2025年10月14日·1 分
GraphQLとは?APIとデータ取得のためのわかりやすいガイド
GraphQLが何か、クエリ・ミューテーション・スキーマの仕組み、RESTの代わりに使うべき場面、実践的な利点・欠点・例を学びます。
GraphQLとは(何でないかも含めて)
GraphQLはクエリ言語でありAPIのためのランタイムです。簡単に言えば:アプリ(ウェブ、モバイル、あるいは別のサービス)がAPIに対して明確で構造化された要求を送り、サーバがその要求に合ったレスポンスを返す仕組みです。
解決する問題
多くのAPIはクライアントに対して固定のエンドポイントが返すものを受け入れるよう強制します。それはしばしば2つの問題につながります:
- オーバーフェッチ:使わないフィールドまで取得してしまう。\n- アンダーフェッチ:一つの画面を構築するために複数のリクエストをしなければならない。
GraphQLではクライアントがまさに必要なフィールドだけを要求できます。これは、異なる画面(または異なるアプリ)が同じ基盤データの異なる「スライス」を必要とする場合に特に有効です。
GraphQLの“居場所”
GraphQLは通常、クライアントアプリとデータソースの間に位置します。データソースには次のようなものがあります:
- データベース
- 既存のRESTサービス
- サードパーティAPI
- マイクロサービス
GraphQLサーバはクエリを受け取り、要求された各フィールドを適切な場所からどう取得するかを決め、最終的なJSONレスポンスを組み立てます。
直感的なモデル
GraphQLをカスタム形状のレスポンスを注文することに例えてください:
- クライアントが欲しいデータの形を記述する。\n- サーバは(可能な限り)その正確な形でデータを返す。
GraphQLでないもの
誤解が多いのでいくつか明確にしておきます:
- それはデータベースではない(データを保存しない)。\n- それは自動的に速いわけではない(不要なデータ転送は減らせるがサーバ作業は依然重要)。\n- “REST 2.0”ではない(強みやトレードオフが異なる代替APIアプローチ)。
この核心定義(クエリ言語 + APIのランタイム)を押さえておけば、他の議論も理解しやすくなります。
GraphQLが作られた理由
GraphQLは実用的なプロダクト課題を解決するために生まれました:チームが実際のUI画面に合わせてAPIを調整するのに時間を使いすぎていたのです。
従来のエンドポイントベースのAPIは、多くの場合「余計なデータを送る」か「必要なデータを得るために追加の呼び出しをする」かという選択を強います。プロダクトが成長するとその摩擦はページの遅延、複雑なクライアントコード、フロントエンドとバックエンドの調整の苦労として表れます。
GraphQLが狙う痛点
オーバーフェッチは、エンドポイントが“完全な”オブジェクトを返すときに起きます。たとえばモバイルのプロフィール画面が名前とアバターだけ必要でも、APIが住所や設定、監査用フィールドまで返すと帯域を無駄にしUXを損なう可能性があります。
アンダーフェッチは逆です:単一のエンドポイントですべてが得られないためクライアントが複数リクエストを送って結果を組み立てなければならない状態。これがレイテンシを増やし部分的失敗の可能性を高めます。
バージョンアップを頻繁にしない進化
多くのREST系APIは変化に対して新しいエンドポイントを追加したりバージョニング(v1, v2, v3)で対応します。バージョニングは必要な場合もありますが、古いクライアントは古いバージョンを使い続け、新機能は別の場所に積み上がるため長期的なメンテナンスコストが増えます。
GraphQLはスキーマにフィールドや型を追加して進化させ、既存フィールドを安定させることで「新バージョン」を作らずに対応できる余地を作ります。
ひとつのAPIで多くのクライアントへ
現代のプロダクトは1つの消費者だけを持つことは稀です。Web、iOS、Android、パートナー連携などがそれぞれ異なるデータ形を必要とします。
GraphQLは各クライアントが必要なフィールドを要求できるよう設計されているため、バックエンドが画面やデバイスごとに別々のエンドポイントを作る必要を減らします。
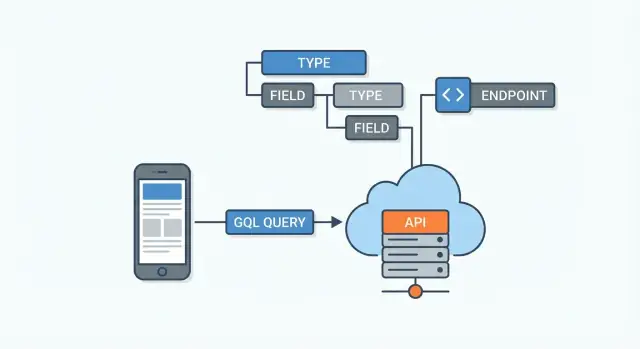
GraphQLスキーマ:API契約
GraphQL APIはスキーマによって定義されます。これはサーバとすべてのクライアント間の合意のようなもので、どんなデータがあってそれらがどう結びつき、何が要求・変更できるかを列挙します。クライアントはエンドポイントを推測するのではなく、スキーマを読み特定のフィールドを要求します。
スキーマの基本:型、フィールド、関係
スキーマは型(UserやPostなど)とフィールド(nameやtitleなど)で構成されます。フィールドは他の型を指すことができ、これがGraphQLでの関係性の表現です。
以下はSchema Definition Language(SDL)での簡単な例です:
type User {
id: ID!
name: String!
posts: [Post!]!
}
type Post {
id: ID!
title: String!
body: String
author: User!
comments: [Comment!]!
}
type Comment {
id: ID!
text: String!
author: User!
post: Post!
}
強い型付け=実行前の検証
スキーマが強い型付けを持つため、GraphQLはリクエストを実行する前に検証できます。クライアントが存在しないフィールド(例:Post.publishDate)を要求すると、サーバは不明瞭な挙動ではなく明確なエラーで拒否または部分的実行を返せます。
時間をかけて安全に進化させる
スキーマは拡張するように設計されています。通常、新しいフィールド(例:User.bio)は既存のクライアントを壊さずに追加できます。フィールドの削除や変更は敏感なので、多くのチームはまず非推奨(deprecate)にしてクライアントを段階的に移行させます。
クエリ:必要なものを正確に要求する
GraphQL APIは通常単一のエンドポイント(例:/graphql)で公開されます。複数のリソース用URL(例:/users、/users/123、/users/123/posts)を持つ代わりに、一ヶ所へクエリを送り必要なデータを詳述します。
フィールドの選択(ネストデータを含む)
クエリは基本的にフィールドの“買い物リスト”です。単純なフィールド(idやname)やネストしたデータ(ユーザーの最近の投稿など)を同じリクエスト内で要求でき、不要なフィールドをダウンロードする必要はありません。
小さな例:
query GetUserWithPosts {
user(id: "123") {
id
name
posts(limit: 2) {
id
title
}
}
}
予測可能なレスポンス形状
GraphQLのレスポンスは予測可能です:返ってくるJSONはクエリの構造を反映します。フロントエンドではデータがどこに現れるかを推測する必要がなく、異なるレスポンス形式をパースする手間が減ります。
単純化したレスポンス例:
{
"data": {
"user": {
"id": "123",
"name": "Sam",
"posts": [
{ "id": "p1", "title": "Hello GraphQL" },
{ "id": "p2", "title": "Queries in Practice" }
]
}
}
}
要求しなかったフィールドは含まれません。要求したフィールドは対応する場所に期待通り入るため、GraphQLは各画面や機能が必要とするデータを取得するのに適した方法です。
ミューテーション:安全にデータを書き換える
クエリが読み取り用なら、ミューテーションはGraphQL APIでデータを変更する方法です(作成、更新、削除)。
典型的なミューテーションの流れ
多くのミューテーションは同じパターンに従います:
- 入力:クライアントは更新するフィールドなどの構造化された入力(多くは
inputオブジェクト)を送る。\n2. 検証と認可:サーバは必須フィールド、データフォーマット、一意性、ユーザーの権限などをチェックする。\n3. 書き込み:サーバはデータベースを変更する(または別サービスを呼ぶ)。\n4. ペイロード/返却型:サーバはUIが更新できるように予測可能な結果の形を返す。
なぜミューテーションはデータを返すのか
GraphQLのミューテーションは通常意図的にデータを返します。単に “success: true” を返すよりも、更新されたオブジェクト(少なくとも id や主要フィールド)を返すほうがUIにとって有益です:
- 追加の往復なしで画面を即座に更新できる
- Apollo Clientのようなクライアントでキャッシュを安全に更新できる
- フィールドレベルのエラーを文脈内で表示できる
一般的な設計は、更新されたエンティティとエラーの両方を含む「ペイロード」型です。
基本的なミューテーション例
mutation UpdateEmail($input: UpdateUserEmailInput!) {
updateUserEmail(input: $input) {
user {
id
email
}
errors {
field
message
}
}
}
UIドリブンのAPIでは「次の状態を描画するのに必要なものを返す」というルールが良い指針です(例:更新された user と errors)。これによりクライアントは単純になり、何が変わったかを推測する必要がなく、失敗時の扱いも容易になります。
リゾルバ:GraphQLが結果を作る仕組み
ソースの完全な所有権を保持
準備ができたらいつでもフルソースをエクスポートして実装を自分のものにする。
スキーマは何が要求できるかを記述します。リゾルバは実際にそれをどう取得するかを記述します。リゾルバはスキーマの特定フィールドに紐づく関数で、クライアントがそのフィールドを要求するとGraphQLはそのリゾルバを呼び出します。
リゾルバはフィールドごとの関数
GraphQLは要求された形を辿ってクエリを実行します。各フィールドに対して対応するリゾルバを見つけ実行します。あるリゾルバは既にメモリにあるオブジェクトのプロパティを返すだけかもしれませんし、データベースを呼んだり別サービスを呼んだり、複数ソースを組み合わせたりすることもあります。
例えばスキーマに User.posts があれば、その posts リゾルバは userId で posts テーブルを照会するか、別の Posts サービスを呼ぶかもしれません。
スキーマのフィールドをデータソースにマッピングする
リゾルバはスキーマと実システムをつなぐ接着剤です:
- データベース:SQL/NoSQLクエリ、ストアドプロシージャ、ORM呼び出し\n- サービス:REST/gRPC呼び出し、内部マイクロサービス、サードパーティAPI\n- 計算フィールド:合計値、フォーマット、派生値
このマッピングは柔軟で、実装を変えてもクライアントが要求する形を変えない限りクエリには影響しません。
性能:遅いリゾルバチェーンを避ける
リゾルバはフィールド単位・リスト内アイテム単位で動くため、多数の小さな呼び出しを引き起こしやすく(例:100ユーザーの投稿を100回別々に取得)、これが遅延を生む「N+1」パターンになります。
よくある対処はバッチングとキャッシュ(例:IDを集めて一度にフェッチする)、およびクライアントに推奨するネストフィールドを意図的に制御することです。
認可と検証の配置
認可はしばしばリゾルバ(または共通ミドルウェア)で強制されます。リゾルバは誰が要求しているか(コンテキスト経由)と何のデータにアクセスしているかを知っているためです。検証は2階層で行われることが多く、GraphQLが型/形の検証を自動で行い、リゾルバがビジネスルール(例:「このフィールドは管理者のみ設定可能」)をチェックします。
エラーと部分結果
GraphQLに慣れていない人を驚かせる点の一つは、リクエストが“成功”しつつもエラーを含むことがあり得ることです。GraphQLはフィールド指向なので、あるフィールドは解決できて別のフィールドはできない、という状況で部分的なデータが返ることがあります。
エラーの見た目
典型的なGraphQLレスポンスは data と errors 配列の両方を含むことがあります:
{
"data": {
"user": {
"id": "123",
"email": null
}
},
"errors": [
{
"message": "Not authorized to read email",
"path": ["user", "email"],
"extensions": { "code": "FORBIDDEN" }
}
]
}
これは有用です:クライアントは持っているデータで表示を続けつつ(例:ユーザープロフィール)、欠けているフィールドを扱えます。
フィールドレベルのエラー vs リクエストレベルの失敗
- フィールドレベルのエラーは実行中に発生します(リゾルバが例外を投げる、権限チェックが失敗する、下流サービスがタイムアウトする等)。他のフィールドは解決できる場合があります。\n- リクエストレベルの失敗は実行を阻害します(無効なJSON、不正なクエリ、スキーマに対する検証エラー)。この場合、
dataはしばしばnullになります。
詳細を漏らさずユーザー向けメッセージを
エラーメッセージはデバッグ用ではなくエンドユーザー向けに書きます。スタックトレースやデータベース名、内部IDを露出させないでください。良いパターンは:
- 短く安全な
message\n- 安定した機械判読可能なextensions.code\n- 安全な範囲の任意のメタデータ(例:retryable: true)
詳細はサーバ側でリクエストIDと一緒にログに残し、内部調査に使います。
クライアント間での一貫した扱いのためのヒント
ウェブとモバイルが共有する小さなエラー「契約」を定義してください:共通の extensions.code 値(例:UNAUTHENTICATED、FORBIDDEN、BAD_USER_INPUT)、いつトーストを表示しいつフィールド内エラーを出すか、部分データをいつ表示するか等。ここを統一すると各クライアントが個別ルールを作るのを防げます。
サブスクリプション(リアルタイムアップデート)
まずスキーマを設計
プランニングモードを使って、コードを書く前に型・クエリ・ミューテーションを設計する。
サブスクリプションはデータが変化した際にサーバからクライアントへプッシュするGraphQLの方法です。通常は持続的な接続(多くはWebSocket)で配信され、サーバが変化を検知した瞬間にイベントを送れます。
サブスクリプションとは(仕組み)
サブスクリプションはクエリに似ていますが、結果は単一レスポンスではありません。結果のストリームであり、それぞれがイベントを表します。
内部では、クライアントがあるトピック(例:チャットの messageAdded)に“購読”します。サーバがイベントを発行すると、接続中の購読者はサブスクリプションの選択セットに一致したペイロードを受け取ります。
一般的なユースケース
サブスクリプションは即時性が求められる場面で力を発揮します:
- チャットメッセージが画面を更新せずに現れる\n- 通知(メンション、注文ステータス、アラート)\n- ライブダッシュボード(システムヘルス、物流、トレーディング、スポーツスコア)
サブスクリプションとポーリングの違い
ポーリングではクライアントが定期的に「何か新しいことは?」と尋ねます。単純だが何も変わらないときにリクエストが無駄になることがあり遅延も感じられます。
サブスクリプションではサーバが「更新です」と即座に通知します。これにより不要なトラフィックが減り体感速度は向上しますが、接続の維持やリアルタイムインフラの管理コストが増えます。
サブスクリプションが不要な複雑さになる場合
更新が稀である、時間的な厳しさがない、またはバッチ処理で十分な場合はサブスクリプションは要らないことが多いです。接続スケーリング、長時間接続の認可、リトライ、モニタリングなどの運用負担が増すため、リアルタイムがプロダクト要件である場合のみ導入を検討するのが良いルールです。
長所・短所・実践的なトレードオフ
GraphQLはしばしば「クライアントに力を与える」と言われますが、その力にはコストがあります。事前にトレードオフを理解しておくことで、GraphQLが適している場面と過剰な選択になる場面を判断できます。
GraphQLが得意な場面
最大の利点は柔軟なデータ取得です:クライアントが正確に必要なフィールドを要求でき、オーバーフェッチを減らしUIの変更を速くします。
もう一つの大きな利点はスキーマによる強い契約です。スキーマが型や利用可能な操作の単一の真実となり、共同作業やツールの活用を促進します。
フロントエンド開発者が新しいエンドポイントを待たずに反復できるためクライアント生産性が向上することも多く、Apollo Clientのようなツールは型生成やデータ取得の流れを簡素化します。
計画すべき一般的な欠点
GraphQLはキャッシュをより複雑にする場合があります。RESTではURLごとのキャッシュが使えることが多いですが、GraphQLでは多くのクエリが同一エンドポイントを共有するため、キャッシュはクエリ形状や正規化キャッシュ、サーバ/クライアントの設定に依存します。
サーバ側には性能の落とし穴があります。小さなクエリでも下流呼び出しが多数発生すると遅くなるため、リゾルバ設計(バッチング、N+1回避、高コストフィールドの管理)に注意が必要です。
また学習コストもあります:スキーマ、リゾルバ、クライアントパターンはエンドポイントベースのAPIに慣れたチームには新しい概念です。
セキュリティと運用
クライアントが多くを要求できるため、GraphQL APIではクエリの深さや複雑度制限を強制して誤用や悪意ある巨大リクエストを防ぐべきです。
認証と認可はルートレベルだけでなくフィールドごとに強制する必要があります。運用面ではGraphQLを理解するロギング、トレーシング、モニタリングに投資してください:操作名、変数(取り扱いに注意)、リゾルバごとの時間、エラー率などを追跡して遅いクエリや回帰を早期に検出します。
GraphQLとREST:違い
GraphQLとRESTはどちらもアプリとサーバの通信を助けますが、その会話の構造はかなり異なります。
RESTの典型的な振る舞い
RESTはリソースベースです。/users/123 や /orders?userId=123 のように複数のエンドポイントを呼び出してデータを取得します。各エンドポイントはサーバ側が決めた固定のデータ形を返します。
RESTはまたHTTPのセマンティクス(GET/POST/PUT/DELETE、ステータスコード、キャッシュルール)を活用します。単純なCRUDやブラウザ・プロキシキャッシュを多用したい場合には自然に感じられることが多いです。
GraphQLの振る舞い
GraphQLはスキーマベースです。多くのエンドポイントの代わりに通常1つのエンドポイントがあり、クライアントは欲しいフィールドを記述したクエリを送ります。サーバはそれをスキーマと照合して検証し、クエリ形状に一致するレスポンスを返します。
この“クライアント主導の選択”が、GraphQLがオーバーフェッチやアンダーフェッチを減らせる理由です。特に複数の関連モデルからデータを集めるUI画面向けに有効です。
RESTがよりシンプルになり得る場面
RESTが適していることが多い場面:
- ファイルのダウンロード/アップロード(ストリーミング、コンテンツタイプ、レンジリクエスト)\n- 主に単純なCRUDで予測可能なペイロードを扱う場合\n- エッジでのHTTPキャッシュへ強く依存し、既存のツールと最大限の互換性を保ちたい場合
ハイブリッドアプローチが一般的
多くのチームは両者を混在させます:
- UI重視のデータ取得にはGraphQLを使う\n- 認証コールバック、Webhook、ファイル処理、内部マイクロサービスのエンドポイントなどにはRESTを残す
実践的な問いは「どちらが優れているか」ではなく「このユースケースに最小の複雑さで合うのはどちらか」です。
GraphQL APIを設計する方法(初心者向けチェックリスト)
今日、最初のクエリを作る
1画面のデータ要件を数分で動作するGraphQL操作に変える。
GraphQL API設計は、データベースの鏡ではなく画面を作る人のためのプロダクトとして扱うと簡単です。小さく始め、実際のユースケースで検証し、必要に応じて拡張してください。
1)テーブルではなくUI画面から始める
主要な画面(例:「商品一覧」「商品詳細」「チェックアウト」)を列挙し、各画面が正確に必要とするフィールドとサポートする操作を書き出します。
これにより“ゴッドクエリ”を避け、オーバーフェッチを減らし、どこでフィルタやソート、ページングが必要かを明確にできます。
2)ドメイン型をモデリングし、操作は段階的に追加する
まずコア型(例:User、Product、Order)とその関係を定義します。それから:
- 実際の画面に合った小さなクエリ群\n- 実ユーザーアクションに合った小さなミューテーション群(例:「addToCart」「placeOrder」)
データベース名ではなくビジネス用語での命名を優先してください。placeOrderはcreateOrderRecordより意図が伝わりやすいです。
3)命名とページングの基本
命名を一貫させてください:単数はアイテム(product)、複数はコレクション(products)。ページングは通常どちらかを選びます:
- カーソルベース:変化の多いリストや「無限スクロール」に向く(安定)\n- オフセットベース:単純だがデータ変化時に項目のスキップや重複が起きる可能性あり
早めに方針を決めると応答構造が定まります。
4)構築しながらドキュメント化する
GraphQLはスキーマに説明を直接書けます—フィールド、引数、注意点に説明を付けましょう。ドキュメントにコピー&ペースト可能な例(ページングや一般的なエラーシナリオを含む)をいくつか追加してください。よく説明されたスキーマはイントロスペクションやAPIエクスプローラを非常に有用にします。
始め方:ツール、テスト、次のステップ
GraphQLを始めるには、よくサポートされたツールをいくつか選び、信頼できるワークフローを作ることが重要です。全部を一度に導入する必要はありません—まず一つのクエリをエンドツーエンドで動かし、それから拡張してください。
サーバフレームワークを選ぶ
スタックとどれだけ「電池付き」を望むかで選びます:
- Apollo Server:大きなエコシステムと良いドキュメントで人気の選択。\n- GraphQL Yoga:軽量でモダンなデフォルト、開発体験が良好。\n- NestJS:既にNestを使っている場合に、モジュール、DI、パターンと統合するのに最適。
実践的な第一歩は:小さなスキーマ(数個の型+1つのクエリ)を定義し、リゾルバを実装し、実際のデータソース(メモリ内のスタブでも可)と接続することです。
さらに素早くアイデアから動くAPIへ進めたい場合は、Koder.ai のようなvibe-codingプラットフォームが、フロントエンドはReact、バックエンドはGo + PostgreSQLといった小さなフルスタックアプリをスキャフォールドし、チャットでスキーマ/リゾルバを反復して実装をエクスポートするのに役立ちます。
クライアントアプローチを選ぶ
フロントエンドでは、意見の強い規約を望むか柔軟性を望むかで選びます:
- Apollo Client:広く使われており強力なキャッシュと開発ツールを提供。\n- Relay:より厳格なパターン、大きなアプリで整合性を重視する場合に向く。\n- urql:小さく構成可能で、細かく制御したいチームに適する。
RESTから移行する場合は、まず1つの画面や機能をGraphQL化し、残りはRESTのままにしておくと良いでしょう。
テスト:スキーマ+リゾルバ+統合
スキーマをAPI契約として扱ってください。役立つテスト層は:
- スキーマ検証(CIでスキーマをビルドし、無効な型で失敗させる)\n- リゾルバの単体テスト(データソースをモックして境界ケースと認可ルールを検証)\n- 統合テスト(テストサーバとテストDBに対して実際のGraphQL操作を実行)
次のステップ
理解を深めるために次に進みましょう:
- /blog/graphql-vs-rest
- /blog/graphql-schema-design
よくある質問
GraphQLを簡単に説明すると何ですか?
GraphQLはAPIのためのクエリ言語とランタイムです。クライアントは欲しいフィールドを正確に記述するクエリを送信し、サーバはその形に対応したJSONレスポンスを返します。
クライアントと複数のデータソース(データベース、RESTサービス、サードパーティAPI、マイクロサービスなど)の間に置かれるレイヤーとして考えると分かりやすいです。
固定されたRESTエンドポイントと比べてGraphQLはどんな問題を解決しますか?
GraphQLは主に次の問題を解決します:
- オーバーフェッチ:画面が必要としないフィールドまで取得してしまう。\n- アンダーフェッチ:1つの画面に必要なデータを得るために複数のリクエストが必要になる。
クライアントが特定のフィールド(ネストしたフィールドを含む)だけを要求できるため、不要なデータ転送を減らしクライアント側のコードを簡素化できます。
GraphQLは何ではないのですか?
GraphQLは次のものではありません:
- データベース(データを保存するものではない)
- 自動的に高速になる仕組み(転送量を減らせるが、サーバ側の処理コストは別)
- “REST 2.0”(別の設計思想を持つAPIスタイル)
APIの契約(スキーマ)とその実行エンジンだと考えてください。性能やストレージの魔法ではありません。
なぜGraphQLは単一のエンドポイントを使うことが多いのですか?
多くのGraphQL APIは単一のエンドポイント(たとえば /graphql)を公開します。複数のURLを用意する代わりに、そこへ様々な操作(クエリやミューテーション)を送ります。
実務上は、キャッシュや可観測性は通常URLではなく操作名+変数に基づくことが多いです。
GraphQLスキーマとは何で、なぜ重要ですか?
スキーマはAPIの契約です。次を定義します:
- 型(例:
User、Post) - それらの型のフィールド(例:
User.name) - 型同士の関係(例:
User.posts)
スキーマはを持つため、クエリは実行前に検証でき、存在しないフィールド要求に対して明確なエラーを返せます。
GraphQLのクエリはどう機能しますか?
GraphQLのクエリは読み取り操作です。必要なフィールドを指定し、レスポンスのJSONはクエリ構造と一致します。
ヒント:
- 操作に名前を付ける(例:
query GetUserWithPosts)とデバッグやモニタリングが楽になります。\n- 引数で結果の成形(例:posts(limit: 2))を行います。
GraphQLのミューテーションはどのように動作し、なぜデータを返すのですか?
ミューテーションは書き込み操作(作成・更新・削除)です。一般的なパターンは:
inputオブジェクトを送る- サーバで検証と認可を行う
- 書き込みを実行する
- 更新されたデータやエラーを含むペイロードを返す
単に success: true を返すのではなくデータを返すことで、UIは追加の往復なしに状態を更新でき、キャッシュの整合性も保ちやすくなります。
リゾルバとは何で、認可やビジネスルールはどこに置くことが多いですか?
リゾルバは各フィールドに付随するフィールドレベルの関数で、どうやってそのフィールドの値を取得・計算するかを定義します。
実際にはリゾルバは:
- データベースを照会したり
- 別の内部サービスやサードパーティAPIを呼んだり
- 派生値を計算したりします。
認可やビジネスルールはリゾルバ(またはそれを横断するミドルウェア)で行われることが多いです。
N+1のような一般的なGraphQLの性能問題をどう避けますか?
典型的なN+1問題(たとえば100人のユーザーそれぞれの投稿を個別クエリで取得してしまう)は発生しやすいです。
一般的な対策:
- バッチ取得(IDを集めて一度にフェッチする)
- キャッシュ(リクエスト内キャッシュや共有キャッシュ)
- 高コストなネストフィールドへのリクエストを抑制する設計
リゾルバの実行時間を計測し、1回のリクエストでどの程度下流呼び出しが繰り返されているかを監視してください。
なぜGraphQLのレスポンスにはデータとエラーが両方含まれることがあるのですか?
GraphQLは部分データと errors 配列を同時に返すことがあります。これはあるフィールドは解決でき、別のフィールドはエラーになった場合に有用です。
良い実践:
- エンドユーザー向けの安全な短い を返す