2025年9月21日·1 分
Eric BrewerのCAP思考:なぜ分散システムはトレードオフを迫られるのか
Eric BrewerのCAP定理を実用的なメンタルモデルとして学ぶ:一貫性・可用性・分断耐性が分散システムの判断にどう影響するかを解説します。
Eric BrewerのCAP定理を実用的なメンタルモデルとして学ぶ:一貫性・可用性・分断耐性が分散システムの判断にどう影響するかを解説します。
同じデータを複数のマシンに保管すると、速度と耐障害性を得られます——しかし新たな問題も生じます:不一致です。二つのサーバが異なる更新を受け取り得るし、メッセージは遅延したり届かなかったり、ユーザーはどのレプリカに当たるかで違う答えを読むかもしれません。CAPが広まったのは、エンジニアがそのややこしい現実を曖昧さなく語れる枠組みを与えたからです。
エリック・ブルーワー(Eric Brewer)は2000年に、故障下のレプリケーションされたシステムについての実用的な主張としてこのコアアイデアを提示しました。それは現場でチームが既に経験していたものと一致したため急速に広まりました:分散システムは単に停止するだけでなく、分裂することで故障するのです。
CAPが最も有用なのは問題が発生したとき、特にネットワークが正常に振る舞わないときです。正常な日には、多くのシステムが十分に一貫して見え、十分に利用可能に見えるかもしれません。試練は、マシンが確実に通信できないときで、その間に読み書きをどう扱うかを決めなければなりません。
この視点がCAPを定番にした理由です:CAPはベストプラクティスを論じるのではなく、具体的な問いを突き付けます——分断時に何を犠牲にしますか?
この記事を読み終えるころには、次ができるようになっているはずです:
CAPが残り続けるのは、「分散が難しい」を意思決定に落とし込めるからです。
分散システムとは平たく言えば「多くのコンピュータが一つのように振る舞おうとすること」です。複数のサーバを別々のラックやリージョン、クラウドのゾーンに置くかもしれませんが、ユーザーから見ればそれは「アプリ」や「データベース」です。
実稼働スケールでその共有システムを動かすには、普通はレプリケーションします:同じデータの複数コピーを別のマシンに保持します。
レプリケーションが採用される実用的な理由は三つです:
ここまではレプリケーションは明らかに有利に見えます。しかし落とし穴は、レプリケーションが新しい仕事を生むことです:すべてのコピーを合意状態に保つことです。
すべてのレプリカが常に瞬時に互いに通信できれば、更新を調整して整合を保てます。しかし現実のネットワークは完璧ではありません。メッセージは遅れる、失われる、失敗を回避する経路に迂回されることがあります。
通信が健全なとき、レプリカは通常更新を交換して同じ状態に収束します。しかし通信が切れる(たとえ一時的にでも)と、**二つのもっともらしい「真実」**が生まれることがあります。
例えば、ユーザーが配送先住所を変更したとします。レプリカAは更新を受け取り、レプリカBは受け取らない。今、システムは一見単純な問いに答えなければなりません:現時点の住所はどれか?
これは次の違いです:
CAP思考はまさにここから始まります:レプリケーションが存在すると、通信障害下の不一致は例外ではなく中心的な設計問題になるのです。
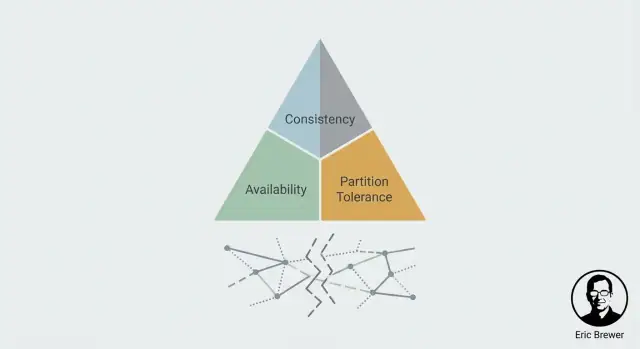
CAPは、システムが複数マシン(多くは複数のロケーション)に分散しているときに「ユーザーが実際に感じること」を扱うメンタルモデルです。良し悪しを判定するものではなく、管理すべき緊張関係を示します。
一貫性は合意についてです。何かを更新したら、その後の読み取り(どこからでも)がその更新を反映するでしょうか?
ユーザー視点では「今変更したことが皆同じ新しい値として見える」か、「しばらくの間は一部の人が古い値を見ることがある」かの違いです。
可用性はリクエスト(読み/書き)に成功結果で応答することを意味します。最速で返すという意味ではなく、「応答を拒絶しない」ことです。
トラブル時(サーバのダウンやネットワークの問題)でも、可用性を優先するシステムはリクエストを受け付け続けますが、データはやや古い可能性があります。
パーティション(分断)はネットワークの分割で、マシンは稼働しているが一部間でメッセージが届かない(あるいは遅すぎて役に立たない)状況です。分散システムではこれを起こり得ないと扱うことはできません—分断が起きたときの振る舞いを定義しておく必要があります。
同じ商品を販売する二つの小売店があり、「在庫カウントは1」で共有していると想像してください。顧客が店舗Aで最後の1つを買い、店舗Aは在庫 = 0と書き込んだ。同時にネットワーク分断で店舗Bにはその情報が届かない。
店舗Bが可用性を維持すれば、在庫のない商品を販売してしまう(分断中に販売を受け入れる)かもしれません。店舗Bが一貫性を強制すれば、最新在庫を確認できるまで販売を拒否する(分断中にサービスを拒否する)かもしれません。
「分断」は単なる「インターネットが落ちた」ではありません。システムの一部同士が信頼して通信できないあらゆる状況です — 各部はまだ正常に動いている場合もあります。
レプリケートされたシステムでは、ノードは常にメッセージを交換しています:書き込み、確認応答、ハートビート、リーダー選出、読み取りリクエスト。そうしたメッセージが届かなくなる(あるいは遅すぎる)と、現実についての不一致が起きます:「その書き込みは実際に起きたのか?」「リーダーは誰か?」「ノードBは生きているか?」といった疑問です。
通信障害はさまざまな不完全な形で現れます:
重要な点は:分断はたいてい劣化として現れ、明確なオン/オフの障害ではないことです。アプリから見ると「十分に遅い」は「落ちている」と区別が付かないことがあります。
マシンやネットワーク、リージョン、依存が増えれば増えるほど、通信が一時的に壊れる機会は増えます。個々のコンポーネントが信頼できても、全体としては依存関係とノード間の協調が多いために障害を経験します。
正確な故障確率は仮定する必要はなく、システムが十分長く稼働し十分なインフラにまたがれば分断は起きると受け入れることが重要です。
分断耐性とは、たとえノードが合意できず相手が見たものを確認できなくても分割中に稼働を続けられるように設計することです。これには選択が伴います:リクエストを受け付けて不一致を許す(可用性)か、いくつかのリクエストを止める/拒否して一貫性を守るか。
レプリケーションがあると分断は単に通信の切断です:システムの二つの部分がしばらくの間信頼して通信できない。レプリカは稼働を続け、ユーザーは操作を行い、サービスはリクエストを受ける——しかしレプリカ同士は最新の真実で合意できない。
これがCAPの緊張の一文でのまとめです:分断が発生したら、一貫性(C)を優先するか可用性(A)を優先するかを選ばなければならない。 同時に両方を得ることはできません。
「応答性より正確さを取る」と宣言しているわけです。リクエストがすべてのレプリカを同期させることを確認できない場合、失敗させるか待つ必要があります。
実際の影響:一部のユーザーはエラーやタイムアウト、あるいは「再試行してください」といったメッセージを見ることが多くなります。二重請求を避ける、席を重複して確保しない、など取り返しのつかない誤りを避けたい場面で使われます。
「ブロックするより応答する方を選ぶ」と宣言しています。分断のそれぞれの側は、調整できなくてもリクエストを受け続けます。
実際の影響:ユーザーは成功応答を得ますが、読み取るデータは古い可能性があり、同時更新は競合するかもしれません。後で和解(マージルール、最終書き込み勝ち、手動レビューなど)に頼ることになります。
これは常にグローバルな設定である必要はありません。多くのプロダクトは戦略を混ぜます:
重要なのは操作ごとに「今ユーザーをブロックすること」と「後で矛盾を直すこと」のどちらがより悪いかを決めることです。
「二つ選べ(pick two)」というスローガンは覚えやすいですが、しばしば誤解を生みます。CAPは、分断が起きたときに何が起こるかを扱います:分断中に分散システムは一貫した答えを返すのか、それともすべてのリクエストに対して可用性を維持するのか、ということです。
現実の分散システムでは分断は無効化できません。マシン、ラック、ゾーン、リージョンにまたがればメッセージは遅延したり、失われたり、順序が入れ替わったりします。これらはソフトウェアから見ると「ノード同士が十分に協調できない」分断です。
物理ネットワークが健全でも、GCポーズ、ノイジーネイバー、DNSの一時不具合などが同じ効果を生みます。
アプリケーションは「分断」をきれいな二値イベントとして経験するわけではありません。むしろレイテンシスパイクやタイムアウトとして経験します。リクエストが200msでタイムアウトするなら、そのパケットが201msで届いたのか全く届かなかったのかに関係なく、アプリは次にどうするかを決めなければなりません。遅い通信は壊れた通信と同じ振る舞いを示します。
多くの実システムは設定や動作条件によって「ほぼ一貫性」または「ほぼ可用性」に見えます。タイムアウト、リトライ方針、クォーラムサイズ、「read-your-writes」オプションが振る舞いを変えます。通常条件下では強い一貫性に見えるデータベースも、ストレスやクロスリージョンの問題下ではリクエストを失敗させ始め(一貫性重視)あるいは古いデータを返し始める(可用性重視)ことがあります。
CAPは製品ラベルを貼るためのものではなく、不一致が発生したときにどんなトレードオフをしているかを理解するためのものです。
CAPの議論は一貫性を二値化しがちですが、現実には複数の保証レベルがあり、不一致やネットワーク断時に異なるユーザー体験をもたらします。
強い一貫性(しばしば「線形化可能」)は、書き込みが確認されたらその後のすべての読み取りがその書き込みを返すことを意味します。
代償:分断時や一部レプリカが到達不能なとき、システムは読み/書きを遅延または拒否して矛盾を避けるかもしれません。ユーザーはタイムアウトや「再試行してください」、一時的な読み取り専用といった挙動を目にします。
最終的一貫性は、更新が止まればすべてのレプリカは収束すると約束します。しかし今この瞬間に二人が見た結果が同じであることは保証しません。
ユーザーが気づくこと:最近更新したプロフィール写真が「戻る」、カウンタが遅れる、別デバイスにメッセージがすぐ見えないなど。
フルの強い一貫性を要求せずに良い体験を得られる保証もあります:
これらは「自分の変更が消えたように見えるな」という体験を避けるのに向いており、分断時にも比較的維持しやすいことが多いです。
まずユーザーへの約束から始めてください:
一貫性はプロダクトの選択です:「間違っている」の定義を書き出し、その誤りを防ぐために必要な最も弱い保証を選びます。
CAPでの可用性は単なる「稼働率自慢(ファイブナインズ)」ではなく、通信不確実性のときにユーザーに何を約束するかです。
レプリカが合意できないとき、多くの場合次の選択になります:
ユーザーは「アプリが動く」と「アプリが正しい」のどちらを感じるかで違います。フィードの少し古い表示は煩わしいが許容できる。口座残高が古いのは致命的です。
不確実性の際に見られる二つの振る舞い:
これは純粋に技術的な判断ではなくポリシーです。どこまでを推測してよいか、何を絶対に推測してはならないかをプロダクトが定義する必要があります。
可用性はめったに白黒ではありません。分断中、あるリージョンやユーザー群は成功し、他は失敗するという部分的可用性が起きます。これは局所的にレプリカが健康なら意図した設計にもできるし、ルーティング不均衡やクォーラム到達性のばらつきで偶発的にも起きます。
実用的な中間解は劣化モードです:安全な操作は継続し、リスクの高い操作は制限します。例:閲覧や検索は許可するが、「資金移動」「パスワード変更」は一時停止する、など。
CAPは抽象に見えますが、ネットワーク分断時にユーザーが何を体験するかに対応付けると現実的になります:システムは応答を続けるべきか、矛盾を避けるために停止すべきか。
二つのデータセンターが注文を受け付けられないほど通信できないとします。
お金は典型的に誤りが高コストなドメインです。分断中に二つのレプリカが独立して引き出しを受け入れると、口座が過剰引き落としされる可能性があります。
システムはクリティカルな書き込みに対して一貫性を優先する傾向があります:最新残高の確認ができない場合は処理を遅らせるか拒否する。可用性を一部犠牲にしても正確さ、監査性、信頼性を守ります。
チャットやソーシャルフィードでは、数秒の遅延やいいね数のずれは通常許容されます。ここでは可用性を設計上優先するのが適切で、どの要素が「最終的に正しくなる」かを明確にしておけばよいでしょう。
CAPの「正解」は、間違うコスト(返金、法的リスク、ユーザー信頼の毀損、運用の混乱)によって決まります。どこで一時的な陳腐さを許容できるか、どこで閉じて保護するかを決めてください。
分断時に何をするかを決めたら、その決定を現実にする仕組みが必要です。これらのパターンはデータベース、メッセージシステム、APIに広く現れます。
クォーラムは単に「レプリカの過半数が合意する」ことです。たとえば5つのコピーがあれば過半数は3です。
読み/書きに過半数を要求すると、古いデータを返す可能性や競合が減ります。例えば書き込みが3つのレプリカの確認を必要とすると、孤立した二つのグループが異なる「真実」を受け入れる可能性が下がります。
トレードオフは遅延と到達性です:過半数に到達できなければ操作を拒否し、可用性より一貫性を選ぶことになります。
多くの「可用性」問題はハードな故障ではなく遅いレスポンスです。短いタイムアウトは応答性を良く感じさせますが、遅い成功を失敗として扱う確率も上げます。
リトライは一時的な障害から回復できますが、過度のリトライは既に苦しむサービスにさらに負荷をかけます。バックオフ(再試行間隔を徐々に延ばす)とジッター(ランダム性)はリトライのスパイク化を防ぎます。
「常に応答する」という約束は多くのリトライとフォールバックを意味し、「決して嘘をつかない」は厳格な制限と明確なエラーを意味します。
分断中に可用性を維持するなら、レプリカが異なる更新を受け入れ後で和解する必要があります。一般的なアプローチ:
リトライは重複を生む可能性があります:二重課金や同一注文の二重送信など。冪等性はそれを防ぎます。
一般的なパターンは**冪等キー(リクエストID)**を用いることです。サーバは最初の結果を保持し、同じキーのリクエストには同じ結果を返す——リトライで可用性を改善しつつデータ破壊を防げます。
システム決定を行うとき、CAPは「分断が起きたら何が壊れるか?」を素早く監査するのに最も有用です。データベース機能、キャッシュ戦略、レプリケーションモードを選ぶ前にこのチェックリストを使ってください。
順に問う:
分断が来たら、これらのうちどれを優先して守るかを決めることになります。
「うちはAPだ」という単一の全体設定は避けてください。代わりに以下で決める:
place order vs view order vs track shipment例:分断中、paymentsへの書き込みはブロック(一貫性優先)し、product_catalogの読み取りはキャッシュで可用性を保つ、といった具合です。
不整合を平叙で書き出してください:
不整合を例で説明できなければ、テストやインシデント時の説明が難しくなります。
次に読むと良いトピック:合意(/blog/consensus-vs-cap)、整合性モデルの解説(/blog/consistency-models-explained)、およびSLOとエラーバジェット(/blog/sre-slos-error-budgets)。
CAPは通信障害下のレプリケートされたシステムを考えるためのメンタルモデルです。ネットワークが遅い・パケットを落とす・分断されるときが最も有用で、レプリカ同士が確実に合意できない状況では次の二択を突き付けられます:
「分散は難しい」を製品と工学上の具体的な意思決定に変えるのがCAPの役割です。
本当のCAP状況には両方が必要です:
単一ノードや状態をレプリケートしていないシステムでは、CAPのトレードオフは核心的な問題にはなりません。
分断とは、マシンが動いていてもシステムの一部同士が要求される時間内に信頼してやり取りできないあらゆる状況です。
実際には分断は次のような形で現れます:
アプリケーション観点では「遅い」は「ダウン」と同様に扱わなければならないことが多いです。
**一貫性(C)**はどこから読んでも最新の書き込みが反映されることを意味します。ユーザーは「自分が変更したら、みんな同じ最新値を見る」と感じます。
**可用性(A)**は、すべてのリクエストが成功応答(必ずしも最新ではない)を受け取ることを意味します。ユーザーは「アプリは動き続けるが、結果は古いかもしれない」と感じます。
分断が起きたとき、すべての操作に対して両方を同時に保証することは通常できません。
分散システムでレプリケートしている限り、分断は無視できるものではありません。ネットワークを無効化することはできないので、分断が発生したときにシステムがどう振る舞うかを定義しておく必要があります。
「分断を許容する」とは、通信が壊れたときに、操作を拒否・一時停止して一貫性を守るか、最善応答を返して可用性を保つかを事前に決めておくことです。
一貫性を優先する場合、通常は:
これは、金銭移動、在庫確保、権限変更のように「間違うと取り返しがつかない」領域で一般的です。
可用性を優先する場合、通常は:
ユーザーはハードエラーが少ない代わりに、古いデータや重複した効果、後処理が必要な矛盾を目にすることがあります。
はい。多くの実システムは操作やデータ型ごとに異なる戦略を採ります。よくある混合戦略:
単一の「うちはAP/CP」ラベルに頼るのではなく、エンドポイントやデータ種別ごとに決めるのが実用的です。
「完全に強い」や「完全に最終的」といった二極だけでなく、現実にはいくつかの有用な保証があります:
不整合が見える状況を意図的に作って、システムが設計通り動くか検証することが重要です。
また、運用手順(runbooks)とユーザー向けメッセージを事前に用意しておくと、分断時の対応がスムーズになります。
ユーザーにとって許容できない「誤り」を防げる最も弱い保証を選ぶのが実務的です。