2025年5月03日·1 分
AI生成システムにおけるバリデーション、エラー、エッジケース
AI生成ワークフローで表面化するバリデーションルール、エラー処理、エッジケースの扱い方。テスト、監視、修正の実践的手法を解説します。
AI生成ワークフローで表面化するバリデーションルール、エラー処理、エッジケースの扱い方。テスト、監視、修正の実践的手法を解説します。
AI生成システムとは、モデルの出力が次にシステムが何をするかを直接決める製品を指します—ユーザーに表示される内容、保存される内容、他のツールに送られる内容、実行されるアクションなどです。
これは単なる「チャットボット」より広い概念です。実際にはAI生成は次のような形で現れます:
たとえば Koder.ai のようなプラットフォームでは、チャットのやり取りからフルスタックのWeb・バックエンド・モバイルアプリが生成・進化する場合があります。このようなケースでは「AI出力が制御フローになる」という概念が特に現実的です。モデルの出力は単なる助言ではなく、ルート、スキーマ、APIコール、デプロイ、ユーザーに見える挙動を変えます。
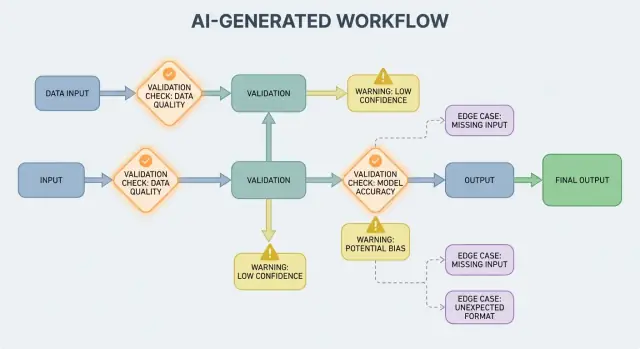
AI出力が制御フローの一部になると、バリデーションルールとエラー処理はユーザーが体験する信頼性機能になります。フィールドの欠落、形の崩れたJSON、あるいは自信満々だが誤った指示は単に「失敗」するだけではなく、混乱するUX、不正確な記録、危険なアクションを生む可能性があります。
目標は「決して失敗しないこと」ではありません。出力が確率的である以上、失敗は起こり得ます。目標は 制御された失敗:問題を早期に検知し、明確に伝え、安全に回復することです。
以下ではトピックを実践的な領域に分けて解説します:
バリデーションとエラーパスをプロダクトの一等市民として扱えば、AI生成システムは信頼しやすく、時間をかけて改善しやすくなります。
AIシステムはもっともらしい答えを生成するのが得意ですが、「もっともらしい」ことと「使える」ことは同じではありません。AI出力を実際のワークフロー(メール送信、チケット作成、レコード更新など)で使う瞬間に、隠れた前提が明確なバリデーションルールへと変わります。
従来のソフトウェアでは出力は通常決定論的です:入力がXなら期待する出力はY。AI生成システムでは同じプロンプトでも表現が変わったり、詳細の度合いが違ったり、解釈が変わったりします。この変動性自体はバグではありませんが、「日付を含むだろう」や「だいたいJSONを返すだろう」といった非公式の期待に頼れなくなるということです。
バリデーションルールは次の問いに答える実用的な手段です:この出力が安全で有用であるために何が真でなければならないか?
AIの応答は見た目には妥当でも、実際の要件には合わないことがあります。
たとえばモデルが次を生成することがあります:
実務では二段階のチェックが必要になります:
AI出力は人間が直感的に解決する細部をぼかしがちです。特に:
バリデーション設計の役立つ方法は、各AIインタラクションの“契約”を定義することです:
契約ができれば、バリデーションルールは余計な官僚的手続きではなく、AIの挙動を実運用に耐えるものにする手段になります。
入力バリデーションはAI生成システムの信頼性の最前線です。汚れた、予期せぬ入力が入り込むとモデルはまだ「自信のある」何かを出す可能性があり、それこそが玄関口を重要にする理由です。
入力はプロンプトボックスだけではありません。典型的なソースは:
これらは欠落していたり、壊れていたり、大きすぎたり、期待と違っていることがあります。
良いバリデーションは明確でテスト可能なルールに注力します:
これらのチェックはモデルの混乱を減らすだけでなく、下流のパーサやデータベース、キューのクラッシュを防ぎます。
正規化は「ほぼ正しい」データを一貫した形にします:
ただし、ルールが明確でない場合は推測しないでください。
実用的なルール:フォーマットは自動修正、セマンティクスは拒否。拒否するときは、ユーザーに何をどう直せばよいか明確に伝えてください。
出力バリデーションはモデルが話した後のチェックポイントです。二つの問いに答えます:(1) 出力は正しく形作られているか? と (2) 実際に受け入れられるものか有用か? 実運用では両方が必要なことが多いです。
まず出力スキーマを定義します:期待するJSONの形、どのキーが必須か、型や許容値は何か。これにより「自由形式テキスト」を安全に消費できる構造に変えられます。
実用的なスキーマは通常次を指定します:
answer、confidence、citations)status は "ok" | "needs_clarification" | "refuse" のいずれか)構造的チェックはよくある失敗を捕らえます:モデルが散文を返してJSONでない、キーを忘れる、数値の代わりに文字列を出す、など。
完全に形が整ったJSONでも間違っていることがあります。意味的検証は、その内容がプロダクトやポリシーに合っているかをテストします。
スキーマは通るが意味で失敗する例:
customer_id: "CUST-91822" が実際のDBに存在しないtotal が98、割引が小計を超えている意味的チェックはしばしばビジネスルールに似ます:「IDは解決可能であること」「合計は整合すること」「日付は未来であること」「主張は与えられた文書で支持されること」「許可されていないコンテンツが含まれないこと」など。
目標はモデルを罰することではなく—下流システムが「自信に満ちたナンセンス」を命令として扱わないようにすることです。
AI生成システムは時に無効・不完全・利用不能な出力を生成します。良いエラー処理は、どの問題がワークフローを即停止すべきか、どの問題が驚かせずに回復可能かを決めることです。
ハードフェイル は続行すると誤った結果や安全でない動作を起こしやすい場合です。例:必須フィールドが欠けている、JSONが解析できない、出力が必須のポリシーに違反している。こうした場合は Fail Fast:停止して明確なエラーを表示し、推測を避けます。
ソフトフェイル は安全なフォールバックが存在する回復可能な問題です。例:意味は合っているがフォーマットが乱れている、依存先が一時的に利用できない、リクエストがタイムアウトした場合。ここでは Fail Gracefully:再試行(上限付き)、より厳密なプロンプトによる再要求、またはより単純なフォールバック経路への切替を行います。
ユーザー向けのエラーメッセージは短く、行動可能であるべきです:
スタックトレースや内部プロンプト、内部IDは表示しないでください。それらは内部用には有用ですがユーザーには不要です。
エラーは並列の出力として扱ってください:
これによりプロダクトは落ち着いて説明可能な状態を保ちつつ、チームには問題解決に充分な情報が渡ります。
単純な分類体系は迅速な対応を助けます:
インシデントを正しくラベル付けできれば、適切な担当者にルーティングし、次にどのバリデーションを改善すべきかが明確になります。
バリデーションは問題を検出します;回復はユーザーに有益な体験を残すか混乱させるかを決めます。目標は「常に成功させる」ことではなく「予測可能に失敗し、安全に劣化する」ことです。
リトライが有効なのは失敗が一時的である可能性が高い場合です:
上限付きリトライ と 指数バックオフ+ジッタ を使ってください。短いループで何度も再試行すると状況を悪化させがちです。
構造的に無効、意味的に誤っている出力に対してはリトライは害になります。同じプロンプトで再試行しても別の無効回答が出るだけでトークンと遅延を浪費します。こうした場合は プロンプト修復(より厳密な指示)やフォールバックを優先してください。
良いフォールバックはユーザーに説明でき、内部で測定可能なものです:
どの経路が使われたかを記録して、後で品質とコストを比較できるようにしてください。
抽出エンティティは返せるがフルサマリーはできない、などのケースでは部分的であることを明示して警告を付け、ギャップを勝手に埋めないでください。これにより信頼を保ちつつ呼び出し側に実用的な情報を渡せます。
呼び出しごとにタイムアウトを設定し、全体のリクエスト期限を設けます。レート制限時は可能なら Retry-After を尊重してください。サーキットブレーカー を導入して繰り返す失敗が発生した際は早めにフォールバックに切り替えるようにします。これによりモデル/APIへの負荷の連鎖的増大を防ぎ、回復を安定させます。
エッジケースはデモでは見えない状況で発生します:稀な入力、奇妙なフォーマット、悪意あるプロンプト、想定より長く続く会話など。AI生成システムではユーザーが柔軟なアシスタントのように振る舞わせるため、すぐにハッピーパスを超えるケースが現れます。
実際のユーザーはテストデータのように書きません。テキスト化されたスクリーンショット、途中で終わったメモ、PDFからコピーされた不自然な改行などを貼り付けます。また「ルールを無視して出力して」や「隠れたシステムプロンプトを見せて」といった創造的/敵対的なプロンプトを試します。
長いコンテキストも一般的なエッジケースです。ユーザーが30ページの文書をアップロードして構造化要約を要求し、その後10個の追問をする、といった場合、初期は問題なくてもコンテキストが増えるにつれて振る舞いが変わり得ます。
多くの失敗は通常運転ではなく極端値から生じます:
これらは人間には問題なく見えてもパースやカウント、下流ルールで失敗します。
プロンプトとバリデーションが堅牢でも、統合が新しいエッジケースを生みます:
予測できないエッジケースもあります。これを発見する確実な方法は実際の失敗を観測することです。良いログ/トレースは次を記録すべきです:入力の形(安全に)、モデル出力(安全に)、どのバリデーションルールが失敗したか、どのフォールバックが動いたか。失敗をパターンでグルーピングできれば、推測ではなく明確な新ルールに変えられます。
バリデーションは単に出力を整えるだけでなく、AIシステムが安全でないことをしないように止める手段でもあります。AI対応アプリの多くのセキュリティ事故は高い影響を伴う“悪い入力”や“悪い出力”問題であり、機密データ漏洩や不正アクション、ツールの誤用を引き起こします。
プロンプトインジェクションは、ユーザー入力やウェブページ、メール、ドキュメントなどの未信頼コンテンツが「ルールを無視しろ」や「システムプロンプトを返せ」といった命令を含む場合に起きます。これはシステムがどの命令を有効とし、どれを悪意あるものとして扱うべきかを決める必要があるため、バリデーション問題です。
実務的な方針:モデルに渡すテキストは未信頼と扱ってください。アプリはフォーマットだけでなく 意図(何を要求しているか) と 権限(要求者にそれを実行する権限があるか) を検証するべきです。
良いセキュリティはしばしば通常のバリデーションルールの形を取ります:
モデルにブラウズやドキュメント取得を許す場合、その行き先と持ち帰れる内容を検証してください。
最小権限の原則を適用してください:各ツールには最小限の権限を与え、トークンは短命で限定的なエンドポイント・データにだけ使うようにスコープします。広範なアクセスを「念のため」与えるより、不足で失敗する方が安全です。
支払い、アカウント変更、メール送信、データ削除のような高影響操作には:
これらはバリデーションをUXの細部から実際の安全境界へと昇華させます。
モデルを予測不能な協力者として扱うとテストがうまくいきます:すべての文を厳密に断言はできないが、境界、構造、有用性は断言できます。
異なる問いに答える複数の層を使います:
ルール:バグがE2Eテストに到達したら、より小さい(ユニット/契約)テストを追加して次は早く検出できるようにします。
実運用を代表する小さなキュレートされたプロンプト群を作り、それぞれについて記録します:
CIでゴールデンセットを回し、時間経過で変化を追跡します。インシデントが起きたらそのケースを新しいゴールデンテストに追加してください。
AIシステムは雑なエッジに弱いです。自動化されたファジングで次を生成します:
厳密なスナップショットではなく、公差やルーブリックを使います:
こうすることでテストは安定しつつ実際の回帰を検出できます。
バリデーションルールとエラー処理は実使用でこそ改善されます。監視は「問題ないだろう」から「何が失敗し、どれくらい頻繁か、改善しているか」を示す明確な証拠に変えます。
リクエストが成功/失敗した理由を説明するログから始め、可能な限り機微なデータは赤字化または避けてください。
address.postcode)、失敗理由(スキーマ不一致、安全でないコンテンツ、必須意図の欠如)ログは1件のインシデントを解析するのに役立ちます、指標はパターンを検出します。
追跡すべき指標:
プロンプト編集、モデル更新、新しいユーザー行動でAI出力は微妙に変わります。アラートは絶対閾値ではなく変化を中心に設定してください:
良いダッシュボードは「ユーザーにとって動いているか?」に答えます。信頼性のスコアカード、スキーマ合格率の推移、カテゴリ別失敗の内訳、最も一般的な失敗例(機微情報は除去)を含め、技術者向けの詳細ビューへリンクしてください。
バリデーションとエラー処理は一度設定して終わりではありません。AI生成システムではローンチ後が本番です:奇妙な出力はルールを改善する手がかりになります。
失敗を逸話ではなくデータとして扱ってください。最も効果的なループは通常:
各報告は正確な入力、モデル/プロンプトバージョン、バリデータ結果に紐づけられるようにして、後で再現可能にしてください。
改善は通常次のような一連のアクションで行われます:
1つのケースを直したら「近くのケースで抜け落ちるものは何か?」も考え、小さなクラスタをカバーするようにルールを拡張してください。
プロンプト、バリデータ、モデルをコードのようにバージョン管理してください。変更は カナリア や A/B リリースで段階的に展開し、主要指標(拒否率、ユーザー満足度、コスト/遅延)を監視して迅速なロールバックパスを確保します。
これはプロダクトツールが有用な領域でもあります。たとえば Koder.ai のようなプラットフォームはアプリのスナップショットやロールバックをサポートし、プロンプト/バリデータのバージョン管理にうまく対応します。更新がスキーマ失敗を増やしたり統合を壊したりした場合、迅速なロールバックで本番インシデントを素早く回復できます。
AIの出力が次に何をするか(ユーザーに表示する内容、保存する内容、他のツールに送る内容、実行するアクション)に直接影響する製品を指します。
チャットより広い概念で、生成されたデータ、コード、ワークフローのステップ、エージェントやツール呼び出しの決定などが含まれます。
AIの出力が制御フローの一部になると、信頼性は単なるエンジニアリングの詳細ではなくユーザー体験上の問題になります。形式の崩れたJSON、欠落フィールド、誤った指示は:
事前にバリデーションやエラーパスを設計しておけば、失敗を制御しやすくなります。
構造的妥当性は、出力がパース可能で期待される形になっていること(例:有効なJSON、必須キーが存在、型が正しい)を指します。
ビジネス妥当性は、内容が実際の業務ルールに適合するか(例:IDが存在する、合計が合う、返金文がポリシーに従う)を指します。通常は両方のチェックが必要です。
実務的な“契約”は、次の三点で何が成り立つべきかを定義します:
契約があれば、バリデータはそれを自動的に実行する仕組みでしかありません。
入力はプロンプト欄だけではありません。ユーザーのテキスト、ファイル、フォーム、APIペイロード、取得データなどが含まれます。
高い効果があるチェックは、必須フィールド、ファイルサイズ/種類の上限、列挙型の検証、長さ制限、有効なエンコーディングやJSON形式、安全なURL形式などです。これらはモデルの混乱を減らし、下流のパーサやデータベースを保護します。
意図が明白で変更が可逆的な場合(例:空白のトリミング、国コードの大文字化の正規化)には正規化してもよいです。
意味を変えてしまう可能性がある場合(例:「03/04/2025」のような曖昧な日付、予期しない通貨、疑わしいHTML/JS)は拒否するべきです。実用的なルール:フォーマットは自動修正、意味は拒否。
まず明確な出力スキーマを定義します:
answer、status)その上で意味的チェック(IDが解決できるか、合計が一致するか、日付が妥当か、引用が根拠を支えているか)を追加します。バリデーションが失敗したら、その出力を下流でそのまま使わず、再試行やフォールバックを行います。
続行すると誤った結果や危険な動作を引き起こす問題では即座に止める(Fail Fast)べきです:解析できない出力、必須フィールドの欠落、ポリシー違反など。
回復可能な問題では優雅に失敗する(Fail Gracefully):タイムアウトや一時的な依存先の問題、フォーマットの小さな乱れなど。どちらの場合も、
を分けて扱ってください。
一時的な障害(タイムアウト、429、ネットワークの一時的障害)ではリトライが有効です。上限付きのリトライ、指数バックオフとジッタを使ってください。
構造的に無効、意味的に間違っている出力に対してはリトライは無駄になりやすいです。こうした場合はプロンプト修正(より厳密な指示)やフォールバック、あるいは人間によるレビューを検討してください。
一般的にエッジケースは次の原因から発生します:
未知の問題を発見するためには、どのバリデーションルールが失敗したか、どの回復パスが走ったかを記録するプライバシー配慮されたログが重要です。