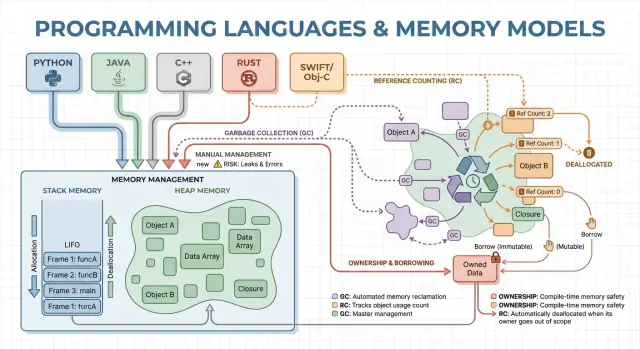
Manajemen memori adalah sekumpulan aturan dan mekanisme yang digunakan program untuk meminta memori, menggunakannya, dan mengembalikannya. Setiap program yang berjalan membutuhkan memori untuk hal-hal seperti variabel, data pengguna, buffer jaringan, gambar, dan hasil sementara. Karena memori terbatas dan dibagi dengan sistem operasi serta aplikasi lain, bahasa harus menentukan siapa yang bertanggung jawab membebaskannya dan kapan hal itu terjadi.
Keputusan tersebut membentuk dua hasil yang sering diperhatikan: seberapa cepat program terasa, dan seberapa andal ia berperilaku saat mendapat tekanan.
Performa bukanlah satu angka tunggal. Manajemen memori dapat memengaruhi:
- Throughput: berapa banyak pekerjaan yang dapat diselesaikan per detik (permintaan ditangani, frame yang dirender, file yang diproses).
- Latensi: berapa lama operasi individu berlangsung, terutama lonjakan tail latency yang disebabkan oleh jeda atau alokasi lambat.
- Jejak memori: berapa banyak RAM yang dipertahankan program saat berjalan, yang memengaruhi biaya, daya baterai, dan seberapa sering OS mulai swapping.
Sebuah bahasa yang cepat mengalokasikan tetapi kadang berhenti untuk membersihkan mungkin terlihat bagus di benchmark tetapi terasa tidak stabil di aplikasi interaktif. Model lain yang menghindari jeda mungkin memerlukan desain lebih hati-hati untuk mencegah kebocoran dan kesalahan lifetime.
Apa arti “keamanan” di sini
Keamanan berhubungan dengan mencegah kegagalan terkait memori, seperti:
- Crash (mengakses memori tidak valid)
- Korupsi data (menulis ke tempat yang tidak seharusnya)
- Kerentanan keamanan (bug yang dapat dieksploitasi)
Banyak masalah keamanan terkenal berakar pada kesalahan memori seperti use-after-free atau buffer overflow.
Panduan ini adalah tur non-teknis tentang model memori utama yang digunakan bahasa populer, apa yang mereka optimalkan, dan trade-off yang Anda terima saat memilih salah satunya.
Konsep Inti: Stack, Heap, dan Lifetime Objek
Memori adalah tempat program menyimpan data saat berjalan. Kebanyakan bahasa mengatur ini di sekitar dua area utama: stack dan heap.
Stack: penyimpanan cepat dan sementara
Bayangkan stack seperti tumpukan sticky note yang rapi untuk tugas saat ini. Ketika sebuah fungsi dimulai, ia mendapatkan sebuah “frame” kecil di stack untuk variabel lokalnya. Ketika fungsi selesai, seluruh frame itu dihapus sekaligus.
Ini cepat dan dapat diprediksi—tetapi hanya bekerja untuk nilai yang ukurannya diketahui dan lifetime-nya berakhir bersama pemanggilan fungsi.
Heap: penyimpanan fleksibel dan berumur lebih lama
Heap lebih mirip ruang penyimpanan di mana Anda bisa menyimpan objek selama yang diperlukan. Ini cocok untuk hal-hal seperti daftar berukuran dinamis, string, atau objek yang dibagikan di berbagai bagian program.
Karena objek heap bisa bertahan melebihi satu fungsi, pertanyaan kuncinya menjadi: siapa yang bertanggung jawab membebaskannya, dan kapan? Tanggung jawab ini adalah “model manajemen memori” dari sebuah bahasa.
Lifetime, dan mengapa pointer/referensi penting
Sebuah pointer atau referensi adalah cara mengakses objek secara tidak langsung—seperti memiliki nomor rak untuk kotak di ruang penyimpanan. Jika kotak dibuang tetapi Anda masih punya nomor rak, Anda mungkin membaca data sampah atau crash (bug use-after-free klasik).
Contoh skenario sederhana
Bayangkan sebuah loop yang membuat catatan pelanggan, memformat pesan, lalu membuangnya:
- Pada stack: variabel sementara kecil yang hanya dipakai saat format.
- Pada heap: catatan pelanggan dan teks pesan (ukuran bervariasi).
Beberapa bahasa menyembunyikan detail ini (pembersihan otomatis), sementara yang lain mengeksposnya (Anda membebaskan memori secara eksplisit, atau harus mengikuti aturan tentang siapa yang memiliki sebuah objek). Sisanya artikel ini mengeksplor bagaimana pilihan itu memengaruhi kecepatan, jeda, dan keamanan.
Manajemen Memori Manual: Kontrol dengan Risiko Lebih Tinggi
Manajemen memori manual berarti program (dan karenanya pengembang) secara eksplisit meminta memori dan kemudian melepaskannya. Dalam praktiknya itu terlihat seperti malloc/free di C, atau new/delete di C++. Ini masih umum di pemrograman sistem di mana Anda memerlukan kontrol tepat kapan memori diperoleh dan dikembalikan.
Untuk apa “alokasi/pelepasan eksplisit” digunakan
Biasanya Anda mengalokasikan memori ketika sebuah objek harus bertahan melebihi pemanggilan fungsi saat ini, tumbuh secara dinamis (mis. buffer yang dapat diubah ukurannya), atau membutuhkan tata letak khusus untuk interoperabilitas dengan hardware, OS, atau protokol jaringan.
Tanpa garbage collector yang berjalan di latar, ada lebih sedikit jeda tak terduga. Alokasi dan dealokasi dapat dibuat sangat dapat diprediksi, terutama bila dipasangkan dengan allocator kustom, pool, atau buffer berukuran tetap.
Kontrol manual juga dapat mengurangi overhead: tidak ada fase tracing, tidak ada write barrier, dan seringkali metadata per objek lebih sedikit. Ketika kode dirancang dengan cermat, Anda bisa memenuhi target latensi ketat dan menjaga penggunaan memori dalam batas yang ketat.
Risiko keamanan: mode kegagalan klasik
Trade-off-nya adalah program dapat melakukan kesalahan yang runtime tidak mencegah secara otomatis:
- Kebocoran memori (lupa membebaskan)
- Double-free (membebaskan dua kali)
- Use-after-free (mengakses memori setelah dilepaskan)
Bug ini bisa menyebabkan crash, korupsi data, dan kerentanan keamanan.
Mitigasi umum
Tim mengurangi risiko dengan mempersempit tempat alokasi mentah diizinkan dan mengandalkan pola seperti:
- RAII di C++ (resource dibebaskan otomatis saat objek keluar scope)
- Smart pointers (mis.
std::unique_ptr) untuk mengenkode kepemilikan
- Standar coding, checklist review kode, sanitizer, dan analisis statis
Kapan ini cocok
Manajemen manual sering menjadi pilihan kuat untuk perangkat tertanam, sistem real-time, komponen OS, dan perpustakaan performa-krusial—tempat di mana kontrol ketat dan latensi yang dapat diprediksi lebih penting daripada kenyamanan pengembang.
Garbage Collection: Produktivitas dan Keamanan yang Lebih Dapat Diprediksi
Garbage collection (GC) adalah pembersihan memori otomatis: alih-alih mengharuskan Anda melakukan free sendiri, runtime melacak objek dan merebut kembali yang tidak lagi dapat dijangkau oleh program. Dalam praktiknya, ini berarti Anda bisa fokus pada perilaku dan aliran data sementara sistem menangani sebagian besar keputusan alokasi dan dealokasi.
Bagaimana GC menemukan objek yang tidak terpakai
Kebanyakan collector bekerja dengan mengidentifikasi objek hidup dulu, lalu merebut kembali sisanya.
Tracing GC dimulai dari “root” (seperti variabel stack, referensi global, dan register), mengikuti referensi untuk menandai semua yang dapat dijangkau, dan kemudian menyapu heap untuk membebaskan objek yang tidak ditandai. Jika tidak ada yang menunjuk ke sebuah objek, objek itu menjadi layak dikoleksi.
Gaya GC yang umum (tingkat tinggi)
Generational GC didasarkan pada pengamatan bahwa banyak objek mati muda. Ia memisahkan heap menjadi generasi dan mengumpulkan area muda lebih sering, yang biasanya lebih murah dan meningkatkan efisiensi keseluruhan.
Concurrent GC menjalankan bagian-bagian koleksi bersamaan dengan thread aplikasi, bertujuan mengurangi jeda panjang. Ia mungkin melakukan lebih banyak bookkeeping agar tampilan memori konsisten saat program tetap berjalan.
GC biasanya menukar kontrol manual dengan pekerjaan runtime. Beberapa sistem memprioritaskan throughput stabil (banyak pekerjaan selesai per detik) tetapi mungkin memperkenalkan jeda stop-the-world. Lainnya meminimalkan jeda untuk aplikasi sensitif-latensi tetapi dapat menambah overhead selama eksekusi normal.
Mengapa pengembang menyukainya
GC menghilangkan satu kelas bug lifetime (terutama use-after-free) karena objek tidak direbut kembali saat masih dapat dijangkau. Ia juga mengurangi kebocoran yang disebabkan oleh dealokasi yang terlewat (meskipun Anda masih bisa “bocor” dengan mempertahankan referensi lebih lama dari yang dimaksudkan). Di basis kode besar di mana kepemilikan sulit dilacak secara manual, ini sering mempercepat iterasi.
Di mana Anda akan menemukannya
Runtime berbasis GC umum pada JVM (Java, Kotlin), .NET (C#, F#), Go, dan mesin JavaScript di browser serta Node.js.
Penghitungan Referensi: Pembersihan Segera dengan Trade-off
Reference counting adalah strategi manajemen memori di mana setiap objek melacak berapa banyak “pemilik” (referensi) yang menunjuk ke-nya. Ketika hitungan turun ke nol, objek dibebaskan segera. Ketegasan itu terasa intuitif: segera setelah tidak ada yang bisa menjangkau objek, memori dikembalikan.
Cara kerjanya (dan mengapa menarik)
Setiap kali Anda menyalin atau menyimpan referensi ke sebuah objek, runtime menaikkan penghitungnya; ketika sebuah referensi hilang, ia menurunkan penghitung. Mencapai nol memicu pembersihan saat itu juga.
Ini membuat manajemen sumber daya sederhana: objek sering melepaskan memori dekat dengan saat Anda berhenti menggunakannya, yang dapat mengurangi puncak penggunaan memori dan menghindari pembersihan tertunda.
Reference counting cenderung memiliki overhead konstan yang stabil: operasi increment/decrement terjadi pada banyak penugasan dan panggilan fungsi. Overhead itu biasanya kecil, tetapi ada di mana-mana.
Kelebihannya adalah Anda biasanya tidak mendapatkan jeda stop-the-world besar seperti beberapa garbage collector tracing. Latensi seringkali lebih halus, meskipun gelombang dealokasi bisa terjadi ketika graf objek besar kehilangan pemilik terakhirnya.
Perangkap besar: siklus
Reference counting tidak bisa merebut kembali objek yang terlibat dalam siklus. Jika A mereferensi B dan B mereferensi A, kedua hitungan tetap di atas nol meskipun tidak ada yang lain dapat menjangkau mereka—menciptakan kebocoran memori.
Ecosystem menangani ini dengan beberapa cara:
- Weak references (pointer non-pemilik) untuk memutus siklus pada pola umum (delegate, tautan parent/child).
- Deteksi siklus yang ditumpuk di atas reference counting (pass tracing yang menemukan siklus yang tak terjangkau).
Di mana Anda akan menemukannya
- Swift / Objective-C menggunakan ARC (Automatic Reference Counting), dengan referensi “strong/weak/unowned” untuk mengelola siklus.
- Python memakai reference counting untuk pembersihan segera, ditambah detektor siklus untuk mengumpulkan garbage siklik.
Kepemilikan dan Pinjaman: Keamanan Memori di Waktu Kompilasi
Buat prototipe yang terukur
Ubah ide arsitektur Anda menjadi aplikasi React + Go + Postgres dari satu chat.
Ownership dan borrowing adalah model memori yang paling dekat dikaitkan dengan Rust. Ide dasarnya sederhana: compiler menegakkan aturan yang membuatnya sulit menciptakan dangling pointer, double-free, dan banyak data race—tanpa mengandalkan garbage collector pada runtime.
Ownership: satu pemilik jelas, pembersihan deterministik
Setiap nilai memiliki tepat satu “pemilik” pada satu waktu. Ketika pemilik keluar scope, nilainya dibersihkan segera dan dapat diprediksi. Itu memberi Anda manajemen sumber daya deterministik (memori, file handle, socket) mirip dengan pembersihan manual, tetapi dengan jauh lebih sedikit cara untuk membuat kesalahan.
Kepemilikan juga bisa berpindah: menetapkan nilai ke variabel baru atau meneruskannya ke fungsi dapat mentransfer tanggung jawab. Setelah sebuah move, binding lama tidak bisa dipakai, yang mencegah use-after-free dengan konstruksi.
Borrowing: akses sementara tanpa mengambil kepemilikan
Borrowing memungkinkan Anda memakai sebuah nilai tanpa menjadi pemiliknya.
Sebuah shared borrow mengizinkan akses baca-saja dan bisa disalin bebas.
Sebuah mutable borrow mengizinkan pembaruan, tetapi harus eksklusif: selama borrow tersebut ada, tidak ada yang lain boleh membaca atau menulis nilai yang sama. Aturan “satu penulis atau banyak pembaca” ini diperiksa saat kompilasi.
Manfaat keamanan—dan biayanya
Karena lifetimes dilacak, compiler bisa menolak kode yang akan hidup lebih lama daripada data yang direferensikannya, menghilangkan banyak bug dangling-reference. Aturan yang sama juga mencegah kelas besar race condition pada kode konkuren.
Trade-off-nya adalah kurva belajar dan beberapa batasan desain. Anda mungkin perlu merestrukturisasi aliran data, memperkenalkan batas kepemilikan yang lebih jelas, atau menggunakan tipe khusus untuk state bersama yang bisa diubah.
Di mana ini unggul
Model ini cocok untuk kode sistem—layanan, embedded, networking, dan komponen sensitif-performa—di mana Anda menginginkan pembersihan yang dapat diprediksi dan latensi rendah tanpa jeda GC.
Arena, Region, dan Pool: Pola Alokasi Cepat
Ketika Anda membuat banyak objek berumur pendek—node AST dalam parser, entitas di frame game, data sementara selama permintaan web—overhead mengalokasikan dan membebaskan tiap objek satu per satu dapat mendominasi waktu berjalan. Arenas (juga disebut regions) dan pools adalah pola yang menukar frees halus untuk manajemen bulk yang cepat.
Apa itu arenas/regions
Arena adalah “zona” memori tempat Anda mengalokasikan banyak objek sepanjang waktu, lalu melepaskan semua sekaligus dengan menjatuhkan atau mereset arena.
Alih-alih melacak lifetime tiap objek secara individu, Anda mengikat lifetime ke batas yang jelas: “semua yang dialokasikan untuk request ini,” atau “semua yang dialokasikan saat mengompilasi fungsi ini.”
Mengapa bisa cepat
Arenas sering cepat karena mereka:
- mengurangi panggilan allocator (sering hanya pointer bumping)
- menghindari biaya free per-objek
- meningkatkan lokalitas cache dengan menjaga objek terkait berdekatan
Ini dapat meningkatkan throughput, dan juga mengurangi lonjakan latensi yang disebabkan free sering atau kontensi allocator.
Kasus penggunaan tipikal
Arenas dan pools muncul di:
- parser dan compiler (syntax tree, tabel simbol)
- data yang berskala per-request pada server (alokasi selama request, dibebaskan di akhir)
- game (alokasi per-frame direset tiap frame)
- simulasi dan pekerjaan batch
Pertimbangan keamanan
Aturan utama sederhana: jangan biarkan referensi melarikan diri dari region yang memiliki memori. Jika sesuatu yang dialokasikan di arena disimpan secara global atau dikembalikan melewati lifetime arena, Anda berisiko bug use-after-free.
Bahasa dan pustaka menangani ini berbeda: beberapa mengandalkan disiplin dan API, yang lain bisa mengekode batas region ke dalam tipe.
Bagaimana ia melengkapi pendekatan lain
Arenas dan pools bukan pengganti GC atau ownership—mereka sering pelengkap. Bahasa berbasis GC umum menggunakan object pool pada jalur panas; bahasa berbasis ownership dapat menggunakan arena untuk mengelompokkan alokasi dan membuat lifetime eksplisit. Jika dipakai dengan hati-hati, mereka memberi alokasi “cepat secara default” tanpa mengorbankan kejelasan kapan memori dilepaskan.
Optimasi Compiler dan Runtime yang Mengubah Cerita
Rencanakan masa hidup objek sejak awal
Petakan masa hidup objek dan batas kepemilikan sebelum menghasilkan kode.
Model memori sebuah bahasa hanyalah bagian dari cerita performa dan keamanan. Compiler dan runtime modern menulis ulang program Anda untuk mengalokasikan lebih sedikit, membebaskan lebih cepat, dan menghindari bookkeeping ekstra. Itulah mengapa aturan praktis seperti “GC itu lambat” atau “memori manual paling cepat” sering runtuh dalam aplikasi nyata.
Escape analysis: ketika heap tidak perlu
Banyak alokasi hanya ada untuk meneruskan data antar fungsi. Dengan escape analysis, compiler dapat membuktikan sebuah objek tidak hidup lebih lama dari scope saat ini dan menyimpannya di stack alih-alih heap.
Itu bisa menghapus alokasi heap sepenuhnya, bersama biaya terkait (pelacakan GC, update reference count, kunci allocator). Pada bahasa terkelola, ini alasan utama objek kecil bisa lebih murah dari yang Anda kira.
Inlining dan penghapusan alokasi
Ketika compiler inline fungsi (mengganti panggilan dengan badan fungsi), ia mungkin “melihat melalui” lapisan abstraksi. Visibilitas itu memungkinkan optimasi seperti:
- menghilangkan objek sementara
- penggantian skalar (mengubah objek menjadi beberapa variabel lokal)
- menghapus trafik reference-count ketika lifetime menjadi jelas
API yang dirancang dengan baik bisa menjadi “zero-cost” setelah optimasi, meskipun di kode sumber terlihat banyak alokasi.
JIT vs kompilasi ahead-of-time
Sebuah runtime JIT (just-in-time) dapat mengoptimalkan menggunakan data produksi nyata: jalur kode mana yang hot, ukuran objek tipikal, dan pola alokasi. Itu sering meningkatkan throughput, tetapi dapat menambah waktu warm-up dan kadang jeda untuk recompilation atau GC.
Kompilasi ahead-of-time harus menebak lebih awal, tetapi memberikan startup yang dapat diprediksi dan latensi yang lebih stabil.
Tuas penyetelan runtime (dan kapan menyentuhnya)
Runtime berbasis GC mengekspos pengaturan seperti ukuran heap, target waktu jeda, dan ambang generasi. Sesuaikan hanya saat Anda punya bukti terukur (mis. spike latensi atau tekanan memori), bukan sebagai langkah pertama.
Mengapa algoritma yang sama berperilaku berbeda
Dua implementasi dari algoritma “yang sama” bisa berbeda dalam jumlah alokasi tersembunyi, objek sementara, dan pointer chasing. Perbedaan itu berinteraksi dengan optimizer, allocator, dan perilaku cache—jadi perbandingan performa membutuhkan profiling, bukan asumsi.
Pilihan manajemen memori tidak hanya mengubah bagaimana Anda menulis kode—mereka mengubah kapan pekerjaan terjadi, berapa banyak memori yang perlu Anda sediakan, dan seberapa konsisten performa terasa bagi pengguna.
Throughput vs. latency (contoh konkret)
Throughput adalah “berapa banyak pekerjaan per unit waktu.” Bayangkan job batch semalaman yang memproses 10 juta record: jika garbage collection atau reference counting menambah overhead kecil tetapi menjaga produktivitas pengembang, Anda mungkin tetap selesai paling cepat secara keseluruhan.
Latensi adalah “berapa lama satu operasi berlangsung end-to-end.” Untuk sebuah permintaan web, satu respons lambat merusak pengalaman pengguna meskipun rata-rata throughput tinggi. Runtime yang kadang berhenti untuk merebut kembali memori bisa cocok untuk pemrosesan batch, tetapi terasa mengganggu untuk aplikasi interaktif.
Jejak memori: biaya dan kecepatan
Jejak memori yang lebih besar meningkatkan biaya cloud dan bisa memperlambat program. Ketika working set tidak muat baik di cache CPU, CPU lebih sering menunggu data dari RAM. Beberapa strategi menukar memori ekstra untuk kecepatan (mis. menjaga objek yang dibebaskan dalam pool), sementara lainnya mengurangi memori namun menambah bookkeeping.
Fragmentasi dan lokalitas cache (penjelasan sederhana)
Fragmentasi terjadi ketika memori bebas terpecah menjadi banyak celah kecil—seperti mencoba memarkir van di lot dengan banyak ruang kecil terserak. Allocator mungkin menghabiskan lebih banyak waktu mencari ruang, dan memori bisa tumbuh meskipun “cukup” secara teknis tersedia.
Lokalitas cache berarti data terkait duduk dekat satu sama lain. Alokasi pool/arena sering meningkatkan lokalitas (objek yang dialokasikan bersama jadi berdekatan), sementara heap jangka panjang dengan ukuran objek campuran bisa meluruh ke tata letak yang kurang ramah cache.
Kebutuhan waktu yang dapat diprediksi
Jika Anda membutuhkan waktu respons yang konsisten—game, aplikasi audio, sistem trading, pengendali embedded atau real-time—“sebagian besar cepat tapi kadang lambat” bisa lebih buruk daripada “sedikit lebih lambat tapi konsisten.” Di sinilah pola dealloc yang dapat diprediksi dan kontrol ketat atas alokasi menjadi penting.
Daftar pemeriksaan pengukuran
- Benchmark throughput (jobs/sec) dan tail latency (p95/p99 waktu respon)
- Profil alokasi: laju alokasi, waktu jeda, dan waktu yang dihabiskan di alloc/free
- Gunakan beban representatif (bentuk traffic nyata, ukuran data, concurrency)
- Lacak memori: peak RSS, ukuran heap dari waktu ke waktu, metrik fragmentasi (jika tersedia)
- Ulangi jalankan untuk menangkap variabilitas (efek warm-up, siklus GC latar)
Keamanan: Bagaimana Model Memori Mencegah Bug Umum
Kesalahan memori bukan hanya “kesalahan programmer.” Di banyak sistem nyata, mereka berubah menjadi masalah keamanan: crash mendadak (denial of service), ekspos data tak sengaja (membaca memori yang dilepas atau belum diinisialisasi), atau kondisi yang dapat dieksploitasi di mana penyerang mengarahkan program menjalankan kode yang tidak diinginkan.
Strategi manajemen memori berbeda cenderung gagal dengan cara berbeda:
- Manajemen manual (mis. C/C++) sering berisiko use-after-free, double free, dan buffer overflow—isu yang dapat merusak memori dan jadi eksploit.
- Garbage collection menghapus sebagian besar error tipe UAF karena objek tidak dibebaskan saat masih dapat dijangkau, tetapi Anda masih bisa mengalami kebocoran memori (menahan referensi secara tidak sengaja) dan risiko interoperabilitas native yang tidak aman.
- Reference counting memberi pembersihan segera yang membantu pelepasan resource yang dapat diprediksi, tetapi bisa menderita siklus (kebocoran) dan isu lifetime halus saat bercampur dengan state bersama yang dapat diubah.
- Ownership/borrowing (mis. model Rust) mencegah banyak kelas UAF dan data-race di waktu kompilasi dengan membuatnya sulit memiliki referensi menggantung atau mutasi bersama tanpa sinkronisasi.
Keamanan thread dan konkurensi
Konkurensi mengubah model ancaman: memori yang “baik” di satu thread bisa jadi berbahaya ketika thread lain membebaskan atau memutasi-nya. Model yang menegakkan aturan berbagi (atau mengharuskan sinkronisasi eksplisit) mengurangi kemungkinan race condition yang menyebabkan korupsi state, kebocoran data, dan crash intermittent.
Defense in depth tetap penting
Tidak ada model memori yang menghilangkan semua risiko—bug logika (kesalahan auth, default tidak aman, validasi yang salah) tetap terjadi. Tim yang kuat menumpuk proteksi: sanitizer dalam testing, perpustakaan standar yang aman, review kode ketat, fuzzing, dan batasan ketat pada kode unsafe/FFI. Keamanan memori memang mengurangi permukaan serangan secara besar, tetapi bukan jaminan.
Prototipe versi mobile
Coba alur kerja yang sama di Flutter untuk membandingkan tekanan memori pada perangkat mobile.
Masalah memori lebih mudah diperbaiki jika Anda menemukannya dekat dengan perubahan yang memperkenalkannya. Kuncinya adalah mengukur dulu, lalu mempersempit masalah dengan alat yang tepat.
Dasar-dasar profiling: apa yang diukur (dan kapan)
Mulai dengan memutuskan apakah Anda mengejar kecepatan atau pertumbuhan memori.
Untuk performa, ukur waktu wall-clock, CPU time, laju alokasi (bytes/sec), dan waktu GC atau allocator. Untuk memori, pantau peak RSS, steady-state RSS, dan jumlah objek dari waktu ke waktu. Jalankan beban dengan input konsisten; variasi kecil bisa menyembunyikan churn alokasi.
Kategori alat (apa yang ditemukan tiap alat)
- Profiler CPU + alokasi: tunjukkan di mana waktu dihabiskan dan jalur mana yang paling banyak mengalokasi. Bagus untuk menemukan “kematian oleh ribuan alokasi kecil.”
- Detektor kebocoran: melaporkan memori yang dialokasikan tapi tidak pernah dibebaskan (atau tidak pernah menjadi tak terjangkau untuk GC).
- Sanitizer: menangkap use-after-free, buffer overflow, data race, dan undefined behavior lebih awal di pengujian.
- Fuzzing: memberi input tak terduga untuk memicu crash dan korupsi memori yang tes normal lewatkan.
Menemukan hotspot alokasi dan mengurangi churn
Tanda umum: satu permintaan mengalokasikan jauh lebih banyak dari yang diharapkan, atau memori naik seiring traffic meskipun throughput stabil. Perbaikan sering termasuk menggunakan ulang buffer, beralih ke arena/pool untuk objek berumur pendek, dan menyederhanakan graph objek sehingga lebih sedikit objek bertahan lintas siklus.
Alur kerja praktis untuk kebocoran dan crash
Reproduksi dengan input minimal, aktifkan pengecekan runtime ketat (sanitizer/verifikasi GC), lalu tangkap:
- profile (CPU + alokasi), 2) snapshot heap atau laporan kebocoran, 3) stack trace saat kegagalan.
Anggap perbaikan pertama sebagai eksperimen; jalankan ulang pengukuran untuk mengonfirmasi perubahan mengurangi alokasi atau menstabilkan memori—tanpa memindahkan masalah ke tempat lain. Untuk lebih lanjut tentang menginterpretasi trade-off, lihat /blog/performance-trade-offs-throughput-latency-memory-use.
Memilih Bahasa: Cocokkan Model Memori ke Tujuan Anda
Memilih bahasa bukan hanya soal sintaks atau ekosistem—model memorinya membentuk kecepatan pengembangan sehari-hari, risiko operasional, dan seberapa dapat diprediksinya performa di lalu lintas nyata.
Mulai dari kebutuhan Anda (bukan preferensi)
Pemetakan kebutuhan produk ke strategi memori dengan menjawab beberapa pertanyaan praktis:
- Keahlian tim dan toleransi terhadap kompleksitas: Apakah kontributor umumnya nyaman menganalisis lifetime dan kepemilikan, atau Anda ingin runtime yang menanganinya?
- Latensi vs throughput: Apakah Anda membutuhkan tail latency konsisten (mis. trading, audio, kontrol real-time), atau throughput rata-rata yang menjadi prioritas (mis. backend web, batch)?
- Kendala deployment: Apakah Anda berjalan di envelope memori yang ketat (embedded, mobile), atau punya ruang untuk runtime dan heap lebih besar?
Kecocokan umum
- Garbage collection (GC): Sering cocok untuk layanan backend dan aplikasi produk di mana kecepatan pengembangan dan keamanan lebih penting daripada jeda mikro-detik.
- Ownership/borrowing (mis. Rust): Cocok untuk kode sistem, komponen krusial-performa, dan kode sensitif-keamanan di mana bug memori tidak dapat diterima.
- Reference counting (RC): Sering cocok untuk aplikasi desktop/mobile dan program UI yang mendapat manfaat dari pembersihan inkremental yang dapat diprediksi, dengan menerima penanganan siklus dan overhead per-penugasan.
Migrasi dan interoperabilitas
Jika Anda mengganti model, rencanakan friksi: memanggil pustaka yang ada (FFI), konvensi memori campuran, tooling, dan pasar perekrutan. Prototipe membantu menemukan biaya tersembunyi (jeda, pertumbuhan memori, overhead CPU) lebih awal.
Pendekatan praktis adalah membuat prototype fitur yang sama di lingkungan yang Anda pertimbangkan dan membandingkan laju alokasi, tail latency, dan memori puncak di bawah beban representatif. Tim kadang melakukan evaluasi “apel-ke-apel” semacam ini di Koder.ai: Anda bisa cepat membuat frontend React kecil plus backend Go + PostgreSQL, lalu iterasi bentuk permintaan dan struktur data untuk melihat bagaimana layanan berbasis GC berperilaku di traffic realistis (dan mengekspor kode sumber jika ingin dibawa lebih jauh).
Kerangka keputusan ringan
Definisikan 3–5 kendala teratas, bangun prototype tipis, dan ukur penggunaan memori, tail latency, dan mode kegagalan.
| Model | Keamanan bawaan | Prediktabilitas latensi | Kecepatan pengembang | Perangkap biasa |
|---|
| Manual | Rendah–Sedang | Tinggi | Sedang | kebocoran, use-after-free |
| GC | Tinggi | Sedang | Tinggi | jeda, pertumbuhan heap |
| RC | Sedang–Tinggi | Tinggi | Sedang | siklus, overhead |
| Ownership | Tinggi | Tinggi | Sedang | kurva belajar |