2025年8月26日·1 分
AI搭載の管理ダッシュボード用ウェブアプリの作り方
AIによるインサイト、厳格なアクセス制御、信頼できるデータ、計測可能な品質を備えた管理ダッシュボードの設計、構築、ローンチ手順を段階的に解説します。
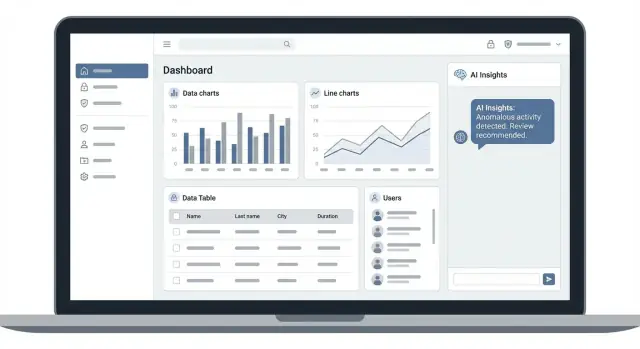
AIによるインサイト、厳格なアクセス制御、信頼できるデータ、計測可能な品質を備えた管理ダッシュボードの設計、構築、ローンチ手順を段階的に解説します。
チャートを描いたりLLMを選んだりする前に、誰のためのダッシュボードで、どんな意思決定を支援するかを明確にしてください。管理ダッシュボードが失敗する最大の原因は「誰にでも使える」ことを目指してしまい、結局誰の役にも立たなくなることです。
ダッシュボードにログインする主要なロール(一般的には ops、support、finance、product)を列挙し、各ロールが毎日/毎週行う上位3~5の意思決定を書き出します。例:
もしウィジェットが意思決定に寄与しないなら、それはノイズである可能性が高いです。
「AI搭載の管理ダッシュボード」は、小さな具体的ヘルパーの集合に翻訳されるべきで、汎用チャットボットを付け足すだけではありません。よく効くAI機能の例:
即時更新が必要なワークフロー(不正チェック、障害、支払いの停止など)と、毎時/毎日更新で問題ないワークフロー(週次の財務サマリー、コホートレポート)を分けてください。この選択が複雑さ、コスト、AI回答の鮮度に直結します。
実運用での価値を示すアウトカムを選びます:
改善を測れなければ、AI機能が役立っているのか、単に作業を生み出しているだけなのか判定できません。
画面やAIを設計する前に、ダッシュボードが実際に頼るデータとその関係性を明確にしてください。管理ダッシュボードの痛みの多くは定義の不一致(「アクティブユーザーとは何か」)や隠れたソース(「返金はDBではなく請求ツールにある」)から発生します。
「真実」が存在する場所をすべて挙げます。多くのチームで含まれるのは:
各ソースについて、誰が所有しているか、アクセス方法(SQL/API/エクスポート)、共通キー(email、account_id、external_customer_id)を記録します。これらのキーが後の結合を可能にします。
管理ダッシュボードは、どこにでも現れる少数のエンティティを中心に作ると最適です。典型は users、accounts、orders、tickets、events です。過剰にモデリングせず、管理者が実際に検索・調査するものだけを選んでください。
シンプルなドメインモデルの例:
これは完璧なDB設計の話ではなく、レコードを開いたとき管理者が「何を見ているか」を合意することが目的です。
重要なフィールドや指標ごとに、誰が定義を所有するかを記録してください。例えば、MRR は Finance、First response time は Support、Activation は Product が所有する、など。所有権が明確だと、矛盾の解決や数値の静かなる変更を避けやすくなります。
ダッシュボードは異なる更新ニーズのデータを組み合わせます:
遅延到着イベントや後からの修正(後日投稿される返金、遅延配送のイベント、手動調整)に対する扱いも決めてください。どこまで遡ってバックフィルを許容するか、履歴をどのように訂正して表示するかを定めないと、管理者の信頼を損ないます。
シンプルなデータ辞書(ドキュメントで十分)を作り、命名と意味を標準化してください。含めるべき項目:
これはダッシュボード分析と後のLLM統合の参照点になります。AIは与えられた定義の一貫性に依存します。
良い管理ダッシュボードのスタックは目新しさよりも予測可能な性能を重視します:高速なページ読み込み、一貫したUI、AIを絡めてもコア業務がもつれない拡張経路。
チームが採用・維持できる主流フレームワークを選んでください。**React(Next.js)やVue(Nuxt)**は管理パネルに向いています。
デザインを一貫させ、開発を速めるためにコンポーネントライブラリを使いましょう:
コンポーネントライブラリはアクセシビリティや標準パターン(テーブル、フィルタ、モーダル)も支援します。管理パネルではカスタムビジュアルよりもこれらが重要です。
どちらでも動きますが、一貫性の方が重要です。
/users、/orders、/reports?from=...&to=...迷うならまずREST+適切なクエリパラメータとページングで始めて、必要になれば後からGraphQLをゲートウェイとして追加可能です。
多くのAI搭載管理ダッシュボードでは:
一般的なパターンは「高コストなウィジェットをキャッシュする」ことです(上位KPIやサマリーカードを短いTTLでキャッシュし、ダッシュボードを瞬時に保つ)。
LLM統合はサーバー側で行い、キーを保護しデータアクセスを制御してください。
RBAC、テーブル、ドリルダウンページ、AIヘルパーを備えた説得力のあるMVPを迅速に出すなら、Koder.ai のようなビジュアルコーディングプラットフォームが開発サイクルを短縮できます。チャットで画面やワークフローを記述すると、React フロントエンドと Go + PostgreSQL のバックエンドを生成してエクスポートでき、スナップショット/ロールバック機能はプロンプトテンプレートやAI UIを破壊せずに反復する際に有用です。
[Browser]
|
v
[Web App (React/Vue)]
|
v
[API (REST or GraphQL)] ---> [Auth/RBAC]
| |
| v
| [LLM Service]
v
[PostgreSQL] <--> [Redis Cache]
|
v
[Job Queue + Workers] (async AI/report generation)
この構成はシンプルに保たれ、段階的にスケールでき、AI機能が全てのリクエスト経路に絡みつくことを防ぎます。
管理ダッシュボードは「何が問題か?」と「次に何をすべきか?」を素早く答えられるかで評価されます。実際の管理作業を中心にUXを設計し、迷いにくくしてください。
管理者が日常的に行う上位のタスク(例:注文の返金、ユーザーのブロック解除、スパイクの調査、プランの更新)に基づいてナビゲーションをグループ化します。基盤となるデータが複数テーブルにまたがっていても構いません。
よく効くシンプル構成:
管理者は検索、フィルタ、ソート、比較を頻繁に繰り返します。これらを常に利用しやすく、挙動を一貫させてください。
チャートはトレンド把握に有効ですが、管理者はレコード単位の正確さを求めます。次を使い分けてください:
早い段階で十分なコントラスト、フォーカス状態、キーボード操作(テーブル制御やダイアログ)を実装してください。
また、すべてのウィジェットに対して空/読み込み/エラー状態を用意します:
プレッシャー下で予測可能なUXが維持できれば、管理者の信頼と作業速度は向上します。
管理者はダッシュボードを「AIと話す」ためではなく、意思決定と問題解決のために開きます。AIは反復作業を減らし、調査時間を短縮し、ミスを減らすものでなければなりません。新たな管理対象を増やすべきではありません。
日々の手作業を置き換える、狭く説明可能で検証しやすい機能を選んでください。
よく効く候補:
出力が編集可能でリスクが低い場合(サマリー、下書き、内部メモ)はAIに書かせる。ヒトの確認が必要な場合(推奨次アクション)はAIに提案させる。
実用的なルール:金銭、権限、顧客アクセスに影響する誤りが起こり得る場合、AIは「提案のみ」を行い、実行は管理者に委ねること。
AIのフラグや推奨には必ず小さな「なぜこれが表示されたか?」説明を付け、使用したシグナルを示してください(例:「過去14日で支払い失敗が3件」や「リリース1.8.4後にエラー率が0.2%→1.1%に上昇」)。これが信頼構築につながり、データ異常の発見を助けます。
権限不足、機微なリクエスト、未サポート操作のときはAIが拒否する条件を定め、曖昧な選択や矛盾するメトリクス、期間指定不足などでは追加の確認を要求するようにしてください。これにより体験が集中し、不正確な出力を減らせます。
管理ダッシュボードは請求、サポート、プロダクト使用、監査ログ、内部メモなどデータが点在しています。AIアシスタントは迅速かつ安全に一貫したコンテキストを組み立てられるかに依存します。
まず短縮したい管理タスクから始めます(例:「なぜこのアカウントがブロックされたか?」、「この顧客の最近のインシデントをまとめて」)。その上で、最小限で予測可能なコンテキスト入力を定義します:
回答に影響しないフィールドは含めないでください。
コンテキストを独立したプロダクトAPIとして扱い、サーバー側のコンテキストビルダーが最小JSONペイロードを生成するようにします。必要なフィールドのみを含め、機密データはマスクまたは除去します(トークン、完全なカード情報、住所の全表記、原文メッセージなど)。
デバッグ/監査のために以下を含めます:
context_versiongenerated_atsources(どのシステムがデータを供給したか)redactions_applied(何を削ったか)全てのチケットやノートをプロンプトに詰め込むのはスケールしません。代わりに、ノートやKB、プレイブック等をインデックス化し、リクエスト時に関連スニペットだけを取得して渡すパターンが有効です。
単純な流れ:
これによりプロンプトを小さく保ち、回答を実データに根拠づけられます。
AI呼び出しは失敗することがあります。設計上の対策:
多くの管理クエリは繰り返されます(「アカウントヘルスをまとめて」など)。エンティティ+プロンプトバージョンで結果をキャッシュし、ビジネス意味に基づいて期限を設けます(ライブ指標なら15分、サマリーは24時間など)。必ず「as of」タイムスタンプを付けて、回答の鮮度を明示してください。
管理ダッシュボードは高トラスト環境です:AIは運用データを見て意思決定に影響を与えます。良いプロンプトは「巧みな言い回し」よりも、構造化、境界の明確化、追跡可能性が重要です。
すべてのAIリクエストをAPI呼び出しとして扱い、入力を明確な形式(JSONまたは箇条書き)で渡し、特定の出力スキーマを要求してください。
たとえば、次を指示します:
これにより自由な創作を減らし、検証しやすい応答が得られます。
機能間でテンプレートを統一してください:
明示的なルールを追加します:秘密を出さない、提供された範囲以外の個人データを扱わない、危険な操作(ユーザー削除、返金、権限変更)は人の確認なしに行わない、等。
可能なら**出典(citation)**を必須にしてください:各主張にソースレコード(チケットID、注文ID、イベントタイムスタンプ)をリンクする。モデルが出典を示せない場合は、その旨を明言させます。
プロンプト、取得したコンテキスト識別子、出力をログに残して再現できるようにします。敏感フィールド(トークン、メール、住所)はマスクして保存し、アクセス制御されたログとして保管します。これにより「なぜAIがこれを提案したのか?」に答えられるようになります。
管理ダッシュボードは権限を集中させます:ワンクリックで価格を変えたり、ユーザーを削除したり、機密データを露出できます。AIが介在すると影響はさらに大きくなります。セキュリティは後付けではなくコア機能として扱ってください。
データモデルやルートが変化している段階でも早期にロールベースアクセス制御を導入してください。小さなロールセット(Viewer、Support、Analyst、Admin 等)を定義し、権限はロールに紐付け、個別ユーザーに直接付与しない方が管理しやすいです。
実用的には、ドキュメント上に「誰がこれを見られるか/変更できるか」を示す権限マトリクスを用意し、それをAPIとUIの設計に反映させてください。これで権限の暴走を防げます。
ページへのアクセスだけで終わらせず、少なくとも次の2レベルに分けます:
広い可視性を付与する際に、誤って重要操作まで許してしまわないようにするためです。
UI上でボタンを隠すのはUX向上に役立ちますが、セキュリティはUIチェックに頼ってはいけません。すべてのエンドポイントで呼び出し元のロール/権限を検証してください:
重要な操作をログに残し、誰がいつどこから何を変えたかを答えられるようにします。最低限、次を記録:操作者のユーザーID、アクション種別、対象エンティティ、タイムスタンプ、変更前後(または差分)、リクエストメタ(IP/User-Agent)。監査ログは追記のみ(append-only)にし、検索可能で改ざん防止の保護を付けます。
セキュリティ前提と運用ルール(セッション管理、管理者アクセス手順、インシデント対応の基本)を文書化します。セキュリティページを用意して製品ドキュメントからリンクすると、管理者や監査人が期待値を確認できます(例:/security)。
APIの形がUIの快適さを決めます。単純なルール:UIが実際に必要とする形(一覧、詳細、フィルタ、いくつかの集計)でエンドポイントを設計し、応答形式を予測可能に保つこと。
主要画面ごとに少数のエンドポイントを定義してください:
GET /admin/users、GET /admin/ordersGET /admin/orders/{id}GET /admin/metrics/orders?from=...&to=...GET /admin/dashboard のような「全部返す」エンドポイントは避けてください。肥大化してキャッシュしにくくなり、部分更新が難しくなります。
管理テーブルは一貫性が命です。サポートすべきは:
limit、cursor または page)sort=created_at:desc)status=paid&country=US)フィルタの意味を途中で変えないこと(URLをブックマークや共有する運用を考慮する)も重要です。
大きなエクスポートや長時間かかるレポート、AI生成は非同期で扱います:
POST /admin/reports → job_id を返すGET /admin/jobs/{job_id} → ステータス+進捗GET /admin/reports/{id}/download で準備完了時にダウンロードこのパターンは「AIサマリー」や「下書き生成」にも適用してUIの応答性を保ちます。
フロントエンドが明確に表示できるようエラーを標準化してください。例:
{ "error": { "code": "VALIDATION_ERROR", "message": "Invalid date range", "fields": { "to": "Must be after from" } } }
これによりAI機能でも「何が悪いのか」具体的に提示でき、曖昧な "something went wrong" を避けられます。
優れた管理ダッシュボードのフロントエンドはモジュール化されています:新しいレポートやAIヘルパーを追加しても全体を作り直す必要がない構造にします。小さな再利用ブロックを標準化し、その振る舞いをアプリ全体で一貫させてください。
コアの「ダッシュボードキット」を作成します:
これらが画面の一貫性を保ち、ワンオフのUI判断を減らします。
管理者はビューをブックマークし共有します。主要な状態をURLに含めてください:
?status=failed&from=...&to=...)?orderId=123 でサイドパネルを開く)保存済みビュー(「My QA queue」、「過去7日間の返金」)を実装すると、ユーザーが同じクエリを繰り返し作らずに済み、ダッシュボードが高速に感じられます。
AI出力を最終回答ではなく下書きとして扱ってください。サイドパネル(あるいは「AI」タブ)には:
常にAI出力にラベルを付け、どのレコードがコンテキストとして使われたかを示してください。
AIがアクションを提案する場合はレビュー手順を必須にします:
何が重要かを計測します:検索使用率、フィルタ変更、エクスポート、AIの開封/クリック率、再生成頻度、フィードバック。これらのシグナルでUI改善やどのAI機能が時間を節約しているかを判断します。
管理ダッシュボードのテストはピクセルではなく「現実条件下での信頼性」が重要です:古いデータ、遅いクエリ、不完全な入力、素早く操作するパワーユーザーなど。
絶対に壊れてはならないワークフローの短いリストから始め、ブラウザ+バックエンド+DBを含むE2Eテストを自動化してください。これにより統合バグを検知できます。
必須フロー例:ログイン(ロール含む)、グローバル検索、レコード編集、レポートのエクスポート、承認/レビューアクション。少なくとも一つは現実的なデータサイズでのテストを入れて、パフォーマンスの退化を検知できるようにしてください。
AI機能用に20~50件のプロンプトからなる評価セットを作成し、各プロンプトに対して期待される「良い」回答といくつかの「悪い」例(幻覚、ポリシー違反、出典欠如)を用意します。これをリポジトリでバージョン管理して、プロンプトやモデルの変更をコードレビューのように扱えるようにします。
シンプルな指標を追跡します:
またプロンプトインジェクションなどの敵対的入力でガードレールが機能するかもテストしてください。
モデルのダウン時に備え、AIパネルを無効化して純粋な分析表示に戻せるようにし、コアの操作は使えるままにしておきます。フィーチャーフラグがあるならAIをフラグの後ろに隠して、素早くロールバックできるようにしてください。
最後にプライバシーを確認:ログをマスクし、識別子を含む生プロンプトを保存しない、デバッグと評価に必要な最小限のみを保管する。/docs/release-checklist に簡単なチェックリストを置くと安定して出せます。
AI搭載管理ダッシュボードのローンチは一回きりのイベントではなく、「動く」→「運用に信頼される」への制御された移行です。環境の分離、可視性、明確なフィードバックループを持ったエンジニアリングワークフローとして扱ってください。
開発/ステージング/本番を分離し、データベース、APIキー、AIプロバイダの認証情報をそれぞれ分けます。ステージングは本番と設定をできるだけ近づけ(フィーチャーフラグ、レート制限、バックグラウンドジョブ)、実運用に近い挙動を検証できるようにします。
設定は環境変数経由で行い、一貫したデプロイプロセスを使うとロールバックが予測可能になります。スナップショットとロールバックをサポートするプラットフォーム(例:Koder.ai のスナップショットフロー)を使えば、AI機能の反復も同様に管理できます。
システム健全性とユーザー体験の両方をモニタリングします:
さらに データ鮮度(例:「売上合計が6時間以上更新されていない」) と ダッシュボード読み込み時間(p95が2秒超) のアラートを追加してください。これら2点が最も管理者に混乱を与える要因です(UIは正常に見えてもデータが古い/遅い場合)。
小さなMVPを出し、実使用に基づいて拡張します:どのレポートが毎日開かれるか、どのAI提案が承認されるか、どこで管理者が躊躇するかを観察してください。新しいAI機能はフラグの後ろに置き、短期実験を行ってからアクセスを広げると安全です。
次の一手:/docs に内部運用手順を公開し、もしプランや利用制限を設定するなら /pricing に明記してください。
まず主要な管理者ロール(サポート、オペレーション、ファイナンス、プロダクト)を列挙し、各ロールが週次で下す3~5の意思決定を書き出します。そこからウィジェットやAIヘルパーを、その意思決定を直接サポートする形で設計してください。
実用的なフィルタは:ウィジェットが次の行動を変えないなら、それはノイズである可能性が高い、です。
「AI搭載」とは、汎用的なチャットボットを付け足すことではなく、ワークフローに埋め込まれた少数の具体的なヘルパーを意味します。
すぐに価値が出る代表例:
即時対応が必要な領域(不正検知、障害、支払い停止など)はリアルタイムに。集計やレポート中心のワークフロー(財務の週次サマリー、コホート分析)は時間遅延(毎時/毎日)でよいことが多いです。
この判断が影響するのは:
「真のデータソース」をすべて洗い出すことから始めます。一般的には:
それぞれについて、、アクセス手段(SQL/API/エクスポート)、および(account_id、external_customer_id、email など)を記録してください。これらのキーがデータ連携の成否を決めます。
管理者が実際に検索/トラブルシュートするコアなエンティティを少数に絞ります。よく使われるセットは:Account、User、Order/Subscription、Ticket、Event。
簡単な関係モデルを文書化して(例:Account → Users / Orders、User → Events、Account/User → Tickets)、メトリクスの所有者(例:MRRはFinanceが所有)を明示すると、画面設計やAIプロンプトが共通定義に基づけます。
現実的なベースラインは:
LLM呼び出しはサーバー側で行い、キー保護とアクセス制御を徹底してください。
ナビゲーションをジョブ(やるべき仕事)基準で設計し、頻繁に使う操作(検索・フィルタ・ソート・比較)を常に近くに置きます。
実用的なパターン:
これらでプレッシャー下でも予測可能なUXを維持できます。
繰り返し作業を減らし、調査時間を短縮する機能に注力してください。初期に効きやすいのは:
重要なルール:ミスが金銭/権限/アクセスに影響する場合、AIは提案のみ行い、自動実行はさせないでください。
AIに渡すコンテキストは最小かつ決定論的にします。サーバー側でコンテキストビルダーを作り、エンティティごと(account/user/ticket)に必要最小限のJSONを返すようにしてください。敏感データ(トークン、カード情報、住所の完全表記など)はマスク/除去します。
デバッグ/監査用のメタデータも含めます:
context_versiongenerated_atsourcesredactions_applied初期段階からRBACを導入し、権限はロールに紐付けて明示的に管理します。少なくともロールの想定例は:Viewer、Support、Analyst、Admin のように分け、誰が何を見られる/変更できるかの権限マトリクスを作りましょう。
加えて:
これらは機能ではなく必須要件です。
チケットやナレッジベースなど長いテキストは全文をプロンプトに詰め込まず、検索インデックスから関連スニペットを取得して引用付きで渡す(retrieval)パターンが有効です。