2025年10月08日·1 分
分散SQLデータベース:Spanner、Cockroach、Yugabyteはいつ使うべきか?
分散SQLとは何か、Spanner・CockroachDB・YugabyteDBの違い、そしてどの実運用ケースでマルチリージョンかつ強整合性のSQLが正当化されるかを学ぶ。
分散SQLとは何か、Spanner・CockroachDB・YugabyteDBの違い、そしてどの実運用ケースでマルチリージョンかつ強整合性のSQLが正当化されるかを学ぶ。
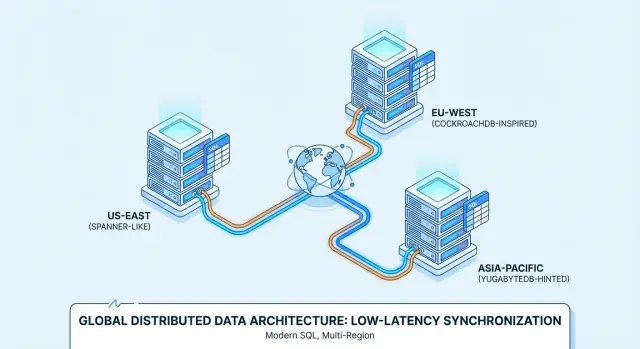
「分散SQL」は、テーブル、行、結合、トランザクション、SQLといった伝統的なリレーショナルデータベースの使い勝手を保ちつつ、複数台(しばしば複数リージョン)にまたがるクラスタとして動作し、ひとつの論理データベースのように振る舞うように設計されたデータベースを指します。
この組み合わせが重要なのは、同時に三つの要素を提供しようとするからです:
古典的なRDBMS(PostgreSQLやMySQLなど)は、すべてが1台のプライマリに収まる場合は運用が最も簡単です。リードレプリカで読み取りをスケールできますが、書き込みのスケールやリージョン障害の耐性はシャーディング、手動フェイルオーバー、アプリ側ロジックなど追加設計を要します。
多くのNoSQLシステムは逆のアプローチを取り、まずスケールと高可用性を優先し、整合性を緩めたりクエリモデルを簡素化したりしました。
分散SQLは中間の道を目指します:リレーショナルモデルとACIDトランザクションを保持しながら、成長や障害に対応するためにデータを自動で分散させます。
分散SQLは以下のような課題向けに作られています:
これが、Google Spanner、CockroachDB、YugabyteDBのようなプロダクトがマルチリージョン展開や常時稼働サービスの候補として評価される理由です。
分散SQLが自動的に「優れている」わけではありません。可用性とスケールを得る代わりに、ネットワーク往復、コンセンサス、クロスリージョン遅延といった別の性能現実とより多くの構成要素を受け入れることになります。
もしワークロードが単一のよく管理されたデータベースに収まり、単純なレプリケーション構成で済むなら、従来のRDBMSの方がシンプルで安価です。分散SQLが費用対効果を発揮するのは、代替がカスタムシャーディングや複雑なフェイルオーバー、あるいはマルチリージョン整合性と稼働を要求するビジネス要件の場合です。
分散SQLは馴染みのあるSQLデータベースの感触を保ちながら、データを複数のマシン(しばしば複数リージョン)に保存します。難しいのは、多数のコンピュータを協調させて信頼できる1つのシステムのように振る舞わせることです。
各データ片は通常複数ノードにコピーされます(複製)。1つのノードが故障しても、別のコピーが読み取りを提供し、書き込みを受け付けられます。
レプリカが乖離するのを防ぐため、分散SQLシステムはコンセンサスプロトコルを使います。代表的なのはRaft(CockroachDB、YugabyteDB)やPaxos(Spanner)です。高レベルではコンセンサスとは:
この「過半数の承認」が強い整合性を与えます:トランザクションがコミットされれば、他のクライアントが古い版を見ることはありません。
単一マシンはすべてを保持できないため、テーブルはシャード/パーティションと呼ばれる小さなチャンクに分割されます(Spannerではsplits、CockroachDBではranges、YugabyteDBではtabletsと呼ぶことが多い)。
各パーティションはコンセンサスで複製され、特定ノードに配置されます。配置はランダムではなくポリシーで制御できます(例:EU顧客データはEUリージョンに留める、ホットパーティションは高速ノードに置くなど)。適切な配置はクロスネットワーク往復を減らし、パフォーマンスを予測可能にします。
単一ノードDBではトランザクションのコミットがローカルディスク操作で済むことがあります。分散SQLではトランザクションが複数パーティションに触れると、そのパーティションが異なるノード上にある可能性があります。
安全にコミットするために通常必要な手順:
これらの手順はネットワーク往復を生むため、特にデータがリージョンをまたぐ場合にトランザクション遅延が増えます。
展開がリージョンをまたぐ場合、システムは操作を「近く」に保とうとします:
これがマルチリージョンにおける核心的なバランスです:ローカルな応答性を最適化できる一方で、長距離にわたる強い整合性は依然としてネットワークコストを伴います。
分散SQLを導入する前に、まず自分の基本的なニーズをチェックしましょう。単一プライマリリージョン、予測可能な負荷、小規模な運用体制であれば、従来のリレーショナルデータベースやマネージドPostgres/MySQLの方が素早く機能を出せます。リードレプリカ、キャッシュ、スキーマ/インデックス最適化で単一リージョン構成をかなり延命できます。
次のうち1つ以上が当てはまると、分散SQLの検討に値します:
分散システムは複雑さとコストを増します。注意すべき状況:
次のうち2つ以上に「はい」と答えられるなら、分散SQLを評価すべきです:
分散SQLは「全部手に入る」ように聞こえますが、実際のシステムは選択を強います。特にリージョン間通信が不安定な場合に顕著です。
ネットワーク分断を「リージョン間のリンクが不安定または切れている状態」と考えると、その瞬間にデータベースが優先できるのは:
分散SQLシステムはしばしばトランザクションに対して整合性を優先するように作られます。それはチームが望むことが多いですが、分断が起きると操作が待たされるか失敗することになります。
強い整合性はトランザクションがコミットされたら以降の読み取りがその値を返すことを意味します。これは次のようなケースで重要です:
「確定したらそれは確かなことだ」というプロダクトの約束をするなら、強い整合性は贅沢品ではなく必須です。
実務で重要なのは次の2点です:
リージョン間で強い整合性を保つには通常コンセンサスが必要です。レプリカが大陸をまたぐ場合、光速が製品制約になります:クロスリージョン書き込みは数十〜数百ミリ秒を追加する可能性があります。
トレードオフは単純です:地理的冗長性と正確さを高めるほど書き込みレイテンシが高くなる。ただし、データの配置やトランザクションを許可する場所を慎重に選べば緩和できます。
Google Spannerは主にGoogle Cloud上のマネージドサービスとして提供される分散SQLデータベースです。複数リージョンにまたがる単一の論理データベースが欲しいケースに向けて設計されています。SpannerはGoogleSQL(ネイティブ方言)とPostgreSQL互換方言の2つをサポートしており、選ぶ方言によって移植性は変わります。
CockroachDBはPostgreSQLに馴染んだチームが扱いやすいことを目標にした分散SQLです。Postgresワイヤープロトコルを使い、多くのPostgres様SQLをサポートしますが、Postgresの完全な互換ではありません。CockroachDB Cloudのようなマネージドサービスとして、またセルフホストでも運用できます。
YugabyteDBはPostgres互換のSQL API(YSQL)とCassandra互換API(YCQL)を持つ分散データベースです。CockroachDB同様、Postgres風の開発体験を維持しつつノードやリージョンにまたがってスケールすることを想定しています。セルフホストとマネージド(YugabyteDB Managed)双方での提供があります。
マネージドサービスはアップグレード、バックアップ、監視統合などの運用工数を減らします。一方でセルフホストはネットワーク設計、インスタンスタイプ、データが物理的にどこに置かれるかに対する細かい制御を可能にします。Spannerは主にGCPのマネージドとして消費され、CockroachDBとYugabyteDBはマネージド/セルフホストの両面でよく使われます(マルチクラウドやオンプレ環境も含む)。
3者とも「SQL」を話しますが、日常的な互換性は方言の選択(Spanner)やPostgres機能のカバレッジ(CockroachDB/YugabyteDB)、アプリが依存するPostgres拡張や関数、トランザクション挙動に左右されます。
計画に時間をかけて、クエリ、マイグレーション、ORMの挙動を早期にテストすることが重要です。単純な置き換えを期待しないでください。
分散SQLの古典的な適合例は、北米、欧州、APACに顧客を持つB2B SaaSです—サポートツール、人事プラットフォーム、分析ダッシュボード、マーケットプレイスなどを想像してください。
ビジネス要件はシンプルです:ユーザーは「ローカルなアプリ」応答性を望み、会社側は単一の論理データベースで常時稼働を実現したい。
多くのSaaSチームは混在した要件に直面します:
分散SQLはテナントごとのローカリティでこれをきれいにモデル化できます:各テナントの主データを特定リージョン(またはリージョン群)に配置しつつ、スキーマとクエリモデルはシステム全体で一貫させる。これにより「リージョンごとに1つのDB」を乱立させずに居住性要件を満たせます。
アプリを速く保つための典型的な方針:
クロスリージョン往復がユーザー体感遅延を支配するため、ローカリティ設計が重要です。強い整合性を維持しつつも、多くのリクエストが大陸間通信のコストを払わないようにできます。
技術的な利点は運用が維持できてこそ意味を持ちます。グローバルSaaSでは次を計画してください:
うまくやれば、分散SQLは単一の製品体験を保ちながらローカル感を提供できます—エンジニアリングチームを「EUスタック」「APACスタック」に分ける必要はなくなります。
金融システムは「最終的整合性」が現金に直結するケースです。顧客が注文を出し、支払いが承認され、残高が更新される。これらのステップは即座に一致した単一の真実を持つ必要があります。
強い整合性は、異なるリージョンやサービスがそれぞれ「合理的な」決定をしてしまい結果的に台帳が不整合になるのを防ぎます。
典型的なワークフロー(注文作成→資金を確保→決済→残高/台帳更新)では、次のような保証が欲しい:
分散SQLはノード(しばしばリージョン)を越えたACIDトランザクションと制約を提供できるので、台帳の不変条件を障害時でも保てます。
支払い統合は再試行が多発します:タイムアウト、Webhookの再送、ジョブの再処理は普通です。DBは再試行を安全にする手助けをすべきです。
実践的な方法はアプリ側の冪等キーとDBでの一意制約を組み合わせることです:
idempotency_keyを保存する。(account_id, idempotency_key)の一意制約を追加する。こうすれば2回目の試行は無害なNo-opになり、二重請求を防げます。
セールイベントや給与処理は突然の書き込み集中を生みます。分散SQLではノードを追加して書き込みスループットを上げることで同じ整合性モデルを維持しつつ拡張できます。
重要なのはホットキー(例:ある1つの加盟店アカウントに全トラフィックが集中する)を想定し、負荷を分散するスキーマパターンを設計することです。
金融ワークフローは不変の監査証跡、誰がいつ何をしたかの追跡、予測可能な保管ポリシーを要します。規制の詳細を挙げなくても、一般に想定すべきは:追加専用の台帳エントリ、タイムスタンプ、アクセス制御、監査を損なわない保管/アーカイブルールです。
在庫や予約は単純に見えますが、複数リージョンが同じ希少資源を扱うと難しくなります:最後のコンサート席、限定ドロップ商品、特定日のホテルルーム。
難しいのは可用性の読み取りではなく、ほぼ同時に2人が同じものを確保してしまうことを防ぐことです。
強い整合性がないマルチリージョン環境では、各リージョンがわずかに古いデータに基づいて在庫があると判断する可能性があります。そのウィンドウに異なるリージョンでチェックアウトが行われると、両方がローカルで受理され、後で調整が必要になることがあります。
これがクロスリージョンでの過剰販売の発生原因です:システムが「間違っている」からではなく、一時的に異なる真実を許容したためです。
分散SQLは書き込み重視の割当て操作に対して単一の権威ある結果を強制できるため、「最後の席」は本当に一度だけ割り当てられます。
Hold + confirm(確保して確定):一時的なホールド(予約レコード)をトランザクションで作り、支払い確定を別ステップにする。
有効期限:ホールドは自動で期限切れにして、ユーザーが中断しても在庫が固定されないようにする(例:10分)。
トランザクショナルアウトボックス:予約が確定したら同一トランザクションで「送信すべきイベント」行を書き、非同期にメールやフルフィルメント、分析、メッセージバスへ配信する。これにより「予約済みだが確認メールが送られていない」というギャップを防げる。
結論として、ビジネスがリージョン間で二重割当を許容できないなら、強いトランザクション保証は技術的な贅沢ではなくプロダクト要件です。
ダウンタイムが高コストで、予測できない障害が許容できず、メンテナンスを退屈にしたいなら分散SQLは良い選択です。
目標は「絶対に故障しない」ことではなく、明確なSLO(例:99.9%や99.99%)を満たすことです。ノードが死ぬ、ゾーンが落ちる、アップグレード中でもサービスを維持することが求められます。
「常時稼働」を測定可能な期待に落とし込みます:月あたりの最大ダウンタイム、RTO、RPOなど。
分散SQLは多くの一般的な障害を通じて読み書きを提供できますが、それはトポロジがSLOに合っていて、アプリが一時的なエラー(リトライ、冪等性)を適切に処理することが前提です。
計画的メンテナンスも重要です。ローリングアップグレードやインスタンス置換が、クラスタ全体を停止せずにリーダーやレプリカを移動できるかを確認しましょう。
マルチゾーンは単一AZ障害や多くのハードウェア障害から保護します。通常レイテンシとコストは低めで、コンプライアンスとユーザーベースが一地域中心なら十分なことが多いです。
マルチリージョンはリージョン全体の障害から保護し、地域フェイルオーバーを可能にしますが、強い整合性の書き込みではレイテンシが高くなり、キャパシティ設計も複雑になります。
フェイルオーバーが即時か目に見えないものだと仮定しないでください。「フェイルオーバー」とは短いエラーのスパイクか、読み取り専用期間、数秒の高レイテンシを意味するのかを定義しましょう。
「ゲームデイ」を実行して検証します:
同期複製であっても、バックアップとリストアの練習は必須です。バックアップはオペレータのミス(誤ったマイグレーション、誤削除)、アプリのバグ、複製されうる破損から守ります。
ポイントインタイムリカバリ(PITR)がある場合はそれを検証し、プロダクションに触れずにクリーンな環境に復元できるかを確認してください。
データ居住性要件は、特定のレコードが特定の国やリージョン内に保管(場合によっては処理も)されるべきだという規則、契約、方針から生じます。
これは個人データ、医療情報、支払いデータ、政府系ワークロード、あるいは顧客契約で保存場所が定められているデータに適用されます。
分散SQLは単一の論理データベースを維持しつつデータを物理的に別リージョンに配置できるため、ここで検討されることが多いです。
規制や顧客が「データはリージョン内に留める」と要求する場合、単に近傍に低遅延レプリカを置くだけでは不十分です。必要なことの例:
これにより、場所が設計の第一級制約になります。
SaaSではテナントごとの配置が一般的です。例:EU顧客の行やパーティションはEUリージョンに固定、米国顧客は米国リージョンに固定。
高レベルでは次を組み合わせます:
目標はオペレーションアクセス、バックアップ復元、クロスリージョン複製による違反を偶発的に起こしにくくすることです。
居住性やコンプライアンス義務は国や業界、契約で大きく異なり、時間とともに変わります。データベーストポロジをコンプライアンスプログラムの一部とし、適切な法務および(該当する場合)監査人の確認を得てください。
居住性に配慮した設計はグローバルな全社ビューを複雑にします。顧客データを意図的に別リージョンに分けると、分析やレポートは:
多くのチームは運用ワークロード(強い整合性、居住性意識)と分析(リージョン単位のウェアハウスや厳格に管理された集約データ)を分離して、コンプライアンスを保ちながら日常の報告を遅くしないようにしています。
分散SQLは痛みを伴う障害や地域制約から守ってくれますが、デフォルトで安くなることは滅多にありません。事前計画で不要な「保険料」を避けましょう。
予算は通常次の4つに分かれます:
分散SQLは特に強い整合性の書き込みで調整を追加します。
影響見積りの実用的な方法:
これは「やめろ」という意味ではなく、逐次書き込みを減らす設計(バッチ化、冪等リトライ、チャットなトランザクションの回避)を検討するべき、という意味です。
ユーザーの大半が一地域にいるなら、単一リージョンのPostgresとリードレプリカ、良いバックアップ、テスト済みのフェイルオーバープランの方が安くてシンプルで高速です。
分散SQLは真にマルチリージョン書き込み、厳格なRPO/RTO、または居住性を伴う配置が必要な場合に費用対効果を発揮します。
支出は次のトレードと考えます:
回避できる損失(ダウンタイム+解約+コンプライアンスリスク)が継続的なプレミアムより大きければマルチリージョン設計は正当化されます。そうでなければシンプルに始め、後で進化する道筋を残しましょう。
分散SQLの採用は単にDBを移すことではなく、データとコンセンサスがノード(場合によってはリージョン)に分散されたときに自分のワークロードがうまく振る舞うかを証明することです。軽量な計画で驚きを避けましょう。
実際の痛みを表す1つのワークロードを選びます:例:checkout/booking、アカウント作成、台帳記入。
事前に成功指標を定義:
PoC段階で速く進めたいなら、小さな実アプリ面(API+UI)を作って合成ベンチだけでなくエンドツーエンドでトランザクションやリトライ、障害時挙動を試すと良いでしょう。例えば、チームはKoder.aiでReact+Go+PostgreSQLのスタータを素早く立ち上げ、DBレイヤをCockroachDB/YugabyteDBに入れ替えたりSpannerに接続してパターンを検証することがあります。要点はスタータスタックではなく、「アイデア」から「測定できるワークロード」へのループを短くすることです。
監視とランブックはSQLと同じくらい重要です:
PoCスプリントから始め、プロダクション準備レビューと段階的な移行(可能ならデュアルライトやシャドウ読み取りを使って)に時間を割いてください。
コストやプランの見積が必要なら /pricing を参照。移行パターンやより実践的な手順は /blog をご覧ください。
PoCの所見やアーキテクチャ上のトレードオフ、移行で学んだことをチーム(および可能なら公開)で共有すると良いでしょう:Koder.aiのようなプラットフォームは教育的コンテンツの作成やほかのビルダー紹介でクレジットを得る方法を提供しており、評価期間の実験費用を相殺するのに役立つことがあります。
分散SQLデータベースは、リレーショナルなSQLインターフェース(テーブル、結合、制約、トランザクション)を提供しつつ、複数のマシン(しばしば複数リージョン)にクラスタとして分散して動作し、「1つの論理データベース」として振る舞うものです。
実際には、狙っているのは次の組み合わせです:
単一ノードまたはプライマリ/リードレプリカ構成のRDBMSは、単一リージョンのOLTPにはしばしばよりシンプルで安く、速い選択です。
分散SQLが魅力的になるのは次のような代替が必要になる場合です:
多くのシステムは2つの基本概念に依存します:
これがノード障害時でも強い整合性を実現しますが、ネットワーク調整のオーバーヘッドが増えます。
テーブルは小さなチャンク(パーティション/シャード、ベンダー固有の呼称では ranges/tablets/splits 等)に分割されます。各パーティションは:
配置は無作為ではなく、ポリシーで影響できます。ホットデータや主な書き込み元を近くに置くとクロスネットワーク往復が減り、性能が安定します。
分散トランザクションは複数のパーティションにまたがることがあり、安全にコミットするには:
これらはネットワーク往復を生むため、特にリージョンをまたぐ場合に書き込みレイテンシが増します。
次のいずれかが当てはまるなら、分散SQLを検討すべきです(2つ以上なら評価に値します):
単一リージョンでレプリカやキャッシュで十分な場合は従来RDBMSの方が簡単です。
強い整合性はトランザクションがコミットされたら以降の読み取りがそのコミットを必ず反映することを意味します。
プロダクト上の利点:
代償として、ネットワーク分断時にはシステムは操作をブロックするか失敗させる(=可用性を犠牲にする)可能性があります。
データベースの制約とトランザクションを組み合わせます:
idempotency_keyを保存する(account_id, idempotency_key)のような一意制約を付けるこうすると再試行は重複ではなく無害なNo-opになります。支払いやプロビジョニング、バックグラウンド処理で重要です。
実務的な区分け:
選択前にORM、マイグレーション、依存しているPostgres拡張をテストすることが重要です。単純な置き換えとは限りません。
クリティカルなワークロード1つを選んでPoCを行います(checkout、booking、台帳記入など)。事前に成功指標を定義:
必要なら実際のAPI+UIを小規模に作り、実負荷に近い振る舞いを計測するのが早道です。PoCのコスト見積りや階層が必要なら /pricing を参照。実装ノートは /blog を参照してください。