2025年9月15日·1 分
デイビッド・パターソン、RISC思考と共設計の持続的影響
デイビッド・パターソンのRISC思考とハードウェア・ソフトウェア共設計が、性能あたりの消費電力をどのように改善し、CPU設計を形作り、現在のRISC-Vにどう繋がっているかを探る。
デイビッド・パターソンのRISC思考とハードウェア・ソフトウェア共設計が、性能あたりの消費電力をどのように改善し、CPU設計を形作り、現在のRISC-Vにどう繋がっているかを探る。
デイビッド・パターソンはしばしば「RISCの先駆者」と紹介されますが、彼の持続的影響は単一のCPU設計を超えています。彼はコンピュータを実用的に考える方法を広めました。つまり、性能は測定して簡潔化し、チップの命令からそれらを生成するソフトウェアツールまでエンドツーエンドで改善できるものだと考えることです。
RISC(Reduced Instruction Set Computing)は、プロセッサがより少ない単純な命令に集中することで、より速く、より予測可能に動くという考え方です。ハードウェアで複雑な操作を大量に実装する代わりに、よく使われる操作を迅速で規則的にし、パイプライン化しやすくします。得られるものは「能力の低下」ではなく、単純な構成要素を効率的に実行することが実ワークロードで勝つことが多い、という点です。
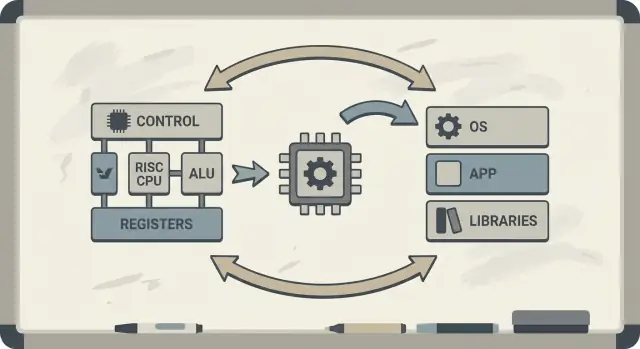
パターソンはハードウェアとソフトウェアの共設計(hardware–software co-design)を推進しました。これはチップ設計者、コンパイラ開発者、システム設計者が反復的に協力するフィードバックループです。
プロセッサが単純なパターンを効率的に実行するよう設計されていれば、コンパイラはそれらのパターンを確実に生成できます。コンパイラが実際のプログラムで特定の操作(例えばメモリアクセス)に時間がかかることを示せば、ハードウェアはそれらのケースに対処するよう調整できます。これが命令セットアーキテクチャ(ISA)の議論が自然にコンパイラ最適化、キャッシュ、パイプラインに結びつく理由です。
この記事では、RISCの考え方がなぜ「生の速度」だけでなく性能あたりのワット(performance per watt)に結び付くのか、「予測可能性」が現代のCPUやモバイルチップをより効率的にする方法、そしてこれらの原則がラップトップからクラウドサーバに至るまで今日のデバイスにどのように現れているかを学べます。
主要概念の地図を先に見たい場合は、/blog/key-takeaways-and-next-steps を先にご覧ください。
初期のマイクロプロセッサはきつい制約下で作られていました:チップは回路面積が限られ、メモリは高価で、ストレージは遅かった。設計者は手頃で「十分に速い」コンピュータを出荷しようとしており、しばしば小さなキャッシュ(あるいは無し)、控えめなクロックスピード、ソフトウェアが要求する量に比べて非常に限られたメインメモリでやりくりしていました。
当時の人気のある考え方の一つは、CPUがより強力で高レベルな命令(複数のステップを一度に実行できるもの)を提供すれば、プログラムは速くなり、書きやすくなるだろう、というものでした。1つの命令が「いくつかの作業を行える」なら、全体の命令数が減り、時間やメモリが節約できる、という直感です。
これは多くのCISC(Complex Instruction Set Computing)設計の背後にある直感です:プログラマやコンパイラに多くの派手な操作を与える。
問題は、実際のプログラム(およびそれを翻訳するコンパイラ)がその複雑さを一貫して活用するわけではないことでした。最も凝った命令の多くはめったに使われず、代わりにロード、ストア、加算、比較、分岐といったごく少数の単純な操作が何度も現れます。
一方で、複雑な命令の大規模なメニューをサポートすることは、CPUの製造や最適化を難しくし、チップ面積や設計努力を消費しました。それらは、本当に頻繁に使われる操作を予測可能で高速にするために使えるはずの資源を奪ってしまったのです。
RISCはそのギャップへの応答でした:CPUをソフトウェアが本当に頻繁に行うことに集中させ、その経路を速くし、オーケストレーションの多くをコンパイラに委ねる、というアプローチです。
CISC(複雑命令セット)は、多くの特殊で派手なツールが揃った作業場のようなものです—それぞれが一度に多くのことをこなせます。1つの命令がメモリからデータを読み込み、計算を行い、結果を格納する、といった処理をまとめて行うことがあります。
RISC(縮小命令セット)は、常に使う信頼できる少数の道具(ハンマー、ドライバー、メジャー)を携えておき、反復可能なステップからすべてを組み立てるような考え方です。各命令は小さく明確な仕事を行う傾向があります。
命令が単純で均質であると、CPUはそれらをよりクリーンな組立ライン(パイプライン)で実行できます。その組立ラインは設計しやすく、高クロックで動かしやすく、常に稼働状態にしておきやすくなります。
CISCスタイルの「一度に多くを行う」命令では、CPUが複雑な命令をデコードして内部的に小さなステップに分解する必要があり、その過程で複雑さが増し、パイプラインを滑らかに保つのが難しくなります。
RISCは命令実行時間の予測可能性を目指します—多くの命令はだいたい同じ時間で動きます。予測可能性はCPUが効率よく作業をスケジュールするのに役立ち、コンパイラがパイプラインを止めずにコードを生成するのを助けます。
RISCは同じタスクを実行するのにより多くの命令が必要になることが多いです。これは次のような影響を意味します:
しかし、各命令が速く、パイプラインが滑らかなら、それでも有利なことが多いです。実際、良く最適化されたコンパイラと適切なキャッシュが「命令が増える」という欠点を相殺できます—CPUは複雑な命令の解きほぐしに費やす時間を減らし、有用な作業により多くの時間を割けるようになります。
バークレーRISCは単なる新しい命令セットではありませんでした。それは研究態度でした:論理的に美しい設計から始めるのではなく、まずプログラムが実際に何をするかを観察し、その現実にCPUを合わせていくという姿勢です。
バークレーのチームは概念的には、とても速く予測可能に動くほどに単純なCPUコアを目指しました。ハードウェアに多くの複雑な命令トリックを詰め込む代わりに、コンパイラにより多くを任せました:単純な命令を選び、うまくスケジュールし、可能な限りレジスタにデータを保持するようにします。
その役割分担が重要でした。小さくクリーンなコアはパイプライン化しやすく、理解しやすく、トランジスタ当たりの性能が高くなることが多いのです。コンパイラはプログラム全体を見て事前に計画できるため、ハードでは難しい最適化が可能です。
デイビッド・パターソンは測定を重視しました。なぜならコンピュータ設計には誘惑的な神話が多く、実際のコードではめったに現れない機能が「有用に見える」だけで追加されがちだからです。バークレーRISCはベンチマークやワークロードトレースを使ってホットパス(ループ、関数呼び出し、メモリアクセス)を特定し、そこを最適化することを推奨しました。
これが「共通ケースを速くする」という原則に直結します。もし大多数の命令が単純な操作やロード/ストアであるなら、それらの頻繁に起きるケースを最適化する方が、稀な複雑命令を高速化するよりも利益が大きいのです。
永続的な教訓は、RISCが単なるアーキテクチャではなく思考法でもあるということです:頻繁に起きることを単純化し、データで検証し、ハードウェアとソフトウェアを単一のチューニング可能なシステムとして扱うことです。
ハードウェア–ソフトウェア共設計は、CPUを孤立して設計しないことを意味します。チップとコンパイラ(場合によってはOS)を相互に意識して設計し、合成的な「最適な命令列」だけでなく実際のプログラムが高速かつ効率的に動くことを目指します。
共設計は次のようなエンジニアリングループで機能します:
ISAの選択:命令セットがCPUで表現しやすい操作を決める(例:load/store、豊富なレジスタ、単純なアドレッシングモード)。
コンパイラ戦略:コンパイラはホットな変数をレジスタに置き、スケジュールを調整してストールを避け、呼び出し規約を選んでオーバーヘッドを減らす。
ワークロード結果:実際のプログラム(コンパイラ、データベース、グラフィックス、OSコード)を測定して、時間とエネルギーがどこに使われているかを見る。
次の設計:測定に基づいてISAやマイクロアーキテクチャ(パイプライン深度、レジスタ数、キャッシュサイズ)を調整する。
ここに、関係性を示す小さなループ(C)があります:
for (int i = 0; i < n; i++)
sum += a[i];
RISCスタイルのISAでは、コンパイラは通常 sum と i をレジスタに保持し、a[i] のために単純な load 命令を使い、ロード中にCPUが空にならないよう 命令スケジューリング を行います。
もしチップがコンパイラがほとんど使わない複雑な命令や特殊なハードウェアを追加すると、その部分は依然として電力と設計努力を消費します。一方で、コンパイラが頼る「地味な」要素—十分なレジスタ、予測可能なパイプライン、効率的な呼び出し規約—は十分に投資されないかもしれません。
パターソンのRISC思考は、実際のソフトウェアが実際に利益を得られる場所にシリコンを投資することを強調しました。
RISCの重要な考えは、CPUの「組立ライン」を稼働させやすくすることでした。その組立ラインはパイプラインです:1つの命令を完全に終える前に次の命令を開始し、処理を段階(fetch, decode, execute, write-back)に分けて重ね合わせます。すべてが順調に流れると、ほぼ1サイクルあたり1命令の完了が達成されます—まるで多段の工場で車が順々に進むように。
パイプラインは各段が似ているときに最も効率的に動きます。RISC命令は比較的一様で予測可能(しばしば固定長で単純なアドレッシング)に設計されており、ある命令が追加時間を要したり特殊な資源を必要としたりする「特殊ケース」を減らします。
実際のプログラムは完璧に滑らかではありません。ある命令は前の命令の結果に依存しており(値が計算されるまで使えない)、またはメモリからのデータを待つ必要があり、あるいは分岐の次の経路がまだ不明であることがあります。
これらはストールを引き起こします—パイプラインの一部がアイドル状態になる短い停止です。直感的には、次の段が必要とするものがまだ到着していないため、有益な作業をできなくなるとストールが発生します。
ここでハードウェア–ソフトウェア共設計が明確に現れます。ハードウェアが予測可能であれば、コンパイラが助けることができます。つまり、意味を変えずに命令の順序を入れ替えて「隙間」を埋めます。例えば、ある値の生成を待っている間に、その値に依存しない独立した命令を差し込むことで待ち時間を有効利用できます。
見返りは役割分担です:CPUは共通ケースをシンプルで高速に保ち、コンパイラはより賢く計画することで、ストールを減らしてスループットを上げます。これにより多くの場合、複雑な命令セットを増やさずに実用的な性能向上が得られます。
CPUは単純な操作を数サイクルで実行できますが、メインメモリ(DRAM)からデータを取り出すには数百サイクルかかることがあります。このギャップは、DRAMが物理的に離れていること、容量とコストに最適化されていること、そしてレイテンシと帯域幅の制約に起因します。
CPUが高速化する一方でメモリが同じ速度で向上しないため、この不一致は「メモリの壁」と呼ばれます。
キャッシュはDRAMのペナルティを毎回支払わないように、CPUの近くに置かれた小さく高速なメモリです。実プログラムには局所性があるためキャッシュが効きます:
現代のチップはキャッシュを階層化(L1, L2, L3)し、作業セットをコアの近くに置くよう努めます。
ここでハードウェア–ソフトウェア共設計の効果が明確になります。ISAとコンパイラはプログラムがキャッシュにかける圧力を形作ります。
日常的に言えば、メモリの壁は高クロックのCPUでも遅く感じる理由です:大きなアプリの起動、データベースクエリ、フィードのスクロール、大規模データセットの処理はしばしばキャッシュミスやメモリ帯域幅でボトルネックになり、純粋な算術性能ではありません。
長い間、CPUの議論はレースのようでした:どのチップがタスクを最速で終えるかが重要だ、という観点です。しかし実際のコンピュータは物理的な制約—バッテリー容量、発熱、ファン音、電気代—の中で動きます。
だからこそ**性能あたりのワット(performance per watt)**が重要な指標になりました:消費したエネルギーに対してどれだけ有用な仕事ができるか、という効率です。
これはピーク性能ではなく効率を意味します。2つのプロセッサが日常使用で同等に速く感じられても、片方は少ない電力でそれを実現でき、冷却やバッテリー寿命で有利です。
ノートやスマホではバッテリー寿命と快適さに直結し、データセンターでは電力と冷却のコストやサーバの密度に影響します。
RISC的思考はハードウェアでやるべきことを減らし、より予測可能にする方向にCPU設計を誘導しました。シンプルなコアはエネルギー面で次のような利点があります:
重要なのは「単純だから常に良い」ということではありません。複雑さにはエネルギーコストがあり、適切に選んだISAとマイクロアーキテクチャは少しの工夫で大きな効率を得られる、という点です。
携帯機器はバッテリと発熱を重視し、サーバは電源供給と冷却を気にします。異なる環境ですが同じ教訓が当てはまります:最速のチップが最良のコンピュータとは限らない。安定したスループットを保ちながらエネルギー消費を抑えられる設計が勝つことが多いのです。
RISCはしばしば「単純な命令が勝つ」と要約されますが、持続的な教訓はもう少し微妙です:命令セットは重要だが、実際の利得の多くはISAそのものよりもチップの作り方から来たということです。
初期のRISC議論は、きれいで小さな命令セットが自動的にコンピュータを速くすると示唆していました。実際には、最も大きな性能向上はRISCが容易にした実装上の選択(単純なデコード、より深いパイプライン、高いクロック、コンパイラによるスケジューリング)から来ることが多かったのです。
そのため、マイクロアーキテクチャ、キャッシュサイズ、分岐予測、製造プロセスが異なれば、異なるISAを持つ2つのCPUが性能面で驚くほど近づくことがあります。ISAはルールを決め、マイクロアーキテクチャが実際の勝負を左右します。
パターソンの時代の重要な変化は、直感ではなくデータに基づいて設計することでした。使われるかどうかが不明な命令を追加するより、プログラムが実際に何をするかを測定し、共通ケースを最適化する方が効果的だとわかったのです。
この姿勢は「機能主導」の設計に比べてしばしば優れた成果をもたらしました。なぜなら、ある命令が数行のコードを節約しても、それがサイクルや電力、チップ面積に与えるコストは至る所で顕在化するからです。
RISC思考は「RISCチップだけ」に影響したわけではありません。多くのCISC CPUも内部的にRISC風の手法(複雑命令を単純な内部操作に分解するなど)を採用しつつ、互換性のあるISAを保ってきました。
結果として起きたのは「RISCがCISCを打ち負かした」という話ではなく、測定、予測可能性、ハードウェアとソフトウェアの緊密な協調を重視する設計への進化でした。
RISCは研究室にとどまらず、MIPSからRISC-Vへと続く明確な流れがありました—単純さと明快さを特徴とするISAが制約ではなく利点とされた系譜です。
MIPSは教育用ISAとしてよく記憶されています。理由は明快です:ルールが説明しやすく、命令フォーマットが一貫しており、基本的なload/storeモデルがコンパイラを邪魔しないからです。
この清楚さは学術的な利点だけでなく実用面でも役立ちました。MIPSプロセッサはワークステーションから組込みまで長年にわたり製品に搭載されました。整然としたISAは速いパイプライン、予測可能なコンパイラ、効率的なツールチェーンを作りやすくしたのです。
RISC-VはMIPSが踏み切らなかった一歩を進めました:それはオープンなISAです。これにより大学、スタートアップ、大企業がISAへのアクセス交渉なしに実験し、シリコンを出荷し、ツールを共有できます。
共設計にとってこのオープン性は重要です。ソフトウェア側(コンパイラ、OS、ランタイム)がハードウェアと公開の場で並行して進化でき、人工的な障壁が少なくなります。
RISC-Vが共設計に適しているもう一つの理由はそのモジュール式アプローチです。小さなベースISAから始め、ベクトル演算、組込み向け制約、セキュリティ機能など、特定のニーズに応じて拡張を追加できます。
これにより健全なトレードオフが促進されます:すべての機能を一つの巨大な設計に詰め込むのではなく、ハードウェア機能を実際に走らせるソフトウェアに合わせて調整できるのです。
より深い入門は /blog/what-is-risc-v を参照してください。
共設計はRISC時代の歴史的注釈ではなく、現代の計算がより速く、より効率的になる方法そのものです。重要な考え方はパターソン流のままです:ハードウェアだけ、あるいはソフトウェアだけで勝てるのではなく、双方が互いの強みと制約に合うときに勝つのです。
スマートフォンや多くの組込みデバイスはRISC原則(多くはARMベース)を強く採用しています:単純な命令、予測可能な実行、エネルギー使用の重視です。
この予測可能性はコンパイラが効率的なコードを生成するのを助け、設計者はスクロール時に少ない電力で動作し、カメラ処理やゲーム時にバーストできるコアを作れます。
ラップトップやサーバも同様の目標—特に「性能あたりのワット」—を追求する傾向にあります。ISAが伝統的に「RISC的」でなくても、多くの内部設計の選択はRISCに似た効率性を目指しています:深いパイプライン、幅広い実行ユニット、アグレッシブな電力管理などです。
GPU、AIアクセラレータ(TPU/ NPU)、メディアエンジンは共設計の実践的な形です。一般目的CPUにすべてを押し付ける代わりに、プラットフォームは一般的な計算パターンに合ったハードウェアを提供します。
これが単なる「追加ハードウェア」ではなく共設計である理由はそれを取り巻くソフトウェアスタックにあります:
ソフトウェアがアクセラレータをターゲットにしなければ、理論上の速さは絵に描いた餅のままです。
似たスペックを持つ2つのプラットフォームが非常に違って感じられることがあるのは、「実際の製品」にはコンパイラ、ライブラリ、フレームワークが含まれるからです。最適化された数学ライブラリ(BLAS)、優れたJIT、賢いコンパイラはチップを変えずに大きな性能向上を生み出します。
だから現代のCPU設計はベンチマーク駆動であることが多いのです:ハードウェアチームはコンパイラやワークロードが実際に何をするかを見て、キャッシュ、分岐予測、ベクタ命令、プリフェッチなどの機能を調整して共通ケースを速くします。
プラットフォーム(携帯、ラップトップ、サーバ、組込みボード)を評価する際は、共設計の兆候を探してください:
現代のコンピューティングの進歩は単一の「より速いCPU」についてではなく、実際のワークロードを測定し設計されたハードウェア+ソフトウェアのシステム全体についての話です。
RISC思考とパターソンのメッセージは、いくつかの持続的な教訓にまとめられます:速くあるべきものを単純化し、実際に何が起きているかを測定し、ハードウェアとソフトウェアを単一のシステムとして扱うこと—ユーザーは部品ではなくシステム全体を体験するからです。
まず、単純さは策略であって美学ではありません。クリーンなISAと予測可能な実行は、コンパイラが良いコードを生成し、CPUがそれを効率的に実行するのを容易にします。
次に、測定は直感に勝ります。代表的なワークロードでベンチマークし、プロファイルデータを集め、実際のボトルネックに基づいて設計判断を行ってください—コンパイラ最適化の調整、CPU SKUの選択、重要なホットパスの再設計などです。
第三に、共設計が利得を積み上げる場所です。パイプラインに優しいコード、キャッシュを意識したデータ構造、現実的な性能あたりのワット目標は、ピーク理論性能を追うよりも実用的な速度をもたらすことが多いです。
プラットフォーム(x86、ARM、あるいはRISC-Vベース)を選ぶなら、ユーザーがどう使うかの観点で評価してください:
もしあなたの仕事が「これらの測定を製品に組み込む」ことであれば、ビルド–測定ループを短くすることが役立ちます。例えば、チームはKoder.aiのようなツールを使ってチャット駆動のワークフローで実アプリ(ウェブ、バックエンド、モバイル)をプロトタイプし進化させ、各変更後に同じエンドツーエンドのベンチマークを再実行します。プランニングモード、スナップショット、ロールバックなどの機能は、パターソンが推した「測る→設計する」訓練を現代のプロダクト開発に適用したものです。
効率に関するより深い入門は /blog/performance-per-watt-basics を参照してください。環境の比較やコスト/性能の簡易見積が必要なら /pricing が役に立つことがあります。
持続する結論はこうです:単純さ、測定、共設計という考え方は、MIPS時代のパイプラインから現代のヘテロジニアスコアやRISC-Vのような新しいISAに至るまで、実装が進化してもなお有効であり続ける、ということです。
RISC(Reduced Instruction Set Computing)は、パイプライン化や最適化がしやすい、小さくて規則的な命令集合を重視します。目的は「機能が少ないこと」ではなく、むしろ実際のプログラムでよく使われる操作(ロード/ストア、算術、分岐など)をより予測可能かつ効率的に実行することです。
CISCは多機能で特殊な命令を多数用意し、1命令で複数の処理を行うことがあるのに対し、RISCは小さく単純な基本命令(多くはload/storeとALU命令)を組み合わせて処理を構成します。実際には、多くのCISCプロセッサが内部で複雑命令をより単純な内部マイクロオペに分解しているため、境界は曖昧になっています。
より単純で均質な命令は、CPUの“組立ライン”(パイプライン)を滑らかに動かしやすくします。これによりスループットが向上し(理想的にはほぼ1サイクルあたり1命令)、特殊処理にかかるオーバーヘッドが減るため、性能と消費電力の両面で有利になります。
予測可能なISAと実行モデルがあれば、コンパイラは次のようなことを確実にできます:
これによりパイプラインのバブル(無駄な空き時間)を減らし、複雑なハードウェア機能を増やさずに実行効率を改善できます。
ハードウェア–ソフトウェア共設計とは、ISAの選択、コンパイラ戦略、実際のワークロードの測定結果が互いにフィードバックし合う反復的なループのことです。CPUを孤立して設計するのではなく、ハードウェア、ツールチェーン、(場合によっては)OS/ランタイムを同時に調整して、実際のプログラムが速く効率的に動くようにします。
パイプラインが進めなくなるのは次のようなときです:
こうしたストールは実行効率を下げます。RISC的な予測可能性は、ハードとコンパイラの両方がこれらの発生頻度とコストを減らすのに役立ちます。
「メモリの壁」とは、CPUの高速化に比べてメインメモリ(DRAM)の応答速度が追いつかないことで生じるギャップです。キャッシュ(L1/L2/L3)は時間的・空間的局所性を利用してこのギャップを埋めますが、キャッシュミスが多いと実行はほとんどDRAM待ちになり、非常にメモリ依存(memory-bound)になります。
「ワット当たりの性能(performance per watt)」は、消費エネルギーあたりに得られる有用な仕事量を示す効率指標です。実運用ではバッテリ駆動時間、発熱、データセンターの電力/冷却コストに直結します。RISC的設計は無駄なスイッチングや複雑さを減らし、予測可能な実行を促してこの指標を改善します。
多くのCISC設計が内部でRISCのような単純な内部マイクロオペに落とす手法を取り入れたため、「RISCがCISCに勝った」という単純な話ではありません。重要だったのはマインドセットです:実際のワークロードを測定し、共通ケースを最適化し、ハードウェアとソフトウェアを連携させることです。
RISC-Vは小さなベースISAとモジュール式拡張を持ち、かつオープンである点が特徴です。大学やスタートアップ、大企業がISAの制約なしに実験・製品化・ツール整備できるため、ハードとソフトが公開の場で一緒に進化できます。「シンプルなコア + 強力なツール + 測定に基づく設計」というRISC的アプローチの現代的継承といえます。詳しくは /blog/what-is-risc-v を参照してください。