2025年5月18日·2 分
ビジネス仮説を時間経過で追跡するウェブアプリの作り方
ビジネス仮説を記録し、証拠を紐付け、時間経過で変化を追跡してチームに見直し・検証を促すウェブアプリの設計と構築方法を学ぶ。
ビジネス仮説を記録し、証拠を紐付け、時間経過で変化を追跡してチームに見直し・検証を促すウェブアプリの設計と構築方法を学ぶ。
ビジネス仮説とは、チームが完全に証明されていない状態で基にしている信念です。例えば:
こうした仮説はピッチ、ロードマップ議論、営業の会話、廊下での雑談など至る所に現れ、そのまま見失われがちです。
多くの場合、チームが仮説を放置するのは無関心だからではありません。ドキュメントの陳腐化、役割交代、知識の“部族化”によって散逸するのです。最新の「真実」はドキュメント、Slack、数件のチケット、そして誰かの記憶に分散します。
そうなると、同じ議論を繰り返したり、同じ実験を再実行したり、まだ検証されていないことに基づいて意思決定をしてしまいます。
シンプルな仮説追跡アプリがもたらすもの:
プロダクトマネージャー、創業者、グロース、リサーチ、セールスリーダーなど、賭けをする人全般が恩恵を受けます。まずは軽量な「仮説ログ」から始め、常に最新に保ちやすいものにして、利用状況に応じて機能を拡張してください。
画面設計や技術選定の前に、何を保存するかを決めてください。明確なデータモデルはプロダクトの一貫性を保ち、後で集計・レポートを可能にします。
チームがアイデアを検証する流れに沿って、まずは5つから始めましょう:
Assumptionは素早く作成でき、かつ実行可能であるべきです:
レビューワークフローを動かすためにタイムスタンプも必要です:
検証の流れをモデル化します:
必須は最小限に: statement、category、owner、confidence、status のみ。タグ、impact、リンクなどは任意にして、人が素早くログできるようにし、証拠が集まってから詳細化できるようにします。
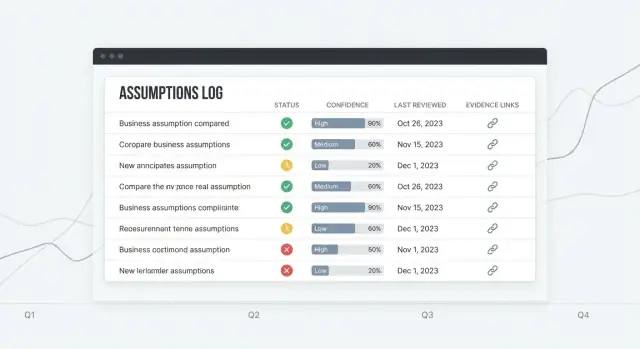
ログが役立ち続けるためには、各エントリに一目で意味が伝わる必要があります:ライフサイクルの位置、どれだけ信じているか、いつ再確認すべきか。このルールはチームが無意識に推測を事実扱いするのを防ぎます。
全ての仮説に対して1つのステータスフローを使います:
Draft → Active → Validated / Invalidated → Archived
1–5のスケールを取り、各値を平易に定義します:
“confidence”は「どれだけそれを望んでいるか」ではなく「証拠の強さ」についてにしてください。
Decision impact: Low / Medium / High を追加します。高影響の仮説は価格、ポジショニング、Go-to-market、主要な開発判断に影響するため優先的に検証すべきです。
各仮説ごとに具体的な基準を書きます:どの結果が“合格”を意味するのか、最低限の証拠は何か(例:30件以上のアンケート回答、10件以上の営業通話で一貫したパターン、事前定義の成功指標を満たすA/Bテスト、3週間のリテンションデータ)。
自動レビューのトリガーを設定します:
これにより “validated” が「永遠の真実」にならないようにします。
仮説追跡アプリはスプレッドシートより速く感じられることが成功の鍵です。人が週に何度も繰り返す数少ない操作に合わせて設計してください:仮説を追加する、信念を更新する、学びを添付する、次のレビュー日を設定する。
ループを短く保ちます:
Assumptions list はホームベース:読みやすいテーブル(Status、Confidence、Owner、Last reviewed、Next review)と、目立つ“Quick add”行を用意して完全なフォームを要求しない。
Assumption detail は意思決定が行われる場所:上部に短い要約、その下に更新のタイムライン(ステータス変更、信頼度変更、コメント)、専用の Evidence パネル。
Evidence library は学びの再利用を支援:タグ、ソース、日付で検索し、複数の仮説に証拠を紐付け可能。
Dashboard は「注意が必要なもの」を答える:予定されているレビュー、最近変更された仮説、低信頼度のハイインパクト項目を表示。
フィルタは永続化して高速に:category、owner、status、confidence、last reviewed date。テンプレート、デフォルト値、段階的表示(詳細フィールドは必要になるまで非表示)で雑多さを減らす。
高コントラストテキスト、明確なラベル、キーボード操作対応。テーブルは行フォーカス、ソート可能なヘッダ、読みやすい余白をサポートする(特にステータスと信頼度のバッジ)。
仮説追跡アプリは大半がフォーム、フィルタ、検索、監査トレイルです。これは良いニュース:単純で確実なスタックで価値を早く出し、ワークフロー(レビュー規則、証拠、意思決定)に注力できます。
一般的で実用的な構成:
チームが既に知っている技術を選ぶことを優先してください。整合性は新技術より重要です。
プロトタイプを早く作りたい場合は、Koder.ai のようなビブコーディングプラットフォームを使うと、チャットでデータモデルや画面を記述し、Planning Modeで反復してReact UIと本番対応のバックエンド(Go + PostgreSQL)を生成し、後でソースコードとしてエクスポートできます。
Postgresは各仮説がワークスペースに属し、オーナーや証拠、実験とリンクするような「つながりのある」データを扱うのに向いています。ステータス、信頼度、レビュー期限、タグ、オーナーでの検索に対してインデックスが効き、バージョン履歴や変更ログを追加する場合にも監査に適しています。変更イベントは別テーブルに格納してレポーティング可能にできます。
マネージドサービスを目標に:
運用負荷を減らすことで「運用するだけで週が潰れる」リスクを低減します。
Koder.ai はデプロイやホスティング、カスタムドメイン、スナップショット/ロールバックなどを提供して早期のワークフロー改良を支援できます。
CRUD、検索、アクティビティフィードのために RESTエンドポイント から始めましょう。デバッグやドキュメントが簡単です。多数の関連オブジェクトをまたぐクライアント主導の複雑なクエリが本当に必要になったらGraphQLを検討してください。
初日から3つの環境を想定します:
この構成は過剰設計せずに仮説追跡を支えます。
共有されるログなら、アクセス制御は退屈で予測可能であるべきです。誰が見られるか、編集できるか、承認できるかを明確にしつつ、チームの速度を落とさないようにします。
多くのチームでは メール+パスワード で十分にローンチできます。大企業やITポリシーが厳しい場合は Google / Microsoft SSO を追加してください。両方サポートする場合はワークスペースごとに管理者が選べると良いです。
ログインの表面は最小限に:サインアップ、サインイン、パスワードリセット、(必要なら)MFAを後から強制できるように。
ロールは一度定義してアプリ全体で一貫させます:
権限チェックはUIだけでなくサーバー側で必ず行ってください。将来「承認」ワークフローを追加する場合、それは新しいロールではなく権限として扱うべきです。
ワークスペース はデータとメンバーの境界です。各仮説、証拠、実験は正確に1つのワークスペースに所属させ、代理店や複数プロダクトを持つ企業が誤って共有しないようにします。
メール招待に有効期限を付け、オフボーディング時はアクセスを削除しつつ履歴は残す方針にします:過去の編集は元の実行者を表示するべきです。
最低限の監査ログを保持してください:誰がいつ何を変更したか(ユーザーID、タイムスタンプ、オブジェクト、アクション)。これは信頼性、説明責任、後で意思決定が問われた時のデバッグに役立ちます。
CRUDは仮説ログを単なるドキュメントではなくシステムに変えます。目的は単に作成・編集することではなく、あらゆる変更を理解可能かつ元に戻せるようにすることです。
最低限サポートすべき操作:
UIではこれらの操作を仮説詳細ページの近くに配置:明確な「編集」、専用の「ステータス変更」、意図的にクリックしにくい「アーカイブ」ボタンなど。
実務的な戦略は2つあります:
多くのチームはハイブリッドを採用:主要な編集はスナップショット、細かい操作はイベントとして記録。
各仮説に タイムライン を提供:
重要な編集(ステータス/信頼度の変更、アーカイブ等)には短い「理由」を必須にして、軽い意思決定ログとして扱いましょう:何が変わったか、どの証拠がトリガーか、その次に何をするかを残します。
破壊的なアクションには確認を入れる:
これにより、急いで作業しても履歴が信頼できるものになります。
証拠がない仮説は危険です。チームが証拠を添付し、軽量な実験を記録できるようにして、すべての主張にトレース可能な軌跡を持たせます。
一般的な証拠タイプをサポートします:インタビューノート、アンケート結果、製品や収益の指標、ドキュメント(PDF、スライド)、単純なリンク(分析ダッシュボード、サポートチケット等)。
証拠を添付する際には、数点のメタデータを取得して数か月後でも有用にします:
重複アップロードを避けるため、証拠は独立したエンティティとして扱い、many-to-many の関係で仮説に紐付けます。ファイルは一度保存するか、リンクのみ保持して複数の仮説と関連付けるべきです。
簡単に記入できる Experiment オブジェクトを追加:
実験はテストする仮説に紐付け、生成された証拠(チャート、ノート、指標スナップショット)を自動的に添付できると便利です。
簡単なルブリック(Weak / Moderate / Strong)を使い、ツールチップで説明します:
目的は完璧さではなく“確信”を明示化し、感覚での判断が意思決定を左右しないようにすることです。
仮説は静かに陳腐化します。シンプルなレビューのワークフローがあれば「再検討すべき」が習慣になり、ログが有用であり続けます。
レビュー頻度は 影響度 と 信頼度 に紐づけます:
次回レビュー日は仮説に保存し、impact/confidence が変わったら自動再計算します。
メール と アプリ内 通知の両方をサポート。デフォルトは保守的にして、期限超過時に1回の催促、続いて穏やかなフォローアップにします。
ユーザー/ワークスペースごとに設定可能に:
長いリストを送る代わりに、焦点を絞ったダイジェストを作成:
これらはUIのフィルタと同じロジックを共有し、ダッシュボードと通知の両方で使えるようにします。
エスカレーションは予測可能で軽量に:
各リマインダーやエスカレーションは仮説のアクティビティ履歴に記録して、いつ何が起きたか見えるようにします。
ダッシュボードは仮説ログをチームが実際に参照するものに変えます。目的は派手な分析ではなく、何がリスクか、何が陳腐化しているか、何が変化しているかを素早く見えるようにすることです。
小さなタイル群から始めます:
各KPIはクリックでアクション可能なビューへ遷移できるようにします。
検証済み vs 無効化 の推移を単純な折れ線で表示すると、学習の加速・停滞がわかります。注意点:
役割ごとに異なる問いがあるため、保存されたフィルタを提供します:
保存ビューは共有可能な安定URL(例:/assumptions?view=leadership-risk)で提供します。
Impact が High で Evidence strength が Low(または confidence が低い)項目を「Risk Radar」テーブルで浮き彫りにします。計画やプレモーテムの議題になります。
レポートは持ち運べる形にします:
これにより会議中に全員がログインする必要がなくなります。
アプリは既存の運用に馴染む必要があります。インポート/エクスポートで素早く始められ、軽量な統合で手作業を減らします。ただしMVPを統合プラットフォームにしないよう注意。
まずはCSVエクスポートを提供します:assumptions、evidence/experiments、change logs の3テーブル。列は予測可能に(ID、statement、status、confidence、tags、owner、last reviewed、timestamps)。
UX上の小さな配慮:
多くのチームは乱雑なGoogleシートから始めます。以下のインポートフローを提供しましょう:
インポートは初期導入の最速ルートになることが多いので、ファーストクラス機能として扱い、期待フォーマットとルールを /help/assumptions に文書化してください。
統合は任意にしてコアアプリをシンプルに保ちます。実務的なパターンは2つ:
assumption.created、status.changed、review.overdue 等のイベントを発火即時価値のために、Slackへの基本的なアラート統合(Webhook)をサポートすると良いです:ハイインパクト仮説のステータス変更やレビュー期限超過時にポストして認知を促します。
仮説ログは機密情報を含むことがあるため、初期から“安全がデフォルト”となる設計をしてください。人は会話のメモや内部決定を貼り付けるため、取り扱いに注意が必要です。
最小権限の原則を適用:
マルチテナントアプリでの漏洩は認可バグが原因です。ワークスペース隔離を第一級のルールにしましょう:
workspace_id を含める実行可能なシンプルな計画を定義:
保存する内容は慎重に:ノートや添付に秘密情報(APIキー、パスワード、プライベートリンク)が入らないよう注意喚起を出すか、一般的なパターンの自動マスキングを検討してください。
診断のためにリクエストボディ全体をログに残すべきではありません。必要ならメタデータ(workspace ID、record ID、エラーコード)をログに残してください。
インタビューノートは個人データを含む可能性があります。対応策:
/settings や /help への短いプライバシーノートで何を保存し、なぜ保存するかを説明する仮説アプリの出荷は「完成」ではなく、安全に実ワークフローに組み込み、利用に基づいて学習することがゴールです。
ユーザー公開前に繰り返して実行できるチェックリスト:
ステージングがあるなら、特にバージョン履歴やチェンジログに関わるリリースはそこで試してください。
シンプルに始めましょう:
ミスが高コストになる箇所にテストを集中:
テンプレートとサンプル仮説を用意し、空の画面で途方に暮れないようにします。短いガイドツアー(3–5ステップ)で:どこに証拠を追加するか、レビューがどう働くか、決定ログの読み方を示します。
ローンチ後は実際の行動に基づいて優先順位を付け:
迅速に反復するなら、チャットブリーフから画面とバックエンド変更を起こせるツール(例:Koder.ai)を使い、スナップショットとロールバック で安全に実験を出し、製品方針が固まったらコードをエクスポートするワークフローが有効です。
チームが十分に証明されていない状態で行動している、単一でテスト可能な信念を追跡します(例:市場需要、支払い意欲、オンボーディングの実現可能性)。重要なのは、それを明示化し、所有者を決め、定期的に見直せるようにして、“なんとなく事実”になってしまうことを防ぐことです。
仮説(assumption)がドキュメント、チケット、チャットなどに散らばり、役割の変化で記憶が失われるためです。専用のログは「最新の真実」を一箇所に集め、同じ議論や実験の繰り返しを防ぎ、何がまだ未検証かを可視化します。
プロダクト、創業者、グロース、リサーチ、営業リーダーなど、週次で仮説に賭けている人たちに向いています。
MVPは軽量に始めましょう:
実際の利用が増えたら必要に応じて機能を拡張してください。
最初に実装すべき実用的なコアは5つのオブジェクトです:
このモデルはトレーサビリティを確保しつつ、初期構築を複雑にしすぎません。
アクション可能にするために最低限必要な項目だけを必須にしましょう:
他はオプションにして摩擦を下げます(タグ、影響度、リンクなど)。また、リマインダーやワークフローのために last reviewed や next review といったタイムスタンプは保持してください。
一貫したフローと明確な定義を使ってチームが共通認識を持てるようにします:
信頼度は1–5のスケールを用い、証拠の強さに基づいて定義してください。また、Decision impact(低/中/高) を付けて優先度を決めます。
各仮説ごとに検証基準を明確に書き出します。例:
検証基準を決めることで“誰かの感覚で検証済み”になるのを防ぎます。
初期に必要な画面とフロー:
日常的に行われる操作(追加、ステータス変更、証拠添付、次回レビュー設定)を最短でできるように最適化してください。
安定して導入できる堅実なスタック例:
Postgresはリレーション(assumptions ↔ evidence/experiments)やインデックス、監査に向きます。まずはCRUDとアクティビティフィードのために REST を使うのが簡単です。
早期はシンプルに始め、必要に応じて SSO を追加します:
workspace_id)マルチテナントではデータ隔離をデータベースレイヤー(RLS 等)で保護してください。