2025年6月17日·1 分
AIが開発者の仕事で置き換えるもの(置き換えないもの)
AIが置き換えられる開発作業、主に拡張する領域、実チームで依然として人間が完全に所有すべきタスクを実践的に分解して説明します。
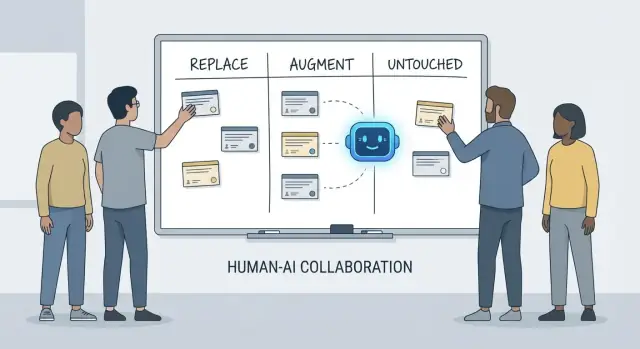
置き換え・拡張・そのまま:シンプルなフレームワーク
「AIが開発者に何をするか」という議論はすぐに混乱します。理由はしばしばツールと責任を混同するからです。ツールはコードを生成したり、チケットを要約したり、テストを提案したりできます。責任とは、提案が間違っていたときにチームが依然として説明できることです。
この記事では、置き換え(replace)、拡張(augment)、**そのまま(untouched)**というシンプルなフレームワークを使い、締め切り、レガシーコード、本番インシデント、信頼できる成果を期待するステークホルダーがいる実際のチームでの日常業務を説明します。
「置き換え」が意味すること(と意味しないこと)
置き換えとは、AIが明確なガードレールの下でタスクを大部分はエンドツーエンドで完了でき、人間の役割は監督とスポットチェックに移ることを指します。
例としては境界がはっきりした仕事が多い:ボイラープレート生成、言語間のコード翻訳、繰り返しのテストケースの草案、一次的なドキュメントの作成など。
ただし「置き換え」が意味するのは「人間の責任がなくなる」ということではありません。出力が本番を壊したり、データを漏らしたり、基準に違反した場合、最終的な責任はチームにあります。
「拡張」が意味すること
拡張とは、AIが開発者をより速く、またはより丁寧にするが、人間の判断なしに信頼して完了できるわけではないことを指します。
これはプロフェッショナルなエンジニアリングで最も一般的なケースです:有用な草案、代替アプローチ、短い説明、または考えられるバグの候補リストを得られますが、何が正しく安全で製品に適切かを決めるのは開発者です。
「そのまま」に残るもの
**そのまま(untouched)**は、コアの責任が人間主導のままであることを意味します。なぜならそれらは文脈、トレードオフ、説明責任を必要とし、プロンプトでは十分に圧縮できないからです。
例:要件の交渉、システムレベルの制約の選定、インシデント対応、品質基準の設定、正解が一つでない場面での判断など。
なぜ責任が分析の単位なのか
ツールは速く変わりますが、責任はゆっくりと変わります。
だから「AIはこのコードを書けるか?」と聞く代わりに「結果の責任は誰にあるか?」と問うべきです。この視点は精度、信頼性、説明責任に基づいた期待を保ち、印象的なデモより重要な点に着目させます。
「開発者の責任」とは何か
人々がAIが開発に「何を置き換えるか」と尋ねるとき、しばしばタスク(関数を書く、テストを生成する、ドキュメントを下書きする)を指します。しかしチームはタスクを出荷するのではなく、成果を出荷します。そこで開発者の責任が重要になります。
一般的な責任の束
開発者の仕事は単なるコーディング以上に広がります:
- デリバリー: 漠然としたアイデアを期限内に動くソフトウェアに仕上げ、出荷すること。
- 品質: 正確さ、保守性、回帰の防止。
- セキュリティとプライバシー: 安全なデフォルト、データ処理、脅威認識。
-
- 運用: サービスの稼働維持、失敗モードの理解、インシデント対応。
- コミュニケーション: プロダクト、デザイン、サポート、他のエンジニアとの整合。
これらの責任はライフサイクル全体にまたがります—「何を作るべきか?」から「安全か?」、「壊れたときに3時に何が起きるか?」まで。
それがチェックリスト以上である理由
各責任は実際には多くの小さな判断の集合です:どのエッジケースが重要か、どの指標が健全性を示すか、いつスコープを切るか、修正が安全に出荷できるか、ステークホルダーにどのようにトレードオフを説明するか。AIは作業の一部(コード下書き、テスト提案、ログの要約)を助けることはできますが、責任は結果を所有することに関わります。
引き渡しでの失敗が起きる場所
障害は多くの場合、引き渡し境界で発生します:
- “QAが見つけるだろう”(しかし品質が何を意味するか定義されていない)
- “セキュリティがレビューする”(しかし設計が既にリスクのある選択を固定している)
- “Opsが対応する”(しかしサービスは運用可能に作られていなかった)
所有権が不明確だと、仕事は隙間に落ちます。
決定権:誰が決め、誰が実行するか
責任を語る有用な方法は決定権です:
- 要件、トレードオフ、許容リスクを誰が決めるか?
- 実装と検証を誰が実行するか?
AIは実行を速められます。決定権と成果に対する説明責任には、依然として人の名前が必要です。
AIがしばしば置き換えられる作業(ガードレールがある場合)
AIコーディングアシスタントは、作業が予測可能で低リスク、検証が容易な場合に本当に役立ちます。高速なジュニアのチームメイトのような存在と考えてください:一次的な成果物は得意ですが、明確な指示と慎重なチェックが必要です。
実務では、一部のチームが“vibe-coding”プラットフォーム(例:Koder.ai)を使い、置き換え可能なチャンクを高速化しています:スキャフォールド生成、CRUDフローの配線、チャットからのUI/バックエンドの初期ドラフト作成。肝心なのは一貫性、レビュー、明確な所有権です。
低リスクのボイラープレート
多くの時間はプロジェクトのスキャフォールディングやレイヤー間のつなぎに費やされます。AIはしばしば以下を生成できます:
- スターターファイルとフォルダ(コントローラ、ルート、DTO)
- レイヤー間の繰り返しの「グルーコード」
- 既存パターンに従う単純なCRUDエンドポイント
ガードレールは一貫性です:既存の規約に合っていること、新たなパターンや依存を勝手に導入しないことを確認してください。
機械的なリファクタとマイグレーション
変更がほとんど機械的な場合—シンボルの一括リネーム、フォーマット変更、単純なAPI利用の更新—AIは単純作業を加速します。
それでもバルク編集として扱ってください:フルテストスイートを実行し、差分をスキャンして意図しない振る舞いの変更を探し、要求されたリファクタ以外の“改善”は避けましょう。
ドキュメント草案(要レビュー)
AIはREADME、インラインコメント、変更履歴をコードやコミットノートから下書きできます。これは明瞭さを速めますが、自信満々に聞こえる誤りを生むこともあります。
ベストプラクティス:構造や表現はAIに任せ、特にセットアップ手順、構成デフォルト、エッジケースの主張は全て検証してください。
基本的なテスト生成の出発点
仕様が明確な純粋関数に対して、AI生成のユニットテストは初期カバレッジを与え、エッジケースの注意喚起になります。ガードレールは所有権です:何が重要かを選び、要件を反映するアサーションを追加し、テストが正しい理由で失敗することを確認してください。
スレッドとログの要約
長いSlackスレッド、チケット、インシデントログを簡潔なノートとアクションアイテムに変換できます。全コンテキストを与え、重要な事実、タイムスタンプ、決定を共有する前に検証してください。
AIが主に拡張する作業:速くなるが終わらない
AIコーディングアシスタントは、何をしたいかが既にわかっている場合に最も力を発揮します。タイプ作業を減らし、有用な文脈を提示しますが、所有、検証、判断の必要性を取り除きません。
実装を早める(強力なファーストパス)
入力、出力、エッジケース、制約が明確な仕様を与えると、AIは実行可能な出発実装(ボイラープレート、データマッピング、APIハンドラ、マイグレーション、単純なリファクタ)を下書きできます。得られるのは勢いです:素早く動くものが手に入ります。
ただし、ファーストパスのコードは微妙な要件(エラーの意味論、性能制約、後方互換)を見落としがちです。インターンの下書きのように扱い、権威あるものとしては扱わないでください。
選択肢を提案する(検証すべきトレードオフ付き)
キャッシング対バッチ処理、楽観的ロック対悲観的ロックなどのアプローチ選択で、AIは代替案とトレードオフのリストを出せます。ブレインストーミングには有益ですが、トレードオフはあなたのシステムの現実(トラフィックの形、データ整合性の必要性、運用制約、チームの慣習)に照らして検証する必要があります。
コード理解とコードベースのナビゲーション
AIは不慣れなコードを説明したり、パターンを指摘したり、「これは何をしているのか?」を平易な言葉に翻訳したりするのが得意です。検索ツールと組み合わせれば、「Xはどこで使われているか?」や、見直すべき呼び出しサイト、設定、テストの影響リストを生成する助けになります。
開発者の作業環境改善:より良いフィードバックループ
実用的なQOL改善に期待してください:明確なエラーメッセージ、小さな使用例、貼り付け可能なスニペット。これらは摩擦を減らしますが、ユーザーや本番システムに影響する変更については慎重なレビュー、ローカル実行、ターゲットテストを置き換えません。
プロダクト理解と要件策定:依然として人間主導
AIは要件を書いたり洗練したりする手助けはできますが、何を作るべきかやなぜそれが重要かを信頼して決定することはできません。プロダクト理解は文脈に根ざしています:ビジネスゴール、ユーザーの痛み、組織上の制約、エッジケース、間違った場合のコスト。これらは会話、歴史、説明責任に生きており、モデルは要約はできても真に所有はできません。
曖昧な目標をビルド可能なものにする
初期の要求は「オンボーディングを滑らかにして」や「サポートチケットを減らして」といった曖昧さを帯びがちです。開発者の仕事はそれを明確な要件と受け入れ基準に翻訳することです。
その翻訳は主に人間の仕事です。なぜなら以下のような判断を引き出す探りが必要だからです:
- どのユーザーセグメントを最適化するのか、どの行動を変えたいのか?
- 何をもって「完了」とみなすか、どのように測るか?
- どの制約が非妥協か(プライバシー、性能、期限)?
AIは測定指標の提案や受け入れ基準の草案を出せますが、どの制約が現実的かを知るのは人間であり、要求が矛盾しているときに突き返すのも人間です。
トレードオフと期待値管理
要件作業は不快なトレードオフが表面化する場です:時間対品質、スピード対保守性、新機能対安定性。チームにはリスクを明示し、選択肢を提案し、ステークホルダーを結果に合わせて整合させる人が必要です。
良い仕様は単なるテキストではなく決定記録です。テスト可能で実装可能、入力・出力・エッジケース・失敗モードが明確であるべきです。AIは文書の構成を助けますが、正確性と「これは曖昧だから決定が必要だ」という指摘の責任は人間にあります。
システム設計とアーキテクチャの意思決定
リスクを元に戻しやすくする
スナップショットとロールバックを使って変更を小さく、元に戻せ、レビューしやすく保つ。
システム設計は「何を作るか」が「何に基づいて作るか、そして壊れたときにどう振る舞うか」に変わる部分です。AIは選択肢を探るのに役立ちますが、結果に対する責任を持つことはできません。
現実に合うアーキテクチャの選択
モノリス、モジュラーモノリス、マイクロサービス、サーバーレス、マネージドプラットフォームのどれが合うかはクイズではありません。期待スケール、予算、タイム・トゥ・マーケット、チームのスキルがフィットするかどうかの問題です。
アシスタントはパターンを要約し参照アーキテクチャを提案できますが、あなたのチームが週替わりでオンコールしているか、採用が遅いか、データベースベンダーの契約更新が来期にあるかなどは知りません。そうした詳細がアーキテクチャの成否を決めることが多いのです。
トレードオフを明示にする
良いアーキテクチャは主にトレードオフです:単純さ対柔軟性、性能対コスト、今の速さ対将来の保守性。AIは素早く利点/欠点リストを出せるので、決定のドキュメント化に有用です。
しかし、トレードオフが痛みを伴うときに優先順位を付けるのはビジネス的判断であり、純粋な技術判断ではありません(例:「わずかに遅い応答を受け入れて単純さと運用のしやすさを優先する」)。
境界、データ所有権、失敗モード
サービスの境界定義、誰がどのデータを所有するか、部分的な障害時に何が起きるかは深いプロダクトと運用の文脈を要します。AIは失敗モードをブレインストーミングできますが(「支払いプロバイダが落ちたら?」)、期待される挙動、顧客向けのメッセージ、ロールバック計画を決めるのは人間です。
使いやすいAPIの設計
API設計は契約設計です。AIは例を生成したり矛盾を見つけたりできますが、バージョニング、後方互換性、長期的に何をサポートするかを決めるのはあなたです。
作らない/削除する決断
最も建築的な判断の一つは「作らない」と言うか、機能を削除することです。AIは機会費用や政治的リスクを測れません。チームが判断すべきです。
実践におけるデバッグと根本原因分析
デバッグはAIが印象的に見えることが多い領域であり、同時に最も時間を無駄にしやすい領域でもあります。アシスタントはログをスキャンし、怪しいコードパスを指摘し、「正しそうな」修正を提案するかもしれません。しかし根本原因分析は説明を生成するだけではなく、それを証明することです。
AIは提案する:根拠はあなたが確認する
AIの出力は結論ではなく仮説として扱ってください。多くのバグには複数の妥当な原因があり、AIは貼り付けたコードスニペットに合致するきれいな説明を選びがちで、稼働中のシステムの現実を反映していないことがあります。
実用的なワークフロー:
- AIに可能な原因と、それらを区別するための証拠を求める。
- 問題を再現してその証拠を収集する。
- その後で修正を受け入れ(そして実際に失敗が消えることを検証する)。
再現と証拠収集は人間主導
信頼できる再現はデバッグのスーパー・パワーです。謎をテストに変えます。AIは最小再現例を書いたり診断スクリプトを下書きしたり追加ログを提案したりできますが、どのシグナルが重要か(リクエストID、タイミング、環境差、フィーチャーフラグ、データ形状、同時実行性)はあなたが決めます。
ユーザーが「アプリが固まった」と報告したとき、その症状をどのエンドポイントが停滞したか、どのタイムアウトが発生したか、どのエラーバジェットのシグナルが変化したかに翻訳するのは人間の文脈です。
「もっともらしいが間違っている」説明を避ける
提案が検証できない場合は、それが間違っていると仮定してください。検証可能な予測をする説明を好みましょう(例:「大きなペイロードでのみ起きるはず」や「キャッシュウォームアップ後のみ発生する」など)。
パッチ・リバート・再設計の選択
原因を特定しても、ハードな判断は残ります。AIはトレードオフを概説できますが、人間が対応を選びます:
- 出血を止めるために素早いパッチを当てる。
- 既知の良好な状態に戻すためにリバートする。
- 失敗が根本的な不一致を示すなら再設計する。
根本原因分析は最終的に説明責任です:説明、修正、再発防止への自信を所有すること。
コードレビュー:判断と基準は自動化できない
ドラフトからデプロイまで進める
準備ができたらアプリをデプロイ・ホストし、必要に応じてロールバックも利用可能。
コードレビューはスタイルのチェックリストだけではありません。チームが何を保守し、サポートし、説明責任を負うかを決める瞬間です。AIはより多くを「見つける」手助けはできますが、何が重要か、プロダクトの意図に合うか、チームが許容するトレードオフかを決められません。
レビューでAIが得意なこと
AIコーディングアシスタントは疲れ知らずの第二の目のように振る舞えます。すばやく:
- ありそうなバグ、怪しいパターン、欠落したnullチェック、安全でない文字列処理を指摘する。
- より明確な命名、リファクタ、単純な制御フローを提案する。
- 一貫性のないフォーマットや明らかな重複を指摘する。
- レビュー質問を生成する(「このAPIが空リストを返したらどうなる?」)。
このように使えば、PRの「オープンからリスク発見まで」の時間を短縮できます。
それでも人間の判断が必要なこと
正しさのレビューは単にコンパイルするかどうかではありません。人間は変更を実際のユーザ行動、本番制約、長期保守性に結び付けます。レビュワーが決めるべきこと:
- 何を出荷するか: AIは問題を列挙できるが、どれをリリース阻害にするかは決められない。
- 可読性と保守性: 「技術的に正しい」コードでも混乱を招き脆弱で拡張しにくいことがある。
- エッジケースと環境差: 多くの失敗は「自分のマシンでは動く」問題—設定、データの癖、同時実行、デプロイのタイミング。AIはランタイムの現実を推測できない。
- 基準と意図: チームだけが規約やリスク許容度、プロダクト目標を知っている。きれいなコードでも間違った挙動であり得る。
実用的ワークフロー:AIを共レビュワーにする
AIを最終承認者ではなく第二のレビュワーとして扱ってください。ターゲットを絞ったチェックを依頼(セキュリティ、エッジケース、後方互換)し、その後人間がスコープ、優先度、チーム基準とプロダクト意図への整合を判断します。
テスト戦略と品質の所有
AIはテストを素早く生成できますが、品質を所有するわけではありません。テストスイートは何が壊れ得るか、何を決して壊してはいけないか、どのエッジケースを証明せずに出荷するかという賭けの集合です。その賭けはプロダクトとエンジニアリングの判断であり、依然として人が行います。
AIはテストを草案できる;人間が目標を設定する
アシスタントはユニットテストの足場、依存のモック、実装からのハッピーパスのカバレッジ生成が得意です。しかしどのカバレッジが重要かを決めることはできません。
人間が定義すること:
- 安全クリティカルまたは頻繁に変更されるモジュールに深いカバレッジが必要かどうか。
- リスキーなリファクタと小さなバグ修正で「完了」が意味するもの。
- 回帰テストに投資するか、監視とロールバック計画に投資するか。
テストタイプの適切な組み合わせを選ぶ
ほとんどのチームは「より多くのテスト」ではなく層状戦略を必要とします。AIはこれらの多くを書けますが、選択と境界は人間主導:
- ユニットテスト: ビジネスルールや厄介なエッジケースのため。
- 統合テスト: DB/キュー/サービス間の相互作用。
- エンドツーエンドテスト: 重要なユーザージャーニー(少数で安定し高価値)。
- 契約テスト: チーム/サービス間のAPI互換性維持。
- パフォーマンステスト: 負荷時のレイテンシとコスト保護。
フレークテストと偽の信頼感を避ける
AI生成のテストは実装に寄り過ぎる傾向があり、壊れやすいアサーションや過剰なモックセットアップを生み、本番での振る舞いが失敗してもテストが通ってしまうことがあります。開発者は次を心掛けて防ぎます:
- 実装の内部ではなく観測可能な振る舞いをテストする。
- 時間、乱数、ネットワーク呼び出しを制御して決定論的にする。
- 失敗をレビューして判断する:本物のバグかテストのバグか環境の問題か。
リスクとリリース頻度に合わせた戦略整合
良い戦略はあなたの出荷方法に合致します。リリースが速いほど自動化チェックと明確なロールバック経路が必要で、ゆっくりなら事前検証を重くできる。品質のオーナーはツールではなくチームです。
重要な成果を測る
品質はカバレッジ割合ではありません:テストが改善しているかを次で測りましょう:本番インシデントの減少、復旧の迅速化、より安全な変更(小さなロールバック、速やかなデプロイ自信)。AIは作業を速めますが、説明責任は開発者に残ります。
セキュリティ、プライバシー、コンプライアンスの責任
セキュリティ作業はコード生成ではなく、現実的な制約の下でトレードオフを行うことに関するものです。AIはチェックリストや一般的な間違いを浮かび上がらせることはできますが、リスク判断の責任はチームに残ります。
脅威モデリングは文脈が必要
脅威モデリングは一般論的な運動ではありません—重要なのはあなたのビジネス優先度、ユーザー、失敗モードに依存します。アシスタントは典型的な脅威(インジェクション、認証破壊、安全でないデフォルト)を提案できますが、あなたのプロダクトにとって真に高コストなもの(アカウント乗っ取りかデータ漏洩か、サービス中断か)を確実に知ることはできません。
アプリ固有のリスクはパターンに見えない
AIは既知のアンチパターンを認識するのが得意ですが、多くのインシデントはアプリ固有の詳細(権限のエッジケース、一時的な管理エンドポイント、承認を迂回するワークフロー)から発生します。こうしたリスクはシステムの意図を読む必要があります。
シークレット、権限、保持は意図的な選択
ツールはキーをハードコードしないように促せますが、完全なポリシーを所有することはできません:
- シークレットの保管場所(Vault、CI、ランタイム)とローテーション方法
- 最小権限の役割とアクセスレビュー
- データ保持:何を、どのくらいの期間、誰がエクスポートできるか
依存関係とサプライチェーンリスク
AIは古いライブラリを指摘するかもしれませんが、チームはバージョンの固定、出所の検証、推移的依存のレビュー、リスクを受け入れるか修復に投資するかを決める実践が必要です。
コンプライアンスと監査は証拠を必要とする
コンプライアンスは「暗号化を追加する」だけではありません。コントロール、ドキュメント、説明責任が必要です:アクセスログ、承認の記録、インシデント手順とそれに従った証拠。AIはテンプレートを下書きできますが、証拠を検証し署名するのは人間です—監査人や顧客が最終的に頼るのはその証拠です。
運用、信頼性、インシデント対応
コンプライアンスに合わせてデプロイする
データ転送やプライバシー要件に合わせて、アプリの実行場所を選ぶ。
AIは運用作業を速くできますが、所有権を奪うものではありません。信頼性は不確実性の下での意思決定の連鎖であり、誤った判断のコストは遅さのコストよりも高いことが多いです。
日常業務でAIが助けるところ
AIは運用資料(ランブック、チェックリスト、「もしXならYを試す」プレイブック)の下書きや維持、ログ要約、類似アラートのクラスタリング、一次的な仮説提案に有用です。これにより以下が速くなります:
- モニタリングダッシュボードとアラート記述の作成
- キャパシティノートやスケーリングのヒューリスティクス
- エラーバジェット報告のテンプレート作成
これらは迅速化のアクセラレータですが、作業そのものではありません。
人間が引き続き所有する部分
インシデントは脚本通りに進まないことがほとんどです。オンコールエンジニアは不明確なシグナル、部分的な障害、限られた時間でのトレードオフに対処します。AIは可能性のある原因を示唆できますが、別チームを呼ぶべきか、機能を無効化すべきか、データ整合性を守るために一時的な顧客影響を受け入れるべきかを確実に決めることはできません。
デプロイの安全性も人間の責任です。ツールはロールバック、フィーチャーフラグ、段階的リリースを勧められますが、チームはビジネス文脈と影響範囲を踏まえて最も安全な道を選ぶ必要があります。
ポストモーテム:学習が目的
AIはタイムラインの草案とチャット、チケット、監視からの主要イベント抽出を下書きできます。人間が行う重要な部分は「良い状態とは何か」を決め、修正事項の優先順位をつけ、再発を防ぐために実際に変更することです(単に同じ症状を繰り返さないための対処ではなく)。
AIをオペスの書類作成とパターン発見のコパイロットとして扱えば、速度を得つつ説明責任を手放すことはありません。
チームコミュニケーション、メンタリング、所有権
AIは「CQRSって何?」「なぜこれでデッドロックが起きるのか?」「このPRを要約して」といった概念を即座に説明できます。これはチームの高速化に寄与します。しかし職場でのコミュニケーションは情報伝達だけではなく、信頼を築き、共有された習慣を確立し、人々が頼れる約束をすることでもあります。
オンボーディング:ドキュメント以上のもの
新人は答えだけでなくコンテキストと関係性を必要とします。AIはモジュールの要約、読書パスの提案、専門用語の翻訳で助けられますが、「ここで重要なこと」「このコードベースでの良いとは何か」「何かおかしいと感じたら誰に聞くか」を教えるのは人間です。
役割間の合意形成
プロジェクトの摩擦は大抵、役割間(プロダクト、デザイン、QA、セキュリティ、サポート)で発生します。AIは会議ノートを下書きし、受け入れ基準を提案し、フィードバックを中立的に言い換えることはできます。優先順位を交渉し、曖昧さを解消し、ステークホルダーが「同意しているように見えて実は同意していない」ことに気付くのは人です。
Doneの定義と所有権の境界
責任があいまいだとチームは失敗します。AIはチェックリストを生成できますが、強制はできません。人間が「完了」の定義(テスト?ドキュメント?ロールアウト計画?モニタリング?)と、マージ後に誰が何を所有するかを定義する必要があります—特にAI生成コードが複雑さを隠している場合は重要です。
チェックリスト:チームワークフローにおける責任あるAI利用
- 意思決定、見積もり、または作成コードに影響する場合はAI使用を開示する。
- 事実(リンク、API、セキュリティ主張、ベストプラクティス)は共有前に検証する。
- プロンプトに秘密を入れない(鍵、顧客データ、インシデント詳細)。
- AI出力を草案とみなし、各決定に対して人間のオーナーを割り当てる。
- チーム規範を書く:いつAIを許可するか、いつ禁止するか、期待値をレビューする。
- 小さくレビュー可能な変更を好む—“一斉大改修”のAIリファクタは避ける。
よくある質問
「置き換え/拡張/そのまま」フレームワークは具体的に何を意味する?
ツールが実行を助けるタスクと、チームが成果として責任を負う責任を分けて考えるためのフレームワークです。
- 置き換え(Replace): ガードレールがあれば、AIが多くの場合タスクをエンドツーエンドで完了でき、人間は監督やスポットチェックを行う。
- 拡張(Augment): AIは作業を高速化するが、何が正しく安全かを判断するのは人間。
- そのまま(Untouched): 文脈やトレードオフ、説明責任が必要なため、人間が主導する責任が残る。
なぜタスクではなく責任に注目するの?
なぜなら、チームは“タスク”を出荷するのではなく“成果”を出荷するからです。
アシスタントがコードやテストを下書きしても、チームが依然として負うものは:
- 正しさと回帰の防止
- セキュリティとプライバシー
- 運用性とインシデント影響
- 実際の要求(ただのプロンプトではない)を満たすこと
つまり、責任に焦点を当てるべきです。
AIが安全に置き換えできる開発作業の種類は?
「置き換え」と呼べるのは、境界が明確で検証しやすく低リスクな作業です。
代表例:
- 既存パターンに従うボイラープレートやグルーコード
- 名前変更などの機械的リファクタ
- レビュー付きの初期ドキュメントや変更履歴
- よく定義された純関数のスターターユニットテスト
「置き換え」を実務で信頼できるようにするためのガードレールは?
エラーを明白かつ安価にするガードレールを使うこと:
- リクエストを制約する(範囲、対象ファイル、規約、依存関係を明確に)
- テストを必須にして実行する(lint/型チェックも)
- 差分をバルク編集として確認する—「余計な改善」を警戒する
- ドキュメント中の事実は検証する(セットアップ手順、デフォルト、エッジケース)
- 変更は小さく、巻き戻し可能にする
なぜプロの工学ではAIは大抵「拡張」であって「置き換え」ではないの?
プロフェッショナルな開発では隠れた制約が多いため、多くの場合AIは「拡張」になるからです。モデルが推測しにくいもの:
- 互換性の期待値(後方互換)
- 性能やレイテンシの予算
- 運用面の現実(デプロイ、オンコール、フィーチャーフラグ)
- プロダクトの意図やエッジケースの意味合い
AIの出力は下書きとして扱い、自分のシステムに合わせて手を入れてください。
デバッグでAIを使うとき誤誘導されないようにするには?
AIを結論ではなく仮説と証拠プランを出す道具として使ってください。
実用的なループ:
- 複数のあり得る原因と、それらを区別するための証拠をAIに求める
- 問題を再現し、ログ・トレース・設定・データ形状などの証拠を集める
- 観測される失敗が変わることを確認したら修正を受け入れる
検証できない提案は、証明されるまで間違っていると仮定してください。
コードレビューでAIはどんな役割を果たすべき?
AIは問題を見つける手助けをするが、人間が何を出荷するかを決める。
有効なAIレビューの使い方:
- 「潜在的なエッジケースと失敗モードを列挙して」
- 「セキュリティ/プライバシーのリスクと危険なデフォルトをチェックして」
- 「後方互換性の懸念を指摘して」
その後、人間が意図、保守性、リリースリスク(ブロッキングかフォローアップか)を判断する。
AIはテストと品質の責任を引き継げる?
AIは多くのテストを下書きできるが、どのカバレッジが重要かを決める責任は負えない。
人間が引き続き責任を持つこと:
- ユニット/統合/E2E/契約/性能テストの適切な混合を決めること
- フレークテストを防ぐ(時間や乱数、ネットワークを制御)
- 実装の詳細ではなく振る舞いをテストすること
- リスクとリリース頻度に応じてテストに投資すること
AIはスキャフォールディングやエッジケースの検討に使い、品質責任者は人間であるべきです。
なぜ要件定義やシステム設計は「そのまま(untouched)」の責任なの?
というのも、これらの決定はビジネス文脈や長期的な説明責任に依存するため、自動化に向かないからです。
AIができること:
- アーキテクチャやトレードオフを提案する
- 失敗モードやAPIの矛盾点をブレインストーミングする
- 決定ドキュメントの草案を作る
しかし人間が決めるべきこと:
- 実際に重要な制約(予算、チームのスキル、オンコール体制)
- サービス境界やデータ所有権、バージョニング方針
- 部分的障害時の許容される挙動
セキュリティ/プライバシー/コンプライアンスの制約下でAIを安全に使うには?
秘密情報や顧客データをプロンプトに貼り付けないでください。
実践的ルール:
- 鍵、トークン、認証情報、社内エンドポイントは伏せる
- 顧客識別子や機密なインシデントタイムラインは避ける
- 最小再現例やサニタイズしたログに集中する
- AI利用が意思決定、見積もり、作成コードに影響する場合は開示するチーム規範を持つ