2025年6月05日·2 分
顧客導入ヘルススコアを監視するWebアプリの作り方
プロダクト利用を追跡し、導入ヘルススコアを算出してチームにリスクを通知するWebアプリの作り方。ダッシュボード、データモデル、計測・スコアリング・アラートのベストプラクティスを紹介します。
目的と採用(Adoption)シグナルの定義
顧客導入ヘルススコアを作る前に、そのスコアがビジネスに対して何をするべきかを決めてください。解約リスクアラートのためのスコアは、オンボーディングや顧客教育、プロダクト改善を導くためのスコアとは見え方が変わります。
自社プロダクトにおける「導入」を定義する
導入は単に「最近ログインした」ではありません。顧客が価値に到達していることを示す本質的な行動をいくつか書き出してください:
- 活性化(Activation): ユーザーが意味ある成果に初めて到達した瞬間(例:「チームメンバーを招待した」「データソースを接続した」「レポートを公開した」)。
- コアアクション: 成功アカウントと相関する再現可能で高シグナルな行動(例:週次のエクスポート、オートメーションの実行、複数ユーザーによって閲覧されたダッシュボード)。
- 継続(Retention): 製品にとって適切な頻度での継続利用(日次/週次/月次)、理想的にはアカウント内の複数ユーザーにまたがるもの。
これらが、機能利用分析や後のコホート分析のための初期の採用シグナルになります。
アプリで有効にしたい意思決定を列挙する
スコアが変化したときに何が起きるかを明確にしてください:
- 閾値を下回ったときに誰に通知されるか?
- どのプレイブックを起動するか(アウトリーチ、トレーニング、サポートのチェックイン)?
- プロダクト導入監視にどのようなインサイトが必要か(摩擦点、未使用機能、Time-to-value)?
決定が特定できない指標は、まだ追跡しないでください。
ユーザー、役割、時間窓を特定する
カスタマーサクセスダッシュボードを誰が使うかを明確にします:
- CSマネージャー は優先順位付けとアカウントコンテキストを必要とします。
- プロダクト はパターン、コホート、機能レベルの動きを必要とします。
- サポート はチケットやインシデント周りの最近のアクティビティを必要とします。
- 経営陣 は理解しやすい集計とトレンドを必要とします。
標準的なウィンドウ(過去7/30/90日)を選び、ライフサイクルステージ(トライアル、オンボーディング、定常、更新)を考慮してください。これにより新規アカウントと成熟アカウントを比較する誤りを避けられます。
成功基準を設定する
ヘルススコアモデルの「完了」を定義します:
- 精度: 現状の手法よりリスクや拡張のシグナルを予測できるか?
- 説明可能性: CSMが1分で「なぜ高い/低いか」を説明できるか?
- 使いやすさ: 時間を節約し、一貫したアクションを促すか?
これらの目標が下流のすべて(イベントトラッキング、スコアリングロジック、スコア周りのワークフロー)を形づくります。
ヘルススコアに使う指標の選定
指標の選び方で、ヘルススコアが有益なシグナルになるか、ノイズだらけの数値になるかが決まります。活動量だけでなく実際の導入を反映する少数の指標を目指してください。
プロダクト導入のシグナルから始める
ユーザーが繰り返し価値を得ているかを示す指標を選びます:
- ログイン/アクティブユーザー: 例:週次アクティブユーザー(WAU)と過去4–8週間のトレンド。
- アクティブ日数: 週/月で何日活動があったか(「一度の長時間セッション」を誤検知しないため)。
- 機能の深さ(Feature depth): 全てのクリックではなく、「価値を生む」機能の利用。
- 接続済みの連携: 連携がスイッチングコストを増やしたり、重要ワークフローを解放する場合は重要。
- シート利用率: 購入済みシートのうち招待されアクティブな割合。
リストは集中させてください。なぜその指標が重要かを一文で説明できないなら、コア入力ではない可能性が高いです。
ビジネスコンテキストを付与する(不公平にならないため)
導入はコンテキストで解釈されるべきです。3シートのチームと500シートの展開では振る舞いが異なります。
一般的なコンテキストシグナル:
- プラン階層 と機能権限
- 契約規模/ARR帯
- ライフサイクルステージ: トライアル、中〜長期、有効期限が近いか
これらは必ずしも「ポイントを加算する」必要はありませんが、セグメントごとに現実的な期待値と閾値を設定するのに役立ちます。
先行指標と遅行指標を決める
有用なスコアは次の混合です:
- 先行指標(将来の成功を予測): アクティブ日数の増加、オンボーディング完了、最初の連携接続。
- 遅行指標(結果を確認): リニューアル、拡張、長期定着。
遅行指標を過重評価しすぎないでください。彼らはすでに起きたことを語るだけです。
任意:定性的入力(注意して使う)
利用可能であれば、NPS/CSAT、サポートチケット数、CSMノートはニュアンスを加えることができます。これらは修飾子やフラグとして使い、基盤にするのは避けてください。定性的データは疎で主観的になりがちです。
シンプルなデータ辞書を作る
チャートを作る前に名前と定義を合わせましょう。軽量なデータ辞書には次を含めます:
- メトリクス名(例:
active_days_28d) - 明確な定義(何がカウントされ、何がカウントされないか)
- 時間ウィンドウと更新頻度
- ソースシステム(プロダクトイベント、CRM、サポート)
これにより、ダッシュボードやアラートを実装するときの「同じ指標なのに意味が違う」混乱を防げます。
説明可能なヘルススコアモデルの設計
チームが信頼できるスコアでないと意味がありません。CSMに1分で、顧客に5分で説明できるモデルを目指してください。
まずは単純に:重み付きポイント(MLの前に)
透明性のあるルールベースのスコアから始めます。少数の採用シグナル(例:アクティブユーザー数、主要機能の利用、連携の有無)を選び、プロダクトの“aha”に合わせて重みを割り当てます。
例(重み付け):
- 週間アクティブユーザー/シート: 0–40ポイント
- 主要機能の利用頻度: 0–35ポイント
- 利用機能の幅: 0–15ポイント
- 最後の意味あるアクティビティからの時間: 0–10ポイント
重みは擁護しやすい値にしてください。完璧を待たず、後で見直せます。
バイアスを減らすための正規化
生のカウントだと小さなアカウントを罰し、大きなアカウントを過度に平坦化します。必要な箇所で正規化を行いましょう:
- シートあたり(使用量/ライセンスシート)
- アカウント年齢別(新規 vs 成熟)
- プラン階層別(機能可用性)
これによりスコアがサイズではなく行動を反映します。
グリーン/イエロー/レッドを理由とともに定義する
閾値を設定します(例:Green ≥ 75, Yellow 50–74, Red < 50)と、その各カットオフの理由を文書化してください。閾値は期待される成果(リニューアルリスク、オンボーディング完了、拡張準備など)に紐づけます。メモは内部ドキュメントや /blog/health-score-playbook に保存してください。
説明可能にする:寄与因子とトレンドを見せる
各スコアは次を表示すべきです:
- 上位3つの寄与因子(何が助けた/損なったか)
- 時間による変化(過去7/30日)
- 平易な要約(「機能Xの利用が前週比35%減少」など)
反復の計画:モデルにバージョンを付ける
スコアリングをプロダクトとして扱ってください。バージョン管理(v1, v2)を行い、影響を測定します:解約リスクアラートの精度は上がったか?CSMはより早く行動したか?各計算にモデルバージョンを保存し、時間経過で結果を比較できるようにします。
プロダクトイベントとデータソースの計測
ヘルススコアは裏にあるアクティビティデータが信頼できることが前提です。スコアリングロジックを作る前に、正しいシグナルが一貫してキャプチャされていることを確認してください。
イベントソースの選択
多くの導入プログラムは次の混合から引きます:
- フロントエンドイベント(ページビュー、クリック、機能操作)
- バックエンドアクション(APIコール、ジョブ完了、レコード作成)
- 請求(プラン、更新、支払い状況、シート数)
- サポート/サクセスツール(チケット、CSAT、オンボーディングマイルストーン)
実用的なルール:重要なアクションはサーバーサイドで追跡(改ざんしにくく、広告ブロッカーの影響を受けにくい)し、フロントエンドはUIエンゲージメントや発見のために使うとよいです。
明確なイベントスキーマを定義する
イベントを簡単に結合、クエリ、説明できるように一貫した契約を保ちます。一般的なベースライン:
event_nameuser_idaccount_idtimestamp(UTC)properties(feature, plan, device, workspace_id など)
event_name は制御語彙(例:project_created, report_exported)を使い、トラッキングプランに文書化してください。
SDK vs サーバーサイド(あるいは両方)の判断
- SDKトラッキング は迅速に導入でき、UIイベントに適しています。
- サーバーサイドトラッキング はシステムオブレコード的なアクションに適しています。
多くのチームは両方を使いますが、同じ実世界のアクションを二重計上しないように注意してください。
アイデンティティの扱いを正しく行う
ヘルススコアは通常アカウントレベルに集約されるので、信頼できるユーザー→アカウントのマッピングが必要です。次の点を計画してください:
- ユーザーが複数アカウントに所属するケース
- アカウントのマージ(買収、ワークスペース統合)
- ログイン前の匿名行動に対する匿名ID(サインアップ後に安全にマージ)
データ品質チェックを組み込む
最低限、欠損イベント、重複バースト、タイムゾーンの一貫性(UTCで保存し表示用に変換)を監視してください。トラッキングが壊れているために解約リスクアラートが発火しないよう、異常を早期にフラグ化します。
データのモデリングとストレージ
顧客導入ヘルススコアアプリは「誰がいつ何をしたか」をどれだけうまくモデル化しているかにかかっています。共通の質問に高速に答えられることが目標です:今週このアカウントはどうか?どの機能が上昇/下降しているか?良いデータモデリングはスコアリング、ダッシュボード、アラートをシンプルに保ちます。
モデル化すべきコアエンティティ
小さな“ソース・オブ・トゥルース”テーブルから始めます:
- Accounts: account_id, plan, segment, lifecycle stage, CSM owner
- Users: user_id, account_id, role/persona, created_at, status
- Subscriptions / Contracts: account_id, start/end, seats, MRR, renewal date
- Features: feature_id, name, category(activation, collaboration, admin 等)
- Events: event_id, account_id, user_id, feature_id(nullable), event_name, timestamp, properties
- Scores: account_id, score_date(または computed_at), overall_score, component scores, explanation fields
これらのエンティティでは安定したID(account_id, user_id)を一貫して使ってください。
ストレージの分離:リレーショナル + 分析
アカウント/ユーザー/サブスクリプション/スコアのような頻繁に更新・結合するものは**リレーショナルDB(例:Postgres)**に、
高ボリュームなイベントはデータウェアハウス/分析ストア(BigQuery/Snowflake/ClickHouse 等)に保存します。これによりダッシュボードやコホート分析の応答性を確保し、トランザクションDBへの負荷を避けられます。
高速化のための集計保存
生イベントからすべてを再計算する代わりに、次を維持します:
- 日次アカウントサマリ(アカウント×日単位):アクティブユーザー数、主要イベント数、最終アクティビティ、導入マイルストーン
- 機能カウンタ: アカウント/日/機能ごとの使用回数、ユニークユーザー数、滞在時間(ある場合)
これらのテーブルがトレンドチャート、「何が変わったか」インサイト、ヘルススコアの構成要素を支えます。
レテンション、パーティショニング、クエリ性能
大規模イベントテーブルは保持期間(例:生データ13ヶ月、集計はより長く)を計画し、日付でパーティションしてください。account_id と timestamp/date でクラスタ/インデックスを作ると「アカウントの時間変化」クエリが速くなります。
リレーショナルテーブルでは、一般的なフィルタやジョインに対してインデックスを作成してください:account_id、サマリには (account_id, date) のインデックス、そして外部キーでデータをきれいに保ちます。
Webアプリのアーキテクチャ設計
アプリの骨格を生成
エンティティと画面を記述すると、Koder.ai が React の UI と Go のバックエンドを生成します。
アーキテクチャは v1 を容易に出荷し、その後の拡張ができるように設計してください。初期は本当に必要な構成要素の数を減らすことが重要です。
モノリス vs サービス(v1はシンプルに)
多くのチームにとって、モジュール化されたモノリスは最速の道です:インジェスト、スコアリング、API、UI といった境界を明確にした単一コードベースでデプロイを少なくし、運用上の問題を減らします。
独立したスケーリング要件、厳格なデータ分離、別チームによる所有など明確な理由が出ない限り、早すぎるマイクロサービス化は障害点を増やし、反復を遅くします。
コアコンポーネントを定義する
最小限で次の責任を計画してください(最初は一つのアプリに含めても構いません):
- Ingestion: プロダクトイベントを受け取る(SDK、Segment、Webhook、バッチインポート)
- Aggregation: 生イベントを日次/週次の使用ファクトに変換する
- Scoring: 顧客導入ヘルススコアと説明を計算する
- API: スコア、トレンド、「なぜ」をUIや外部統合に提供する
- UI: アカウントビュー、コホート、ドリルダウンを備えたカスタマーサクセスダッシュボード
迅速なプロトタイプには、vibe-coding 的なアプローチが有効です。例えば Koder.ai は entities(accounts, events, scores)、エンドポイント、画面の簡単なチャット説明から React ベースの UI と Go + PostgreSQL のバックエンドを生成できます。これにより CS チームが早期に反応できる v1 を立ち上げる手助けになります。
スケジュールバッチ vs ストリーミング
導入監視ではバッチスコアリング(時間単位や夜間)が通常十分で、運用もシンプルです。ストリーミングはリアルタイムアラート(急激な利用低下)や非常に高いイベントボリュームが必要な場合に意味を持ちます。
実用的なハイブリッド:イベントを継続的にインジェストし、集約/スコアリングをスケジュールで行い、リアルタイムが必要な少数のシグナルだけをストリーミングで処理します。
環境、シークレット、非機能要件
dev/stage/prod を早期に設定し、ステージにサンプルアカウントを用意してダッシュボードを検証します。マネージドなシークレットストアを使い、資格情報をローテーションしてください。
事前に要件を文書化します:期待イベント量、スコアの鮮度(SLA)、APIレスポンスタイム、可用性、データ保持、プライバシー制約(PIIの扱いとアクセス制御)など。これにより、遅れて圧力のかかる状況での設計判断を防げます。
データパイプラインとスコアリングジョブの構築
ヘルススコアはそれを生成するパイプラインの信頼性に依存します。スコアリングを再現可能で観測可能にし、「なぜこのアカウントが今日下がったのか?」という質問に答えられるように扱ってください。
単純なパイプライン:raw → validated → aggregates
狭めて行く段階的フローから始めます:
- Raw events: アプリ、モバイル、連携、請求/CRMのエクスポートからの追記型インジェスト
- Validated events: スキーマチェック(必須フィールド、型)、アイデンティティチェック(user→account マッピング)、重複除去を通過したイベント
- Daily aggregates: アカウント別のロールアップ(アクティブユーザー、主要イベント数、TTVマイルストーン、トレンド差分)
こうすることで、スコアリングは巨大な生行からではなく、クリーンでコンパクトなテーブル上で動くため、速く安定します。
再計算スケジュールとバックフィル
スコアの「鮮度」を決めてください:
- 毎時スコアは CSM の早急な対応が必要な場合に有効
- 日次スコアは SMB/セルフサーブに十分でコストも抑えられます
スケジューラはバックフィル(過去30/90日の再処理)をサポートし、トラッキング修正や重みの変更時に対応できるようにします。バックフィルは緊急スクリプトではなく第一級の機能としてください。
冪等性:二重カウントを避ける
ジョブは再試行され、インポートは再実行され、Webhook は二度届くことがあります。これに耐える設計にします。
- イベント用の冪等キー(event_id または timestamp + user_id + event_name + properties の安定ハッシュ)を使い、validated 層で一意性を保持
- 集計は
(account_id, date)で upsert し、再計算が以前の結果を置き換えるようにする
監視と異常チェック
次を監視してください:
- ジョブの成功/失敗 と再試行回数
- データ遅延(最新の集計がどれだけ「現在」から遅れているか)
- ボリューム異常(イベントの急な減少/増加、主要アクションの減少)
簡単な閾値(例:「イベントが7日平均に比べて40%減少」)でも、ダッシュボードを誤導する静かな障害を防げます。
各スコアの監査トレイル
アカウント×スコア実行ごとに監査記録を保存します:入力メトリクス、導出フィーチャ(週間差分など)、モデルバージョン、最終スコア。CSMが「なぜ?」をクリックしたときに、ログを逆にたどることなく何が変わったかを示せます。
ヘルスとインサイトのための安全なAPI作成
コードベースを所有
カスタマイズする準備ができたらソースコードをエクスポートして、完全にコントロールできます。
アプリはAPIが契約です。スコアリングジョブ、UI、下流ツール(CSプラットフォーム、BI、データエクスポート)をつなぐ契約として、速く、予測可能で、安全なAPIを目指してください。
実務を支えるコアエンドポイント
CSが導入を探索する方法に合わせてエンドポイントを設計します:
- Account health:
GET /api/accounts/{id}/healthは最新スコア、ステータスバンド(例:Green/Yellow/Red)、最終計算時刻を返す。 - Trends:
GET /api/accounts/{id}/health/trends?from=&to=はスコアの時系列と主要メトリクスの差分を返す。 - Drivers(「なぜ」):
GET /api/accounts/{id}/health/driversは主要な正/負の要因(例:「週間アクティブシートが35%低下」)を返す。 - Cohorts:
GET /api/cohorts/health?definition=はコホート分析とピアベンチマークを提供。 - Exports:
POST /api/exports/healthは一貫したスキーマでCSV/Parquetを生成する。
フィルタ、ページング、キャッシュ
リスト系エンドポイントをスライスしやすくします:
- フィルタ:
plan,segment,csm_owner,lifecycle_stage,date_rangeが基本 - ページング:データが変化しても安定するカーソルベースのページング(
cursor,limit)を使う - キャッシュ:重いクエリ(コホートロールアップ、トレンド系列)をキャッシュし、
ETag/If-None-Matchを返して繰り返し読み込みを減らす。キャッシュキーはフィルタと権限を意識して作る
ロールベースのアクセス制御でセキュリティを確保
アカウントレベルでデータを保護します。RBAC(例:Admin, CSM, Read-only)を実装し、すべてのエンドポイントでサーバー側により強制してください。CSM は自分が所有するアカウントのみを見られるべきで、ファイナンス系はプランレベルの集計は見られてもユーザーレベルの詳細は見られないといった権限分離を行います。
常に説明可能性を返す
数値の顧客導入ヘルススコアとともに「なぜ」フィールド(上位ドライバ、影響を受けたメトリクス、比較ベースライン:前期間やコホート中央値)を返してください。これによりプロダクト導入監視が単なる報告で終わらず、行動につながります。
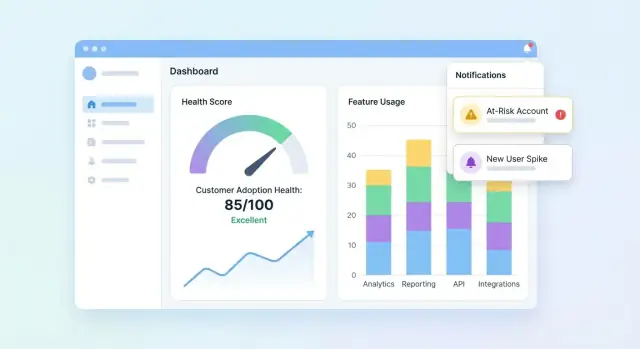
ダッシュボードとアカウントビューの設計
UIは3つの質問に短時間で答えるべきです:誰が健全か?誰が滑っているか?なぜか? まずはポートフォリオを要約するダッシュボードを作り、ユーザーがアカウントへドリルダウンしてスコアの背景を理解できるようにします。
ポートフォリオダッシュボードの必須要素
CSチームが数秒でスキャンできるコンパクトなタイルとチャートを含めてください:
- スコア分布(ヒストグラムまたは Healthy / Watch / At-risk のバケット)
- At-risk リスト(アカウント、オーナー、スコア、最終アクティビティ、上位ドライバなど、行動に必要な最小限のフィールド)
- スコアの時間的推移(ラインチャート)とセグメントフィルタ
At-risk リストはクリック可能にして、ユーザーがアカウントを開いてすぐに何が変わったか見られるようにします。
アカウントビュー:スコアを説明する
アカウントページは導入のタイムラインのように読むべきです:
- タイムライン(オンボーディング完了、連携接続、管理者変更、主要機能の初回使用など)
- 主要メトリクス(アクティブユーザー、主要機能アクション、最後の意味あるアクティビティまでの時間)
- 機能別採用の内訳(どの機能が採用され、無視され、後退しているか)
“Why this score?” パネルを追加し、スコアをクリックすると寄与シグナル(正負)と平易な説明が表示されるようにしてください。
コホート/セグメントビュー
チームがアカウントを管理する方法に合わせたコホートフィルタを提供します:オンボーディングコホート、プラン階層、業界。各コホートにトレンドラインとトップムーバーの小さなテーブルを添えて、結果を比較しパターンを発見できるようにします。
アクセシブルで信頼できるビジュアル
ラベルと単位を明確にし、曖昧なアイコンは避け、色に依存しないステータス表示(テキストラベル+形状)を提供してください。チャートを意思決定ツールとして扱い、スパイクに注釈を付け、日付レンジを表示し、ページ間のドリルダウン挙動を一貫させます。
アラート、タスク、ワークフローの追加
ヘルススコアはアクションを生み出して初めて有用です。アラートとワークフローは「興味深いデータ」をタイムリーなアウトリーチやオンボーディング修正、プロダクトナッジに変えます。ダッシュボードを四六時中見張る必要はありません。
実際のリスクに結びつくアラートルールを定義する
まずは高シグナルなトリガーの小さなセットから始めます:
- スコアの急落(例:週間で15ポイント低下)
- レッドステータス(重要閾値を越えた)
- 突然の利用低下(主要機能の利用が基準を下回る)
- オンボーディングステップの失敗(チェックリストが停止、連携未完了)
すべてのルールを明確かつ説明可能にします。「ヘルスが悪い」とだけ通知するのではなく、「機能Xが7日間で無活動かつオンボーディング未完了」のように具体化してください。
チャネルを選び、設定可能にする
チームによって働き方が異なるため、チャネルサポートと設定を用意します:
- メール:アカウントオーナーとマネージャー向け
- Slack:チームの可視性と迅速な対応
- インアプリタスク:カスタマーサクセスダッシュボード内で作業が見失われないように
各チームが誰に通知するか、どのルールを有効にするか、どの閾値を「緊急」とみなすかを設定できるようにします。
ノイズを減らすガードレール
アラート疲れは導入監視を破壊します。次のような制御を追加してください:
- クールダウンウィンドウ(同じアカウントに対してN時間/日で再通知しない)
- 最小データ閾値(最近のデータが少なすぎるアカウントはスキップ)
- バッチ/ダイジェスト(緊急でないシグナルは日次/週次のまとめで通知)
コンテキストと次のステップを付ける
各アラートは次を回答するべきです:何が変わったか、なぜ重要か、次に何をするか。最近のスコアドライバ、短いタイムライン(例:過去14日)、推奨タスク(「オンボーディングコールを設定」や「連携ガイドを送付」など)を含め、アカウントビュー(例:/accounts/{id})へリンクします。
結果を追跡してループを閉じる
アラートを作業項目として扱い、ステータスを持たせます:acknowledged(確認済), contacted(連絡済), recovered(回復), churned(解約)。成果をレポートすることでルールを改善し、プレイブックを磨き、ヘルススコアが実際に定着率に寄与していることを証明できます。
データ品質、プライバシー、ガバナンスの確保
モデルを明確に計画
コーディング前にイベント・指標・閾値を整理し、その設計から一気に構築します。
ヘルススコアが信頼できるデータに基づいていなければ、チームはそれを信頼せず、行動もしなくなります。品質、プライバシー、ガバナンスは副次的なものではなくプロダクトの機能として扱ってください。
自動化されたデータチェックを導入する
受け渡しポイントごと(ingest → warehouse → scoring output)で軽量な検証を行います。高シグナルなテストが多くの問題を早期に検出します:
- スキーマチェック: 期待する列が存在するか、型が変わっていないか、列挙型が有効か
- 範囲チェック: 不可能な値(負のセッション数、未来のタイムスタンプ)を失敗させる
- Nullチェック: 必須フィールド(account_id, event_name, occurred_at)が空でないか
テストが失敗したときはスコアリングジョブをブロックするか、結果に「stale(古い)」フラグを付けて、壊れたパイプラインが静かに誤った解約リスクアラートを出さないようにします。
よくある例外ケースを明示的に扱う
ヘルススコアは「奇妙だが普通な」状況で崩れます。次のルールを定義してください:
- データが少ない新規アカウント: 「データ不足」を表示するか、ランプアップ用のベースラインを使う(低スコアを付けない)
- 季節性のある利用: 普遍的な閾値ではなく、そのアカウントの過去期間やコホート比較を使う
- アウトージやトラッキングギャップ: 影響を受けたウィンドウをフラグ化し、自社のダウンタイムで顧客を罰しない
権限とプライバシー制御を追加する
PIIはデフォルトで制限してください:プロダクト導入監視に必要なものだけを保存し、ウェブアプリでは役割ベースのアクセスを適用し、誰がデータを閲覧/エクスポートしたかをログに残し、エクスポート時には不要フィールドをマスクしてください(例:CSVでメールを隠す)。
ランブックとガバナンス習慣を作る
インシデント対応の短いランブックを書いてください:スコアリングの一時停止方法、データのバックフィル、歴史的ジョブの再実行手順など。顧客成功メトリクスとスコア重みを定期(毎月または四半期)でレビューして、プロダクトの進化に伴うドリフトを防ぎます。プロセス整合のために内部チェックリストを /blog/health-score-governance にリンクしてください。
ヘルススコアの検証、反復、スケール
検証はヘルススコアが「見栄えの良いチャート」から「行動を促す信頼できる指標」へ変わる場所です。最初のバージョンは仮説として扱い、確定答えではありません。
パイロットを実行し、人的判断と較正する
まずはパイロットアカウント群(例:セグメントごとに20–50アカウント)で開始します。各アカウントについて、スコアとリスク理由をCSMの評価と比較してください。
探すべきパターン:
- CSMの評価より一貫して高すぎる/低すぎるスコア(キャリブレーション)
- 誤警報(高リスクだが実際は問題ない)と 見逃し(スコアは健全だが解約する)
- 実際の状況と合わない理由(説明可能性のギャップ)
実際に役立っているかを測る
精度は重要ですが、使いやすさが投資対効果を決めます。次の運用結果を追いかけてください:
- リスク検出の早さ(問題をどれだけ早く検知できたか)
- アウトリーチ成功率(リスクと判定されたアカウントのうち改善した割合)
- 解約削減のプロキシ指標(リニューアル可能性の変化、拡張シグナル、サポート負荷の変化)
バージョン管理で安全に変更をテストする
閾値や重み、新しいシグナルを追加するときは新しいモデルバージョンとして扱います。A/B テストを同等のコホートやセグメントで行い、ヒストリカルバージョンを保存してスコアが変わった理由を説明できるようにしてください。
UI内でフィードバックを集める
「スコアが間違っているように感じる」ボタンと理由(例:「最近のオンボーディング完了が反映されていない」「利用は季節的」「アカウントのマッピングが誤っている」)を軽量に追加してください。このフィードバックをバックログに送ってアカウントとスコアバージョンにタグ付けし、デバッグを速めます。
ロードマップとともにスケールする
パイロットが安定したらスケール計画を立てます:CRM/請求/サポートとの深い連携、プラン/業界/ライフサイクル別のセグメンテーション、自動化(タスクとプレイブック)、非エンジニアが設定をカスタマイズできるセルフサーブ化など。
スケール時にもビルド/反復ループを維持してください。多くのチームは Koder.ai を使って新しいダッシュボードページの立ち上げ、API 形状の改良、ワークフロー機能(タスク、エクスポート、ロールバック可能なリリース)の追加をチャットから直接行い、スコアモデルのバージョン管理と UI+バックエンド変更を迅速に進めています。
よくある質問
カスタマー導入(adoption)ヘルススコアはビジネスに対して何をすべきですか?
まず、スコアの目的を定義してください:
- 解約リスクアラート(スリップしているアカウントを特定)
- オンボーディング支援(セットアップ手順の優先付け)
- プロダクト改善(摩擦点や未使用機能の発見)
スコアが変化したときに意思決定が変わらないメトリクスは、まだ追跡しないでください。
自社プロダクトで「導入(adoption)」をどう定義すればよいですか?
顧客が価値を得ていることを証明する少数の行動を書き出してください:
- Activation(活性化):最初の意味のある成果(例:チームメンバーを招待、データソースを接続)
- Core actions(コアな操作):成功アカウントと相関する再現可能な行動
- Retention cadence(継続利用の頻度):週次/月次での継続利用(理想は複数ユーザーによる利用)
ログインだけを「最近ログインした」に定義しないでください。ログインが価値に直結する場合のみ例外です。
ヘルススコアにどの指標を入れるべきですか?
少数の高シグナル指標から始めてください:
- 週次アクティブユーザー(WAU)とそのトレンド
- アクティブ日数(1回の長時間セッションを誤検知しないため)
- キー機能の利用頻度(価値を生む機能)
- 接続済みの連携(ワークフローを解放し離脱障壁を高めるもの)
- シート利用率(招待済み/活性化済み/実際に活動しているシートの割合)
一文で重要性を説明できないメトリクスはコア入力ではない可能性があります。
小規模アカウントと大規模アカウントに対してスコアを公平に保つには?
公平にするために正規化とセグメンテーションを行ってください:
- シートあたりで正規化(使用量/ライセンス済シート)
- アカウント経過時間で調整(新規か成熟か)
- プラン階層/権限で閾値を分ける、ARR帯でのセグメント化
これにより生のカウントが小さいアカウントを不利に扱ったり、大きいアカウントを過剰に有利にすることを避けられます。
ヘルススコアにおけるリーディング指標とラギング指標の違いは?
リーディング指標は早めの行動を促し、ラギング指標は結果を確認します。
- リーディング:アクティブ日数の増加、オンボーディング完了、初回連携接続
- ラギング:更新(リニューアル)、拡張、長期維持
早期警告が目的ならラギング指標に比重を置きすぎないでください。ラギングは主に検証とキャリブレーションに使いましょう。
機械学習を使わずに説明可能なスコアモデルをどう作る?
まずは透明性のある加重ポイント方式から始めましょう。例の構成要素:
- WAU(シートあたり): 0–40
- キー機能の頻度: 0–35
- 利用機能の広がり: 0–15
- 最後の意味あるアクティビティからの時間: 0–10
その上で明確なステータス閾値(例:Green ≥ 75、Yellow 50–74、Red < 50)を定義し、カットオフの理由を文書化してください。
スコアに必要なプロダクトイベントは何を計測すべきですか?
最低限、各イベントに次が含まれるようにしてください:
event_name,user_id,account_id,timestamp(UTC)- 任意の
properties(feature, plan, workspace_id など)
可能なら重要なアクションはサーバーサイドで追跡し、 は制御語彙で管理して、SDK と二重計測しないように注意してください。
ヘルススコア用のデータはどうモデル化・保存すべきですか?
いくつかの中核エンティティをモデル化し、ワークロードで保存先を分けます:
- RDB(例:Postgres):accounts, users, subscriptions, scores
- データウェアハウス:高ボリュームな生イベント
- 集計:日次アカウントサマリや機能別カウンタ(高速なトレンド表示用)
大きなイベントテーブルは日付でパーティションし、account_id でインデックス/クラスタ化して「アカウントの時間変化」クエリを高速化します。
信頼できてデバッグしやすいスコアリングジョブはどう作る?
スコアを生産システムとして扱ってください:
- Raw → Validated → Daily aggregates → Score
- イベントの重複を避けるための冪等性(event_id または安定ハッシュ)
- 集計は
(account_id, date)で upsert する - バックフィル(過去30/90日など)をサポートする
- 各実行に対して入力・導出指標・モデルバージョン・最終スコアを格納する(監査記録)
こうすれば「なぜスコアが下がった?」にログを掘らずに答えられます。
最初に作るべきAPIとアラートルールは何ですか?
まずはワークフローに直結するエンドポイントから:
GET /api/accounts/{id}/health(最新スコア+ステータス)GET /api/accounts/{id}/health/trends?from=&to=(時系列+差分)GET /api/accounts/{id}/health/drivers(主要な正負の要因)
サーバー側で RBAC を強制し、リスト系はカーソルベースのページネーションにし、アラートはクールダウンや最小データ閾値でノイズを減らしてください。アラートはアカウントビュー(例:/accounts/{id})にリンクさせましょう。