2025年9月27日·2 分
Blue/Green(ブルー/グリーン)と Canary(カナリア)デプロイ:明確なリリース戦略
Blue/Green と Canary デプロイの使い分け、トラフィックシフトの仕組み、監視すべき指標、そして安全なリリースのための実践的なロールアウト/ロールバック手順を解説します。
Blue/Green と Canary デプロイの意味
新しいコードを出すのは本質的にリスクがあります。理由は単純で、実際のユーザーが当たるまで本当の挙動がわからないからです。Blue/Green と Canary は、ダウンタイムをほぼゼロに保ちながらそのリスクを抑えるための一般的な手法です。
平易に言えば:Blue/Green
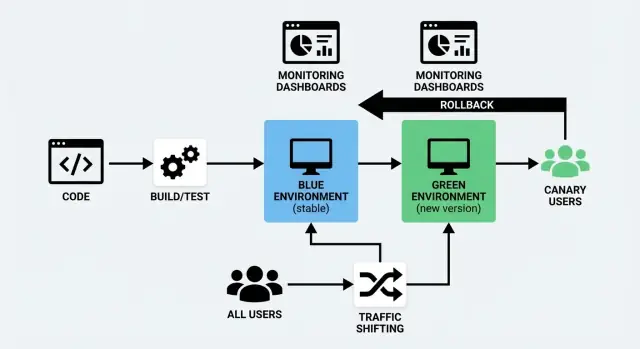
Blue/Green デプロイは、別々の似た環境を2つ用意します:
- Blue:現在ユーザーにサービスを提供しているバージョン(“本番”)。
- Green:新しいバージョンをデプロイして準備しておく、もう一つの環境。
Green 環境をバックグラウンドで準備し(ビルドをデプロイしてチェックを実行し、ウォームアップする)、確信が持てたら Blue から Green へトラフィックを切り替えます。何か問題があれば素早く戻せます。
重要なのは「色が二つあること」ではなく、クリーンで可逆的な切り替えができることです。
平易に言えば:Canary
カナリアリリースは段階的なロールアウトです。全員を一度に切り替えるのではなく、まずはごく一部(例:1〜5%)のユーザーに新しいバージョンを送ります。問題がなければ段階的に拡大し、最終的に100%にします。
重要なのは、本番トラフィックから学習してから完全移行することです。
共通の目的:ダウンタイムを抑えた安全なリリース
どちらの手法も次を目指します:
- 問題発生時のユーザー影響を減らす
- ゼロダウンタイムデプロイ(あるいはシステムが許す限りそれに近い)を実現する
- ロールバックをストレスなく予測可能にする
実現方法は異なり、Blue/Green は環境間の高速な切替に、Canary はトラフィックシフトによる制御された露出に重点を置きます。
"ベスト" は状況次第
どちらが自動的に優れているということはありません。選択はプロダクトの使われ方、テストの自信度、迅速にフィードバックが必要か、避けたい障害の種類などによります。
多くのチームは両者を組み合わせます。インフラ的には Blue/Green を使い、ユーザー露出は Canary 的に制御するなどです。
次のセクションでは両者を比較し、それぞれが向く場面を示します。
Blue/Green と Canary:クイック比較
Blue/Green と Canary はどちらもユーザーを中断させずに変更を出す方法ですが、どのようにトラフィックを新しいバージョンへ移すかが異なります。
トラフィックの切替方法
Blue/Greenは完全な2つの環境("Blue":現行、"Green":新)を走らせ、Green を検証後に一度に全トラフィックを切り替えるイメージです。
Canaryはまずごく一部(例:1–5%)に新バージョンを出し、実世界のパフォーマンスを見ながら段階的にトラフィックを移すやり方です。
実際に重要な長所と短所
| 要素 | Blue/Green | Canary |
|---|---|---|
| スピード | 検証後の切替は非常に高速 | 段階的なので意図的に遅い |
| リスク | 中程度:切り替え後に問題だと全員に影響 | 低い:完全展開前に問題が露見することが多い |
| 複雑さ | 中程度(環境が二つある、クリーンな切替が必要) | 高い(トラフィック分割、解析、段階制御が必要) |
| コスト | 高め(展開時に容量がほぼ倍になる) | 多くは低め(既存容量で段階的に増やせる) |
| 向き | 大規模で調整が必要な変更 | 頻繁に小さな改善を出す場合 |
簡単な意思決定ガイド
大きな変更、マイグレーション、旧バージョンと新バージョンを明確に分けたい場合は Blue/Green を選びます。
頻繁にデプロイし、実際の利用から安全に学びたい・影響範囲を小さくしたい場合は Canary が向きます。
迷うならまず Blue/Green で運用の簡潔さを確立し、監視とロールバックの習慣が固まったら高リスクサービスに対して Canary を導入しましょう。
Blue/Green が向いている場面
Blue/Green はリリースを“スイッチ一つ”の感覚にしたい場合に有効です。2つの本番に近い環境(Blue:現行、Green:新)を用意し、Green を検証後にルーティングします。
ほぼゼロダウンタイムが必要な場合
チェックアウト、予約、ログインダッシュボードなど、明確なメンテナンス表示が許されないプロダクトでは、Blue/Green が有効です。新バージョンはユーザーに送る前に起動・ウォームアップ・チェックを済ませられます。
最もシンプルなロールバックを求める場合
ロールバックは多くの場合トラフィックを Blue に戻すだけで済みます。これが価値を発揮するのは:
- リリースを数分で可逆的に戻す必要があるとき
- 緊急ホットフィックスを避けたいとき
- 明確で再現可能な障害対応が欲しいとき
ロールバックが再ビルドや再デプロイを必要としない点が最大の利点です。
データベース変更を互換に保てる場合
Blue/Green はデータベースのマイグレーションが後方互換であると簡単です。短期間 Blue と Green が共存する可能性があるため、両方で読み書きできる状態が理想です。
適合しやすいパターン:
- 追加の nullable カラムや新しいテーブルなどの増補的変更
- 古いコードが無視できる形でデータフォーマットを拡張する変更
適さないリスクの高い変更:カラムの削除、フィールド名の変更、意味の変化など。そうした変更は "元に戻す" 約束を破るので、段階的なマイグレーションを計画する必要があります。
環境を二重に保つ余裕とルーティング制御がある場合
Blue/Green は追加キャパシティ(二重のスタック)とトラフィック制御手段(ロードバランサ、Ingress、プラットフォームのルーティング)が必要です。環境の自動化やクリーンなルーティング手段があれば、Blue/Green は高信頼で低ドラマのリリース手段になります。
Canary リリースが向いている場面
カナリアリリースは変更をまず一部の実ユーザーに当て、学習してから拡大する手法です。大規模トラフィックかつ明確な指標があり、段階的導入でリスクを減らしたい場合に向いています。
トラフィックが多く、指標が明確なとき
Canary は高トラフィックアプリと相性が良いです。1–5% のトラフィックでも十分なデータが短時間で得られることが多く、エラー率やレイテンシ、コンバージョンなど明確なメトリクスで検証できます。
性能やエッジケースが心配なとき
本番負荷でしか現れない問題(DB クエリの遅さ、キャッシュミス、地域ごとの遅延、稀なデバイス挙動など)があります。Canary なら全ユーザーに広げる前に性能悪化やエラー増加がないか確認できます。
段階的なロールアウトが必要なとき
頻繁にリリースがあり、複数チームが寄与する場合、あるいは UI の微調整や価格実験など段階導入可能な変更は Canary が自然に合います(1% → 10% → 50% → 100%)。
機能フラグが利用できるとき
カナリアは機能フラグと非常に相性が良いです。コードを安全にデプロイし、機能は一部のユーザーや地域、アカウントに対して有効化できます。ロールバックはフラグをオフにするだけで済む場合もあり、再デプロイが不要です。
プログレッシブデリバリーを目指すなら、Canary は柔軟な出発点になります。
See also: /blog/feature-flags-and-progressive-delivery
トラフィックシフトの基礎(専門用語抜きで)
トラフィックシフトとは、新しいバージョンを誰にいつ渡すかを制御することです。全員を一度に切り替える代わりに、リクエストを段階的(または選択的)に古いバージョンから新しいバージョンに移します。これは Blue/Green と Canary の実務的な核心であり、ゼロダウンタイムデプロイを現実的にします。
“ハンドル”:どこでトラフィックをルーティングするか
スタックのどの地点でトラフィックを制御するかは複数あります。選択は既存の構成とどの程度細かく制御したいかに依存します。
- ロードバランサ:二つの環境やサーバ群にリクエストを分割する。
- Ingress コントローラ(Kubernetes):ルールに応じて異なる Service にルーティングする。
- サービスメッシュ:細かいルールと可視性でサービス間トラフィックを制御する。
- CDN / エッジルーティング:ユーザーに近い地点でのルーティングが有用な場合(主にウェブトラフィック)。
すべてのレイヤーが必要なわけではありません。ルーティング決定の“単一の真実のソース”を決め、リリース管理が推測にならないようにします。
よく使われるトラフィック分割方法
多くのチームは次のどれか(または混合)を使います:
- 割合ベース:1% → 5% → 25% → 50% → 100%。古典的なカナリアパターン。
- ヘッダベース:特定のヘッダ(QA ツールや内部テスター由来など)を持つリクエストを新バージョンへルーティング。
- ユーザコホート:従業員、ベータユーザー、特定の地域や顧客層などを優先して切り替える。
割合ベースが説明は簡単ですが、コホートは誰に見せるかを制御できるため安全なことが多いです(最初の数時間で重要顧客を驚かせないなど)。
セッションとキャッシュ:よくある落とし穴
計画が堅牢でも、次の2点で躓くことが多いです。
スティッキーセッション(セッションアフィニティ)。ユーザーを特定のサーバ/バージョンに紐づけていると、10% の分割が実際には 10% の挙動を示さないことがあります。セッション中にバージョンを行き来すると混乱する不具合も起きます。共有セッションストアを使う、あるいはルーティングでユーザーを一貫して同じバージョンに保つなど対策が必要です。
キャッシュのウォームアップ。新バージョンは CDN やアプリのキャッシュ、DB クエリキャッシュがコールドになりがちです。これはコード自体の問題でなく性能低下に見えることがあります。高トラフィックページや高コストなエンドポイントは、トラフィックを増やす前にウォームアップを計画しましょう。
トラフィック変更は管理された操作にする
ルーティング変更は単なるボタン操作ではなく、本番変更と同じ扱いにしてください。
文書化すること:
- 誰がトラフィックスプリットを変更できるか
- どうやって承認されるか(オンコール?リリースマネージャ?チェンジチケット?)
- どこで設定するか(ロードバランサ設定、Ingress ルール、メッシュポリシー)
- "停止" がどう見えるか(ロールアウトを一時停止してロールバック計画に従うトリガー)
このガバナンスがないと、「ちょっと 50% にしてみよう」と無邪気にやられている間に、検証がまだ終わっていない事態を招くことがあります。
ロールアウト中に監視すべきこと
まずロールアウトを計画
新バージョンに流す前に、手順・確認・ロールバックのトリガーを設計しましょう。
ロールアウトは「デプロイが成功したか?」だけでなく「実ユーザーの体験が悪化していないか?」を確かめることです。Blue/Green や Canary 中に落ち着いていられる方法は、システムが健全で、変更が顧客を害していないかを示す少数のシグナルを見ることです。
4つのコアシグナル:エラー、レイテンシ、飽和、ユーザー影響
エラー率:HTTP 5xx、リクエスト失敗、タイムアウト、依存サービスのエラー(DB、決済、サードパーティ)を追跡します。小さなエラー増加でもサポート負荷を生むことがあります。
レイテンシ:p50 と p95(p99 が取れるならそれも)を監視します。平均が安定でも長尾の遅延はユーザーに響きます。
飽和:CPU、メモリ、ディスク IO、DB コネクション、キュー深度、スレッドプールなどシステムの“満杯度”。飽和は大規模障害の前に現れることが多いです。
ユーザー影響シグナル:チェックアウト失敗、サインイン成功率、検索結果返却、アプリのクラッシュ率、主要ページの読み込み時間など、実際にユーザーが経験する問題を測ります。これらはインフラ指標よりも意味があることが多いです。
みんなが読める“リリースダッシュボード”を作る
ワン画面に収まる小さなダッシュボードを作り、それをリリースチャネルで共有します。ロールアウトごとに一貫したダッシュボードにしておくと、グラフ探しで時間を浪費しません。
含める項目:
- エラー率(全体+主要エンドポイント)
- レイテンシ(重要経路の p50/p95)
- 飽和(スタックの上位3つの制約、例:アプリ CPU、DB コネクション、キュー深度)
- ユーザー影響 KPI(最重要な 1–3 のビジネスフロー)
Canary の場合はバージョン/インスタンス群ごとに分割して比較できるようにし、Blue/Green の場合は切替ウィンドウで新旧を比較できるようにします。
一時停止/ロールバックの閾値を明確にする
トラフィックを動かす前にルールを決めておきます。例:
- エラー率がベースライン比で X% 増加が Y 分続いたら停止
- p95 レイテンシが固定値を超える(またはベースライン比で X% 増加)
- ユーザー影響 KPI が許容値を下回る
数値はサービスによって異なりますが、合意が重要です。全員がトリガーとロールバック計画を知っていれば、顧客が影響を受けている間に議論する必要はありません。
ロールアウトウィンドウ向けのアラート
ロールアウト中に特化した(または一時的に厳しくした)アラートを追加します:
- 5xx/タイムアウトの予期せぬ急増
- 重要経路での突然のレイテンシ劣化
- コネクションプールやキューの急増など飽和指標の急上昇
アラートは実行可能であること(何が変わったか・どこか・次に何をするか)を重視します。ノイズが多いアラートは、本当に重要なシグナルを見逃す原因になります。
リリース前チェックで問題を早期発見する
多くのロールアウト失敗は大きなバグではなく、小さな不整合(設定値の欠落、マイグレーションの失敗、期限切れ証明書、統合の違い)によるものです。プレリリースチェックは被害範囲が小さいうちにそれらを発見するチャンスです。
ヘルスチェックとスモークテストから始める
トラフィックを動かす前に(Blue/Green の切替でも Canary の最初の段階でも)新バージョンが基本的に生きているか確認します。
- アプリのヘルスエンドポイントが OK を返す(単にプロセスが動いているだけでないこと)
- 依存関係(DB、キャッシュ、キュー、オブジェクトストレージ、メール/SMS プロバイダ)が使える
- シークレットや環境変数が存在し、正しくスコープされている
デプロイ先で短い E2E テストを走らせる
ユニットテストは有用ですが、デプロイされたシステム自体が動くことを証明しません。数分で終わる短い自動化されたエンドツーエンドテストを新環境で走らせます。
サービス間を横断するフロー(Web → API → DB → サードパーティ)に焦点を当て、重要な統合ごとに少なくとも1回の"実際の"リクエストを含めます。
重要なユーザージャーニーを人の目で検証する
自動テストで見落としがちな点を防ぐために、コアワークフローをターゲットにした手動または半自動の検証も行います:
- ログインとパスワードリセット
- チェックアウトや決済フロー(失敗パスも含めて)
- 日常的な作成/更新/削除操作
複数ロール(管理者 vs カスタマー)があるなら、各ロールの代表的な流れを確認します。
プレリリースの準備チェックリストを持つ
チェックリストは暗黙知を繰り返し可能な手順に変えます。短く実行可能に保ちます:
- DB マイグレーションは適用済みで可逆(または明確に安全)
- 可観測性が整っている:ログ、ダッシュボード、主要指標のアラート
- ロールバック計画がレビュー済み(誰が、どうやって、停止はどう見えるか)
これらが日常化すれば、トラフィックシフトは制御された一手順になります。
Blue/Green ロールアウト:実践プレイブック
学んで報酬を得る
Koder.aiで作ったものや学んだことを共有してクレジットを獲得しましょう。
Blue/Green ロールアウトはチェックリストに従うと簡単に回せます:準備、デプロイ、検証、切替、観察、クリーンアップ。
1) Green にデプロイ(ユーザーに触らせない)
新バージョンを Green 環境にデプロイし、その間 Blue は現行のままトラフィックを捌きます。設定やシークレットは揃えて Green がミラーとなるようにします。
2) トラフィックを切り替える前に Green を検証
高速で信号性の高いチェックを行います:アプリが正常に起動するか、主要ページが表示されるか、決済/ログインが動くか、ログに異常がないか。自動スモークテストがあれば今実行します。Green 用の監視ダッシュボードやアラートが有効かもここで確認します。
3) DB マイグレーションは安全に(拡張→縮約)
データベース変更は注意が必要です。拡張(expand)→縮約(contract) アプローチを使います:
- 拡張:後方互換な形で新カラムやテーブルを追加
- Green をデプロイして旧スキーマでも動く状態にする
- 縮約:Blue を廃止して新コードが安定した後に旧フィールドを削除
これにより「Green は動くが Blue に戻せない」状況を避けます。
4) キャッシュのウォームアップとバックグラウンドジョブの扱い
切替前に重要なキャッシュ(ホームページやよく使われるクエリ)をウォームアップして、ユーザーにコールドスタートの負担をかけないようにします。
バックグラウンドジョブや cron については、切替中に二重実行を避けるため:
- ジョブはどちらか一方の環境だけで実行するように決める
5) トラフィックを切り替えて観察する
ロードバランサ/DNS/Ingress を用いて Blue から Green にルーティングを切替えます。短いウィンドウでエラー率、レイテンシ、ビジネスメトリクスを監視します。
6) 切替後の検証とクリーンアップ
実ユーザー観点でスポットチェックを行い、しばらく Blue をフォールバック用に残します。安定を確認したら Blue のジョブを停止し、ログをアーカイブし、コストと混乱を減らすために Blue を削除します。
Canary ロールアウト:実践プレイブック
Canary の要点は安全に学ぶことです。全員に一斉に出すのではなく、実ユーザーのごく一部に露出して監視し、証拠に基づいて段階的に拡大します。目的は「ゆっくり出す」ことではなく「各段階で安全を証明する」ことです。
シンプルな段階プラン(1–5% → 25% → 50% → 100%)
- カナリアの準備
新バージョンを安定版と並べてデプロイします。各々にトラフィック割合を割り当てられることと、両方が監視で見えること(別ダッシュボードやタグがあると便利)を確認します。
- ステージ1:1–5%
ごく小さく開始します。ここで早く明らかになるのは壊れたエンドポイント、設定漏れ、DB マイグレーションの不整合、予期しない遅延スパイクなどです。
ステージ中に残すメモ:
- このリリースで変わったこと(小さな設定変更も含めて)
- 期待していた動作
- 観察したこと(エラー、レイテンシ、ユーザー影響)
- ステージ2:25%
最初が問題なければ約 25% に増やします。より多様なユーザ行動や長尾のデバイス、競合が見えてきます。
- ステージ3:50%
半分トラフィックでスケーリングや性能の限界が見えやすくなります。ここで警告サインが現れることが多いです。
- ステージ4:100%(プロモーション)
指標が安定しユーザー影響が許容範囲であれば全トラフィックを新バージョンへ移し、プロモート完了とします。
各段階の待ち時間(どれくらい待つか)
待ち時間はリスクとトラフィック量に依存します:
- 高リスクあるいは低トラフィック:各段階で十分な信号を得るために長めに待つ(例:30–60 分、場合によってはそれ以上)。低トラフィックサービスはパターンを確認するのに数時間必要なこともあります。
- 低リスクで高トラフィック:短め(例:5–15 分)でもデータはすぐ集まります。
また、ビジネスの時間帯(ランチタイムや週末、課金タイミング)も考慮して、問題が起きやすい条件をカバーする長さにします。
プロモーションとロールバックを自動化する
手動だとためらいや不整合が出ます。可能なら自動化しましょう:
- 指標がしきい値内で一定時間保たれたら自動でプロモート
- しきい値を超えたら自動でロールバック(例:エラー率やレイテンシの閾値)
自動化は人の判断をなくすものではなく、遅延を取り除くものです。
各段階を実験として扱う
各段階ごとに次を記録します:
- 変更の概要(何が違うのか)
- 成功基準(どの指標が安定しているべきか)
- 観察結果(何を見たか、"特に異常なし" も含めて)
- 判断(プロモート、保留、ロールバック)とその理由
これらの記録はロールアウト履歴を次回のプレイブックに変え、将来のインシデント診断を容易にします。
ロールバック計画と障害対応
ロールバックは『何が"まずい"か』と『誰がボタンを押すか』を事前に決めておくと最も簡単です。ロールバック計画は悲観的ではなく、小さな問題を長期障害にしないための手段です。
明確なロールバックトリガーを定義する
議論を回避するため、短いリストで測定可能なトリガーを決めます。一般的なもの:
- エラー率:5xx スパイク、チェックアウト失敗、ログイン失敗、API タイムアウト
- レイテンシ:p95/p99 が合意した上限を超える(持続時間付き、例:5–10 分)
- ビジネス KPI:コンバージョンや決済成功率、サインアップの急落、キャンセルの増加
トリガーは測定可能に(例:「p95 > 800ms が 10 分間続く」)し、オンコールやリリースマネージャなど実行権限のある担当者に紐づけます。
速く(そして地味に)戻す
スピードが重要です。ロールバックは次のいずれかであるべきです:
- トラフィックを元に戻す(Blue/Green や Canary では典型的)
- 前の安定版を再デプロイする:インフラが変わっている場合は最後の安定ビルドを再デプロイしてヘルスチェックを再実行
最初の手段は「マニュアル修正して続行」ではなく、まず安定化→その後調査にします。
部分的ロールアウトへの備え
Canary では一部のユーザーが新バージョンでデータを作る場合があります。事前に決めておく事項:
- カナリアユーザーを即座に戻すか、それとも評価中はそのままにするか
- データフォーマットが変わっている場合、DB が後方互換かどうか。互換性がなければロールバックは別の対処が必要
事後レビューで次回を良くする
安定したら短い事後報告を残します:何がロールバックを引き起こしたか、欠けていたシグナル、チェックリストに加えること。これは責める場ではなく、リリースプロセスの改善サイクルです。
機能フラグとプログレッシブデリバリー
Koder.aiを紹介
チームや仲間を招待し、彼らがKoder.aiを使い始めるとクレジットがもらえます。
機能フラグは デプロイ(コードを本番に出す) と リリース(ユーザーに公開する) を切り離します。これは大きな利点で、同じデプロイパイプライン(Blue/Green や Canary)を使いながら露出をスイッチで制御できます。
プレッシャーなしにデプロイし、意図を持ってリリースする
フラグを使えば、機能がまだ全員向けでなくてもマージしてデプロイできます。コードは存在するが無効化された状態で、本番に置けます。確信が持てたら段階的にフラグを有効化し、問題があれば素早く無効化できます。
部分的有効化(全か無かではない)
プログレッシブデリバリーはアクセスを段階的に増やすことです。フラグは次の対象に有効化できます:
- 特定のユーザーグループ(社内スタッフ、ベータ利用者、有料層)
- 地域(まず一国や一つのデータセンタ)
- ユーザーの割合(1% → 10% → 50% → 100%)
Canary で新バージョンが健全でも、機能リスクを個別に管理したいときに特に有効です。
“フラグ負債”を防ぐガードレール
機能フラグは強力ですが、管理がないと問題になります。簡潔なガードレール:
- 所有権:各フラグに責任チーム/担当者を設定
- 期限:削除日またはレビュー日を設定し、古いフラグを放置しない
- ドキュメント:フラグの機能、影響範囲、ロールバック方法を記載
実務ルール:誰かが「これをオフにしたら何が起きる?」に答えられないなら、そのフラグは準備不足です。
より深いガイダンスは /blog/feature-flags-release-strategy を参照してください。
戦略の選び方と最初の一歩
Blue/Green と Canary の選択は“どちらが優れているか”ではなく、どのリスクを制御したいか、そして現在のチームとツールで現実的に運用できるかで決まります。
決め手の簡単な指針
クリーンで予測可能な切替と「元に戻す」ボタンが最優先なら、Blue/Green が通常簡単に合います。
影響範囲を小さくし実ユーザーから学びたいなら、Canary が安全です(特に変更頻度が高くテストで全て検証しにくい場合)。
実務的なルール:深夜2時に運用できる方法を選ぶこと。継続的に実行できることが何より重要です。
小さく始める:1つだけパイロットを回す
1つのサービス(またはユーザー向けワークフロー)を選び、数回のリリースでパイロットを行います。重要だがあまりにもクリティカルでない対象が良いです。目的はトラフィックシフト、監視、ロールバックの筋力トレーニングを積むことです。
短いランブックを書き、所有権を割り当てる
1ページ程度で十分です:
- “良好” の定義(主要指標と閾値)
- ロールアウト中の担当者
- 一時停止、ロールバック、コミュニケーションの方法
所有権を明確にしないと、戦略は単なる提案に終わります。
まず既存のツールを使う
新しいプラットフォームを入れる前に、既に使っているツール(ロードバランサ設定、デプロイスクリプト、既存の監視、インシデントプロセス)で何ができるか見てください。パイロットで感じた摩擦を解消する場合にのみ新しいツール導入を検討します。
もしサービスを迅速に作ってデプロイする必要があるなら、アプリ生成とデプロイ制御を組み合わせたプラットフォームが運用負荷を下げることがあります。例えば、Koder.ai はチャットインターフェースからウェブ/バックエンド/モバイルアプリを生成し、リリースの安全機能(スナップショットとロールバック)、カスタムドメイン、ソースコードのエクスポートをサポートしてホストできるプラットフォームです。これらの機能はこの記事の核心—リリースを再現可能に、可観測に、可逆にする—に合致します。
次に取るべきステップ(提案)
実装オプションと対応ワークフローを確認するには /pricing と /docs/deployments を見てください。次に最初のパイロットリリースをスケジュールし、何がうまくいったかを記録してランブックを毎回改善しましょう。