2025年9月12日·1 分
Day One監視のためのプロダクション観測スターターパック
Day 1向けのプロダクション観測スターターパック:追加すべき最小限のログ、メトリクス、トレースと、「遅い」報告に対するシンプルなトリアージフロー。
Day 1向けのプロダクション観測スターターパック:追加すべき最小限のログ、メトリクス、トレースと、「遅い」報告に対するシンプルなトリアージフロー。
まず壊れるのはアプリ全体ではなく、たいていは一つのステップです。テストでは問題なかったクエリが忙しくなったり、ある依存先がタイムアウトを始めたりします。実際のユーザーは多様です:遅い端末、不安定なネットワーク、予期しない入力、都合の悪い時間のトラフィックスパイク。
「遅い」と言われたときには意味がいくつもあります。ページの読み込みが遅いのか、操作がもたつくのか、あるAPIコールがタイムアウトしているのか、バックグラウンドジョブが溜まっているのか、サードパーティが全体を引きずっているのか。
だからダッシュボードが必要になる前に、まず信号が必要です。初日では全てのエンドポイントの完璧なグラフは不要です。どこに時間が使われているかを速く答えられるだけのログ、メトリクス、トレースがあれば十分です。
初期段階で過剰に計測するリスクもあります。イベントが多すぎるとノイズになり、コストが増え、アプリを遅くすることさえあります。さらに悪いのは、チームがテレメトリを信頼しなくなることです。
現実的なDay 1の目標はシンプルです:"遅い"という報告を受けたら、15分以内に遅いステップを見つけられること。クライアント描画、APIハンドラとその依存、データベースやキャッシュ、バックグラウンドワーカーや外部サービスのどこにボトルネックがあるかを判断できること。
例:新しいチェックアウトフローが遅く感じられる。大量のツールがなくても、「95%の時間が支払いプロバイダ呼び出しに使われている」や「カートのクエリが多くの行をスキャンしている」と言えることが欲しい。Koder.aiのようなツールで素早くアプリを出すなら、このDay 1のベースラインはさらに重要です。出荷の速さは、デバッグが速ければこそ役に立ちます。
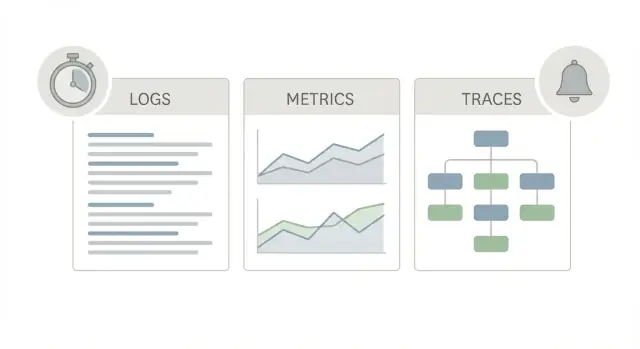
良いプロダクション観測スターターパックは同じアプリを三つの異なる「視点」で見るようにします。それぞれが違う問いに答えます。
ログはストーリーです。1つのリクエスト、1人のユーザー、1つのバックグラウンドジョブで何が起きたかを伝えます。ログ行は「注文123の支払いが失敗した」や「DBが2秒でタイムアウトした」といった情報と、request ID、user ID、エラーメッセージなどの詳細を含めます。奇妙な単発の問題が報告されたとき、ログは発生と影響範囲を確認する最速手段です。
メトリクスはスコアボードです。トレンドやアラートに使う数値:リクエスト率、エラー率、レイテンシのパーセンタイル、CPU、キューの深さ。メトリクスは問題が稀なのか広範なのか、悪化しているかを教えます。もし10:05に全員のレイテンシが上がったなら、メトリクスがそれを示します。
トレースは地図です。トレースは単一のリクエストがシステムを通る経路(web -> API -> database -> third-party)を追い、時間がどこで使われたかを段階的に示します。なぜ重要かというと、「遅い」はほとんどの場合ひとつの大きな謎ではなく、たいてい1つの遅いホップだからです。
インシデント中の実用的な流れはこうです:
簡単なルール:数分たっても1つのボトルネックを指せないなら、アラートを増やすべきではありません。より良いトレースと、トレースとログをつなぐ一貫したIDが必要です。
「見つからない」インシデントの多くはデータ不足ではなく、同じ事象がサービス間で異なる形で記録されていることが原因です。Day 1にいくつかの共通規約を決めておくと、答えを急ぐときにログ、メトリクス、トレースが揃います。
まず、デプロイ単位ごとに1つのservice nameを選び、安定させましょう。もし「checkout-api」がダッシュボードの半分では「checkout」になると履歴が失われ、アラートが壊れます。環境ラベルも同様に少数(例:prod, staging)にして一貫して使いましょう。
次に、すべてのリクエストを追いやすくします。エッジ(APIゲートウェイ、ウェブサーバ、最初のハンドラ)でrequest IDを生成し、HTTP呼び出しやメッセージキュー、バックグラウンドジョブに渡してください。サポートチケットで「10:42に遅かった」と言われたら、1つのIDで正確なログとトレースを引けます。
Day 1に有効な規約セットの例:
時間単位は早めに合意してください。APIレイテンシはmilliseconds、長いジョブはsecondsなどにしておくと混乱が減ります。混在すると見かけ上は問題なくても誤った結論になります。
具体例:すべてのAPIがduration_ms, route, status, request_idをログしていれば、「テナント418のチェックアウトが遅い」といったレポートは素早くフィルタで絞れます。
プロダクション観測スターターパックで一つだけやるとしたら、ログを検索しやすくすることです。まずは構造化ログ(通常JSON)と、全サービスで同じフィールドを使うこと。プレーンテキストログはローカル開発では問題ありませんが、実トラフィックやリトライ、複数インスタンスがあるとノイズになります。
良い指針は:インシデントで実際に使うものだけログすること。多くのチームは次の質問に答えられる必要があります:このリクエストは何か?誰がやったか?どこで失敗したか?何に触れたか?これらに役立たないログ行は不要です。
Day 1では小さく一貫したフィールドセットを保ち、サービス間でフィルタや結合ができるようにしてください:
request_id, trace_idがあればそれも)user_idやsession_id、route、method)duration_ms)エラーが起きたら、文脈付きで一度だけログしてください。エラータイプ(またはコード)、短いメッセージ、サーバーエラーならスタックトレース、関与した上流依存(例:postgres、payment provider、cache)を含めます。リトライごとに同じスタックトレースを繰り返すのは避け、代わりにrequest_idを付けてチェーンを追えるようにします。
例:ユーザーが設定を保存できないと報告したら、request_idで検索してPATCH /settingsの500を確認し、ダウンストリームでPostgresタイムアウトがduration_ms付きで見つかる。フルペイロードは不要で、ルート、ユーザー/セッション、依存先名があれば十分です。
プライバシーは後回しにするものではありません。パスワード、トークン、認証ヘッダ、フルリクエストボディ、敏感なPIIはログに残さないでください。ユーザーを特定する必要があるなら、メールや電話番号の代わりに安定したID(またはハッシュ)をログしましょう。
Koder.aiでReact、Go、Flutterのアプリを作るなら、これらのフィールドを最初から生成されるサービスに組み込んでおく価値があります。初めてのインシデントで「ログを直す」羽目にならないように。
良いスターターパックは、小さなメトリクスセットで「今システムが健康かどうか、問題があるならどこが痛んでいるか」を素早く答えます。
多くのプロダクション問題は4つの“ゴールデンシグナル”のどれかで現れます:レイテンシ(応答が遅い)、トラフィック(負荷の変化)、エラー(失敗)、飽和(共有リソースが限界)。アプリの主要部分ごとにこれらが見えれば、推測なしで大半のインシデントをトリアージできます。
レイテンシは平均ではなくパーセンタイルで見るべきです。p50、p95、p99を追って、少数のユーザーがひどい体験をしているのを見つけます。トラフィックはリクエスト/秒(ワーカーならジョブ/分)。エラーは4xxと5xxを分けて見る:4xxの上昇はクライアント挙動やバリデーションの変化、5xxの上昇はアプリ側や依存先を示します。飽和はCPU、メモリ、DB接続、キューのバックログなどの「何かが限界に近い」信号です。
ほとんどのアプリをカバーする最小セット:
具体例:ユーザーが「遅い」と報告し、APIのp95が上がってトラフィックは平常なら、飽和を確認します。DBプール使用率が最大近くに張り付いてタイムアウトが増えていれば、そこがボトルネックです。DBが問題なければキュー深さの急増を見て、バックグラウンド処理が共有リソースを奪っている可能性を疑います。
Koder.aiでアプリを作るなら、このチェックリストをDay 1の定義済みの完了条件として扱ってください。アプリが小さいうちにメトリクスを追加する方が、最初の本番インシデント中に追加するより簡単です。
ユーザーが「遅い」と言ったら、ログは何が起きたかを、メトリクスはどれくらい頻発しているかを示します。トレースは1つのリクエストの内部で時間がどこに使われたかを教えてくれます。その単一のタイムラインが漠然とした不満を明確な修正に変えます。
まずはサーバー側から始めましょう。アプリのエッジ(リクエストを最初に受け取るハンドラ)で入り口を計測して、すべてのリクエストがトレースを生成できるようにします。クライアント側のトレースは後回しで構いません。
Day 1で有効なトレースは、遅くなりがちな部分に対応するスパンを持ちます:
トレースを検索・比較しやすくするために、いくつかの主要属性をサービス間で一貫してキャプチャしてください。
受信リクエストスパンにはroute(/orders/:idのようなテンプレート)、HTTPメソッド、ステータスコード、レイテンシを記録します。DBスパンにはDB種別(PostgreSQL、MySQL)、操作タイプ(select、update)、可能ならテーブル名を記録します。外部呼び出しには依存名(payments、email、maps)、ターゲットホスト、ステータスを記録します。
Day 1ではサンプリングが重要です。さもないとコストとノイズが急増します。シンプルなhead-basedルールを使いましょう:エラーと遅いリクエストは100%トレース(SDKが対応していれば)、通常トラフィックは少量(1–10%)サンプリング。低トラフィック時には高めにして、使用量が増えたら下げます。
「良い」トレースの例:1つのトレースで話の流れが読めること。GET /checkoutが2.4sかかり、DBが120ms、キャッシュが10ms、外部の支払い呼び出しが2.1s(リトライあり)という具合です。これで問題は依存先にあるとわかります。これがプロダクション観測スターターパックの核心です。
誰かが「遅い」と言ったら、その漠然とした感覚をいくつかの具体的な質問に変えることが最速の勝利です。このスターターパックのトリアージフローは、新しいアプリでも機能します。
問題を絞り、証拠に従って調査してください。最初からDBに跳ぶのはやめましょう。
安定化させたら、小さな改善を一つだけ行い、何が欠けていたかを書き留めます。例えば、遅延が特定リージョンだけか判別できなかったなら、レイテンシメトリクスに地域タグを追加します。長いDBスパンがあってどのクエリか分からなかったら、注意してクエリラベルか「query name」フィールドを追加します。
簡単な例:checkoutのp95が400msから3sに跳ね上がり、トレースで支払い呼び出しに2.4s使われているなら、アプリコードの議論はやめてプロバイダ、リトライ、タイムアウトを調べます。
「遅い」と言われると、意味を突き止めるだけで1時間無駄にすることがあります。スターターパックは、問題を素早く絞るのに役立つことが前提です。
最初に3つの明確化質問から始めます:
次に、通常は次の数値がどこへ進むべきかを教えてくれます。完璧なダッシュボードを探す必要はありません。「いつもより悪い」信号が欲しいだけです。
p95が上がってエラーが平常なら、過去15分の遅いルートのトレースを一つ開いてください。1つのトレースで時間がDB、外部API呼び出し、ロック待ちのどれに使われているかが分かります。
次にログ検索を一つ行います。ユーザー報告があるならrequest_id(または保存しているならトレースID)で検索してタイムラインを読む。なければ、同時間帯に最も共通するエラーメッセージで検索し、遅延と一致するかを確認します。
最後に、今すぐ緩和するか深掘りするかを決めます。ユーザーがブロックされていて飽和が高いなら、スケールアップ、ロールバック、非必須機能の無効化などのクイックな緩和で時間を稼げます。影響が小さくシステムが安定しているなら、トレースやスロークエリログで深掘りしてください。
リリース後数時間でサポートに「チェックアウトが20〜30秒かかる」というチケットが増えます。誰も自分のラップトップで再現できないため、推測が始まります。ここでスターターパックの価値が出ます。
まずメトリクスで症状を確認します。HTTPリクエストのp95レイテンシチャートが明確にスパイクしているが、POST /checkoutだけに限定され、他のルートは正常、エラー率も平常です。これで「サイト全体が遅い」から「あるエンドポイントが遅くなった」に絞れます。
次に、遅いPOST /checkoutリクエストのトレースを開きます。ウォーターフォールが犯人を明らかにします。よくある二つの結果:
PaymentProvider.chargeスパンが18秒かかっていて、大部分が待ち時間。DB: insert orderスパンが遅く、クエリの返答まで長い待ちがある。その後、トレースのrequest_id(またはトレースID)を使ってログで検証します。ログには「payment timeout reached」や「context deadline exceeded」のような繰り返し警告と、リリースで追加されたリトライが見えるかもしれません。DB経路なら、ロック待ちメッセージやしきい値を超えた遅いクエリ文が確認できるかもしれません。
三つの信号が揃えば、対処は簡単になります:
重要なのは捜索しなかったことです。メトリクスがエンドポイントを示し、トレースが遅いステップを示し、ログがその失敗モードを正確なリクエストで裏付けました。
ほとんどのインシデント時間は回避可能なギャップで失われます:データはあるがノイズが多い、リスクがある、あるいは必要な細部が欠けているために因果関係をつなげられない。
一つの罠はログを多く取りすぎること、特にリクエストボディの生ログです。役立ちそうに聞こえますが、ストレージコストが膨らみ、検索が遅くなり、パスワードやトークン、個人データを誤って取り込むリスクがあります。構造化フィールド(route、status code、latency、request_id)を優先し、入力の小さく明示的に許可されたスライスのみをログしてください。
もう一つの無駄は詳細そうに見えるが集約不能なメトリクスです。高カードinalityのラベル(完全なユーザーID、メール、ユニークな注文番号)はメトリクス系列を爆発させ、ダッシュボードを使えなくします。代わりに粗いラベル(route名、HTTPメソッド、ステータスクラス、依存名)を使い、ユーザー固有のものはログに置きます。
診断を妨げ続ける間違い:
小さな実用例:checkoutのp95が800msから4sに上がったら、数分で答えたいのは「デプロイ直後に始まったか?」と「時間はアプリ内か依存先か?」です。パーセンタイル、リリースタグ、ルートと依存名のあるトレースがあればすぐに答えられます。ないと推測で時間を燃やします。
本当の利得は一貫性です。スターターパックは、すべての新しいサービスが同じ基本を同じ名前で出荷し、壊れたときに簡単に見つけられるときにのみ役に立ちます。
Day 1の選択を短いテンプレートにしてチームで再利用してください。小さく、しかし具体的に保ちます。
インシデント時に誰でも開ける「ホーム」ビューを一つ作ってください。1画面でrequests/min、エラー率、p95レイテンシ、主要な飽和メトリクスが見えて、environmentとversionでフィルタできるのが理想です。
アラートは最初は最小に保ちます。2つのアラートで多くをカバーできます:主要ルートのエラー率スパイクと同じルートのp95レイテンシスパイク。追加するなら、それぞれに明確なアクションを定義してください。
最後に、毎月のレビューを習慣に。ノイズの多いアラートを削り、命名を整え、前回のインシデントで時間を節約できたような欠けた信号を1つ追加します。
これをビルドプロセスに組み込むには、リリースチェックリストに「observability gate」を入れてください:request IDs、version tags、ホームビュー、そして2つのベースラインアラートがないとデプロイしない。Koder.aiで出荷する場合は、これらのDay 1信号をplanning modeで定義し、スナップショットとロールバックを使って素早く調整できるようにします。
Start with the first place users enter your system: the web server, API gateway, or your first handler.
request_id and pass it through every internal call.route, method, status, and duration_ms for every request.That alone usually gets you to a specific endpoint and a specific time window fast.
Aim for this default: you can identify the slow step in under 15 minutes.
You don’t need perfect dashboards on day one. You need enough signal to answer:
Use them together, because each answers a different question:
During an incident: confirm impact with metrics, find the bottleneck with traces, explain it with logs.
Pick a small set of conventions and apply them everywhere:
Default to structured logs (often JSON) with the same keys everywhere.
Minimum fields that pay off immediately:
Start with the four “golden signals” per major component:
Then add a tiny component checklist:
Instrument server-side first so every inbound request can create a trace.
A useful day-one trace includes spans for:
Make spans searchable with consistent attributes like (template form), , and a clear dependency name (for example , , ).
A simple, safe default is:
Start higher when traffic is low, then reduce as volume grows.
The goal is to keep traces useful without exploding cost or noise, and still have enough examples of the slow path to diagnose it.
Use a repeatable flow that follows evidence:
These mistakes burn time (and sometimes money):
service_name, environment (like prod/staging), and versionrequest_id generated at the edge and propagated across calls and jobsroute, method, status_code, and tenant_id (if multi-tenant)duration_ms)The goal is that one filter works across services instead of starting over each time.
timestamp, level, service_name, environment, versionrequest_id (and trace_id if available)route, method, status_code, duration_msuser_id or session_id (a stable ID, not an email)Log errors once with context (error type/code + message + dependency name). Avoid repeating the same stack trace on every retry.
routestatus_codepaymentspostgrescacheWrite down the one missing signal that would have made this faster, and add it next.
Keep it simple: stable IDs, percentiles, clear dependency names, and version tags everywhere.