2025年9月21日·1 分
低遅延のDisruptorパターン:予測可能なリアルタイム設計
Disruptorパターンを使って低遅延で予測可能なリアルタイム設計を学ぶ。キュー、メモリ、アーキテクチャの選択で応答時間を安定させる方法を解説します。
Disruptorパターンを使って低遅延で予測可能なリアルタイム設計を学ぶ。キュー、メモリ、アーキテクチャの選択で応答時間を安定させる方法を解説します。
速さには2つの顔があります:スループットとレイテンシ。スループットは1秒あたりに処理できる仕事量(リクエスト、メッセージ、フレーム)です。レイテンシは1件の仕事が開始から終了までにかかる時間です。
システムはスループットが高くても、いくつかのリクエストが極端に長くかかれば遅く感じます。平均値は誤解を招きます。99件が5msで1件が80msなら平均は問題なさそうに見えますが、80msに当たったユーザーにはカクつきが起きます。リアルタイムではその稀なスパイクが全てで、リズムを壊してしまいます。
予測できるレイテンシとは、単に平均を下げることではなく、一貫性を目指すことです。多くの操作が狭い範囲内で終わるようにする。だからチームはテール(p95, p99)を監視します。そこに停止が隠れています。
50msのスパイクは音声や映像(音の途切れ)、マルチプレイヤーゲーム(ラグやラバーバンディング)、リアルタイム取引(価格を逃す)、産業監視(アラーム遅延)、ライブダッシュボード(数値ジャンプ、信頼感の欠如)などでは大きな問題になります。
単純な例としてチャットアプリを考えてみてください。多くの場合メッセージは速く届きますが、背景で一時停止が起きて1件が60ms遅れると、入力中の表示がちらつき会話が遅く感じられます。サーバー側は平均で「速い」のに体感は悪い、という典型です。
リアルタイムをそれらしく感じさせたいなら、驚きを減らす必要があります。単にコードを速くするだけでは不十分です。
多くのリアルタイムシステムが遅く感じるのはCPUが足りないからではありません。仕事が実行されるより先に待ちに費やされているからです:スケジュール待ち、キューでの待ち、ネットワーク待ち、ストレージ待ち。
エンドツーエンドのレイテンシは「何かが起きてからユーザーが結果を見るまで」の全時間です。ハンドラが2msで動いても、処理が複数箇所で一時停止すれば合計で80msになることがあります。
経路を分解すると便利です:
それらの待ちが積み重なります。ここ数ミリ秒の差が「速い」コードパスをユーザーにとって遅い体験に変えてしまいます。
テールレイテンシこそユーザーが文句を言い始める場所です。平均は問題無く見えても、p95やp99は最も遅い5%や1%を示します。外れ値は通常、まれに起きる一時停止から来ます:GC、ホスト上の騒がしい隣人、短時間のロック競合、キャッシュの再補充、バーストで生じたキューの増加などです。
具体例:価格更新がネットワークで5msで届き、忙しいワーカーのために10ms待ち、他のイベントの後ろで15ms待ち、さらにDBの停滞で30msかかるとします。コード自体は2msで動いていても、ユーザーは62ms待つことになります。目標は計算だけを速くすることではなく、各ステップを予測可能にすることです。
速いアルゴリズムでも、リクエストごとの時間が大きくばらつくと遅く感じます。ユーザーは平均ではなくスパイクを感じ取ります。このばらつきがジッターで、多くはコードが完全にコントロールできない要因から来ます。
CPUキャッシュやメモリアクセスの挙動は隠れたコストです。ホットデータがキャッシュに収まらないとCPUはRAMを待ちます。オブジェクトが多い構造、散在するメモリアクセス、「もう一回参照する」が繰り返されるとキャッシュミスが増えます。
メモリ割り当てもランダム性を招きます。短命オブジェクトを大量に割り当てるとヒープ圧が上がり、後でGCの一時停止やアロケータの競合として現れます。GCがなくても頻繁な割り当ては断片化と局所性の喪失を招きます。
スレッドスケジューリングも一般的な原因です。スレッドがデスケジュールされるとコンテキストスイッチのオーバーヘッドが発生し、キャッシュの温度が下がります。忙しいマシンではリアルタイムスレッドが別の仕事の後ろで待たされることがあります。
ロック競合は予測可能なシステムを崩壊させる場面です。「通常は空いている」ロックがコンボイを生むと、スレッドが順番に目を覚ましてはまた寝ることになり、テールレイテンシが伸びます。
I/O待ちも他を圧倒します。システムコール一回、満杯のネットワークバッファ、TLSハンドシェイク、ディスクフラッシュ、遅いDNSルックアップなどがシャープなスパイクを生み、マイクロ最適化では解決できません。
ジッターを追うときは、キャッシュミス(ポインタ多用やランダムアクセスが原因)、頻繁な割り当て、過剰なスレッドや騒がしい隣人によるコンテキストスイッチ、ロック競合、ブロッキングI/O(ネットワーク、ディスク、同期ログなど)をまず探してください。
例:価格ティッカーサービスは更新をマイクロ秒で計算できても、同期ログ呼び出しや競合するメトリクスロック一つで数十ミリ秒が断続的に追加されることがあります。
Martin Thompsonは低レイテンシエンジニアリングで、平均速度だけでなく圧力下での予測可能な速度に注目した人物として知られています。LMAXチームとともに、イベントを小さく一貫した遅延でシステムに流すための参照的アプローチとしてDisruptorパターンを広めました。
Disruptorの考え方は、多くの「速い」アプリを予測不可能にする要因、つまりコンテンションと協調に対する回答です。典型的なキューはロックや重いアトミック操作に頼ることが多く、スレッドの起床と休止を繰り返し、プロデューサとコンシューマが共有構造を奪い合うと待ちが発生します。
キューの代わりにDisruptorはリングバッファを使います:固定サイズの循環配列にスロットとしてイベントを置きます。プロデューサは次のスロットを確保してデータを書き込み、シーケンス番号を公開します。コンシューマはそのシーケンスに従って順に読んでいきます。バッファを事前確保することで頻繁な割り当てを避け、GCの圧力を減らせます。
重要な考え方はシングルライタの原則です:ある共有状態(例えばリングのカーソル)には一つの書き手だけを置く。書き手が少なければ「次は誰だ?」という競合が減ります。
バックプレッシャーは明示的です。コンシューマが追いつかないとプロデューサはまだ使われているスロットに当たります。その時点で待つか捨てるか遅らせるかを制御して対処します。無制限にキューが伸びるのとは違い、問題を隠さずに可視化して対処します。
Disruptor風設計が速いのは巧妙なマイクロ最適化のせいではありません。予測不可能な一時停止(割り当て、キャッシュミス、ロック競合、ホットパスに混ざった重い作業)を取り除くことが理由です。
有用なメンタルモデルは組立ラインです。イベントが明確な手渡しで固定ルートを通ると共有状態が減り、各ステップが単純で計測しやすくなります。
速いシステムは驚きの割り当てを避けます。バッファやメッセージオブジェクトを事前確保して再利用すれば、GCやヒープ増大、アロケータ競合による「時々起きる」スパイクを減らせます。
またメッセージは小さく安定させると良いです。イベントごとに触るデータがCPUキャッシュに収まればメモリ待ちが減ります。
実践的には:イベントごとに毎回新しいオブジェクトを作る代わりに再利用し、イベントデータをコンパクトに保ち、共有状態には単一の書き手を使い、バッチングは慎重に行う—という習慣が重要です。
リアルタイムアプリにはログ、メトリクス、リトライ、データベース書き込みのような余分な処理が必要なことがあります。Disruptorの考え方は、それらをコアループから切り離してブロックできないようにすることです。
ライブな価格配信では、ホットパスはティックを検証して次のスナップショットを公開するだけにし、ディスクやネットワーク呼び出し、重いシリアライズは別のコンシューマやサイドチャンネルに移します。そうすることで予測可能なパスは壊れません。
予測可能なレイテンシは大半がアーキテクチャの問題です。速いコードを書いても、あまりに多くのスレッドが同じデータを争ったり、メッセージが無駄にネットワークを往復したりすればスパイクは起きます。
まず、同じキューやバッファに何人の書き手と読み手が触るかを決めてください。シングルプロデューサーは調整が少なく安定しやすいです。マルチプロデューサーはスループットを上げられますが、競合が増えて最悪時のタイミングが不確実になります。複数のプロデューサが必要なら、userIdやinstrumentIdでシャーディングして各シャードに独立したホットパスを与えると良いでしょう。
コンシューマ側では、順序が重要な場合はシングルコンシューマが最も安定したタイミングを提供します。タスクが本当に独立しているならワーカープールが役に立ちますが、スケジュール遅延を増やし順序を壊す可能性がある点に注意してください。
バッチングはトレードオフです。小さなバッチはオーバーヘッドを減らしますが、バッチを満たすための待ちが発生すると遅延を生みます。リアルタイムでは待ち時間を制限する(例:「最大16イベントまたは200マイクロ秒」)方が安全です。
処理境界も重要です。厳しいレイテンシが必要ならプロセス内メッセージングが通常最善です。ネットワークホップはスケールのために有効ですが、各ホップはキュー、再試行、可変遅延を生みます。ホップが必要ならプロトコルを単純にしてホットパスでのファンアウトを避けてください。
実用的なルール:可能ならシャードごとにシングルライタパスを保つ、1つのホットキューを複数で共有するよりキーでシャードする、バッチは時間上限を設ける、並列処理は独立作業のみで導入する、ネットワークホップは測定できるまでジッター源と見なす。
まずコードに触る前にレイテンシ予算を書いてください。何が「良い」かの目標とp99の上限を決め、それを入力、検証、マッチング、永続化、外部への更新などの段階に割り当てます。ステージに予算がないと無制限になります。
次にデータフロー全体を描き、すべてのハンドオフ(スレッド境界、キュー、ネットワークホップ、ストレージ呼び出し)をマークします。ハンドオフはジッターが隠れる場所です。見えるようにすれば減らせます。
ワークフローの一例:
次に、ユーザーにとって「今」に見えるものだけをクリティカルパスに残し、それ以外は非同期にします。
分析、監査ログ、二次インデックスは多くの場合ホットパスから外して良い候補です。検証、順序付け、次状態を作るために必要な処理は通常クリティカルパスに残ります。
速いコードでもランタイムやOSが不適切だと仕事が不意に停止して遅く感じます。目標はスループットだけでなく、遅い1%の驚きを減らすことです。
GCのあるランタイム(JVM、Go、.NET)は生産性で優れますが、メモリクリーンアップ時に一時停止を導入することがあります。現代のコレクタは改善されていますが、負荷下で短命オブジェクトを大量に作るとテールレイテンシが跳ね上がることがあります。GCのない言語(Rust、C、C++)はGC停止を避けられますが、手動での所有権管理や割り当ての規律が必要になります。どちらでもメモリ挙動はCPU速度と同じくらい重要です。
実践的な習慣は簡単です:割り当てがどこで起きるかを見つけてそれを平坦にする。オブジェクトを再利用し、バッファを事前サイズし、ホットパスのデータを一時文字列やマップにしない。
スレッドの選択もジッターに現れます。キューや非同期ホップ、スレッドプールのハンドオフは待ちを増やし分散を広げます。長寿命の少数スレッドを好み、プロデューサ–コンシューマの境界を明確にし、ホットパスでのブロッキング呼び出しを避けてください。
OSやコンテナ設定もテールに影響します。CPU制限によるスロットリング、共有ホスト上の騒がしい隣人、配置ミスのログやメトリクスが突然の遅延を生むことがあります。1つだけ変えるなら、遅延スパイク時の割り当て率とコンテキストスイッチを測定することから始めてください。
多くのレイテンシスパイクは「遅いコード」ではなく、想定外の待ちです:DBロック、リトライストーム、停滞するサービス呼び出し、キャッシュミスからのフルトリップなど。
クリティカルパスは短く保ってください。ホップが増えるほどスケジューリング、シリアライズ、ネットワークキュー、ブロック場所が増えます。1プロセスと1データストアで答えられるならまずそうする。サービス分割は各呼び出しが任意か厳密に境界がある場合に行うべきです。
待ちを有界にすることが平均と予測可能なレイテンシの違いです。リモート呼び出しには厳しいタイムアウトを設け、依存が不健康なら速やかに失敗させてください。サーキットブレーカーはサーバーを守るだけでなく、ユーザーがどれだけ長く待たされるかを上限にします。
データアクセスがブロックするなら経路を分けてください。読み取りはインデックス化されデノーマライズされキャッシュフレンドリーな形が望ましい。書き込みは永続性や順序を重視する。分離すると競合を避けロック時間を減らせます。整合性要件が許すなら、追記のみ(イベントログ)はインプレース更新より予測しやすいことが多いです。
リアルタイムアプリの簡単なルール:永続化をクリティカルパスに置かない(正当性が本当に必要な場合を除く)。多くの場合は:メモリで更新→応答→非同期で永続化(アウトボックスやライトアヘッドログのようなリプレイ機構)という形が良いです。
リングバッファパイプラインでは、メモリ内バッファに公開→状態を更新→応答→別のコンシューマがPostgreSQLへバッチ書き込み、という流れになることが多いです。
ライブコラボレーションアプリや小さなマルチプレイヤーゲームを想像してください。毎16ms(約60Hz)で更新を送るとします。目標は「平均が速い」ではなく「通常16ms以内に収まる」ことです。ひとりの接続が悪くても全体のリズムを守る必要があります。
シンプルなDisruptor風フローはこうです:ユーザー入力を小さなイベントにし、事前確保されたリングバッファに公開、固定セットのハンドラが順に処理(validate -> apply -> prepare outbound messages)、最後にクライアントへブロードキャスト。
エッジではバッチングが有効なことがあります。例えばクライアントごとにティックごとに送信をバッチしてネットワークコール回数を減らす。しかしホットパス内部で「もう少し待ってバッチを埋める」という待ちは避けてください。待つことでティックを逃します。
何かが遅くなったら、封じ込めの問題として扱ってください。あるハンドラが遅いならそのハンドラを独自のバッファの後ろに隔離して、メインループをブロックしない軽量ワークアイテムを公開する。あるクライアントが遅ければブロードキャスタを詰まらせないようにクライアントごとに小さな送信キューを与え、古い更新を捨てるか合体して最新の状態だけを保つ。バッファ深度が増えたらエッジでバックプレッシャーをかける(そのティックでの入力受け付けを止める、機能を劣化させるなど)。
動いている証拠は数字が退屈なことです:バックログ深度がゼロ付近で推移し、ドロップや合体は稀で説明可能、p99がティック予算を超えないこと。
多くのスパイクは自分で招いています。コードは速くてもシステムが他スレッドやOS、CPUキャッシュの外で待つと停止します。
繰り返し見かけるミス:
スパイクを減らす簡単な方法は、待ちを可視化して有界にすることです。遅い作業は別経路に移し、キューの上限を設定し、満杯時にどう振る舞うか(ドロップ、負荷撤回、合体、バックプレッシャー)を決めてください。
予測可能なレイテンシは製品機能のように扱い、偶然に任せないでください。コードをチューニングする前に目標とガードレールを整えましょう。
簡単なテスト:バースト(通常の10倍のトラフィックを30秒)をシミュレートしてみてください。p99が爆発するなら、待ちがどこで起きているかを尋ねてください:増えるキュー、遅いコンシューマ、GC一時停止、共有リソース。
Disruptorパターンをライブラリ選びではなくワークフローとして扱ってください。薄いスライスで予測可能性を実証してから機能を増やしましょう。
「即時に感じさせたい」1つのユーザーアクションを選び(例:「新しい価格が来てUIが更新される」)、エンドツーエンドの予算を書き、早期からp50/p95/p99を測定してください。
うまくいく流れの例:
Koder.ai (koder.ai)でプロトタイピングする場合はまずイベントフローをPlanning Modeでマップすると、キューやロック、サービス境界がうっかり発生するのを防げます。スナップショットとロールバックも、スループットは上がるがp99が悪化する変更を何度も試して元に戻すのに便利です。
計測は正直に行ってください。固定のテストスクリプトを使い、システムをウォームアップし、スループットとレイテンシの両方を記録します。負荷でp99が跳ねるなら、まずコード最適化に飛びつかず、GC、騒がしい隣人、ログバースト、スレッドスケジューリング、隠れたブロッキング呼び出しからの一時停止を探してください。
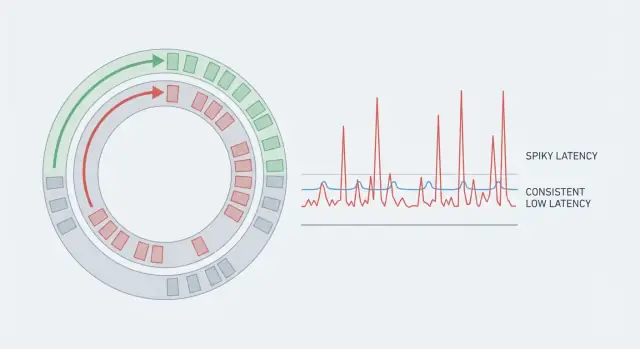
平均値は珍しい遅延を隠します。ほとんどの処理が速くても、一部が大幅に遅ければユーザーは「カクつき」や遅延を感じます。リアルタイムの流れではリズムが重要なので、稀なスパイクが目立ちます。
だから、p95やp99のようなテールレイテンシを追跡してください。そこに目に見える遅延が隠れています。
スループットは1秒あたりに処理できる仕事量です。レイテンシは1つの処理が開始から終了までにかかる時間です。
スループットが高くても、個別の処理が時々長時間待たされればリアルタイムアプリは遅く感じます。重要なのは一貫性です。
テールレイテンシ(p95/p99)は典型的なリクエストではなく、遅い方のリクエストを示します。p99は全体の1%がその値より遅いことを意味します。
リアルタイムの場面では、その1%が目に見えるジッター(音の破裂、ラグ、UIのチラつき、ティックの欠落など)になります。
ほとんどの時間は計算ではなく待ちに使われます:
ハンドラが2msでも、いくつかの待ちが積み重なればエンドツーエンドで60–80msになることはよくあります。
代表的なジッター原因は次の通りです:
デバッグするには、遅延スパイク時の割り当て率、コンテキストスイッチ、キュー深度と相関を取ってください。
Disruptorはパイプラインを小さく一貫した遅延で流すためのパターンです。事前確保されたリングバッファとシーケンス番号を使い、典型的な共有キューに伴う競合、割り当て、スレッドのウェイクアップを減らすことを目的としています。
端的に言えば、コンテンションや協調の不確実性を避ける設計です。
ホットループ内でオブジェクトやバッファを事前確保して再利用してください。これにより:
また、イベントデータは小さく安定させ、CPUが触るメモリ量を減らすとキャッシュ挙動が良くなります。
可能ならシャードごとにシングルライタパスから始めてください(理由が分かりやすく競合が少ない)。スケールするならuserIdやinstrumentIdでシャードして各シャードをホットパスにする方が、一つのキューを複数スレッドで争うよりも予測性が高いです。
ワーカープールは本当に独立した作業向けに使いましょう。そうでなければスループット向上と引き換えにテールレイテンシが悪化することがあります。
バッチ処理はオーバーヘッドを減らしますが、バッチを埋めるために待つと待ち時間が増えます。
実用的なルールはサイズと時間の両方で上限を設けることです(例:「最大N件、または最大Tマイクロ秒のどちらか早い方」)。これでバッチが静かにレイテンシ予算を破ることを防げます。
まずレイテンシ予算を書く(ターゲットとp99)→ステージごとに分割して各ハンドオフを可視化する→キューやロック、ブロッキング呼び出しをマークする、という流れが実用的です。
重要なのは:ホットパスにブロッキングI/Oを置かない、キューは有界にしてオーバーロード時の振る舞いを決める(ドロップ、負荷削減、合体、バックプレッシャー)、そして早期からp99を測ることです。