2025年8月07日·1 分
分散データベース:一貫性と可用性のトレードオフ
分散データベースが障害時に可用性を維持するために一貫性を緩める理由、CAPやクォーラムの仕組み、各アプローチを選ぶタイミングを解説。
分散データベースが障害時に可用性を維持するために一貫性を緩める理由、CAPやクォーラムの仕組み、各アプローチを選ぶタイミングを解説。
データベースが複数のマシン(レプリカ)に分散されると、速度と耐障害性が得られる一方で、機械同士が完全に一致しない、あるいは確実に通信できない期間が生じます。
一貫性とは: 成功した書き込みの後、誰が読んでも同じ値が返ること を意味します。プロフィールのメールアドレスを更新したら、次の読み取りはどのレプリカに当たっても新しいメールを返すべきです。
実務では、整合性を優先するシステムは故障時に矛盾した答えを返さないように、いくつかのリクエストを遅らせたり拒否したりします。
可用性とは: システムがすべてのリクエストに応答すること を意味します。いくつかのサーバーがダウンしているか切断されていても、応答は返ってきます。最新のデータが得られないことはありますが、回答は得られます。
実務では、可用性を優先するシステムはレプリカ間で意見が分かれている間でも読み書きを受け入れ、後で差分を修復します。
トレードオフとは、すべての障害シナリオで両方を最大化できないことを意味します。レプリカが協調できない場合、データベースは次のどちらかを選ばなければなりません:
どのバランスが良いかは、許容できる誤り(短時間の停止か、短期間の誤った/古いデータか)によって決まります。多くの実システムはその中間を選び、トレードオフを明示します。
データとサービスを複数のノードで保管・提供するデータベースを「分散」と呼びます。アプリケーションからは一つのデータベースのように見えるかもしれませんが、内部では異なる場所の異なるノードがリクエストを扱います。
ほとんどの分散データベースはデータを複製します:同じレコードが複数のノードに保存されます。これを行う目的は:
レプリケーションは強力ですが、同時に「二つのノードが同じデータを持っているとき、常に一致させるにはどうするか?」という疑問を生みます。
単一サーバーでは「死んでいるか生きているか」は比較的明白です。分散システムでは障害は部分的に起こります。あるノードは立っているが遅いかもしれない。ネットワークリンクがパケットを落とすかもしれない。ラック全体が接続を失うこともあります。
ノードは別のノードが本当に落ちているのか、一時的に到達不能なのか、単に遅れているだけなのかを即座に知ることができません。調べている間に、入ってくる読み書きにどう対応するかを決めなければなりません。
単一サーバーでは一つの真実源があり、すべての読み取りは最新の成功した書き込みを見る。\n\n複数のノードでは「最新」は協調に依存します。もし書き込みがノードAで成功したがノードBに届かない場合、データベースは:
この緊張関係が、分散によってルールが変わる理由です。
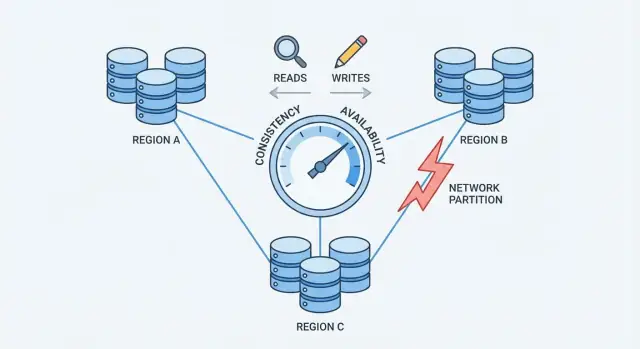
ネットワーク分割とは、本来一体として動くべきノード間の通信が断たれることです。ノードは稼働していてもメッセージを確実に交換できないことがあります。原因は壊れたスイッチ、過負荷のリンク、誤ったルーティング、ファイアウォール設定ミス、クラウドの“ノイジー”な隣人など多岐にわたります。
システムが複数のマシン(ラック、ゾーン、リージョン)に広がると、それらの間のすべての経路を制御できなくなります。ネットワークはパケットを落とし、遅延を生み、時に“島”に分かれます。小規模では稀でも、大規模では日常的に発生します。短時間の中断でも重要です。データベースは何が起きたかを常に合意する必要があるからです。
分割中、両側はリクエストを受け続けます。両側で書き込みが可能なら、片方の更新をもう片方が見ていないまま別の更新を受け入れることがあります。
例:ノードAが住所を「New Street」に更新し、同時にノードBが「Old Street Apt 2」に更新したとします。各側は自分の書き込みが最新だと考えます——リアルタイムで比較する手段がないからです。
分割はわかりやすいエラーメッセージとして出るとは限りません。次のような混乱した動作として現れます:
この状況が圧力点になり、ネットワークが通信を保証できないときに分散データベースが整合性を優先するか可用性を優先するかを決める必要が生じます。
CAPはデータベースを複数の機械に分散したときに起きることをコンパクトに表現する方法です。
分割がないときは、多くのシステムが整合性と可用性の両方を満たすように見えます。\n\n分割があるときは何を優先するかを選ぶ必要があります:
balance = 100 をサーバーAに書き込む。\n- 10:01 ネットワーク分割:サーバーAがサーバーBに到達できなくなる。\n- 10:02 クライアントがサーバーBから読み取る。\n - 整合性を優先するなら、サーバーBは拒否または待機する。\n - 可用性を優先するなら、サーバーBは応答するが balance = 80 のように古い値を返すかもしれない。CAPは「恒久的に2つだけ選べ」という意味ではありません。分割が起きたときには、整合性と可用性の両方を保証することはできない――という意味です。分割がない場合は多くのシステムがほとんど両方を満たしますが、ネットワークが誤動作すると限界が露呈します。
整合性を選ぶと、データベースは「みんなが同じ真実を見る」ことを「常に応答する」より優先します。実務では、多くの場合これが強い整合性(線形化可能な振る舞い)を意味します:書き込みが確定した後の任意の後続読み取りはどこからでもその値を返す。
ネットワークが分割してレプリカが協調できない場合、強整合なシステムは独立した更新を両側で安全に受け入れられません。正しさを守るために通常は:
ユーザーから見ると、いくつかのマシンは稼働していてもサービスが停止しているように見えることがあります。
主な利点は考えやすさです。アプリケーションは複数のレプリカに対して動いているのではなく、一つのデータベースとやり取りしているかのように振る舞えます。これにより次のような「変な瞬間」が減ります:
監査や請求、初回から正確である必要がある処理に対しては理解しやすいモデルが得られます。
整合性には実際のコストがあります:
製品が部分的な停止時にリクエストの失敗を許容できないなら、強整合は高価に感じられることがあります—それでも正しさのためには必要な場合があります。
可用性を選ぶと、単純な約束を最適化します:システムは応答する。実務での「高可用性」は「エラーが全くない」ことではなく、ノード故障や過負荷、ネットワーク障害時でも多くのリクエストが答えを得られることを意味します。
分割中、レプリカは互いに通信できません。可用性優先のデータベースは通常、到達可能な側からトラフィックをさばき続けます:
これによりアプリは動き続けますが、異なるレプリカが一時的に異なる真実を受け入れる可能性があります。
稼働率の向上が得られます:ユーザーは地域が孤立しても閲覧、カートへの追加、コメント投稿、イベント記録などが続けられます。
ストレス時により滑らかなユーザー体験が得られます。タイムアウトの代わりにアプリは「あなたの更新は保存されました」といった挙動で継続し、後で同期します。多くのコンシューマー用途や分析用途ではこのトレードオフは有効です。
代償は古い読み取りを返す可能性です。ユーザーがあるレプリカでプロフィールを更新してすぐ別のレプリカから読むと古い値が見えることがあります。
また書き込みの競合リスクもあります。分割の両側で同一レコードが更新され、修復時にどちらが勝つかを決める必要が出てきます。どちらか一方が勝つ、フィールドをマージする、あるいはアプリ側で解決するなどのルールが必要になります。
可用性優先設計は、一時的な不一致を受け入れて製品の応答性を保ち、後で不一致を検出・修復する仕組みに投資する考え方です。
クォーラムは多くの複製データベースが一貫性と可用性を調整するために使う実用的な「投票」技術です。単一のレプリカを信用する代わりに「十分な数」のレプリカの合意を取ります。
クォーラムはしばしば以下の3つの数で表現されます:
よくある経験則は R + W > N で、これにより読み取りが最新の成功した書き込みと少なくとも1つ重なるようになり、古い読み取りの可能性が減ります。
N=3 の場合:
システムによっては W=3(全レプリカ)にして強い整合性を取るが、その場合は任意のレプリカが遅い/ダウンすると書き込み失敗が増える。
クォーラムは分割問題を消すわけではありませんが、誰が進行できるかを定義します。たとえば分割が 2–1 の場合、2側は R=2 と W=2 を満たせるため進行でき、孤立した1つのレプリカは進行できません。これにより競合更新は減るが、一部のクライアントはエラーやタイムアウトを見ることになります。
クォーラムは通常、レイテンシ増加(より多くのノードと連絡する)、コスト増(ノード間トラフィック増)、そしてタイムアウトが可用性低下に見えるようなより微妙な障害動作をもたらします。利点は調整可能な中間点が得られることで、重要度に応じて R や W を最新重視/書き込み成功重視にダイアルできます。
最終的整合性は、レプリカが一時的に不一致でも後で同じ値に収束すれば良い、という考え方です。
あるチェーンの喫茶店が共有の「売り切れ」表示を更新すると、1店舗が売り切れをマークしてもその更新が他店舗に数分遅れて届くことがあります。その間、別の店ではまだ「在庫あり」と表示されて最後の商品を売ってしまうかもしれません。システムが壊れているわけではなく、更新が追いついていないだけです。
データがまだ伝播中のとき、クライアントは驚くような振る舞いを経験することがあります:
最終的整合性システムは通常、バックグラウンドで不整合を減らす仕組みを持ちます:
可用性が整合性より重要で、少し古いデータが許容できる場合に適しています:アクティビティフィード、ビューカウンタ、推薦、キャッシュされたプロフィール、ログ/テレメトリなど「しばらく後に正しくなる」ことが許されるデータです。
データベースが複数のレプリカで書き込みを受け入れると、分割中に同一アイテムに対する異なる更新が発生し競合が起きます。
典型的な例は、あるデバイスで配送先住所を更新し、別のデバイスで電話番号を同時に変更した場合です。各更新が違うレプリカに到達していると、レプリカが同期したときに「真の」レコードを決める必要があります。
多くのシステムはlast-write-winsを使います:最新のタイムスタンプを持つ更新が他を上書きします。
実装も簡単で計算も速いのが魅力ですが、重要なデータを黙って失う可能性があります。異なるフィールドに対する古い更新が捨てられることがあり得ますし、タイムスタンプが信用できることを前提にしているためクロックスキューで誤った勝者が選ばれることもあります。
安全な競合処理は因果関係の追跡を必要とすることが多いです。
概念的には、バージョンベクター(やその簡易版)が各レコードに付与され、どのレプリカがどの更新を見たかをまとめたメタデータになります。レプリカがバージョンを交換すると、あるバージョンが他を包含している(競合でない)か、分岐している(競合)かを検出できます。
一部のシステムは論理時計(Lamport時計)やハイブリッド論理時計を使い、壁時計に頼らず順序のヒントを与えることもあります。
競合を検出したら選択肢があります:
どの方法が最適かは、そのデータにとって「正しい」とは何かで決まります—場合によっては書き込みが失われても問題ないこともありますし、重大なビジネス上の不具合になることもあります。
整合性/可用性の姿勢を決めるのは哲学的議論ではなくプロダクトの意思決定です。まず問うべきは:「一瞬間違うことのコスト」と「『後でまた試してください』と言うコスト」はどちらが大きいか」です。
いくつかのドメインは書き込み時に単一の正当な答えを必要とします:
逆に一時的な不一致の影響が小さい/可逆なら可用性寄りにできます。
多くのUXはやや古い読み取りで問題ありません:
「どれくらい古くて良いか」を明確に:秒、分、時間が設計の指針になります。
レプリカが合意できないとき、典型的なUXは三つになります:
機能ごとに最も害が少ない選択をし、グローバルに一つの方針に固定しないことが重要です。
整合性(C)寄りにするべきとき: 結果が間違っていると金銭的/法的リスクやセキュリティ問題、不可逆な操作になる場合。
可用性(A)寄りにするべきとき: ユーザーが応答性を重視し、古いデータが許容でき、競合は後で安全に解決できる場合。
迷ったらシステムを分割する:重要なレコードは強整合性で扱い、派生ビュー(フィード、キャッシュ、分析)は可用性最適化にする。
システム全体で一つの「整合性設定」を選ぶ必要はほとんどありません。多くのモダンな分散データベースは操作ごとに整合性を選べます。賢いアプリはこれを使い分けて、UXを滑らかにしつつ現実を隠さない設計をします。
一貫性をダイヤルのように扱い、ユーザーの操作に応じて調整します:
これによりすべてに最高のコストを払う必要がなく、本当に必要な操作だけを保護できます。
一般的なパターンは書き込みは強く、読み取りは弱くです:
場合によっては逆も有効です:速い(キュー済み/最終的)書き込みと確認時の強い読み取り(「注文は完了しましたか?」の確認)を組み合わせる。
ネットワークが不安定なとき、クライアントは再試行します。再試行を安全にするためにidempotency keysを使い、「注文を2回送ったら2件できる」事態を避けます。初回の結果をキーと紐づけて再利用します。
複数サービスにまたがるマルチステップ操作にはサーガを使います:各ステップに対応する補償アクション(返金、予約解放、出荷キャンセルなど)を用意し、部分的な障害や一時的不一致が起きても回復可能にします。
整合性/可用性のトレードオフは見えなければ管理できません。本番の問題は「ランダムな失敗」に見えることが多いので、適切な計測とテストを入れることが重要です。
ユーザー影響に直結する少数の指標から始めましょう:
可能ならメトリクスに整合性モード(クォーラム vs ローカル)やリージョン/ゾーンでタグ付けして挙動の差を見つけやすくします。
本番の障害を待たないでください。ステージングでカオス実験を行い、以下をシミュレートします:
重要なのは「システムが稼働し続けるか」だけでなく、どの保証が維持されるかを検証することです:読み取りは新鮮か、書き込みはブロックされるか、クライアントは明確なエラーを受け取るか。
次のようなアラートを設定しましょう:
最後に、運用チームとプロダクトチームに対して通常時と分割時に何を保証するのかを文書化し、ユーザーに何が見えるかを教育しておきましょう。
新製品でこれらのトレードオフを探る際は、特に障害モードやリトライ挙動、UI上での「古さ」がどのように見えるかを早期に検証することが役立ちます。
実用的なアプローチは、ワークフローの小さなプロトタイプ(書き込み経路、読み取り経路、リトライ/冪等性、再調整ジョブ)を作って検証することです。Koder.ai のようなツールを使えば、チャット駆動のワークフローでウェブアプリやバックエンドを素早く立ち上げ、データモデルやAPIを反復し、強い書き込み+緩い読み取りのような異なる整合性パターンを本格的な構築コストなしに試せます。プロトタイプが望む振る舞いを示したら、ソースコードをエクスポートして本番へと発展させられます。
レプリケートされたデータベースでは「同じ」データが複数のマシンに存在します。これは耐障害性や低レイテンシをもたらしますが、調整の問題も導入します:ノードは遅延したり到達不能になったり、ネットワークで分断されたりするため、常に最新の状態で合意できるとは限りません。
一貫性とは、成功した書き込みの後、どのレプリカから読んでも同じ値が返ることを意味します。実際のシステムでは、これを保証するために十分なレプリカ(またはリーダー)が更新を確認するまで読み書きを遅らせたり拒否したりすることがよくあります。
可用性とは、一部のノードがダウンしたり通信できない場合でも、システムがすべてのリクエストに対してエラーでない応答を返すことを意味します。返ってくる応答は古い情報や局所的な状態に基づくかもしれませんが、障害時にユーザーをブロックしないことを優先します。
ネットワーク分割とは、本来一つのシステムとして動作すべきノード間の通信が断たれることです。ノードは稼働しているかもしれませんがメッセージを確実に交換できないため、データベースは次のどちらかを選ばざるを得ません:
分割中、両側で更新を受け付けられると、それぞれの側が互いに共有できない更新を受け入れることがあります。その結果として見られる現象は:
これらはレプリカが一時的に調整できないことのユーザー向けの表れです。
それは「永遠に2つ選べ」という意味ではありません。分割が発生したとき、整合性と可用性の両方を同時に保証することはできない――という意味です。分割が無い時には、多くのシステムが両方に非常に近い振る舞いを示しますが、ネットワークが問題を起こすとその限界が露呈します。
クォーラムはレプリカ間の投票によってバランスを取る現実的な手法です:
一般的な目安は R + W > N で、これにより読み取りセットと直近の書き込みセットが少なくとも1つ重なるため古い値を読む確率が下がります。クォーラムは分割を無くすわけではなく、どちらの側が進行できるかを定義します(たとえば過半数を持つ側など)。
最終的整合性は、レプリカが一時的に不整合でも時間が経てば収束することを許容するモデルです。よくある異常は:
システムは通常、リードリペア、ヒンテッドハンドオフ、定期的な**アンチエントロピー(差分照合)**などで不整合の窓を小さくします。
分割中に異なるレプリカが同じアイテムに別々の書き込みを受け付けると競合が起きます。解決方法の例:
「正しい」とは何かで最適な戦略が変わります。場合によっては書き込みを失うことが許容されるが、重大なビジネス領域では許されません。
ビジネスリスクと許容できるエラーの種類で決めてください:
実務的には、操作ごとに整合性レベルを変えたり、アイドンプトン性キーで安全にリトライを設計したり、長いワークフローにはサーガと補償アクションを使うことが有効です。