2025年5月13日·1 分
アカウント階層別にプロダクト導入を追跡するWebアプリを構築する
アカウント階層ごとのプロダクト導入を測定するためのデータ設計、イベント設計、ダッシュボードの作り方を学び、アラートや自動化でインサイトに対応する方法を解説します。
アカウント階層ごとのプロダクト導入を測定するためのデータ設計、イベント設計、ダッシュボードの作り方を学び、アラートや自動化でインサイトに対応する方法を解説します。
ダッシュボードを作る前、あるいはイベントを計測する前に、このアプリの目的、誰が使うのか、階層がどう定義されるのかを明確にしておきます。多くの「導入トラッキング」プロジェクトが失敗するのは、データから始めて最終的に定義の不一致でおかしくなるからです。
実用的なルール:もし二つのチームが「導入」を同じ文で定義できないなら、そのダッシュボードは後で信用されません。
主要な利用者と彼らがデータを見て次に何をする必要があるかを命名します:
有用なリトマス試験:各利用者は「で、つまり?」に1分以内で答えられるべきです。
導入は単一の指標ではありません。チームが合意できる定義を書きます—通常はシーケンスとして:
常に顧客価値に基づいてください:探索ではなく、結果を得ていることを示す行動シグナルを基準にします。
階層を列挙し、割り当てを決定論的にします。一般的な階層は SMB / Mid-Market / Enterprise、Free / Trial / Paid、あるいは Bronze / Silver / Gold などです。
ルールは平易な言葉(あとでコードにも落とす)で文書化します:
アプリが可能にすべき意思決定を書き出します。例:
受け入れ基準として使います:
アカウント階層は挙動が異なるため、単一の「導入」指標はSMBを罰したり、Enterpriseのリスクを隠したりします。まず階層ごとに成功の定義を決め、それを反映する指標を選びます。
主要なアウトカムを一つ選びます:
ノースターは数えられ、階層別に分かれ、操作しにくいものであるべきです。
解釈に依存しないよう、採用ファネルを段階と明示的なルールで書きます。
例:
階層差は重要:Enterpriseの「Activated」は管理者アクション かつ エンドユーザーのアクションを要求するかもしれません。
先行指標で早期の勢いを察知します:
遅行指標で耐久的な導入を確認します:
目標は期待される時間対価値(time-to-value)と組織の複雑性を反映すべきです。例:SMBは7日以内の活性化を目標にし、Enterpriseは30–60日以内に連携を目標にするなど。
目標は文書化し、アラートとスコアカードがチーム間で一貫するようにします。
明確なデータモデルは後の「謎の計算」を防ぎます。誰が何を、どのアカウントで、どの階層下で、いつ行ったかを簡単に答えられるようにします。
小さな実務に即したエンティティ群から始めます:
account_id)、名前、ステータス、ライフサイクルフィールド(created_at, churned_at)を保持。\n- User:個人。user_id、メールドメイン、created_at, last_seen_at を含める。\n- Workspace / Project(オプション):製品に複数スペースがある場合は workspace_id と account_id の外部キーで明示的にモデル化。\n- Subscription:請求オブジェクト。プラン、請求期間、席数、MRR、タイムスタンプを保持。\n- Tier:正規化されたテーブル(例:Free, Team, Business, Enterprise)で名称を一貫させる。アナリティクスの「粒度」を明確にします:
実用的なデフォルトはユーザー単位でイベントを記録し、account_id を付けてアカウント単位に集計すること。ユーザーが存在しない場合のみアカウントのみのイベントを使う。
イベントは「何が起きたか」を語り、スナップショットは「何が真であったか」を示します。
「現在の階層」を上書きしてコンテキストを失わないようにします。account_tier_historyテーブルを作成:
account_id, tier_id\n- valid_from, valid_to(現在はnullable)\n- source(billing, sales overrideなど)これにより、アカウントがTeamだった期間の導入を計算でき、後のアップグレードによる歪みを避けられます。
「アクティブユーザーとは何か」「イベントをどうアカウントに紐づけるか」「月中の階層変更をどう扱うか」など、指標定義を一度書いてプロダクト要件として扱います。これにより二つのダッシュボードで異なる真実が表示されることを防げます。
導入分析は収集するイベントの質に依存します。各階層にとって意味ある“クリティカルパス”の行動セットをマップして、Web、モバイル、バックエンドで一貫して計測します。
意味のあるステップを表すイベントに集中します(すべてのクリックは不要):
signup_completed(アカウント作成)\n- user_invited と invite_accepted(チーム成長)\n- first_value_received(“aha”の瞬間;明確に定義)\n- key_feature_used(再現可能な価値アクション)\n- integration_connected(連携が定着を促す場合)すべてのイベントは階層や役割でスライスできる文脈を持つべきです:
account_id(必須)\n- user_id(人物が関与する場合必須)\n- tier(イベント時点でキャプチャ)\n- plan(請求プラン/SKU)\n- role(owner/admin/memberなど)\n- オプション:workspace_id, feature_name, source(web/mobile/api), timestamp予測可能なスキームを使い、ダッシュボードが辞書プロジェクトにならないようにします:
report_exported, dashboard_shared)\n- プロパティ:一貫した名詞(account_id を使い acctId は避ける)\n- 機能イベント:専用イベント(invoice_sent)か feature_name を持つ単一イベントのどちらかに統一匿名と認証済みの両方に対応する:
anonymous_id を割り当て、ログイン時に user_id と紐付ける。\n- マルチワークスペース製品では常に workspace_id を含め、サーバー側で account_id にマッピングしてクライアントのバグを避ける。主要メトリクスがブラウザや広告ブロッカーに依存しないようバックエンドでシステムアクションを計測します。例:subscription_started, payment_failed, seat_limit_reached, audit_log_exported。
これらのサーバー側イベントはアラートやワークフローのトリガーに最適です。
ここで追跡がシステムになります:イベントがアプリから届き、クレンジングされ、安全に保存され、チームが使える指標に変換されます。
多くのチームは混合を使います:
いずれを選んでも、取り込みを契約(contract)として扱う:解釈できないイベントは隔離し、黙って受け入れないこと。
取り込み時に下流のレポーティングを信頼できるようにいくつかのフィールドを標準化します:
account_id, user_id, 必要なら workspace_id。\n- 必須プロパティ(event_name, tier, plan, feature_key)を検証し、明示的でない場合はデフォルトを追加しない。生イベントの保存場所はコストとクエリパターンで決める:
日次/時間単位の集計ジョブで以下のようなテーブルを作成します:
ロールアップは決定論的にして、階層定義やバックフィルが変わったときに再実行できるようにします。
以下の保持方針を明確にする:
導入スコアは忙しいチームにとって1つの監視値になりますが、単純で説明可能であるべきです。0–100のスコアで意味ある行動を反映し、「なぜ動いたか」を分解できるようにします。
重み付けされたチェックリスト(合計100点)から始め、重みは四半期ごとに安定させてトレンド比較が可能なようにします。
例(プロダクトに合わせて調整):
各行動は明確なイベントルールにマップされるべきです(例:「core usage」= core_action が3日別で発生)。スコアが変化したら寄与要素を保存して「+15 点は招待2名のため」や「-10 点は主要利用が3日未満に落ちたため」のように説明できるようにします。
スコアはアカウントごと(日次または週次スナップショット)で計算し、階層ごとに集計するときは分布(中央値、25/75パーセンタイル、閾値以上の割合)で示します。
階層ごとに 週次変化 と 30日変化 を追跡しますが、階層サイズを混ぜない工夫をします:
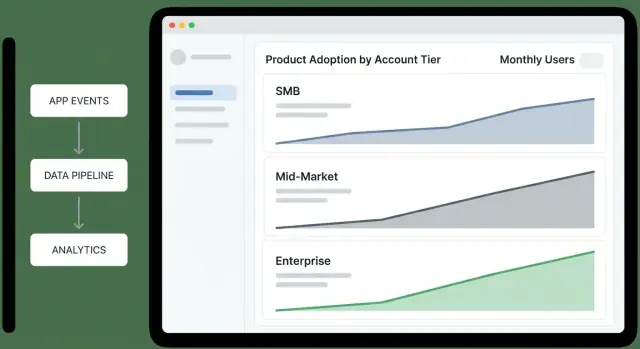
階層概要ダッシュボードは経営が1分以内に「どの階層が改善/悪化しているか、理由は何か」を答えられるようにします。報告の寄せ集めではなく意思決定画面として扱ってください。
Tierファネル(認知 → 活性化 → 習慣化):"階層ごとにどこでアカウントが詰まっているか?" ファネルのステップは製品に合わせて一貫させます(例:「ユーザー招待」→「最初の主要アクション完了」→「週次アクティブ」)。
階層別の活性化率:"新規または再活性化したアカウントがファーストバリューに到達しているか?" 分母(対象となるアカウント数)を併記して小サンプルのノイズを判断できるようにします。
階層別の定着(例:7/28/90日):"初回成功後も使われ続けているか?" 各階層ごとにシンプルなラインを表示し、概要では過度に細分化しないでください。
利用の深さ(機能幅):"複数領域を採用しているか、それとも浅く留まっているか?" 階層ごとに積み上げ棒(1エリア、2–3エリア、4+エリア使用の割合)が有効です。
どこにでも二つの比較を入れます:
絶対的なパーセントポイント差を一貫して使い、経営が素早くスキャンできるようにします。
フィルタは限定的でグローバル、かつスティッキーにします:
あるフィルタが指標定義を変えてしまうなら、概要では提供せずドリルダウンへ誘導します。
各階層に小さなパネルを付け「今期に高い導入と関連があるものは何か?」を示します:
説明可能な形を好みます:例えば「導入から3日以内にXを設定したアカウントは定着が18pp高い」といった具合に、ブラックボックスのモデル出力よりも明確な因果を示します。
上部に階層KPIカード(活性化、定着、深さ)、中央にトレンドチャートを1画面分、下部にドライバーと次のアクションを配置します。各ウィジェットは一つの問いに答えるべきで、それ以外は概要に不要です。
階層ダッシュボードは優先順位を示しますが、実際の作業は「なぜその階層が動いたのか」「誰に対応するか」を掘るところで起きます。ドリルダウンはガイド付きの経路に設計します:階層 → セグメント → アカウント → ユーザー。
階層概要テーブルから出発し、ユーザーがカスタムレポートを作らずに意味のあるセグメントにスライスできるようにします。共通のセグメントフィルタ:
各セグメントページは「この階層の導入スコアを上げ下げしているアカウントはどれか?」に答えるべきです。スコア変化と寄与機能を伴う上位アカウントのランキングを含めます。
アカウントプロフィールはケースファイルのようにしておきます:
スキャンしやすく:差分表示("今週+12")やスパイクに注釈を付けてどのイベントが原因かを示します。
アカウントページからは役割ごとに最近のアクティビティ順にユーザーを並べます。ユーザーをクリックするとその機能利用と最終アクセスの文脈が見えます。
コホートビュー(サインアップ月、オンボーディングプログラム、サインアップ時の階層)を追加し、CSが同じ条件の集団同士で比較して学べるようにします。
階層ごとの「誰が何を使っているか」ビュー:導入率、頻度、トレンド機能を示し、各機能の利用有無でのアカウントリストにワンクリックで行けるようにします。
CSやSales向けにエクスポート/共有オプション(CSV、保存ビュー、フィルタ付きの共有リンク /accounts/{id})を付け、作業フローに組み込みやすくします。
ダッシュボードは理解のために役立ちますが、適切なタイミングでの通知があるとチームは行動します。アラートは階層に紐づけ、CSやSalesが低価値のノイズに溺れないように、あるいは高価値アカウントの重大な問題を見逃さないようにします。
最初は小さなセットで始めます:
これらは階層を考慮して設定します。例:Enterpriseは週次コアワークフローの15%減でアラート、SMBは40%減でないとノイズが多すぎる、など。
拡張アラートは価値増加を示すものにします:
閾値は階層で異なります:SMBでは単一のパワーユーザーでも重要だが、Enterpriseの拡張はマルチチーム採用を要求する、など。
アラートを実際の作業場所にルーティングします:
通知のペイロードは実行可能にします:アカウント名、階層、何が変わったか、比較ウィンドウ、ドリルダウンリンク(例:/accounts/{account_id})。
各アラートにはオーナーと短いプレイブックを割り当てます:誰が対応するか、最初の2–3チェック(データ鮮度、最近のリリース、管理者変更)、推奨される接触方法やアプリ内ガイダンス。
プレイブックは指標定義の隣にドキュメント化しておき、対応が一貫するようにします。
導入指標がCSの介入、価格議論、ロードマップの判断などを左右する場合、データにはガードレールが必要です。簡潔なチェックとガバナンス習慣でダッシュボードの“謎の落ち込み”を防ぎ、ステークホルダーが数値の意味に合意できるようにします。
イベントはできるだけ早く(クライアントSDK、APIゲートウェイ、取り込みワーカーで)検証します。信頼できないイベントは拒否または隔離します。
実装例:
account_id や user_id の欠如(accountsテーブルに存在しない値)\n- 無効な tier 値(許可されたenumにないもの)\n- ありえないタイムスタンプ(未来/過去)や主要イベントの必須プロパティの欠如不正イベントは隔離テーブルで検査できるようにし、分析を汚染しないようにします。
導入トラッキングは時間が重要なので、遅延イベントは週次アクティブや階層ロールアップを歪めます。監視すべき項目:
これらのモニタはオンコールチャネルに送るべきで、全員に送らないようにします。
モバイルネットワーク、ウェブフックの再配信、バッチの再生などでリトライは起こります。idempotency_key や安定した event_id を用い、一定期間内での重複除去を実装します。
集計は再実行しても二重計上しないように設計します。
各指標の入力、フィルタ、時間窓、階層帰属ルールを定義した用語集を作り、それを唯一の真実のソースとして扱います。ダッシュボードやドキュメントからこの用語集(例:/docs/metrics)へリンクします。
指標定義や導入スコアルールの変更履歴(誰がいつ何を変更したか)を残し、トレンドの変化を素早く説明できるようにします。
導入分析は信頼されてこそ有用です。可能な限り最小限の敏感データだけを収集し、「誰が何を見られるか」を設計段階から考えます。
導入洞察に十分な識別子だけを保存します:account_id, user_id(または仮名化ID)、タイムスタンプ、機能、限られた行動プロパティ(プラン、階層、プラットフォーム)。名前、メール本文、フリーテキスト入力、機密が入り得るものは避けます。
ユーザーレベル分析が必要ならPIIとは別にユーザー識別子を保存し、必要時にのみ結合します。IPやデバイス識別子は敏感情報として扱い、スコアに不要なら保持しないでください。
明確なアクセスロールを定義します:
デフォルトは集約ビューにし、ユーザーレベルのドリルダウンは明示的な許可とし、メールアドレスやフルネームなどの敏感フィールドは本当に必要な役割だけに表示します。
削除要求に対応できるよう、ユーザーのイベント履歴を削除または匿名化でき、契約終了時にアカウントデータを削除できるようにします。
保持ルール(生イベントはN日、集計は長めなど)を実装し、方針を文書化します。処理の同意や責任を記録することも忘れないでください。
価値を早く出すには、既にデータがある場所に合ったアーキテクチャを選びます。後で進化させるのは可能です—重要なのは信頼できる階層レベルの洞察を早く人手に渡すことです。
ウェアハウスファースト分析:イベントがウェアハウス(BigQuery/Snowflake/Postgres)に入り、そこで導入指標を計算し、軽量なWebアプリで提供します。SQLに慣れたアナリストがいるチームや、他のレポートと共通の真実を共有したい場合に最適です。
アプリファースト分析:Webアプリがイベントを自前DBに書き込み、アプリ内で指標を計算します。小規模製品では素早く着手できますが、イベント量が増えたり履歴の再処理が必要になったときに行き詰まることが多いです。
多くのSaaSチームには、構成テーブル(階層、指標定義、アラートルール)用の小さな運用DBを置いた上でのウェアハウスファーストが実用的デフォルトです。
まずは次を出します:
フィードバックループを早く組み込み:Sales/CSがダッシュボード上から「これはおかしい」とフラグできるようにします。指標定義にバージョン管理を入れ、履歴を書き換えることなくフォーミュラを変更できるようにします。
段階的に展開(1チーム→組織全体)し、指標更新の変更ログをアプリ内(例:/docs/metrics)に残して、ステークホルダーが常に何を見ているか分かるようにします。
"仕様" から内部アプリの動くプロトタイプへ移すなら、vibe-coding的なアプローチは有効です—特にMVP段階で定義を検証したいときに。これはUI(React)、APIレイヤ、Postgresのデータモデル、スケジュールされたロールアップが絡むため、頻繁に進化します。
Koder.ai を使った一般的なワークフロー:
Koder.ai はデプロイ/ホスティング、カスタムドメイン、コードエクスポートをサポートするため、長期のアーキテクチャ選択(warehouse-first vs app-first)を開いたまま説得力ある内部MVPを作るのに実用的です。
まず、導入を次のシーケンスとしてチームで共通定義します:
さらに、これを階層(tier)別に設計します(例:SMBは7日以内の活性化、Enterpriseは管理者アクション+エンドユーザーのアクションが必要、など)。
階層ごとに行動パターンが異なるため、1つの指標で全体を表すと誤解を招きます:
階層ごとのセグメンテーションにより、現実的な目標設定、各階層に適したノースターメトリクス、そして高価値アカウント向けの適切なアラートを設計できます。
一貫したレポートのために決定論的で文書化されたルールを使います:
account_tier_historyテーブル(valid_from / valid_to)を保持する。こうすることで、アカウントがアップグレード・ダウングレードしても過去のレポートの意味が崩れません。
階層ごとに実際の価値を表す単一のアウトカムを選びます:
数えられ、階層別に分けられ、操作可能であること(容易にゲームできないこと)が重要です。
ステージとその判定ルールを明確に定義し、解釈の余地をなくします。例:
Enterpriseでは「Activated」に管理者のアクションとエンドユーザーのアクションを両方要求するなど、階層差を設けます。
まずは重要経路(critical path)のイベントに絞るべきです:
signup_completed\n- user_invited, invite_accepted\n- first_value_received(“aha”を明確に定義)\n- key_feature_used(機能ごとのイベントや共通イベント)\n- integration_connected進捗を示すイベントに優先度を置き、すべてのUIインタラクションを追うのは避けます。
スライスとアトリビューションを確実にするプロパティを含めます:
account_id(必須)\n- user_id(人物が関与する場合は必須)\n- (イベント時点でキャプチャ)\n- / SKU(該当する場合)\n- (owner/admin/memberなど)\n- オプション:, , , 両方使うのが実用的です:
スナップショットには当日のアクティブユーザー数、主要機能数、導入スコアの構成要素、当日の階層を含め、階層変更が過去データを上書きしないようにします。
シンプルで説明可能、かつ安定した設計にします:
core_actionが14日間で3日以上)。\n- スコア変化時に寄与要素を保存し、「なぜ増減したか」を示せるようにする。階層ごとには分布(中央値、パーセンタイル、閾値以上の割合)で集計し、平均値だけに頼らないようにします。
階層を考慮したアラート設計でノイズを減らします:
アラートは作業が起こる場所へ送る(緊急はSlack/メール、低優先は週次ダイジェスト)。ペイロードにはアカウント名、階層、変化点、比較ウィンドウ、ドリルダウンリンク(例:/accounts/{account_id})を含めます。
tierplanroleworkspace_idfeature_namesourcetimestamp命名は一貫させ(snake_case推奨)、クエリが訳語の翻訳作業にならないようにします。