2025年8月26日·1 分
アプリロジックでモデルを組み込んだAIファーストプロダクトの作り方
モデルが意思決定を担うAIファーストプロダクトの実践ガイド:アーキテクチャ、プロンプト、ツール、データ、評価、安全性、監視について。
AIファーストプロダクトを作るとはどういうことか
「AIを追加する」だけがAIファーストではありません。AIファーストとは、モデルがルールエンジン、検索インデックス、推薦アルゴリズムと同じようにアプリケーションのロジックの一部として実際に動作する、という意味です。
アプリが単にAIを「使う」のではなく、モデルが入力を解釈し、アクションを選択し、システムの他の部分が依存する構造化された出力を生成することを前提に設計されます。
実務上は、すべての意思決定経路をハードコーディングする(「XならYを実行」)代わりに、言語、意図、曖昧さ、優先順位付けなど曖昧な部分をモデルに任せ、コード側は厳密であるべき処理(権限、支払い、DB書き込み、ポリシー適用)を担います。
AIファーストが適している場合(と適していない場合)
AIファーストが最も有効なのは、問題が以下のようなときです:
- 入力が多様(自由テキスト、乱雑な文書、さまざまなユーザー目標)
- 手作業でルールを維持するには境界条件が多すぎる
- 完全な決定論より判断、要約、合成に価値がある
要件が安定していて厳密であるべき場合(税計算、在庫ロジック、適格性チェック、監査が必要なワークフローなど)は、通常はルールベースの自動化の方が適しています。
AIファーストが支える典型的なプロダクトゴール
チームがモデル駆動のロジックを採用する理由は主に:
- スピード向上:回答案の作成、フィールド抽出、リクエストのルーティングを高速化する
- 体験のパーソナライズ:説明、プラン、推薦を個別に調整する
- 意思決定支援:トレードオフの提示、選択肢生成、証拠の要約
受け入れるべきトレードオフ(設計すること)
モデルは予測不可能で、時に自信満々に間違うことがあり、プロンプトやプロバイダ、取得されたコンテキストの変化で挙動が変わることがあります。また、呼び出しごとのコストやレイテンシを追加し、安全性や信頼(プライバシー、有害出力、ポリシー違反)に関する懸念を生じさせます。
適切な心構えは:モデルはコンポーネントであり、魔法の答え箱ではないと扱うことです。仕様、故障モード、テスト、モニタリングを備えた依存物として扱い、柔軟性を得つつ製品を運用上の賭けにしないようにします。
適切なユースケースを選び、成功を定義する
すべての機能がモデルを中心にするべきではありません。最良のAIファーストユースケースは、明確なジョブ・トゥ・ビー・ダン(やるべき仕事)から始まり、週次で追跡できる測定可能な成果で終わります。
モデルではなくジョブから始める
一文のジョブストーリーを書きます:「When ___, I want to ___, so I can ___(いつ〜したい、〜できるように)」。その後、成果を計測可能にします。
例:「長い顧客メールを受け取ったとき、ポリシーに沿った返信案を提案してほしい。そうすれば2分以内に返信できる。」これは「メールにLLMを追加する」よりずっと実行可能です。
意思決定ポイントをマップする
モデルがアクションを選ぶ瞬間を特定します。これらの意思決定ポイントは明示的で検証可能であるべきです。
よくある意思決定ポイント:
- 意図を分類して適切なワークフローにルーティングする
- 明確化質問をするか進めるか判断する
- 使用するツール(検索、CRM参照、ドラフト作成、チケット作成)を選ぶ
- 人間にエスカレーションするタイミングを決める
意思決定が名前で呼べないなら、モデル駆動ロジックを出荷する準備ができていない可能性があります。
振る舞いの受け入れ基準を書く
モデルの振る舞いを他のプロダクト要件と同様に扱います。「良い」と「悪い」を平易に定義します。
例:
- 良い:最新のポリシーを使い、正しい注文IDを引用し、情報が欠けている場合は一つの明確な質問をする
- 悪い:割引をでっち上げる、サポートされていないロケールを参照する、必要なデータを確認せずに回答する
これらの基準は後の評価セットの基礎になります。
制約を早期に特定する
設計選択を形作る制約を列挙します:
- 時間(応答レイテンシ目標)
- 予算(タスクごとのコスト)
- コンプライアンス(PII取り扱い、監査要件)
- サポートするロケール(言語、トーン、文化的期待)
監視できる成功指標を定義する
ジョブに結びついた少数の指標を選びます:
- タスク完了率
- 代表的ケースでの正確さ(またはポリシー順守率)
- CSATや定性的なユーザー評価
- タスクあたりの時間短縮(または解決までの時間)
成功が測れないと、感覚論争になり改善が進みません。
AI駆動のユーザーフローとシステム境界を設計する
AIファーストなフローは「LLMを呼ぶ画面」ではありません。モデルが意思決定を行い、プロダクトが安全に実行し、ユーザーが方向感覚を保てるエンドツーエンドの旅です。
エンドツーエンドのループをマップする
パイプラインを単純なチェーンとして描きます:入力 → モデル → アクション → 出力。
- 入力:ユーザーが提供するもの(テキスト、ファイル、選択)とアプリのコンテキスト(アカウント階層、ワークスペース、最近のアクティビティ)
- モデルステップ:モデルが担う決定(分類、ドラフト、要約、次のアクション選択)
- アクション:システムが行う可能性のあること(検索、タスク作成、レコード更新、メール送信)
- 出力:ユーザーが見るもの(ドラフト、説明、確認画面、次の手順を示すエラー)
このマップは、どこで不確実性が許容されるか(ドラフティング)と許されないか(請求変更)を明確にします。
モデルと決定論的コードの境界を描く
決定論的な経路(権限チェック、ビジネスルール、計算、DB書き込み)とモデル駆動の決定(解釈、優先順位付け、自然言語生成)を分離します。
実用的なルール:モデルは推奨できるが、コードが検証してから不可逆な操作を行うべきです。
モデルの稼働場所を決める
制約に基づいてランタイムを選びます:
- サーバー:機密データ、整ったツールチェーン、監査ログに最適
- クライアント:軽量な支援やローカル処理によるプライバシーに有利だが制御が難しい
- エッジ:グローバルでの低レイテンシに有利だが依存関係が限定される
- ハイブリッド:エッジでの高速な意図検出とサーバでの重い処理を分ける
レイテンシ、コスト、データ許可を予算化する
リトライやツール呼び出しを含めたリクエストごとのレイテンシとコストの予算を設定し、UXを(ストリーミング、段階的結果、バックグラウンド継続などで)設計します。
各ステップでモデルが読み取れるもの、書き込めるもの、明示的なユーザー承認が必要なものを文書化します。これはエンジニアリングと信頼のための契約になります。
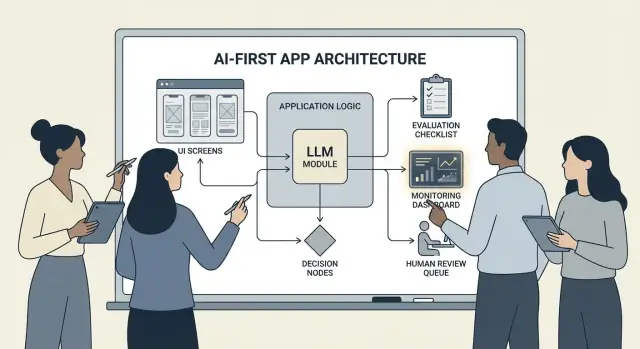
アーキテクチャパターン:オーケストレーション、状態、トレース
モデルがアプリのロジックに組み込まれると、アーキテクチャは単なるサーバやAPIではなく、モデルの連鎖的な意思決定を信頼性高く実行する方法になります。
オーケストレーション:AI作業の指揮者
オーケストレーションは、プロンプトやテンプレート、ツール呼び出し、メモリ/コンテキスト、リトライ、タイムアウト、フォールバックを含めて、AIタスクがエンドツーエンドでどのように実行されるかを管理するレイヤーです。
良いオーケストレータはモデルをパイプラインの一コンポーネントとして扱います。どのプロンプトを使うか、いつツール(検索、DB、メール、支払い)を呼ぶか、コンテキストを圧縮または取得する方法、モデルが無効なものを返したときの対処を決めます。
アイデアから動くオーケストレーションに速く移したければ、vibe-coding的なワークフローでアプリのスキャフォールドを一から作り直さずにプロトタイプできます。たとえば、Koder.aiはチームがチャット経由でWebアプリ(React)、バックエンド(Go + PostgreSQL)、モバイル(Flutter)まで作成でき、"inputs → model → tool calls → validations → UI" のようなフローを計画モード、スナップショット、ロールバック機能と共に反復でき、準備ができたらソースコードをエクスポートできます。
マルチステップタスクのための状態マシン
トリアージ → 情報収集 → 確認 → 実行 → 要約 のようなマルチステップ体験は、ワークフローや状態マシンとしてモデル化すると最適に動作します。
簡単なパターンは、各ステップに(1)許可された入力、(2)期待される出力、(3)遷移を定義することです。これにより会話の迷走を防ぎ、ユーザーが考えを変えた場合や部分情報を提供した場合のエッジケースが明示化されます。
シングルショット vs. マルチターン推論
シングルショットは、メッセージ分類、短い返信のドラフト、文書からのフィールド抽出など、完結したタスクに向いています。安価で高速、検証が容易です。
マルチターン推論は、モデルが明確化質問をする必要がある場合や、ツールを反復的に使う必要がある場合(計画 → 検索 → 改良 → 確認)に向いています。意図的に使い、ループは時間やステップ数で上限を設けてください。
冪等性:繰り返し副作用を避ける
モデルはリトライし、ネットワークは失敗し、ユーザーはダブルクリックします。AIステップが副作用(メール送信、予約、課金)を引き起こす可能性がある場合は、冪等性を確保します。
一般的な手法:各実行アクションに冪等性キーを付与し、アクション結果を保存し、リトライ時に同じ結果を返すようにすることです。
トレース:各ステップをデバッグ可能にする
モデルが見たもの、決定したこと、どのツールが動いたかに答えられるようにトレース性を追加します。
実行ごとに構造化されたトレースをログに残します:プロンプトバージョン、入力、取得したコンテキストID、ツールのリクエスト/レスポンス、検証エラー、リトライ、最終出力など。これにより「AIが変なことをした」が監査可能で修正可能なタイムラインになります。
プロンプトをプロダクトロジックとして扱う:明確な契約とフォーマット
モデルがアプリロジックの一部になると、プロンプトは単なる"コピー"ではなく実行可能な仕様になります。明確な範囲、予測可能な出力、変更管理が必要です。
契約を定義するシステムプロンプトから始める
システムプロンプトはモデルの役割、できること・できないこと、製品にとって重要な安全ルールを設定するべきです。安定かつ再利用可能に保ちます。
含めるべき内容:
- 役割と目標:誰として振る舞うか(例:「サポートトリアージアシスタント」)と成功の定義
- 範囲の境界:拒否・エスカレーションすべきリクエスト
- 安全ルール:PII取り扱い、医療/法務の免責、憶測禁止
- ツールポリシー:いつツールを呼ぶか、直接回答するか
入力/出力を明確にしたプロンプト構造
プロンプトはAPI定義のように書きます:提供する正確な入力(ユーザーテキスト、アカウント階層、ロケール、ポリシースニペット)と期待する正確な出力を列挙します。実際のトラフィックに近い1〜3件の例を追加し、難しいエッジケースも含めます。
有用なパターンは:Context → Task → Constraints → Output format → Examples です。
機械可読な結果のために制約されたフォーマットを使う
コードが出力を処理する場合は、散文に頼らずJSONのようなスキーマで返すよう指示し、そうでないものは拒否します。
{
"type": "object",
"properties": {
"intent": {"type": "string"},
"confidence": {"type": "number", "minimum": 0, "maximum": 1},
"actions": {
"type": "array",
"items": {"type": "string"}
},
"user_message": {"type": "string"}
},
"required": ["intent", "confidence", "actions", "user_message"],
"additionalProperties": false
}
プロンプトのバージョン管理と安全なロールアウト
プロンプトをバージョン管理し、リリースにタグを付け、機能のように段階的に展開します。A/Bテストが適切なら行い、クイックロールバックを用意します。デバッグ用に各応答にプロンプトバージョンをログに残します。
プロンプトテストスイートを作る
代表的なケース(ハッピーパス、曖昧な要求、ポリシー違反、長文、異なるロケール)から小さなテストセットを作り、プロンプト変更時に自動で実行して出力が契約を壊したらビルドを失敗させます。
ツール呼び出し:モデルに決めさせ、コードに実行させる
プロトタイプを超えて拡張
AI機能が成長するにつれて、個人のプロトタイプから共有ワークスペースへ移行できます。
ツール呼び出しは責任分担を分かりやすくします:モデルは「何を」「どの能力で」行うかを決め、アプリケーションコードはそのアクションを実行して検証済みの結果を返します。
これにより、事実や計算、副作用(チケット作成、レコード更新、メール送信)を決定論的で監査可能なコード内に置き、自由形式テキストに頼らないようにできます。
小さく意図的なツールセットを設計する
最初はリクエストの80%をカバーし、セキュアに扱いやすい少数のツールから始めます:
- 検索(ドキュメント/ヘルプセンター)で製品質問に答える
- DB参照(まずは読み取り専用)でユーザー/アカウント/注文状況を取得
- 計算機能(価格、合計、換算、ルールに基づく計算)
- チケッティング(ユーザーが人間のフォローを要する場合にサポートチケットを作る)
各ツールの目的は狭く保ちます。「何でもできる」ツールはテスト困難で誤用されやすいです。
入力を検証し、出力をサニタイズする
モデルを信頼できないコール元として扱います。
- ツール入力を検証:厳格なスキーマ(型、範囲、列挙)で検証し、不足しているIDや広すぎるクエリなどは拒否または修復します。
- ツール出力をサニタイズ:モデルに返す前に機密を除去し、フォーマットを正規化し、モデルが必要とするフィールドのみを返します。
これにより、取得テキストを介したプロンプトインジェクションのリスクを下げ、意図しないデータ漏洩を防ぎます。
ツールごとに権限とレート制限を追加する
各ツールは以下を強制すべきです:
- 権限チェック:誰がどのレコードや操作にアクセスできるか
- レート制限:ユーザー/セッション/ツールごとの制限で乱用や無限ループを抑える
状態を変更するツール(チケット作成、返金)はより強い認可を要求し、監査ログを残します。
「ツールを使わない」パスを常に用意する
時には最良のアクションは何もしないこと(既存のコンテキストから回答する、明確化質問をする、制限を説明する)です。
「ツールを使わない」をファーストクラスの結果として扱い、モデルが忙しく見せるためだけにツールを呼ばないようにします。
データとRAG:モデルを自社の現実で根付かせる
製品の回答が自社ポリシー、在庫、契約、内部知識に合致する必要があるなら、モデルを一般的学習だけでなく自社データで根付かせる仕組みが必要です。
RAG、ファインチューニング、単純コンテキストの使い分け
- 単純なコンテキスト(プロンプトに数段落貼り付ける)は、知識が小さく安定していて毎回送れる場合に有効(短い価格表など)。
- **RAG(Retrieval-Augmented Generation)**は、情報が大きく頻繁に変わる、または出典が必要な場合に最適(ヘルプ記事、製品ドキュメント、アカウント固有データ)。
- ファインチューニングは、一貫したスタイルやドメイン特有のパターンを得たいときに有効で、事実の保存手段として主要に使うべきではありません。書き方やルール遵守の改善に使い、最新性はRAGで補います。
インジェストの基本:チャンク化、メタデータ、鮮度
RAGの品質は主にインジェストの問題です。
ドキュメントをモデル向けのサイズ(多くの場合数百トークン)にチャンク化し、見出しやFAQエントリなどの自然な境界に合わせます。ドキュメントタイトル、セクション見出し、製品/バージョン、対象、ロケール、権限などのメタデータを保存します。
鮮度を計画する:再インデックスのスケジュールを決め、「最終更新」を追跡し、古いチャンクを失効させます。高くランクされた古いチャンクは機能全体を静かに劣化させます。
引用と校正された回答
モデルに以下を返させるようにします: (1) 回答、(2) スニペットID/URLのリスト、(3) 信頼度の声明。
検索結果が薄い場合は、モデルに確認できないことを述べさせ、次の手順(「このポリシーが見つかりませんでした。連絡先はこちら」)を提案させます。隙間を埋めるような推測は許さないでください。
プライベートデータ:アクセス制御と赤字化
取得前にアクセスを強制(ユーザー/組織の権限でフィルタ)し、生成前に再度赤字化します。
埋め込みやインデックスを機密データストアとして扱い、監査ログを付けます。
取得が失敗したとき:優雅なフォールバック
上位結果が無関係または空なら:明確化質問をする、人的サポートにルーティングする、あるいは推測せず限界を説明する非RAGモードに切り替える、などのフォールバックを行います。
信頼性:ガードレール、検証、キャッシュ
モデルがアプリロジックの中に入ると、「大抵は十分」ではだめです。信頼性とは、ユーザーに一貫した振る舞いを見せ、システムが出力を安全に消費でき、障害時に劣化が穏やかであることです。
修正前に信頼性目標を定義する
機能にとって「信頼できる」とは何かを書き出します:
- 一貫した出力:似た入力は比較可能な回答を生成する(トーン、詳細レベル、制約)
- 安定したフォーマット:応答は毎回パース可能(JSON、箇条書き、特定フィールド)
- 振る舞いの上限:モデルがすべきでないことの明確な限界(憶測禁止、出典提示、不確かな場合は質問)
これらはプロンプトとコード双方の受け入れ基準になります。
ガードレール:検証、フィルタ、ポリシーの強制
モデル出力を信頼できない入力として扱います。
- スキーマ検証:厳格なフォーマット(必須キーを持つJSONなど)を要求し、パースできないものは拒否
- コンテンツフィルタ:罵倒検出、PII検出、ポリシーバリデータをユーザー入力とモデル出力の両方にかける
- ビジネスルール:価格範囲、適格性ルール、許可されたアクションなどはコードで強制(プロンプトに書かれていても)
検証に失敗したら、安全なフォールバックを返します(明確化質問、単純テンプレートに切替、あるいは人間へ回す)。
実際に役立つリトライ
無闇に繰り返すのは避けます。失敗モードに対処するようにプロンプトを変更してリトライします:
- 「有効なJSONのみ返してください。マークダウン禁止」
- 「不確かなら
confidenceを低くし、一つだけ質問してください」
リトライには上限を設け、失敗理由をログに残します。
決定論的な後処理
コードでモデルの生成物を正規化します:
- 単位、日付、名前を正規化
- 項目の重複排除
- ランキングルールや閾値の適用
これがばらつきを減らし、テストしやすくします。
プライバシーを崩さないキャッシュ
同一クエリ、共有埋め込み、ツールレスポンスなどの再現可能な結果をキャッシュしてコストとレイテンシを削減します。
推奨:
- ユーザー固有データには短いTTLを使う
- キャッシュキーに生のPIIを含めない(慎重にハッシュする)
- 機密フローには「キャッシュしない」フラグを使う
適切に運用すれば、キャッシュは一貫性を高めながらユーザーの信頼を保てます。
安全性と信頼:UXを壊さずにリスクを低減する
AIプロダクトをデプロイ
プロトタイプからプロジェクト設定をやり直すことなくホスティングされたアプリに移行します。
安全性は最後に付け足すコンプライアンス層ではありません。AIファースト製品ではモデルがアクション、文言、意思決定に影響するため、安全性はアシスタントが許されること、拒否すること、助けを求めるべき状況を定めた製品契約の一部である必要があります。
設計すべき主要な安全懸念
実際にアプリが直面するリスクを列挙し、それぞれに対してコントロールを割り当てます:
- 機密データ:個人識別情報、資格情報、機密文書、規制対象データ
- 有害な助言:自傷、暴力、違法行為、危険な医療/金融操作を助長する指示
- バイアスと不公平な結果:グループ間でのサービス品質や推薦のばらつき
許可/ブロック対象とエスカレーション経路
製品が実行できること・できないことの明示的ポリシーを書きます。具体的なカテゴリ、例、期待される応答を含めると良いです。
3段階で扱います:
- 許可:通常通り回答する
- 制限付き:一般的情報のみ(ステップバイステップは不可)など制約付きで答える
- ブロック:拒否してエスカレーション(サポートや人間)に回す
エスカレーションは単なる拒否メッセージではなくプロダクトフローであるべきです。"人と話す"オプションを用意し、引き継ぎ時にユーザーが既に共有したコンテキストを(同意に基づき)渡します。
重大なアクションには人間レビューを
モデルが支払い、返金、アカウント変更、解約、データ削除など実害を及ぼす可能性がある場合はチェックポイントを入れます。
良いパターン:確認画面、"ドラフトして承認"、金額上限、エッジケース用の人間レビューキュー。
開示、同意、テスト可能なポリシー
ユーザーにAIとやり取りしていること、どのデータが使われるか、何が保存されるかを伝えます。会話の保存やシステム改善への利用については必要に応じて同意を取ります。
内部の安全ポリシーはコードのように扱い、バージョン管理し、理由を文書化し、例となるプロンプトと期待結果でテストを追加して、安全性がプロンプトやモデル更新で回帰しないようにします。
評価:モデルを他の重要コンポーネントと同様にテストする
LLMが製品を変える可能性があるなら、それがまだ機能していることを繰り返し証明する方法が必要です――ユーザーに発見される前に。
プロンプト、モデルバージョン、ツールスキーマ、検索設定はリリース相当のアーティファクトとして扱い、テストが必要です。
実際から評価セットを作る
サポートチケット、検索クエリ、チャットログ(同意のあるもの)、営業通話から実際のユーザー意図を収集し、以下を含むテストケースにします:
- 一般的なハッピーパスのリクエスト
- 明確化質問が必要な曖昧なプロンプト
- エッジケース(データ欠損、矛盾する制約、珍しいフォーマット)
- ポリシーに敏感なシナリオ(個人データ、禁止コンテンツ)
各ケースには期待される振る舞いを含めます:回答、取るべき決定(例:「ツールAを呼ぶ」)、必要な構造(JSONフィールド、引用の有無など)。
製品リスクに合った指標を選ぶ
1つのスコアで品質を表せません。ユーザー成果に結びつく少数の指標を使います:
- 正確性/タスク成功率:ユーザーの目的が達成されたか
- 根拠性:主張が提供されたコンテキストやソースで裏付けられているか
- フォーマットの妥当性:出力が契約(JSON、表、箇条書き)に合っているか
- 拒否率:拒否すべき時に拒否しているか、逆に不要に拒否していないか
コストとレイテンシも品質と並べて追跡します。応答時間が倍になる「良い」モデルはコンバージョンを下げるかもしれません。
変更ごとにオフライン評価を実行する
リリース前とプロンプト、モデル、ツール、検索の変更ごとにオフライン評価を実行します。結果をバージョン管理し、比較して何が壊れたかを迅速に特定できるようにします。
ガード付きのオンラインテストを追加する
実際の成果(完了率、編集数、ユーザー評価)を測るためにA/Bテストを行いますが、安全レールを入れます:無効な出力、拒否、ツールエラーの急増を停止条件にして自動ロールバックするようにします。
本番でのモニタリング:ドリフト、故障、フィードバック
Planning Modeで設計
コード生成前に意思決定・ツール・境界を可視化します。
AIファースト機能を出荷するのは終点ではありません。実際のユーザーが来ると、モデルは新しい言い回し、エッジケース、変化するデータに直面します。モニタリングは「ステージングで動いた」を「来月も動き続ける」に変えます。
秘密を収集せずに重要なものをログする
失敗を再現できるだけのコンテキストを捕捉します:ユーザー意図、プロンプトバージョン、ツール呼び出し、モデルの最終出力。
ログはプライバシー保護のために赤字化して保存します。メール、電話番号、トークン、個人情報を含む可能性のある自由文は除去します。特定セッションのみで一時的に有効にする"デバッグモード"を設け、デフォルトで最大ログを取らないようにします。
適切なシグナルを監視する
エラー率、ツールの失敗、スキーマ違反、ドリフトを監視します。具体的には:
- ツールコールの成功率とタイムアウト(モデルが正しいツールを選び実行できたか)
- 出力フォーマット/スキーマの準拠率(バリデータが拒否したか)
- フォールバック利用率(安全または単純なパスに切り替えた頻度)
- コンテンツ安全のブロック数(拒否やサニタイズの頻度)
ドリフトについては、基準と比較してトピックの割合、言語、平均プロンプト長、未知の意図の変化を追います。ドリフトが常に悪いわけではありませんが、再評価の合図になります。
アラート、ランブック、インシデント対応
アラート閾値とオンコール用のランブックを設定します。アラートは行動につながるべきです:プロンプトバージョンのロールバック、壊れているツールの無効化、検証の強化、フォールバックへの切替など。
安全でないまたは誤った振る舞いに対するインシデント対応を計画します。誰が安全スイッチを切れるか、ユーザー通知方法、イベントの文書化と学習方法を定義します。
ユーザーフィードバックでループを閉じる
サムズアップ/ダウン、理由コード、バグ報告などのフィードバックループを使います。短い"なぜ?"オプション(事実が間違っている、指示に従わない、安全でない、遅い)を用意し、問題をプロンプト、ツール、データ、ポリシーのどこに振り分けるかを特定できるようにします。
モデル駆動ロジックのUX:透明性とコントロール
モデル駆動機能はうまく動くと魔法のように感じられ、失敗すると脆く感じられます。UXは不確実性を前提にしつつ、ユーザーがタスクを完了できるように設計する必要があります。
過度にならない範囲で「なぜ」を示す
ユーザーは生成物の出所が見えると信頼します。目的は講義をすることではなく、行動すべきか判断する手助けをすることです。
段階的開示を使います:
- まず結果を表示(回答、ドラフト、推奨)
- 「理由」や「作業を表示」トグルで主要な入力:ユーザーの要求、使用されたツール、参照したソースやレコードを見せる
- 取得を使う場合は、引用が該当スニペットにジャンプするようにして(例:「Policy §3.2 に基づく」)見やすくする
より詳しい解説がある場合はUI内に詰め込まず、内部の相対リンク(例:/blog/rag-grounding)で案内します。
不確実性を設計する(恐ろしい警告なしに)
モデルは電卓ではありません。インターフェースは信頼度を伝え、検証を促すべきです。
実用的なパターン:
- 「おそらく正しい」「確認が必要」などの平易な言葉で信頼度を示す
- 単一の回答ではなく複数案を提示:「返信案を3つ示す」など。初回の間違いのコストを下げる
- 影響の大きい操作には確認を入れる(例:「12人に送信しますか?」)
修正と回復を容易にする
ユーザーが出力を捨てずに軌道修正できるようにします:
- インライン編集と「変更を適用」でモデルがユーザーの修正から継続できる
- トーン、長さ、制約を指定して「再生成」できる制御
- 「元に戻す」と履歴を可視化してミスを取り消せるようにする
エスケープハッチを提供する
モデルが失敗したりユーザーが不安なときは、決定論的なフローや人間の支援を提供します。
例:「手動フォームに切替」「テンプレートを使う」「サポートに連絡する(/support)」など。これは失敗の恥ではなく、タスク完了と信頼を守る手段です。
プロトタイプから本番へ(すべてを作り直さずに)
多くのチームが失敗する理由はLLMの能力ではなく、プロトタイプから信頼性がありテスト可能で監視可能な機能にするまでの道のりが長すぎることです。
道を短くする実用的な方法は、早期に「プロダクトの骨組み」を標準化することです:状態マシン、ツールスキーマ、検証、トレース、デプロイ/ロールバックのストーリー。Koder.aiのようなプラットフォームは、AIファーストワークフローを迅速に立ち上げ(UI、バックエンド、DBを一緒に構築)、スナップショット/ロールバックで安全に反復し、カスタムドメインやホスティングを備え、準備ができたらソースコードをエクスポートしてCI/CDや可観測性スタックへ移行できます。