2025年9月01日·2 分
AI支援ワークフローでアイデアからデプロイ済みアプリへ
AI支援ワークフローを用いて、アプリのアイデアからデプロイ済みプロダクトへ移す実践的なエンドツーエンド手順—ステップ、プロンプト、チェックを示します。
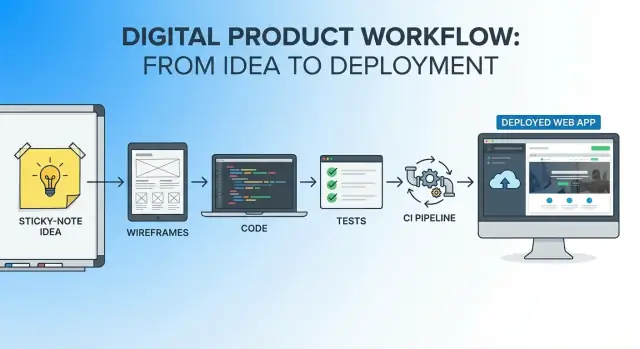
AI支援ワークフローを用いて、アプリのアイデアからデプロイ済みプロダクトへ移す実践的なエンドツーエンド手順—ステップ、プロンプト、チェックを示します。
小さくて有用なアプリのアイデアを想像してください:カフェのスタッフがボタン一つで顧客を待ちリストに追加し、席が用意できたら自動でSMSを送る「Queue Buddy」。成功の指標はシンプルで測定可能です:2週間で平均待ち時間に関する混乱による電話を50%削減し、スタッフのオンボーディングは10分以下に抑えること。
この記事の精神はこうです:明確で限定されたアイデアを選び、「うまくいった」を定義し、ツールやドキュメント、思考モデルを行ったり来たりせずにコンセプトから本番デプロイまで進めること。
単一ワークフローとは、アイデアの最初の一文から最初の本番リリースまでの一つの継続したスレッドです:
複数のツール(エディタ、リポ、CI、ホスティング)は使いますが、各フェーズでプロジェクトを「再起動」することはありません。物語と制約がそのまま継続します。
AIがもっとも価値を発揮するのは:
しかし、プロダクトの意思決定をAIに任せてはいけません。あなたが決定します。ワークフローは常に検証するように設計されています:この変更は指標を動かすか?安全に出荷できるか?
次のセクションで順を追って進めます:
これらを終える頃には、アイデアからライブアプリへ移す再現可能なやり方を持ち、スコープ、品質、学習を密に結びつけられるはずです。
AIに画面やAPI、DBテーブルを生成させる前に、ターゲットを鋭くしておく必要があります。ここでの少しの明確化が、後で何時間もの「ほぼ正しい」出力を節約します。
あなたが作るのは、特定の人々が繰り返し直面する摩擦を取り除くためのアプリです:その人たちは現在のツールで重要な作業を素早く、確実に、安心して完了できていません。v1の目標は、ワークフローの一つの痛いステップを取り除くことです―すべてを自動化しようとせず、ユーザーが「Xをやる必要がある」から「Xが終わった」へ数分で移れるようにし、何が起きたかの明確な記録を残します。
主ユーザーを一つ選びます。副次的なユーザーは後回しで良いです。
仮定を可視化しておかないと良いアイデアは静かに失敗します。
v1は出荷可能な小さな勝ちであるべきです。
軽量な要件ドキュメント(1ページ程度)は「良いアイデア」から「実装可能な計画」への橋渡しです。これがフォーカスを保ち、AIアシスタントに適切な文脈を与え、最初のバージョンが数か月のプロジェクトに膨らむのを防ぎます。
読みやすく、スキミングしやすく保ちます。簡単なテンプレート:
成果として記述した5–10機能に留め、ランク付けします:
このランク付けはAIに生成させる計画やコードの優先度付けにも使います:「まずは Must のみ実装して」。
上位3–5の機能に対して2–4の受入基準を付けます。平易でテスト可能な文面にします。
例:
最後に「Open Questions」を短く書きます—チャット一回、ユーザーへの短いヒアリング、または素早い検索で答えられること。
例:「Googleログインは必要か?」「最小限に保存すべきデータは何か?」「管理者承認は必要か?」
このドキュメントは単なる書類仕事ではなく、ビルドの進行に合わせて更新する共有された真実のソースです。
AIにスクリーンを生成させる前に、製品の「物語」を固めます。短いジャーニースケッチが、ユーザーの目的、成功の見え方、どこで問題が起き得るかを全員に示します。
ハッピーパス:主要な価値を提供する最も単純なシーケンスから始めます。
例の一般的フロー:
次に、取り扱いを誤るとコストが高いであろうエッジケースをいくつか追加します:
大きな図は不要です。番号付きリストと注記で、プロトタイピングとコード生成を導けます。
各画面に対して「やるべき仕事」を短く書きます。UI寄りではなくアウトカムに焦点を当てます。
AIと作業する場合、このリストは優れたプロンプト素材になります:「Dashboard を生成して X, Y, Z をサポートし、空/読み込み/エラー状態を含めて」。
「ナプキンスキーマ」レベルで十分です—画面とフローを支えるための情報量で良い。
User → Projects → Tasks の関係や権限に影響するものを明記します。
ミスが信頼を壊すポイントをマークします:
これは過剰設計ではなく、動くデモからローンチ後のサポート地獄に変わるのを防ぐためです。
v1 のアーキテクチャは一つのことをうまくやるべきです:最小の有用なプロダクトを出荷して、自分を窮地に追い込まないこと。良いルールは「1リポジトリ、1デプロイ可能バックエンド、1デプロイ可能フロントエンド、1データベース」。明確な要件が出ない限り余計な要素は追加しません。
典型的なウェブアプリなら現実的なデフォルトは:
サービスの数は最小限に。v1 では「モジュラー・モノリス」(整理されたコードベースだが1つのバックエンド)がマイクロサービスより簡単なことが多いです。
AIファーストの環境でアーキテクチャ、タスク、生成コードを密につなげたいなら、Koder.aiのようなプラットフォームは適しています:v1 のスコープをチャットで説明し、「planning mode」で反復して React フロントエンドと Go + PostgreSQL バックエンドを生成する、といった流れが可能です。レビューとコントロールはあなたの手に残ります。
コード生成前に小さなAPI表を書いて、あなたとAIが同じ目標を共有していることを確認します。例:
GET /api/projects → { items: Project[] }POST /api/projects → { project: Project }GET /api/projects/:id → { project: Project, tasks: Task[] }POST /api/projects/:id/tasks → { task: Task }ステータスコードやエラーフォーマット(例:{ error: { code, message } })、ページネーションの注記を加えます。
v1 をパブリックまたはシングルユーザーで出せるなら認証を省いて速く出荷します。アカウントが必要ならマネージドプロバイダ(メールのマジックリンクや OAuth)を使い、権限はシンプルに「ユーザーは自分のレコードの所有者」という方針にします。実際の使用で役割が必要になったら追加します。
いくつかの実用的な制約を文書化します:
これらは AI に生成させるコードを「動くだけでなくデプロイ可能なもの」に導きます。
モメンタムを殺す最速の方法はツール議論に一週間費やしてまだ動くコードがないことです。ここでの目標は「hello app」に到達すること:ローカルで起動し、画面が見え、リクエストを受けられること。変更は小さく、レビューしやすい状態を維持します。
AIに与えるプロンプトは厳密に:フレームワーク、基本ページ、APIのスタブ、期待されるファイルを指定します。予測可能な慣習を求め、巧妙さは避けます。
良い最初の構成例:
/README.md
/.env.example
/apps/web/
/apps/api/
/package.json
単一リポであれば基本ルート(例:/ と /settings)と1つのAPIエンドポイント(例:GET /health または GET /api/status)を用意するよう指示します。それで配管が動くことが確認できます。
Koder.ai を使っているなら、ここで最小の「web + api + database-ready」スケルトンを要求し、構造と慣習に満足したらソースをエクスポートするのが自然な流れです。
UIは意図的に地味に保ちます:1ページ、1ボタン、1呼び出し。
例の挙動:
これで即時のフィードバックループができます:UIは読み込んだが呼び出しが失敗するなら(CORS、ポート、ルーティング、ネットワーク)調べるべき箇所が明確です。ここで認証やDB、複雑な状態管理は追加しないでください—スケルトンが安定してから行います。
初日から .env.example を用意します。これで「自分の環境では動く」問題を防ぎ、オンボーディングが楽になります。
例:
WEB_PORT=3000
API_PORT=4000
API_URL=http://localhost:4000
README は1分以内に実行できるようにします:
.env.example を .env にコピーこの段階は基礎を整える作業です。小さな勝利ごとにコミットします:「init repo」「add web shell」「add api health endpoint」「wire web to api」。小さなコミットは AI 支援の反復を安全にします:生成変更が問題を起こしたら1日分の作業を失わずに戻せます。
スケルトンがエンドツーエンドで動いたら「全部仕上げる誘惑」を抑え、狭い垂直スライスを作ってデータベース、API、UIに触れさせます。薄いスライスはレビューを早くし、バグを小さくし、AI支援を検証しやすくします。
アプリが機能するために不可欠なモデルを一つ選びます—多くはユーザーが作成・管理する「モノ」です。フィールド、必須か任意か、デフォルトを明確に定義し、リレーショナルDBを使うならマイグレーションを追加します。最初は平凡に保ち、賢い正規化や過度な柔軟性は避けます。
AIにモデルを草案してもらう場合は、各フィールドとデフォルトを一文で説明させてください。説明できないものは v1 に不要な可能性が高いです。
最初のユーザージャーニーに必要なエンドポイントだけを作ります:通常は作成、読み取り、最小限の更新。バリデーションは境界の近く(リクエスト DTO/スキーマ)に置き、ルールを明示します:
バリデーションは仕上げ作業ではなく機能の一部です—後でデータの散らかりが作業を遅らせるのを防ぎます。
エラーメッセージはデバッグとサポートのためのUXです。クライアントには何が失敗してどう直すかを明確に伝え、機微な詳細は返さないようにします。サーバー側のログにはリクエストIDなどの技術的コンテキストを残して、推測なしで追跡できるようにします。
AIに段階的でPRサイズの変更を提案させます:一つのマイグレーション+一つのエンドポイント+一つのテストを頼む、といった具合。チームメイトの変更をレビューするように差分をチェックしてください:命名、エッジケース、セキュリティ前提、この変更が本当にユーザーの「小さな勝ち」を支えているかを確認します。余分な機能が入っていたら削ぎ落として先に進みます。
v1 にエンタープライズ級のセキュリティは不要ですが、ローンチ後にサポート地獄に陥るような予測可能な失敗は避けるべきです。目標は「十分に安全」:悪い入力を防ぎ、デフォルトでアクセスを制限し、不具合時に追跡可能な痕跡を残すこと。
すべての境界を信頼しないものとして扱います:フォーム、APIペイロード、クエリパラメータ、内部Webhookまで。型、長さ、許容値を検証し、保存前にデータを正規化(トリム、ケーシング変換)します。
実用的なデフォルト:
AIにハンドラを生成させる場合は "validate input" とだけ指示するのではなく、明示的な検証ルール(例:「最大140文字」または「次のいずれかである必要がある:…」)を含めるよう頼んでください。
シンプルな権限モデルで十分なことが多いです:
所有権チェックはミドルウェアやポリシー関数に集約して、コードベース中に if userId == … を散らさないようにします。
良いログは「誰に何が起き、どこで起きたか」に答えます。含めるべきは:
update_project, project_id)イベントをログに残し、秘密情報は書かないこと:パスワード、トークン、完全な支払い情報は書きません。
アプリを「十分に安全」と呼ぶ前に確認:
テストは完璧なスコアのためではなく、ユーザーに害を及ぼす失敗、信頼を失わせる問題、または高コストの火消しを防ぐためにあります。AI支援ワークフローでは、テストは生成コードが本当に意図した通りに振る舞うという「契約」でもあります。
大量のカバレッジを追う前に、ミスが高コストになる箇所を特定します。典型的には金銭・クレジット、権限、データ変換、エッジケースのバリデーションです。
これらに対してユニットテストを書きます。小さく特定的に:入力 X が与えられたとき期待する出力 Y(またはエラー)。分岐が多すぎてテストが煩雑なら、その関数は簡潔化するサインです。
ユニットはロジックの不具合を捕まえます;統合テストは「配線」の不具合を捕まえます—ルート、DB呼び出し、認証チェック、UIフローが一緒に動くかどうか。
コアジャーニー(ハッピーパス)を自動化します:
2つの堅実な統合テストは多数の小さなテストより多くの事故を防ぐことがあります。
AIはテストのスケルトンや見落としがちな境界ケースの列挙が得意です。頼むと良いもの:
foo/bar ではなく)生成されたアサーションはすべてレビューしてください。テストは実装の詳細を検証するのではなく振る舞いを検証すべきです。バグが残ってもテストが通るなら、そのテストは役に立ちません。
控えめな目標(例:コアモジュールで60–70%)を設定し、それを指標ではなくガードレールとして使います。安定して再現性のある、CIで速く回るテストに注力します。フレークするテストは信頼を損ねます—信頼がなくなればテストスイートは保護してくれません。
自動化は AI 支援ワークフローが「自分のマシンで動くプロジェクト」から「自信を持って出荷できる手順」へ変わる部分です。目標は派手なツールではなく再現性です。
ローカルと CI で同じ結果を生むコマンドを一本決めます。Nodeなら npm run build、Pythonなら make build、モバイルなら Gradle/Xcode の特定ステップなど。
開発用と本番用の設定は早めに分けます。簡単なルール:dev のデフォルトは便利に、本番のデフォルトは安全に。
{
"scripts": {
"lint": "eslint .",
"format": "prettier -w .",
"test": "vitest run",
"build": "vite build"
}
}
リンターはリスクの高いパターン(未使用変数、危険な非同期呼び出し)を捕まえます。フォーマッタはスタイル論争を差分ノイズにしません。v1 ではルールは控えめにして一貫して適用します。
実用的なゲート順序:
最初のCIワークフローは小さくて構いません:依存をインストールし、ゲートを実行して速やかに失敗させる。それだけで壊れたコードが静かに混入するのを防げます。
name: ci
on: [push, pull_request]
jobs:
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
with:
node-version: 20
- run: npm ci
- run: npm run format -- --check
- run: npm run lint
- run: npm test
- run: npm run build
シークレットの置き場所を決めます:CIのシークレットストア、パスワードマネージャ、またはデプロイ先プラットフォームの環境設定。絶対に git にコミットしないでください—.env を .gitignore に入れ、.env.example を安全なプレースホルダで含めます。
次のステップとして、これらのゲートをデプロイ工程に繋げ、"green CI" が本番への唯一の道となるようにすると良いです。
リリースはボタン一押しではなく再現可能なルーティンです。v1 の目標は単純:スタックに合ったデプロイ先を選び、小さくデプロイし、常に戻れる道を確保すること。
アプリの実行方法に合うプラットフォームを選びます:
「再デプロイしやすさ」を優先することが多く、この段階で「最大のコントロール」を求めることは逆効果です。
ツール切り替えを最小化したいなら、ビルド+ホスティング+ロールバック機能をまとめてくれるプラットフォームを選ぶと良いです。例として Koder.ai はデプロイとホスティングにスナップショットやロールバックをサポートしており、リリースを一方通行の決定ではなく可逆的なステップとして扱えます。
チェックリストを一度書いて毎回使います。短くして実際に守られるように:
リポジトリに /docs/deploy.md として置けばコードに近く保てます。
依存性へ到達できるかを答える軽量のエンドポイントを作ります。一般的なパターン:
GET /health(ロードバランサや稼働監視用)GET /status(基本的なアプリバージョン+依存性チェックを返す)応答は高速かつキャッシュフリーで、安全に(秘密や内部詳細を返さない)保ちます。
ロールバック計画は明示的にします:
デプロイが可逆であれば、リリースは日常業務になり、より頻繁に安全に出せます。
ローンチは最も有用なフェーズの始まりです:実際のユーザーがどう使うか、どこで壊れるか、どの小さな変更が成功指標を動かすかを学びます。目標は、開発時に使った AI 支援ワークフローをそのまま「仮定」ではなく「証拠」に向けて使い続けることです。
まずは次の3問に答えられる最小限の監視を始めます:動いているか?失敗しているか?遅くないか?
稼働チェックは健康エンドポイントへの定期的なアクセスで良いです。エラートラッキングはスタックトレースとリクエストコンテキストを(機微データを集めずに)捕まえます。パフォーマンス監視は主要エンドポイントの応答時間とフロントエンドのページロード指標から始めます。
AIに手伝ってもらうと良い点:
全部を追うのではなく、アプリが機能していることを示すものだけを追います。主要な成功指標を1つ定義し(例:「チェックアウト完了」「最初のプロジェクト作成」「チームメンバー招待」)、小さなファネルを計測します:エントリ → キーアクション → 成功。
AIにイベント名とプロパティの案を出させ、その後プライバシーと明確さの観点で見直します。イベント名は安定的に保つこと—毎週変えるとトレンドが無意味になります。
シンプルなインテークを作ります:アプリ内フィードバックボタン、短い受信用メールエイリアス、軽量なバグテンプレート。週次でトリアージし、テーマでグルーピングし、分析と結びつけて次の1–2改善を決めます。
監視アラート、分析の落ち込み、フィードバックのテーマを新しい「要件」として扱います。同じプロセスに流し込みます:ドキュメントを更新し、小さな変更提案を生成し、薄いスライスで実装し、ターゲットを絞ったテストを追加し、同じ可逆的なリリースプロセスでデプロイします。チームがいる場合は共有の「Learning Log」ページ(/blog や社内ドキュメントへのリンク)を用意すると決定が見える化され、再現可能になります。
「シングルワークフロー」は、アイデアから本番までの次の要素が一続きになっていることを指します:
複数のツールを使っても構いませんが、各フェーズでプロジェクトを“再起動”するのを避けます。
AIは「オートパイロット」にならないように次の用途で使います:草案や選択肢の生成、少しずつレビュー可能なスターターコードやテストの生成、見落としがちなエッジケースの列挙(バリデーション、権限、ログなど)。
使い方のルールを明確に:この変更は指標を動かすか?安全に出荷できるか? を常に確認します。
測定可能な成功指標と厳密な v1 の「完了定義」を設定します。例:
これらに寄与しない機能は v1 の非目標とします。
目を通しやすい1ページの軽量PRD(必要な要素のみ)を用意します:
その上でコア機能を5–10個に絞り、Must/Should/Nice にランク付けします。AI に生成させる計画やコードはこの順位に従って制限します。
上位3–5機能には、それぞれ2–4のテスト可能な受入基準を追加します。良い受入基準は:
例:バリデーションルール、想定されるリダイレクト、エラーメッセージ、権限挙動(例:権限のないユーザーは明確なエラーを見てデータ漏洩がない)など。
まずハッピーパス(主要な価値を届ける最短経路)を番号付きで書き、その後で発生しやすくコストが高い失敗ケースをいくつか挙げます:
簡単なリストで十分です。UI状態、APIレスポンス、テスト作成の指針になります。
v1 には「モジュラー・モノリス」が現実的です:
必要が生じたときだけサービスを追加します。これにより調整コストが下がり、AI支援での反復・リバートが容易になります。
コード生成の前に小さな「API契約」を書きます:
{ error: { code, message } })これがあればフロント、バック、テストの不一致を防げます。
「配管が機能する」ことを証明する“hello app”を目標にします:
/health).env.example と 1 分以内に起動できる README小さなマイルストーンでコミットし、生成された変更が問題を起こしたら戻せるようにします。
AI支援ワークフローで特に重要なテストと CI のゲートは:
CIでは次の順でゲートを設けます:
テストは安定かつ高速であること。フレークは信頼を失わせます。