2025年8月18日·1 分
クリス・ラトナーのLLVM:現代ツールチェーンを支える静かな原動力
Chris Lattner の LLVM がどのように言語やツールの背後にあるモジュール式コンパイラ基盤となり、最適化、診断の向上、迅速なビルドを実現しているかを解説します。
LLVM を平たく言うと
LLVM は、多くのコンパイラや開発ツールが共有する「エンジンルーム」と考えるのがわかりやすい。
C、Swift、Rust のような言語でコードを書くと、そのコードを CPU が実行できる命令に翻訳する必要がある。従来のコンパイラはパイプラインの各部分を自前で構築することが多かった。LLVM は別のアプローチを取る:最適化、解析、さまざまなプロセッサ向けの機械語生成といった難しくコストのかかる部分を扱う、高品質で再利用可能なコアを提供するのだ。
多くの言語が共有する基盤
LLVM は多くの場合「直接使う単一のコンパイラ」ではない。これはコンパイラのインフラであり、言語チームが組み合わせてツールチェーンを作るための部品群だ。あるチームは構文や意味解析、開発者向けの機能に集中し、重たい作業を LLVM に引き渡すことができる。
こうした共有基盤のおかげで、現代の言語は何十年分のコンパイラ技術を再発明することなく、迅速で安全なツールチェーンを提供できるようになった。
コンパイラを専門にしていない人にも重要な理由
LLVM は日々の開発体験に現れる:
- 高速化:高水準のコードを多様なプラットフォームで効率的な機械語に変換できる。\n- 改善されたエラーとデバッグ:LLVM 周辺のエコシステムはより豊かな診断や優れたツールを可能にする。\n- 単なる「コンパイル」以上のもの:静的解析、サニタイザ、コードカバレッジなどの開発支援は、同じ中間表現やライブラリ上に構築されることが多い。
この記事の狙い(と範囲外のこと)
これは Chris Lattner が動かし始めたアイデアの案内ツアーだ:LLVM の構造、なぜ中間層が重要なのか、そしてそれが最適化やマルチプラットフォーム対応をどう可能にするかを見ていく。教科書ではないので、形式的な理論より直感と実世界でのインパクトに焦点を当てる。
Chris Lattner の元々のビジョン
Chris Lattner は計算機科学者で、2000年代初頭の大学院生として LLVM を始めた。動機は実用的な不満だった:コンパイラ技術は強力だが再利用が難しかった。新しい言語を作るとき、より良い最適化や新しい CPU のサポートが欲しいなら、しばしば密に結合した「オールインワン」コンパイラをいじる必要があり、どの変更にも副作用がついて回った。
彼が解きたかった問題
当時、多くのコンパイラは単一の大きな機械のように構築されていた:言語を理解する部分、最適化する部分、機械語を生成する部分が深く絡み合っていた。その結果、本来の目的には有効でも、適応するには手間がかかった。
Lattner の目標は「ある一つの言語のためのコンパイラ」ではなかった。複数の言語やツールを支えられる共有基盤をつくり、誰もが同じ複雑な部品を何度も書き直す必要をなくすことだった。パイプラインの中間を標準化できれば、端の部分でより速くイノベーションできるという賭けだった。
「モジュラーなインフラ」が新鮮だった理由
重要な転換は、コンパイルを明確な境界を持つ分離可能な部品群として扱うことだった。モジュラーな世界では:
- 言語チームはパーシングや開発者向け機能に集中できる、\n- 最適化チームは一度改善すれば広く共有できる、\n- ハードウェアのサポートは上流を再設計せずに追加できる。
この分離は今では自明に感じられるが、多くの実用コンパイラが進化してきたやり方には反していた。
オープンソースとして、他者に使われるために作られた
LLVM は早い段階でオープンソースとして公開され、それが重要だった。共有インフラは複数のグループが信用し、検査し、拡張できて初めて機能する。時間が経つにつれ、大学、企業、独立の貢献者がターゲットの追加、コーナーケースの修正、パフォーマンス改善、新しいツールの構築でプロジェクトを形作っていった。
コミュニティの側面は単なる善意ではなく、設計の一部でもあった:コアを広く有用にし、共同で維持する価値を生むこと。
大きなアイデア:フロントエンド、共有コア、バックエンド
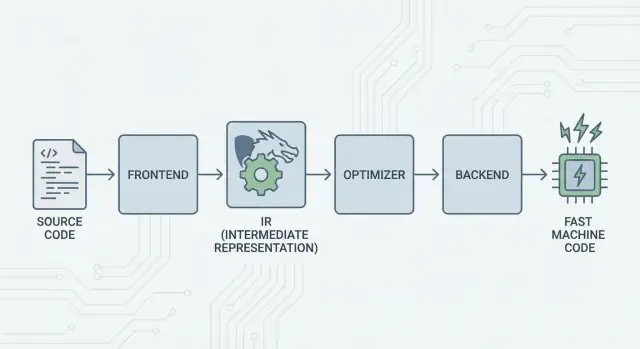
LLVM の基本アイデアは単純だ:コンパイラを三つの主要な部分に分け、多くの言語が最も難しい作業を共有できるようにする。
1) フロントエンド:「プログラマは何を意図したのか?」
フロントエンド は特定のプログラミング言語を理解する。ソースコードを読み、規則(構文や型)をチェックし、構造化された表現に変換する。
重要な点は:フロントエンドはすべての CPU 詳細を知る必要がない。彼らの仕事は関数、ループ、変数といった言語概念をより普遍的なものに翻訳することだ。
2) 共有の中間層:N×M の作業を 1 つに
従来、コンパイラを作るということは同じ作業を繰り返すことを意味した:
- N 言語 と M チップターゲット があると、サポートすべき組み合わせは N×M になる。
LLVM はそれを次のように削減する:
- N 個のフロントエンド が共有の形式に翻訳し、\n- M 個のバックエンド がその共有形式から機械語に翻訳する。
この「共有形式」が LLVM の中心であり、最適化や解析が存在する共通のパイプラインだ。中間での改善(より良い最適化やデバッグ情報など)は、多くの言語に一度に恩恵をもたらす。
3) バックエンド:「この CPU 上でどう高速に動かすか?」
バックエンド は共有表現を受け取り、x86、ARM など特定の出力を生成する。ここではレジスタ、呼び出し規約、命令選択といった詳細が重要になる。
パイプラインの直感的な図
コンパイルを旅行ルートに例えると:
- ソースコード は言語固有の国(フロントエンド)から始まり、\n- 共有で標準化された「中間言語」(LLVM のコア表現とパス)を通過し、\n- 最後に特定の目的地(ターゲットマシン向けのバックエンド)へ行くローカルな輸送に乗る。
結果はモジュラーなツールチェーンだ:言語はアイデアの表現に集中し、LLVM の共有コアは多くのプラットフォーム上でそれらを効率的に動かすことに集中する。
LLVM IR:再利用を可能にする中間層
LLVM IR(中間表現)は、プログラミング言語と CPU が実行する機械語の間にある「共通言語」だ。
コンパイラのフロントエンド(C/C++ 用の Clang など)はソースコードをこの共有形式に翻訳する。次に LLVM の最適化器とコード生成器が IR 上で動き、最後にバックエンドが IR を特定のターゲット(x86、ARM など)の命令に変換する。
ツールと CPU のあいだの共通言語
LLVM IR は慎重に設計された橋のようなものだ:
- 上側:多くのソース言語(C、C++、Rust、Swift、Julia など)が接続できる。\n- 下側:多くの CPU がターゲットになり得る。\n- 中間:同じ解析や最適化ツールが再利用される。
このため人々は LLVM を「コンパイラ」ではなく「コンパイラ基盤」と表現する。IR がその再利用性を可能にする共通契約だからだ。
なぜ IR が再利用を可能にし(労力を節約する)のか
コードが LLVM IR に入れば、ほとんどの最適化パスはそれが元々 C++ テンプレート、Rust のイテレータ、あるいは Swift のジェネリクスのどれから始まったかを知らなくて済む。最適化器が興味を持つのは次のような普遍的な事柄だ:
- 「この値は定数だ」\n- 「この計算は繰り返されている。結果を再利用できるか?」\n- 「このメモリロードは安全に移動または削除できるか?」
ですから言語チームは独自の最適化スタック全体を作り(維持し)る必要がない。フロントエンド(構文解析、型チェック、言語固有ルール)に集中し、重たい作業を LLVM に任せられる。
概念的な「見た目」
LLVM IR は機械語にマッピングしやすいほど低レベルだが、解析可能な程度に構造化されている。概念的には単純な命令(add、compare、load/store)、明示的な制御フロー(分岐)、型の明確な値から構成され、コンパイラ向けに設計された整理されたアセンブリ言語のようだ。
最適化はどう働くか(数式抜きで)
「コンパイラ最適化」と聞くと神秘的なトリックを想像しがちだが、LLVM では多くの最適化は 安全な機械的書き換え として理解できる—プログラムの意味を保ちつつ、より速く(あるいは小さく)実行されるように変換する手続きだ。
発明ではなく編集のように考える
LLVM はコード(LLVM IR)を受け取り、小さな改善を繰り返し適用していく。草稿を磨くようなプロセスだ:
- 重複作業の削減:ある値が二度計算されているがその間に何も変わらなければ、一度だけ計算して再利用する。\n- 明白なロジックの簡略化:定数式を先に畳み(例:
3 * 4を12にする)、CPU の実行負担を減らす。\n- ループの整理:ループ関連のパスは繰り返しチェックを減らしたり、不変な作業をループ外に移動したり、効率的に実行できるパターンを認識したりする。
これらの変更は慎重に行われる。パスは書き換えがプログラムの意味を変えないと証明できるときだけ適用する。
親しみやすい例
プログラムが次のようなことをしているとき:
- ループの各イテレーションで同じ設定値を読み取る、\n- 同じ入力に対する同じ計算を複数箇所で行う、\n- ある条件がある文脈では常に真/偽であることをチェックする、
…LLVM は「セットアップを一度だけ行う」「結果を再利用する」「不要な分岐を消す」ように変換しようとする。魔法というよりは家事のような整備だ。
実際のトレードオフ:コンパイル時間 vs 実行時間
最適化は無料ではない:解析が増え、パスが増えるほどコンパイル時間は長くなる。一方で最終的なプログラムは速くなることが多い。だからツールチェーンには「少し最適化する」か「積極的に最適化する」かのレベルが用意されている。
プロファイルを使うとこのトレードオフが改善される。プロファイル指向最適化(PGO) では実際にプログラムを実行して使用データを集め、それをもとに再コンパイルすることで LLVM が本当に重要な経路に最適化努力を集中できるようにする。
バックエンド:すべてを書き直さずに多くの CPU に到達する
チャットで構築
簡単なチャットでアイデアを動くアプリに。ツールチェーンの設定は不要。
コンパイラには二つの非常に異なる仕事がある。ひとつはソースコードを理解すること、もうひとつは特定の CPU が実行できる機械語を生成することだ。LLVM のバックエンドは後者に集中する。
バックエンドが実際にやること
LLVM IR を「普遍的なレシピ」と考えると、バックエンドはそのレシピを特定のプロセッサファミリ向けの正確な命令に変換する。デスクトップやサーバの多くで使われる x86-64、スマホや新しいラップトップで多い ARM64、あるいは WebAssembly のような特殊ターゲットがある。
具体的には、バックエンドは次を担当する:
- 命令選択:IR の操作を実際の CPU 命令にマッピングする、\n- レジスタ割り当て:どの値を高速な CPU レジスタに置き、どれをメモリに置くかを決める、\n- スケジューリング:CPU が効率的に実行できるよう命令の順序を決める、\n- アセンブリ/オブジェクト出力:リンカや OS が理解するコードを出力する。
共有インフラで新ハードウェア対応が容易になる理由
共有コアがないと、すべての言語が各 CPU に対してこれらすべてを再実装しなければならない。これは膨大な作業量で、継続的な保守負担となる。
LLVM はこれを逆転させる:フロントエンド(例:Clang)は一度 LLVM IR を生成し、バックエンドが各ターゲットごとの「最後の一里」を担当する。新しい CPU をサポートするには通常、1 つのバックエンドを書く(または既存のものを拡張する)だけでよく、すべてのコンパイラを書き直す必要はない。
複数プラットフォームで出荷するチームにとっての移植性
Windows/macOS/Linux、x86 と ARM、あるいはブラウザ上での実行などをサポートしなければならないプロジェクトにとって、LLVM のバックエンドモデルは実用的な利点だ。ひとつのコードベースやビルドパイプラインを維持し、ターゲットを変えたいときは別のバックエンドを選ぶ(あるいはクロスコンパイルする)ことで済む。
この移植性が LLVM が広く使われる理由の一つだ:単に高速化のためだけでなく、プラットフォーム固有のコンパイラ作業を繰り返さないことでチームの足を引っ張らない点が重要だ。
Clang:多くの開発者が最初に触れる LLVM
Clang は LLVM に接続する C、C++、Objective-C の フロントエンド だ。LLVM が最適化と機械語生成を担当する共有エンジンなら、Clang はソースファイルを読み、言語ルールを理解し、LLVM が扱える形に変換する役割を担う。
Clang が注目された理由
多くの開発者は論文ではなく、コンパイラを切り替えたときにフィードバックが突然よくなったことで LLVM を知った。
Clang の診断は可読性が高く具体的だと評判だ。あいまいなエラーの代わりに、問題を引き起こした正確なトークンを指し示し、該当行を表示し、期待していたものを説明してくれることが多い。これは日常の作業で重要で、「コンパイル→修正→再試行」ループがずっと快適になる。
Clang は libclang や Clang ツールリングといった明瞭でドキュメント化されたインターフェースも公開している。これによりエディタや IDE、その他の開発ツールが深い言語理解を統合しやすくなり、C/C++ パーサを再発明する必要がなくなった。
日常のワークフローでの現れ方
ツールが信頼してコードをパース・解析できると、次のような機能が「単なるテキスト編集」以上の体験になる:
- 大規模でマクロ多用の C++ プロジェクトでも正確なコードナビゲーション(「定義へジャンプ」「参照を探す」)が可能、\n- 記号やスコープを理解するリファクタリング支援(単純な検索置換でない)、\n- 実際の構文・型情報に基づくインラインヒントやクイックフィックス。
これらは多くの場合、開発者が初めて LLVM に触れる入口であり、IR やバックエンドについて考えなくても、補完や静的チェック、ビルドエラーの扱いやすさといった恩恵を受けられる理由だ。
なぜ多くの現代言語が LLVM を採用するのか
LLVM が言語チームに魅力的なのは単純な理由だ:完全な最適化コンパイラを一から作る代わりに、言語に集中できるからだ。
市場投入までの時間を短縮できる
新しい言語を構築するにはパーシング、型チェック、診断、パッケージツール、ドキュメント、コミュニティサポートなどが必要だ。そこに生産品質の最適化器、コード生成器、プラットフォーム対応をゼロから加えると、出荷が遅れる—時には数年単位で。
LLVM は既成のコンパイルコア(レジスタ割り当て、命令選択、成熟した最適化パス、一般的な CPU 向けターゲット)を提供する。チームは自分たちの言語を LLVM IR に落とし込み、既存のパイプラインに頼って macOS、Linux、Windows 向けのネイティブコードを生成できる。
「ヒーロー的な努力」なしで高性能を得られる
LLVM の最適化器とバックエンドは長年の工学的蓄積と実戦による改善の結果だ。これは LLVM を採用する言語にとって初期段階から強力な性能のベースラインをもたらすことが多い:初期でも十分に速く、LLVM 自体が改善されるにつれてさらに良くなる可能性がある。
このため、いくつかの著名な言語は LLVM を中核に据えている:
- Swift は Apple プラットフォーム全体で高性能なネイティブバイナリを生成するために LLVM を利用している。\n- Rust はコード生成と多くのアーキテクチャターゲットで LLVM に依存している。\n- Julia は高速な数値コードと、特殊化されたワークロードのためのランタイムコンパイルを可能にするために LLVM を使う。
すべての言語が LLVM を必要とするわけではない
LLVM を選ぶのはトレードオフであり必須ではない。ある言語は小さなバイナリ、非常に速いコンパイル、ツールチェーン全体の厳密な制御を優先するかもしれない。別の言語は既に確立されたコンパイラ(例えば GCC 系エコシステム)を持っているか、より単純なバックエンドを好むこともある。
LLVM は強力なデフォルトだから人気があるのであって、唯一の正しい道ではない。
JIT とランタイムコンパイル:高速なフィードバックループ
共有でクレジットを獲得
作ったものを共有したり、他の人をKoder.aiに招待するとクレジットがもらえます。
「ジャストインタイム(JIT)コンパイル」は最も簡単には「実行しながらコンパイルする」ことだ。すべてを事前に翻訳して最終実行ファイルを作る代わりに、JIT エンジンはあるコードが実際に必要になったときにその部分をオンザフライでコンパイルする。しばしば実行時の情報(正確な型やデータサイズなど)を使ってより良い選択をする。
なぜ JIT が速く感じられるか
すべてを先にコンパイルする必要がないため、JIT システムは対話的な作業で迅速なフィードバックを提供できる。コードの一部を書いたり生成したりしてすぐ実行でき、システムはその時点で必要な部分だけをコンパイルする。同じコードが繰り返し実行されるなら、JIT はコンパイル済み結果をキャッシュしたり、ホットな箇所をより積極的に再コンパイルしたりする。
ランタイムコンパイルが実用で役立つ場面
JIT は動的または対話的なワークロードで威力を発揮する:
- REPL やノートブック:スニペットを即時評価しつつ、重いループではネイティブ速度を得られる。\n- プラグインや拡張:アプリケーションが実行時にユーザコードを読み込み、ホスト CPU に最適化してコンパイルできる。\n- 動的ワークロード:入力が大きく変動する場合、実行時プロファイリングがどの経路を最適化すべきかを示す。\n- 科学計算:特定の行列サイズやモデル形状、ハードウェア機能向けに生成されたカーネルをオンデマンドでコンパイルできる。
LLVM の役割(誇張なしに)
LLVM 自体がすべてのプログラムを魔法のように速くするわけではなく、完全な JIT を単体で提供するわけでもない。LLVM が提供するのはツールキットだ:明確に定義された IR、大量の最適化パス、多くの CPU 向けのコード生成。プロジェクトはこれらの上に JIT エンジンを構築し、起動時間、ピーク性能、複雑さのトレードオフを選べる。
性能、予測可能性、現実のトレードオフ
LLVM ベースのツールチェーンは極めて高速なコードを生成できるが、「速い」という性質は一様でも安定でもない。コンパイラのバージョン、ターゲット CPU、最適化設定、そしてコンパイラに対する仮定によって変わる。
「同じソースで違う結果」が起きる理由
同じ C/C++(あるいは Rust、Swift)のソースを二つのコンパイラが読み、明確に異なる機械語を生成することは珍しくない。理由の一部は意図的だ:各コンパイラは固有の最適化パスやヒューリスティック、デフォルト設定を持つ。LLVM 内でも Clang のバージョンが変わればインラインの判断やループのベクトル化、命令スケジューリングが変わることがある。
また 未定義動作 や 未規定動作 に起因する場合もある。言語標準が保証しない挙動(例:C における符号付き整数のオーバーフロー)に依存していると、異なるコンパイラやフラグで「最適化」により結果が変わることがある。
決定性、デバッグビルド、リリースビルド
人々はコンパイルが決定的であること(同じ入力は同じ出力を生む)を期待しがちだが、実際にはほぼ同じになることはあっても常に完全一致するわけではない。ビルド経路、タイムスタンプ、リンク順序、プロファイルデータ、LTO の選択などが最終成果物に影響を与える。
現実的な区別は デバッグビルドとリリースビルド だ。デバッグビルドは多くの最適化を無効にしてステップ実行や読みやすいスタックトレースを維持する。リリースビルドは積極的な変換を有効にし、コードを並べ替え、関数をインライン化し、変数を削除する—パフォーマンスには有利だがデバッグは難しくなる。
実務的な助言:推測せず計測する
性能は計測の問題として扱うべきだ:
- 代表的なハードウェアと現実的なデータセットでベンチマークする。\n- キャッシュをウォームアップし、複数回実行する。\n- 明確なフラグでビルドを比較する(例:
-O2と-O3の差、LTO の有無、-marchの指定)。
小さなフラグの変更が性能を大きく変えることがある。安全なワークフローは仮説を立て、測定し、本番に近いベンチマークを保つことだ。
コンパイルを超えたツーリング:解析、デバッグ、安全性
素早く復旧
不具合のある変更をすばやく元に戻し、勢いを失わずに作業を続けられます。
LLVM はコンパイラツールキットと表現されるが、多くの開発者はコンパイルの「周辺」にあるツール群—アナライザ、デバッガ、安全性チェック—を通じてその影響を感じる。
解析や計測は「アドオン」として
LLVM は明確な中間表現(IR)とパスパイプラインを公開しているため、速度以外の目的でコードを検査・書き換える追加ステップを構築しやすい。あるパスはプロファイル用のカウンタを挿入したり、疑わしいメモリ操作にマークを付けたり、カバレッジデータを集めたりするかもしれない。
こうした機能は言語チームが同じ配管を再発明せずに統合できる点が肝心だ。
サニタイザ:ソースに近い段階でバグを捕まえる
Clang と LLVM は、テスト中に一般的なクラスのバグ(範囲外アクセス、use-after-free、データレース、未定義動作パターン)を検出するランタイム「サニタイザ」を普及させた。これらは魔法の盾ではなく、通常はプログラムを遅くするので CI や事前リリースのテストで使われる。しかし発報時は正確なソース位置とわかりやすい説明を示すことが多く、断続的なクラッシュの追跡に非常に有用だ。
より良い診断 = 早いオンボーディング
ツーリング品質はコミュニケーションでもある。明確な警告、実行可能なエラーメッセージ、一貫したデバッグ情報は新人の「謎」を減らす。ツールチェーンが「何が起きたか」と「どう直すか」を説明してくれれば、開発者はコンパイラの細かい挙動を覚える時間を減らし、コードベースを学ぶ時間に充てられる。
LLVM 自体が完璧な診断や安全性を保証するわけではないが、これらの開発者向けツールを実用的に構築・維持・共有できる共通基盤を提供する。
いつ LLVM を使うべきか(そして使わないべきか)
LLVM は「自分でコンパイラとツールを作るためのキット」と考えるのがよい。その柔軟性が現代の多くのツールチェーンを支えているが、すべてのプロジェクトに最適とは限らない。
LLVM が非常に適している場合
LLVM は本格的なコンパイラ工学を再利用したいときに輝く。
- 新しいプログラミング言語 を構築しているなら、LLVM は成熟した最適化パイプライン、プラットフォーム向けのコード生成、良好なデバッグサポートの道筋を与える。\n- クロスプラットフォームで出荷するアプリケーション なら、LLVM のバックエンド群は異なるアーキテクチャ向けの作業を減らす。\n- 開発者向けツール(リンタ、静的解析、コードナビゲーション、リファクタリング)を目指すなら、LLVM のエコシステムはコンパイラが既にコード構造や型を理解している点で強力な基盤となる。
過剰な場合
LLVM は組み込み機器でビルドサイズ、メモリ、コンパイル時間が厳密に制約されるような場合には重いかもしれない。
また非常に特殊化されたパイプラインや、一般的な最適化が不要な固定 DSL(ドメイン固有言語)のような場合には適さないこともある。
簡単なチェックリスト
次の三つを問い直してみる:
- 近いうちに 複数のプラットフォーム/CPU をターゲットにする必要があるか?\n- 既存の最適化やデバッグ情報 を自前で作るより利用した方が得か?\n- 最小限のカスタムコンパイラより、エコシステム(ツール、統合、採用) を重視するか?
「はい」が多ければ LLVM は実用的な選択になることが多い。主に狭い問題を解く最小のコンパイラが欲しいだけなら、より軽いアプローチが勝つこともある。
プロダクトチーム向けの実践的メモ:コンパイラ専門家にならなくても得られる LLVM の利点
ほとんどのチームは LLVM を「採用する」こと自体をプロジェクトにしたくない。彼らが欲しいのは成果物だ:クロスプラットフォームビルド、速いバイナリ、良好な診断、信頼できるツール。
それが Koder.ai のようなプラットフォームが興味深い理由の一つだ。ワークフローが高レベルな自動化(設計、スキャフォールディング生成、反復の高速化)によって駆動されるなら、LLVM はツールチェーンの下層で間接的に利益をもたらす。React のウェブアプリでも、Go バックエンド+PostgreSQL のサービスでも、Flutter のモバイルクライアントでも、該当する箇所では LLVM/Clang とその周辺ツールが最適化、診断、移植性の地味だが重要な仕事を裏で行っている。