2025年5月05日·1 分
Datadog とプラットフォームのシフト:テレメトリ、統合、ワークフロー
テレメトリ、統合、ワークフローがプロダクトになるとき、Datadog はどうやってプラットフォームになるのか—あなたのスタックに適用できる実践的なアイデアを紹介します。
テレメトリ、統合、ワークフローがプロダクトになるとき、Datadog はどうやってプラットフォームになるのか—あなたのスタックに適用できる実践的なアイデアを紹介します。
オブザーバビリティツールは通常、チャートやログ、クエリ結果を見せて特定の問いに答えるものです。問題が起きたときに「使う」ものです。
オブザーバビリティプラットフォームはより広範です:テレメトリの収集方法、チームの探索手順、インシデントのエンドツーエンドの扱いを標準化します。多くのサービスとチームにまたがって、組織が「毎日運用する」ものになります。
多くのチームはダッシュボードから始めます:CPU のチャート、エラー率のグラフ、いくつかのログ検索。それは有益ですが、真の目的は見栄えの良いチャートではなく検知の高速化と解決の高速化です。
プラットフォーム化は「これをグラフ化できるか?」ではなく、次のような問いを立てるときに起きます:
これらはアウトカム指向の問いで、可視化以上のものを要します。共有されたデータ標準、一貫した統合、テレメトリをアクションに繋げるワークフローが必要です。
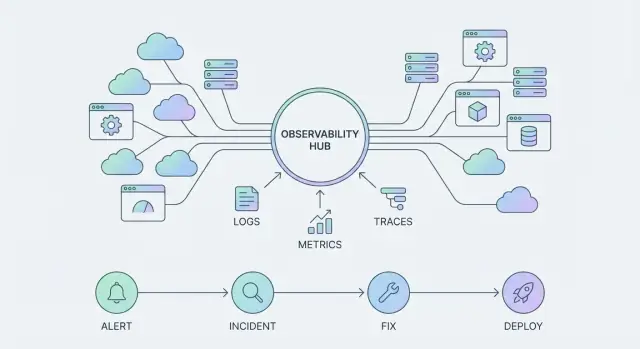
Datadog のようなプラットフォームが進化すると、"プロダクト面" はダッシュボードだけではありません。相互に結合する3つの柱があります:
単一のダッシュボードは1つのチームを助けます。プラットフォームはオンボードされるサービスごと、追加される統合ごと、標準化されるワークフローごとに強くなります。時間が経つほど盲点は減り、ツールの重複は少なくなり、インシデントは短縮します—なぜなら各改善が一回限りではなく再利用可能になるからです。
オブザーバビリティが「クエリするツール」から「構築するプラットフォーム」に変わると、テレメトリは単なる排気(raw exhaust)ではなくプロダクトの表面になります。何を発行するか、どれだけ一貫して発行するかが、チームが何を見て自動化し信頼できるかを決めます。
多くのチームは次の少数の信号を標準化します:
個々の信号は有用ですが、合わせるとダッシュボード、アラート、インシデントタイムライン、ポストモーテムの単一インターフェースになります。
よくある失敗は「すべてを収集するが命名が一貫しない」ことです。あるサービスが userId、別のサービスが uid、さらに別のサービスが何もログしない場合、データを確実にスライスしたり信号を結合したり再利用可能なモニタを作ったりできません。
チームは摂取量を倍にするより、サービス名、環境タグ、リクエスト ID、標準属性といったいくつかの慣習で合意するほうが多くの価値を得ます。
高カードinality フィールドは多くの可能値を持つ属性(user_id、order_id、session_id など)です。個別の顧客だけで発生する問題のデバッグに強力ですが、至る所で使うとコスト増とクエリ遅延を招きます。
プラットフォーム的アプローチは意図的に扱います:捜査上の明確な価値がある場所に高カードinalityを残し、グローバル集計用の場所では避けます。
メトリクス、ログ、トレース、イベント、プロファイルが同じコンテキスト(service、version、region、request ID)を共有すると払い戻しは速くなります。エンジニアは証拠をつなぐ時間を減らし、問題修正に多くの時間を割けます。ツール間を行き来して推測する代わりに、症状から根本原因まで一本のスレッドを辿れます。
多くのチームは「データを入れる」ことからオブザーバビリティを始めます。それは必要ですが戦略ではありません。テレメトリ戦略はオンボーディングを速く保ち、共有ダッシュボード、信頼できるアラート、意味のある SLO を支えるほどデータを一貫させます。
Datadog は通常、実用的な経路をいくつか通じてテレメトリを得ます:
初期はスピードが勝ちます:チームはエージェントを入れていくつかの統合を有効にし、すぐに価値を見ます。リスクは各チームが自分勝手なタグ、サービス名、ログ形式を作り、サービス間のビューがめちゃくちゃになりアラートの信頼性が落ちることです。
シンプルなルール:“クイックスタートは許可するが、30 日以内に標準化を必須にする。” これで勢いを保ちつつ混沌を固定化しません。
大きなタクソノミーは不要です。すべての信号(ログ、メトリクス、トレース)が持つべき小さなセットから始めましょう:
service:短く安定、英小文字(例:checkout-api)\n- env:prod、staging、dev\n- team:所有チーム識別子(例:payments)\n- version:デプロイバージョンまたは git SHAすぐに効果が出るもう一つのタグは tier(frontend、backend、data)です。フィルタが楽になります。
コスト問題は往々にして寛大すぎるデフォルトから生じます:
目標は収集量を減らすことではなく、正しいデータを一貫して収集し、驚きなくスケールできるようにすることです。
多くの人はオブザーバビリティツールを「インストールするもの」と考えますが、実際には良いコネクタが広がる方法で組織内に広がります:一つずつの統合経由で。
統合は単なるデータパイプではありません。通常、三つの部分があります:
最後の部分が統合を流通チャネルに変えます。ツールが「読み取るだけ」ならダッシュボードの宛先に過ぎません。書き込みもできれば日常業務の一部になります。
良い統合は妥当なデフォルトを含むためセットアップ時間を短縮します:事前構築のダッシュボード、推奨モニタ、パースルール、共通タグ。各チームが自分で "CPU ダッシュボード" や "Postgres アラート" を作る代わりに、ベースラインからカスタマイズできます。
標準化はツール統合の際に重要です:統合は新しいサービスがコピーできる再現可能なパターンを生み出し、成長を管理しやすくします。
選択肢を評価する際は「信号を取り込めるか」だけでなく「アクションを実行できるか?」を問ってください。例:チケット作成、インシデントチャンネルの更新、PR やデプロイビューにトレースリンクを埋める等。双方向のセットアップはワークフローがネイティブに感じられる場所です。
小さく予測可能に始めます:
経験則:即座にインシデント対応を改善する統合を優先し、単にチャートを増やすだけの統合は後回しにします。
標準ビューはオブザーバビリティプラットフォームが日常的に使える場所です。チームが同じメンタルモデル(「サービスとは何か」「健全とは何か」「最初にどこをクリックするか」)を共有すると、デバッグは速くなりハンドオフは明確になります。
少数の “ゴールデンシグナル” を選び、それぞれを具体的で再利用可能なダッシュボードにマップします。ほとんどのサービスでは:
一貫性が鍵です:サービス横断で使えるレイアウト一つが、複数の凝ったカスタムダッシュボードより有効です。
軽量なサービスカタログでも「誰かが見ておくべき」から「このチームが所有する」へと変わります。サービスにオーナー、環境、依存関係をタグ付けすると、プラットフォームは速やかに答えられます:このサービスにどのモニタが適用されるか?どのダッシュボードを開くべきか?誰がページされるか?
この明確さはインシデント中の Slack のやり取りを減らし、新しいエンジニアの自己解決を助けます。
これらを標準アーティファクトとして扱ってください:
バニティダッシュボード(判断につながらない綺麗なチャート)、場当たり的なワンオフアラート、 undocumented なクエリ(一人だけが理解している) はプラットフォームのノイズになります。重要なクエリなら保存し名前を付け、他者が見つけられるサービスビューに紐づけてください。
オブザーバビリティがビジネスに「本当に効く」ようになるのは、問題から確かな修復までの時間を短くするときです。それはワークフロー—信号からアクション、アクションから学習へとつなぐ繰り返し可能な経路—を通じて起きます。
スケーラブルなワークフローは単なるページング以上です。
アラートは焦点を絞ったトリアージループを開くべきです:影響を確認し、影響を受けるサービスを特定し、関連コンテキスト(最近のデプロイ、依存の健康、エラー急増、飽和シグナル)を引き出す。そこから伝達は技術的イベントを協調的な対応に変えます—誰がインシデントを所有しているか、ユーザが何を見ているか、次のアップデートの時刻はいつか。
緩和では「安全な操作」を手元に置きたい:機能フラグ、トラフィックシフト、ロールバック、レート制限、既知の回避策など。最後に学習は軽量なレビューでループを閉じ、何が変わったか、何が効いたか、次に自動化すべきことを記録します。
Datadog のようなプラットフォームは共有作業をサポートするときに価値を発揮します:インシデントチャンネル、ステータス更新、ハンドオフ、一貫したタイムライン。ChatOps 統合はアラートを構造化された会話に変えられます—インシデントを作成し、役割を割り当て、主要グラフやクエリをスレッド内に投稿して全員が同じ証拠を見るようにします。
有用なランブックは短く、意見がはっきりしており安全であるべきです。含める項目:目標(サービス復旧)、明確なオーナー/オンコールローテーション、ステップバイステップのチェック、適切なダッシュボード/モニタへのリンク、リスクを下げる「安全な操作」とそのロールバック手順。深夜 3 時に実行できないなら、それは完成していません。
インシデントとデプロイ、設定変更、機能フラグのフリップを自動相関すると根本原因は速く見つかります。「何が変わったか?」を第一級のビューにして、トリアージが証拠から始まるようにしてください。
SLO(Service Level Objective) は一定期間におけるユーザ体験についての単純な約束です—例えば「30 日間で 99.9% のリクエストが成功する」や「p95 ページロードが 2 秒未満」など。
これは“緑のダッシュボード”より優れます。ダッシュボードはしばしばシステムの健康(CPU、メモリ、キュー深度)を示すだけで、実際の顧客影響を示しません。SLO はチームにユーザが実際に感じるものを測らせます。
エラーバジェット は SLO が許容する非信頼性の量です。99.9% を約束した場合、30 日でおよそ 43 分のエラーを許容します。
これは意思決定のための実用的な運用システムを生みます:\n\n- バジェットが健康:機能を出し、実験をし、合理的なリスクを取る\n- バジェットが燃えている:リリースを遅らせ、信頼性作業に注力する\n- バジェットを使い果たした:リスクの高いデプロイを停止し、主要な故障源に対処する
リリース会議で意見を戦わせる代わりに、全員が見られる数字で議論できます。
SLO アラートは burn rate(エラーバジェットをどれだけ速く消費しているか)でアラートするのが効果的です。こうするとノイズが減ります:\n\n- 自己回復する短いスパイクは誰もページしないかもしれない\n- バジェットをすぐに消費し尽くすような持続的な問題は明確で実行可能なアラートを出す
多くのチームは 2 つのウインドウを使います:速い消費(すぐページ)と 遅い消費(チケット/通知)。
小さく始めて、実際に使う 2–4 個に絞ってください:
安定したら拡張してください。さもないとただ別のダッシュボード壁を作るだけになります。詳しくは /blog/slo-monitoring-basics を参照してください。
アラートは多くのオブザーバビリティプログラムが停滞する場所です:データはあり、ダッシュボードは良く見えるがオンコール経験がノイジーで信頼できない。人々がアラートを無視するようになると、プラットフォームはビジネスを守る能力を失います。
よくある原因は:\n\n- 行動不要の“FYI”アラートが多すぎる\n- コンテキスト無しに閾値がコピペされる(違うワークロードに同じ CPU ルール)\n- 複数ツールやチームが同じ症状をアラート(APM のエラー率モニタとログベースのエラーモニタが同じ事象でページ)\n- ノイジーなメトリクス(スパイクするパーセンタイル、オートスケール効果)
Datadog の文脈では、異なる“サーフェス”(メトリクス、ログ、トレース)からモニタが作られ、どれを正式なページソースにするか決めていないと信号の重複が発生します。
アラートをスケールさせるには人間にとって意味のあるルーティング規則が必要です:\n\n- 所有:各モニタに明確なオーナー(サービス/チーム)とエスカレーション経路を設定する\n- 重大度:ページングは緊急でユーザに影響するものに限定し、低重大度はチケットやチャット通知にする\n- メンテナンスウィンドウ:計画済みデプロイやマイグレーション、負荷試験はページを発生させない
有用なデフォルトの一つは:指標の変動ではなく症状でアラートする。ユーザが感じるもの(エラー率、チェックアウト失敗、持続的なレイテンシ、SLO バーン)でページし、入力(CPU、ポッド数)ではページしない、という考えです(予測可能に影響する場合を除く)。
運用の一部としてアラート衛生を含める:月次のモニタ削除とチューニング。鳴らないモニタを削除し、頻発する閾値を調整し、重複を統合して各インシデントにプライマリのページと補助コンテキストだけが残るようにします。
うまくやれば、アラートは人々が信頼するワークフローになり、バックグラウンドノイズにはなりません。
オブザーバビリティを“プラットフォーム”と呼ぶのは、単にログやメトリクス、トレース、たくさんの統合が一箇所にあるという意味だけではありません。ガバナンス—システムがチーム、サービス、ダッシュボード、アラートの数が増えても使えるままでいるための一貫性とガードレール—を含意します。
ガバナンスがなければ Datadog(あるいはどんなプラットフォームでも)が雑多な寄せ集めに堕し、数百の微妙に異なるダッシュボード、タグの不一致、所有権不明瞭、信頼されないアラートが溜まります。
よいガバナンスは誰が何を決めるか、システムが乱れたときに誰が説明責任を負うかを明確にします:\n\n- プラットフォームチーム:標準(タグ付け、命名、ダッシュボードパターン)を定義し、共有コンポーネントと統合を維持\n- サービスオーナー:自分のサービスのテレメトリ品質を所有し、モニタを意味あるものに保つ\n- セキュリティ&コンプライアンス:データ処理ルール(PII、保持、アクセス制御)を設け、高リスク統合をレビュー\n- リーダーシップ:信頼性目標やインシデント応答の期待値とガバナンスを整合させ、資金を配分
軽量な制御で効果が出ます:\n\n- テンプレートをデフォルトに:サービス種別(API、ワーカー、DB)ごとのスターターダッシュボードとモニタパック\n- タグポリシー:必須セット(例:service、env、team、tier)と任意タグのルール。可能なら CI で強制\n- アクセスと所有:機微データへのロールベースアクセス、ダッシュボードとモニタにオーナー必須\n- 高影響変更の承認フロー:ページングするモニタ、コストに影響するログパイプライン、機密データを引く統合はレビューを要求
品質をスケールさせる最速の方法は働くものを共有することです:\n\n- 共有ライブラリ:ロギングフィールド、トレース属性、共通メトリクスを標準化する内部パッケージやスニペット\n- 再利用可能なダッシュボードとモニタ:中央カタログに“ゴールデン”テンプレートを置き、チームがクローンして適用\n- バージョン管理された標準:主要資産をコードのように扱う—変更を文書化し、古いパターンを廃止し、更新を一箇所で告知
定められた道を通ることが簡単にしておく(クリック数が少ない、セットアップが速い、所有が明確)と定着します。
オブザーバビリティがプラットフォームのように振る舞うと経済性が出てきます:採用が進むほどテレメトリが増え、より有用になります。
フライホイール:\n\n- 採用サービス増 → クロスサービスの可視性と相関が向上\n- 可視性向上 → 診断速度向上、インシデント短縮、ツールへの信頼増加\n- 信頼増加 → さらに多くのチームが計測・統合 → さらにデータ増
ただし同じループがコストも増やします。ホスト、コンテナ、ログ、トレース、合成、カスタムメトリクスが予算を超えて増える可能性があるため意図的に管理する必要があります。
「全部オフにする」必要はありません。まずデータの形を整えます:\n\n- サンプリング:重要エンドポイントは高忠実度、他は積極的にサンプルする\n- 保持階層:生ログは短期保持、キュレーションされた監査/セキュリティストリームは長期保持\n- ログフィルタリングとパース:初期段階でノイズ(ヘルスチェック、静的アセット要求)を捨て、属性でルーティングできるようにパースを標準化\n- メトリク集約:無制限のカードinality を避け、パーセンタイル、レート、ロールアップを優先
プラットフォームがリターンを出しているかを示す少数の指標を追ってください:\n\n- MTTD(平均検知時間)\n- MTTR(平均復旧時間)\n- インシデント数と再発インシデント数(同一根本原因)\n- デプロイ頻度(と変更失敗率があれば)
これは監査ではなくプロダクトレビューにしてください。プラットフォーム所有者、数チーム、財務を集めて次をレビュー:\n\n- データタイプ別、チーム別のトップコスト要因\n- トップの成果:短縮されたインシデント、回避された障害、削減された作業負担\n- 合意された 2–3 のアクション(例:サンプリング調整、保持階層追加、ノイジーな統合修正)
目的は共有所有:コストが計測の意思決定の入力になるようにし、観測停止の理由にしないことです。
オブザーバビリティがプラットフォームに変わると、ツールスタックは点在するソリューションの集まりではなく共有インフラとして機能し始めます。この変化はツールスプロールを単なる不快から深刻な問題にします:計測の重複、不一致な定義(何がエラーか?)、オンコール負荷増大—ログ、メトリクス、トレース、インシデント間で信号が揃わないことが原因です。
統合は必ずしも「すべてを一ベンダーにする」ことを意味しません。むしろテレメトリと対応の記録場所を絞り、障害時に見るべき場所を減らすことを意味します。
ツールスプロールは通常、次の三つにコストを隠します:UI 間の切替に費やす時間、保守が必要な脆い統合、フラグメント化されたガバナンス(命名、タグ、保持、アクセス)。
より統合されたプラットフォームアプローチはコンテキスト切替を減らし、サービスビューを標準化し、インシデントワークフローを再現可能にします。
スタックを評価するとき(Datadog を含む)、次を検証してください:\n\n- 必須統合:クラウド、Kubernetes、CI/CD、インシデント管理、ページング、主要データストア+ビジネスで必須のシステム\n- ワークフロー:アラート→オーナー→ランブック→タイムライン→ポストモーテムがコピペ無しで行けるか\n- ガバナンス:タグ基準、アクセス制御、保持、ダッシュボード/モニタのスプロール防止策\n- 価格モデル:何がコスト要因か(ホスト、コンテナ、取り込みログ、インデックス化トレースなど)?成長を予測できるか?
1–2 のサービスを選び、"根本原因特定時間が 30 分→10 分に短縮" など明確な成功指標を定義します。必要なものだけを計測して 2 週間後に結果をレビューし、学びを中央化してください。
内部ドキュメントは集中化して学びが蓄積されるようにします(例:/blog/observability-basics を内部出発点としてリンク)。
Datadog を "一度で導入する" のではなく、小さく始め、早期に基準を決め、有効なものをスケールします。
0–30 日:オンボード(速く価値を示す)\n\n1–2 の重要サービスと 1 つの顧客向けジャーニーを選びます。ログ、メトリクス、トレースを一貫して計測し、既存の統合(クラウド、Kubernetes、CI/CD、オンコール)を接続します。
31–60 日:標準化(再現可能にする)\n\n学んだことをデフォルトにします:サービス命名、タグ、ダッシュボードテンプレート、モニタ命名、所有権。ゴールデンシグナルビュー(レイテンシ、トラフィック、エラー、飽和)と重要エンドポイントの最小 SLO セットを作ります。
61–90 日:スケール(混乱なく拡大)\n\n同じテンプレートで追加チームをオンボードし、ガバナンス(タグルール、必須メタデータ、モニタ追加のレビュー)を導入し、プラットフォームが健全でいるようコスト対利用を追跡し始めます。
オブザーバビリティをプラットフォームとして扱うと、通常小さな“接着”アプリが欲しくなります:サービスカタログ UI、ランブックハブ、インシデントタイムラインページ、オーナー→ダッシュボード→SLO→プレイブックを結ぶ内部ポータル。
こうした軽量内部ツールは Koder.ai のようなプラットフォームでチャット経由に素早く生成し、React フロントエンド+Go + PostgreSQL バックエンド等でプロトタイプからコード書き出し、デプロイまで支援できます。実務ではガバナンスとワークフローを、プロダクトチームを脱線させずに実装するためによく使われます。
45 分を 2 回:\n\n1) "ここでのクエリの仕方" — サービス、env、リージョン、バージョン別の共有クエリパターン\n2) "トラブルシューティングプレイブック" — フロー:影響確認 → デプロイマーカー確認 → サービス絞り込み → トレース確認 → 依存の健康確認 → ロールバック/緩和決定
オブザーバビリティのツールは問題が起きたときに参照するもの(ダッシュボード、ログ検索、クエリ)。オブザーバビリティのプラットフォームは継続的に運用するもの:テレメトリ、統合、アクセス、所有権、アラート、インシデントワークフローの標準化を通じて、検知と復旧の速度を上げるように組織全体で動かします。
最大の成果はアウトカムから来るためです(見た目のグラフではない):
グラフは助けになりますが、MTTD/MTTRを一貫して改善するには共有された基準とワークフローが必要です。
まず全ての信号に必須で付けるベースラインから始めてください:
serviceenv(prod, staging, dev)高カードinalityフィールド(user_id、order_id、session_id のように多くの値を取る属性)は、「特定の顧客だけで発生する問題」をデバッグするのに有用ですが、あちこちで使うとコストが増え、クエリが遅くなります。
使いどころのルール例:
多くのチームは次を標準化します:
重要なのはこれらが同じコンテキスト(service/env/version/request ID)を共有し、相関を速くすることです。
実用的なデフォルトは:
制御の度合いに合わせて経路を選び、全てで同じ命名/タグルールを適用してください。
両方行います:
これで導入の勢いを保ちながら、各チームが独自スキーマで固定化するのを防げます。
統合は単なるデータパイプではなく、次を含みます:
双方向の統合(信号を取り込み、かつアクションを起こせるもの)を優先すると、オブザーバビリティが日常業務に組み込まれます。
一貫性と再利用を重視してください:
バニティダッシュボードや場当たり的なアラートを避け、重要なクエリは保存して名前を付け、サービスビューに添付してください。
スパイクごとにページするのではなく、**エラーバジェットの消費率(burn rate)**でアラートするほうがノイズを減らせます。一般的なパターン:
サービス当たり小さく始める(2〜4 の SLO)こと。詳しくは /blog/slo-monitoring-basics を参照してください。
一般的な原因は:
ルーティングでスケールさせるには、所有者、重大度、メンテナンスウィンドウを明確にして、月次のモニタ見直しを実行する習慣をつくってください。
ガバナンスは人とプロセスの問題です。役割例:
テンプレート、必須タグ、オーナーの割当て、レビューのフローなど軽量な統制を導入すると乱雑さを防げます。
プラットフォームにすることでフライホイールが回り始めます:
その一方でコストも増えるため、サンプリング、保持階層、ログフィルタリング、メトリク集約などのレバーで信号を殺さずに形を整えてください。
ツール群が単なる点在するソリューションから共有インフラへと変わると、観測の重複や定義の不一致、オンコール負荷の増大といった問題が顕在化します。統合は "全てを一社に" という意味ではなく、テレメトリと対応のための記録場所を減らし、障害時に見るべき場所を絞ることです。
評価チェックリストの例:必須統合、ワークフロー(アラート→オーナー→ランブック→ポストモーテムの流れ)、ガバナンス、価格モデルを確認してください。
1〜2 のサービスでパイロットを回し、明確な成功指標(例:Root cause の同定が 30 分→10 分に短縮、ノイズアラート 40% 削減)を定めてください。必要最小限を計測し、2 週間後に結果をレビューして学びを中央化します(例:/blog/observability-basics)。
簡単に始めて基準を設定し、効果が出たものだけを拡張する。30/60/90 日プランの要点:
短期間で価値を示しつつ標準化してスケールすることが肝要です。
オブザーバビリティをプラットフォームとして扱うと、周辺の小さな“接着”アプリ(サービスカタログUI、ランブックハブ、インシデントタイムライン、オーナー→ダッシュボード→SLO→プレイブックを結ぶ内部ポータル)が必要になります。
こうした軽量な内部ツールは Koder.ai のようなプラットフォームで素早くプロトタイプ/デプロイでき、ガバナンスやワークフローを実装する際にフルプロダクトチームを割かずに済みます。
週内で出せるクイックウィンの例:
また、実用的なトレーニングを 2 回(各 45 分)実施すると定着します:1 回は「ここでのクエリの仕方」、もう1 回は「トラブルシューティングプレイブック」です。
teamversion(デプロイバージョンや git SHA)必要なら短期的に効果が出る追加タグとして tier(frontend, backend, data)を加えるとフィルタが楽になります。