2025年10月02日·1 分
ブレンダン・バーンズとKubernetes:オーケストレーションを形作ったアイデア
ブレンダン・バーンズのKubernetes時代のオーケストレーションの考え方—宣言的状態、コントローラ、スケーリング、サービス運用—がなぜ標準になったのかを実務的に解説。
ブレンダン・バーンズのKubernetes時代のオーケストレーションの考え方—宣言的状態、コントローラ、スケーリング、サービス運用—がなぜ標準になったのかを実務的に解説。
Kubernetesは単なる新しいツールの導入にとどまらず、“日々の運用”のあり方そのものを変えました。何十、何百ものサービスを運用する状況では、オーケストレーション以前はチームがスクリプトや手作業のランブック、属人的な知識で同じ問いに繰り返し対処していました:このサービスはどこで動かすべきか? どう安全に変更を展開するか? 深夜2時にノードが落ちたらどうする?
本質的には、オーケストレーションはあなたの意図(「こう動かしたい」)と、機械の故障、トラフィック変動、継続的なデプロイといった現実の間をつなぐ調整層です。各サーバーを特別扱いする代わりに、計算資源をプールとして扱い、ワークロードを移動可能なスケジューラブルな単位として扱います。
Kubernetesはチームが「何を望むか」を記述し、システムがその記述に現実を合わせ続けるモデルを普及させました。この変化は、運用をヒーロー的な対応から再現可能なプロセスへと変えます。
Kubernetesは多くのサービスチームが必要とする運用上の成果を標準化しました:
この記事はKubernetes(およびBrendan Burnsのようなリーダー)に関連するアイデアとパターンに焦点を当てており、個人の伝記ではありません。また「始まり方」や「設計理由」を語る際には、会議の発表、設計ドキュメント、上流ドキュメントといった公開情報に基づくべきで、神話化された話ではなく検証可能なストーリーにすることを意図しています。
ブレンダン・バーンズは、Joe Beda、Craig McLuckieと並んでKubernetesの共同創設者の一人として広く認識されています。Googleでの初期のKubernetes作業において、Burnsは技術的な方向性とプロジェクトのユーザーへの説明方法の形成に寄与しました。特に「コンテナをどう実行するか」だけでなく「ソフトウェアをどう運用するか」に焦点を当てていました(出典:Kubernetes: Up & Running(O’Reilly)、KubernetesプロジェクトのAUTHORS/メンテナ情報)。
Kubernetesは完成した社内システムとして単に公開されたわけではなく、増え続ける貢献者、ユースケース、制約とともに公開の場で作られていきました。そのオープンさが、さまざまな環境で生き残れるインターフェイスへの設計を後押ししました:
この協調的なプレッシャーは、Kubernetesが何を最適化したかに影響を与えました:多くのチームが合意できる共有プリミティブと再現可能なパターンです。
Kubernetesが「デプロイや運用を標準化した」と言うとき、それはすべてのシステムを同一にしたという意味ではありません。むしろ、共通の語彙とワークフローを提供したという意味です:
共通モデルがあることで、ドキュメントやツール、チームのプラクティスが会社間で移転しやすくなりました。
Kubernetes(オープンソースプロジェクト)とKubernetesエコシステムは分けて考えると有益です。
プロジェクトはコアのAPIとコントロールプレーンコンポーネントで構成されるプラットフォーム本体です。エコシステムはそこから成長したものすべて――ディストリビューション、マネージドサービス、アドオン、関連するCNCFプロジェクト――を指します。実運用で多くのチームが依存する「Kubernetesの機能」の多くは、コアではなくエコシステム側(観測スタック、ポリシーエンジン、GitOpsツール等)に存在しています。
宣言的な設定は、システムを記述する方法の単純な転換です:手順(ステップ)を列挙するのではなく、達成したい最終結果を記述します。
Kubernetesの文脈では、プラットフォームに「コンテナを起動してポートを開けて、クラッシュしたら再起動する」と逐次命令するのではなく、「このアプリのコピーを3つ動かし、このポートで到達可能にし、このコンテナイメージを使う」と宣言します。Kubernetesはその宣言と現実を一致させる責任を負います。
命令型の運用はランブックのようなものです:前回有効だったコマンド列を再実行して対応します。
望ましい状態は契約に近いものです。設定ファイルに意図した結果を記録し、システムが継続的にその結果に向けて動きます。もしドリフトが起きれば(インスタンスが死ぬ、ノードが消える、手動変更が入るなど)、プラットフォームが不一致を検出して修正します。
以前(命令型ランブック思考):
このやり方は成り立ちますが、サーバーが“スノーフレーク化”し、限られた人しか信用しない長いチェックリストが残りがちです。
以後(宣言的な望ましい状態):
apiVersion: apps/v1
kind: Deployment
metadata:
name: checkout
spec:
replicas: 3
selector:
matchLabels:
app: checkout
template:
metadata:
labels:
app: checkout
spec:
containers:
- name: app
image: example/checkout:1.2.3
ports:
- containerPort: 8080
ファイルを変更(たとえば image や replicas を更新)して適用すれば、Kubernetesのコントローラが実行中の状態を宣言と一致させるように働きます。
宣言的な望ましい状態は「この17ステップを実行する」から「こうしておけ」に変えることで運用工数を下げます。また、設定の真実の単一のソースが明示的でレビュー可能(多くはバージョン管理)になるため、ドリフトが減り、驚きが発生しにくく、監査やロールバックが容易になります。
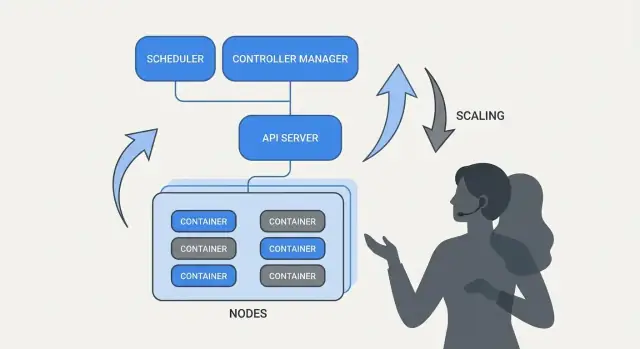
Kubernetesが“自己管理的”に感じられるのは、単純なパターンの上に成り立っているからです:望ましい状態を記述すると、システムが現実をその記述に合わせて継続的に動く。エンジンはコントローラです。
コントローラはクラスタの現在状態を監視し、YAMLやAPIで宣言された望ましい状態と比較して差分があればその差分を埋めるアクションを取るループです。
一度だけ動くスクリプトではなく、人間のクリックを待つものでもありません。繰り返し実行される(観察→判断→行動)ことで、いつでも変化に応答できます。
その繰り返しの比較と修正の振る舞いをリコンシリエーションと言います。これは「自己修復」の一般的な保証の背後にあるメカニズムです。システムは障害を魔法のように防ぐわけではなく、ドリフトを検出して修正します。
ドリフトは以下のような日常的な理由で起きます:
リコンシリエーションはKubernetesがそれらのイベントを意図を再チェックして復元するための合図として扱うことを意味します。
コントローラは親しみのある運用結果に変換されます:
核心は、症状を手動で追いかけるのではなく、目標を宣言し制御ループが継続的に「その状態にしておく」作業を行う点です。
この方法は単一のリソース型に限定されません。Kubernetesは同じコントローラとリコンシリエーションの考え方をDeployments、ReplicaSets、Jobs、Nodes、Endpointsなど多くのオブジェクトに適用しています。この一貫性が、プラットフォーム化の大きな理由です:パターンを理解すれば、新しい機能(カスタムリソースを含む)を追加したときの挙動を予測できます。
もしKubernetesが単に「コンテナを動かす」だけなら、どこでワークロードを走らせるかという最も難しい部分は残ったままです。スケジューリングはPodを適切なノードに自動的に配置する組み込みの仕組みで、リソース要求やルールに基づいて配置します。
配置決定は稼働時間とコストに直接影響します。混雑したノードに固定されたWeb APIは遅くなるかクラッシュする可能性があります。バッチジョブがレイテンシに敏感なサービスの隣に置かれればノイズィネイバー問題を引き起こします。KubernetesはこれをスプレッドシートとSSHによる手作業ではなく、再現可能な製品機能に変えます。
基本的には、スケジューラはPodの要求を満たせるノードを探します。
この単純な習慣――現実的なrequestsを設定すること――がランダムな不安定性を減らすことが多いです。重要なサービスが他のものと奪い合わなくなります。
リソース以外に、実稼働クラスタではいくつかの実務的なルールが使われます:
スケジューリング機能は運用意図をコード化します:
実用的な要点:スケジューリングルールをプロダクト要件として扱い、文書化・レビューし、一貫して適用することで、信頼性が深夜の誰かの記憶に依存しないようにすることです。
Kubernetesのもっとも実用的な考え方の一つは、スケーリングにアプリコードの書き換えや新しいデプロイ方式が不要であるべきだ、という点です。アプリが1つのコンテナで動くなら、同じワークロード定義で通常は数百〜数千のコピーまで拡張できます。
Kubernetesはスケーリングを二つの関連する決定に分けます:
この分割は重要です:200個のPodを要求しても、クラスタに50しか場所がなければスケーリングは保留(Pending)になります。
Kubernetesでは一般に三つのオートスケーラが使われます。それぞれ異なるレバーにフォーカスします:
これらを組み合わせると、スケーリングは「レイテンシを一定に保つ」や「CPUをX%に保つ」といったポリシーになります。手動で誰かを呼び出す作業ではなくなります。
スケーリングは入力の質に依存します:
繰り返し見かけるミスは二つ:間違ったメトリクスでスケールする(CPUは低いがリクエストがタイムアウトする)ことと、リソースrequestsを設定していないこと(オートスケーラが容量を予測できずPodが詰め込まれて性能が不安定になる)。
Kubernetesが普及させた大きな転換は「デプロイを単発のスクリプトではなく継続的な制御問題として扱う」ことです。ローアウトとロールバックはファーストクラスの振る舞いです:どのバージョンを望むか宣言すれば、Kubernetesが可用性を確認しながらその状態に向けてシステムを移行します。
Deploymentではローアウトは古いPodを段階的に新しいPodに置き換えるプロセスです。一度に全てを止めて再起動するのではなく、容量を保ちながら実トラフィックで新バージョンを検証できます。
新バージョンが失敗し始めたら、ロールバックは緊急の手順ではなく通常の操作になります:以前のReplicaSet(最後に正常だったバージョン)へ戻してコントローラに旧状態を復元させます。
ヘルスチェックはローアウトを希望的観測から計測可能なものに変えます。
プローブを適切に使うことで、Podが単に起動しただけで見かけ上は成功しているが実際にはリクエストを処理できない、という誤判定を減らせます。
Kubernetesはローリングアップデートを標準でサポートしますが、チームはしばしばその上に別のパターンを重ねます:
安全なデプロイは信号に依存します:エラー率、レイテンシ、飽和度、ユーザー影響です。多くのチームはロールアウトの意思決定をSLOとエラーバジェットに紐づけます—もしカナリアが許容されるバジェットを消費しすぎたら昇格を止めます。
目標は、失敗時に自動的にロールバックするトリガー(readinessの失敗、5xxの増加、レイテンシの急上昇など)を持つことで、「ロールバック」が予測可能なシステム応答になり、深夜のヒーロー対応を減らすことです。
コンテナプラットフォームが“自動的”に感じられるのは、他のシステム要素がアプリを動的に見つけられるときです。実運用のクラスタではPodは作成、削除、再スケジュール、スケールを常に繰り返します。もし変更のたびにIPアドレスを設定に書き換えなければならないなら、運用は忙殺され、障害が常態化します。
サービスディスカバリはクライアントが変化するバックエンド群に確実に到達する方法を与えます。Kubernetesの重要な変化は、個々のインスタンス(「10.2.3.4を呼べ」)を狙うのをやめ、名前付きサービス(「checkoutを呼べ」)を呼ぶようにする点です。プラットフォームが現在どのPodがその名前を提供しているかを管理します。
Service はPod群の安定した入口です。クラスタ内で一貫した名前と仮想アドレスを持ち、背後のPodが変わっても表面は変わりません。
Selector はどのPodがその入口の背後にいるかを決める方法で、通常はラベル(例:app=checkout)で一致させます。
Endpoints(またはEndpointSlices)はセレクタに現在一致する実際のPod IPの生きた一覧です。Podがスケールアップ、ロールアウト、再スケジュールされるとこの一覧が自動で更新され、クライアントは同じService名を使い続けられます。
運用上、これが提供するものは:
外部からの北南トラフィックについては、Kubernetesは通常Ingressや新しいGatewayアプローチを使います。どちらもホスト名やパスでリクエストをルーティングし、TLS終端などの懸念を集中化できます。重要なのは同じ考え方:外部へのアクセスを安定させ、バックエンドは下で変わり続けられるようにする点です。
Kubernetesの「自己修復」は魔法ではありません。自動化された反応の集合です:再起動、再スケジュール、置換。プラットフォームはあなたが宣言した望ましい状態を監視し、現実をその状態へ戻すために働き続けます。
プロセスが終了するかコンテナが不健康になった場合、Kubernetesは同じノード上で再起動できます。主な駆動要因は:
実運用の典型パターンは、単一コンテナがクラッシュ→Kubernetesが再起動→ServiceはヘルシーなPodだけにルーティングし続ける、です。
ノード全体がダウンした場合(ハードウェア故障、カーネルパニック、ネットワーク喪失など)、KubernetesはそのノードをNotReadyとして検出し、ワークを他へ移します。大まかな流れは:
これがクラスタレベルでの「自己修復」です:人間がSSHで介入するのを待つ代わりに、システムが容量を置き換えます。
自己修復が意味を持つのは検証できるときだけです。チームは通常次を監視します:
Kubernetesでもガードレールが間違っていると「修復」が働かないことがあります:
自己修復が適切に設定されていれば、障害は短く小さくなり、そして何より測定可能になります。
Kubernetesが勝利したのは単にコンテナを動かせたからではありません。最も一般的な運用ニーズ(デプロイ、スケーリング、ネットワーク、観測)に対して標準化されたAPIを提供したからです。チームが同じオブジェクトの「形」(Deployment、Service、Jobなど)に合意すると、ツールを共有でき、トレーニングが簡単になり、開発と運用の引き継ぎが属人的知識に依存しなくなります。
一貫したAPIがあれば、デプロイパイプラインは各アプリの細かい違いを知らなくても同じ操作(作成、更新、ロールバック、ヘルスチェック)を実行できます。
また、整合性が向上します:セキュリティチームはガードレールをポリシーとして表現でき、SREは共通のヘルス信号に基づくランブックを標準化でき、開発者は共通語彙でリリースを考えられるようになります。
Custom Resource Definitions(CRD) でクラスタに新しいタイプのオブジェクト(例:Database、Cache、Queue)を追加できます。
Operator はそれらのカスタムオブジェクトにコントローラを組み合わせ、バックアップやフェイルオーバー、バージョンアップといった従来手動だったタスクを自動化します。重要なのは魔法ではなく、Kubernetesが他で使っている同じ制御ループのアプローチを再利用している点です。
KubernetesがAPI駆動であるため、現代的なワークフローとの統合が容易です:
これらのアイデアに基づいたより実践的なデプロイ・運用ガイドが欲しければ、/blog を参照してください。
多くのKubernetesの考え方(Brendan Burnsの初期のフレーミングに関連するものを含む)は、VM、サーバーレス、より小規模なコンテナ環境でも有効に翻訳できます。
「望ましい状態」を書き、それを自動化で守らせる。 Terraform、Ansible、CIパイプラインのいずれであれ、設定を単一の真実のソースとして扱ってください。結果として手動デプロイ手順が減り「自分の環境では動いたのに本番では動かない」という驚きが減ります。
一回きりのスクリプトではなくリコンシリエーションを使う。 一度実行して終わりのスクリプトではなく、バージョンや設定、インスタンス数、ヘルスといった重要なプロパティを継続的に検証するループを作りましょう。これが再現可能な運用と障害からの予測可能な回復につながります。
スケジューリングとスケーリングを明確な製品機能にする。 いつ、なぜキャパシティを増やすのか(CPU、キュー深さ、レイテンシのSLO)を定義します。Kubernetesのオートスケーリングがなくても、チームはスケールルールを標準化しておけば成長時にアプリを書き換えたり誰かを呼び出したりする必要が減ります。
ローアウトを標準化する。 ローリング更新、ヘルスチェック、迅速なロールバック手順は変更のリスクを下げます。ロードバランサ、フィーチャーフラグ、リリースを実際の信号でゲートするデプロイパイプラインでこれを実現できます。
これらのパターンは不適切なアプリ設計、安全でないデータマイグレーション、コスト管理を自動で解決するわけではありません。バージョン管理されたAPI、マイグレーション計画、予算/制限、デプロイが顧客影響と結びつく可観測性は別途必要です。
顧客向けサービスの1つを選んでチェックリストをエンドツーエンドで実装し、その後に他へ展開してください。
新しいサービスを素早く「デプロイ可能」にしたい場合、Koder.aiはチャット駆動の仕様からフロントはReact、バックエンドはGoとPostgreSQL、モバイルはFlutterといったフルスタックアプリを生成し、ソースコードをエクスポートしてこの記事で取り上げたKubernetesパターン(宣言的設定、再現可能なローアウト、ロールバックに優しい運用)を適用できるように支援します。コストやガバナンスを評価するチームは /pricing を確認できます。
オーケストレーションは、あなたの意図(何を動かしたいか)と現実世界の変化(ノード故障、ローリングデプロイ、スケーリングなど)を調整する仕組みです。個々のサーバーを直接管理する代わりに、ワークロードを管理し、プラットフォームに配置、再起動、置き換えを任せます。
実務的には、次を減らします:
宣言的な設定は、実行手順ではなく「達成したい結果」を述べる方法です(例:「このイメージを3レプリカでこのポートで公開する」)。
即座に使える利点:
コントローラは、クラスタの現在の状態を監視し、YAMLやAPIで宣言した望ましい状態と比較してギャップを埋めるためのループです。
このパターンによりKubernetesは一般的な結果を“自己管理”できます:
スケジューラはPodをどのノードで実行するかを決定します。制約や利用可能な容量に基づいて配置するため、手動配置に比べてノイズィネイバーやホットスポット、同一ノードへのレプリカ集中を防ぎやすくなります。
運用意図をコード化するための一般的なルール:
requestsはスケジューラに「このPodが必要とする量」を伝え、limitsはPodが使える上限を制限します。現実的なrequestsがないと配置が推測任せになり、安定性が損なわれがちです。
実務的な出発点:
Deploymentのロールアウトは古いPodを段階的に置き換える制御された遷移です。可用性を保ちながら新バージョンを検証し、問題があれば既知の良いReplicaSetへ戻す(ロールバック)ことが通常の操作になります。
安全なロールアウトに必要な要素:
Serviceは変化するPod群に対する安定したフロントドアです。ラベル/セレクタでどのPodがその背後にいるかを決め、Endpoint(EndpointSlice)が実際のPod IPの一覧を管理します。
運用上の意味:
service-name を呼べばよい各オートスケーラは異なるレバーを担当します:
よくある失敗:
CRD(Custom Resource Definition)を使うと新しいAPIオブジェクト(例:Database、Cache)をクラスタに追加できます。Operatorはそれらのカスタムオブジェクトに対してコントローラを組み合わせ、望ましい状態へ継続的にリコンシリエーションします。
よく自動化される処理の例:
ただしOperatorはプロダクションソフトウェアなので、導入前に成熟度、可観測性、障害モードを評価してください。