2025年10月18日·1 分
データのインポート・エクスポートと検証のためのウェブアプリを構築する方法
CSV/Excel/JSONの入出力、分かりやすい検証エラー、ロール管理、監査ログ、信頼できる処理を備えたウェブアプリの設計方法を学ぶ。
CSV/Excel/JSONの入出力、分かりやすい検証エラー、ロール管理、監査ログ、信頼できる処理を備えたウェブアプリの設計方法を学ぶ。
画面やファイルパーサーを選ぶ前に、誰が製品のデータを出し入れするのか、そしてなぜを具体化してください。内部オペレーター向けのデータインポートは、顧客がセルフで使うExcelインポートツールとは大きく異なります。
インポート/エクスポートに関わる役割を列挙します:
各ロールについて、期待されるスキルレベルと複雑さへの許容度を定義してください。顧客向けは通常、選択肢を減らし、より充実したインプロダクト説明を用意する必要があります。
主要なシナリオを書き出し、優先順位を付けます。よくある例:
成功指標を定義しましょう。例:失敗したインポートの減少、エラー対応時間の短縮、 "ファイルがアップロードできない" に関するサポートチケットの減少。これらは後のトレードオフ(明確なエラーレポートへの投資 vs. 対応可能なファイルフォーマットの増加)に役立ちます。
初日で何をサポートするか明確にします:
最後に、PIIを含むか、保存期間、監査要件(誰が、いつ、何をインポートしたか)などのコンプライアンス要件を早めに特定してください。これらはストレージ、ログ、権限に影響します。
列挙型のマッピングUIやCSV検証ルールを考える前に、チームが確実に運用・デリバリーできるアーキテクチャを選んでください。インポート/エクスポートは「地味な」インフラなので、反復の速さとデバッグしやすさが革新性より重要です。
一般的なウェブスタックで十分運用できます。選択は既存スキルと採用事情に基づいて:
重要なのは一貫性です。新しいインポートタイプ、検証ルール、エクスポート形式を追加する際に書き直しが発生しないスタックを選んでください。
ワンオフのプロトタイプを避けつつスキャフォールディングを加速したい場合、Koder.ai のようなビブコーディングプラットフォームが役立ちます。チャットでインポートフロー(アップロード→プレビュー→マッピング→検証→バックグラウンド処理→履歴)を説明すると、React UI+Go + PostgreSQLバックエンドのコードを生成し、プランニングモードやスナップショット/ロールバックで素早く反復できます。
構造化レコード、アップサート、データ変更の監査ログにはリレーショナルDB(Postgres/MySQL)を使います。
オリジナルのアップロード(CSV/Excel)はオブジェクトストレージ(S3/GCS/Azure Blob)に保存してください。生ファイルを保管することでサポートが容易になり、パースの再現やジョブの再実行、エラー判定の説明が可能になります。
小さなファイルは同期処理(upload → validate → apply)でスナッピーなUXを提供できます。大きなファイルはバックグラウンドジョブへ移行します:
これによりリトライやレート制御が容易になります。
SaaSを作るなら、テナントデータの分離方法(行レベルスコープ、スキーマ分割、DB分割)を早期に決めてください。これはデータエクスポートAPI、権限、パフォーマンスに影響します。
稼働率、最大ファイルサイズ、インポートあたりの想定行数、完了時間、コスト上限などを数値化しておくと、ジョブキュー選定、バッチ戦略、インデックス設計に役立ちます。
受け付けフローはインポートのトーンを決めます。予測可能かつ寛容に感じられれば、ユーザーは問題が起きても再挑戦しますし、サポート件数も減ります。
Web UIにはドラッグ&ドロップと従来のファイルピッカーの両方を提供しましょう。ドラッグは上級者向けに高速で、ファイルピッカーはアクセシビリティと慣れの面で重要です。
他システムからの取り込みニーズがある場合はAPIエンドポイントも用意します。multipart(ファイル+メタデータ)や、より大きなファイル向けには事前署名URLフローをサポートすると良いです。
アップロード時に軽量なパースを行い、データを確定せずに「プレビュー」を作成します:
このプレビューが後の列マッピングや検証の基盤になります。
元のファイルは常に安全に保存(オブジェクトストレージ)し、不変で保持してください。そうすると:
各アップロードをファーストクラスのレコードとして扱ってください。保存するメタ情報例:アップローダー、タイムスタンプ、ソースシステム、ファイル名、チェックサム(重複検出と整合性確認用)。これは監査性とデバッグに有用です。
高速な事前チェックを即座に行い、本当におかしいファイルは早期に弾きます:
事前チェックで失敗した場合は、明確なメッセージと修正点を示してください。重要なのは、マッピングやクレンジングで直せる妥当なデータを不必要に拒否しないことです。
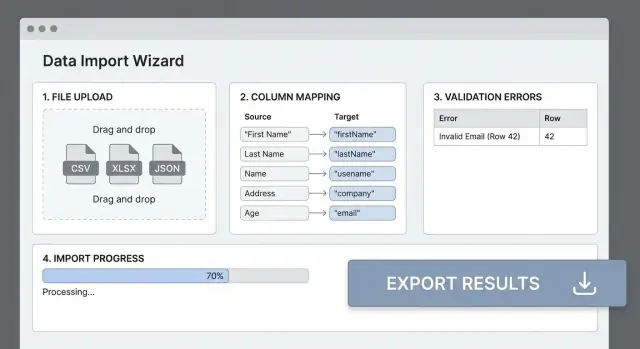
多くのインポート失敗はファイルのヘッダーがアプリ側のフィールドと一致しないことが原因です。明確な列マッピング工程は「汚いCSV」を予測可能な入力に変え、ユーザーの試行錯誤を減らします。
シンプルな表:ソース列 → 宛先フィールド を表示します。可能な一致は自動検出(大文字小文字非区別、同義語)してユーザーが上書きできます。
QOL向上のために:
顧客が毎週同じフォーマットを取り込むなら、ワンクリックで済ませられるようにします。テンプレートのスコープ例:
新しいファイルがアップロードされたときは列の重なりでテンプレートを提案し、バージョン管理をサポートして古い実行を壊さないようにします。
各マッピングフィールドに適用できる軽量な変換を提供します:
UIで変換を明示的に表示(「適用:Trim → Parse Date」)し、出力が説明可能であることを担保してください。
全ファイル処理の前に(例えば)20行のマッピング後のプレビューを表示します。元の値、変換後の値、警告(例:「日付を解析できませんでした」)を表示してユーザーが早期に問題を発見できるようにします。
ユーザーにキー字段(email、external_id、SKU 等)を選ばせ、重複時の挙動を説明します。アップサートを後で扱う場合でも、このステップで期待値を設定できます:ファイル内の重複キーに対してどのレコードが勝つか(先頭、末尾、エラー)を示すなど。
検証は単なる「ファイルアップローダー」と「信頼できるインポート機能」を分ける要素です。目的は厳格さそのものではなく、悪いデータの拡散を防ぎ、ユーザーに明確で実行可能なフィードバックを与えることです。
検証を3つのチェックに分けて扱います:
emailは文字列か?amountは数値か?customer_idが存在するか? これはパース直後に高速で実行できます。amountは正であること、statusは許可された値のいずれかであること、などプロダクトの振る舞いを反映するルール。country=USならstate必須、end_dateはstart_dateより後、プラン名がワークスペース内に存在すること、など。他の列やDB参照が必要になることが多いです。これらを分離すると拡張やUIでの説明がしやすくなります。
インポートを次のいずれにするかを早めに決めます:
両方サポートすることも可能です:デフォルトはstrict、管理者向けに「部分インポートを許可」オプションを提供するなど。
すべてのエラーは「何が起きたか、どこで、どう直すか」を答えるべきです。
例:「Row 42, Column ‘Start Date’: must be a valid date in YYYY-MM-DD format.」
区別する点:
ユーザーは一度で全てを直すことは稀です。検証結果をインポート試行に紐づけたままにして、修正済みファイルを再アップロードしやすくしてください。エラーレポートのダウンロード機能(後述)と組み合わせると大量修正が楽になります。
実用的なアプローチはハイブリッドです:
これにより柔軟性を保ちつつ、設定迷宮にならないようにします。
インポートの失敗は往々にして退屈な原因(遅いDB、ピーク時のファイルスパイク、単一の壊れた行)が多いです。信頼性は重い作業をリクエスト/レスポンスパスから外し、各ステップを何度でも安全に実行できるようにすることにあります。
パース、検証、書き込みをキュー/ワーカーで処理してウェブのタイムアウトを回避します。これにより、顧客がより大きなスプレッドシートを取り込む際にワーカーを独立してスケールできます。
実用的なパターン:作業をチャンクに分割(例:1,000行/ジョブ)。親インポートジョブがチャンクジョブをスケジュールし、結果を集約して進捗を更新します。
インポートを状態機械としてモデル化し、UIや運用チームが常に状況を把握できるようにします:
各遷移にタイムスタンプと試行回数を保存し、「いつ開始したか」「リトライは何回か」の回答をログなしで提供できるようにします。
処理済み行数、残行数、現時点でのエラー数などの測定可能な進捗を表示してください。スループットが見積もれるなら概算ETA(「約3分」など)を出すと良いですが、正確なカウントダウンは避ける方がよいです。
リトライで重複や二重適用が起きないように:
import_id と row_number(または行ハッシュ)を冪等キーとして使うワークスペースごとの同時インポート数制限や、書き込み集約部分の秒間行数制限(max N rows/sec)を設定して、DBへの過負荷を防ぎ、他ユーザー体験を守ります。
原因が分からないとユーザーは同じファイルを何度も送ってしまいます。各インポートをファーストクラスの「実行」として扱い、明確なトレースと実用的なエラーを提供してください。
ファイル提出の時点で import run エンティティを作成します。このレコードには次を含めます:
これがインポート履歴画面になります:実行のリスト、ステータス、カウント、詳細ビューに遷移できるようにします。
アプリケーションログはエンジニアに便利ですが、ユーザーはクエリ可能なエラーを必要とします。エラーは構造化してインポート実行へ紐づけて保存します:
この構造により「今週の上位3つのエラータイプ」などの集計が簡単になります。
実行詳細ページで列/タイプ/重大度でフィルタできるようにし、検索ボックス(例:"email")を提供します。また、元の行に error_columns と error_message を付けたCSVエラーレポートのダウンロードを提供し、"日付をYYYY-MM-DDに直してください" のような明確なガイダンスを添えてください。
dry run は同じマッピングとルールで全検証を行うが書き込みは行わないモードです。初回インポートに最適で、安全に反復できます。
行がDBに入って「完了」したように見えても、長期的なコストは混乱した更新、重複、不明瞭な変更履歴に現れます。ここではインポートを予測可能、可逆、説明可能にするデータモデル設計について述べます。
取り込んだ行がドメインモデルのどの操作になるかを定義します。各エンティティごとに、インポートが:
この挙動はインポート設定UIで明示し、インポートジョブに保存して再現性を担保してください。
「作成または更新」をサポートするなら安定したアップサートキーが必要です。一般的な選択:
external_id(他システム由来ならベスト)account_id + sku)衝突処理ルールを定義します:同じキーを持つ2行がある場合、キーが複数レコードにマッチした場合の挙動。デフォルトは「行を失敗させる(明確なエラー)」か「最後の行が勝つ」など、意図的に選んでください。
一貫性が必要な箇所ではトランザクションを使います(親と子の同時生成など)。しかし200k行の巨大トランザクションはテーブルロックを引き起こし、リトライを難しくします。チャンク書き込み(500〜2,000行)+冪等アップサートを好んで使ってください。
行が親レコードを参照する場合(Companyなど)、参照先が存在することを要求するか、制御されたステップで作成するかを決めてください。早期に「親がない」エラーで失敗させると半端な接続データを防げます。
インポート駆動の変更については監査ログを追加してください:誰がインポートを起こしたか、いつ、ソースファイル、各レコードの変更サマリ(旧値 vs 新値)。これによりサポートが楽になり、信頼構築やロールバックが容易になります。
エクスポートは一見シンプルですが、顧客が締切直前に「全部ちょうだい」と言ってくると問題になります。スケーラブルなエクスポートは大規模データを処理しつつアプリを遅くしない設計が必要です。
まずは次の3タイプを用意してください:
増分エクスポートは統合に特に有用で、フルダンプの繰り返しを減らします。
どれを選んでも、一貫したヘッダーと安定した列順を保ち、下流処理が壊れないようにしてください。
大きなエクスポートで全行をメモリに読み込まないでください。フェッチしながら書き出すストリーミング/ページングを使ってタイムアウトとメモリ不足を防ぎます。
大規模データの場合はバックグラウンドジョブでファイルを生成し、準備完了時にユーザーに通知するパターンが有効です。一般的な流れ:
インポート用のバックグラウンドジョブと同じ「実行履歴+ダウンロード可能成果物」パターンと相性が良いです。
エクスポートは監査対象になりやすいので常に:
これらで混乱を減らし、調整可能な照合がしやすくなります。
インポート/エクスポートは大量データをすばやく移動できる分、セキュリティバグの温床になり得ます:過度に緩い役割、リークしたファイルURL、機密データを含むログの一行など。
アプリ全体で使っている認証方式を流用してください。インポート専用の特別な認証経路を作らないこと。
ブラウザ利用が主ならセッションベース+SSO/SAMLが一般的。自動化や外部統合が中心ならAPIキーやOAuthトークンをスコープと回転方針と共に提供します。
実用的なルール:インポートUIとインポートAPIは異なる利用者でも同じ権限チェックを強制すること。
インポート/エクスポート機能を明示的な権限として扱います。一般的な権限:
「ファイルをダウンロードできるか」を別権限にすることを強く推奨します。多くのリークは誰かが実行結果を参照できるのにファイルダウンロード権限を持っていないケースで起きます。
また行レベルやテナントレベルの境界も考慮:ユーザーは所属するアカウント/ワークスペースのデータのみ操作できるべきです。
保存ファイル(アップロード、生成されたエラCSV、エクスポートアーカイブ)はプライベートなオブジェクトストレージと短寿命リンクを使って保護します。必要に応じて暗号化(保存時)を行い、元ファイル、処理中のステージングファイル、生成レポートは一貫した扱いにしてください。
ログにも注意。機密フィールド(メール、電話、ID、住所)は赤丸でマスクし、デフォルトで生データをログに出さないでください。詳しいデバッグが必要な場合は管理者限定設定で「詳細行ログ」を有効化し、有効期限付きで残すようにしてください。
すべてのアップロードは不信な入力として扱います:
構造が明らかに壊れているファイルはバックグラウンドジョブに渡す前に弾き、ユーザーに明確な修正点を提示してください。
調査時に必要なイベントを記録します:誰がファイルをアップロードしたか、誰がインポートを開始したか、誰がエクスポートをダウンロードしたか、権限変更、アクセス失敗など。
監査エントリはアクター、タイムスタンプ、ワークスペース/テナント、対象オブジェクト(import run ID、export ID)を含めますが、機密な行データは保存しないでください。インポート履歴UIと組み合わせると「誰がいつ何をしたか?」に素早く答えられます。
インポート/エクスポートが顧客データに触れるなら、やがてエッジケース(奇妙なエンコーディング、結合セル、半分埋まった行、重複、昨日は動いたのに今日は動かない)に直面します。運用性はそれらがサポート地獄にならないようにする仕組みです。
パース、マッピング、検証が最も故障しやすい部分なので重点的にテストします:
その上で少なくとも1つのエンドツーエンドテストを追加:アップロード → バックグラウンド処理 → レポート生成。これによりUI、API、ワーカー間の契約不一致を検出できます。
ユーザー影響のある指標を監視します:
アラートは例外の全てではなく、ユーザー影響のある症状(失敗率の上昇、キュー深度の増加)に紐づけてください。
内部チーム向けに小さな管理UIを用意し、ジョブの再実行、停止、失敗原因の検査(入力ファイルのメタデータ、使用マッピング、エラーサマリ、ログ/トレースへのリンク)を可能にしてください。
ユーザー向けには、インラインヒント、ダウンロード可能なサンプルテンプレート、エラー画面での次の手順を明確に示すことで防げるエラーを減らします。中央のヘルプページを用意し、インポートUIからリンクしてください(例:/docs)。
インポート/エクスポート機能は単に「本番へプッシュ」するだけでなく、デフォルトを安全にし、復旧手段を用意し、進化できる余地を残して出荷してください。
dev/staging/prodの分離された環境と、アップロード/生成物用の別々のオブジェクトストレージバケット(またはプレフィックス)を用意します。暗号鍵や資格情報も環境ごとに分け、ワーカープロセスが正しいキューを参照するようにしてください。
ステージングは本番を鏡像するように設定:ジョブの並列度、タイムアウト、ファイルサイズ制限を本番と同じにしてパフォーマンスと権限を検証できるようにします。
インポートは長期間そのまま使われがちなので、データベースマイグレーションに加えてインポートテンプレートにバージョンを持たせる設計をしてください。スキーマ変更が前四半期のCSVを壊さないように互換コードを用意し、古いバージョンのテンプレートは段階的に廃止します。
実践的には、template_version を各インポート実行に保存し、互換性保護コードを一定期間残すのが有効です。
機能フラグで安全に変更を展開します:
フラグにより内部ユーザーや小さな顧客群で先行テストできます。
サポートがインポート失敗を調査するための手順書を用意します:テンプレートバージョンの確認、最初に失敗した行のレビュー、ストレージアクセスの確認、ワーカーログの確認、など。これを内部ルンブックに記載し、管理UIからリンクしてください(例:/admin/imports)。
コアワークフローが安定したら、アップロード以外の導線を拡張します:
これらは手作業を減らし、顧客の既存ワークフローに自然に馴染む体験を提供します。
製品機能として短期間で「最初に使えるバージョン」を出したい場合、Koder.ai を用いてインポートウィザード、ジョブステータス画面、実行履歴画面をエンドツーエンドでプロトタイプし、そのソースを通常のエンジニアリングワークフローへエクスポートする方法は実務的です。初日からUI完璧主義にこだわらず、信頼性と反復速度を優先する場合に特に有効です。
まず、誰がインポート/エクスポートを行うのか(管理者、オペレーター、顧客)と主要なユースケース(オンボーディングの一括取り込み、定期同期、単発エクスポート)を明確にしてください。
初日での制約を書き出します:
これらの決定はアーキテクチャ、UIの複雑さ、サポート負荷に影響します。
ファイルが小さく、検証+書き込みがウェブリクエストのタイムアウト内で確実に終わる場合は同期処理を使います。
以下の場合はバックグラウンドジョブを使ってください:
一般的なパターン:アップロード → キュー登録 → 実行状況/進捗を表示 → 完了時に通知。
両方を保存しておく理由:
生ファイルは不変に保ち、インポート実行レコードに紐づけてください。
コミットする前に見本を出すプレビューを用意し、(例)20〜100行をサンプリングしてヘッダーを検出します。
共通のばらつきに対処しましょう:
読み取れないファイルや必須列の欠落のような本当に阻害する問題は早期に弾く一方で、後でマッピングや変換で対処できるデータは拒否しない方針が良いです。
シンプルなマッピング表を使って「ソース列 → 宛先フィールド」を表示します。
ベストプラクティス:
処理前にマッピングしたプレビューを見せて、ユーザーがミスを早期に発見できるようにしてください。
早期にサポートすべき変換は予測可能で軽量なものです:
ACTIVE)プレビューで「元の値 → 変換後の値」を必ず表示し、変換できない場合は警告を出してください。
検証は層に分けて設計します:
emailは文字列か、amountは数値か)処理をリトライ安全(idempotent)にする方法:
import_id + row_number や行ハッシュ)external_id等)によるアップサートを優先し、常に挿入する方式は避けるさらに、ワークスペースごとの同時インポート制限や書き込みスロットルでDBや他ユーザーを保護してください。
ファイル提出時点で**インポート実行(import run)**レコードを作成し、構造化された問い合わせ可能なエラーを保存してください。
便利なエラー報告機能:
error_columns と error_message を含むCSVエラーレポートのダウンロードこれらは「同じファイルをとにかく再試行する」行動やサポートチケットを減らします。
取り扱うデータ量が多いため、インポート/エクスポートは強力である一方でセキュリティ上の問題になりやすいです。基本方針:
PIIを扱う場合は保持や削除のルールを早めに決めて、不要なファイルをため込まないようにしてください。
country=USstateUIでは「行番号・列名でどこがどう間違っているか」を明確に伝える(例:「Row 42, Start Date: must be YYYY-MM-DD」)。
インポートをファイル全体で失敗させる(strict)か、有効な行だけ受け入れる(lenient)かは早めに決め、管理者向けに両方を選べるようにするのが現実的です。