2025年7月13日·1 分
バックエンドフレームワークがコード構成とチーム習慣に与える影響
バックエンドフレームワークがフォルダ構成、境界設計、テスト、チームワークフローにどう影響するかを学び、より一貫性があり保守しやすいコードで素早く出荷する方法を示します。
バックエンドフレームワークがフォルダ構成、境界設計、テスト、チームワークフローにどう影響するかを学び、より一貫性があり保守しやすいコードで素早く出荷する方法を示します。
バックエンドフレームワークは単なるライブラリの集合ではありません。ライブラリはルーティング、バリデーション、ORM、ログなど個別の作業を助けますが、フレームワークは「やり方」を意見ありで提供します:デフォルトのプロジェクト構成、共通パターン、組み込みツール、部品のつなぎ方に関する規則です。
フレームワークが導入されると、数百の小さな選択に影響します:
だから、同じ言語とDBを使っていても、フレームワークの慣習によって「同じAPI」を作っているはずの二つのチームのコードベースが全く違うものになることがよくあります。フレームワークの規約が「ここではこうやる」のデフォルト回答になるのです。
フレームワークはしばしば柔軟性を予測可能な構造とトレードします。利点はオンボーディングが速く、議論が減り、再利用可能なパターンが偶発的複雑性を減らすことです。欠点は、製品が特殊なワークフローや性能チューニング、非標準アーキテクチャを必要とするときに規約が制約に感じられることです。
良い判断は「フレームワークか否か」ではなく、どれだけの規約を採用するかと、それに伴うカスタマイズコストをチームが払うかどうかです。
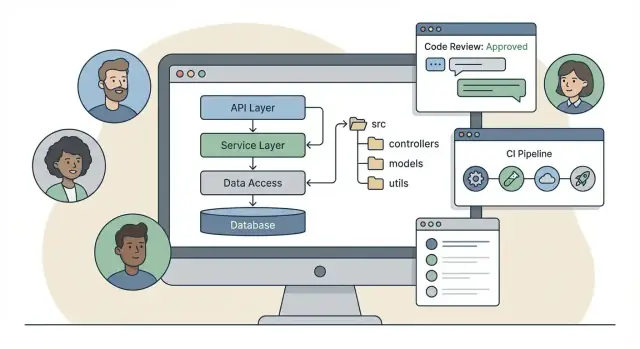
ほとんどのチームは空のフォルダから始めるわけではなく、フレームワークが推奨するレイアウトから始めます。これらのデフォルトが、コードをどこに置くか、どう命名するか、レビューで何が「普通」に見えるかを決めます。
あるフレームワークは古典的なレイヤー構造(controllers / services / models)を推します。学習が容易でリクエスト処理に対応しやすい:
/src
/controllers
/services
/models
/repositories
別のフレームワークはフィーチャーモジュール寄りで、ある機能に関する全て(HTTPハンドラ、ドメインルール、永続化)をまとめます。そうすると“Billing”を扱うときに一つのフォルダを開くだけで済み、局所的な推論がしやすくなります:
/src
/modules
/billing
/http
/domain
/data
どちらが自動的に優れているわけではありませんが、それぞれ習慣を形作ります。レイヤー型は横断的な標準(ロギング、バリデーション、エラーハンドリング)を集中化しやすく、モジュール優先はコードベースが大きくなったときの“横方向のスクロール”を減らす傾向があります。
CLIジェネレータ(スキャフォールディング)は粘着性があります。ジェネレータが各エンドポイントに対してcontroller + serviceのペアを作るなら、たとえ簡単な関数で済む場合でも人はそれを続けます。逆に明確な境界を持つモジュールを生成するなら、締め切りプレッシャー下でもチームはその境界を守りやすくなります。
このダイナミクスは「vibe-coding」ワークフローでも現れます。プラットフォームのデフォルトが予測可能なレイアウトと明確なモジュールの継ぎ目を生むなら、チームはコードベースを成長に合わせて一貫して保てます。例えば Koder.ai はチャットプロンプトからフルスタックアプリを生成し、速度以外の実務上の利点は初期から一貫した構造とパターンを標準化できる点にあります—必要ならソースコードをエクスポートして完全な制御を取ることもできます。
コントローラを主役にしすぎるフレームワークは、チームにビジネスルールをリクエストハンドラに詰め込ませる誘惑を与えます。実用的な経験則: コントローラはHTTP → アプリケーション呼び出しを翻訳するだけに留め、ビジネスロジックはサービス/ユースケース層(またはモジュールドメイン層)に置いて、HTTPを起動せずにテストでき、バックグラウンドジョブやCLIで再利用できるようにします。
「料金ロジックはどこにあるか」を一文で説明できないなら、フレームワークのデフォルトがドメインと戦っている可能性があります。早めに調整しましょう—フォルダは簡単に変えられますが、習慣は変えにくいです。
バックエンドフレームワークは単なるライブラリ群ではなく、リクエストがコードを通過する方法を定義します。皆が同じリクエスト経路に従えば、機能提供が速くなり、レビューはスタイルより正当性に集中します。
ルートはAPIの目次のように読めるべきです。良いフレームワークは、次のようなルートを促します:
実用的な慣習として、ルートファイルはマッピングに集中させます: GET /orders/:id -> OrdersController.getById のようにして、「ユーザーがVIPならXを行う」などのロジックは入れないでください。
コントローラ(あるいはハンドラ)は、HTTPとコアロジックの間の翻訳役として最も効果的です:
フレームワークがパース、バリデーション、レスポンス整形のヘルパーを提供すると、コントローラにロジックを積み上げがちになります。健康的なパターンは「薄いコントローラ、厚いサービス」です: リクエスト/レスポンスの関心事はコントローラに、ビジネス判断はHTTPを知らない別レイヤに置きます。
ミドルウェア(フィルタ/インターセプタ)は認証、ロギング、レート制限、リクエストIDのような繰り返し行う振る舞いの置き場所を形作ります。重要な慣習は: ミドルウェアはリクエストを拡張または保護すべきで、製品ルールを実装すべきではないということです。
例えば、認証ミドルウェアは req.user を付与し、コントローラはそのIDをコアロジックに渡します。ロギングミドルウェアは何を標準でログに残すかを定め、各コントローラがそれを再発明するのを防ぎます。
予測可能な名前に合意してください:
OrdersController, OrdersService, CreateOrder(ユースケース)authMiddleware, requestIdMiddlewarevalidateCreateOrder(スキーマ/バリデータ)名前が意図を内包していれば、コードレビューは「どこに置くべきか」よりも振る舞いに集中できます。
フレームワークは単にエンドポイントを出荷するのを助けるだけでなく、チームを特定のコードの“形”に押し込みます。早期に境界を定義しないと、デフォルトでコントローラがORMを呼び、ORMがDBを呼び、ビジネスルールがあちこちに散らばる重力に引かれがちです。
単純で耐久性のある分割は次のようになります:
CreateInvoice, CancelSubscription)。作業とトランザクションをオーケストレーションするが、フレームワークに依存しない。「controller + service + repository」を生成するフレームワークは有用ですが、それをすべての機能が必ず全てのレイヤーを持つべきだという要件として扱わないことが重要です。方向性としての流れとして捉えてください。
ORMは便利で検証まで兼ねていることが多いため、DBモデルをあちこちに渡したくなる誘惑を生みます。リポジトリは「idで顧客を取る」「請求書を保存する」のような狭いインターフェースを提供し、アプリケーションやドメインコードがORMの詳細に依存しないように助けます。
「すべてがDBに依存する」設計を避けるためのルール:
ロジックがエンドポイント間で再利用される、トランザクションが必要、あるいはルールを一貫して適用する必要がある場合にはサービス/アプリケーション層を追加してください。真に単純なCRUDでビジネス振る舞いが全く無い場合は、余分なレイヤーが儀式だけを増やすので省いて構いません。
DIはフレームワークのデフォルトとしてチーム全体を訓練します。フレームワークに組み込まれていると、ランダムな場所でサービスを new する代わりに依存を宣言し、配線し、意図的に差し替える習慣が生まれます。
DIは小さく焦点の絞られたコンポーネントを作る傾向があります: コントローラはサービスに依存し、サービスはリポジトリに依存し、それぞれの役割が明確になります。テスト容易性が改善し、実装の差し替えが容易になります(例: 実際の決済ゲートウェイ⇄モック)。
一方でDIは複雑さを隠すことがあります。全てのクラスが5つの依存を持つと、リクエスト時に実際に何が動くか把握しにくくなります。誤構成されたコンテナは、編集したコードから遠い場所でエラーを引き起こすことがあります。
ほとんどのフレームワークはコンストラクタ注入を推奨します。これは依存関係を明示にし、“サービスロケータ”パターンを防ぐからです。
役立つ習慣は、コンストラクタ注入とインターフェース駆動設計を組み合わせることです: コードは EmailSender のような安定した契約に依存し、特定のベンダークライアントに依存しないことで、プロバイダを切り替えるときの影響を局所化できます。
DIはモジュールがコヒーレントであるときに最も機能します: ひとつのモジュールがひとつの機能スライス(orders, billing, auth)を所有し、小さな公開サーフェスを露出します。
循環依存はよくある失敗モードで、境界が不明瞭であることのサインです。二つのモジュールが共有する概念は別モジュールに分けるか、どちらかがやりすぎている可能性があります。
依存関係を登録する場所に合意してください: 単一のComposition Root(startup/bootstrap)と、モジュール内部の配線はモジュールレベルで行う、という方針です。
配線を中央に置くことでレビューが簡単になります: 新しい依存関係をレビュワーが見つけやすく、正当性を確認でき、DIがツールから謎に変わるのを防げます。
バックエンドフレームワークはチームにとって「良いAPI」が何かの基準を形成します。バリデーションがファーストクラス(デコレータ、スキーマ、パイプ、ガード)であると、エンドポイントは明確な入力と予測可能な出力を前提に設計されます—正しいことをするのが簡単で、スキップするのが難しいからです。
バリデーションが境界にあると、チームはリクエストペイロードを「クライアントが送る何でも」ではなく契約として扱い始めます。それにより:
またフレームワークは、どこでバリデーションを定義するか、エラーをどう表現するか、未知フィールドを許可するかなどについて共有された慣習を促します。
グローバル例外フィルタ/ハンドラをサポートするフレームワークなら、一貫性を達成しやすいです。各コントローラが独自のレスポンスを考える代わりに、次のような標準化ができます:
code, message, details, traceId)一貫したエラー形はフロントエンドの分岐ロジックを減らし、APIドキュメントを信頼しやすくします。
多くのフレームワークは入力用DTOと出力用ビュー・モデルに寄せるよう促します。これは健康的な分離で、内部フィールドの誤公開を防ぎ、クライアントとDBスキーマの結合を避け、リファクタを安全にします。実用的なルール: コントローラはDTOで話し、サービスはドメインモデルで話す。
小さなAPIでも進化します。ルーティングの慣習はバージョン管理をURLベース(/v1/...)にするかヘッダベースにするかを決めがちです。どちらを選ぶにせよ基本を早めに決めてください: フィールドを削除するときは非推奨期間を設ける、フィールドの追加は下位互換になるようにする、変更を一箇所(例: /docs や /changelog)に記載する。
フレームワークは機能の出荷を助けるだけでなく、テストの形も決めます。組み込みのテストランナー、ブートストラップユーティリティ、DIコンテナが何を簡単にするかを決め、それがチームが実際に行うことになります。
多くのフレームワークはコンテナを立ち上げ、ルートを登録し、インメモリでリクエストを実行できる“テストアプリ”ブートストラッパーを提供します。これにより統合テストが取り組みやすくなり、早めに取り入れられることが多いです。
実用的な分割:
多くのサービスでは速度が重要です。良いルールは: 小さなユニットテストをたくさん持ち、境界(DB、キュー)周りにフォーカスした統合テストを置き、契約を証明する薄いE2E層を持つことです。
フレームワークがリクエストシミュレーションを安価にしているなら、統合テストをやや重めにしてもよいですが、ドメインロジックを分離してユニットテストを安定させておくべきです。
モッキング戦略はフレームワークが依存を解決する方法に従うべきです:
フレームワークの起動時間がCIのボトルネックになることがあります。テストを素早く保つには、重いセットアップをキャッシュし、スイートごとにマイグレーションを一度だけ実行し、分離が保証される場所だけで並列化を使うと良いです。失敗を診断しやすくするには、一貫したシーディング、決定論的なクロック、厳密なクリーンアップフックが有効です。
フレームワークは最初のAPIを出荷する手助けをするだけでなく、「一つのサービス」が多数の機能やチーム、統合に成長したときにコードがどう増えるかを形作ります。フレームワークが簡単にしてくれるモジュール/パッケージの仕組みが長期的アーキテクチャになります。
多くのバックエンドフレームワークは設計上モジュール化を促します: apps, plugins, blueprints, modules, feature folders, packages のような仕組みです。デフォルトがこれなら、チームは新機能を「もう一つのモジュール」として追加する傾向になり、ファイルをプロジェクト全体に撒き散らすことが減ります。
実用的なルール: 各モジュールをミニプロダクトとして扱い、公開サーフェス(routes/handlers, service interfaces)、非公開の内部、テストを持たせてください。フレームワークが自動検出(モジュールスキャン)をサポートしている場合は、注意して使い、明示的なimportの方が依存を把握しやすいこともあります。
コードベースが大きくなると、ビジネスルールとアダプタを混ぜるのは高コストになります。役に立つ分割:
フレームワークの規約が「サービスクラス」を奨励するなら、ドメインサービスはコアモジュールに置き、コントローラ/ミドルウェア/プロバイダのようなフレームワーク固有の配線はエッジに置いてください。
チームはしばしば早すぎる共有をしてしまいます。小さなコードは安定するまでコピーしておき、次の条件が満たされたら抽出してください:
抽出するなら内部パッケージ(またはワークスペースライブラリ)として公開し、厳格な所有権と変更履歴管理を行ってください。
モジュラー・モノリスは多くの場合“中規模”に最適な選択です。モジュールに明確な境界と最小限のクロスインポートがあれば、後でモジュールをサービスに切り出すときの手間は小さくなります。モジュールは技術レイヤーではなくビジネス機能に基づいて設計してください。詳細な戦略は /blog/modular-monolith を参照してください。
フレームワークの設定モデルはデプロイの一貫性に影響します。設定がバラバラだと、チームは差異をデバッグすることに時間を取られ、機能開発がおろそかになります。
多くのフレームワークは一次の真実のソース(設定ファイル、環境変数、コードベースの設定)を使うことを促します。どの方法を選ぶにせよ早めに標準化してください:
config/default.yml)良い慣習: デフォルトはバージョン管理する設定ファイルに置き、環境変数で環境ごとに上書きし、コードは一つの型付き設定オブジェクトを読む。こうすればインシデント時に「どこを変えれば良いか」が明確になります。
フレームワークはenv読み取り、シークレットストア統合、起動時の設定検証のヘルパーを提供することが多いです。その機能を使ってシークレットを扱いやすく/誤用しにくくしてください:
.envの乱立より、ランタイム注入(CI/CD、オーケストレータ、シークレットマネージャ)を優先する目指す運用習慣は: 開発者は安全なプレースホルダでローカル実行できるが、実際の資格情報はそれを必要とする環境だけに存在するという状態です。
フレームワークのデフォルトはパリティを促進するか、逆に特殊例を作るかします。目標は同じ起動コマンドと同じ設定スキーマを各環境で使い、値だけを変えることです。
ステージングはリハーサルの場とし、同じ機能フラグ、同じマイグレーション経路、同じバックグラウンドジョブを小さいスケールで実行するようにしてください。
設定が文書化されていないと、メンバーは推測で変更を行い、それが障害になります。リポジトリに短く維持された参照(例: /docs/configuration)を置き、次を一覧にしてください:
多くのフレームワークは起動時に設定検証をサポートします。これを文書と組み合わせれば「自分のマシンでは動く」が恒常的な問題でなくなります。
フレームワークは本番環境でシステムをどう理解するかの基準を設定します。観測性が組み込まれている(または強く推奨される)と、チームはログやメトリクスを“あとでやる”ものではなくAPI設計の一部として扱い始めます。
多くのフレームワークは構造化ログ、分散トレーシング、メトリクス収集と直接統合します。その結果、横断的関心事を中央化(ロギングミドルウェア、トレーシングインターセプタ、メトリクスコレクタ)する傾向が強まり、コントローラにプリント文をまき散らすことが減ります。
良い標準は、リクエスト関連のログ行が必ず含むべき少数のフィールドを定義することです:
correlation_id(または request_id): サービス間のログを結び付けるroute と method: 関連するエンドポイントを把握するためuser_id または account_id(可能な場合): サポート調査のためduration_ms と status_code: 性能と信頼性のためフレームワークの慣習(リクエストコンテキストオブジェクトやミドルウェアパイプライン)は相関IDを一貫して生成・伝播するのを容易にし、開発者が各機能でパターンを再発明するのを防ぎます。
フレームワークのデフォルトはヘルスチェックを第一級市民にするか後回しにするかを決めます。/health(liveness)と/ready(readiness)のような標準エンドポイントは「完了」の定義の一部にし、次のような境界を促します:
これらを早期に標準化すれば、運用要件がランダムな機能コードに漏れ出すのを防げます。
観測性データは意思決定ツールにもなります。トレースで特定のエンドポイントが同じ依存先で繰り返し時間を費やしているなら、そのモジュールを抽出する、キャッシュを追加する、クエリを再設計するサインです。ログが一貫しないエラー形を示すなら、エラーハンドリングを集中化する合図です。つまり、フレームワークの観測性フックはデバッグを助けるだけでなく、コードベースを自信を持って再編成する手助けにもなります。
フレームワークはコードを整理するだけでなく、チームの“ハウスルール”を設定します。皆が同じ規約(ファイル配置、命名、依存関係の配線方法)に従うと、レビューは速くなり、オンボーディングは容易になります。
スキャフォールディングは新しいエンドポイントやモジュール、テストを数分で標準化して作れます。罠はジェネレータにドメインモデルを決めさせてしまうことです。
スキャフォールドを一貫したシェルを作るために使い、その出力を即座に編集して自チームの規約に合わせてください。AI支援のワークフローを使う場合も同じ規律を適用し、生成されたコードはスキャフォールドとして扱い、レビューでモジュール境界、DIパターン、エラー形を守らせてください。スピードは構造を損なわない場合にのみ有効です。
フレームワークはどこでバリデーションを書くか、どのようにエラーを上げるか、サービスをどう命名するかなどの慣習を示唆します。それらの期待を短いチームスタイルガイドにまとめ、次を含めてください:
軽量で実践的に保ち、/contributing から参照できるようにしてください。
規約を自動化してください。フォーマッタとリンタをフレームワーク慣習(imports、デコレータ/アノテーション、asyncパターン)に合わせて設定し、pre-commitフックとCIで強制することでレビューが設計に集中するようにします。
フレームワークベースのチェックリストは一貫性の緩みを防ぎます。PRテンプレートに次のような確認項目を入れてください:
こうした小さなガードレールがチーム拡大時にコードベースを保守可能に保ちます。
フレームワーク選択はレイアウト、コントローラスタイル、DI、テストの書き方といったパターンを固定化します。目標は完璧なフレームワークを選ぶことではなく、チームのソフトウェア提供の仕方に合うものを選び、要件が変わっても変更可能な状態を保つことです。
機能チェックリストではなくデリバリ制約から始めてください。小規模チームは強い規約、バッテリーインクルードのツール、速いオンボーディングから恩恵を受けます。大規模チームは明確なモジュール境界、安定した拡張点、隠れた結合を作りにくいパターンを必要とすることが多いです。
実用的な問い:
書き換えは長年の小さな痛みを無視した末に起きることが多いです。注意すべき兆候:
シーム(分離点)を導入して段階的に進めます:
コミットする前(あるいは次のメジャーアップグレード前)に短いトライアルを行ってください:
選択肢を評価する体系的な方法が必要なら、軽量なRFCを作ってコードベースに保存してください(例: /docs/decisions)。そうすれば将来のチームがなぜその選択をしたか、どう安全に変えるか理解できます。
付け加える視点: チームがビルドループの高速化(チャット駆動開発を含む)を試しているなら、ワークフローが同じアーキテクチャ成果物を生むか評価してください—明確なモジュール、強制できる契約、運用可能なデフォルトが維持されているかどうかです。フレームワークCLIでもKoder.aiのようなプラットフォームでも、最高の速度向上はサイクルタイムを短縮しつつバックエンドの保守性を損なわないものです。
バックエンドフレームワークは、意見を持ったアプローチでアプリケーションを構築するためのものです: デフォルトのプロジェクト構成、リクエストライフサイクルの慣習(routing → middleware → controllers/handlers)、組み込みツール群、そして「推奨される」パターン。ライブラリは個別の問題(ルーティング、バリデーション、ORM)を解決しますが、チーム全体でそれらをどう組み合わせるかを強制することは少ないです。
フレームワークの規約が日々の判断のデフォルトになります: コードの配置場所、リクエストの流れ、エラーの形、依存関係の配線方法などです。その結果、オンボーディングが速くなり、レビューの議論が減りますが、一方で後からパターンを変えるのが難しくなる“ロックイン”も生まれます。
技術的関心点(controllers/services/models)を明確に分けて横断的な振る舞い(認証、バリデーション、ロギング)を中央集権化したいならレイヤー型を選びます。
機能ごとに作業を完結させたい(例: Billing)場合はフィーチャーモジュール型が有利で、フォルダ間を行き来する頻度が減ります。
どちらを選ぶにせよ、ルールを文書化し、レビューで守るようにしてください。そうしないとコードベースが成長したときに一貫性が失われます。
ジェネレータは一貫したスケルトン(routes/controllers、DTO、テストの雛形)を素早く作れますが、出力をそのまま受け入れるのは避けてください。生成物を出発点として扱い、チームのアーキテクチャ規則に合わせて即座に修正しましょう。
もしスキャフォールディングが常にcontroller+service+repoを生成するなら、単純なエンドポイントでも儀式が増えてしまうため、テンプレートを定期的に見直して実際の開発スタイルに合わせて更新してください。
コントローラはHTTPの翻訳に集中させます:
ビジネスロジックはアプリケーション層/ドメイン層に移し、ジョブやCLIでも再利用でき、HTTPスタックを起動せずにテストできるようにします。
ミドルウェアはリクエストを拡張したり保護したりする役割に限定すべきで、製品固有のルールを実装する場所ではありません。
適切な例:
一方で価格判定や適格性判定、ワークフロー分岐のようなビジネス判断はサービス/ユースケースに置きます。
DIはテストしやすさを向上させ、実装の差し替え(実決済→モックなど)を容易にします。
ただし理解しやすさを保つために:
循環依存が出たら、それはたいてい境界が不明瞭であることを示しています。DI自体の問題ではありません。
リクエスト/レスポンスを契約として扱います:
code, message, details, traceId)を使うDTO/ビュー・モデルを使うことで内部のフィールドやORM構造を誤って公開するのを防ぎ、クライアントをDBスキーマに結びつけないようにできます。
フレームワークのツールが「何が簡単か」を決め、それが実際にチームが行うテストの形を作ります。意図的な分割を維持してください:
モックはDIバインディングの上書きを優先し、インメモリアダプタを使うと脆いモックを減らせます。CI向けに高速に保つため、フレームワークの起動やDBセットアップを最小化してください。
初期のサインに注意してください:
リスクを減らす方法: