2025年4月23日·2 分
ベクトルデータベースがAIアプリのセマンティック検索を支える仕組み
ベクトルデータベースが埋め込みを保存し、高速類似度検索を実行してセマンティック検索、RAGチャットボット、レコメンデーションなどのAIアプリを支える仕組みを解説します。
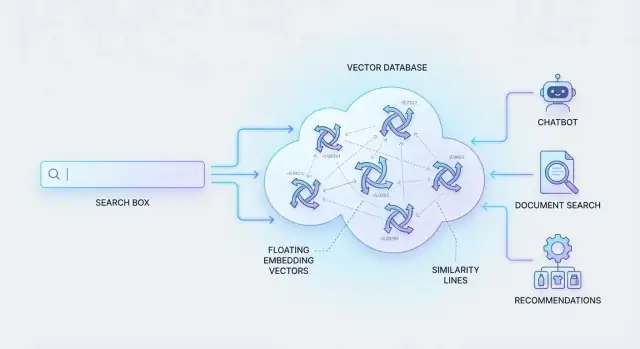
ベクトルデータベースが埋め込みを保存し、高速類似度検索を実行してセマンティック検索、RAGチャットボット、レコメンデーションなどのAIアプリを支える仕組みを解説します。
セマンティック検索は、あなたが「何を意味しているか」に注目する検索方法で、入力した単語そのものだけに頼りません。
「答えはここにあるはずなのに、なぜ見つからないんだ?」と思ったことがあれば、キーワード検索の限界を感じた経験があるはずです。従来の検索は用語一致を行います。クエリの表現とコンテンツの表現が重なる場合はうまく機能しますが、そうでないと見逃してしまいます。
キーワード検索は次の点で苦戦します:
また、同じ単語の繰り返しを過大に評価して、表面的には関連して見えるが実際に質問に答えているページを見逃すことがあります。
ヘルプセンターに「Pause or cancel your subscription(サブスクリプションを一時停止または解約)」という記事があるとします。ユーザーが検索します:
“stop my payments next month”
その記事に「stop」や「payments」が含まれていなければ、キーワードシステムは高くランク付けしないかもしれません。セマンティック検索は「stop my payments」が「cancel subscription」と意味的に近いことを理解し、その記事を上位に表示します。なぜなら意味が一致しているからです。
この仕組みを実現するには、コンテンツとクエリを「意味の指紋」(類似性を表す数値)として表現します。そして、これらの指紋を何百万件と高速に検索する必要があります。
それを可能にするのがベクトルデータベースです:数値表現を保存し、類似性の高いものを効率的に取得することで、大規模でもセマンティック検索を瞬時に感じさせます。
**埋め込み(embedding)**は意味を数値で表したものです。ドキュメントをキーワードで説明する代わりに、内容を表す数値の並び(=ベクトル)で表現します。意味が近いコンテンツ同士は、その数値空間上で近い位置に置かれます。
埋め込みは高次元の地図上の座標のようなものです。数値自体を人が直接読むことはほとんどありません。価値は振る舞い(類似度の計算)にあります:もし「cancel my subscription」と「how do I stop my plan?」が近いベクトルを生成すれば、単語の重複が少なくてもそれらを関連と見なせます。
埋め込みはテキストに限りません。
このため、1つのベクトルデータベースで「画像で検索」「似た曲を見つける」「この商品に似た商品を推薦する」といった機能をサポートできます。
ベクトルは手作業でタグ付けして得られるものではなく、機械学習モデルが意味を数値に圧縮して生成します。コンテンツを埋め込みモデル(自分でホストするか外部提供者)に送ると、モデルはベクトルを返します。アプリはそのベクトルを元のコンテンツやメタデータと一緒に保存します。
どの埋め込みモデルを選ぶかで結果が大きく変わります。大きなモデルや専門特化したモデルは関連性を向上させることが多いですが、コストが高く遅くなる可能性があります。小さなモデルは安く速いですが、特にドメイン固有の言語や多言語、短いクエリにおいて微妙さを見逃すことがあります。多くのチームはスケールする前に複数モデルをテストして最適なトレードオフを見つけます。
ベクトルデータベースは単純なアイデアに基づいて構築されています:意味(ベクトル)と、結果を識別・フィルタ・表示するために必要な情報を一緒に保存することです。
ほとんどのレコードは次のようになります:
doc_18492 や UUID)例としてヘルプセンターの記事は次のように保存されます:
kb_123{ "title": "Reset your password", "url": "/help/reset-password", "tags": ["account", "security"] }ベクトルが意味的な類似性を支え、ID とメタデータが結果を実用的にします。
メタデータには二つの仕事があります:
メタデータが不十分だと、正しい意味を取得しても誤った文脈を表示してしまう可能性があります。
埋め込みのサイズはモデルによって異なり、384, 768, 1024, 1536 次元が一般的です。次元が増えるとニュアンスをより表現できますが、同時に次の点が増加します:
直感的には、次元を倍にするとインデックスやメモリのコストやレイテンシーが上がることが多いです。インデックス手法や圧縮で補う必要があります。
実データセットは変化するので、ベクトルデータベースは通常次をサポートします:
早い段階で更新を計画しておかないと、検索が「古い知識」を返す問題に陥ります。
テキスト、画像、商品が埋め込みに変換されたら、検索は幾何学的な問題になります:「このクエリベクトルに最も近いベクトルはどれか?」これを最短近傍検索と言います。キーワード一致の代わりに、システムは二つのベクトルの近さを測って意味を比較します。
各コンテンツを高次元空間の点として想像してください。ユーザーが検索すると、そのクエリも別の点になります。類似度検索はクエリに最も近い点(近傍)を返します。近傍は表現が違っていても、意図やトピック、文脈を共有している可能性が高いです。
ベクトルデータベースは通常いくつかの標準的な「近さ」の測り方をサポートします:
異なる埋め込みモデルは特定の指標で訓練されているので、モデル提供者の推奨指標を使うことが重要です。
正確検索はすべてのベクトルをチェックして真の最短近傍を見つけますが、数百万件規模では遅く高コストになります。
多くのシステムは ANN(近似近傍) を使います。ANN は有望な候補に検索を絞るためのスマートなインデックス構造を用います。通常、真の最良候補に「十分に近い」結果をはるかに高速に返せます。
ANN が人気なのは、要件に応じてチューニングできるからです:
この調整が、実アプリでベクトル検索が高速かつ高い関連性を両立する理由です。
セマンティック検索は単純なパイプラインとして考えると分かりやすい:テキストを意味に変換し、類似する意味を検索し、最も有用なマッチを提示する。
ユーザーが質問を入力します(例:「How do I cancel my plan without losing data?」)。そのテキストを埋め込みモデルに通し、クエリの意味を表すベクトルを生成します。
そのクエリベクトルをベクトルデータベースに送ると、保存されているコンテンツの中から「最も近い」ベクトルを探します。
ほとんどのシステムはtop-Kマッチを返します:最も類似した K 個のチャンク/ドキュメント。
類似度検索は速度最適化されているため、初期の top-K に近い外れが含まれることがあります。リランカーはクエリと各候補を合わせて見て再度並べ替え、より精度の高い順序にします。
ベクトル検索が強力なショートリストを提供し、リランキングが最良の順序を選ぶイメージです。
最後に最良のマッチをユーザーに返す(検索結果として)か、AIアシスタントに渡して(例えば RAG システムで)「根拠」として使います。
この種のワークフローをアプリに組み込む際、Koder.ai のようなプラットフォームはプロトタイプを素早く作る手助けになります:チャットインターフェースでセマンティック検索や RAG の体験を記述し、React フロントエンドと Go/PostgreSQL バックエンドを反復しつつ、(埋め込み → ベクトル検索 → 任意のリランキング → 回答) の取得パイプラインを主要なプロダクト部分として扱えます。
ヘルプセンターの記事に「terminate subscription」と書かれていて、ユーザーが「cancel my plan」と検索した場合、キーワード検索は「cancel」と「terminate」が一致しないため見落とすかもしれません。
セマンティック検索は両フレーズが同じ意図を表していると判断して取得する傾向があります。リランキングを加えれば、上位結果は「類似している」だけでなく、ユーザーの質問に直接役立つものになります。
純粋なベクトル検索は「意味」に優れていますが、ユーザーは常に意味だけで検索するわけではありません。氏名の完全一致、SKU、請求書ID、ログからコピーしたエラーコードなど、正確一致が必要な場合があります。ハイブリッド検索は意味的シグナル(ベクトル)と字句的シグナル(BM25 のような従来検索)を組み合わせて解決します。
ハイブリッドクエリは通常並列で二つの検索パスを実行します:
その後、システムはこれらの候補結果を統合して一つのランク付けリストにします。
ハイブリッド検索は、以下のような「必ず一致させたい文字列」が含まれる場合に強みを発揮します:
セマンティック検索だけだと広く関連するページが返り、キーワード検索だけだと言い換え表現を逃します。ハイブリッドは両方の失敗モードをカバーします。
メタデータフィルタはランキングの前(または同時)に取得対象を制限し、関連性と速度を改善します。一般的なフィルタ:
多くのシステムは実用的な混合を使います:両方の検索を実行し、スコアを正規化して比較可能にし、重み付け(例:ID にはキーワードを重視)を適用します。製品によっては統合したショートリストを軽量モデルやルールで再ランクしており、フィルタはまず適切なサブセットを保証します。
RAG(Retrieval-Augmented Generation)は LLM からより信頼できる回答を得るための実践的パターンです:まず関連情報を取得し、その後生成する。
会社のドキュメントをモデルに「記憶させる」代わりに、ドキュメントを埋め込みとしてベクトルデータベースに保存し、質問時に最も関連性の高いチャンクを取得して LLM に渡します。
LLM は生成が得意ですが、必要な事実がないと自信満々に穴を埋めることがあります。ベクトルデータベースはナレッジベースから意味的に最も近いパッセージを取得してプロンプトに供給することで、モデルを「創作」から「これらのソースを要約・説明する」モードにシフトさせます。
また、どのチャンクが取得されたかを追跡し、引用として表示することで回答の監査が容易になります。
RAG の品質はモデルよりもチャンク化に依存することがよくあります。
この流れを想像してください:
ユーザー質問 → クエリを埋め込み → ベクトルDBで top-k チャンクを取得(メタデータフィルタ付き)→ 取得チャンクをプロンプトに組み込む → LLM が回答を生成 → 回答とソースを返す。
ベクトルデータベースは各リクエストに最も関連する証拠を素早く供給する「速い記憶」として中央に位置します。
ベクトルデータベースは単に検索を「賢く」するだけでなく、ユーザーが自然言語で求めることを記述しても関連結果が返るような製品体験を可能にします。以下は頻出する実用的なユースケースです。
サポートチームはナレッジベース、過去チケット、チャットの記録、リリースノートを持っていますが、キーワード検索は同義語や言い換え、あいまいな問題記述で苦戦します。
セマンティック検索を使えば、エージェント(またはチャットボット)が表現は違っても意味が同じ過去チケットを取得でき、対応速度が上がり重複作業が減り、新人の立ち上がりも早くなります。ベクトル検索とメタデータフィルタ(製品ライン、言語、問題タイプ、日付範囲)を組み合わせると結果が絞りやすくなります。
買い物客は製品名を正確に知らないことが多く、「ラップトップが入る小さめのビジネス用バックパック」のように用途や要望で検索します。埋め込みはスタイル、機能、制約といった好みを取り込み、結果は人間の販売担当に近い感覚になります。
この手法は小売カタログ、旅行リスト、不動産、求人ボード、マーケットプレイスなどで有効です。価格、サイズ、在庫、ロケーションなどの構造化された制約と意味的関連性を組み合わせられます。
ベクトルデータベースの典型機能は「これに似たものを探す」です。ユーザーがアイテムを閲覧したり記事を読んだり動画を見たりしたとき、カテゴリが一致しなくても意味や属性が似ている他のコンテンツを取得できます。
用途例:
社内の情報はドキュメント、Wiki、PDF、会議メモに散らばっています。セマンティック検索を使うと従業員は自然言語で質問して正しいソースを見つけられます(例:「会議費の精算ポリシーは?」)。
ここで絶対に必要なのはアクセス制御です。結果はチーム、ドキュメント所有者、機密レベル、ACL リストでフィルタして、ユーザーが参照可能なものだけが返るようにする必要があります。
これをさらに進めると、先述の RAG 型 Q&A システムの土台にもなります。
セマンティック検索はそれに供給するパイプラインが堅牢であるかどうかに依存します。ドキュメントが不整合に到着し、チャンク化が悪く、編集後に再埋め込みされないと、結果はユーザーの期待から逸れていきます。
多くのチームは次の手順を繰り返します:
多くの勝敗は「チャンク」ステップで決まります。チャンクが大きすぎると意味が希薄になり、小さすぎると文脈が失われます。実用的には見出し・段落・Q&A ペアなどの自然な構造でチャンク化し、継続性のために小さなオーバーラップを入れるのが良い方法です。
コンテンツは常に変化します—ポリシーは更新され、価格は変わり、記事は書き直されます。埋め込みは派生データとして再生成する必要があります。
一般的な対策:
複数言語に対応する場合、多言語埋め込みモデルを使うか、言語ごとのモデルを使うか選べます。前者は簡潔で、後者は品質が高いことがあります。モデルを試す場合は埋め込みのバージョン(例:embedding_model=v3)を管理して A/B テストやロールバックが可能にしてください。
セマンティック検索はデモで良さそうに見えても本番で失敗することがあります。違いを生むのは計測です:実ユーザーの振る舞いに近いクエリで、明確な関連性指標と速度目標を評価する必要があります。
まずは少数の指標を決め、それを継続的に使い続けてください:
評価用データセットは次のソースから作成します:
テストセットはバージョン管理して、リリース間で比較できるようにしてください。
オフラインの指標だけでは不十分です。A/B テストを行い、軽量なシグナルを収集してください:
これらを使って関連性判断を更新し、失敗パターンを発見します。
パフォーマンスが変わるのは次のようなときです:
変更後はテストスイートを再実行し、MRR/nDCG の急落や p95 レイテンシーの急上昇にアラートを設定して週次でモニタリングしてください。
ベクトル検索はデータの取得方法を変えますが、誰が見られるかを変えてはいけません。セマンティック検索や RAG システムが正しいチャンクを「見つけられる」なら、設計を誤ると誤ってユーザーが参照すべきでないチャンクを返してしまう可能性があります。
最も安全なルールは簡単です:ユーザーは参照できるコンテンツだけを取得する。ベクトルデータベースが結果を返す前に(アプリ側で隠すのではなく)その段階で権限を適用してください。なぜなら一度外部に出てしまうと境界が越えられてしまうからです。
実用的アプローチ:
多くのベクトルDBは tenant_id, department, project_id, visibility のようなメタデータベースのフィルタをサポートし、類似度検索と一緒に適用できます。正しく使えば取得時に権限を適用するクリーンな方法です。
重要な点:そのフィルタは必須かつサーバーサイドで適用され、クライアント側のロジックに依存してはいけません。ロールの組み合わせが爆発的に増える場合は「有効なアクセスグループ」を事前計算するか、クエリ時にフィルタトークンを発行する専用の認可サービスを検討してください。
埋め込みは元テキストの意味を符号化します。埋め込み自体が生の PII を自動的に露出するわけではありませんが、検索で特定の機微情報が取り出しやすくなるリスクがあります。
推奨ガイドライン:
ベクトルインデックスは本番データとして扱ってください:
これらをうまく設計すれば、セマンティック検索はユーザーにとって魔法のように感じられますが、後でセキュリティ上の問題になることはありません。
ベクトルデータベースは「差し込めば動く」ように見えますが、多くの失望は周辺の選択(チャンク化、埋め込みモデルの選択、常時の鮮度維持)から来ます。
不適切なチャンク化は最も多い原因です。チャンクが大きすぎると意味が希薄になり、小さすぎると文脈が失われます。ユーザーが「正しいドキュメントは見つかったが、間違った箇所が返された」と言う場合はチャンク化戦略を見直してください。
埋め込みモデルのミスマッチは、流暢だがトピックがずれている結果として現れます。これはモデルがあなたのドメイン(法務、医療、サポートチケットなど)やコンテンツタイプ(表、コード、多言語テキスト)に適していないときに起こります。
データの陳腐化は信頼を急速に失わせます:最新ポリシーを検索して古い版が返るとユーザーは信用しません。ソースが変わると埋め込みとメタデータを更新し、削除は確実に行ってください。
立ち上げ当初はコンテンツが少なかったり、クエリが少なくてチューニングできていないことがあります。対策:
コストは主に次の4つから発生します:
ベンダー比較時は、ドキュメント数、平均チャンクサイズ、ピーク QPS を用いた簡単な月次見積もりを依頼してください。多くの驚きはインデックス化後やトラフィックスパイク時に起こります。
次の短いチェックリストを使って適切なベクトルデータベースを選んでください:
良い選択は最新のインデックスタイプを追いかけることではなく、データを新鮮に保ち、アクセスを制御し、コンテンツとトラフィックが増えても品質を維持できる信頼性を選ぶことです。
キーワード検索は厳密なトークン一致を行います。セマンティック検索は意味を比較してマッチさせます。具体的には埋め込み(ベクトル)を使い、表現が異なっていても意図が近い結果を返せます(例:「stop payments」→「cancel subscription」)。
ベクトルデータベースは埋め込み(数値配列)と ID やメタデータを格納し、クエリにもっとも意味が近いアイテムを高速に見つけるための最短近傍(nearest-neighbor)検索を行います。大量(しばしば百万件単位)のベクトルに対する類似度検索に最適化されています。
埋め込みはモデルが生成する数値上の「指紋」です。数値自体を直接読むものではなく、類似度を測るために使います。
実際の流れ:
通常のレコードは次のような項目を含みます:
メタデータは次の2つの重要な役割を果たします:
メタデータが不十分だと、意味は合っていても文脈が間違った結果を表示したり、アクセス制御が破られたりします。
一般的な選択肢は次の通りです:
埋め込みモデルは特定の指標を念頭に訓練されていることが多いので、モデル提供者の推奨指標を使うのが重要です。間違った指標はランキング品質を確実に悪化させます。
正確検索(exact)はクエリを全ベクトルと照合して本当の最短近傍を見つけますが、スケールすると遅く高コストです。
ANN(approximate nearest neighbor)はインデックス構造を使って候補を絞り、ほとんどの場合「十分に近い」結果をずっと高速に返します。ANNはレイテンシーとリコール(真の上位候補をどれだけ見つけるか)をトレードオフで調整できます。
ハイブリッド検索は次を組み合わせます:
コーパスに「必ず一致させたい文字列」が含まれる場合(製品名の修飾語、注文番号、エラーコードなど)はハイブリッドがよいデフォルトです。
RAG(Retrieval-Augmented Generation)は LLM の出力を信頼性の高いものにする実践的なパターンです:
典型的なフロー:
これによりモデルの幻覚(hallucination)が減り、どのチャンクが使われたかを監査できるようになります。
特に影響が大きい失敗パターンは次の通りです:
対策として、構造に基づくチャンク化、埋め込みのバージョン管理、サーバー側で必須のメタデータフィルタ(例:tenant_id や ACL フィールド)を強制してください。
title, url, tags, language, created_at, tenant_id)ベクトルが意味的な類似性を提供し、メタデータはフィルタリング、アクセス制御、表示に使われます。