07 Nov 2025·8 menit
Penjelasan Terobosan Jaringan Syaraf Geoffrey Hinton
Panduan ringkas tentang ide kunci Geoffrey Hinton—dari backprop dan mesin Boltzmann hingga deep nets dan AlexNet—dan bagaimana gagasan itu membentuk AI modern.
Panduan ringkas tentang ide kunci Geoffrey Hinton—dari backprop dan mesin Boltzmann hingga deep nets dan AlexNet—dan bagaimana gagasan itu membentuk AI modern.
Panduan ini ditujukan untuk pembaca penasaran yang non-teknis yang sering mendengar bahwa “jaringan syaraf mengubah segalanya” dan ingin penjelasan yang jelas—tanpa perlu kalkulus atau pemrograman.
Anda akan mendapatkan tur bahasa-baku tentang ide-ide yang didorong Geoffrey Hinton, mengapa itu penting pada masanya, dan bagaimana ide-ide tersebut tersambung ke alat AI yang dipakai orang sekarang. Anggap ini sebagai cerita tentang cara yang lebih baik mengajari komputer mengenali pola—kata, gambar, suara—dengan belajar dari contoh.
Hinton tidak “menemukan AI,” dan tidak ada satu orang pun yang menciptakan pembelajaran mesin modern sendirian. Pentingnya dia adalah bahwa dia berkali-kali membantu membuat jaringan syaraf bekerja secara praktis ketika banyak peneliti menganggapnya jalan buntu. Dia menyumbang konsep kunci, eksperimen, dan budaya riset yang menempatkan pembelajaran representasi (fitur internal yang berguna) sebagai masalah sentral—alih-alih menulis aturan secara manual.
Di bagian-bagian berikut, kita akan mengurai:
Dalam artikel ini, terobosan berarti pergeseran yang membuat jaringan syaraf lebih berguna: mereka dilatih lebih andal, belajar fitur yang lebih baik, menggeneralisasi ke data baru dengan lebih akurat, atau diskalakan ke tugas yang lebih besar. Ini lebih tentang mengubah ide menjadi metode yang dapat diandalkan, bukan sekadar demo yang mencolok.
Jaringan syaraf tidak diciptakan untuk “mengganti pemrogram.” Janji awalnya lebih spesifik: membangun mesin yang bisa mempelajari representasi internal yang berguna dari masukan dunia nyata yang berantakan—gambar, suara, dan teks—tanpa insinyur menulis setiap aturan.
Sebuah foto hanyalah jutaan nilai piksel. Rekaman suara adalah aliran pengukuran tekanan. Tantangannya adalah mengubah angka mentah itu menjadi konsep yang dipahami orang: tepi, bentuk, fonem, kata, objek, niat.
Sebelum jaringan syaraf menjadi praktis, banyak sistem bergantung pada fitur yang dibuat tangan—pengukuran yang dirancang hati-hati seperti “detektor tepi” atau “deskriptor tekstur.” Itu bekerja di pengaturan sempit, tetapi sering gagal ketika pencahayaan berubah, aksen berbeda, atau lingkungan lebih kompleks.
Jaringan syaraf berusaha menyelesaikan ini dengan belajar fitur secara otomatis, lapis demi lapis, dari data. Jika sebuah sistem bisa menemukan blok bangunan menengah yang tepat sendiri, ia bisa menggeneralisasi lebih baik dan beradaptasi ke tugas baru dengan rekayasa manual yang lebih sedikit.
Idenya menarik, tetapi beberapa hambatan membuat jaringan syaraf tidak memberikan janji itu untuk waktu yang lama:
Bahkan ketika jaringan syaraf sedang tidak populer—terutama pada 1990-an dan awal 2000-an—peneliti seperti Geoffrey Hinton terus mendorong pembelajaran representasi. Dia mengusulkan ide-ide (sejak pertengahan 1980-an) dan mengulang ide lama (seperti model berbasis energi) sampai perangkat keras, data, dan metode mengejar. Ketekunan itu membantu menjaga tujuan inti tetap hidup: mesin yang belajar representasi yang tepat, bukan hanya jawaban akhir.
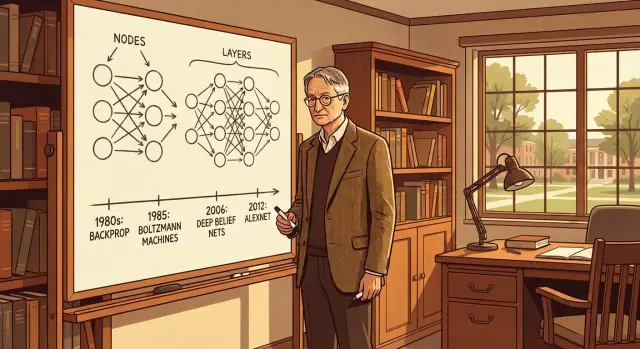
Backpropagation (sering dipersingkat menjadi “backprop”) adalah metode yang memungkinkan jaringan syaraf memperbaiki diri dengan belajar dari kesalahan. Jaringan membuat prediksi, kita mengukur seberapa salah prediksinya, lalu kita menyesuaikan “kenop” internal jaringan (bobotnya) agar nanti lebih baik.
Bayangkan sebuah jaringan mencoba memberi label foto sebagai “kucing” atau “anjing.” Ia menebak “kucing,” padahal jawaban yang benar “anjing.” Backprop mulai dari kesalahan akhir itu dan bekerja mundur melalui lapisan jaringan, menentukan seberapa besar setiap bobot berkontribusi pada jawaban yang salah.
Cara praktis memikirkannya:
Dorongan-dorongan itu biasanya dilakukan dengan algoritma pendamping bernama gradient descent, yang berarti “melangkah kecil menuruni lereng error.”
Sebelum backprop diadopsi luas, melatih jaringan berlapis banyak tidak andal dan lambat. Backprop membuat layak melatih jaringan lebih dalam karena menyediakan cara sistematis dan berulang untuk menyetel banyak lapisan sekaligus—daripada hanya mengubah lapisan akhir atau menebak penyesuaian.
Perubahan itu penting untuk terobosan berikutnya: begitu Anda bisa melatih beberapa lapisan secara efektif, jaringan bisa belajar fitur yang lebih kaya (tepi → bentuk → objek, misalnya).
Backprop bukanlah jaringan “berpikir” atau “memahami” seperti manusia. Ini umpan balik berbasis matematika: cara menyesuaikan parameter agar lebih cocok dengan contoh.
Juga, backprop bukan model tunggal—itu adalah metode pelatihan yang bisa digunakan pada banyak jenis jaringan syaraf.
Jika Anda ingin penjelasan lebih mendalam tentang struktur jaringan, lihat /blog/neural-networks-explained.
Mesin Boltzmann adalah salah satu langkah kunci Geoffrey Hinton menuju membuat jaringan syaraf mempelajari representasi internal yang berguna, bukan sekadar mengeluarkan jawaban.
Mesin Boltzmann adalah jaringan unit sederhana yang bisa menyala/mati (atau, pada versi modern, bernilai real). Alih-alih memprediksi keluaran langsung, mesin ini memberi energi pada keseluruhan konfigurasi unit. Energi rendah berarti “konfigurasi ini masuk akal.”
Analogi yang membantu adalah meja yang ditutupi lekukan dan lembah kecil. Jika Anda menjatuhkan sebuah kelereng, ia akan bergulir dan mendarat pada titik rendah. Mesin Boltzmann mencoba melakukan hal serupa: diberi informasi sebagian (seperti beberapa unit terlihat diisi oleh data), jaringan “bergoyang” unit internalnya sampai mencapai keadaan yang memiliki energi rendah—keadaan yang dipelajari sebagai yang mungkin.
Melatih mesin Boltzmann klasik melibatkan mengambil sampel berulang dari banyak kemungkinan keadaan untuk memperkirakan apa yang diyakini model versus apa yang ditunjukkan data. Pengambilan sampel itu bisa sangat lambat, terutama untuk jaringan besar.
Meski begitu, pendekatan ini berpengaruh karena:
Sebagian besar produk saat ini mengandalkan jaringan feedforward mendalam yang dilatih dengan backpropagation karena lebih cepat dan lebih mudah diskalakan.
Warisan mesin Boltzmann lebih bersifat konseptual daripada praktis: gagasan bahwa model yang baik mempelajari “keadaan yang disukai” dari dunia—dan bahwa pembelajaran bisa dilihat sebagai memindahkan massa probabilitas menuju lembah energi rendah itu.
Jaringan syaraf tidak sekadar semakin baik dalam menyesuaikan kurva—mereka semakin baik dalam menciptakan fitur yang tepat. Itulah yang dimaksud dengan “pembelajaran representasi”: alih-alih manusia membuat aturan apa yang dicari, model belajar deskripsi internal (representasi) yang membuat tugas menjadi lebih mudah.
Representasi adalah cara model merangkum masukan mentah. Itu belum berupa label seperti “kucing”; itu struktur berguna di jalan menuju label itu—pola yang menangkap apa yang cenderung penting. Lapisan awal mungkin merespons sinyal sederhana, sementara lapisan berikutnya menggabungkannya menjadi konsep yang lebih bermakna.
Sebelum pergeseran ini, banyak sistem bergantung pada fitur yang dirancang ahli: detektor tepi untuk gambar, ciri audio buat tangan untuk suara, atau statistik teks yang direkayasa. Fitur-fitur itu bekerja, tetapi sering kali rusak ketika kondisi berubah (pencahayaan, aksen, cara menulis).
Pembelajaran representasi memungkinkan model menyesuaikan fitur pada data itu sendiri, yang meningkatkan akurasi dan membuat sistem lebih tangguh terhadap masukan nyata yang berantakan.
Benang merahnya adalah hierarki: pola sederhana bergabung menjadi pola yang lebih kaya.
Dalam pengenalan gambar, sebuah jaringan mungkin pertama-tama belajar pola seperti tepi (perubahan terang-ke-gelap). Selanjutnya ia menggabungkan tepi menjadi sudut dan kurva, lalu menjadi bagian seperti roda atau mata, dan akhirnya menjadi objek utuh seperti “sepeda” atau “wajah.”
Terobosan Hinton membantu membuat pembangunan fitur berlapis ini menjadi praktis—dan itulah alasan besar kenapa pembelajaran mendalam mulai menang pada tugas yang penting bagi orang.
Deep belief networks (DBN) adalah batu loncatan penting menuju jaringan yang lebih dalam seperti yang kita kenal sekarang. Secara garis besar, DBN adalah tumpukan lapisan di mana setiap lapisan belajar merepresentasikan lapisan di bawahnya—mulai dari masukan mentah dan secara bertahap membangun “konsep” yang lebih abstrak.
Bayangkan mengajari sistem mengenali tulisan tangan. Alih-alih belajar semuanya sekaligus, DBN pertama-tama mempelajari pola sederhana (seperti tepi dan goresan), lalu kombinasi pola itu (lingkaran, sudut), dan akhirnya bentuk yang lebih tinggi yang menyerupai bagian angka.
Ide kuncinya adalah setiap lapisan mencoba memodelkan pola pada inputnya tanpa diberi jawaban yang benar. Setelah tumpukan itu mempelajari representasi yang semakin berguna, Anda bisa menyetel seluruh jaringan untuk tugas spesifik seperti klasifikasi.
Jaringan dalam sebelumnya sering kesulitan dilatih ketika diinisialisasi secara acak. Sinyal pelatihan bisa melemah atau tidak stabil saat lewat banyak lapisan, dan jaringan bisa berakhir pada pengaturan yang tidak membantu.
Pra-pelatihan lapis demi lapis memberi model sebuah “awal yang wajar.” Setiap lapisan mulai dengan pemahaman struktur data yang masuk akal, sehingga jaringan penuh tidak mencari secara buta.
Pra-pelatihan tidak menyelesaikan semua masalah, tetapi membuat kedalaman menjadi praktis pada saat data, tenaga komputasi, dan trik pelatihan lebih terbatas daripada sekarang.
DBN membantu menunjukkan bahwa mempelajari representasi yang baik di banyak lapisan bisa berhasil—dan bahwa kedalaman bukan hanya teori, melainkan jalan yang dapat digunakan.
Jaringan syaraf bisa janggalnya pandai “belajar untuk ujian” dengan cara terburuk: mereka menghafal data pelatihan alih-alih mempelajari pola yang mendasar. Masalah ini disebut overfitting, dan muncul ketika model tampak hebat pada latihan tetapi mengecewakan pada masukan baru di dunia nyata.
Bayangkan Anda mempersiapkan ujian mengemudi dengan menghafal rute tepat yang instruktur pakai terakhir kali—setiap belokan, setiap rambu, setiap lubang. Jika ujian memakai rute yang sama, Anda hebat. Tapi jika rute berubah, performa turun karena Anda tidak belajar keterampilan umum mengemudi; Anda belajar satu skrip khusus.
Itu overfitting: akurasi tinggi pada contoh yang familiar, hasil lebih lemah pada yang baru.
Dropout dipopulerkan oleh Geoffrey Hinton dan rekan sebagai trik pelatihan yang sederhana namun ampuh. Saat pelatihan, jaringan secara acak “mematikan” (drop out) beberapa unit pada setiap lintasan data.
Ini memaksa model berhenti bergantung pada jalur atau set fitur “favorit.” Sebaliknya, model harus menyebarkan informasi di banyak koneksi dan mempelajari pola yang tetap berlaku meskipun sebagian jaringan hilang.
Model mental yang membantu: seperti belajar sambil kadang-kadang kehilangan akses ke halaman-halaman acak dari catatan Anda—Anda didorong memahami konsep, bukan menghafal satu cara penulisan.
Manfaat utamanya adalah generalization yang lebih baik: jaringan menjadi lebih andal pada data yang belum pernah dilihat. Dalam praktiknya, dropout membantu melatih jaringan yang lebih besar tanpa mereka runtuh menjadi penghafal licik, dan menjadi alat standar di banyak pengaturan pembelajaran mendalam.
Sebelum AlexNet, “pengenalan gambar” bukan hanya demo keren—itu kompetisi yang dapat diukur. Tolok ukur seperti ImageNet menanyakan: diberi foto, bisakah sistem Anda menyebut apa isinya?
Permasalahannya adalah skala: jutaan gambar dan ribuan kategori. Ukuran itu penting karena memisahkan ide yang terdengar baik pada eksperimen kecil dari metode yang tahan saat dunia menjadi berantakan.
Kemajuan pada papan peringkat ini biasanya bertahap. Kemudian AlexNet (dibangun oleh Alex Krizhevsky, Ilya Sutskever, dan Geoffrey Hinton) muncul dan membuat hasil terasa bukan sekadar kenaikan bertahap tetapi langkah besar.
AlexNet memperlihatkan bahwa jaringan konvolusional dalam bisa mengalahkan pipeline visi tradisional terbaik ketika tiga bahan digabungkan:
Ini bukan hanya “model lebih besar.” Ini resep praktis untuk melatih jaringan dalam secara efektif pada tugas dunia nyata.
Bayangkan menggeser sebuah “jendela” kecil di atas foto—seperti memindahkan perangko melintasi gambar. Di dalam jendela itu, jaringan mencari pola sederhana: tepi, sudut, garis. Pemeriksa pola yang sama dipakai di seluruh gambar, jadi ia bisa menemukan “bentuk-mirip-tepi” dimanapun berada. Tumpuk cukup banyak lapis ini dan Anda mendapatkan hierarki: tepi menjadi tekstur, tekstur menjadi bagian, bagian menjadi objek.
AlexNet membuat pembelajaran mendalam terasa andal dan layak diinvestasikan. Jika jaringan dalam bisa mendominasi tolok ukur gambar yang sulit, kemungkinan besar mereka dapat meningkatkan produk juga—pencarian, penandaan foto, fitur kamera, alat aksesibilitas, dan lain-lain.
Itu membantu mengubah jaringan syaraf dari “riset menjanjikan” menjadi arah yang jelas bagi tim yang membangun sistem nyata.
Pembelajaran mendalam tidak “datang dalam semalam.” Ia mulai terlihat dramatis ketika beberapa bahan akhirnya bertemu—setelah bertahun-tahun kerja sebelumnya menunjukkan ide-ide itu menjanjikan tetapi sulit diskalakan.
Lebih banyak data. Web, smartphone, dan dataset berlabel besar (seperti ImageNet) membuat jaringan syaraf dapat belajar dari jutaan contoh bukan ribuan. Dengan dataset kecil, model besar cenderung menghafal.
Lebih banyak komputasi (terutama GPU). Melatih jaringan dalam berarti melakukan matematika yang sama miliaran kali. GPU membuatnya terjangkau dan cukup cepat untuk beriterasi. Yang dulu butuh minggu kini bisa selesai dalam hari—atau jam—sehingga peneliti bisa mencoba lebih banyak arsitektur dan hyperparameter.
Trik pelatihan yang lebih baik. Perbaikan praktis mengurangi ketidakpastian apakah model akan melatih atau tidak:
Tidak ada yang mengubah ide inti jaringan syaraf; mereka meningkatkan keandalan dalam membuatnya bekerja.
Begitu komputasi dan data mencapai ambang tertentu, perbaikan mulai saling memperkuat. Hasil yang lebih baik menarik lebih banyak investasi, yang mendanai dataset dan perangkat keras lebih besar, yang memungkinkan hasil lebih baik lagi. Dari luar tampak seperti loncatan; dari dalam, itu penggandaan bertahap.
Skalasi membawa biaya nyata: penggunaan energi lebih besar, pelatihan yang lebih mahal, dan usaha lebih untuk menyebarkan model secara efisien. Ia juga memperbesar jurang antara apa yang bisa diprototipe tim kecil dan apa yang hanya bisa dilatih oleh laboratorium dengan pendanaan besar.
Ide-ide kunci Hinton—mempelajari representasi berguna dari data, melatih jaringan dalam dengan andal, dan mencegah overfitting—bukan “fitur” tunggal yang bisa Anda tunjuk di aplikasi. Mereka adalah alasan banyak fitur sehari-hari terasa lebih cepat, lebih akurat, dan kurang menyebalkan.
Sistem pencarian modern tidak hanya mencocokkan kata kunci. Mereka belajar representasi dari kueri dan konten sehingga “best noise-canceling headphones” bisa menampilkan halaman yang tidak mengulang frasa persis. Pembelajaran representasi yang sama membantu feed rekomendasi memahami bahwa dua item “mirip” walaupun deskripsinya berbeda.
Penerjemahan mesin meningkat drastis begitu model lebih baik dalam belajar pola berlapis (dari karakter ke kata ke makna). Meskipun tipe model dasar telah berkembang, resep pelatihan—dataset besar, optimisasi hati-hati, regularisasi—masih membentuk bagaimana tim membangun fitur bahasa andal.
Asisten suara dan diktasi bergantung pada jaringan syaraf yang memetakan audio yang berantakan menjadi teks yang bersih. Backpropagation adalah tenaga kerja yang menyetel model-model ini, sementara teknik seperti dropout membantu mencegah model menghafal keanehan pembicara atau mikrofon tertentu.
Aplikasi foto bisa mengenali wajah, mengelompokkan adegan serupa, dan membiarkan Anda mencari “pantai” tanpa penandaan manual. Itu pembelajaran representasi dalam praktik: sistem belajar fitur visual (tepi → tekstur → objek) yang membuat penandaan dan pengambilan bekerja di skala.
Bahkan jika Anda tidak melatih model dari awal, prinsip-prinsip ini muncul dalam kerja produk sehari-hari: mulai dengan representasi yang kuat (sering lewat model pra-latih), stabilkan pelatihan dan evaluasi, dan gunakan regularisasi ketika sistem mulai “menghafal tolok ukur.”
Ini juga alasan mengapa alat “vibe-coding” modern bisa terasa sangat kapabel. Platform seperti Koder.ai duduk di atas LLM generasi sekarang dan alur agen untuk membantu tim mengubah spesifikasi berbahasa biasa menjadi aplikasi web, backend, atau mobile—sering lebih cepat daripada jalur tradisional—sementara tetap memungkinkan ekspor kode sumber dan penerapan seperti tim engineering normal.
Jika Anda ingin intuisi pelatihan tingkat tinggi, lihat /blog/backpropagation-explained.
Terobosan besar sering disederhanakan menjadi cerita singkat. Itu membuatnya lebih mudah diingat—tetapi juga menciptakan mitos yang menyembunyikan apa yang sebenarnya terjadi, dan apa yang masih penting hari ini.
Hinton adalah figur sentral, tetapi jaringan syaraf modern adalah hasil kerja puluhan tahun dari banyak kelompok: peneliti yang mengembangkan metode optimisasi, orang yang membuat dataset, insinyur yang membuat GPU praktis untuk pelatihan, dan tim yang membuktikan ide pada skala. Bahkan dalam karya Hinton, murid dan kolaboratornya memainkan peran besar. Cerita sebenarnya adalah rantai kontribusi yang akhirnya selaras.
Jaringan syaraf telah diteliti sejak pertengahan abad ke-20, dengan periode kegembiraan dan kekecewaan. Yang berubah bukan keberadaan ide, melainkan kemampuan melatih model lebih besar dengan andal dan menunjukkan kemenangan nyata pada masalah riil. Era “deep learning” lebih merupakan kebangkitan daripada penemuan tiba-tiba.
Model lebih dalam bisa membantu, tetapi bukan sihir. Waktu pelatihan, biaya, kualitas data, dan hasil yang berkurang adalah batasan nyata. Kadang model lebih kecil mengungguli yang besar karena lebih mudah disetel, kurang sensitif terhadap noise, atau lebih cocok untuk tugas.
Backpropagation adalah cara praktis menyesuaikan parameter model menggunakan umpan balik berlabel. Manusia belajar dari jauh lebih sedikit contoh, memakai pengetahuan awal yang kaya, dan tidak mengandalkan sinyal kesalahan eksplisit seperti itu. Jaringan syaraf mungkin terinspirasi dari biologi tapi bukan replika otak manusia.
Kisah Hinton bukan sekadar daftar penemuan. Itu pola: pegang gagasan pembelajaran sederhana, uji tanpa henti, dan tingkatkan bahan pendukung (data, komputasi, trik pelatihan) sampai bekerja pada skala.
Kebiasaan yang paling dapat ditransfer bersifat praktis:
Mudah tergoda mengambil pelajaran tajuk utama sebagai “model lebih besar selalu menang.” Itu tidak lengkap.
Mengejar ukuran tanpa tujuan yang jelas sering mengarah pada:
Default yang lebih baik: mulai kecil, buktikan nilai, lalu skala—dan hanya skala bagian yang jelas membatasi performa.
Jika Anda ingin mengubah pelajaran ini menjadi praktik sehari-hari, bacaan lanjutan yang baik:
Dari aturan belajar dasar backprop, ke representasi yang menangkap makna, ke trik praktis seperti dropout, ke demo terobosan seperti AlexNet—busurnya konsisten: pelajari fitur yang berguna dari data, buat pelatihan stabil, dan validasi kemajuan dengan hasil nyata.
Itulah playbook yang layak dijaga.
Geoffrey Hinton penting karena dia berkali-kali membantu membuat jaringan syaraf bekerja secara praktis ketika banyak peneliti menganggapnya jalan buntu.
Alih-alih “menemukan AI,” dampaknya datang dari dorongan pada pembelajaran representasi, pengembangan metode pelatihan, dan membantu membentuk budaya riset yang menekankan belajar fitur dari data alih-alih menulis aturan secara manual.
Di sini, “terobosan” berarti jaringan syaraf menjadi lebih dapat diandalkan dan berguna: melatih lebih stabil, mempelajari fitur internal yang lebih baik, menggeneralisasi lebih baik ke data baru, atau dapat diskalakan ke tugas yang lebih sulit.
Ini bukan soal demo yang mencolok, melainkan mengubah sebuah gagasan menjadi metode berulang yang dapat dipercaya tim.
Jaringan syaraf bertujuan mengubah masukan mentah yang berantakan (piksel, gelombang audio, token teks) menjadi representasi yang berguna—fitur internal yang menangkap apa yang penting.
Alih-alih insinyur merancang setiap fitur, model belajar lapisan fitur dari contoh, yang cenderung lebih tahan ketika kondisi berubah (pencahayaan, aksen, pilihan kata).
Backpropagation adalah metode pelatihan yang memperbaiki jaringan dengan belajar dari kesalahan:
Metode ini biasanya berjalan dengan algoritma seperti gradient descent, yang mengambil langkah-langkah kecil untuk menurunkan error seiring waktu.
Backprop membuat memungkinkan penyetelan banyak lapisan sekaligus dengan cara sistematis.
Itu penting karena jaringan yang lebih dalam bisa membangun hirarki fitur (mis. tepi → bentuk → objek). Tanpa cara andal untuk melatih banyak lapisan, kedalaman sering kali gagal memberikan peningkatan nyata.
Mesin Boltzmann bekerja dengan memberi energi (skor) pada konfigurasi unit; energi rendah berarti “konfigurasi ini masuk akal.”
Mereka berpengaruh karena:
Namun dalam produk saat ini, versi klasiknya kurang umum karena pelatihannya lambat jika diskala besar.
Pembelajaran representasi berarti model belajar fitur internalnya sendiri yang memudahkan tugas, alih-alih mengandalkan fitur yang dirancang manusia.
Dalam praktiknya, ini meningkatkan ketahanan: fitur yang dipelajari beradaptasi pada variasi data nyata (noise, kamera berbeda, pembicara berbeda) lebih baik daripada pipeline fitur yang rapuh dan dibuat tangan.
Deep belief networks (DBN) membantu membuat kedalaman praktis dengan melakukan pra-pelatihan lapis demi lapis.
Setiap lapis pertama-tama mempelajari struktur pada inputnya (sering tanpa label), memberi jaringan keseluruhan sebuah “awal hangat.” Setelah itu, seluruh tumpukan dapat diselaraskan (fine-tune) untuk tugas tertentu seperti klasifikasi.
Dropout melawan overfitting dengan secara acak “mematikan” beberapa unit selama pelatihan.
Itu mencegah jaringan bergantung pada jalur tunggal dan mendorongnya mempelajari fitur yang masih berfungsi meskipun sebagian model hilang—seringkali meningkatkan generalisasi pada data nyata yang belum pernah dilihat.
AlexNet menunjukkan resep praktis yang dapat diskalakan: jaringan konvolusional dalam + GPU + banyak data berlabel (ImageNet).
Itu bukan sekadar “model lebih besar”—AlexNet membuktikan bahwa pembelajaran mendalam dapat secara konsisten mengalahkan pipeline visi tradisional pada tolok ukur publik yang sulit, dan itu memicu investasi industri yang luas.