Mengapa tim sering mentok dengan integrasi tradisional
Kebanyakan produk dimulai dengan integrasi point-to-point sederhana: Sistem A memanggil Sistem B, atau skrip kecil menyalin data dari satu tempat ke tempat lain. Itu bekerja sampai produk tumbuh, tim terpecah, dan jumlah koneksi bertambah. Tidak lama setiap perubahan membutuhkan koordinasi di beberapa layanan, karena satu field kecil atau pembaruan status bisa merambat lewat rantai ketergantungan.
Kecepatan biasanya hal pertama yang rusak. Menambahkan fitur baru berarti memperbarui beberapa integrasi, redeploy beberapa layanan, dan berharap tidak ada yang bergantung pada perilaku lama.
Kemudian debugging menjadi menyakitkan. Ketika sesuatu terlihat salah di UI, sulit menjawab pertanyaan dasar: apa yang terjadi, dalam urutan apa, dan sistem mana yang menulis nilai yang Anda lihat?
Bagian yang hilang seringkali jejak audit. Jika data didorong langsung dari satu database ke database lain (atau diubah di sepanjang jalan), Anda kehilangan sejarah. Anda mungkin melihat keadaan akhir, tapi bukan urutan peristiwa yang membawanya ke sana. Review insiden dan dukungan pelanggan menderita karena Anda tidak bisa memutar ulang masa lalu untuk memastikan apa yang berubah dan mengapa.
Di sinilah juga argumen “siapa yang memegang kebenaran” muncul. Satu tim berkata, “Layanan billing adalah sumber kebenaran.” Yang lain berkata, “Layanan order yang dimaksud.” Kenyataannya, setiap sistem punya pandangan parsial, dan integrasi point-to-point membuat ketidaksepakatan itu menjadi gesekan sehari-hari.
Contoh sederhana: sebuah order dibuat, lalu dibayar, lalu dikembalikan. Jika tiga sistem saling memperbarui langsung, masing-masing bisa punya cerita berbeda ketika retry, timeout, atau perbaikan manual terjadi.
Itu mengarah ke pertanyaan desain inti di balik streaming event Kafka: apakah Anda hanya perlu memindahkan pekerjaan dari satu tempat ke tempat lain (antrian), atau Anda butuh catatan bersama dan tahan lama tentang apa yang terjadi yang bisa dibaca banyak sistem, diputar ulang, dan dipercaya (log)? Jawabannya mengubah cara Anda membangun, debugging, dan mengembangkan sistem.
Jay Kreps, Kafka, dan gagasan log
Jay Kreps membantu membentuk Kafka dan, lebih penting, cara banyak tim memikirkan pemindahan data. Perpindahan mindset yang berguna adalah: berhenti memperlakukan pesan sebagai pengiriman sekali saja, dan mulai memandang aktivitas sistem sebagai sebuah rekaman.
Idenya sederhana. Modelkan perubahan penting sebagai aliran fakta yang tak bisa diubah:
- Sebuah order dibuat.
- Pembayaran diotorisasi.
- Pengguna mengubah email mereka.
Setiap event adalah fakta yang sebaiknya tidak diedit setelahnya. Jika sesuatu berubah kemudian, Anda menambahkan event baru yang menyatakan kebenaran baru itu. Seiring waktu, fakta-fakta itu membentuk sebuah log: riwayat append-only dari sistem Anda.
Di sinilah streaming event Kafka berbeda dari banyak pengaturan messaging dasar. Banyak antrian dibangun di sekitar “kirim, proses, hapus.” Itu cukup ketika pekerjaan murni hanya perpindahan tugas. Pandangan log mengatakan, “simpan sejarah agar banyak consumer bisa menggunakannya, sekarang dan nanti.”
Memutar ulang sejarah adalah kekuatan praktisnya.
Jika sebuah laporan salah, Anda bisa menjalankan ulang sejarah event yang sama melalui job analytics yang sudah diperbaiki dan melihat di mana angka berubah. Jika bug menyebabkan email salah, Anda bisa memutar ulang event ke lingkungan uji dan mereproduksi garis waktu yang tepat. Jika fitur baru butuh data lama, Anda bisa membuat consumer baru yang mulai dari awal dan mengejar ketertinggalan sesuai kecepatannya.
Contoh konkret: bayangkan Anda menambahkan pemeriksaan fraud setelah memproses bulan-bulan pembayaran. Dengan log pembayaran dan event akun, Anda bisa memutar ulang masa lalu untuk melatih atau mengkalibrasi aturan pada urutan nyata, menghitung skor risiko untuk transaksi lama, dan backfill event “fraud_review_requested” tanpa menulis ulang database.
Perhatikan apa yang dipaksa oleh pendekatan ini. Pendekatan berbasis log mendorong Anda memberi nama event dengan jelas, menjaga stabilitasnya, dan menerima bahwa banyak tim dan layanan akan bergantung padanya. Ini juga memaksa pertanyaan berguna: Apa sumber kebenaran? Apa arti event ini dalam jangka panjang? Apa yang kita lakukan ketika kita membuat kesalahan?
Nilainya bukan pada kepribadian. Nilainya adalah menyadari bahwa log bersama bisa menjadi memori sistem Anda, dan memori adalah apa yang membuat sistem bisa tumbuh tanpa rusak setiap kali Anda menambahkan consumer baru.
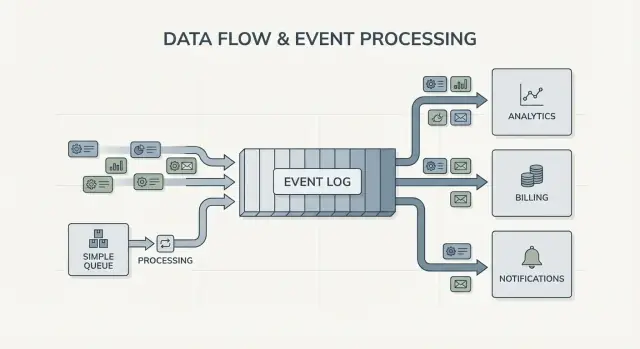
Antrian vs log: model mental paling sederhana
Message queue seperti barisan tugas untuk perangkat lunak Anda. Producer menaruh pekerjaan ke dalam barisan, consumer mengambil item berikutnya, melakukan pekerjaan, lalu item itu hilang. Sistem ini tentang mengerjakan setiap tugas sekali, secepat mungkin.
Log berbeda. Ia adalah catatan berurutan dari fakta yang terjadi, disimpan dalam urutan yang tahan lama. Konsumen tidak “mengambil” event. Mereka membaca log sesuai kecepatannya, dan bisa membacanya lagi nanti. Dalam streaming event Kafka, log itu adalah ide inti.
Cara praktis mengingat perbedaan:
- Queue = pekerjaan yang harus dilakukan. Setelah worker mengonfirmasi, tugas itu hilang.
- Log = sejarah apa yang terjadi. Event tetap ada untuk periode retensi.
Retensi mengubah desain. Dengan queue, jika nanti Anda butuh fitur baru yang bergantung pada pesan lama (analytics, pemeriksaan fraud, replay setelah bug), Anda sering harus menambahkan database terpisah atau mulai menangkap salinan tambahan di tempat lain. Dengan log, replay adalah hal biasa: Anda bisa membangun kembali view turunan dengan membaca dari awal (atau dari checkpoint yang diketahui).
Fan-out adalah perbedaan besar lainnya. Bayangkan layanan checkout memancarkan OrderPlaced. Dengan queue, biasanya Anda memilih satu grup worker untuk memprosesnya, atau menggandakan pekerjaan ke beberapa queue. Dengan log, billing, email, inventori, indexing pencarian, dan analytics bisa semua membaca aliran event yang sama secara independen. Setiap tim bisa bergerak dengan kecepatannya sendiri, dan menambah consumer baru nanti tidak memerlukan perubahan pada producer.
Jadi model mentalnya jelas: gunakan queue ketika Anda memindahkan tugas; gunakan log ketika Anda merekam event yang banyak bagian perusahaan mungkin ingin baca, sekarang atau nanti.
Apa yang berubah dalam desain sistem dengan event streaming
Event streaming membalikkan pertanyaan default. Alih-alih bertanya, “Ke siapa saya harus mengirim pesan ini?”, Anda mulai dengan merekam “Apa yang baru saja terjadi?” Itu terdengar kecil, tapi mengubah cara Anda memodelkan sistem.
Anda menerbitkan fakta seperti OrderPlaced atau PaymentFailed, dan bagian lain sistem memutuskan apakah, kapan, dan bagaimana mereka bereaksi.
Dengan streaming event Kafka, producer tidak lagi perlu daftar integrasi langsung. Layanan checkout bisa menerbitkan satu event, dan tidak perlu tahu apakah analytics, email, pemeriksaan fraud, atau layanan rekomendasi di masa depan akan menggunakannya. Konsumer baru bisa muncul nanti, yang lama bisa dijeda, dan producer tetap berperilaku sama.
Ini juga mengubah cara Anda pulih dari kesalahan. Di dunia pesan-saja, begitu konsumen melewatkan sesuatu atau punya bug, data seringkali “hilang” kecuali Anda membangun backup kustom. Dengan log, Anda bisa memperbaiki kode dan memutar ulang sejarah untuk membangun kembali state yang benar. Itu seringkali lebih baik daripada mengedit tabel database secara manual atau skrip satu-kali yang tak dipercaya.
Dalam praktik, pergeseran ini muncul dalam beberapa cara andal: Anda memperlakukan event sebagai catatan tahan lama, Anda menambah fitur dengan berlangganan alih-alih memodifikasi producer, Anda bisa membangun kembali read model (index pencarian, dashboard) dari awal, dan Anda mendapatkan timeline yang lebih jelas tentang apa yang terjadi di seluruh layanan.
Observability meningkat karena event log menjadi referensi bersama. Ketika sesuatu salah, Anda bisa mengikuti urutan bisnis: order dibuat, inventori dicadangkan, pembayaran dicoba ulang, pengiriman dijadwalkan. Garis waktu itu seringkali lebih mudah dipahami daripada log aplikasi yang tercecer karena berfokus pada fakta bisnis.
Contoh konkret: jika bug harga diskon salah selama dua jam, Anda bisa mengirim perbaikan dan memutar ulang event yang terdampak untuk menghitung ulang total, memperbarui faktur, dan menyegarkan analytics. Anda memperbaiki hasil dengan menurunkan kembali hasil, bukan menebak tabel mana yang harus dipatch secara manual.
Kapan antrian sederhana sudah cukup
Antrian sederhana adalah alat yang tepat ketika Anda memindahkan pekerjaan, bukan membangun catatan jangka panjang. Tujuannya adalah menyerahkan tugas ke worker, menjalankannya, lalu melupakannya. Jika tidak ada yang perlu memutar ulang masa lalu, memeriksa event lama, atau menambah konsumen baru nanti, queue menjaga semuanya lebih sederhana.
Queue unggul untuk pekerjaan latar belakang: mengirim email pendaftaran, mengubah ukuran gambar setelah upload, menghasilkan laporan malam, atau memanggil API eksternal yang lambat. Dalam kasus ini pesan hanyalah tiket kerja. Setelah worker menyelesaikan tugas, tiket itu juga selesai.
Queue juga sesuai dengan model kepemilikan yang biasa: satu consumer group bertanggung jawab menjalankan pekerjaan, dan layanan lain tidak diharapkan membaca pesan yang sama secara independen.
Queue biasanya cukup ketika kebanyakan dari ini benar:
- Data punya nilai singkat.
- Satu tim atau satu layanan memiliki pekerjaan secara end-to-end.
- Replay dan retensi panjang bukan persyaratan.
- Debugging tidak bergantung pada menjalankan ulang sejarah.
Contoh: produk mengunggah foto pengguna. Aplikasi menulis tugas “resize image” ke antrian. Worker A mengambilnya, membuat thumbnail, menyimpannya, dan menandai tugas selesai. Jika tugas berjalan dua kali, outputnya sama (idempoten), jadi delivery minimal-sekali cukup. Tidak ada layanan lain yang perlu membaca tugas itu nanti.
Jika kebutuhan Anda mulai bergeser ke fakta bersama (banyak konsumen), replay, audit, atau “apa yang sistem percayai minggu lalu?”, di sanalah streaming event Kafka dan pendekatan berbasis log mulai terasa menguntungkan.
Kapan pendekatan berbasis log menguntungkan
Pendekatan berbasis log menguntungkan ketika event berhenti menjadi pesan sekali dan mulai menjadi sejarah bersama. Alih-alih “kirim dan lupakan,” Anda menyimpan catatan berurutan yang banyak tim bisa baca, sekarang atau nanti, dengan kecepatan mereka sendiri.
Sinyal paling jelas adalah banyak konsumen. Satu event seperti OrderPlaced dapat memberi makan billing, email, pemeriksaan fraud, indexing pencarian, dan analytics. Dengan log, setiap konsumen membaca aliran yang sama secara independen. Anda tidak perlu membangun pipeline fan-out kustom atau mengoordinasikan siapa yang mendapat pesan duluan.
Kegunaan lain adalah kemampuan menjawab, “Apa yang kita tahu saat itu?” Jika pelanggan membantah biaya, atau rekomendasi tampak salah, sejarah append-only memungkinkan Anda memutar ulang fakta seperti saat mereka diterima. Jejak audit itu sulit ditambahkan ke antrian sederhana nanti.
Anda juga mendapatkan cara praktis untuk menambah fitur tanpa menulis ulang yang lama. Jika Anda menambahkan halaman “status pengiriman” beberapa bulan kemudian, layanan baru bisa berlangganan dan backfill dari sejarah yang ada untuk membangun state-nya, daripada meminta tiap sistem upstream mengekspor data.
Pendekatan berbasis log sering sepadan ketika Anda mengenali satu atau lebih kebutuhan ini:
- Event yang sama harus memberi makan beberapa sistem (analytics, pencarian, billing, alat dukungan).
- Anda butuh replay, auditing, atau investigasi berdasarkan fakta masa lalu.
- Layanan baru harus backfill dari sejarah tanpa job satu-kali.
- Urutan penting per entitas (per order, per user).
- Format event akan berkembang dan Anda butuh cara terkontrol untuk menangani versioning.
Polanya umum: produk mulai dengan order dan email. Kemudian finance ingin laporan pendapatan, produk ingin funnel, dan ops ingin dashboard live. Jika setiap kebutuhan baru memaksa Anda menyalin data lewat pipeline baru, biaya dan kompleksitas tumbuh cepat. Event log bersama memungkinkan tim membangun di atas sumber kebenaran yang sama, bahkan ketika sistem berkembang dan bentuk event berubah.
Cara memutuskan, langkah demi langkah
Memilih antara queue sederhana dan pendekatan berbasis log lebih mudah ketika Anda menganggapnya sebagai keputusan produk. Mulai dari apa yang Anda butuhkan satu tahun dari sekarang, bukan hanya apa yang bekerja minggu ini.
5 langkah praktis untuk memutuskan
-
Petakan publisher dan reader. Tuliskan siapa yang membuat event dan siapa yang membacanya hari ini, lalu tambahkan kemungkinan konsumen di masa depan (analytics, indexing pencarian, pemeriksaan fraud, notifikasi pelanggan). Jika Anda mengharapkan banyak tim membaca event yang sama secara independen, log mulai masuk akal.
-
Tanyakan apakah Anda akan perlu membaca ulang sejarah. Jelaskan alasannya: replay setelah bug, backfill, atau konsumen yang membaca dengan kecepatan berbeda. Queue bagus untuk menyerahkan pekerjaan sekali. Log lebih baik ketika Anda menginginkan catatan yang bisa diputar ulang.
-
Definisikan apa arti “selesai”. Untuk beberapa workflow, selesai berarti “job berjalan” (kirim email, ubah ukuran gambar). Untuk yang lain, selesai berarti “event adalah fakta tahan lama” (sebuah order dibuat, pembayaran diotorisasi). Fakta tahan lama mendorong Anda ke log.
-
Pilih ekspektasi delivery dan putuskan bagaimana menangani duplikat. Delivery minimal-sekali umum, yang berarti duplikat bisa terjadi. Jika duplikat bisa berbahaya (double-charge), rencanakan idempotency: simpan ID event yang sudah diproses, gunakan constraint unik, atau buat update yang aman diulang.
-
Mulai dengan satu irisan tipis. Pilih satu topik event yang mudah dipahami dan kembangkan dari sana. Jika Anda memilih streaming event Kafka, jaga topic pertama fokus, beri nama event jelas, dan hindari mencampur tipe event yang tidak terkait.
Contoh konkret: jika OrderPlaced nanti akan memberi makan shipping, invoicing, support, dan analytics, log memungkinkan setiap tim membaca sesuai kecepatannya dan memutar ulang setelah kesalahan. Jika Anda hanya membutuhkan worker latar belakang untuk mengirim email tanda terima, queue sederhana biasanya cukup.
Contoh: event order di produk yang berkembang
Bayangkan toko online kecil. Awalnya hanya perlu menerima order, menagih kartu, dan membuat permintaan pengiriman. Versi paling mudah adalah satu job latar yang berjalan setelah checkout: “process order.” Ia memanggil API pembayaran, memperbarui baris order di database, lalu memanggil pengiriman.
Gaya antrian itu bekerja baik ketika ada satu alur jelas, hanya satu consumer (worker), dan retry serta dead letter menutupi sebagian besar kasus kegagalan.
Itu mulai menyakitkan saat toko tumbuh. Support ingin update otomatis “di mana order saya?”. Finance ingin angka pendapatan harian. Tim produk ingin email pelanggan. Pemeriksaan fraud harus terjadi sebelum pengiriman. Dengan satu job “process order”, Anda terus-menerus mengedit worker yang sama, menambah cabang, dan mempertaruhkan bug baru di alur inti.
Dengan pendekatan berbasis log, checkout menghasilkan fakta-fakta kecil sebagai event, dan setiap tim bisa membangun di atasnya. Event tipikal mungkin terlihat seperti:
OrderPlacedPaymentConfirmedItemShippedRefundIssued
Perubahan kuncinya adalah kepemilikan. Layanan checkout memiliki OrderPlaced. Layanan pembayaran memiliki PaymentConfirmed. Pengiriman memiliki ItemShipped. Nanti, konsumen baru bisa muncul tanpa mengubah producer: layanan fraud membaca OrderPlaced dan PaymentConfirmed untuk memberi skor risiko, layanan email mengirim tanda terima, analytics membangun funnel, dan alat support menyimpan timeline kejadian.
Di sinilah streaming event Kafka terasa berharga: log menyimpan sejarah, sehingga konsumen baru bisa memutar mundur dan mengejar dari awal (atau dari titik yang diketahui) daripada meminta setiap tim upstream menambahkan webhook baru.
Log tidak menggantikan database Anda. Anda tetap butuh database untuk state saat ini: status order terbaru, record pelanggan, jumlah inventori, dan aturan transaksional (seperti “jangan kirim kecuali pembayaran dikonfirmasi”). Anggap log sebagai catatan perubahan dan database sebagai tempat Anda menanyakan “apa yang benar sekarang.”
Kesalahan umum dan jebakan
Event streaming bisa membuat sistem terasa lebih rapi, tapi beberapa kesalahan umum bisa menghapus manfaatnya dengan cepat. Sebagian besar berasal dari memperlakukan event log seperti remote control bukan catatan.
Jebakan yang sering terjadi adalah menulis event sebagai command, seperti “SendWelcomeEmail” atau “ChargeCardNow.” Itu membuat konsumen sangat terikat pada niat Anda. Event bekerja lebih baik sebagai fakta: “UserSignedUp” atau “PaymentAuthorized.” Fakta lebih tahan lama. Tim baru bisa menggunakan ulang tanpa menebak maksud Anda.
Duplikat dan retry adalah sumber sakit besar berikutnya. Di sistem nyata, producer me-retry dan konsumen memproses ulang. Jika Anda tidak merencanakannya, Anda mendapatkan tagihan ganda, email ganda, dan tiket support marah. Perbaikannya tidak eksotis, tapi harus disengaja: handler idempotent, ID event yang stabil, dan aturan bisnis yang mendeteksi “sudah diterapkan.”
Jebakan umum:
- Menggunakan event bergaya command yang memberi tahu layanan apa yang harus dilakukan alih-alih merekam apa yang terjadi.
- Membangun konsumen yang rusak jika melihat event yang sama dua kali.
- Memecah stream terlalu dini, sehingga satu alur bisnis tersebar ke terlalu banyak topic.
- Mengabaikan aturan skema sampai perubahan kecil memecah konsumen lama.
- Menganggap streaming sebagai pengganti desain database yang baik.
Skema dan versioning layak mendapat perhatian khusus. Bahkan jika Anda mulai dengan JSON, Anda tetap butuh kontrak jelas: field yang wajib, field opsional, dan bagaimana perubahan digulirkan. Perubahan kecil seperti mengganti nama field bisa diam-diam memecah analytics, billing, atau aplikasi mobile yang update-nya lebih lambat.
Jebakan lain adalah over-splitting. Tim terkadang membuat stream baru untuk tiap fitur. Sebulan kemudian, tak ada yang bisa menjawab “Apa keadaan saat ini dari sebuah order?” karena cerita tersebar di terlalu banyak tempat.
Event streaming tidak menghilangkan kebutuhan model data yang solid. Anda tetap butuh database yang merepresentasikan kebenaran saat ini. Log adalah riwayat, bukan seluruh aplikasi Anda.
Daftar periksa cepat dan langkah selanjutnya
Jika Anda bingung memilih antara queue dan streaming event Kafka, mulailah dengan beberapa pengecekan cepat. Mereka akan memberi tahu apakah Anda hanya butuh handoff sederhana antar worker, atau log yang bisa dipakai ulang selama bertahun-tahun.
Pemeriksaan cepat
- Apakah Anda perlu replay (untuk backfill, perbaikan bug, atau fitur baru), dan sejauh mana?
- Apakah lebih dari satu konsumen akan membutuhkan event yang sama sekarang atau segera (analytics, pencarian, email, fraud, billing)?
- Apakah Anda butuh retensi supaya tim bisa membaca ulang sejarah tanpa meminta producer mengirim ulang?
- Seberapa penting urutan, dan pada level apa: per entitas (per order, per user) atau benar-benar global?
- Bisakah konsumen dibuat idempotent (aman untuk retry event yang sama tanpa double-charge, double-email, atau update ganda)?
Jika Anda menjawab “tidak” untuk replay, “satu konsumen saja,” dan “pesan bernilai singkat,” antrian dasar biasanya cukup. Jika Anda menjawab “ya” untuk replay, banyak konsumen, atau retensi lebih lama, pendekatan berbasis log cenderung menguntungkan karena mengubah satu aliran fakta menjadi sumber bersama yang bisa dibangun sistem lain.
Langkah selanjutnya
Ubah jawaban menjadi rencana kecil yang bisa diuji.
- Daftarkan 5–10 event inti dalam bahasa sederhana (contoh: OrderPlaced, PaymentAuthorized, OrderShipped) dan catat siapa penerbit dan siapa konsumen masing-masing.
- Tentukan ordering key (sering per entitas, seperti orderId) dan dokumentasikan apa arti “urutan yang benar.”
- Definisikan aturan idempotency per konsumen (misal: simpan ID event terakhir yang diproses per order).
- Pilih target retensi yang sesuai (hari untuk workflow mirip queue, minggu/bulan ketika replay penting).
- Jalankan satu slice end-to-end di sandbox sebelum Anda mengunci seluruh sistem.
Jika Anda sedang prototipe cepat, Anda bisa menggambar aliran event di Koder.ai planning mode dan iterasi desain sebelum mengunci nama event dan aturan retry. Karena Koder.ai mendukung ekspor source code, snapshot, dan rollback, itu juga cara praktis untuk menguji satu producer-consumer slice dan menyesuaikan bentuk event tanpa mengubah eksperimen awal menjadi hutang produksi.