2025年9月18日·1 分
データアクセス要求(DSAR)とプライバシー対応のウェブアプリの作り方
監査ログ、レダクション、エクスポート、コンプライアンス対応レポートを備えたデータアクセス要求(DSAR)を受付、検証、実行、追跡するウェブアプリの設計と構築方法を学びます。
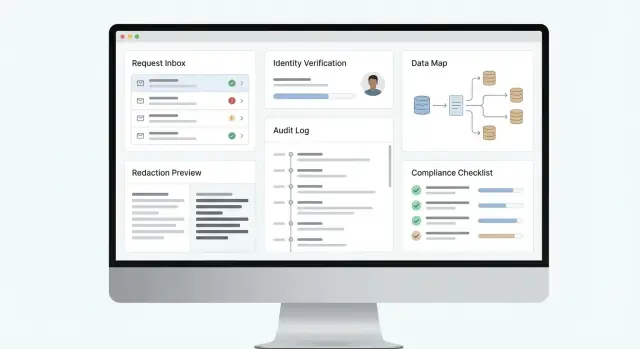
監査ログ、レダクション、エクスポート、コンプライアンス対応レポートを備えたデータアクセス要求(DSAR)を受付、検証、実行、追跡するウェブアプリの設計と構築方法を学びます。
データアクセス要求 — 多くはDSAR(Data Subject Access Request)やSAR(Subject Access Request)と呼ばれます — は、個人が組織に対して自分に関する個人データの内容、利用方法、コピーの提供を求めるものです。ビジネスが顧客、ユーザー、従業員、見込み客のデータを収集しているなら、これらのリクエストは必ず発生すると想定してください。
うまく対応することは罰金を避けるだけでなく信頼の問題です。明確で一貫した対応は、データを把握しており個人の権利を尊重していることを示します。
多くのチームはまずGDPRやCCPA/CPRAを中心に設計しますが、アプリは複数の法域や社内ポリシーに対応できる柔軟性を備えるべきです。
一般的なリクエストタイプには:
「アクセス」でも範囲はさまざまで、「あなたが持っているすべて」や特定アカウント・期間・製品に紐づくデータなどがあります。
DSARアプリは複数のステークホルダーの交差点にあります:
強力なDSARウェブアプリは、すべてのリクエストをタイムリーに、追跡可能に、一貫して処理します。つまり明確な受付、信頼できる本人確認、システム横断でのデータ収集、判断の文書化(拒否や一部対応を含む)、誰がいつ何をしたかの監査可能な記録です。
目標は各リクエストが火事場の対応にならずに、内部でも規制当局に対しても説明可能な繰り返し可能なプロセスを持つことです。
画面設計やツール選定の前に、組織にとって「完了」とは何かを明確にしてください。データアクセス要求ウェブアプリの成功は、すべてのリクエストが確実に受付から配信まで移動し、法定期間を守り(GDPR、CCPAなど)、弁護可能な記録を残すことです。
アプリが初日からサポートすべきコアDSARワークフローを文書化します:
実用的に:どのチャネルを受け付けるか(ウェブフォームのみ vs メール/手動入力)、対応する言語/ロケール、早期に扱う“エッジケース”(共有アカウント、元従業員、未成年者)を定義してください。
要件を週次で追えるKPIに変換します:
各ステップの所有者(プライバシーチーム、サポート、セキュリティ、法務)を書き出します。これを後でアクセス制御や監査ログに反映するための基礎にします。
進捗を標準化して報告する場合、“唯一の真実のソース”(アプリ)と内部報告ツールへエクスポートすべき項目を決めてください。
DSARウェブアプリは単なるフォームとエクスポートボタン以上のものです。アーキテクチャは厳格な期限、監査用の証拠、頻繁な方針変更をサポートし、毎回カスタムプロジェクトにならないようにする必要があります。
多くのチームはプロダクトに三つの“顔”を持たせます:
これらを分離すると(同一コードベースでも)権限管理、監査、将来の変更が容易になります。
スケーラブルなDSARワークフローは通常、いくつかの主要サービスに分かれます:
次を使い分けます:
ボリュームが低くチームが小さいなら、単一デプロイ可能アプリで始めるのが素早い。コネクタ数、トラフィック、監査要件が増えたらモジュラーサービスに移行し、統合を更新しても管理業務をリスクにさらさないようにする。
内製で構築する場合、Koder.aiのようなツールは、構造化された会話からReactベースの管理ポータルとGo+PostgreSQLバックエンドの実装を生成して、最初の実用的なフローを早く作るのに役立ちます。
プラットフォーム機能で特に有用なのは:
それでもプライバシー/法務の承認とセキュリティレビューは必要ですが、“最初の使えるエンドツーエンド”を加速すると要件検証が早くなります。
受付体験は多くのDSAR/プライバシー案件の成功/失敗を左右します。提出が容易でなかったり、トリアージが遅いと期限を逃し、過剰収集や約束した対応を見失う原因になります。
実用的なウェブアプリは複数の入口をサポートし、すべてを単一のケースレコードに正規化します:
重要なのは一貫性です:どのチャネルからでも同じケースフィールド、同じタイマー、同じ監査トレイルになること。
受付フォームは短く目的志向に:
“念のため”にセンシティブな詳細を求めないでください。追加が必要なら検証ステップで求めます。
ケース状態は明示的にし、スタッフとリクエスターの双方に見せます:
received → verifying → in progress → ready → delivered → closed
各遷移は誰が動かせるか、何が証拠として要るか(例:本人確認完了)、何がログに残るかを明確にします。
ケース作成時点で適用法に紐づくSLAタイマーを開始します。期限が近づけばリマインダーを送り、ポリシーで許される場合は(確認待ちなど)クロックを一時停止し、エスカレーションルール(例:“verifying”が5日放置ならマネージャーに通知)を追加します。
適切に設計された受付とライフサイクルは、コンプライアンスを受信箱の問題から予測可能なワークフローに変えます。
本人確認はプライバシーコンプライアンスが現実になる場面です:これから個人データを開示するため、申請者がデータ主体である(または正当に代理できる)ことに確信を持つ必要があります。ワークフローの第一級要素として組み込みます。
複数のオプションを用意して正当な利用者がブロックされないようにしつつ、プロセスの正当性を保ちます:
UIでは次に何が起きるかを明確に示してください。ログイン済みユーザーには既知データを事前入力し、不要な追加情報は求めないでください。
申請者がデータ主体でないケースを扱えるようにします:
これをデータスキーマで明示的にモデル化(例:"requester" vs "data subject")し、権限を確立した方法をログに残します。
すべてのリクエストが同じリスクを持つわけではありません。以下の場合に検証レベルを自動で上げるルールを設定します:
検証をエスカレーションする際は、短い平易な理由を表示して恣意的に見えないようにします。
IDや委任状、監査イベントなどの検証アーティファクトは暗号化し、アクセス制御し、限られた役割だけが見られるようにします。保存は必要最小限にし、明確な保持期間を定めて自動削除します。
検証証拠自体をセンシティブデータとして扱い、後のコンプライアンス証明のために監査トレイルに反映させます。
DSARアプリは、個人データが実際にどこにあるかをどれだけ可視化できるかで価値が決まります。コネクタを書く前に、実務的なシステムインベントリを作成し、それを維持可能にしてください。
まずユーザー識別情報を含みやすいシステムから始めます:
各システムについて、所有者、目的、保存しているデータカテゴリ、利用可能な識別子(メール、ユーザーID、デバイスID)、アクセス方法(API/SQL/エクスポート)、制約(レート制限、保持、ベンダー対応時間)を記録します。このインベントリがリクエスト到着時の“真実のソース”になります。
コネクタは華美である必要はなく、信頼性が重要です:
コネクタはアプリの他部分から分離し、更新してもワークフローを壊さないようにします。
異なるシステムは同じ人物を異なる形で表現します。レビュー担当が“リンゴとリンゴ”を比較できるように、一貫したスキーマに正規化します。実用的なモデル例:
person_identifier(マッチに使った識別子)data_category(プロフィール、通信、取引、テレメトリ)field_name と field_valuerecord_timestamp出所(プロベナンス)は結果を正当化する要素です。各値にメタデータを付与して保存します:
「これはどこから来たのか?」という問いに正確に答えられるようになります。
ここは“この人物に関するすべてを見つける”部分であり、雑に扱うとプライバシーリスクが生じやすい箇所です。良い取得・マッチングエンジンは広く検索して完全性を確保しつつ、無関係なデータを引かないように制御されます。
エンジンを、受付時に信頼して収集できる識別子を中心に設計します。一般的な開始点はメール、電話番号、顧客ID、注文番号、郵送先住所です。
プロダクトや分析でよく使われる識別子も拡張していきます:
安定したキーがないシステムにはファジーマッチ(正規化した名前+住所など)を追加し、結果を“候補”としてレビュー扱いにします。
“ユーザーテーブル全部をエクスポート”する誘惑を避け、識別子でクエリして関連フィールドだけを返すようにします。特にログやイベントストリームでは最小限の取得が重要です。
実務的なパターンは二段階フロー: (1) 軽量な“識別子が存在するか?”チェック、(2) 確認されたマッチに対してフルレコードを取得。
複数ブランドや地域、事業部門を扱う場合、すべてのクエリにテナントスコープを含めます。フィルタはUIだけでなくコネクタ層で適用し、クロス・テナントの漏洩を防ぐテストを行います。
重複や曖昧さに備えます:
マッチ信頼度、どの識別子でマッチしたかの証拠、タイムスタンプを保存し、レビュー担当が理由を説明できるようにします。
取得エンジンが関連レコードを集めても、そのままリクエスターに送ってはいけません。多くの組織は第三者の個人データ、機密事業情報、法律や契約で制限されるコンテンツの誤開示を防ぐために人によるレビューを必要とします。
レビュー担当者が実際に使える構造化された「ケースレビュー」ワークスペースを作ります:
ここで判断を標準化します。少数の決定タイプ(include、redact、withhold、needs legal)にすると一貫性と監査が容易になります。
レダクション(データの一部を削除)と、開示が許されない場合にレコード全体を除外する機能の両方をサポートするべきです。
レダクション対象例:
除外は開示できない場合に採られ、その理由を構造化して保存します(例:法律上の特権、営業秘密、第三者に不利益を与える恐れ)。
データを単に隠すだけでなく、判断理由を構造化して記録しておくことで将来正当化できます。
多くのDSARワークフローは次の二つの成果物でうまく動きます:
ソース、関連日付、レダクションや除外の説明、問い合わせや異議申立て方法などのメタデータを含めて、単なるデータダンプから理解可能な成果物にします。
一貫した見た目を保ちたい場合はレスポンステンプレートを使い、バージョン管理して、どのテンプレートが使われたかを示せるようにし、監査ログと組み合わせて変更履歴を追跡します。
セキュリティはデータアクセス要求アプリで後付けする機能ではなく、センシスです:センシブな個人データの漏洩を防ぎ、各リクエストが正しく処理されたことを証明します。目標は簡単:適切な人だけが適切なデータにアクセスし、すべてのアクションが追跡可能で、エクスポートファイルの悪用を防ぐことです。
責任が曖昧にならないように、明確な役割ベースアクセス制御から始めてください。典型的な役割:
権限は細かく設定します。例えばレビュアーは取得データを見られても期限を変更できない、承認者はレスポンスを公開できてもコネクタ認証情報を編集できない、など。
DSARワークフローは次をカバーするappend-only監査ログを生成するべきです:
監査エントリは改ざんを困難にします:アプリサービスに書き込み権限を限定し、編集を禁止し、可能なら書き込み専用ストレージやログバッチのハッシュ/署名を検討します。
監査ログは部分開示や却下といった判断を弁護する際の主要証拠です。
送信中(TLS)と保存時(DB、オブジェクトストレージ、バックアップ)の両方で暗号化してください。APIトークンやDB資格情報などのシークレットは専用のシークレットマネージャーに保管し、コードや設定ファイル、サポートチケットに埋め込まないでください。
エクスポートには短命の署名付きダウンロードリンクや暗号化ファイルを使い、誰が生成できるかを制限して自動的に失効させます。
プライバシーアプリはスクレイピングやソーシャルエンジニアリングの対象になります。次を導入してください:
これらによりリスクを下げつつ、実際の顧客や運用チームの使い勝手を維持できます。
DSARワークフローは顧客が即座に気づく2点で成功か失敗かが決まります:期限内に応答するか、そして更新が明確で信頼できるか。コミュニケーションは最初から設計する機能として扱ってください。
少数の承認済みテンプレートを用意してローカライズできるようにします。短く具体的に、法的な過剰説明は避けるべきです。
よく使うテンプレート:
変数(リクエストID、日付、ポータルリンク、配信方法)を埋められるようにし、法務/プライバシー承認済みの文言を保持します。
期限は法(GDPR vs CCPA/CPRA)、リクエスト種別(アクセス、削除、訂正)、本人確認の進捗によって変わります。アプリは以下を計算・表示すべきです:
期限はケース一覧、ケース詳細、スタッフのリマインダーで常に可視化します。
組織によっては追加の受信箱は望まれません。Webhookやメール統合を提供して、既存ツール(ヘルプデスクや内部チャット)に更新を流せるようにします。
イベントドリブンなフック例:case.created、verification.requested、deadline.updated、response.delivered。
シンプルなポータルはやり取りを減らします:顧客はステータス(“received”、“verifying”、“in progress”、“ready”)を確認し、書類をアップロードし、結果を取得できます。
データを配る際は添付ファイルを避け、認証付きの時限ダウンロードリンクを提供し、有効期限と期限切れ時の対処を明示します。
保持と報告はDSARツールが単なるワークフローアプリを超えてコンプライアンスシステムになる部分です。目標は単純:必要なものは保持し、不要なものは削除し、証拠で示すこと。
保持はオブジェクトタイプごとに定義します。典型的な区分:
保持期間は法域やリクエストタイプで設定可能にします。例:監査ログは長期間保持し、本人確認の証拠は短く、エクスポートは配信後速やかに削除してハッシュとメタデータだけ残すなど。
削除タイマーを止め、スタッフの操作を制限する明示的なリーガルホールドステータスを追加します。これには:
また免除や制限(第三者データ、特権通信など)を構造化結果としてモデル化し、自由記述に頼らず一貫して報告可能にします。
規制当局や内部監査は事例ではなく傾向を求めます。次をカバーするレポートを作成してください:
レポートは一般的なフォーマットでエクスポートでき、レポート定義はバージョン管理して数値の説明責任を担保します。
アプリは組織が公開するルールと同じものを参照すべきです。管理設定やケースビューから /privacy や /security のような内部リソースに直接リンクを張り、各保持判断の“なぜ”をオペレータが確認できるようにします。
UIが動いたら完成というわけではありません。最もリスクの高い障害は端っこで起こります:人物の取り違え、コネクタのタイムアウト、データの抜け落ちたエクスポート。テストと運用を最初から組み込みます。
本番で問題になりやすいDSARの落とし穴に基づく再現可能なテストスイートを作ります:
各コネクタに対して“ゴールデン”フィクスチャ(サンプルレコード+期待出力)を用意し、スキーマ変更を早期に検出します。
運用監視はアプリの健全性とコンプライアンス結果の両方をカバーすべきです:
メトリクスは構造化ログと組み合わせて、「どのシステムが、どのケースで、ユーザーには何が見えたか」を答えられるようにします。
ツールの追加、フィールド名の変更、ベンダーの停止は常に発生します。コネクタのプレイブック(所有者、認証方法、レート制限、既知のPIIフィールド)とスキーマ変更承認プロセスを作ってください。
実用的な段階的ロールアウト:
継続的改善のチェックリスト:月次の障害レポートのレビュー、マッチ閾値の調整、テンプレートの更新、レビュアー再トレーニング、未使用コネクタの廃止。
迅速に反復するなら、ステージングを含む環境戦略と容易に戻せるデプロイ戦略を使ってください。Koder.aiのようなプラットフォームはデプロイ/ホスティングとソースコードエクスポートをサポートし、プライバシーワークフローが頻繁に変わる場合に実装と監査可能性を揃えるのに役立ちます。
DSAR(Data Subject Access Request、個人データ開示請求)またはSARは、個人が組織に対して自分に関する個人データの内容、利用目的、そしてそのコピーの提供を求めるリクエストです。
DSAR向けのウェブアプリは、リクエストの受付、本人確認、検索、レビュー、返答を一貫して、かつ期限内に行えるようにし、監査可能な記録を残せるようにします。
少なくとも以下をサポートすることを想定してください:
「アクセス」リクエストも、特定の期間や製品に限定したものから「すべて」のような広範なものまで幅があります。
実用的な最小ワークフローは次の通りです:
これらのステップをエンドツーエンドで完遂できないと、期限遵守が難しくなります。
コンプライアンスと運用の健全性を反映する計測可能なKPIを使ってください。例:
週次で追って改善につなげてください。
多くのチームは次のように分けます:
これらの体験を分離するとRBACや監査、将来の方針変更が容易になります。
複数の方法を提供し、リスクに応じて厳格化するのが良いです:
何を確認したかをログに残し、証拠は安全に保管し、保持期間を定めて削除してください。
個人データがどこにあるかを把握するための“生きた”システムインベントリを作ってからコネクタを構築してください。主な候補:
各システムについて、所有者、目的、保存しているデータカテゴリ、利用可能な識別子(メール、ユーザーID、デバイスID)、アクセス方法(API/SQL/エクスポート)、制約(レート制限、保持)を記録してください。
信頼性とスコープされたクエリを優先します:
コネクタはアプリの他部分から分離し、結果を一貫したスキーマに正規化し、プロベナンス(出所、タイムスタンプ、マッチ方法と信頼度)を保存することで、結果の正当性を担保します。
高信頼の識別子から始め、低信頼識別子は慎重に扱うマッチ戦略を使ってください:
過剰収集を防ぐため、まず“存在するか”の軽量チェックを行い、確認されたマッチに対してのみフルレコードを取得する二段階フローが実務的です。
レビューは多くの組織で必須です:
配布物は人間向けレポート(HTML/PDF)と機械可読エクスポート(JSON/CSV)を両方生成し、メール添付ではなく時限付きの安全なダウンロードリンクを使って提供してください。