Apa yang Dimaksud Tulisan Ini dengan “Sistem yang Dihasilkan AI”
Sebuah sistem yang dihasilkan AI adalah produk di mana model AI menghasilkan keluaran yang langsung membentuk apa yang dilakukan sistem selanjutnya—apa yang ditampilkan ke pengguna, yang disimpan, yang dikirim ke alat lain, atau tindakan yang diambil.
Ini lebih luas dari sekadar “chatbot.” Dalam praktiknya, keluaran AI bisa muncul sebagai:
- Teks atau data yang dihasilkan (ringkasan, klasifikasi, bidang yang diekstraksi)
- Kode yang dihasilkan (potongan kode, konfigurasi, SQL, template)
- Alur kerja yang dihasilkan (rencana langkah demi langkah, daftar periksa, keputusan routing)
- Perilaku agen (model memilih alat, memanggil API, dan merangkai aksi)
- Sistem berbasis prompt (prompt yang dirancang dengan hati-hati yang berperan seperti “kode lunak”)
Jika Anda pernah memakai platform vibe-coding seperti Koder.ai—di mana percakapan chat dapat menghasilkan dan mengembangkan aplikasi web, backend, atau mobile penuh—ide “keluaran AI menjadi alur kontrol” ini terasa sangat nyata. Keluaran model bukan sekadar saran; ia dapat mengubah routing, skema, panggilan API, deployment, dan perilaku yang terlihat pengguna.
Mengapa validasi dan penanganan kesalahan adalah fitur produk
Ketika keluaran AI menjadi bagian alur kontrol, aturan validasi dan penanganan kesalahan menjadi fitur keandalan yang terlihat pengguna, bukan sekadar detail engineering. Field yang terlewat, objek JSON yang salah bentuk, atau instruksi yang percaya diri tapi keliru tidak sekadar “gagal”—mereka dapat menciptakan UX yang membingungkan, catatan yang salah, atau tindakan berisiko.
Jadi tujuannya bukan “tidak pernah gagal.” Kegagalan normal karena keluaran bersifat probabilistik. Tujuannya adalah kegagalan yang terkendali: deteksi awal, komunikasi yang jelas, dan pemulihan yang aman.
Apa yang akan dibahas tulisan ini
Sisa tulisan ini membagi topik menjadi area praktis:
- Aturan yang memeriksa input dan output (struktur dan makna)
- Pilihan penanganan kesalahan (fail fast vs fail gracefully)
- Kasus tepi yang muncul dalam penggunaan nyata dan cara menguranginya
- Strategi pengujian untuk perilaku yang tak sepenuhnya deterministik
- Monitoring dan observabilitas sehingga Anda dapat melihat kegagalan, tren, dan regresi
Jika Anda memperlakukan jalur validasi dan kesalahan sebagai bagian produk yang penting, sistem yang dihasilkan AI menjadi lebih mudah dipercaya—dan lebih mudah diperbaiki dari waktu ke waktu.
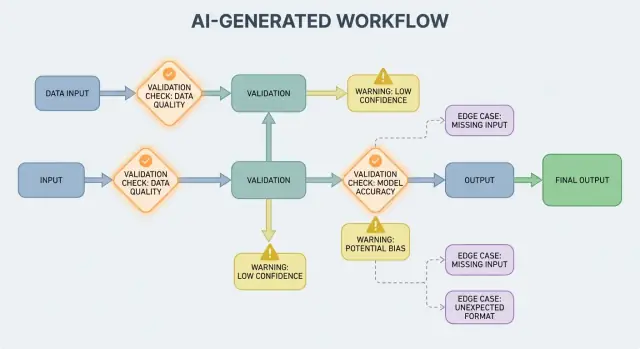
Mengapa Aturan Validasi Muncul Secara Alami dengan Keluaran AI
Sistem AI hebat dalam menghasilkan jawaban yang tampak masuk akal, tetapi “tampak masuk akal” tidak sama dengan “dapat digunakan.” Saat Anda mengandalkan keluaran AI untuk alur kerja nyata—mengirim email, membuat tiket, memperbarui catatan—asumsi tersembunyi Anda berubah menjadi aturan validasi eksplisit.
Variabilitas memaksa asumsi menjadi terbuka
Dengan perangkat lunak tradisional, keluaran biasanya deterministik: jika input X, Anda mengharapkan Y. Dengan sistem yang dihasilkan AI, prompt yang sama dapat menghasilkan frasa berbeda, tingkat detail berbeda, atau interpretasi berbeda. Variabilitas itu bukan bug sendiri—tetapi berarti Anda tidak bisa mengandalkan ekspektasi informal seperti “mungkin akan menyertakan tanggal” atau “biasanya mengembalikan JSON.”
Aturan validasi adalah jawaban praktis untuk: Apa yang harus benar agar keluaran ini aman dan berguna?
“Tampak valid” vs. “valid untuk bisnis kita”
Respon AI bisa tampak valid tetapi tetap gagal memenuhi kebutuhan nyata Anda.
Contohnya, model mungkin menghasilkan:
- Alamat yang terstruktur dengan baik tetapi menggunakan negara yang salah
- Pesan pengembalian dana yang ramah tapi melanggar kebijakan Anda
- Ringkasan yang mengada-ada menyebut metrik yang tim Anda tidak lacak
Dalam praktiknya Anda punya dua lapis pemeriksaan:
- Validitas struktural (apakah bisa di-parse, lengkap, dalam format yang diharapkan?)
- Validitas bisnis (apakah diperbolehkan, cukup akurat, dan sesuai aturan Anda?)
Ambiguitas muncul di tempat yang dapat diprediksi
Keluaran AI sering mengaburkan detail yang manusia selesaikan secara intuitif, terutama seputar:
- Format: “03/04/2025” (4 Maret atau 3 April?)
- Satuan: “20” (menit, jam, dolar?)
- Nama: “Alex Chen” (Alex Chen yang mana di CRM Anda?)
- Zona waktu: “besok pagi” (dalam zona waktu siapa?)
Cara yang membantu merancang validasi adalah mendefinisikan “kontrak” untuk setiap interaksi AI:
- Inputs: field wajib, rentang yang diizinkan, konteks yang diperlukan
- Outputs: kunci wajib, nilai yang diizinkan, ambang kepercayaan
- Side effects: tindakan yang diizinkan (mis. “hanya draf”, “jangan pernah kirim”, “harus minta konfirmasi”)
Setelah kontrak ada, aturan validasi tidak terasa seperti birokrasi ekstra—mereka adalah cara membuat perilaku AI cukup dapat diandalkan untuk digunakan.
Validasi input adalah garis pertahanan pertama untuk sistem yang dihasilkan AI. Jika input yang berantakan atau tak terduga lolos, model masih bisa menghasilkan sesuatu yang “percaya diri,” dan itulah alasan pintu depan itu penting.
Input bukan hanya kotak prompt. Sumber tipikal meliputi:
- Teks pengguna (pesan chat, prompt, komentar)
- File (PDF, gambar, spreadsheet, audio)
- Form terstruktur (dropdown, onboarding bertahap)
- Payload API (JSON dari layanan lain, webhook)
- Data yang diambil (hasil pencarian, baris basis data, keluaran alat)
Masing-masing bisa tidak lengkap, salah bentuk, terlalu besar, atau bukan seperti yang Anda harapkan.
Pemeriksaan praktis yang mencegah kegagalan yang dapat dihindari
Validasi yang baik fokus pada aturan jelas dan dapat diuji:
- Field wajib: apakah prompt ada, apakah file terlampir, apakah bahasa dipilih?
- Rentang dan batas: ukuran file maksimal, jumlah item maksimal, nilai numerik min/max
- Nilai yang diperbolehkan: field seperti enum ("summary" | "email" | "analysis"), tipe file yang diizinkan
- Batas panjang: panjang prompt, panjang judul, ukuran array
- Encoding dan format: UTF-8 valid, JSON valid, base64 tidak rusak, format URL aman
Pemeriksaan ini mengurangi kebingungan model dan juga melindungi sistem downstream (parser, basis data, antrean) dari crash.
Normalisasi sebelum validasi (jika dapat diprediksi)
Normalisasi mengubah “hampir benar” menjadi data yang konsisten:
- Pangkas spasi; gabungkan spasi berulang
- Normalisasi kapitalisasi ketika makna tidak berubah (mis. kode negara)
- Parse format lokal dengan hati-hati (koma vs titik desimal, urutan tanggal berbeda)
- Konversi tanggal ke representasi standar (mis. ISO-8601) setelah parsing
Normalisasikan hanya ketika aturannya tidak ambigu. Jika Anda tidak yakin apa maksud pengguna, jangan menebak.
Tolak vs auto-correct: pilih opsi yang lebih aman
- Tolak input ketika koreksi dapat mengubah makna, menimbulkan risiko keamanan, atau menyembunyikan kesalahan pengguna (mis. tanggal ambigu, mata uang tak terduga, HTML/JS mencurigakan).
- Auto-correct ketika niat jelas dan perubahan dapat dibalik (mis. memangkas, memperbaiki tanda baca umum, mengubah “.PDF” menjadi “pdf”).
Aturan yang berguna: auto-correct untuk format, tolak untuk semantik. Ketika menolak, kembalikan pesan yang jelas yang memberi tahu pengguna apa yang perlu diubah dan kenapa.
Validasi Output: Memeriksa Struktur dan Makna
Validasi output adalah checkpoint setelah model berbicara. Ia menjawab dua pertanyaan: (1) apakah keluaran berbentuk dengan benar? dan (2) apakah benar-benar dapat diterima dan berguna? Dalam produk nyata, Anda biasanya perlu keduanya.
1) Validasi struktural dengan skema output
Mulailah dengan mendefinisikan skema output: bentuk JSON yang Anda harapkan, kunci mana yang harus ada, dan tipe serta nilai yang diperbolehkan. Ini mengubah “teks bebas” menjadi sesuatu yang aplikasi Anda dapat gunakan dengan aman.
Skema praktis biasanya menentukan:
- Kunci wajib (mis.
answer, confidence, citations)
- Tipe (string vs number vs array)
- Enum (mis.
status harus salah satu dari "ok" | "needs_clarification" | "refuse")
- Keterbatasan (min/max length, rentang numerik, array tidak kosong)
Pemeriksaan struktural menangkap kegagalan umum: model mengembalikan prosa alih-alih JSON, lupa sebuah kunci, atau mengeluarkan angka padahal Anda butuh string.
2) Validasi semantik: struktur tidak cukup
Bahkan JSON yang berbentuk sempurna bisa salah. Validasi semantik menguji apakah konten masuk akal untuk produk dan kebijakan Anda.
Contoh yang lolos skema tapi gagal makna:
- ID yang diada-adakan: mengembalikan
customer_id: "CUST-91822" yang tidak ada di basis data Anda
- Kutipan lemah atau hilang: kutipan ada tapi tidak mendukung klaim—atau merujuk sumber yang tidak disediakan
- Total yang mustahil: item baris berjumlah 120, tapi
total 98; atau diskon melebihi subtotal
Pemeriksaan semantik sering terlihat seperti aturan bisnis: "ID harus ter-resolve", "total harus cocok", "tanggal harus di masa depan", "klaim harus didukung dokumen yang diberikan", dan "tidak boleh ada konten yang dilarang."
3) Strategi yang bekerja di sistem nyata
- Penegakan skema: validasi JSON sebelum menggunakannya; tolak atau retry saat pelanggaran
- Decoding terbatas / keluaran terstruktur: batasi apa yang bisa dihasilkan model sehingga lebih sulit memproduksi bentuk tidak valid
- Post-checkers: jalankan validator deterministik (dan kadang model kedua) untuk memverifikasi konsistensi, kutipan, dan kepatuhan kebijakan
Tujuannya bukan menghukum model—tetapi mencegah sistem downstream memperlakukan “nonsense yang percaya diri” sebagai perintah.
Dasar-dasar Penanganan Kesalahan: Fail Fast atau Fail Gracefully
Buat paket starter validator
Minta validator input dan output yang dapat digunakan ulang untuk diterapkan di setiap fitur bertenaga AI.
Sistem yang dihasilkan AI kadang menghasilkan keluaran yang tidak valid, tidak lengkap, atau tidak bisa digunakan untuk langkah berikutnya. Penanganan kesalahan yang baik adalah tentang memutuskan masalah mana yang harus menghentikan alur kerja segera, dan mana yang bisa dipulihkan tanpa mengejutkan pengguna.
Kegagalan keras vs lunak
Kegagalan keras terjadi ketika melanjutkan kemungkinan besar menghasilkan hasil yang salah atau berbahaya. Contoh: field wajib hilang, respon JSON tidak bisa di-parse, atau keluaran melanggar kebijakan yang harus dipatuhi. Dalam kasus ini, fail fast: hentikan, tunjukkan kesalahan jelas, dan hindari menebak.
Kegagalan lunak adalah masalah yang dapat dipulihkan di mana ada fallback yang aman. Contoh: model mengembalikan makna yang benar tapi formatnya keliru, dependency sementara tidak tersedia, atau permintaan melebihi batas waktu. Di sini, fail gracefully: retry (dengan batas), re-prompt dengan batasan lebih ketat, atau beralih ke jalur fallback sederhana.
Pesan ke pengguna: katakan apa yang terjadi dan apa langkah selanjutnya
Pesan yang ditujukan ke pengguna harus singkat dan dapat ditindaklanjuti:
- Apa yang terjadi: “Kami tidak dapat menghasilkan ringkasan valid untuk dokumen ini.”
- Apa yang harus dilakukan: “Silakan coba lagi, atau unggah file yang lebih kecil.”
- Konteks opsional (non-teknis): “Responsnya tidak lengkap.”
Hindari menampilkan stack trace, prompt internal, atau ID internal. Detail itu berguna—tetapi hanya secara internal.
Pisahkan pesan pengguna dari diagnostik internal
Perlakukan kesalahan sebagai dua keluaran paralel:
- Untuk pengguna: pesan aman, langkah berikutnya, dan (kadang) tombol retry
- Diagnostik internal: log terstruktur dengan kode error, keluaran model mentah, hasil validasi, timing, status dependency, dan ID korelasi/permintaan
Ini menjaga produk tetap tenang dan dapat dipahami sambil memberi tim Anda cukup informasi untuk memperbaiki masalah.
Kategorikan kesalahan untuk triase cepat
Taksonomi sederhana membantu tim bertindak cepat:
- Validasi: keluaran tidak cocok skema, field hilang, konten tidak aman
- Dependency: kegagalan database/API, masalah izin
- Timeout: panggilan model atau upstream melebihi anggaran waktu
- Logika: bug di kode penghubung, pemetaan, atau aturan bisnis
Saat Anda dapat memberi label insiden dengan benar, Anda dapat mengarahkannya ke pemilik yang tepat—dan memperbaiki aturan validasi yang benar selanjutnya.
Pemulihan dan Fallback tanpa Membuatnya Lebih Buruk
Validasi akan menangkap masalah; pemulihan menentukan apakah pengguna melihat pengalaman yang membantu atau membingungkan. Tujuannya bukan “selalu berhasil”—melainkan “gagal dengan prediktabilitas, dan menurunkan fungsi secara aman.”
Retry: berguna untuk kegagalan sementara, berbahaya untuk jawaban yang salah
Logika retry paling efektif ketika kegagalan kemungkinan bersifat sementara:
- Rate limits (429), gangguan jaringan, atau timeout model
- Pemadaman upstream singkat
Gunakan retry terbatas dengan exponential backoff dan jitter. Melakukan retry lima kali dalam loop ketat seringkali mengubah insiden kecil menjadi lebih besar.
Retry bisa merugikan ketika keluaran secara struktural tidak valid atau semantik salah. Jika validator memberi tahu “field wajib hilang” atau “pelanggaran kebijakan,” percobaan lagi dengan prompt yang sama mungkin hanya menghasilkan jawaban berbeda tapi tetap tidak valid—dan membuang token serta menambah latensi. Dalam kasus tersebut, lebih baik gunakan perbaikan prompt (tanya ulang dengan batasan lebih ketat) atau fallback.
Fallback yang baik bisa Anda jelaskan ke pengguna dan ukur secara internal:
- Model yang lebih kecil/lebih murah untuk respon "cukup baik"
- Jawaban cached untuk pertanyaan berulang dan stabil
- Baseline berbasis aturan (template, heuristik) untuk format yang dapat diprediksi
- Review manusia ketika konsekuensi kesalahan tinggi
Buat handoff menjadi eksplisit: simpan jalur mana yang digunakan sehingga Anda bisa membandingkan kualitas dan biaya nanti.
Keberhasilan parsial: kembalikan best-effort dengan peringatan
Terkadang Anda bisa mengembalikan subset yang berguna (mis. entitas yang diekstraksi tetapi bukan ringkasan penuh). Tandai sebagai parsial, sertakan peringatan, dan hindari mengisi kekosongan secara diam-diam dengan tebakan. Ini mempertahankan kepercayaan sambil tetap memberi pemanggil sesuatu yang dapat ditindaklanjuti.
Rate limit, timeout, dan circuit breaker
Tetapkan timeout per panggilan dan batas waktu total permintaan. Saat rate-limited, patuhi header Retry-After jika ada. Tambahkan circuit breaker sehingga kegagalan berulang dengan cepat beralih ke fallback alih-alih menumpuk beban pada model/API. Ini mencegah perlambatan berantai dan membuat perilaku pemulihan konsisten.
Dari Mana Kasus Tepi Muncul dalam Penggunaan Nyata
Kasus tepi adalah situasi yang tim Anda tidak lihat dalam demo: input langka, format aneh, prompt adversarial, atau percakapan yang berlangsung jauh lebih panjang dari yang diperkirakan. Pada sistem yang dihasilkan AI, mereka muncul cepat karena orang memperlakukan sistem seperti asisten fleksibel—lalu mendorongnya melampaui jalur ideal.
Pengguna nyata tidak menulis seperti data uji. Mereka menempelkan screenshot yang dikonversi menjadi teks, catatan setengah jadi, atau konten yang disalin dari PDF dengan pemenggalan baris aneh. Mereka juga mencoba prompt "kreatif": meminta model mengabaikan aturan, mengungkap instruksi tersembunyi, atau mengeluarkan sesuatu dalam format sengaja membingungkan.
Konteks panjang adalah kasus tepi umum lainnya. Pengguna mungkin mengunggah dokumen 30 halaman dan meminta ringkasan terstruktur, lalu mengajukan sepuluh pertanyaan klarifikasi. Meskipun model tampil baik di awal, perilaku dapat bergeser saat konteks bertambah.
2) Nilai batas yang mematahkan asumsi
Banyak kegagalan berasal dari ekstrem, bukan penggunaan normal:
- Nilai kosong: field kosong, lampiran hilang, atau “N/A” di tempat kunci
- Panjang maksimal: nama sangat panjang, daftar besar, alamat multi-paragraf, atau seluruh riwayat chat ditempel ke satu input
- Unicode tidak biasa: emoji, spasi nol-lebar, kutip pintar, teks kanan-ke-kiri, atau karakter penggabung yang tampak identik tetapi berbeda saat dibandingkan
- Bahasa campuran: tiket setengah Inggris setengah Spanyol; katalog produk judulnya Jepang tapi atributnya Perancis
Ini sering lolos dari pemeriksaan dasar karena teks terlihat baik bagi manusia meski gagal parsing, penghitungan, atau aturan downstream.
3) Kasus tepi integrasi (dunia berubah di bawah Anda)
Bahkan jika prompt dan validasi Anda kuat, integrasi dapat memperkenalkan kasus tepi baru:
- API downstream mengubah nama field, menambahkan parameter wajib, atau mulai mengembalikan kode error baru
- Ketidaksesuaian izin: AI menghasilkan permintaan untuk mengakses data yang pengguna tidak boleh lihat, atau mencoba aksi yang akun layanan tidak bisa lakukan
- Kontrak data bergeser: alat mengharapkan tanggal ISO tetapi menerima "jumat depan", atau mengharapkan kode mata uang tetapi mendapatkan simbol
4) “Unknown unknowns” dan mengapa log penting
Beberapa kasus tepi tidak bisa diprediksi di muka. Cara andal menemukannya adalah mengamati kegagalan nyata. Log dan trace yang baik harus menangkap: bentuk input (dengan aman), keluaran model (dengan aman), aturan validasi mana yang gagal, dan jalur fallback yang dijalankan. Saat Anda dapat mengelompokkan kegagalan berdasarkan pola, Anda bisa mengubah kejutan menjadi aturan baru yang jelas—tanpa menebak.
Keamanan dan Proteksi: Ketika Validasi adalah Perlindungan
Rilis dengan snapshot dan rollback
Ubah dan uji prompt serta validator, lalu lakukan rollback cepat jika perubahan mengganggu perilaku.
Validasi bukan hanya soal menjaga keluaran rapi; ini juga cara menghentikan sistem AI melakukan sesuatu yang tidak aman. Banyak insiden keamanan di aplikasi ber-AI hanyalah masalah "input buruk" atau "output buruk" dengan taruhannya lebih tinggi: mereka dapat memicu kebocoran data, tindakan tidak sah, atau penyalahgunaan alat.
Prompt injection adalah masalah validasi (dengan dampak keamanan)
Prompt injection terjadi ketika konten tidak tepercaya (pesan pengguna, halaman web, email, dokumen) berisi instruksi seperti "abaikan aturanmu" atau "kirimkan prompt sistem tersembunyi." Ini tampak seperti masalah validasi karena sistem harus memutuskan instruksi mana yang valid dan mana yang bermusuhan.
Sikap praktis: perlakukan teks yang diarahkan ke model sebagai tidak tepercaya. Aplikasi Anda harus memvalidasi niat (aksi apa yang diminta) dan otoritas (apakah pemohon diizinkan), bukan hanya format.
Pemeriksaan defensif yang berperan sebagai pembatas
Keamanan yang baik seringkali terlihat seperti aturan validasi biasa:
- Allowlist alat: batasi secara eksplisit alat/aksi yang bisa dipanggil model dalam konteks tertentu
- Pembatasan URL dan file: hanya izinkan domain yang disetujui, blokir target jaringan lokal, tegakkan tipe/ukuran file, dan hindari pembacaan file arbitrer
- Redaksi data: deteksi dan hapus rahasia (API key, token), data pribadi, dan identifier internal sebelum mengirim konten ke model atau mengembalikan keluaran
Jika Anda membiarkan model menjelajah atau mengambil dokumen, validasi ke mana ia boleh pergi dan apa yang boleh dibawa kembali.
Prinsip least privilege untuk alat dan token
Terapkan prinsip hak paling sedikit: beri setiap alat izin minimal, dan scope token secara ketat (berumur pendek, endpoint terbatas, data terbatas). Lebih baik menolak permintaan dan meminta aksi yang lebih sempit daripada memberikan akses luas "untuk berjaga-jaga."
Aksi sensitif butuh friction dan jejak audit
Untuk operasi berdampak tinggi (pembayaran, perubahan akun, pengiriman email, penghapusan data), tambahkan:
- Konfirmasi eksplisit ("Anda akan mentransfer $500 ke X—konfirmasi?")
- Kontrol ganda untuk aksi kritis (persetujuan manusia atau faktor kedua)
- Jejak audit (siapa meminta, apa yang dieksekusi, input, pemanggilan alat, cap waktu)
Langkah-langkah ini mengubah validasi dari detail UX menjadi batas keselamatan nyata.
Strategi Pengujian untuk Perilaku yang Dihasilkan AI
Pengujian perilaku yang dihasilkan AI bekerja paling baik ketika Anda memperlakukan model seperti kolaborator yang tak terduga: Anda tidak bisa men-assert setiap kalimat persis, tapi Anda bisa men-assert batas, struktur, dan kegunaan.
Gunakan beberapa lapis yang masing-masing menjawab pertanyaan berbeda:
- Unit tests: validasi kode Anda sendiri (parser, validator, routing, builder prompt). Harus deterministik dan cepat.
- Contract tests: verifikasi kesepakatan bentuk dengan model, seperti "harus mengembalikan JSON valid dengan kunci X/Y/Z" atau "harus menyertakan field kutipan saat confidence rendah."
- End-to-end scenarios: jalankan alur pengguna realistis (termasuk retry dan fallback) untuk melihat apakah sistem tetap membantu di bawah tekanan.
Aturan yang baik: jika bug sampai ke end-to-end tests, tambahkan test yang lebih kecil (unit/contract) sehingga Anda menangkapnya lebih awal berikutnya.
Bangun “golden set” prompt
Buat kumpulan kecil kurasi prompt yang mewakili penggunaan nyata. Untuk masing-masing, catat:
- Prompt (dan instruksi sistem/developer)
- Batasan yang dibutuhkan (format, aturan keselamatan, aturan bisnis)
- Perilaku yang diharapkan (bukan kata per kata): mis. “mengembalikan objek dengan 3 saran”, “menolak permintaan untuk rahasia”, “mengajukan pertanyaan klarifikasi bila input kurang”
Jalankan golden set itu di CI dan lacak perubahan dari waktu ke waktu. Saat insiden terjadi, tambahkan test golden baru untuk kasus itu.
Sistem AI sering gagal pada tepi yang berantakan. Tambahkan fuzzing otomatis yang menghasilkan:
- String acak dan encoding campuran
- JSON yang salah bentuk, payload terpotong, koma ekstra
- Nilai ekstrem (teks sangat panjang, field kosong, angka besar, tanggal tak biasa)
Menguji keluaran non-deterministik
Alih-alih menyimpan snapshot teks persis, gunakan toleransi dan rubrik:
- Skor keluaran berdasarkan checklist (field wajib, konten terlarang, batas panjang)
- Pengecekan semantik (mis. label klasifikasi ada di set yang diizinkan)
- Ambang kemiripan untuk ringkasan, plus assert “harus menyebut fakta kunci”
Ini menjaga tes stabil sekaligus menangkap regresi nyata.
Monitoring dan Observabilitas untuk Validasi dan Kesalahan
Luncurkan aplikasi AI Anda hari ini
Buat, luncurkan, dan host aplikasi Anda, lalu sambungkan domain kustom saat siap.
Aturan validasi dan penanganan kesalahan hanya membaik ketika Anda bisa melihat apa yang terjadi dalam penggunaan nyata. Monitoring mengubah “kami rasa baik-baik saja” menjadi bukti jelas: apa yang gagal, seberapa sering, dan apakah keandalan meningkat atau diam-diam menurun.
Apa yang harus dilog (tanpa menciptakan masalah privasi)
Mulailah dengan log yang menjelaskan mengapa permintaan berhasil atau gagal—lalu redaksi atau hindari data sensitif secara default.
- Input dan output (kesadaran privasi): simpan hash, kutipan terpotong, atau field terstruktur alih-alih teks mentah bila memungkinkan. Jika Anda harus menyimpan konten mentah untuk debugging, gunakan retensi singkat, kontrol akses, dan tujuan yang jelas.
- Kegagalan validasi: nama aturan, path field (mis.
address.postcode), dan alasan kegagalan (mismatch skema, konten tidak aman, intent wajib hilang).
- Pemanggilan alat dan efek samping: alat mana yang dipanggil, parameter (disanitasi), kode respons, dan timing. Ini esensial saat kegagalan berasal dari luar model.
- Exception dan timeout: stack trace untuk error internal, plus kode error yang aman untuk pengguna yang memetakan kategori yang dikenal.
Metrik yang benar-benar memprediksi keandalan
Log membantu debug satu insiden; metrik membantu Anda melihat pola. Lacak:
- Tingkat kegagalan validasi (total dan per aturan)
- Tingkat lolos skema (output yang cocok struktur yang diharapkan)
- Tingkat retry dan tingkat keberhasilan pemulihan (seberapa sering fallback berhasil)
- Latensi (end-to-end dan per pemanggilan alat)
- Kategori error teratas (mis. “field hilang”, “timeout alat”, “pelanggaran kebijakan”)
Peringatan atas drift
Keluaran AI bisa bergeser setelah edit prompt, pembaruan model, atau perilaku pengguna baru. Alert sebaiknya fokus pada perubahan, bukan hanya ambang absolut:
- Kenaikan mendadak dalam aturan validasi tertentu yang gagal
- Kategori error baru muncul
- Perubahan bentuk keluaran (mis. sebuah field JSON berubah jadi teks bebas)
Dashboard yang bisa digunakan tim non-teknis
Dashboard yang baik menjawab: “Apakah ini bekerja untuk pengguna?” Sertakan kartu skor keandalan sederhana, garis tren tingkat lolos skema, rincian kegagalan menurut kategori, dan contoh tipe kegagalan paling umum (dengan konten sensitif dihilangkan). Hubungkan tampilan teknis lebih dalam untuk engineer, tapi buat tampilan tingkat atas dapat dibaca oleh tim produk dan dukungan.
Perbaikan Berkelanjutan: Mengubah Kegagalan Menjadi Aturan yang Lebih Baik
Validasi dan penanganan kesalahan bukan sesuatu yang diatur sekali lalu dilupakan. Dalam sistem yang dihasilkan AI, pekerjaan nyata dimulai setelah peluncuran: setiap keluaran aneh adalah petunjuk tentang aturan apa yang seharusnya Anda miliki.
Bangun loop umpan balik yang ketat
Perlakukan kegagalan sebagai data, bukan anekdot. Loop paling efektif biasanya menggabungkan:
- Laporan pengguna (tombol “Laporkan masalah” sederhana + screenshot/ID keluaran opsional)
- Antrian review manusia untuk kasus ambigu (menyesatkan, tidak aman, atau “terlihat salah")
- Pelabelan otomatis (kegagalan regex/skema, flag toksisitas, deteksi bahasa yang salah, sinyal ketidakpastian tinggi)
Pastikan setiap laporan terkait kembali ke input tepat, versi model/prompt, dan hasil validator sehingga Anda bisa mereproduksinya nanti.
Bagaimana perbaikan benar-benar terjadi
Sebagian besar perbaikan masuk ke beberapa langkah yang dapat diulang:
- Perketat skema: jika Anda mengharapkan JSON, sebutkan kunci wajib, enum, dan tipe; tolak “hampir JSON.”
- Tambahkan validator terfokus: tegakkan satuan, format tanggal, rentang yang diizinkan, dan constraint "harus menyertakan".
- Sesuaikan prompt: jelaskan prioritas ("Jika ragu, katakan tidak tahu"), tambahkan contoh, dan kurangi instruksi ambigu.
- Tambahkan fallback: retry dengan prompt lebih ketat, ganti dengan respons template yang lebih aman, atau rute ke review manusia—tanpa diam-diam mengarang detail.
Saat Anda memperbaiki satu kasus, tanyakan juga: “Kasus dekat mana yang masih bisa lolos?” Perluas aturan untuk menutupi klaster kecil, bukan hanya satu insiden.
Versioning dan rollout yang aman
Versioning untuk prompt, validator, dan model seperti kode. Lakukan rollout dengan canary atau A/B, pantau metrik kunci (tingkat penolakan, kepuasan pengguna, biaya/latensi), dan siapkan jalur rollback cepat.
Ini juga tempat tooling produk membantu: mis. platform seperti Koder.ai mendukung snapshot dan rollback selama iterasi aplikasi, yang cocok dengan versioning prompt/validator. Ketika pembaruan meningkatkan kegagalan skema atau mematahkan integrasi, rollback cepat mengubah insiden produksi menjadi pemulihan cepat.
Daftar periksa praktis
- Bisakah kami mereproduksi masalah yang dilaporkan dari log?
- Apakah kegagalan diarahkan ke bucket yang tepat (retry, fallback, review manusia, hard stop)?
- Apakah kami memperbarui skema/validator dan prompt bersama-sama?
- Apakah kami menambahkan test case untuk kegagalan ini agar tidak kembali?
- Apakah kami meluncurkan perubahan di balik canary dan memantau dampaknya?