23 Sep 2025·8 menit
ZSTD vs Brotli vs GZIP: Memilih Kompresi untuk API
Bandingkan ZSTD, Brotli, dan GZIP untuk API: kecepatan, rasio, biaya CPU, dan default praktis untuk payload JSON dan biner di produksi.
Bandingkan ZSTD, Brotli, dan GZIP untuk API: kecepatan, rasio, biaya CPU, dan default praktis untuk payload JSON dan biner di produksi.
Kompresi respons API berarti server Anda mengenkripsi (encode) body respons (sering JSON) menjadi aliran byte yang lebih kecil sebelum mengirimkannya lewat jaringan. Klien (browser, aplikasi mobile, SDK, atau layanan lain) kemudian melakukan dekompresi. Di atas HTTP, ini dinegosiasikan lewat header seperti Accept-Encoding (apa yang didukung klien) dan Content-Encoding (apa yang dipilih server).
Kompresi terutama memberi Anda tiga hal:
Pertukarannya jelas: kompresi menghemat bandwidth tetapi biaya CPU (kompres/dekompres) dan kadang memori (buffer). Apakah ini layak tergantung pada bottleneck Anda.
Kompresi cenderung efektif ketika respons bersifat:
Jika Anda mengembalikan daftar JSON besar (katalog, hasil pencarian, analitik), kompresi sering menjadi salah satu optimasi termudah.
Kompresi sering kali menjadi penggunaan CPU yang buruk ketika respons:
Saat memilih antara ZSTD vs Brotli vs GZIP untuk kompresi API, keputusan praktis biasanya turun ke:
Sisa artikel ini tentang menyeimbangkan ketiganya untuk API dan pola trafik Anda.
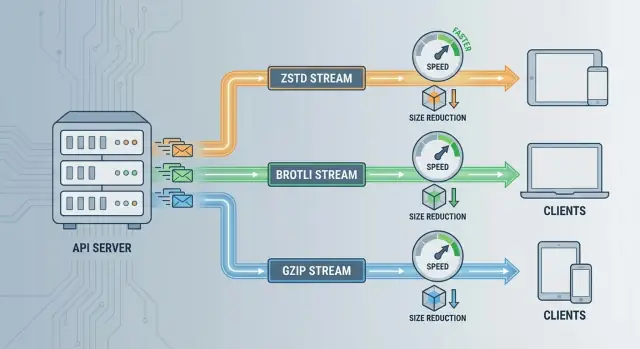
Ketiganya mengurangi ukuran payload, tetapi mereka mengoptimalkan batasan yang berbeda—kecepatan, rasio kompresi, dan kompatibilitas.
Kecepatan ZSTD: Bagus ketika API Anda sensitif terhadap tail latency atau server Anda terikat CPU. Ia dapat mengompresi cukup cepat sehingga overhead sering kali dapat diabaikan dibandingkan waktu jaringan—terutama untuk respons JSON berukuran sedang hingga besar.
Rasio kompresi Brotli: Terbaik ketika bandwidth adalah kendala utama (klien seluler, egress mahal, pengiriman lewat CDN) dan respons sebagian besar berbasis teks. Payload yang lebih kecil bisa bernilai meskipun kompresi memakan waktu lebih lama.
Kompatibilitas GZIP: Terbaik ketika Anda memerlukan dukungan klien maksimum tanpa risiko negosiasi (SDK lama, klien embedded, proxy legacy). Ini baseline yang aman meskipun bukan performer tertinggi.
“Level” kompresi adalah preset yang menukar waktu CPU untuk output yang lebih kecil:
Dekompressi biasanya jauh lebih murah daripada kompresi untuk ketiganya, tetapi level yang sangat tinggi masih dapat menambah beban CPU klien—penting untuk perangkat mobile.
Kompresi sering dipasarkan sebagai “respons lebih kecil = API lebih cepat.” Itu sering benar pada jaringan lambat atau mahal—tetapi tidak otomatis. Jika kompresi menambah cukup banyak waktu CPU server, Anda bisa mendapat permintaan yang lebih lambat meskipun byte di jaringan berkurang.
Bermanfaat memisahkan dua biaya:
Rasio kompresi yang tinggi dapat mengurangi waktu transfer, tetapi jika kompresi menambah (mis.) 15–30 ms CPU per respons, Anda mungkin kehilangan lebih banyak waktu daripada yang dihemat—terutama pada koneksi cepat.
Di bawah beban, kompresi dapat merugikan p95/p99 latency lebih daripada p50. Saat penggunaan CPU melonjak, permintaan mengantri. Antrian memperbesar biaya per-request kecil menjadi delay besar—rata-rata latency tampak baik, tetapi pengguna paling lambat menderita.
Jangan menebak. Jalankan A/B test atau rollout bertahap dan bandingkan:
Uji dengan pola trafik dan payload yang realistis. “Level” kompresi terbaik adalah yang mengurangi waktu total, bukan hanya byte.
Kompresi tidaklah “gratis”—ia memindahkan kerja dari jaringan ke CPU dan memori pada kedua ujung. Dalam API, itu muncul sebagai waktu penanganan request yang lebih tinggi, jejak memori lebih besar, dan kadang perlambatan di sisi klien.
Sebagian besar CPU dihabiskan untuk mengompresi respons. Kompresi menemukan pola, membangun state/dictionary, dan menulis output terenkode.
Dekompressi biasanya lebih murah, tetapi tetap relevan:
Jika API Anda sudah terikat CPU (app server sibuk, auth berat, query mahal), mengaktifkan level kompresi tinggi dapat menambah tail latency meskipun payload mengecil.
Kompresi dapat meningkatkan penggunaan memori dalam beberapa cara:
Di lingkungan containerized, puncak memori yang lebih tinggi bisa berujung pada OOM kills atau batas lebih ketat yang mengurangi densitas.
Kompresi menambah siklus CPU per respons, mengurangi throughput per instance. Itu dapat memicu autoscaling lebih cepat, menaikkan biaya. Pola umum: bandwidth turun, tetapi pengeluaran CPU naik—pilihan yang tepat bergantung pada sumber daya mana yang langka untuk Anda.
Di perangkat mobile atau perangkat berdaya rendah, dekompresi bersaing dengan rendering, eksekusi JavaScript, dan baterai. Format yang menghemat beberapa KB tetapi memakan waktu dekompresi lebih lama bisa terasa lebih lambat, khususnya ketika “waktu sampai data dapat digunakan” penting.
Zstandard (ZSTD) adalah format kompresi modern yang dirancang untuk memberikan rasio kompresi kuat tanpa memperlambat API Anda. Untuk banyak API berbasis JSON, ini sering menjadi “default” yang kuat: respons lebih kecil dari GZIP pada latency yang serupa atau lebih rendah, ditambah dekompresi yang sangat cepat di klien.
ZSTD paling bernilai saat Anda peduli pada waktu end-to-end, bukan sekadar byte terkecil. Ia cenderung mengompresi cepat dan mendekompresi sangat cepat—berguna untuk API di mana setiap milidetik CPU bersaing dengan penanganan request.
Ia juga berkinerja baik di berbagai ukuran payload: JSON kecil-ke-sedang sering melihat keuntungan bermakna, sementara respons besar bisa mendapat manfaat lebih.
Untuk sebagian besar API, mulai dengan level rendah (umumnya level 1–3). Ini sering memberi trade-off terbaik antara latency/ukuran.
Gunakan level lebih tinggi hanya ketika:
Pendekatan pragmatis: default global rendah, lalu tingkatkan level secara selektif untuk beberapa endpoint “respons besar”.
ZSTD mendukung streaming, yang dapat mengurangi puncak memori dan mulai mengirim data lebih cepat untuk respons besar.
Dictionary mode bisa menjadi keuntungan besar untuk API yang mengembalikan banyak objek serupa (kunci berulang, skema stabil). Ini paling efektif ketika:
Dukungan sisi server mudah di banyak stack, tetapi kompatibilitas klien bisa menjadi faktor penentu. Beberapa HTTP client, proxy, dan gateway masih tidak mengiklankan atau menerima Content-Encoding: zstd secara default.
Jika Anda melayani konsumen pihak ketiga, sediakan fallback (biasanya GZIP) dan aktifkan ZSTD hanya ketika Accept-Encoding jelas menyertakannya.
Brotli dirancang untuk memampatkan teks dengan sangat baik. Pada JSON, HTML, dan payload “banyak kata” lainnya, ia sering mengalahkan GZIP pada rasio kompresi—terutama pada level kompresi yang lebih tinggi.
Respons berbasis teks adalah titik kuat Brotli. Jika API Anda mengirim dokumen JSON besar (katalog, hasil pencarian, blob konfigurasi), Brotli dapat mengurangi byte secara signifikan, yang membantu pada jaringan lambat dan dapat menurunkan biaya egress.
Brotli juga kuat ketika Anda dapat mengompresi sekali lalu melayani banyak kali (respons cacheable, resource berversion). Dalam kasus itu, Brotli level tinggi bisa sepadan karena biaya CPU teramortisasi.
Untuk respons API dinamis (dihasilkan setiap permintaan), rasio terbaik Brotli sering membutuhkan level tinggi yang bisa mahal CPU-nya dan menambah latency. Setelah Anda memperhitungkan waktu kompresi, keuntungan nyata dibanding ZSTD (atau bahkan GZIP yang disetel baik) mungkin lebih kecil dari yang diharapkan.
Brotli juga kurang menarik untuk payload yang tidak bisa terkompresi baik (data yang sudah dikompresi, banyak format biner). Pada kasus tersebut Anda hanya membakar CPU.
Browser umumnya mendukung Brotli dengan baik lewat HTTPS, itulah sebabnya ia populer untuk trafik web. Untuk klien API non-browser (SDK mobile, perangkat IoT, stack HTTP lama), dukungan bisa tidak konsisten—jadi negosiasikan dengan benar lewat Accept-Encoding dan sediakan fallback (biasanya GZIP).
GZIP tetap jawaban default untuk kompresi API karena merupakan opsi yang paling dipahami secara universal. Hampir setiap HTTP client, browser, proxy, dan gateway memahami Content-Encoding: gzip, dan prediktabilitas itu penting saat Anda tidak sepenuhnya mengendalikan apa yang ada di antara server dan pengguna.
Keuntungannya bukan karena GZIP “terbaik”—melainkan karena jarang menjadi pilihan yang salah. Banyak organisasi memiliki pengalaman operasional bertahun-tahun dengannya, default masuk akal di web server mereka, dan lebih sedikit kejutan dengan perantara yang mungkin salah menangani encoding baru.
Untuk payload API (sering JSON), level kompresi menengah-ke-rendah biasanya merupakan titik manis. Level seperti 1–6 sering memberikan sebagian besar pengurangan ukuran sambil menjaga CPU tetap wajar.
Level sangat tinggi (8–9) bisa memeras sedikit lagi, tetapi waktu CPU tambahan biasanya tidak sepadan untuk traffic request/response dinamis di mana latency penting.
Di hardware modern, GZIP umumnya lebih lambat daripada ZSTD pada rasio kompresi serupa, dan sering tidak bisa menyamai rasio terbaik Brotli pada teks. Dalam beban kerja API nyata, itu biasanya berarti:
Jika Anda harus mendukung klien lama, perangkat embedded, proxy perusahaan ketat, atau gateway legacy, GZIP adalah pilihan paling aman. Beberapa perantara akan menghapus encoding yang tidak dikenal, gagal meneruskannya, atau merusak negosiasi—isu yang jauh lebih jarang terjadi dengan GZIP.
Jika lingkungan Anda campur atau tidak pasti, mulai dengan GZIP (dan tambahkan ZSTD/Brotli hanya di mana Anda mengendalikan seluruh jalur) sering kali strategi rollout paling andal.
Kemenangan kompresi bukan hanya soal algoritma. Penggerak terbesar adalah jenis data yang Anda kirim. Beberapa payload mengecil drastis dengan ZSTD, Brotli, atau GZIP; lainnya hampir tidak berubah dan hanya membakar CPU.
Respons berbasis teks cenderung sangat bisa dikompresi karena mengandung kunci berulang, whitespace, dan pola yang dapat diprediksi.
Semakin banyak repetisi dan struktur, semakin baik rasio kompresi.
Format biner seperti Protocol Buffers dan MessagePack lebih ringkas daripada JSON, tetapi mereka bukan “acak”. Mereka masih bisa mengandung tag berulang, layout record serupa, dan urutan yang dapat diprediksi.
Itu berarti mereka sering kali masih bisa dikompresi, terutama untuk respons besar atau endpoint yang mengembalikan daftar. Jawaban yang andal hanyalah menguji dengan trafik nyata Anda: endpoint yang sama, data yang sama, kompresi on/off, dan bandingkan ukuran dan latency.
Banyak format sudah terkompresi secara internal. Menerapkan kompresi respons HTTP di atasnya biasanya memberi sedikit penghematan dan dapat menambah waktu respons.
Untuk ini, umum menonaktifkan kompresi berdasarkan tipe konten.
Pendekatan sederhana adalah hanya mengompresi ketika respons melewati ukuran minimum.
Content-Encoding.Ini menjaga CPU fokus pada payload tempat kompresi benar-benar mengurangi bandwidth dan memperbaiki performa end-to-end.
Kompresi hanya berjalan mulus ketika klien dan server sepakat pada encoding. Kesepakatan itu terjadi lewat Accept-Encoding (dikirim klien) dan Content-Encoding (dikirim server).
A client mengiklankan apa yang bisa didekodekan:
GET /v1/orders HTTP/1.1
Host: api.example
Accept-Encoding: zstd, br, gzip
Server memilih salah satu dan menyatakan apa yang ia gunakan:
HTTP/1.1 200 OK
Content-Type: application/json
Content-Encoding: zstd
Jika klien mengirim Accept-Encoding: gzip dan Anda merespons dengan Content-Encoding: br, klien itu mungkin gagal mem-parse body. Jika klien tidak mengirim Accept-Encoding, default paling aman adalah tidak mengirim kompresi.
Urutan praktis untuk API sering kali:
zstd pertama (keseimbangan kecepatan/rasio yang bagus)br (sering lebih kecil, kadang lebih lambat)gzip (kompatibilitas terluas)Dengan kata lain: zstd > br > gzip.
Jangan menganggap ini universal: jika trafik Anda kebanyakan browser, br mungkin pantas diprioritaskan lebih tinggi; jika Anda punya klien mobile lama, gzip mungkin pilihan “terbaik” yang paling aman.
Jika respons dapat disajikan dalam beberapa encoding, tambahkan:
Vary: Accept-Encoding
Tanpa itu, CDN atau proxy mungkin meng-cache versi gzip (atau zstd) dan keliru menyajikannya ke klien yang tidak meminta (atau tidak bisa menangani) encoding tersebut.
Beberapa klien mengaku mendukung tapi mempunyai decoder yang buggy. Untuk tetap tahan banting:
zstd, fallback sementara ke gzip.Negosiasi kurang tentang mengeruk setiap byte dan lebih tentang tidak pernah merusak klien.
Kompresi API tidak berjalan sendiri. Protokol transport, overhead TLS, dan CDN atau gateway di antaranya dapat mengubah hasil dunia nyata—atau bahkan merusak jika salah konfigurasi.
Dengan HTTP/2, beberapa request berbagi satu koneksi TCP. Itu mengurangi overhead koneksi, tetapi kehilangan paket bisa menahan semua stream karena head-of-line blocking TCP. Kompresi dapat membantu dengan memperkecil body respons, mengurangi jumlah data yang “terjebak” di balik event loss.
HTTP/3 berjalan di atas QUIC (UDP) dan menghindari head-of-line blocking TCP antar stream. Ukuran payload tetap penting, tetapi penalti kehilangan biasanya kurang dramatis per koneksi. Dalam praktiknya, kompresi tetap bernilai—manfaatnya cenderung muncul sebagai penghematan bandwidth dan lebih cepat “time to last byte” daripada penurunan latency yang dramatis.
TLS sudah mengonsumsi CPU (handshake, enkripsi/dekripsi). Menambahkan kompresi (terutama di level tinggi) dapat mendorong Anda melewati batas CPU saat lonjakan. Ini sebabnya pengaturan “kompresi cepat dengan rasio layak” seringkali mengungguli “rasio maksimal” di produksi.
Beberapa CDN/gateway otomatis mengompresi tipe MIME tertentu, sementara yang lain meneruskan apa yang origin kirim. Beberapa mungkin menormalisasi atau bahkan menghapus Content-Encoding jika salah konfigurasi.
Verifikasi perilaku per route, dan pastikan Vary: Accept-Encoding dipertahankan agar cache tidak menyajikan varian terkompresi ke klien yang tidak memintanya.
Jika Anda cache di edge, pertimbangkan menyimpan varian terpisah per encoding (gzip/br/zstd) daripada merekompres pada setiap hit. Jika Anda cache di origin, Anda masih mungkin ingin edge menegosiasikan dan menyimpan beberapa encoding.
Kuncinya konsistensi: Content-Encoding yang benar, Vary yang benar, dan kepemilikan yang jelas di mana kompresi terjadi.
Untuk API yang berhadapan dengan browser, prioritaskan Brotli ketika klien mengiklankan itu (Accept-Encoding: br). Browser biasanya mendekode Brotli secara efisien, dan sering memberikan pengurangan ukuran yang lebih baik pada respons teks.
Untuk API internal antar-layanan, default ke ZSTD ketika kedua sisi berada di bawah kontrol Anda. Ia biasanya lebih cepat pada rasio yang setara dibanding GZIP, dan negosiasi mudah.
Untuk API publik yang digunakan oleh SDK beragam, pertahankan GZIP sebagai baseline universal dan tambahkan ZSTD secara opt-in untuk klien yang eksplisit mendukungnya. Itu menghindari merusak stack HTTP lama.
Mulailah dengan level yang mudah diukur dan tidak mengejutkan:
Jika Anda butuh rasio lebih kuat, validasi dengan sampel payload mirip produksi dan pantau p95/p99 latency sebelum menaikkan level.
Mengompresi respons kecil bisa menelan CPU lebih banyak daripada penghematan di jaringan. Titik awal praktis:
Tuning dengan membandingkan: (1) byte yang dihemat, (2) waktu server tambahan, (3) perubahan end-to-end latency.
Rollout kompresi di balik feature flag, lalu tambahkan konfigurasi per-route (aktifkan untuk /v1/search, nonaktifkan untuk endpoint yang sudah kecil). Sediakan client opt-out menggunakan Accept-Encoding: identity untuk troubleshooting dan klien edge. Selalu sertakan Vary: Accept-Encoding agar cache tetap benar.
Jika Anda menghasilkan API cepat (mis. memutar frontend React dengan backend Go + PostgreSQL, lalu iterasi berdasarkan trafik nyata), kompresi menjadi salah satu knob “konfigurasi kecil, dampak besar”.
Di Koder.ai, tim sering mencapai titik ini lebih awal karena dapat mem-prototype dan deploy full-stack apps cepat, lalu menyetel perilaku produksi (termasuk kompresi respons dan header cache) setelah endpoint dan bentuk payload stabil. Intinya tetap: anggap kompresi sebagai fitur performa, rilis di balik flag, dan ukur p95/p99 sebelum menyatakan kemenangan.
Perubahan kompresi mudah dipakai dan cukup mudah salah. Perlakukan seperti fitur produksi: rollout bertahap, ukur dampak, dan sediakan rollback sederhana.
Mulai dengan canary: aktifkan Content-Encoding baru (mis. zstd) untuk sebagian kecil trafik atau satu klien internal.
Lalu naikkan bertahap (mis. 1% → 5% → 25% → 50% → 100%), berhenti jika metrik kunci bergerak ke arah yang buruk.
Simpan jalur rollback yang mudah:
gzip).Lacak kompresi sebagai perubahan performa dan reliabilitas:
4xx/5xx, error decode klien, dan timeout.Saat sesuatu rusak, ini biasanya penyebabnya:
Content-Encoding disetel tapi body tidak terkompresi (atau sebaliknya).Accept-Encoding, atau mengembalikan encoding yang klien tidak iklankan.Content-Length salah, atau intervensi proxy/CDN.Jelaskan encodings yang didukung di dokumentasi Anda, termasuk contoh:
Accept-Encoding: zstd, br, gzipContent-Encoding: zstd (atau fallback)Jika Anda mengirim SDK, tambahkan contoh decode copy-pasteable kecil dan nyatakan versi minimum yang mendukung Brotli atau Zstandard jika relevan.
Gunakan kompresi respons ketika respons bersifat berat teks (JSON/GraphQL/XML/HTML), berukuran sedang hingga besar, dan pengguna Anda berada di jaringan yang lambat/mahal atau Anda membayar biaya egress yang signifikan. Lewati (atau tetapkan ambang tinggi) untuk respons sangat kecil, media yang sudah terkompresi (JPEG/MP4/ZIP/PDF), dan layanan yang terikat CPU di mana pekerjaan per-request tambahan akan merusak p95/p99 latency.
Karena kompresi menukar bandwidth dengan CPU (dan kadang memori). Waktu kompresi dapat menunda kapan server mulai mengirim byte (TTFB), dan di bawah beban hal ini dapat memperbesar antrean—seringkali merugikan tail latency meskipun rata-rata latency membaik. Pengaturan terbaik adalah yang mengurangi waktu end-to-end, bukan hanya ukuran payload.
Prioritas praktis untuk banyak API adalah:
zstd pertama (cepat, rasio bagus)br (sering kali paling kecil untuk teks, dapat lebih mahal CPU)gzip (kompatibilitas paling luas)Selalu dasarkan pilihan akhir pada apa yang diiklankan klien di , dan sediakan fallback aman (biasanya atau ).
Mulailah dari rendah dan ukur.
Gunakan ambang ukuran respons minimum sehingga Anda tidak membakar CPU untuk payload kecil.
Tuning per-endpoint dengan membandingkan byte yang dihemat vs waktu server tambahan dan dampaknya terhadap p50/p95/p99 latency.
Fokus pada tipe konten yang terstruktur dan berulang:
Kompresi harus mengikuti negosiasi HTTP:
Accept-Encoding (mis. zstd, br, gzip)Content-Encoding yang didukungJika klien tidak mengirim , respons paling aman biasanya . Jangan pernah mengembalikan yang tidak diiklankan klien, atau Anda berisiko membuat klien gagal.
Tambahkan:
Vary: Accept-EncodingHeader ini mencegah CDN/proxy meng-cache (mis. sebuah respons gzip) dan keliru menyajikannya ke klien yang tidak meminta atau tidak dapat mendekode gzip (atau zstd/br). Jika Anda mendukung banyak encoding, header ini penting untuk perilaku caching yang benar.
Mode kegagalan umum meliputi:
Rollout seperti fitur performa:
Accept-EncodinggzipidentityLevel yang lebih tinggi biasanya memberi keuntungan ukuran yang berkurang namun dapat memicu lonjakan CPU dan memperburuk p95/p99.
Pendekatan umum: aktifkan kompresi hanya untuk nilai Content-Type yang menyerupai teks dan nonaktifkan untuk format yang sudah dikompresi.
Accept-EncodingContent-EncodingContent-Encoding mengatakan gzip tetapi body tidak dikompresi)Accept-Encoding)Saat debugging, tangkap header respons mentah dan verifikasi dekompresi dengan tool/klien yang diketahui baik.
Jika tail latency naik di bawah beban, turunkan level, naikkan ambang, atau pindah ke codec yang lebih cepat (seringkali ZSTD).