2025年10月24日·1 分
なぜデータベースインデックスが最も重要なパフォーマンス向上なのか
データベースインデックスがクエリ時間をどう削減するか、いつ役立ち(あるいは害になるか)、実運用でインデックスを設計・検証・保守する実践的手順を解説します。
データベースインデックスがクエリ時間をどう削減するか、いつ役立ち(あるいは害になるか)、実運用でインデックスを設計・検証・保守する実践的手順を解説します。
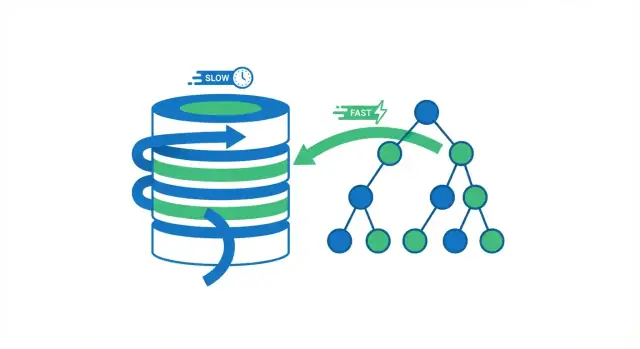
データベースインデックスは、データベースが行をより速く見つけるための別個の検索用構造です。テーブルの二重コピーではありません。本の巻末索引のページを想像してみてください:索引を使っておおよその場所にジャンプし、そこから正確なページ(行)を読みます。
インデックスがないと、データベースはしばしば唯一の安全な選択肢しか持ちません:多数の行を読みながら条件に合うかをチェックすることです。これはテーブルが数千行のときは問題になりませんが、数百万行に増えると「より多くの行をチェックする」ことはより多くのディスク読み取り、メモリの圧迫、CPU作業につながります—その結果、以前は瞬時だったクエリが遅く感じられるようになります。
インデックスは、ID=123 の注文を探す、あるいは特定のメールを持つユーザーを取得する、のような問いに対してデータベースが調べる必要のあるデータ量を減らします。すべてを走査する代わりに、コンパクトな検索用構造を参照して探索範囲を素早く狭めます。
しかし、インデックスが万能の解決策というわけではありません。広範なレポート、選択性の低いフィルタ、重い集計など、まだ多くの行を処理する必要があるクエリも存在します。さらにインデックスには実際のコストがあります:追加のストレージと、挿入や更新時にインデックスも更新するための書き込み遅延です。
この記事では以下を説明します:
データベースがクエリを実行するとき、広く分けて2つの選択肢があります:テーブル全体を行ごとに走査するか、マッチする行に直接ジャンプするか。ほとんどのインデックスによる勝利は不要な読み取りを避けることから生まれます。
フルテーブルスキャンはその名の通り:データベースがすべての行を読み、WHERE条件に合うかを確かめてから結果を返します。小さいテーブルでは許容されますが、テーブルが大きくなるに従って遅くなるのは予測可能です—行が増えれば作業も増えます。
インデックスを使うと、データベースは多くの行を読むのを避けられることが多いです。まず検索用に作られたコンパクトな構造(インデックス)を参照し、マッチする行がどこにあるかを見つけてから、その特定の行だけを読みます。
本を思い浮かべてください。「光合成」を含むすべてのページを探したければ、本を最初から最後まで読む(フルスキャン)こともできます。あるいは索引を使って該当ページにジャンプし、そこだけを読む(インデックス検索)。後者の方が速いのは、ほとんどのページをスキップできるからです。
データベースは特にデータがメモリにない場合、読み取り待ちに多くの時間を費やします。触る行(ページ)を減らせば通常、以下が減ります:
インデックスはデータが大きく、クエリパターンが選択的なとき(例:1000万行から20行を取得するような場合)に最も効果を発揮します。もしクエリがたいていテーブルの大部分を返すか、テーブルが十分小さくメモリに収まるなら、フルスキャンの方が同等かむしろ速いことがあります。
インデックスは値を整理することで、データベースがすべての行を確認する代わりに目的に近い場所へジャンプできるようにします。
SQLデータベースで最も一般的なインデックス構造はBツリー(B-tree、B+treeとも表記)です。概念的には:
ソートされているため、Bツリーは等価検索(WHERE email = ...)や範囲検索(WHERE created_at >= ... AND created_at < ...)の両方に向いています。データベースは目的の値の近傍に移動して、そのまま前方に読み進められます。
Bツリー検索が“対数的”と呼ばれるのは、テーブルが数千から数百万に増えても、検索に必要なステップ数が緩やかにしか増えないからです。
「データが2倍で作業が2倍」ではなく、「データが何倍にも増えてもナビゲーションレベルが少し増えるだけ」で済む、と考えると分かりやすいです。
一部のエンジンはハッシュインデックスも提供します。値をハッシュに変換して直接エントリを見つけるため、等価検索では非常に高速なことがあります。
トレードオフとして、ハッシュは通常範囲検索や順序付きスキャンには役立たず、利用可否や挙動はデータベースに依存します。
PostgreSQL、MySQL/InnoDB、SQL Serverなどはインデックスの格納方法(ページサイズ、クラスタリング、includeカラム、可視性チェック)で差がありますが、基本コンセプトは共通です:インデックスはコンパクトでたどれる構造を作り、テーブル全体を走査するよりずっと少ない作業でマッチする行を見つけます。
インデックスは「SQL全体を速くする」わけではなく、フィルタ、結合、ソートの方法に合ったアクセスパターンを速くします。インデックスがあなたのクエリのフィルタや結合、ソートを反映していれば、データベースは関連する行に直接ジャンプできます。
大きなテーブルを小さな行セットに絞れるクエリには通常インデックスが有効です。ユーザーを識別子で検索するのが典型例です。
users.email にインデックスがなければ、データベースは全行を走査する必要があります:
SELECT * FROM users WHERE email = '[email protected]';
email にインデックスがあれば、該当する行を素早く見つけて処理を終えられます。
結合は「小さな非効率」が大きなコストになる場面です。orders.user_id を users.id と結合するなら、結合列にインデックスがあると、繰り返しの走査を避けられます(通常 users.id は主キーでインデックス済みです)。
大量の行を集めてからソートするのは高コストです。たとえば:
SELECT * FROM orders WHERE user_id = 42 ORDER BY created_at DESC;
user_id とソート列に合うインデックスがあれば、エンジンは必要な順序で行を読み取れて、大きな中間ソートを回避できます。
グルーピングは、データをグループ化された順序で読めると労力を減らせます。必ずしも保証ではありませんが、よく使うグループ列がフィルタと組み合わさっている場合などに恩恵があります。
Bツリーは日付、価格、BETWEEN系などの範囲条件に強いです:
SELECT * FROM orders
WHERE created_at >= '2025-01-01' AND created_at < '2025-02-01';
ダッシュボード、レポート、「最近のアクティビティ」などでこのパターンは頻出し、範囲列へのインデックスは即効性のある改善をもたらすことが多いです。
要点は単純です:クエリの検索やソートのやり方がインデックスと合っていれば、データベースは広い走査の代わりに狙いを定めた読み取りができます。
インデックスが役立つのは、検索対象の行数を大きく減らせるときです。この特性を選択性と呼びます。
選択性とは簡単に言えば「ある値にどれだけの行がマッチするか」です。高選択性の列は多くの異なる値を持ち、各検索が少数行にマッチします。
email、user_id、order_number(一意またはほぼ一意)is_active、is_deleted、値が少ないstatus高選択性ならインデックスは少数の行に飛べますが、低選択性だとインデックスが大きなテーブル領域を指すため、結局多くの行を読む必要が出ます。
例:10百万行のテーブルで is_deleted が 98% false の場合、
SELECT * FROM orders WHERE is_deleted = false;
はほとんどテーブル全体にマッチします。インデックスを使うと、インデックスエントリとテーブルページを行き来する追加作業のためにシーケンシャルスキャンより遅くなることさえあります。
クエリプランナはコストを見積もります。インデックスが十分に作業を減らさない(多くの行がマッチする、クエリがほとんどの列を必要とする、など)場合、フルスキャンを選ぶことがあります。
データ分布は固定ではありません。ある列の値の偏りが時間で変わると、統計が古いままではプランナの推定が大きく外れ、かつて有効だったインデックスが効果を失うことがあります。
単一列インデックスは出発点として良いですが、多くの実クエリは1列でフィルタし別の列でソートしたりします。そうした場合、複合(マルチカラム)インデックスが1つで複数の役割を果たせます。
多くのデータベース(特にBツリー)は複合インデックスを左端の列から順にしか効率的に使えません。インデックスはまず列Aでソートされ、次に列Bでソートされる、というイメージです。
つまり:
account_id で絞ってから created_at で絞ったりソートしたりするクエリに最適created_at のみでフィルタするクエリには通常役に立たない(左端でないため)“このアカウントの最新イベントを表示”という典型クエリ:
SELECT id, created_at, type
FROM events
WHERE account_id = ?
ORDER BY created_at DESC
LIMIT 50;
は次のようなインデックスで大きな改善を得やすいです:
CREATE INDEX events_account_created_at
ON events (account_id, created_at);
データベースはインデックス内の1アカウント部分に直接ジャンプし、時間順に行を読み取れます。大きな集合をスキャンしてからソートする必要はありません。
カバリングインデックスはクエリが必要とするすべての列を含むため、テーブル行を参照せずにインデックスだけで結果を返せます(読み取りが少なくて済む)。
注意点:余分な列を追加するとインデックスが巨大になりコスト増です。
幅の広い複合インデックスは書き込みを遅くし、ストレージを大量に消費します。特定の高価値クエリのためだけに追加し、EXPLAINと実測で必ず検証してから本番に展開してください。
インデックスは「無料の速度」ではありません。インデックス構造は基礎テーブルが変わるたびに維持され、実際のリソースを消費します。
INSERT時、データベースは行を書くだけでなく、そのテーブルの各インデックスに対応するエントリも挿入します。同様にDELETEや多くのUPDATEでもインデックスを更新します。
そのためインデックスが多いと書き込み負荷の高いワークロードで明確に遅延が生じます。特にインデックス付き列を更新するUPDATEは、古いインデックスエントリを削除して新しいものを追加するため高コストになり得ます。
各インデックスはディスクスペースを必要とします。大きなテーブルではインデックスがテーブル本体と同じかそれ以上のサイズになることもあります。
キャッシュ(バッファプール)にも影響があります。作業セットに複数の大きなインデックスが含まれると、キャッシュはより多くのページを保持する必要があり、そうでないとディスクI/Oが増えて性能が不安定になります。
インデックス化は“どこを速くするか”を選ぶ作業です。読み取りが主体のワークロードならインデックスを増やす価値があります。書き込みが多いなら、最重要クエリをサポートするインデックスに絞り、重複するものを避けます。経験則として:そのインデックスが助ける「具体的なクエリ」を1つ言えるときだけ追加し、読み取りの改善が書き込みと保守のコストを上回るか検証してください。
インデックスを追加すれば助かるはず、というのは見かけ上の期待に過ぎません。実際に検証するには、クエリプラン(EXPLAIN)と変更前後の実測が不可欠です。
対象のクエリで EXPLAIN(あるいは EXPLAIN ANALYZE)を実行します。
EXPLAIN ANALYZE):プランが100行を推定したのに実際は100,000行触っているなら、オプティマイザの見積りが誤っていることを示します(統計が古いか選択性の見積りが甘い)。ORDER BYに合致するインデックスを追加すると、このソートが消えて大きな改善になることがあります。同じパラメータ、実運用に近いデータサイズでクエリをベンチマークし、レイテンシと読み取った行数、CPU/IOの影響を記録します。
キャッシュに注意:最初の実行はデータがメモリにないため遅く、繰り返し実行するとキャッシュの効果で速く見えることがあります。複数回の実行を比較し、プランが実際に変わったか(インデックス利用や読み取り行数の減少)を重視してください。
EXPLAIN ANALYZEで読み取り行数や高コストステップ(ソートなど)が減っていれば、インデックスが有効だったと証明できます。
“正しい”インデックスを追加しても、クエリの書き方がインデックスの使用を妨げると効果が出ません。クエリは正しい結果を返しても、遅いプランが選ばれることがあります。
WHERE name LIKE '%term'
のように書くと、通常のBツリーインデックスは使用できません。なぜなら「%term」がソート順のどこから始まるか判らないからです。多くの場合大量の行を走査する羽目になります。
代替案:
WHERE name LIKE 'term%' を使うWHERE LOWER(email) = '[email protected]'
のように書くと、email に対する通常のインデックスが直接使えなくなります。
代替案:
WHERE email = ... とするLOWER(email) 用の式インデックス(関数ベースインデックス)を作るLIKE '%x')?LOWER(col)、DATE(col)、CAST(col))?EXPLAINで実際のプランを確認したか?インデックスは「作って終わり」ではありません。データやクエリパターンが変わるにつれてテーブルやインデックスの物理形状が変化し、適切なインデックスが徐々に効果を失ったり害になることがあります。
ほとんどのデータベースはクエリプラン(オプティマイザ)に統計情報—値の分布、行数、偏りの要約—を与えてプラン選択を行います。
統計が古いと、プランナの行数推定が大きく外れ、非効率なプラン(想定よりずっと多くの行を触るインデックス利用や、インデックスを使わない選択など)につながります。
対策:定期的な統計更新(ANALYZE等)をスケジュールし、大量ロードや大幅な削除後は早めに更新する。
挿入・更新・削除を繰り返すと、インデックスにボリューム(無駄領域)や断片化が生じ、インデックスが大きくなり範囲検索等でのI/Oが増えます。
対策:使用頻度の高いインデックスが異常に大きくなったり性能が劣化したら、定期的に再構築または再編成を行う。ただし手順や影響はDBごとに異なるので、計画的に実行すること。
以下を監視しておくと良いです:
このフィードバックループがあれば、保守が必要なタイミングやインデックスを調整・削除すべきタイミングを見逃しにくくなります。改善の検証方法については /blog/how-to-prove-an-index-helps-explain-and-measurements を参照してください。
インデックス追加は推測ではなく意図的な変更であるべきです。軽量なワークフローで測定可能な改善に集中し、「インデックスの増殖」を防ぎます。
スロークエリログ、APMトレース、ユーザーレポートなどの証拠から始めます。遅く頻繁に実行されるクエリを1つ選びます—稀に10秒かかるレポートより、頻繁に200msかかるルックアップの方が優先度が高いことが多いです。
実行される正確なSQLとパラメータパターンを記録してください(小さな差で適切なインデックスが変わることがあります)。
現在のレイテンシ(p50/p95)、スキャンした行数、CPU/IO影響を記録します。現在のプラン(EXPLAIN / EXPLAIN ANALYZE)も保存して比較できるようにします。
クエリのフィルタやソートに合う最小限の列を選びます。テストはステージング環境で、可能な限り本番に近いデータ量で行ってください。小規模データで良く見えてもスケールすると期待外れになることがあります。
大きなテーブルではオンラインオプション(PostgreSQLの CREATE INDEX CONCURRENTLY 等)を使い、書き込みをロックする可能性がある場合は低トラフィック時間に実行します。
同じクエリを再実行して比較します:
インデックスが書き込みコストを増やしたりメモリを圧迫する場合は、きれいに削除できるようにします(可能なら DROP INDEX CONCURRENTLY のような安全な方法を用意する)。マイグレーションは可逆的にしておきます。
マイグレーションやスキーマノートに、そのインデックスがどのクエリを支援しどの指標が改善したかを書き残しておきます。将来のあなたや同僚が「なぜ存在するのか」を理解しやすくなります。
新しいサービスを作る際に早期の「インデックススプロール」を避けたいなら、Koder.ai はこのループ(クエリ診断→最小インデックス設計→マイグレーション)を速く回す手助けをします:React + Go + PostgreSQL のアプリをチャットから生成し、スキーマやインデックスのマイグレーションを要件の変化に合わせて調整し、準備ができたらソースをエクスポートして手動で引き継げます。実務では「このエンドポイントが遅い」→「EXPLAINプラン、最小限インデックス、可逆マイグレーション」の一連を待ち時間なく進められる利点があります。
インデックスは強力なレバーですが、すべてを速くする魔法ではありません。しばしばリクエストの遅さは、データベースが正しい行を見つけた後に発生します。あるいはクエリの性質上、インデックスが最適な第一手ではないこともあります。
クエリが良いインデックスを使っているのにまだ遅い場合、以下を疑ってください:
OFFSET を大きく使う(例:ページ1000)とインデックスがあっても遅い。キーセットページネーション(前回のid/タイムスタンプ以降を取得)を検討する。SELECT * や数万件のレコードを返すとネットワークやJSONシリアライズ、アプリ処理がボトルネックになる。これらは /blog/how-to-prove-an-index-helps と組み合わせるとボトルネック診断に有効です。
推測で動かないでください。時間がどこに使われているか(データベース実行時間 vs. 返される行の数 vs. アプリコード)を計測して判断します。データベースが十分に速くてAPIが遅いなら、インデックスを増やしても意味がありません。
データベースのインデックスは、選択した列の値を検索しやすく整列して格納し、テーブル行へのポインタを持つ別のデータ構造(多くはBツリー)です。データベースはそれを使って、選択的なクエリで「テーブルのほとんどを読む」のを避けます。
テーブルの完全なコピーではありませんが、いくつかの列データとメタ情報を複製するため、追加のストレージを消費します。
インデックスがないと、データベースはWHERE句に合致するかを確かめるために多く(または全て)の行を走査する必要があり、これをフルテーブルスキャンと呼びます。
インデックスを使えば、マッチする行の位置に直接ジャンプして、その行だけを読み取れることが多く、ディスクI/O、CPUによるフィルタ処理、キャッシュの負荷が大きく減ります。
Bツリーは値をソートしてページ(チャンク)に分け、ページ同士がポインタでつながった構造を持ちます。データベースはこれをたどって目的の“近傍”に素早く到達できます。
そのためBツリーは以下に向いています:
WHERE email = ...)WHERE created_at >= ... AND created_at < ...)ハッシュインデックスは、値をハッシュしてバケットに直接ジャンプするため、等価検索(=)では非常に高速です。
トレードオフ:
多くの実運用では、より多用途なBツリーがデフォルトとして選ばれます。
インデックスは特定のアクセスパターンを速くします。特に効果的なのは:
WHEREフィルタJOINの結合キー(外部キーなど)ORDER BYがインデックス順と合致する場合(ソートを回避)GROUP BYがインデックス順と整合する場合(ケースによる)逆にクエリがテーブルの大部分を返すなら、効果は小さいです。
選択性(selectivity)は、ある値に対してどれだけ少ない行がマッチするかを表す概念です。多くの異なる値を持ち、各値が少数行にしかマッチしない列は高選択性です。
email、user_id、order_numberis_active、is_deleted、値が少ないstatus低選択性の列に対するインデックスは、大きなテーブルでは効果が乏しく、インデックス利用が逆に遅くなることすらあります。
オプティマイザはコストを見積もり、インデックスを使っても作業量が十分に減らないと判断すれば無視します。
典型的な理由:
EXPLAINで実際のプランを確認するのが重要です。
ほとんどのBツリー実装では、インデックスは最初の列でまずソートされ、その次に二番目の列でソートされる、という「左から右」の順序で使えます。
例:
(account_id, created_at) は WHERE account_id = ? のようなフィルタ+時間のソートに有効created_at だけを使うクエリには通常役に立ちません(左端でないため)カバリングインデックスは、クエリが必要とするすべての列をインデックスが含むため、テーブル行を参照せずにインデックスだけで結果を返せます。
メリット:
コスト:
高価値な特定クエリに対してのみ使うべきです。
次の2点を確認します:
EXPLAIN / EXPLAIN ANALYZE で Seq Scan → Index Scan/Seek に変わったか、読み取る行数やソート手順が減ったかを確認する。さらに、新しいインデックスが書き込み性能に与える影響(INSERT/UPDATE/DELETEの遅延)も監視してください。