Way It’s Meant to Be Played” memperkuat citra Nvidia sebagai pilihan default bagi gamer serius.
Pada awal 2000‑an, Nvidia telah berubah dari startup yang berjuang dengan produk pertama yang keliru menjadi kekuatan dominan dalam grafis PC, menyiapkan panggung untuk semua yang akan mengikuti dalam komputasi GPU dan akhirnya AI.
Bertaruh pada Programmability: CUDA dan Komputasi GPU
Saat Nvidia dimulai, GPU kebanyakan adalah mesin fungsi‑tetap: pipeline yang dipasang keras yang menerima vertex dan tekstur lalu mengeluarkan pixel. Mereka sangat cepat, tetapi hampir sepenuhnya tidak fleksibel.
Dari Fungsi‑Tetap ke Shader yang Dapat Diprogram
Sekitar awal 2000‑an, shader yang dapat diprogram (Vertex dan Pixel/Fragment Shader di DirectX dan OpenGL) mengubah formula itu. Dengan chip seperti GeForce 3 dan kemudian GeForce FX serta GeForce 6, Nvidia mulai mengekspos unit kecil yang dapat diprogram yang membiarkan pengembang menulis efek kustom alih‑alih bergantung pada pipeline kaku.
Shader ini masih ditujukan untuk grafis, tetapi mereka menanamkan ide penting di dalam Nvidia: jika GPU bisa diprogram untuk banyak efek visual, mengapa tidak diprogram untuk komputasi yang lebih luas?
Taruhan radikal: CUDA dan GPGPU
General‑purpose GPU computing (GPGPU) adalah taruhan kontrarian. Secara internal, banyak yang mempertanyakan apakah masuk akal menghabiskan anggaran transistor, waktu rekayasa, dan upaya perangkat lunak pada beban kerja di luar gaming. Secara eksternal, skeptis menganggap GPU hanyalah mainan untuk grafis, dan eksperimen GPGPU awal—memaksa aljabar linier ke fragment shader—terkenal menyakitkan.
Jawaban Nvidia adalah CUDA, diumumkan pada 2006: model pemrograman mirip C/C++, runtime, dan toolchain yang dirancang untuk membuat GPU terasa seperti coprocessor paralel masif. Alih‑alih memaksa ilmuwan berpikir dalam segitiga dan pixel, CUDA mengekspos thread, block, grid, dan hierarki memori eksplisit.
Ini adalah risiko strategis besar: Nvidia harus membangun kompiler, debugger, perpustakaan, dokumentasi, dan program pelatihan—investasi perangkat lunak lebih khas perusahaan platform daripada vendor chip.
Kasus penggunaan non‑grafis awal
Kemenangan pertama datang dari komputasi performa‑tinggi (HPC):
- Dinamika molekuler dan kimia komputasional
- Aljabar linier dan solver numerik
- Penetapan harga opsi, simulasi risiko, dan beban kerja kuantitatif lain
- Pencitraan seismik dan pemrosesan sinyal
Peneliti tiba‑tiba bisa menjalankan simulasi yang memakan minggu dalam hitungan hari atau jam, sering pada satu GPU di workstation alih‑alih seluruh klaster CPU.
Menyemai ekosistem pengembang
CUDA melakukan lebih dari sekadar mempercepat kode; itu menciptakan ekosistem pengembang di sekitar perangkat keras Nvidia. Perusahaan berinvestasi dalam SDK, perpustakaan matematika (seperti cuBLAS dan cuFFT), program universitas, dan konferensi sendiri (GTC) untuk mengajari pemrograman paralel pada GPU.
Setiap aplikasi dan perpustakaan CUDA memperdalam parit: pengembang mengoptimalkan untuk GPU Nvidia, toolchain matang di sekitar CUDA, dan proyek baru mulai dengan Nvidia sebagai akselerator default. Jauh sebelum pelatihan AI mengisi pusat data dengan GPU, ekosistem ini sudah mengubah programmability menjadi salah satu aset strategis paling kuat Nvidia.
Dari Gaming ke Pusat Data: Membangun Bisnis Baru
Referensikan Seorang Pembuat
Bagikan Koder.ai dengan tautan rujukan dan dapatkan kredit ketika orang lain bergabung.
Melihat melampaui grafis PC
Menjelang pertengahan 2000‑an, bisnis gaming Nvidia makmur, tetapi Jensen Huang dan timnya melihat batas mengandalkan GPU konsumen semata. Daya pemrosesan paralel yang membuat game lebih halus juga dapat mempercepat simulasi ilmiah, keuangan, dan akhirnya AI.
Nvidia mulai memposisikan GPU sebagai akselerator tujuan‑umum untuk workstation dan server. Kartu profesional untuk desainer dan insinyur (lini Quadro) adalah langkah awal, tetapi taruhan lebih besar adalah langsung masuk ke jantung pusat data.
Tesla: GPU untuk server dan superkomputer
Pada 2007 Nvidia memperkenalkan lini produk Tesla, GPU pertamanya yang dibangun khusus untuk komputasi performa‑tinggi (HPC) dan beban kerja server alih‑alih untuk tampilan.
Papan Tesla menekankan performa presisi‑ganda, memori dengan error‑correcting, dan efisiensi daya di rak padat—fitur yang jadi perhatian pusat data dan situs superkomputer lebih daripada frame rate.
HPC dan lab nasional menjadi adopter awal yang krusial. Sistem seperti superkomputer “Titan” di Oak Ridge National Laboratory menunjukkan bahwa klaster GPU yang dapat diprogram dengan CUDA dapat memberikan percepatan besar untuk fisika, pemodelan iklim, dan dinamika molekuler. Kredibilitas itu kemudian membantu meyakinkan pembeli enterprise dan cloud bahwa GPU adalah infrastruktur serius, bukan sekadar perangkat gaming.
Penelitian, cloud, dan komposisi pendapatan baru
Nvidia berinvestasi besar dalam hubungan dengan universitas dan institut riset, menanam lab dengan perangkat keras dan alat CUDA. Banyak peneliti yang bereksperimen dengan komputasi GPU di akademia kemudian mendorong adopsi di perusahaan dan startup.
Pada saat yang sama, penyedia cloud awal mulai menawarkan instance bertenaga Nvidia, mengubah GPU menjadi sumber daya on‑demand. Amazon Web Services, diikuti Microsoft Azure dan Google Cloud, membuat GPU kelas Tesla dapat diakses oleh siapa pun dengan kartu kredit, yang sangat penting bagi deep learning di GPU.
Seiring pasar pusat data dan profesional tumbuh, basis pendapatan Nvidia melebar. Gaming tetap pilar, tetapi segmen baru—HPC, enterprise AI, dan cloud—berkembang menjadi mesin pertumbuhan kedua, meletakkan fondasi ekonomi untuk dominasi AI Nvidia yang kemudian terjadi.
Terobosan Deep Learning: Ketika AI Bertemu GPU
Titik balik datang pada 2012, ketika jaringan saraf bernama AlexNet mengejutkan komunitas visi komputer dengan menggilas benchmark ImageNet. Yang krusial, model itu berjalan pada sepasang GPU Nvidia. Apa yang sebelumnya ide nisbah—melatih jaringan saraf besar dengan chip grafis—tiba‑tiba tampak seperti masa depan AI.
Mengapa GPU cocok untuk deep learning
Jaringan saraf dalam dibangun dari sejumlah besar operasi identik: perkalian matriks dan konvolusi yang diterapkan pada jutaan bobot dan aktivasi. GPU dirancang untuk menjalankan ribuan thread sederhana secara paralel untuk shading grafis. Paralelisme yang sama tepat cocok untuk jaringan saraf.
Alih‑alih merender pixel, GPU dapat memproses neuron. Beban kerja yang berat komputasi dan sangat paralel yang berjalan sangat lambat di CPU kini dapat dipercepat berkali‑kali lipat oleh GPU. Waktu pelatihan yang dulu memakan minggu berkurang menjadi hari atau jam, memungkinkan peneliti beriterasi dengan cepat dan memperbesar model.
Dari perangkat keras mentah ke tumpukan AI
Nvidia bergerak cepat untuk mengubah rasa ingin tahu penelitian ini menjadi platform. CUDA sudah memberi pengembang cara memprogram GPU, tetapi deep learning membutuhkan alat tingkat lebih tinggi.
Nvidia membangun cuDNN, perpustakaan yang dioptimalkan GPU untuk primitif jaringan saraf—konvolusi, pooling, fungsi aktivasi. Framework seperti Caffe, Theano, Torch, dan kemudian TensorFlow dan PyTorch mengintegrasikan cuDNN, sehingga peneliti bisa mendapatkan percepatan GPU tanpa menyetel kernel secara manual.
Pada saat yang sama, Nvidia menyesuaikan perangkat kerasnya: menambahkan dukungan presisi campuran, memori bandwidth tinggi, dan kemudian Tensor Cores pada arsitektur Volta dan seterusnya, yang dirancang khusus untuk matematika matriks dalam deep learning.
Kemitraan, DGX, dan GPU yang berfokus AI
Nvidia memupuk hubungan dekat dengan lab AI terkemuka dan peneliti di tempat seperti University of Toronto, Stanford, Google, Facebook, dan startup awal seperti DeepMind. Perusahaan menawarkan perangkat keras awal, bantuan rekayasa, dan driver khusus, dan sebagai imbalannya mendapat umpan balik langsung tentang apa yang dibutuhkan beban kerja AI berikutnya.
Untuk membuat superkomputasi AI lebih mudah diakses, Nvidia memperkenalkan sistem DGX—server AI pra‑terintegrasi yang penuh dengan GPU kelas atas, interkoneksi cepat, dan perangkat lunak yang disetel. DGX‑1 dan penerusnya menjadi perangkat standar bagi banyak lab dan enterprise yang membangun kapabilitas deep learning serius.
Dengan GPU seperti Tesla K80, P100, V100 dan akhirnya A100 dan H100, Nvidia berhenti menjadi “perusahaan gaming yang juga melakukan komputasi” dan menjadi mesin default untuk melatih dan melayani model deep learning terdepan. Momen AlexNet membuka era baru, dan Nvidia memosisikan dirinya tepat di pusatnya.
Membangun Platform dan Ekosistem AI Nvidia
Nvidia tidak menang AI hanya dengan menjual chip lebih cepat. Ia membangun platform ujung ke ujung yang membuat membangun, menerapkan, dan menskalakan AI jauh lebih mudah pada perangkat keras Nvidia dibandingkan tempat lain.
CUDA di inti
Dasarnya adalah CUDA, model pemrograman paralel Nvidia yang diperkenalkan pada 2006. CUDA membiarkan pengembang memperlakukan GPU sebagai akselerator tujuan‑umum, dengan toolchain C/C++ dan Python yang familier.
Di atas CUDA, Nvidia menempatkan perpustakaan dan SDK khusus:
- Matematika & HPC: cuBLAS, cuSPARSE, cuFFT untuk rutin numerik inti.
- AI & deep learning: cuDNN untuk jaringan saraf, TensorRT untuk optimisasi inferensi, Triton Inference Server untuk serving model.
- Data & analitik: RAPIDS untuk data science yang dipercepat GPU, cuGraph untuk analitik graf.
Tumpukan ini membuat peneliti atau insinyur jarang menulis kode GPU tingkat rendah; mereka memanggil perpustakaan Nvidia yang disetel untuk setiap generasi GPU baru.
Parit perangkat lunak dan penguncian pengembang
Tahun‑tahun investasi pada tooling CUDA, dokumentasi, dan pelatihan menciptakan parit yang kuat. Jutaan baris kode produksi, proyek akademik, dan proyek open‑source dioptimalkan untuk GPU Nvidia.
Berpindah ke arsitektur pesaing sering berarti menulis ulang kernel, memvalidasi ulang model, dan melatih ulang insinyur. Biaya switching itu menjaga pengembang, startup, dan enterprise terpaut pada Nvidia.
Melayani penyedia cloud dan enterprise
Nvidia bekerja erat dengan hyperscale cloud, menyediakan platform referensi HGX dan DGX, driver, dan tumpukan perangkat lunak yang disetel sehingga pelanggan dapat menyewa GPU dengan friksi minimal.
Suite Nvidia AI Enterprise, katalog perangkat lunak NGC, dan model pra‑latih memberi enterprise jalur yang didukung dari pilot ke produksi, baik on‑prem maupun di cloud.
Tumpukan AI vertikal
Nvidia memperluas platformnya ke solusi vertikal lengkap:
- Swakemudi dengan Nvidia Drive (perangkat keras, persepsi, pemetaan, simulasi, dan alat perangkat lunak).
- Kesehatan dengan Nvidia Clara untuk pencitraan medis, genomik, dan federated learning.
- Robotika dengan Nvidia Isaac untuk simulasi, persepsi, dan kendali.
- Digital twin & simulasi industri dengan Nvidia Omniverse dan tumpukan simulasi terkait.
Platform vertikal ini menggabungkan GPU, SDK, aplikasi referensi, dan integrasi mitra, memberi pelanggan sesuatu yang mendekati solusi turnkey.
Ekosistem sebagai pengganda kekuatan
Dengan memupuk ISV, mitra cloud, lab penelitian, dan integrator sistem di sekitar tumpukan perangkat lunaknya, Nvidia mengubah GPU menjadi perangkat keras default untuk AI.
Setiap framework baru yang dioptimalkan untuk CUDA, setiap startup yang mengirimkan produk di Nvidia, dan setiap layanan AI cloud yang disetel untuk GPU‑nya memperkuat loop umpan balik: lebih banyak perangkat lunak di Nvidia menarik lebih banyak pengguna, yang membenarkan lebih banyak investasi, memperlebar jarak dengan pesaing.
Taruhan Strategis, Akuisisi, dan Perluasan di Luar GPU
Jaga Sumber Tetap Portabel
Dapatkan kode sumber untuk ditinjau, dikembangkan, atau dipindahkan ke alur kerja Anda.
Kebangkitan Nvidia menjadi dominan AI sama tentang taruhan strategis di luar GPU seperti juga tentang chip itu sendiri.
Mellanox dan puzzle jaringan
Akuisisi Mellanox pada 2019 adalah titik balik. Mellanox membawa InfiniBand dan Ethernet kelas atas, plus keahlian dalam interkoneksi latensi rendah dan throughput tinggi.
Melatih model AI besar bergantung pada menyatukan ribuan GPU menjadi satu komputer logis. Tanpa jaringan cepat, GPU itu menganggur sambil menunggu data atau sinkronisasi gradien. Mellanox memberi Nvidia kontrol penting atas fabric itu.
Kesepakatan Arm yang tak selesai
Pada 2020 Nvidia mengumumkan rencana mengakuisisi Arm, bertujuan menggabungkan keahliannya pada akselerasi AI dengan arsitektur CPU yang banyak dilisensikan yang digunakan di ponsel, embedded, dan semakin di server.
Regulator di AS, UK, UE, dan China mengangkat kekhawatiran anti‑persaingan serius: Arm adalah pemasok IP netral bagi banyak pesaing Nvidia, dan konsolidasi mengancam netralitas itu. Setelah pengawasan panjang dan penolakan industri, Nvidia membatalkan kesepakatan pada 2022.
Meski tanpa Arm, Nvidia melanjutkan dengan CPU Grace sendiri, menunjukkan niatnya untuk membentuk node pusat data penuh, bukan sekadar kartu akselerator.
Omniverse, otomotif, dan edge AI
Omniverse memperluas Nvidia ke simulasi, digital twin, dan kolaborasi 3D. Ia menghubungkan alat dan data di sekitar OpenUSD, memungkinkan perusahaan mensimulasikan pabrik, kota, dan robot sebelum menerapkannya di dunia nyata. Omniverse adalah beban kerja GPU berat sekaligus platform perangkat lunak yang mengikat pengembang.
Di otomotif, platform DRIVE Nvidia menargetkan komputasi terpusat dalam mobil, swakemudi, dan bantuan pengemudi lanjutan. Dengan menyediakan perangkat keras, SDK, dan alat validasi kepada pembuat mobil dan pemasok tier‑1, Nvidia menanamkan dirinya dalam siklus produk panjang dan pendapatan perangkat lunak berulang.
Di edge, modul Jetson dan tumpukan perangkat lunak terkait menenagai robotika, kamera cerdas, dan AI industri. Produk‑produk ini mendorong platform AI Nvidia ke ritel, logistik, kesehatan, dan kota—menangkap beban kerja yang tidak dapat hidup hanya di cloud.
Dari vendor chip ke perusahaan platform penuh
Melalui Mellanox dan jaringan, permainan yang gagal namun berharga seperti Arm, dan ekspansi ke Omniverse, otomotif, dan edge AI, Nvidia dengan sengaja bergerak melampaui menjadi “vendor GPU.”
Kini ia menjual:
- Chip (GPU, DPU, dan CPU seperti Grace)
- Sistem (DGX, HGX, arsitektur referensi)
- Perangkat lunak cloud dan enterprise (CUDA, framework AI, Omniverse, SDK vertikal)
- Platform ujung ke ujung untuk industri seperti mobil, robotika, dan digital twin
Taruhan‑taruhan ini membuat Nvidia lebih sulit digeser: pesaing harus menandingi bukan hanya chip, tetapi tumpukan terintegrasi yang mencakup komputasi, jaringan, perangkat lunak, dan solusi spesifik domain.
Persaingan, Regulasi, dan Hambatan Geopolitik
Kebangkitan Nvidia menarik pesaing kuat, regulator yang lebih ketat, dan risiko geopolitik baru yang membentuk setiap langkah strategis perusahaan.
Arena kompetitif: AMD, Intel, dan startup AI
AMD tetap peer terdekat Nvidia dalam GPU, sering bersaing kepala‑kepala pada gaming dan akselerator pusat data. Seri MI AMD menargetkan pelanggan cloud dan hyperscale yang sama dengan H100 dan bagian penerus Nvidia.
Intel menyerang dari beberapa sudut: CPU x86 yang masih mendominasi server, GPU diskret sendiri, dan akselerator AI khusus. Pada saat yang sama, hyperscaler seperti Google (TPU), Amazon (Trainium/Inferentia), dan gelombang startup (mis. Graphcore, Cerebras) merancang chip AI mereka sendiri untuk mengurangi ketergantungan pada Nvidia.
Pertahanan utama Nvidia tetap kombinasi kepemimpinan performa dan perangkat lunak. CUDA, cuDNN, TensorRT, dan tumpukan SDK yang mendalam mengunci pengembang dan enterprise. Perangkat keras saja tidak cukup; memporting model dan tooling jauh dari ekosistem Nvidia membawa biaya switching nyata.
Regulasi, kontrol ekspor, dan pengawasan geopolitik
Pemerintah kini memperlakukan GPU canggih sebagai aset strategis. Kontrol ekspor AS berkali‑kali memperketat batas pengiriman chip AI tingkat atas ke China dan pasar sensitif lain, memaksa Nvidia merancang varian “patuh ekspor” dengan performa dibatasi. Kontrol ini melindungi keamanan nasional tetapi membatasi akses ke wilayah pertumbuhan besar.
Regulator juga mengamati kekuatan pasar Nvidia. Gagalnya akuisisi Arm menyoroti kekhawatiran memberi Nvidia kontrol atas IP chip fundamental. Saat pangsa Nvidia atas akselerator AI tumbuh, regulator di AS, UE, dan tempat lain semakin siap meneliti eksklusivitas, bundling, dan potensi diskriminasi akses ke perangkat keras dan perangkat lunak.
Rantai pasok, foundry, dan geopolitik
Nvidia adalah perusahaan fabless, sangat bergantung pada TSMC untuk manufaktur proses terdepan. Gangguan di Taiwan—baik akibat bencana alam, ketegangan politik, atau konflik—akan langsung memengaruhi kemampuan Nvidia memasok GPU tingkat atas.
Kelangkaan global kapasitas packaging canggih (CoWoS, integrasi HBM) sudah menciptakan hambatan pasokan, memberi Nvidia fleksibilitas lebih sedikit menanggapi lonjakan permintaan. Perusahaan harus merundingkan kapasitas, menavigasi gesekan teknologi AS–China, dan menutup risiko kontrol ekspor yang bisa berubah lebih cepat daripada roadmap semikonduktor.
Menyeimbangkan tekanan‑tekanan ini sambil mempertahankan keunggulan teknologi kini sama pentingnya sebagai tugas geopolitik dan regulatori seperti tantangan rekayasa.
Kepemimpinan, Budaya, dan Cara Nvidia Beroperasi
Taruh Aplikasi Anda di Domain
Buat situs sederhana untuk proyek AI Anda dan jalankan di domain kustom Anda sendiri.
Gaya kepemimpinan Jensen Huang
Jensen Huang adalah CEO pendiri yang masih berperilaku seperti insinyur yang terlibat langsung. Ia sangat terlibat dalam strategi produk, menghabiskan waktu dalam review teknis dan sesi papan tulis, bukan hanya panggilan hasil kuartalan.
Persona publiknya memadukan showmanship dan kejelasan. Presentasi jaket kulitnya disengaja: ia menggunakan metafora sederhana untuk menjelaskan arsitektur kompleks, memosisikan Nvidia sebagai perusahaan yang memahami baik aspek fisika maupun bisnis. Secara internal, ia dikenal karena umpan balik langsung, ekspektasi tinggi, dan kesiapan mengambil keputusan yang tidak nyaman ketika teknologi atau pasar bergeser.
Budaya: rekayasa, iterasi, dan taruhan besar
Budaya Nvidia dibangun di atas tema berulang:
- Keunggulan rekayasa: Tim silikon, perangkat lunak, dan sistem didorong untuk mencapai target performa dan daya yang agresif. Kegagalan ditoleransi hanya jika pelajaran ditangkap dan dimasukkan ke desain berikutnya.
- Iterasi cepat: Arsitektur GPU, rilis CUDA, dan SDK berkembang pesat. Tim mengirimkan produk, mengukur, dan menyetel alih‑alih menunggu desain sempurna.
- Pengambilan risiko berani: CUDA, GPU pusat data, dan investasi awal AI semuanya adalah taruhan yang tidak populer pada saat itu. Perusahaan mendorong proyek kontrarian jika didukung oleh alasan teknis yang kuat.
Campuran ini menciptakan budaya di mana loop umpan balik panjang (desain chip) hidup berdampingan dengan loop cepat (perangkat lunak dan riset), dan di mana kelompok perangkat keras, perangkat lunak, dan riset diharapkan berkolaborasi erat.
Menyeimbangkan visi jangka panjang dengan realitas kuartalan
Nvidia rutin menginvestasikan pada platform multi‑tahun—arsitektur GPU baru, jaringan, CUDA, framework AI—sementara tetap mengelola ekspektasi kuartalan.
Secara organisasi, ini berarti:
- Roadmap inti (arsitektur, node proses, interkoneksi) diperlakukan sebagai komitmen yang tidak tergoyahkan.
- Penyesuaian jangka pendek terjadi di sekitar campuran produk, harga, dan fokus go‑to‑market, bukan arah teknologi inti.
Huang sering membingkai diskusi hasil dengan tren sekuler jangka panjang (AI, komputasi terakselerasi) untuk menjaga investor selaras dengan horizon waktu perusahaan, meski permintaan jangka pendek berfluktuasi.
Hubungan pengembang dan ekosistem mitra
Nvidia memperlakukan pengembang sebagai pelanggan utama. CUDA, cuDNN, TensorRT, dan puluhan SDK domain didukung oleh:
- Dokumentasi ekstensif dan contoh kode
- Dukungan langsung untuk lab AI kunci, penyedia cloud, dan enterprise
- Program yang membantu startup mengoptimalkan dan menskalakan pada platform Nvidia
Ekosistem mitra—OEM, penyedia cloud, integrator sistem—dipupuk dengan desain referensi, pemasaran bersama, dan akses awal ke roadmap. Ekosistem rapat ini membuat platform Nvidia lengket dan sulit digeser.
Perubahan budaya saat Nvidia mengembang
Seiring Nvidia tumbuh dari penjual kartu grafis menjadi perusahaan platform AI global, budayanya berevolusi:
- Dari fokus utama pada gaming menjadi multi‑vertikal (riset, cloud, otomotif, kesehatan)
- Dari pusat perhatian AS menjadi organisasi yang terdistribusi global, dengan perhatian lebih pada regulasi, keamanan, dan geopolitik
- Dari berorientasi produk menjadi berorientasi platform, mengintegrasikan jaringan, tumpukan perangkat lunak, dan layanan bersama GPU
Meskipun skala itu, Nvidia berusaha mempertahankan mentalitas pemimpin pendiri dan prioritas pada rekayasa, di mana taruhan teknis ambisius didorong dan tim diharapkan bergerak cepat mengejar terobosan.
Dari Pembuat Chip Niche ke Raksasa Pasar: Kisah Finansial
Lengkungan finansial Nvidia adalah salah satu yang paling dramatis di teknologi: dari pemasok grafis PC yang tangguh menjadi perusahaan multi‑triliun dolar di pusat ledakan AI.
Dari small‑cap ke klub triliun dolar
Setelah IPO pada 1999, Nvidia menghabiskan tahun‑tahun berikutnya bernilai dalam kisaran miliaran rendah, sebagian besar terkait dengan pasar siklikal PC dan gaming. Sepanjang 2000‑an, pendapatan tumbuh secara stabil menjadi beberapa miliar, tetapi perusahaan masih dipandang sebagai vendor chip spesialis, bukan pemimpin platform.
Infleksi datang pertengahan 2010‑an saat pendapatan pusat data dan AI mulai mengkompaun. Sekitar 2017 kapitalisasi pasar Nvidia melampaui $100 miliar; pada 2021 ia menjadi salah satu perusahaan semikonduktor paling bernilai di dunia. Pada 2023 sempat bergabung dengan klub triliun dolar, dan hingga 2024 sering diperdagangkan jauh di atas tingkat itu, mencerminkan keyakinan investor bahwa Nvidia adalah infrastruktur AI fundamenta
Pertanyaan umum
Apa yang membuat visi awal Nvidia berbeda dari perusahaan chip lain di tahun 1990-an?
Nvidia didirikan dengan sebuah taruhan yang sangat spesifik: bahwa grafis 3D akan berpindah dari workstation mahal ke PC massal, dan perpindahan itu membutuhkan prosesor grafis khusus yang dipadukan erat dengan perangkat lunak.
Alih‑alih berusaha menjadi perusahaan semikonduktor umum, Nvidia:
- Fokus pada grafis akselerasi untuk semua orang, bukan hanya profesional.
- Mendesain chip dan driver/perangkat lunak bersama, bukan terpisah.
- Mengoptimalkan untuk biaya dan adopsi OEM, sehingga produsen PC besar bisa mengirimkan Nvidia sebagai konfigurasi default.
Fokus yang sempit tapi mendalam pada satu masalah—grafis real‑time—menciptakan dasar teknis dan budaya yang kemudian diterjemahkan menjadi komputasi GPU dan akselerasi AI.
Bagaimana CUDA membantu Nvidia menjadi perangkat keras default untuk AI dan pembelajaran mendalam?
CUDA mengubah GPU Nvidia dari perangkat grafis fungsi‑tetap menjadi platform komputasi paralel tujuan‑umum.
Cara‑cara kunci ia memfasilitasi dominasi AI:
- : Peneliti bisa menulis dalam C/C++ (dan kemudian Python lewat framework) alih‑alih menyalahgunakan API grafis.
Mengapa akuisisi Mellanox begitu penting untuk strategi AI Nvidia?
Mellanox memberi Nvidia kontrol atas fabrik jaringan yang menghubungkan ribuan GPU dalam superkomputer AI.
Untuk model besar, kinerja ditentukan bukan hanya oleh chip cepat tetapi juga seberapa cepat mereka dapat menukar data dan gradien. Mellanox membawa:
- InfiniBand dan Ethernet tingkat tinggi untuk link latensi rendah dan bandwidth besar.
Bagaimana Nvidia menghasilkan uang saat ini, dan bagaimana komposisi pendapatannya berubah dari waktu ke waktu?
Pendapatan Nvidia telah bergeser dari didominasi gaming menjadi didominasi pusat data.
Secara garis besar:
- Gaming: GPU GeForce, laptop gaming, dan perangkat lunak terkait tetap merupakan bisnis besar dan menguntungkan.
Ancaman kompetitif apa yang dihadapi Nvidia dari AMD, Intel, dan chip AI kustom?
Nvidia menghadapi tekanan dari rival tradisional dan akselerator kustom:
- AMD: Bersaing langsung di GPU gaming dan akselerator AI seri MI, sering menawarkan biaya per FLOP lebih rendah.
- Intel: Menyerang lewat CPU, GPU diskret, dan chip AI khusus.
- Cloud dan perusahaan besar: Google (TPU), Amazon (Trainium/Inferentia), dan lainnya merancang chip in‑house untuk mengurangi ketergantungan pada Nvidia.
Bagaimana kontrol ekspor, regulasi, dan geopolitik memengaruhi bisnis Nvidia?
GPU kelas lanjut kini diperlakukan sebagai teknologi strategis, terutama untuk AI.
Dampaknya pada Nvidia meliputi:
- Kontrol ekspor: Aturan AS membatasi pengiriman GPU AI tingkat atas ke China dan beberapa wilayah lain. Nvidia harus merancang varian dengan spesifikasi lebih rendah dan mungkin kehilangan sebagian permintaan bernilai tinggi.
Seperti apa tumpukan perangkat lunak AI Nvidia secara sederhana?
Tumpukan perangkat lunak AI Nvidia adalah lapisan‑lapisan alat yang menyembunyikan kompleksitas GPU dari sebagian besar pengembang:
- : Model pemrograman inti yang mengekspose GPU sebagai prosesor paralel.
Bagaimana taruhan Nvidia di bidang mengemudi otonom dan robotika cocok dengan strategi keseluruhannya?
Otonom dan robotika adalah perluasan dari platform AI dan simulasi inti Nvidia ke sistem fisik.
Secara strategis, mereka:
- Menggunakan kembali CUDA dan perpustakaan AI yang sama yang dikembangkan untuk pusat data.
- Mendorong permintaan untuk GPU edge/embedded (Jetson, platform in‑car Drive).
- Mengunci pelanggan dengan siklus produk panjang (pabrikan mobil, perusahaan industri) melalui kombinasi perangkat keras + perangkat lunak + alat.
Pelajaran apa yang bisa diambil pendiri dan insinyur dari evolusi Nvidia dari startup grafis menjadi platform AI?
Evolusi Nvidia menawarkan beberapa pelajaran penting:
- Miliki seluruh stack: Menggabungkan chip, desain sistem, dan perangkat lunak (CUDA, SDK) menciptakan moat yang tahan lama.
- Bertaruh lebih awal pada bottleneck komputasi berikutnya: Shader yang dapat diprogram, CUDA, dan dukungan deep learning semua dibuat sebelum pasar jelas.
Bagaimana posisi Nvidia bisa berubah jika arsitektur perangkat keras AI bergerak melampaui GPU tradisional?
Jika beban kerja masa depan menjauh dari pola yang cocok dengan GPU, Nvidia perlu menyesuaikan perangkat keras dan perangkat lunaknya dengan cepat.
Perubahan yang mungkin terjadi:
- Adopsi luas ASIC AI khusus yang menukar fleksibilitas dengan efisiensi pada tugas sempit.
- Paradigma baru (mis. neuromorfik, analog, atau hierarki memori radikal) yang tidak cocok dengan desain GPU saat ini.
- Tumpukan perangkat lunak terbuka yang matang (mis. ekosistem mirip ROCm) yang melemahkan kunci CUDA.
Respons probable Nvidia: