2025年3月20日·1 分
チケットとSLAを備えたカスタマーサポート用Webアプリの作り方
チケットワークフロー、SLA追跡、検索可能なナレッジベースを備えたカスタマーサポートWebアプリを計画・設計・構築する方法。役割、分析、統合も含む。
目的、ユーザー、範囲を定義する
機能中心で作るとチケッティング製品はすぐにややこしくなります。フィールド、キュー、オートメーションを設計する前に、誰のためのアプリか、どんな痛みを取り除くか、「良い」とは何かを合わせておきましょう。
ユーザー(と彼らの日常業務)を特定する
まずは役割と、通常の週にそれぞれが成し遂げるべきことを列挙します:
- エージェント: チェック、返信、迅速に解決・記録する。\n- チームリード: ワークロードの再配分、滞留チケットの発見、SLAの管理、コーチング。\n- 管理者(Admin): チャネル、カテゴリ、オートメーション、権限、テンプレートの設定。\n- 顧客(任意): リクエストの送信、ステータスの追跡、詳細の追加、ポータルでの回答検索。
このステップを飛ばすと、意図せず管理者向けに最適化され、エージェントがキューで困ることになります。
解決する問題を書き出す
具体的に、観察可能な行動に結びつけて書いてください:
- SLAの見逃し: チケットが静かに古くなり、エスカレーションが遅れる。\n- 混乱したキュー: 所有者が不明、重複作業、どこに振るべきかの混乱。\n- 繰り返しの質問: 同じ回答を何度も入力して解決が遅くなる。
アプリの利用場所を決める
明確に:これは内部ツールのみか、顧客向けポータルも提供するか?ポータルが入ると認証、権限、コンテンツ、ブランディング、通知の要件が変わります。
成功指標を早めに決める
初日から追跡する小さな指標を選びます:
- 初回返信時間\n- 解決時間\n- 回避率(ナレッジベースで解決され、チケットにならなかった比率)
シンプルなv1スコープ文を作る
v1に含める(必須ワークフロー)と後回しにするもの(高度なルーティング、AI提案、詳細レポートなど)を5~10文で記述します。これがリクエストが増えたときのガードレールになります。
チケットモデルとライフサイクルを設計する
チケットモデルはキュー、SLA、レポート、エージェント画面などすべての“真実の源”です。早めに正しく設計すれば後の移行が楽になります。
一文で説明できるライフサイクルをマッピングする
まずは明確な状態セットを用意し、それぞれの意味を運用面で定義します:
- New(新規): 作成され、未トリアージ\n- Assigned(担当割当): エージェントまたはチームが所有\n- In progress(対応中): 積極的に作業中\n- Waiting(保留): ブロック(顧客の返信、第三者、エンジニアリングなど)\n- Solved(解決済): エージェントが解決と判断(通知をトリガーすることが多い)\n- Closed(クローズ): 最終状態(編集がロックまたは制限される)
状態遷移ルールを追加します。例:Assigned/In progress のチケットのみ Solved にでき、Closed チケットはフォローアップを新規で作らない限り再開できない、等。
チケットの流入方法を決める
今サポートするすべての取り込み経路(後で追加する予定も含む)を列挙:Webフォーム、受信メール、チャット、API。各チャネルはほぼ同じチケットオブジェクトを作り、メールヘッダやチャットのトランスクリプトIDなどチャネル固有のフィールドを少し持たせます。整合性が自動化とレポートを簡潔にします。
必須フィールドを選び(最小限に保つ)
最低限要求するのは:
- 件名(Subject) と 説明(description)\n- 依頼者(Requester)(顧客の識別)\n- 優先度(Priority)(どれだけ緊急か)\n- カテゴリ(Category)(どんな問題か)
それ以外は任意か派生可能にします。入力項目が多すぎると入力品質が落ち、エージェントの手間が増えます。
実チーム向けにタグとカスタムフィールドを計画する
軽量フィルタ用にタグ(例:「billing」「bug」「vip」)を使い、構造化されたレポートやルーティングが必要な場合はカスタムフィールド(例:「製品領域」「注文ID」「地域」)を作ります。フィールドはチーム単位でスコープできるようにして、ある部署が他部署を煩わせないようにします。
チケット内でのコラボレーションを定義する
エージェントは調整できる安全な場所が必要です:
- 内部メモ(顧客には見えない)\n- @メンション とフォロワー/CCリスト\n- リンクされたチケット(重複、親/子インシデント)
エージェントUIはこれらをメインのタイムラインからワンクリックで使えるようにしてください。
チケットキューと割当ワークフローを構築する
キューと割当は、チケッティングシステムが単なる共有受信箱から運用ツールになるポイントです。ゴールは単純:全てのチケットに「次に行うべきこと」が明確にあり、各エージェントが今取り組むべきものを知っていること。
「次は何?」に答えるエージェントキューを設計する
最も時間に敏感な作業がデフォルトで表示されるキュービューを作ります。エージェントが実際に使う一般的なソートオプション:
- 優先度(例:P1–P4)\n- SLAの期限(差し迫っている順)\n- 最終更新(停滞した会話を拾うため)
チーム、チャネル、製品、顧客階層などのクイックフィルタと高速検索を追加します。リストは密に:件名、依頼者、優先度、ステータス、SLAカウントダウン、担当者があれば十分です。
割当ルール:可能な限り自動化、必要なときは手動
チームがツールを変えずに進化できるよう、いくつかの割当パスをサポートします:
- 手動割当(エッジケースやトレーニング時)\n- ラウンドロビン(負荷を均等配分)\n- スキルベースルーティング(言語、製品領域、請求対技術など)\n- チームベースルーティング(例:「決済」「エンタープライズ」「返品」)
「Assigned by: Skills → French + Billing」のように、ルール決定を可視化してエージェントがシステムを信頼できるようにします。
作業を止めないステータスとテンプレート
Waiting on customer や Waiting on third party のようなステータスは、対応がブロックされているときにチケットが「アイドルに見える」ことを防ぎ、レポートを正直にします。
返信を速めるために、定型返信(canned replies) や 返信テンプレート を用意し、安全な変数(名前、注文番号、SLA日付)を使います。テンプレートは検索可能で、権限のあるリードが編集できるようにします。
衝突(複数エージェントによる同一チケット同時操作)を防ぐ
エージェントがチケットを開いたときに短時間の「閲覧/編集ロック」や「現在対応中」バナーを出します。誰かが他の人の対応中に返信しようとしたら警告し、送信に確認を要求する(または送信をブロックする)ことで重複や矛盾する応答を防ぎます。
SLAルール、タイマー、エスカレーションを実装する
SLAは何を測るかで全員が合意しており、アプリが一貫して実行する場合にのみ効果を発揮します。「迅速に返信する」をシステムが計算できるポリシーに落とし込みましょう。
SLAポリシーを定義する(何を測るか)
多くのチームはチケットごとに2つのタイマーから始めます:
- 初回返信時間:チケット作成から最初のエージェント返信(または自動でない最初の公開応答)まで\n- 解決時間:チケット作成から「Solved/Closed」まで
ポリシーは優先度、チャネル、顧客階層ごとに設定可能にします(例:VIPは初回1時間、標準は営業時間で8時間など)。
SLAの時計をいつ開始/停止するか決める
コードを書く前にルールを書いておきましょう。例外がすぐに増えます:
- 営業時間 vs 24/7:タイムゾーン、平日、休日を定義するカレンダー\n- 一時停止状態:チケットが「Waiting on customer」や「Pending external vendor」の場合は時計を止める\n- 再開条件:顧客が返信したときや状態が「Open/In progress」に戻ったときに再開する
SLAイベント(開始、停止、一時停止、再開、違反)を保存しておけば、後で「なぜ違反したのか」を説明できます。
UIでSLAステータスを明確にする
エージェントがチケットを開いて初めてSLAが差し迫っていると知ることがないように:
- カウントダウンタイマー(残り時間)\n- 警告レベルのある 期限切れフラグ(警告 vs 違反)\n- 閾値が近づいたときの任意の アラート(アプリ内、メール、チャット)
エスカレーション経路を作る
エスカレーションは自動で予測可能に:
- 許容時間の80%でチームリードに通知\n- 違反したらオンデューティーキューに再割当\n- 優先度を上げる、または「Escalated」タグを付与
SLAレポートを計画する
最低でも違反数、違反率、時間による推移を追跡します。また違反理由(長すぎる一時停止、誤った優先度、スタッフ不足など)を記録して、レポートが非難ではなく改善につながるようにします。
繰り返しチケットを減らすナレッジベースを作る
良いナレッジベース(KB)は単なるFAQのフォルダではなく、繰り返しの質問を実際に減らし、解決を速める製品機能です。チケットワークフローの一部として設計し、別物にしないでください。
構成:メンテナンスしやすくする
拡張しやすいシンプルな情報モデルで始めます:
- カテゴリ → セクション → 記事(顧客とエージェント両方のナビゲーションに優しい)\n- 複製を避けるための タグ(billing、login、integrations等)\n- コンテンツの鮮度を保つための明確な所有者(誰がレビューするか)
記事テンプレートは一貫させます:問題の要約、ステップバイステップの解決、スクリーンショットは任意、そして「これで解決しない場合…」という案内で適切なチケットフォームやチャネルへ誘導します。
実際に見つかる検索を作る
多くのKB失敗は検索の失敗です。検索には以下を実装します:
- 関連度チューニング(タイトル/見出しのブースト、鮮度ブースト)\n- 同義語(例:「invoice」↔「bill」、「2FA」↔「authentication code」)\n- 誤字訂正とステミング(複数形/単数形の扱い)
また匿名化したチケット件名もインデックスして実際の顧客の言葉を学び、同義語リストに反映します。
下書き、レビュー、公開承認
軽量なワークフローを追加します:下書き → レビュー → 公開、任意でスケジュール公開。バージョン履歴を保存し「最終更新」メタデータを含めます。役割(著者、レビュワー、公開者)を用意して、すべてのエージェントが公開ドキュメントを編集できないようにします。
チケットを減らすものを測る
ページビューだけでなく次を測ります:
- 役立ち票(はい/いいえ)と「何が足りなかったか?」のフィードバック\n- 回避シグナル:検索→記事閲覧→X時間内にチケットが作られなかった場合\n- 良い結果が得られなかったトップ検索(コンテンツギャップ)
作業が行われる場所に記事をリンクする
エージェントの返信作成画面内で、チケットの件名、タグ、検出された意図に基づいて推奨記事を表示します。ワンクリックで公開リンク(例:/help/account/reset-password)か内部スニペットを挿入できるようにします。
上手くやればKBは第一のサポートラインになり、顧客が自分で解決し、エージェントは繰り返しチケットを減らして一貫性高く対応できます。
ロール、権限、監査可能性を設定する
問い合わせを減らすナレッジベースを構築
ナレッジベースの構造と検索フローを構築し、実際の検索に基づいて改善。
権限はチケッティングツールが安全で予測可能に動くか、早々に混乱するかの分かれ道です。ローンチ後に「ロックダウン」するのを待たずに、早めにアクセスモデルを作り、チームが迅速に動けて機密チケットやシステムルール変更の誤用を防ぎましょう。
役割を分け(シンプルに保つ)
最初は明確な役割を少数用意し、本当に必要になったら詳しくします:
- エージェント: チケット処理、メモ追加、返信、フィールド更新\n- リード: エージェントの権限に加え再割当、キュー管理、コーチングワークフロー\n- 管理者(Admin): チャネル、ユーザー管理、設定などシステム全体\n- コンテンツエディタ: ナレッジベース記事の作成と公開\n- 閲覧のみ: 監査、財務、法務、ステークホルダーなどの変更なしでの可視化
権限を機能別に定義する
「全部か無か」のアクセスを避け、主要なアクションを明示的な権限にします:
- チケットの閲覧 vs 編集(内部メモ含む)\n- マクロ/定型返信の管理\n- SLAルール、タイマー、エスカレーションポリシーの編集\n- ナレッジベースの公開/非公開
これにより最小権限の付与が容易になり、成長(新チーム、新地域、外部委託)を支えます。
機密キューのチームベースアクセス
一部のキューはデフォルトで制限されるべきです—請求、セキュリティ、VIP、人事関連など。チームメンバーシップで以下を制御します:
- どのキューが見えるか\n- 誰が再割当やマージをできるか\n- 顧客データフィールドをマスクするかどうか
実用的な監査ログ
誰が、何を、いつ、ビフォー/アフター値とともに主要アクションをログに残します:割当変更、削除、SLA/ポリシー編集、役割変更、KB公開など。ログは検索・エクスポート可能にして、調査でDBアクセスが不要になるようにします。
マルチブランド/マルチ受信箱を早めに計画する
複数ブランドや受信箱をサポートする場合、ユーザーがコンテキストを切り替えるのか、アクセスを分離するのかを決めます。これは権限チェックやレポートに影響するため、初日から一貫させてください。
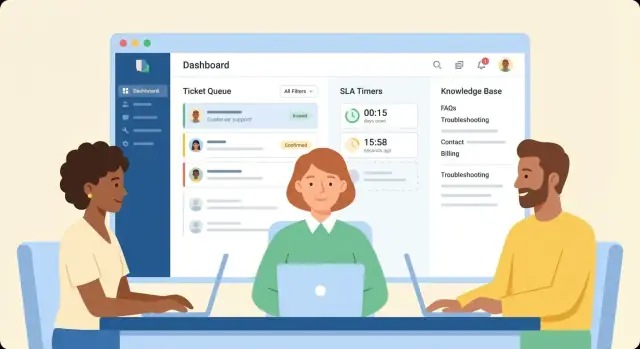
エージェントと管理者のユーザー体験を設計する
チケッティングシステムの成否は、エージェントが状況をどれだけ早く理解して次の行動に移せるかにかかっています。エージェントのワークスペースを「ホーム画面」として扱い、以下の三つの質問に即答できるようにします:何が起きたか、この顧客は誰か、次に何をすべきか。
エージェントワークスペースのレイアウト
コンテキストを見失わずに作業できる分割ビューから始めます:
- 会話スレッド(メール/チャット/メッセージ)、はっきりしたタイムスタンプ、添付、引用表示\n- 顧客パネル(識別、プラン/アカウント階層、組織、過去チケット、主要メモ)\n- チケットフィールド(ステータス、優先度、キュー、担当者、タグ、SLAタイマー)を論理的にグループ化
スレッドは読みやすく:顧客、エージェント、システムイベントを区別し、内部メモは視覚的に明確にして誤送信を防ぎます。
摩擦を取り除くワンクリック操作
一般的なアクションをカーソルの近くに配置します—最後のメッセージ付近やチケット上部:
- 割当/再割当\n- ステータス変更(「waiting on customer」を含む)\n- 内部メモ追加\n- マクロ適用(事前入力返信+フィールド更新)
「ワンクリック+任意コメント」フローを目指してください。モーダルが必要なら短く、キーボードで操作しやすくします。
多量処理チーム向けの速度機能
高スループットなサポートは予測可能なショートカットを必要とします:
- 返信、メモ、割当、自分に割当、クローズ、次のチケットなどのキーボードショートカット\n- リストビューでの一括アクション(タグ付け、割当、クローズ、マージ)\n- パワーユーザー向けの高速コマンドパレット
アクセシビリティとUIの安全性
アクセシビリティを初日から組み込みます:十分なコントラスト、フォーカス表示、タブでの完全な操作、コントロールとタイマーのスクリーンリーダーラベル。同時に誤操作を防ぐ小さなセーフガードも導入:破壊的操作の確認、"公開返信" と "内部メモ" の明確なラベル、送信前に何が送られるかを表示。
管理者と顧客ポータルのUX
管理者にはキュー、フィールド、オートメーション、テンプレートのためのシンプルでガイドされた画面を提供します—重要事項を深い設定階層に隠さないでください。
顧客が問題を提出・追跡できる場合は軽量なポータルを設計します:チケット作成、ステータス確認、更新追加、提出前の推奨記事表示。 /help からリンクし、ブランドと一貫性のあるデザインにします。
統合、API、オムニチャネル入力を計画する
エージェントUIをすばやくモック
エージェントの作業画面、キュー表示、ワンクリック操作を数分で作成。
チケッティングアプリは顧客が既に使っている場所と、解決に使うツールに接続することで有用になります。
最初に接続すべきシステムをリストする
“初日”の統合と各統合から必要なデータを書き出します:
- メール(共有受信箱、転送ルール、送信用SMTP)\n- チャット(サイトウィジェット、WhatsApp、Intercom系)\n- CRM(アカウントコンテキスト、オーナー、プラン階層)\n- 請求システム(サブスクリプション状態、請求書、返金)\n- IDプロバイダ(Google/Microsoft経由のSSO、SCIMユーザープロビジョニング)
データの流れ(読み取り専用か書き戻し可か)と各統合の担当を明確にします。
APIとWebhookを早めに設計する
統合を後回しにする場合でも、安定したプリミティブを定義しておきます:
- チケットの create, update, search、コメント/メッセージ、ステータス変更のためのAPIエンドポイント\n- 主要イベント(ticket.created, ticket.updated, message.received, sla.breached)用のWebhook
認証は予測可能に(サーバーはAPIキー、ユーザーインストールアプリはOAuth)、APIのバージョニングで破壊的変更を避けます。
メールスレッディングで重複チケットを防ぐ
メールは端がややこしくなる場所です。計画すべき点:
- Message-ID / In-Reply-To / References ヘッダを使ったスレッド化\n- 転送メールや一般的な署名の安全な解析\n- 繰り返し届く同一ペイロードの検出による重複除去
ここに少し投資するだけで「返信のたびに新しいチケットが作られる」問題を避けられます。
添付ファイルの安全な扱い
添付をサポートするが、制限とガードレールを付けます:ファイルの種類/サイズ制限、安全な保存、ウイルススキャンフック(またはスキャンサービス)。危険な形式は取り除き、信頼できないHTMLをインライン表示しないようにします。
セットアップを製品機能のように文書化する
統合ガイドを短く作ります:必要な認証情報、ステップバイステップの設定、トラブルシューティング、テスト手順。ドキュメントを維持するなら /docs にある統合ハブへのリンクを設け、管理者がエンジニアを必要とせず接続できるようにします。
サポートパフォーマンスのための分析とレポーティングを追加する
分析により、チケッティングシステムは「働く場所」から「改善の手段」になります。重要なのは正しいイベントをキャプチャし、いくつかの一貫した指標を計算して、異なる対象者に提示することです(機密データを露出しないこと)。
現在のチケット状態だけでなくイベントトレイルを始めに作る
チケットがそう見える理由を説明する瞬間を保存します。最低限以下を追跡:ステータス変更、顧客/エージェントの返信、割当/再割当、優先度/カテゴリ更新、SLAタイマーイベント(開始/停止、一時停止、違反)。これにより「違反は人手不足のためか、顧客待ちのためか?」といった問いに答えられます。
可能な限りイベントは追記専用にしておくと監査とレポートが信頼できます。
チームリード向けダッシュボード
リードが今日アクションできる運用ビューを用意します:
- キュー/優先度/カテゴリ別のバックログ\n- エイジング(例:最も古いオープン、最も古い顧客待ち)\n- SLAリスク(X時間以内に違反する可能性のあるチケット)\n- エージェントの負荷(割当数、アクティブ作業、最終更新からの時間)
これらは時間範囲、チャネル、チームでフィルタできるようにし、マネージャーをスプレッドシートに頼らせないでください。
経営層向けレポート
経営は個別チケットよりトレンドを重視します:
- カテゴリ/チャネル別のボリューム、ピーク日・時間\n- 初回返信と解決のトレンド(中央値と90パーセンタイル)\n- CSATの推移(および回答率)
カテゴリと成果を結び付けられれば、要員、トレーニング、製品改善の正当性を示せます。
フィルタ、エクスポート、アクセス制御
一般的なビューのCSVエクスポートを追加しますが、権限で制御してメールやメッセージ本文、顧客識別子の漏洩を防ぎます。誰がいつ何をエクスポートしたかをログに残します。
リスクのないデータ保持
チケットイベント、メッセージ内容、添付、分析集計をどれくらい保持するかを定義します。設定可能な保持期間を好み、削除と匿名化の違いをドキュメント化して、検証できない保証をしないようにします。
実用的なアーキテクチャと技術スタックを選ぶ
チケッティング製品に複雑なアーキテクチャは必須ではありません。多くのチームにとって、シンプルな構成は早く出荷でき、保守が容易で、十分にスケールします。
単純なシステム図から始める
実用的なベースラインの例:
- Webフロントエンド:エージェント/管理者UIと顧客向けフォーム/ポータル\n- APIバックエンド:チケット、SLA、ユーザー、KBのビジネスルール\n- データベース:チケット、ユーザー、イベント、設定の真実の源\n- バックグラウンドジョブ:時間ベースや長時間処理
この「モジュラーモノリス」アプローチ(1つのバックエンド、明確なモジュール)はv1を管理しやすくし、必要なら後でサービスを分離できます。
v1を加速したい場合、Koder.ai のようなvibe-codingプラットフォームでエージェントダッシュボード、チケットライフサイクル、管理画面をチャットでプロトタイプし、準備ができたらソースコードをエクスポートする方法もあります。
バックグラウンドで何が動くべきかを知る
チケッティングはリアルタイムに感じられますが、多くは非同期です。以下は早めに計画すべきです:
- SLAタイマーとエスカレーション(例:「30分で初回返信」)\n- 通知(メール、アプリ内、Webhook)\n- 検索インデックス作成(チケットとKB記事)\n- 受信メール処理(解析、添付、スレッディング)
バックグラウンド処理を後回しにするとSLAが信頼できなくなり、エージェントの信頼を失います。
正確性のためにデータを保存し、速度のために検索する
コアレコード(チケット、コメント、ステータス、割当、SLAポリシー、監査/イベントテーブル)にはリレーショナルDB(PostgreSQL/MySQL)を使います。
高速検索と関連性のために別の検索インデックス(Elasticsearch/OpenSearchやマネージドサービス)を用意します。製品が検索依存ならRDBで全文検索を無理にやらせないでください。
自前構築 vs 購入の判断
以下の3領域は購入で何ヶ月も節約できることが多いです:
- 認証:SSO、MFA、パスワードポリシーなどの実績あるプロバイダ\n- メール配信:配信性とバウンス処理のためのトランザクションメールサービス\n- 検索:社内の専門知識がなければマネージド検索
差別化するのはワークフロールール、SLAの挙動、ルーティングロジック、エージェント体験です。
マイルストーンでv1を計画する
機能ではなくマイルストーンで工数を見積もります。堅実なv1マイルストーン例:チケットCRUD+コメント、基本割当、SLAタイマー(コア)、メール通知、最小限のレポート。高度な自動化、複雑な役割、深い分析はv1の外に明示的に置きます。
セキュリティ、プライバシー、信頼性の基本をカバーする
仕様から動くアプリへ
チケットモデルとライフサイクルをReact画面とGoのAPIに変換。
セキュリティと信頼性は早めに組み込むほど簡単で安価です。サポートアプリは機密会話、添付、アカウント詳細を扱うため、サイドツールではなくコアシステムとして扱ってください。
顧客データをデフォルトで保護する
内部サービス間通信も含めてトランスポートは常に暗号化(HTTPS/TLS)から始めます。データ保管もDBやオブジェクトストレージを暗号化し、シークレットは管理されたボルトに保管します。
最小権限アクセスを実装し、エージェントは許可されたチケットのみ見られるようにし、管理者の権限は必要時のみ付与します。アクセスログを残して「誰がいつ何を閲覧/エクスポートしたか」を追跡できるようにします。
対象ユーザーに合った認証を選ぶ
小規模チームにはメール+パスワードで十分なこともあります。大企業向けならSSO(SAML/OIDC)が要件になる場合があります。軽量な顧客ポータルにはマジックリンクが摩擦を減らします。
どれを選ぶにせよ、セッションは安全に(短命トークン、リフレッシュ戦略、セキュアクッキー)し、管理者アカウントにはMFAを追加します。
一般的な攻撃を事前に防ぐ
ログイン、チケット作成、検索エンドポイントにレート制限をかけてブルートフォースやスパムを遅らせます。入力は検証・サニタイズして注入や危険なHTMLを防ぎます。
クッキーを使う場合はCSRF対策を。APIには厳格なCORSルールを適用。ファイルアップロードはマルウェアスキャンとファイルタイプ/サイズ制限。
バックアップ、復旧、測定可能な目標
RPO/RTO目標(許容できるデータ損失量と復旧時間)を定義します。DBとファイルストレージのバックアップを自動化し、定期的に復元テストを行います。復元できないバックアップは意味がありません。
ユーザーが求めるプライバシーの基本
サポートアプリはプライバシー要求の対象になることが多いです。顧客データのエクスポートと削除手段を提供し、何が削除され何が法務/監査のため保持されるかを文書化します。監査トレイルとアクセスログを管理者が利用できるようにして、インシデント調査を迅速に行えるようにします(参照:/security)。
実際のサポートチームでテスト、ローンチ、改善する
カスタマーサポートWebアプリの出荷は終点ではなく学習の始まりです。テストとロールアウトの目的は日常業務を守りつつ、チケッティングとSLA管理が正しく動くことを検証することです。
実業務に即したエンドツーエンドのテストシナリオを書く
ユニットテストに加え、リスクが高いフローを反映するエンドツーエンドシナリオを文書化(可能なら自動化)します:
- チケット作成: メール/Webフォーム/APIの取り込みが正しいフィールド、顧客識別、初期ステータスでチケットを作る。\n- 返信とスレッディング: 顧客返信が正チケットに紐づき、エージェント返信が顧客に通知され、内部メモは公開されない。\n- SLA違反: タイマーが正しく始まり/止まり(例:"Waiting on customer"で一時停止)、違反が適切にエスカレーションされ、監査トレイルが記録される。\n- ナレッジベース検索: エージェントがチケットビューから素早く関連記事を見つけ、顧客は提出前に有益な提案を見る。
ステージング環境があるなら、現実的なデータ(顧客、タグ、キュー、営業時間)でシードしておくと理論上の成功だけで終わりません。
パイロットを実施し週次でフィードバックを集める
小さなサポートグループ(または単一キュー)で2~4週間開始し、週に30分のフィードバックルーチンを設けます:遅くした原因、顧客を混乱させた点、驚きのあったルールをレビューします。
フィードバックは構造化して集めます:「課題は何か?」「期待したことは?」「実際に何が起きた?」「どのくらいの頻度で起きる?」。これによりスループットやSLA準拠に影響する修正を優先できます。
管理者とエージェント向けのオンボーディングチェックリストを作る
ローンチが特定の人物に依存しないようオンボーディングを反復可能にします。
必須項目:ログイン、キュー表示、公開返信と内部メモの違い、割当/メンション、ステータス変更、マクロ使用、SLA指標の読み方、KB記事の検索/作成。管理者向けには役割管理、営業時間、タグ、オートメーション、レポートの基本を含めます。
段階的ロールアウト(ロールバックオプション付き)を計画する
チーム、チャネル、チケットタイプごとに段階的に展開します。事前にロールバックの手順を定義:取り込みを一時的に戻す方法、再同期が必要なデータ、決定者。
Koder.ai を使うチームはスナップショットとロールバックを活用して、初期パイロット中にワークフロー(キュー、SLA、ポータルフォーム)を安全に反復します。
イテレーションロードマップを設定する
パイロットが安定したら波状的に改善を計画します:
- マクロ、トリガー、自動タグ付けなどのより良い自動化\n- より高度なルーティング(スキルベース、負荷分散)\n- KBワークフローの強化(記事レビュー、フィードバックループ、回避指標)
各波を小さなリリースとして扱い:テスト、パイロット、測定、拡張の順で進めます。