2025年9月14日·2 分
データ品質チェックとアラートの Web アプリの作り方
データ品質チェックを実行し結果を追跡、オーナーに届くアラート、ログ、ダッシュボードを備えた Web アプリの計画と構築方法を解説します。
データ品質チェックを実行し結果を追跡、オーナーに届くアラート、ログ、ダッシュボードを備えた Web アプリの計画と構築方法を解説します。
何かを作る前に、チームが「データ品質」で実際に何を意味しているかを揃えてください。データ品質監視 のための Web アプリは、保護すべき成果とサポートすべき意思決定にチーム全員が合意している場合にのみ有用です。
多くのチームは複数の次元を混ぜて扱います。重要なものを選び、平易な言葉で定義し、これらの定義をプロダクト要件として扱ってください:
これらの定義は データ検証ルール の基礎となり、アプリがサポートすべき データ品質チェック を決めるのに役立ちます。
不良データのリスクと影響を受ける人を列挙してください。例えば:
こうすることで「興味深い」指標だけを追うツールにならず、実際にビジネスを害する点を見逃さないようにできます。これは Web アプリのアラート 設計にも影響します:適切なメッセージが適切な担当者に届くべきです。
次のどれが必要かを明確にしてください:
期待されるレイテンシ(数分か数時間か)を明確にしてください。その判断はスケジューリング、ストレージ、アラートの緊急度に影響します。
アプリを稼働させた後に「良くなった」と判断する基準を定義します:
これらの指標は データオブザーバビリティ の取り組みを集中させ、単純なルール検証と 異常検知の基本 のどちらを優先するかを助けます。
チェックを作る前に、手元のデータが何か、どこにあるか、何かが壊れたときに誰が直せるかを把握してください。軽量なインベントリを今作っておくと後で数週間の混乱を避けられます。
データが発生または変換されるすべての場所をリストアップします:
各ソースについて、オーナー(個人またはチーム)、Slack/メールの連絡先、期待される更新頻度を記録してください。オーナーが不明確だとアラートも不明確になります。
重要なテーブル/フィールドを選び、それに依存するものを文書化します:
「orders.status → revenue dashboard」のような簡単な依存メモで十分です。
影響度と発生確率に基づいて優先順位を付けます:
これらが初期の監視範囲と最初の成功指標になります。
既に経験した具体的な失敗(サイレントなパイプライン障害、検出の遅さ、コンテキストのないアラート、不明瞭なオーナーシップ等)を文書化し、後述の要件(アラートルーティング、監査ログ、調査ビュー)に変換してください。内部ページ(例: /docs/data-owners)を保持しているなら、アプリからリンクして応答者が迅速に行動できるようにします。
画面設計やコードを書く前に、製品が実行するチェックを決めてください。これがルールエディタ、スケジューリング、性能、アラートの実用性全てを形作ります。
多くのチームは次のコアチェックで即時価値を得ます:
email の null が 2% を超えない」など。order_total は 0〜10,000 の間である」order.customer_id は customers.id に存在する」user_id は日単位でユニークである」初期カタログは明確な意見(opinionated)を持たせ、ニッチなチェックは後から UI を複雑にしない範囲で追加してください。
通常 3 つの選択肢があります:
実用的には「UI ファースト、エスケープハッチを第二」にして、80% はテンプレート/UI で賄い、残りをカスタム SQL に任せるのが良いでしょう。
重大度を意味のある一貫したものにします:
トリガーについても明示します:単発の失敗で上げるのか、「N 回連続失敗でアラート」か、割合ベースの閾値、抑制ウィンドウの有無など。
SQL/スクリプトをサポートするなら、事前に決めておくべき項目:許可する接続、タイムアウト、リードオンリーアクセス、パラメータ化されたクエリ、結果を pass/fail + メトリクス に正規化する方法。これにより柔軟性を保ちつつ、データとプラットフォームを保護できます。
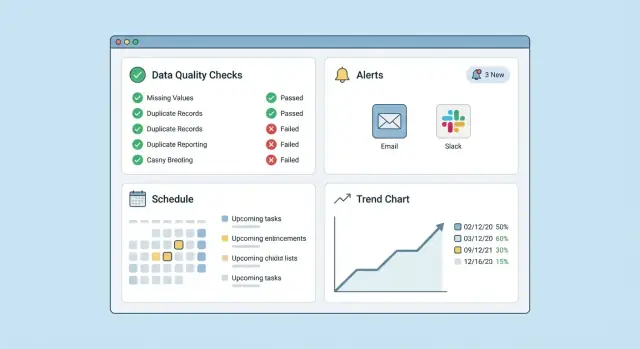
データ品質アプリは、誰かが素早く次の 3 つの質問に答えられるかで成功が決まります:何が失敗したか、なぜ重要か、誰が担当か。ユーザーがログを掘り下げたり暗号的なルール名を解読しなければならないなら、アラートは無視され、ツールへの信頼は失われます。
ライフサイクルを端から端まで支える小さな画面セットから始めます:
主なフローは明白で繰り返しやすくしてください:
チェック作成 → スケジュール/実行 → 結果参照 → 調査 → 解決 → 学習。
「調査」はファーストクラスのアクションとし、失敗した実行からデータセットへジャンプして、失敗した指標/値を見て、過去の実行と比較し、原因に関するメモを残せるようにします。「学習」は改善を促す場所です:閾値調整、補助チェックの追加、あるいは失敗を既知インシデントに紐づける提案などを行います。
最初はロールを最小限に保ちます:
失敗結果ページには必ず表示する:
データ品質アプリは、関心事を分離するとスケールしやすく、デバッグもしやすくなります:ユーザーが見るもの(UI)、設定を変える方法(API)、チェックを実行する(workers)、事実を保存する(storage)を分離します。こうすることで「制御プレーン」(設定と決定)と「データプレーン」(チェックの実行と結果記録)を明確に分けられます。
まずは「何が壊れていて誰が担当か」を答える 1 画面から始めてください。シンプルなフィルタ付きダッシュボードで十分に機能します:
各行から実行詳細ページ(チェック定義、サンプル失敗、最後の正常実行)にドリルダウンできるようにします。
API はアプリが管理するオブジェクト中心に設計します:
書き込みは小さくバリデートし、ID とタイムスタンプを返して UI がポーリングして応答性を保てるようにします。
チェックは Web サーバの外で実行するべきです。scheduler はジョブをエンキューする役割にして、重い処理は行わないようにします。ワーカーは次を実行します:
この設計によりデータセットごとの同時実行制限や安全なリトライを実装できます。
別々のストアを使います:
この分離によりダッシュボードは高速に保て、失敗時には詳細な証拠を残せます。
MVP を素早く出荷したい場合、Koder.ai のような vibe-coding プラットフォームで、React ダッシュボード、Go API、PostgreSQL スキーマを仕様(checks、runs、alerts、RBAC)からブートストラップすることができます。コア CRUD フローと画面を早く作ってからチェックエンジンや統合を固めるのに便利です。Koder.ai はソースエクスポートをサポートするので、生成されたコードを自分のリポジトリで引き続き管理・強化できます。
優れたデータ品質アプリは表面上はシンプルに見えますが、裏側のデータモデルがしっかりしています。目的はすべての結果が説明可能になること:何が実行され、どのデータセットに対し、どのパラメータで、時間経過で何が変わったかを示せるようにすることです。
まず小さな一級オブジェクト群から始めます:
調査のために 生の結果詳細(失敗行のサンプル、問題のある列、クエリ出力の抜粋)を保持しつつ、ダッシュボードやトレンドのために最適化された 要約メトリクス を保持してください。この分離によりチャートは高速に、デバッグ時には詳細な証拠が利用できます。
CheckRun を上書きしないでください。追記型の履歴により監査("火曜日に何を知っていたか")やデバッグ("ルールが変わったのかデータが変わったのか")が可能になります。各実行にはチェックのバージョン/構成ハッシュを記録してください。
Dataset と Check に team、domain、PII フラグ のようなタグを追加します。タグはダッシュボードのフィルタに使え、PII タグ付きデータセットの生サンプルは特定ロールのみ閲覧可能にする等の権限ルールにも活用できます。
実行エンジンはデータ品質監視アプリのランタイムです:いつチェックが走るか、どう安全に実行するか、結果が信頼できるよう何を記録するかを決めます。
まずはカデンツ(cron 風)でチェックをトリガーするスケジューラを用意し、スケジューラ自身が重い作業をしないようにします。キュー(DB やメッセージブローカーに基づく)を使うことで:
チェックはしばしば本番 DB やウェアハウスに対してクエリを打ちます。誤設定のチェックが性能を低下させないようガードレールを設けてください:
また「進行中」状態をキャプチャし、ワーカーがクラッシュ後に放置されたジョブを安全に拾えるようにしてください。
文脈のない pass/fail は信頼されません。各結果に次のコンテキストを保存してください:
これにより数週間後でも「正確に何が実行されたか?」に答えられます。
チェックを有効化する前に次を提供してください:
これらは驚きを減らし、初日からアラートの信頼性を保ちます。
アラートはデータ品質監視が信頼されるか無視されるかの分岐点です。目的は「問題をすべて知らせること」ではなく「次に何をすべきか・どれだけ緊急か」を伝えることです。各アラートが三つの質問に答えるようにしてください:何が壊れたか、どれほど深刻か、誰が担当か。
チェックによって必要なトリガーは異なります。以下の実用的なパターンをサポートしてください:
これらは各チェックで設定可能にし、「先月はこれが 5 回トリガーされていた」といったプレビューを見せて感度を調整できるようにします。
同じインシデントで繰り返し通知されると人はミュートするようになります。次を追加してください:
また状態遷移を追跡し、新規失敗でアラートし、復旧時に(オプションで)通知するようにします。
ルーティングはデータ駆動にします:データセットオーナー、チーム、重大度、または タグ(例:finance、customer-facing)で振り分けます。ルーティングロジックはコードではなく設定で管理してください。
メールと Slack は多くのワークフローをカバーし導入が容易です。アラートペイロードを将来的な webhook に対応しやすく設計し、より深いトリアージのために調査ビューへのリンク(例:/checks/{id}/runs/{runId})を含めてください。
ダッシュボードはデータ品質監視を使えるものにします。目的はきれいなグラフではなく、次の二つの質問に素早く答えられることです:「何か壊れているか?」と「次に何をすべきか?」。
まずはコンパクトな“ヘルス”ビューを用意し、高速に読み込めて注目すべきものを強調してください。
表示すべき項目:
この最初の画面は運用コンソールのように感じられ、クリックを最小限にして一貫したラベルで示すべきです。
失敗したチェックから調査を強力にサポートする詳細ビューを提供し、ユーザーがアプリを離れずに対応できるようにしてください。
含めるべきもの:
可能であればワンクリックで「調査を開く」パネルを出し、runbook やデバッグ用クエリへの相対リンク(例: /runbooks/customer-freshness, /queries/customer_freshness_debug)を含めてください。
失敗は明白ですが緩やかな劣化は見逃されがちです。各データセット/チェックにトレンドタブを追加します:
これらのグラフは異常検知の基本を実務的にします:一時的なものかパターンなのかを人が判断できます。
チャートや表の各点は基になった実行履歴と監査ログにリンクしているべきです。各ポイントに「View run」リンクを提供し、チームが入力、閾値、アラートルーティングの判断を比較できるようにしてください。トレース可能性はデータオブザーバビリティや ETL データ品質ワークフローに対する信頼を築きます。
初期に下したセキュリティ設計は将来システムを単純に運用できるか、常に手戻りが発生するかを左右します。データ品質ツールは本番システム、認証情報、時には規制対象データに触れるため、最初から内部管理者向け製品として扱ってください。
組織に既に SSO があるなら OAuth/SAML をできるだけ早くサポートしてください。それまではメール/パスワードで MVP を始めることは許容されますが、次の基本を守ってください:ソルト付きパスワードハッシュ、レート制限、アカウントロックアウト、MFA。
SSO があっても障害時の“break-glass” 管理者アカウントを安全に保管しておき、使用手順を文書化して制限してください。
"結果の閲覧" と "挙動の変更" を分けます。一般的なロール:
権限は UI だけでなく API 側でも強制してください。さらにワークスペース/プロジェクト単位でスコープを分け、チームが誤って他チームのチェックを編集できないように検討してください。
PII を含む可能性のある生の行サンプルを保存するのは避けてください。代わりに集計と要約を保存します(件数、null 率、最小/最大、ヒストグラム)。デバッグのためにサンプルを保存する必要がある場合は明示的オプトイン、短期保持、マスキング/マスク解除の厳しい制約、厳格なアクセス制御を実装してください。
以下を監査ログに残します:ログインイベント、チェック編集、アラートルート変更、シークレット更新。監査トレイルは変更時の推測を減らし、コンプライアンスに役立ちます。
DB 認証情報や API キーはプレーンテキストで DB に置いてはいけません。Vault や環境ベースの注入を使い、ローテーションを設計(複数の有効バージョン、最終ローテーション時刻、接続テストフロー)。シークレットの可視性は管理者に限定し、値そのものをログに残さないようにしてください。
アプリを信頼してデータ問題を検出させる前に、確実に失敗を検知し、誤アラートを避け、クリーンに回復できることを実証してください。テストはプロダクト機能と同様に扱い、ノイズの多いアラートやサイレントな欠落からユーザーを守ります。
サポートする各チェックタイプ(フレッシュネス、行数、スキーマ、null 率、カスタム SQL 等)について、1 件は合格するケースと失敗する複数のケースを含む小さくバージョン管理された再現可能な golden テストケースを用意してください。
良い golden テストは次に答えます:期待結果は何か?UI はどんな証拠を表示すべきか?監査ログには何が書かれるべきか?
アラートの不具合はチェックの不具合よりもダメージが大きいことが多いです。閾値、クールダウン、ルーティングに関するアラートロジックをテストしてください:
監視対象を監視するメトリクスを追加して、監視自体が壊れていないかを見られるようにします:
よくある失敗(ジョブが詰まる、認証情報不足、スケジュール遅延、抑制されたアラート)をカバーする明確なトラブルシューティングページを作り、内部リンク(例: /docs/troubleshooting)してください。"what to check first" のステップ、ログ/run ID/最近のインシデントの探し方を含めます。
データ品質アプリの出荷は“大きなローンチ”ではなく、小さな信頼を積み重ねることです。最初のリリースはエンドツーエンドのループを実証すべきです:チェックを実行し、結果を表示し、アラートを送り、実際の問題を誰かが直せること。
狭く確実な機能セットで始めます:
MVP は柔軟性よりも明瞭さに注力してください。ユーザーがなぜチェックが失敗したのか理解できなければ、アラートに対応しません。
プロトタイプ段階で UX を素早く検証したい場合、CRUD が多い部分(チェックカタログ、実行履歴、アラート設定、RBAC)は Koder.ai でプロトタイプし、計画段階で反復してから本実装に進むのも有効です。内部ツールではスナップショットやロールバック機能が、アラートノイズや権限調整をしているときに特に便利です。
監視アプリを本番インフラのように扱ってください:
単一のチェックや統合全体をオフにする“キルスイッチ”は初期導入時に数時間を節約してくれます。
最初の 30 分を成功にしてください。"Daily pipeline freshness" や "Uniqueness for primary keys" のようなテンプレートと /docs/quickstart の短いセットアップガイドを提供します。
また軽量なオーナーシップモデルを定義します:誰がアラートを受け取り、誰がチェックを編集できるか、障害後の「完了」の定義(例:acknowledge → fix → rerun → close)。
MVP が安定したら、実際のインシデントに基づいて拡張します:
反復は時間-診断短縮とアラートノイズ低減に集中してください。ユーザーがアプリで確実に時間を節約できると感じれば、採用は自然と進みます。
まずチームにとって「データ品質」が何を意味するかを書き出します。通常は 正確性(accuracy)、完全性(completeness)、タイムリーさ(timeliness)、一意性(uniqueness) です。各次元を具体的な結果(例: “orders は午前6時までにロードされる”、“email の null 率 < 2%”)に落とし込み、インシデント削減や検出速度向上、誤アラート率低下などの成功指標を決めてください。
多くのチームは 両方 を使うのが最良です:
遅延要件(数分か数時間か)を明確にしてください。これがスケジューリング、ストレージ、アラートの緊急度に影響します。
まず 5–10件の『壊れてはいけない』データセット を優先します。基準は:
各データセットにはオーナーと想定更新頻度を記録し、アラートが対処可能な相手に届くようにしてください。
MVP で扱う実用的なカタログ例:
order.customer_id が customers.id に存在する等)これらは多くの重要な障害をカバーし、初期段階で複雑な異常検知に頼りすぎる必要はありません。
「UI 優先、脱出ハッチ(二次)」が実用的です:
カスタム SQL を許す場合は、リードオンリー接続、タイムアウト、パラメータ化、標準化された pass/fail 出力などの保護を設けてください。
最初のリリースでは小さくても完結する画面群を用意します:
各障害ビューは 、、 を明示すべきです。
スケーラブルな設計の基本は 4 つに分けること:UI、API、Worker(実行系)、ストレージ。
この分離により制御面と実行面を独立してスケール/デバッグできます。
追記型(append-only)のモデルを採用します:
行動につながるアラート設計が重要です。ノイズ低減に注力してください:
調査ページへの直接リンク(例:/checks/{id}/runs/{runId})を含め、復旧時の通知も選択できるようにしてください。
管理者ツールとして扱い、初期からセキュリティ設計を入れてください:
要約メトリクスと調査用の生データ(安全に扱う)を両方保持し、各実行にチェック定義のバージョン/ハッシュを記録して「ルール変更」か「データ変更」かを区別できるようにしてください。